Структура оператора SELECT
Среди DML-операторов SELECT является наиболее сложным и важным. Умение составлять SELECT-запросы – необходимое условие разработки приложений БД. В общем случае, SELECT-запрос может быть частью запроса к БД, выполненного с помощью любого другого DML-оператора.
Структура оператора SELECT представлена на рис. 7.1.

Рис. 7.1. Структура оператора SELECT
Оператор SELECT состоит из нескольких секций: SELECT, INTO, FROM, WHERE, GROUP BY, HAVING, ORDER BY. Кроме того, в секции SELECT могут использоваться опции TOP и/или DISTINCT, а в секции ORDER BY опции ASC или DESC. Обязательной является только секция SELECT.
Для пояснения работы оператора SELECT уточним некоторые понятия, который до сих пор использовались интуитивно.
Строка – это упорядоченный список данных, состоящий из одного или нескольких элементов. Каждый элемент списка характеризуется типом данных и уникальным в рамках строки именем. Если имя элемента не задано, то именем считается его номер в списке. Упорядоченная последовательность типов и имен элементов строки называется структурой строки.
Набор однородных строк – набор строк, имеющих одинаковую структуру. Множество элементов из набора однородных строк, имеющих одно и то же имя, образуют столбец набора однородных строк. Набор однородных строк может содержать 0, 1 или более строк. Набор, содержащий 0 строк, называется пустым набором однородных строк. Набор однородных строк, состоящий из одной строки, в которой только один элемент, называется скалярным набором.
Результатом работы SELECT-запроса являются данные, организованные в виде набора однородных строк, называемого результирующим набором данных. Результирующий набор данных, не содержащий ни одной строки, называется пустым результирующим набором данных. Результирующий набор, состоящий из одной строки, в которой только один элемент, называется скалярным результирующим набором.
Основное назначение секции SELECT – указать порядок и имена столбцов результирующего набора данных. Основой для содержимого SELECT-секции является набор однородных строк, описанный во FROM. В простейшем случае SELECT без изменения выводит все столбцы однородного набора строк, сформированного в секции FROM. Опция DISTINCT позволяет избавиться от повторяющихся строк в результирующем наборе, а TOP – ограничить в нем их количество. В общем случае в этой секции указывается список выражений, содержащих имена столбцов набора строк из FROM, константы, а также скалярные результаты SELECT-запросов. Такой список будем называть SELECT-списком. Часто говорят, что SELECT-список определяет вертикаль результирующего набора.
Секция INTO позволяет на основе структуры результирующего набора (заданную SELECT-списком) создать новую таблицу и заполнить ее строками результирующего набора.
Секция FROM в общем случае содержит выражение, результатом которого является набор однородных строк с явно поименованными столбцами. В простейшем случае – это таблица БД, а в общем случае, может быть достаточно сложное выражение, содержащее несколько таблиц, SELECT-запросов, представлений и табличных функций (представления и табличные функции рассматриваются позже).
Секция WHERE применяется для отбора (фильтрации) строк, сформированных в секции FROM. Как правило, секция содержит логическое выражение, которое вычисляется для каждой строки. В том случае, если выражение принимает истинное значение – строка отбирается. Логическое выражение может быть достаточно сложным и содержать в себе другой SELECT-запрос. Говорят, что секция WHERE определяет горизонталь результирующего набора.
GROUP BY – секция, позволяющая сгруппировать данные по значениям, хранящимся в столбцах однородного набора строк, сформированного в секции FROM. Секция GROUP BY ограничивает содержимое SELECT-списка.
Секция HAVING имеет такое же назначение, что и WHERE, но применяется после выполнения секции GROUP BY.
Для сортировки результирующего набора применяется секция ORDER BY. В этой секции может быть указано одно или несколько выражений над элементами столбцами набора однородных строк, сформированного в секции FROM. Выражения дают возможность задать порядок строк в результирующем наборе. Опции ASC и DESC позволяют указать порядок сортировки строк (по возрастанию или по убыванию). Применение опции DISTINCT в секции SELECT ограничивает возможности сортировки.
Очень важным для понимания работы оператора SELECT является последовательность применения сервером СУБД секций и опций SELECT-запроса (рис. 7.2).
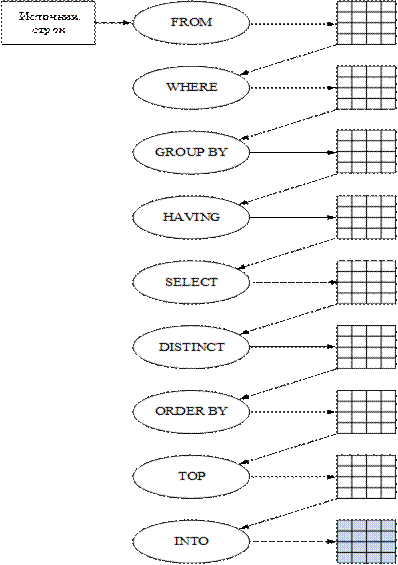
Рис. 7.2. Последовательность выполнения секций в SELECT-запросе
В результате выполнения каждой секции (на рис. 7.2 обозначены овалами) формируются промежуточные результирующие наборы (прямоугольники).
Первой выполняется секция FROM. В этой секции на основе источника строк формируется первый промежуточный результирующий набор данных.
Секция INTO выполняется последней. В ней на основе входящего промежуточного результирующего набора формируется и заполняется строками таблица.
На рис. 7.2 изображены все секции, но в реальном SELECT-запросе такое случается редко. Например, не всякий SELECT-запрос завершается построением новой таблицы. В этом случае, в результате выполнения SELECT-запроса будет сформирован выходной результирующий набор, являющийся выходным для опции TOP. Если не указан TOP, то результат будет сформирован секцией ORDER BY.
Некоторые секции являются зависимыми. Например, секция HAVING может обрабатывать только результат выполнения секции GROUP BY, а при наличии секции DISTINCT, запрещается использовать в секции ORDER BY имена столбцов, отсутствующих в списке SELECT.
Обязательной является только секция SELECT, все остальные секции могут быть опущены. На рис. 7.3 представлены примеры SELECT-запросов разной сложности.
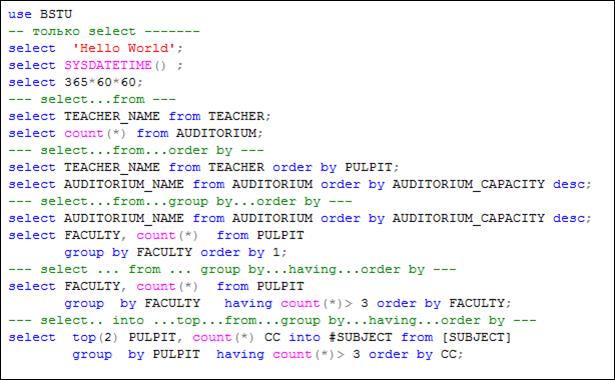
Рис. 7.3. Примеры SELECT-запросов
Список выбора
Список выбора (SELECT-список) определяет перечень и имена столбцов результирующего набора данных. В простейшем случае (рис. 7.4) SELECT-список может содержать константы или выражения независящие от строк, указанных в секции FROM (если она есть).
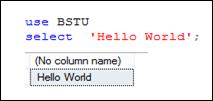
Рис. 7.4. Пример простейшего SELECT-запроса
Обратите внимание (рис. 7.4) на то, что, если секция FROM отсутствует, то в результирующем наборе формируется только одна строка. В SELECT-списке задана строчная константа – она и отобразилась в безымянном столбце результирующего набора (No column name). Имя столбца, может быть задано с помощью ключевого слова AS (рис. 7.5).

Рис. 7.5. SELECT-запрос c поименованными столбцами
SELECT-запрос на рис. 7.5 формирует результирующий набор, состоящий из двух поименованных столбцов. Заданные имена (их еще называют псевдонимами или алиасами) указываются через ключевое слово AS или сразу после элемента списка (AS может быть опущено). Если псевдоним не удовлетворяет правилам именования столбцов таблицы, то его можно указать с применением квадратных скобок.
Если в SELECT-запросе указан источник строк с помощью секции FROM, то в результирующем наборе формируется столько строк, сколько их сформировала секция FROM. В примере на рис. 7.6 в качестве источника используется таблица с именем FACULTY. Таблица содержит шесть строк, поэтому результирующий набор состоит из шести строк. SELECT-список применяется для каждой строки FROM-набора. В связи с тем, что единственное в SELECT-списке выражение (константа) не зависит от значений в строках, значение этого выражения повторяется шесть раз.
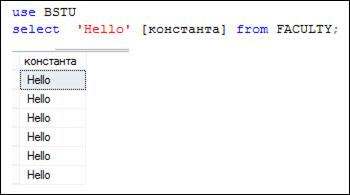
Рис. 7.6. SELECT-запрос с указанным источником строк
Специальное выражение * (звездочка) используется для обозначения списка с именами всех столбцов FROM-набора. В примерах на рис. 7.7 и 7.8 SELECT-запросы формируют результирующие наборы, аналогичные содержимому таблицы FACULTY, являющейся источником строк для FROM-набора.
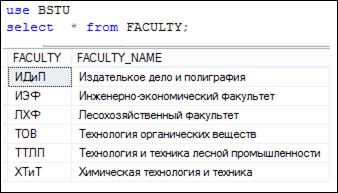
Рис. 7.7. SELECT-запрос, выводящий все столбцы FROM-набора
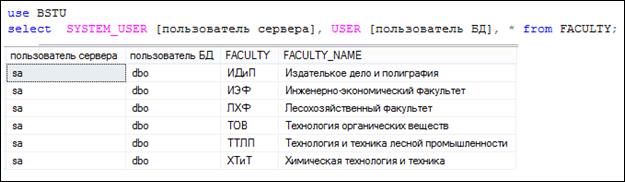
Рис. 7.8. SELECT-запрос, выводящий все столбцы FROM-набора
Обратите внимание на рис. 7.7: в результирующий набор выводятся строки, идентичные строкам таблицы FACULTY.
На рис. 7.8 помимо строк и столбцов таблицы FACULTY имеются два дополнительных столбца, значения в которых формируются для каждой строки FROM-набора, но они никак не зависят от их содержимого.
Список столбцов
Обычно при выполнении SELECT-запроса список столбцов указывается явно (рис. 7.9, 7.10). Если не указаны псевдонимы, то имена столбцов результирующего набора совпадают с именами столбцов источника.
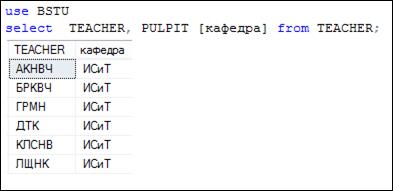
Рис. 7.9. SELECT-запрос с явным списком столбцов
Таблица TEACHER имеет три столбца. В SELECT-запросе на рис. 7.9 в результирующий набор выводится только два столбца, причем второй столбец переименовывается (ему назначается псевдоним).
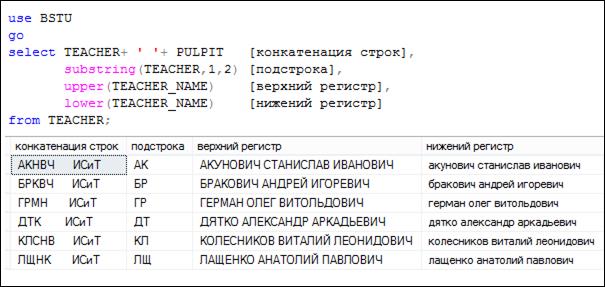
Рис. 7.10. SELECT-запрос, применяющий выражения над содержимым столбцов
Пример на рис. 7.10 демонстрирует применение SELECT-списка, в котором используются выражения над содержимым явно указанных столбцов.
Ключевое слово DISTINCT
На рис. 7.11 представлен SELECT-запрос и фрагмент результирующего набора, сформированного этим запросом.
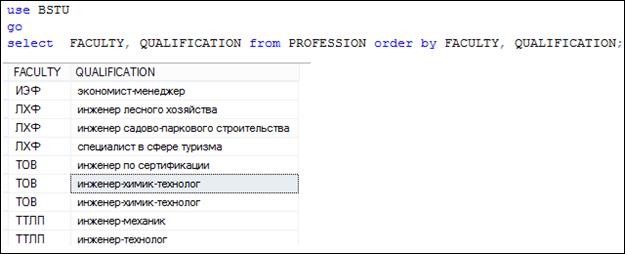
Рис. 7.11. SELECT-запрос, формирующий результирующий набор
с повторяющимися строками
Обратим внимание на то, что среди строк результирующего набора есть повторяющиеся.
Ключевое слово DISTINCT позволяет избавиться от повторяющихся строк (рис. 7.11) в результирующем наборе.
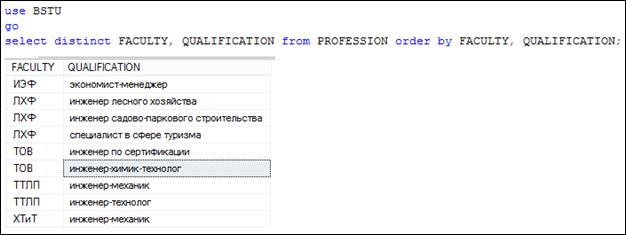
Рис. 7.12. SELECT-запрос с применением ключевого слова DISTINCT
Ключевое слово TOP
Ключевое слово TOP позволяет ограничить количество строк в результирующем выражении.
На рис. 7.13 демонстрируется применение ключевого слова TOP для получения первых трех строк результирующего набора.
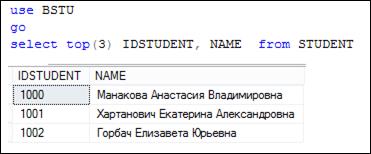
Рис. 7.13. Применение ключевого слова TOP для выбора
первых трех строк результирующего набора данных
Кроме абсолютного значения в TOP можно указать количество выбираемых строк в процентах (рис. 7.14).
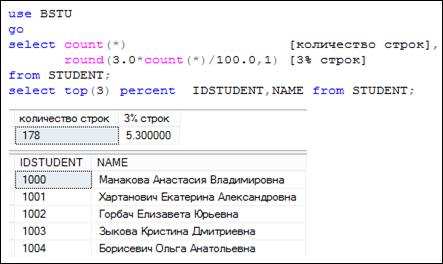
Рис. 7.14. Применение ключевого слова TOP для выбора трех процентов первых строк результирующего набора
Следует отметить, что обычно ключевое слово TOP применяется с секцией ORDER BY, предназначенной для сортировки. Опция TOP выполняется после сортировки – это позволяет отобрать строки, оказавшиеся в результирующем наборе на первых позициях после сортировки.
Допустимо применение TOP совместно с DISTINCT (рис. 7.15). В этом случае, сначала устраняются повторяющиеся строки (выполняется DISTINCT), а потом выбирается заданное количество первых строк (TOP).
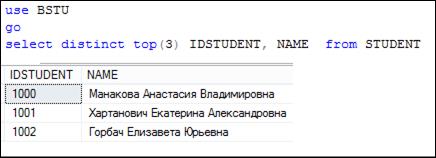
Рис. 7.15. Совместное применение DISTINCT и TOP
Дата: 2019-02-25, просмотров: 374.