| Тип данных | Размер в байтах | Количество байт |
| binary(n) | 1–8000 | n |
| varbinary(n) | 1–8000 | Количество символов + 2 |
| varbinary(max) | 1–(231 – 1) | Количество символов + 2 |
Тип BINARY применяется в том случае, если размер двоичных данных фиксирован, заранее известен и не превышает 8000 байт. В тех случаях, когда нет предположений относительно размера двоичных данных, применяют тип VARBINARY.
На рис. 5.11 и 5.12 приведен пример использования типов для хранения двоичных данных.
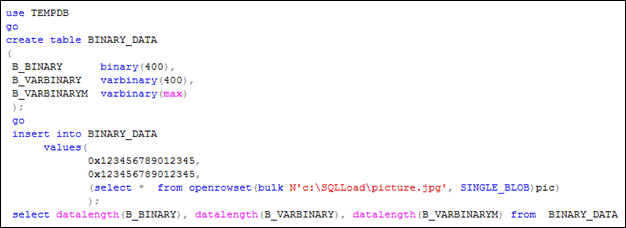
Рис. 5.11. Пример использования типов для хранения двоичных данных

Рис. 5.12. Результат выполнения SELECT-запроса на рис. 5.9
5.2.1.5. Типы данных TIMESTAMP и ROWVERSION. По определению, строки в таблицах БД не имеют порядка. Пользователь, который выбирает строки из одной или нескольких таблиц с помощью оператора SELECT, может установить порядок строк в результирующем наборе только с помощью секции ORDER BY этого оператора.
В процессе обработки данных бывает необходимым установить хронологию изменения данных. Другими словами, необходима возможность отсортировать строки в порядке их ввода или последнего изменения или просто выяснить, какая из двух строк была введена или откорректирована позже, чем другая. Для решения такой задачи могут быть использованы специальный тип данных ROWVERSION и его синоним TIMESTAMP.
Столбец типа ROWVERSION занимает 8 байт и хранит номер (двоичное представление) изменения БД. Другими словами, если в БД были выполнены две операции, изменяющие (INSERT или UPDATE) одну или две разные таблицы, имеющие столбцы типа ROWVERSION, то значение, хранящееся в таком столбце, будет меньшим в строке, которая была введена или откорректирована раньше, чем введена или откорректирована другая строка.
Значения в столбцах типа ROWVERSION может вводиться и изменяться только сервером, пользователь может только считывать это значение в SELECT-запросе.
На рис. 5.13 и 5.14 представлен пример использования типов ROWVERSION и TIMESTAMP.
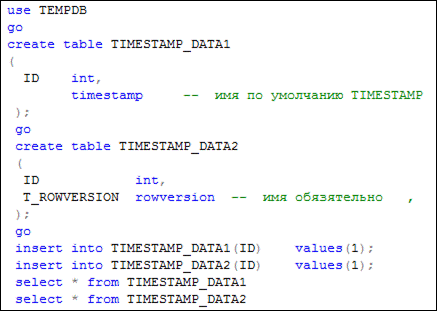
Рис. 5.13. Пример применения типов ROWVERSION и TIMESTAMP
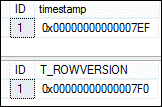
Рис. 5.14. Результаты выполнения SELECT-запросов на рис. 5.13
5.2.1.6. Тип данных UNIQUEIDENTIFIER. Тип данных UNIQUEIDENTIFIER используется для хранения идентификаторов стандарта UUID (Universally Unique Identifier). Идентификаторы типа UNIQUEIDENTIFIER занимают 128 бит и могут быть получены с помощью встроенной функции NEWID. Главная особенность алгоритма генерации UUID-идентификаторов (описан в RFC 4122) – способность генерировать уникальные значения, которые с очень малой вероятностью могут быть независимо получены с помощью этого же алгоритма еще раз.
Пример использования типа UNIQUEIDENTIFIER приведен на рис. 5.15 и 5.16.
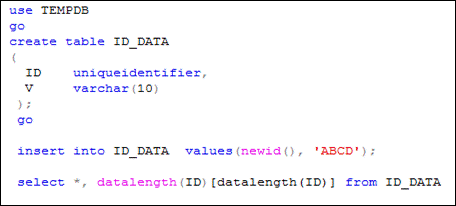
Рис. 5.15. Пример применения типов ROWVERSION и TIMESTAMP

Рис. 5.16. Результат выполнения SELECT-запроса на рис. 5.15
5.2.1.7. Остальные типы данных. Типы данных, которые используются относительно редко, сведены в табл. 5.6. XML-тип будет рассматриваться в этом пособии позже. С полным описанием остальных типов можно ознакомиться в издании [5].
Таблица 5.6
Дата: 2019-02-25, просмотров: 341.