На рис. 5.1 изображена трехуровневая модель БД, отражающая три взгляда на понятие «база данных».

Рис. 5.1. Трехуровневая модель базы данных
С точки зрения системного администратора БД – это набор файлов операционной системы, размещенных на магнитных носителях и имеющих определенную физическую структуру, формат и организацию.
С точки зрения проектировщика БД – это логическая схема данных, представляющая собой набор специальным образом типизированных и структурированных данных с заданными ограничениями и связями. Вид логической схемы зависит от выбранной проектировщиком модели данных. Наиболее известны три модели: иерархическая, сетевая и реляционная. Наиболее распространенной является реляционная модель, использующая в качестве структур данных таблицы, а для доступа к данным – язык SQL. СУБД Microsoft SQL Server 2008 поддерживает реляционную модель данных.
Пользователю БД может быть представлена различными способами: в простейшем случае в виде подмножества таблиц или представлений (объекты БД, о которых будет рассказано позже), набора процедур и функций на языке T- SQL и пр. В общем случае, пользователь БД видит то, что предоставляет используемый им для доступа к данным инструментарий и применяемый интерфейс с БД. Если пользователь – разработчик программного приложения, то его представление во многом зависит от применяемого им программного интерфейса. Если пользователь работает с табличным редактором Excel, то он может применить для доступа к данным PowerPivot – специальное программное средство, встраиваемое в Exс el. Кроме того, представление пользователя зависит от настроек системы безопасности СУБД, регулирующей (часто говорят авторизующей) область видимости данных и порядок доступа к ресурсам БД.
Теория реляционных БД предполагает независимость трех уровней друг от друга. Другими словами физическое размещение данных (физический уровень) никак не должно ограничивать возможности проектирования логической схемы данных, а представления пользователей о БД не зависят от структуры логической схемы. В реальности современные СУБД обеспечивают лишь частичную независимость уровней друг от друга.
Центральное место в рассматриваемой на рис. 5.1 модели занимает логический уровень. Именно здесь определяется состав данных и связи между ними. Процесс проектирования логической схемы реляционной БД заключается в представлении данных в виде набора логически связанных таблиц.
Теория реляционных БД предлагает формализованную процедуру разбиения данных на таблицы. Процедура называется нормализацией и представляет собой поэтапное преобразование логической схемы БД. В результате каждого этапа логическая схема преобразует таблицы (обычно путем вертикального разбиения одной таблицы на несколько) к нормальной форме. Теория различает шесть нормальных форм реляционной таблицы. В практике проектирования применятся только три. Поэтому нормализация заключается в приведении таблиц логической схемы БД к третьей нормальной форме.
Процесс нормализации осуществляется в три этапа: исходными являются таблицы в первой нормальной форме, на втором этапе эти таблицы преобразовываются ко второй, а на третьем – к третьей.
Таблицы в первой нормальной форме построить просто – достаточно все данные разместить в таблицах с неповторяющимися строками. Преобразование таблиц ко второй и затем к третьей нормальным формам основывается на фундаментальном понятии теории реляционных БД – функциональной зависимости данных, изучение которой не предусматривается в данном пособии. Здесь лишь поясним, что процесс нормализации – это процесс устранения избыточности данных (хотя и сопровождается увеличением количества таблиц), позволяющий построить логическую схему БД, предотвращающую неоднозначные (противоречивые) результаты SELECT-запросов.
Для знакомства с основами теории реляционных БД, а также с процессом нормализации рекомендуется прочитать ставшую классической книгу К. Дейта [2].
Создание таблиц
Таблица в БД создается с помощью DDL-оператора CREATE TABLE.
На рис. 5.2 приведен пример создания таблицы AUDITORIUM, предназначенной для хранения данных об аудиторном фонде вуза.

Рис. 5.2. Пример создания таблицы
Таблица AUDITORIUM включает четыре столбца с именами: AUDITORIUM, AUDITORIUM_TYPE, AUDITORIUM_CAPACITY, AUDITORIUM_NAME.
Следует обратить внимание на то, что таблица будет размещена в файловой группе с именем FG1.
Типы данных
Каждый столбец таблицы, создаваемой с помощью оператора CREATE TABLE, характеризуется типом данных, для хранения которых он предназначен. Microsoft SQL Server 2008 поддерживает следующие типы данных: числовые, символьные, для хранения даты и времени, денежные, двоичные и специальные.
5.2.1.1. Числовые данные. Числовые данные могут быть точными и приближенными. В табл. 5.1 сведены точные числовые типы. Все, кроме DECIMAL и NUMERIC, типы являются целочисленными. Тип NUMERIC используется для хранения данных с фиксированной точкой точности p (максимальное количество цифр в числе) и масштабом s (количество цифр после десятичной точки). Тип DECIMAL является синонимом NUMERIC.
Таблица 5.1
Точные числовые типы
| Тип данных | Диапазон значений | Количество байт |
| tinyint | 0–255 | 1 |
| smallint | –32 768–32 768 | 2 |
| int | –231–(231 – 1) | 4 |
| bigint | –263–(263 – 1) | 8 |
| bit | 0 или 1 | 1 |
| decimal(p,s) numeric(p,s) 1 ≤ p ≤ 38, 0 ≤ s < p | (–1038 + 1) – (1038 + 1) | 5–17 |
На рис. 5.3 приведен пример использования точных числовых типов для столбцов таблицы. После создания таблицы с помощью операторов INSERT в нее добавляются три строки, а затем с помощью SELECT содержимое таблицы выводится в результирующий набор (рис. 5.4).
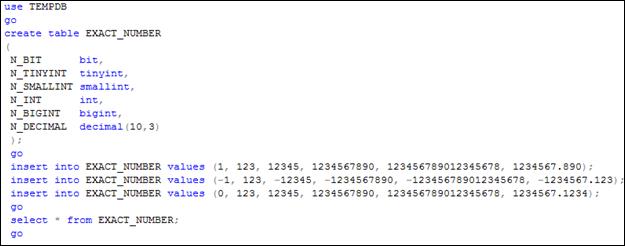
Рис. 5.3. Пример использования точных числовых типов

Рис. 5.4. Результат выполнения SELECT-запроса на рис. 5.3
Следует обратить внимание, что ввод любых отличных от нуля (положительных и отрицательных) значений в столбец типа BIT интерпретируется как единица, а ввод числа с четырьмя знаками после точки в столбец DECIMAL(10,3) приводит к округлению до трех знаков.
В табл. 5.2 сведены приближенные числовые типы. Для типа FLOAT можно указать точность p, но поддерживается только два значения точности: 24 (для всех 1 ≤ p ≤ 24) и 53 (p > 24). По сути, приближенный тип только один – FLOAT, тип REAL является синонимом типа FLOAT(24).
Таблица 5.2
Приближенные числовые типы
| Тип данных | Диапазон значений | Количество байт |
| float(p) 1 ≤ p ≤ 53 | От –1,79·10308 до –2,23·10–308;
0;
от 2,23·10–308 до 1,79·10308 | 4 или 8 |
| real float(24) | От –3,4·1038 до –1,18·10–38; 0; от 1,18·10–38 до 3,4·1038 | 4 |
На рис. 5.5 приведен пример использования приближенных числовых типов для столбцов таблицы. После создания таблицы с помощью операторов INSERT в нее добавляются шесть строк, а затем с помощью SELECT содержимое таблицы выводится в результирующий набор (рис. 5.6).
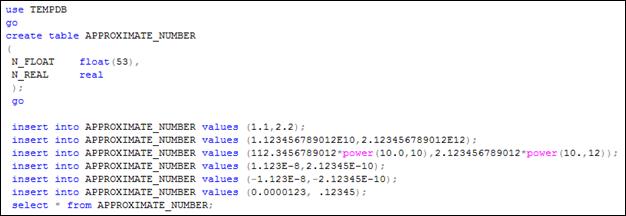
Рис. 5.5. Пример использования приближенных числовых типов
Следует обратить внимание на формат представления чисел, применяемых в операторах INSERT. Символы 1.123E-8 следует интерпретировать как 1,123·10–8 . Кроме того, в третьем операторе INSERT применяется встроенная функция POWER(X,Y), результатом которой является число равное XY.
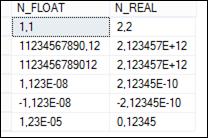
Рис. 5.6. Результат выполнения SELECT-запроса на рис. 5.5
5.2.1.2. Символьные данные. Для хранения символьных данных в таблицах БД применяется шесть типов, перечисленных в табл. 5.3.
Таблица 5.3
Символьные типы
| Тип данных | Размер в символах | Количество байт |
| char(n) | 1–8000 | n |
| varchar(n) | 1–4000 | Количество символов + 2 |
| varchar(max) | 1–(231 – 1) | Количество символов + 2 |
| nchar(n) | 1–8000 | 2n |
| nvarchar(n) | 1–4000 | 2·количество символов + 2 |
| nvarchar(max) | 1–(230 – 1) | 2·количество символов + 2 |
Все символьные типы данных можно разбить на две группы: обычные символьные данные (CHAR, VARCHAR), символьные данные в формате Юникода (NCHAR, NVARCHAR). Обычные символьные данные для хранения одного символа используют один байт. Символьные данные в формате Юникода для хранения одного символа использует два байта.
Типы данных VARCHAR(MAX) и NVARCHAR(MAX) применяются для хранения больших символьных данных объемом до 4 Гб.
На рис. 5.7 приведен пример использования символьных типов. Таблица CHARACTER_DATA состоит из шести столбцов, имеющих различные символьные типы (табл. 5.3). С помощью оператора INSERT в таблицу добавляется одна строка. Следует обратить внимание на литералы, используемые в списке VALUES оператора INSERT: одинарные кавычки ограничивают содержимое строки; символ N, примененный в трех последних элементах списка, обозначает, что далее следует строка в формате Юникода. Обратите внимание, что во все столбцы строки вводятся строки, имеющие по пять символов.
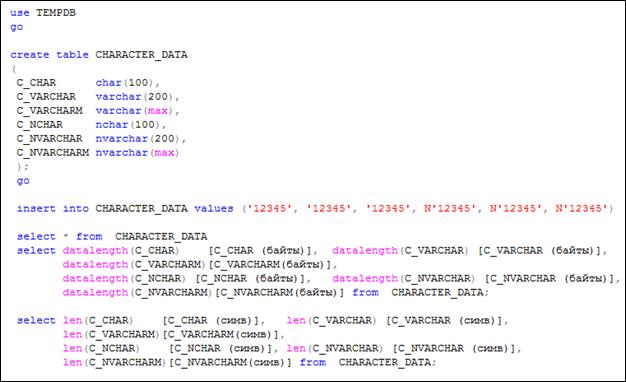
Рис. 5.7. Пример использования символьных типов
За оператором создания таблицы следует три оператора SELECT: первый выводит строку из таблицы, второй – длину в байтах (встроенная функция DATALENGTH) каждого элемента этой строки и третий оператор выводит длину в символах (встроенная функция LEN). Результат выполнения трех SELECT-запросов представлен на рис. 5.8.
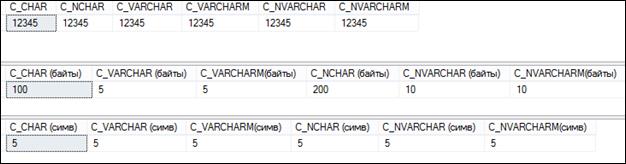
Рис. 5.8. Результат выполнения SELECT-запросов на рис. 5.7
При использовании «широких» типов данных следует помнить об ограничении, которое накладывается на таблицы: указанная при создании суммарная длина строки таблицы не должна превышать 8060 байтов. В расчет не включаются столбцы с типами VARCHAR(MAX) и NVARCHAR(MAX).
5.2.1.3. Типы для хранения даты и времени. Для хранения даты и/или времени применяются типы данных, представленные в табл. 5.4. Для каждого типа указывается диапазон, точность и формат строки, который может быть автоматически преобразован к соответствующему типу.
Таблица 5.4
Типы для даты и времени
| Тип данных | Диапазон, точность, формат | Количество байт |
| date | 01.01.1753–31.12.9999; 1 день; YYYYMMDD | 3 |
| time(p) 0 ≤ p ≤ 7 | 00:00:00.0000000–23:59:59.9999999; 100 нс; hh:mm:ss.nnnnnnn | 3–5 |
| smalldatetime | 01.01.1900 00:00–06.06.2079 23:59, 1 мин; YYYYMMDD hh:mm | 4 |
| datetime | 01.01.1753 00:00:00.000–31.12.9999 23:59:59.999; 0.003 с; YYYYMMDD hh:mm:ss.nnn | 8 |
| datetime2(p) 0 ≤ p ≤ 7 | 01.01.0001 00:00:00.00000000–31.12.9999 23:59:59.9999999; 100 нс; YYYYMMDD hh:mm:ss.nnnnnnnn | 6–8 |
| datetimeoffset(p) 0 ≤ p ≤ 7 | 01.01.0001.00:00:00:00000000+00:00–31.12.9999.23:59:59:9999999+23:59; 100 нс; YYYYMMDDhh:mm:ss:nnnnnnnn ± hh:mm | 8–10 |
На рис. 5.9 и 5.10 приведен пример использования типов для хранения даты и времени в таблицах БД. Для некоторых типов можно указать точность (в табл. 5.4 обозначается символом p), которая задает количество знаков после десятичной точки в секундах.
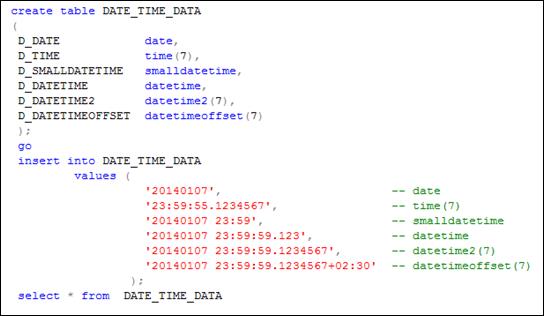
Рис. 5.9. Пример применения типов для хранения даты и времени

Рис. 5.10. Результат использования SELECT-запроса на рис. 5.9
Следует обратить внимание на формат данных в строковых литералах, используемых при вводе или корректировке (операторы INSERT и UPDATE) даты и времени. Приведенные в табл. 5.4 и на рис. 5.9 форматы не являются единственно возможными. В пособии [5] можно ознакомиться с другими формами представления даты и времени в виде строки. Кроме того, можно воспользоваться встроенными функциями преобразования CAST или CONVERT (будут рассматриваться ниже), с помощью которых можно явно преобразовать строку к одному типу из строки в дату и/или время.
5.2.1.4. Двоичные данные. В некоторых случаях в БД необходимо хранить просто последовательность битов безотносительно их дальнейшего применения. Другими словами Microsoft SQL Server 2008 ничего не «знает» о формате таких данных и рассматривает их как последовательность (часто говорят – поток) битов. О том, как использовать (интерпретировать) эти данные, решает пользователь, извлекающий эти данные из соответствующего столбца таблицы. Типы для хранения двоичных данных (говорят также – бинарных данных) часто применяются для хранения изображений (например, фотографий, фильмов) и звука. В то же время в двоичном виде можно хранить любые данные, например, файлы форматов PDF, DOC, XLS.
Типы, которые используются для хранения бинарных данных, перечислены в табл. 5.5.
Таблица 5.5
Дата: 2019-02-25, просмотров: 372.