Криптография. Общая схема симметричного шифрования. Примеры симметричных алгоритмов шифрования
Методы замены
Методы шифрования заменой (подстановкой) основаны на том, что символы исходного текста, обычно разделенные на блоки и записанные в одном алфавите, заменяются одним или несколькими символами другого алфавита в соответствии с принятым правилом преобразования.
Одноалфавитная замена
Одним из важных подклассов методов замены являются одноалфавитные (или моноалфавитные) подстановки, в которых устанавливается однозначное соответствие между каждым знаком ai исходного алфавита сообщений A и соответствующим знаком ei зашифрованного текста E. Одноалфавитная подстановка иногда называется также простой заменой, так как является самым простым шифром замены.
Примером одноалфавитной замены является шифр Цезаря, рассмотренный ранее. В рассмотренном в примере первая строка является исходным алфавитом, вторая (с циклическим сдвигом на k влево) – вектором замен.
В общем случае при одноалфавитной подстановке происходит однозначная замена исходных символов их эквивалентами из вектора замен (или таблицы замен). При таком методе шифрования ключом является используемая таблица замен.
Подстановка может быть задана с помощью таблицы, например, как показано на рис. 2.3.
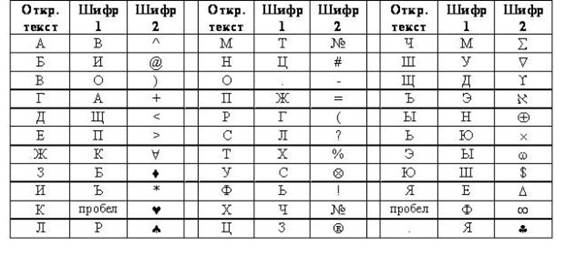
Рис. 2.3. Пример таблицы замен для двух шифров
В таблице на рис. 2.3 на самом деле объединены сразу две таблицы. Одна (шифр 1) определяет замену русских букв исходного текста на другие русские буквы, а вторая (шифр 2) – замену букв на специальные символы. Исходным алфавитом для обоих шифров будут заглавные русские буквы (за исключением букв "Ё" и "Й"), пробел и точка.
Зашифрованное сообщение с использованием любого шифра моноалфавитной подстановки получается следующим образом. Берется очередной знак из исходного сообщения. Определяется его позиция в столбце "Откр. текст" таблицы замен. В зашифрованное сообщение вставляется шифрованный символ из этой же строки таблицы замен.
Полученный таким образом текст имеет сравнительно низкий уровень защиты, так как исходный и зашифрованный тексты имеют одинаковые статистические закономерности. При этом не имеет значения, какие символы использованы для замены – перемешанные символы исходного алфавита или таинственно выглядящие знаки.
Зашифрованное сообщение может быть вскрыто путем так называемого частотного криптоанализа. Для этого могут быть использованы некоторые статистические данные языка, на котором написано сообщение.
Известно, что в текстах на русском языке наиболее часто встречаются символы О, И. Немного реже встречаются буквы Е, А. Из согласных самые частые символы Т, Н, Р, С. В распоряжении криптоаналитиков имеются специальные таблицы частот встречаемости символов для текстов разных типов – научных, художественных и т.д.
Криптоаналитик внимательно изучает полученную криптограмму, подсчитывая при этом, какие символы сколько раз встретились. Вначале наиболее часто встречаемые знаки зашифрованного сообщения заменяются, например, буквами О. Далее производится попытка определить места для букв И, Е, А. Затем подставляются наиболее часто встречаемые согласные. На каждом этапе оценивается возможность "сочетания" тех или иных букв. Например, в русских словах трудно найти четыре подряд гласные буквы, слова в русском языке не начинаются с буквы Ы и т.д. На самом деле для каждого естественного языка (русского, английского и т.д.) существует множество закономерностей, которые помогают раскрыть специалисту зашифрованные противником сообщения.
Возможность однозначного криптоанализа напрямую зависит от длины перехваченного сообщения. Если же в руки криптоаналитиков попадает достаточно длинное сообщение, зашифрованное методом простой замены, его обычно удается успешно дешифровать. На помощь специалистам по вскрытию криптограмм приходят статистические закономерности языка. Чем длиннее зашифрованное сообщение, тем больше вероятность его однозначного дешифрования.
Интересно, что если попытаться замаскировать статистические характеристики открытого текста, то задача вскрытия шифра простой замены значительно усложнится. Например, с этой целью можно перед шифрованием "сжимать" открытый текст с использованием компьютерных программ-архиваторов.
С усложнением правил замены увеличивается надежность шифрования. Можно заменять не отдельные символы, а, например, двухбуквенные сочетания – биграммы. Таблица замен для такого шифра может выглядеть, как в таблице 2.3.
| Таблица 2.3. Пример таблицы замен для двухбуквенных сочетаний | |||
| Откр. текст | Зашифр. текст | Откр. текст | Зашифр. текст |
| аа | кх | бб | пш |
| аб | пу | бв | вь |
| ав | жа | ... | ... |
| ... | ... | яэ | сы |
| ая | ис | яю | ек |
| ба | цу | яя | рт |
Оценим размер такой таблицы замен. Если исходный алфавит содержит N символов, то вектор замен для биграммного шифра должен содержать N2 пар "откр. текст – зашифр. текст". Таблицу замен для такого шифра можно также записать и в другом виде: заголовки столбцов соответствуют первой букве биграммы, а заголовки строк – второй, причем ячейки таблицы заполнены заменяющими символами. В такой таблице будет N строк и N столбцов (таблица 2.4).
| Таблица 2.4. Другой вариант задания таблицы замен для биграммного шифра | ||||
| а | б | ... | я | |
| а | кх | цу | ... | ... |
| б | пу | пш | ... | ... |
| в | жа | вь | ... | ... |
| ... | ... | ... | ... | ... |
| ю | ... | ... | ... | ек |
| я | ис | ... | ... | рт |
Возможны варианты использования триграммного или вообще n-граммного шифра. Такие шифры обладают более высокой криптостойкостью, но они сложнее для реализации и требуют гораздо большего количества ключевой информации (большой объем таблицы замен). В целом, все n-граммные шифры могут быть вскрыты с помощью частотного криптоанализа, только используется статистика встречаемости не отдельных символов, а сочетаний из n символов.
Пропорциональные шифры
К одноалфавитным методам подстановки относятся пропорциональные или монофонические шифры, в которых уравнивается частота появления зашифрованных знаков для защиты от раскрытия с помощью частотного анализа. Для знаков, встречающихся часто, используется относительно большое число возможных эквивалентов. Для менее используемых исходных знаков может оказаться достаточным одного или двух эквивалентов. При шифровании замена для символа открытого текста выбирается либо случайным, либо определенным образом (например, по порядку).
При использовании пропорционального шифра в качестве замены символам обычно выбираются числа. Например, поставим в соответствие буквам русского языка трехзначные числа, как указано в таблице 2.5.
| Таблица 2.5. Таблица замен для пропорционального шифра | |||||||||||
| Символ | |||||||||||
Варианты замены
Варианты замены
В этом случае сообщение
БОЛЬШОЙ СЕКРЕТможет быть зашифровано следующим образом:
101757132562103213762751800761754134130759В данном примере варианты замен для повторяющихся букв (например, "О") выбирались по порядку.
Пропорциональные шифры более сложны для вскрытия, чем шифры простой одноалфавитной замены. Однако, если имеется хотя бы одна пара "открытый текст – шифротекст", вскрытие производится тривиально. Если же в наличии имеются только шифротексты, то вскрытие ключа, то есть нахождение таблицы замен, становится более трудоемким, но тоже вполне осуществимым.
Многоалфавитные подстановки
В целях маскирования естественной частотной статистики исходного языка применяется многоалфавитная подстановка, которая также бывает нескольких видов. В многоалфавитных подстановках для замены символов исходного текста используется не один, а несколько алфавитов. Обычно алфавиты для замены образованы из символов исходного алфавита, записанных в другом порядке.
Примером многоалфавитной подстановки может служить схема, основанная на использовании таблицы Вижинера. Этот метод, известный уже в XVI веке, был описан французом Блезом Вижинером в "Трактате о шифрах", вышедшем в 1585 году. В этом методе для шифрования используется таблица, представляющая собой квадратную матрицу с числом элементов NxN, где N — количество символов в алфавите ( таблица 2.6). В первой строке матрицы записывают буквы в порядке очередности их в исходном алфавите, во второй — ту же последовательность букв, но с циклическим сдвигом влево на одну позицию, в третьей — со сдвигом на две позиции и т. д.
| Таблица 2.6. Подготовка таблицы шифрования | |
| АБВГДЕ........ | ..........ЭЮЯ |
| БВГДЕЖ........ | ..........ЮЯА |
| ВГДЕЖЗ........ | ..........ЯАБ |
| ГДЕЖЗИ......... | ..........АБВ |
| ДЕЖЭИК......... | ..........БВГ |
| ЕЖЗИКЛ......... | ..........ВГД |
| ........... | .......... |
| ЯАБВГД......... | ..........ЬЭЮ |
Для шифрования текста выбирают ключ, представляющий собой некоторое слово или набор символов исходного алфавита. Далее из полной матрицы выписывают подматрицу шифрования, включающую первую строку и строки матрицы, начальными буквами которых являются последовательно буквы ключа.
В процессе шифрования под каждой буквой шифруемого текста записывают буквы ключа, повторяющие ключ требуемое число раз, затем шифруемый текст по таблице шифрования заменяют буквами, расположенными на пересечениях линий, соединяющих буквы текста первой строки таблицы и буквы ключа, находящейся под ней.
Рассмотрим на примере процесс расшифрования сообщения по методу Вижинера. Пусть имеется зашифрованное с помощью ключа ВЕСНА сообщение КЕКХТВОЭЦОТССВИЛ (пробелы при шифровании пропущены). Расшифровка текста выполняется в следующей последовательности:
· над буквами шифрованного текста сверху последовательно записывают буквы ключа, повторяя ключ требуемое число раз;
· в строке подматрицы таблицы Вижинера для каждой буквы ключа отыскивается буква, соответствующая знаку шифрованного текста. Находящаяся над ней буква первой строки и будет знаком расшифрованного текста;
· полученный текст группируется в слова по смыслу.
Раскрыть шифр Вижинера, тем же способом, что и шифр одноалфавитной замены, невозможно, так как одни и те же символы открытого текста могут быть заменены различными символами зашифрованного текста. С другой стороны, различные буквы открытого текста могут быть заменены одинаковыми знаками зашифрованного текста.
Особенность данного метода многоалфавитной подстановки заключается в том, что каждый из символов ключа используется для шифрования одного символа исходного сообщения. После использования всех символов ключа, они повторяются в том же порядке. Если используется ключ из десяти букв, то каждая десятая буква сообщения шифруется одним и тем же символом ключа. Этот параметр называется периодом шифра. Если ключ шифрования состоит из одного символа, то при шифровании будет использоваться одна строка таблицы Вижинера, следовательно, в этом случае мы получим моноалфавитную подстановку, а именно шифр Цезаря.
С целью повышения надежности шифрования текста можно использовать подряд два или более зашифрования по методу Вижинера с разными ключами (составной шифр Вижинера).
На практике кроме метода Вижинера использовались также различные модификации этого метода. Например, шифр Вижинера с перемешанным один раз алфавитом. В этом случае для расшифрования сообщения получателю необходимо кроме ключа знать порядок следования символов в таблице шифрования.
Еще одним примером метода многоалфавитной подстановки является шифр с бегущим ключом или книжный шифр. В этом методе один текст используется в качестве ключа для шифрования другого текста. В эпоху "докомпьютерной" криптографии в качестве ключа для шифра с бегущим ключом выбирали какую-нибудь достаточно толстую книгу; от этого и произошло второе название этого шифра. Периодом в таком методе шифрования будет длина выбранного в качестве ключа произведения.
Методы многоалфавитной подстановки, в том числе и метод Вижинера, значительно труднее поддаются "ручному" криптоанализу. Для вскрытия методов многоалфавитной замены разработаны специальные, достаточно сложные алгоритмы. С использованием компьютера вскрытие метода многоалфавитной подстановки возможно достаточно быстро благодаря высокой скорости проводимых операций и расчетов.
В первой половине ХХ века для автоматизации процесса выполнения многоалфавитных подстановок стали широко применять роторные шифровальные машины. Главными элементами в таких устройствах являлись роторы – механические колеса, используемые для выполнения подстановки. Роторная шифровальная машина содержала обычно клавиатуру и набор роторов. Каждый ротор содержал набор символов (по количеству в алфавите), размещенных в произвольном порядке, и выполнял простую одноалфавитную подстановку. После выполнения первой замены символы сообщения обрабатывались вторым ротором и так далее. Роторы могли смещаться, что и задавало ключ шифрования. Некоторые роторные машины выполняли также и перестановку символов в процессе шифрования. Самым известным устройством подобного класса являлась немецкая шифровальная роторная машина Энигма (лат. Enigma — загадка), использовавшаяся во время второй мировой войны. Выпускалось несколько моделей Энигмы с разным числом роторов. В шифрмашине Энигма с тремя роторами можно было использовать 16900 разных алфавитов, и все они представляли собой различные перестановки символов.
Методы гаммирования
Еще одним частным случаем многоалфавитной подстановки является гаммирование. В этом способе шифрование выполняется путем сложения символов исходного текста и ключа по модулю, равному числу букв в алфавите. Если в исходном алфавите, например, 33 символа, то сложение производится по модулю 33. Такой процесс сложения исходного текста и ключа называется в криптографии наложением гаммы.
Пусть символам исходного алфавита соответствуют числа от 0 (А) до 32 (Я). Если обозначить число, соответствующее исходному символу, x, а символу ключа – k, то можно записать правило гаммирования следующим образом: z = x + k (mod N),
где z – закодированный символ, N - количество символов в алфавите, а сложение по модулю N - операция, аналогичная обычному сложению, с тем отличием, что если обычное суммирование дает результат, больший или равный N, то значением суммы считается остаток от деления его на N. Например, пусть сложим по модулю 33 символы Г (3) и Ю (31): 3 + 31 (mod 33) = 1, то есть в результате получаем символ Б, соответствующий числу 1.
Наиболее часто на практике встречается двоичное гаммирование. При этом используется двоичный алфавит, а сложение производится по модулю два. Операция сложения по модулю 2 часто обозначается  , то есть можно записать:
, то есть можно записать:
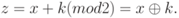
Операция сложения по модулю два в алгебре логики называется также "исключающее ИЛИ" или по-английски XOR.
Сложим по модулю два двоичные числа 1110 и 1100:
Исходное число 1 1 1 0Гамма 1 1 0 0Результат 0 0 1 0В результате сложения получили двоичное число 0010. Если перевести его в десятичную форму, получим 2. Таким образом, в результате применения к числу 14 операции гаммирования с ключом 12 получаем в результате число 2.
Каким же образом выполняется расшифрование? Зашифрованное число 2 представляется в двоичном виде и снова производится сложение по модулю 2 с ключом:
Зашифрованное число 0 0 1 0Гамма 1 1 0 0Результат 1 1 1 0Переведем полученное двоичное значение 1110 в десятичный вид и получим 14, то есть исходное число.
Таким образом, при гаммировании по модулю 2 нужно использовать одну и ту же операцию как для зашифрования, так и для расшифрования. Это позволяет использовать один и тот же алгоритм, а соответственно и одну и ту же программу при программной реализации, как для шифрования, так и для расшифрования.
Операция сложения по модулю два очень быстро выполняется на компьютере (в отличие от многих других арифметических операций), поэтому наложение гаммы даже на очень большой открытый текст выполняется практически мгновенно. Благодаря указанным достоинствам метод гаммирования широко применяется в современных технических системах сам по себе, а также как элемент комбинированных алгоритмов шифрования.
Методы перестановки
При использовании шифров перестановки входной поток исходного текста делится на блоки, в каждом из которых выполняется перестановка символов. Перестановки в классической "докомпьютерной" криптографии получались в результате записи исходного текста и чтения шифрованного текста по разным путям геометрической фигуры.
Простейшим примером перестановки является перестановка с фиксированным периодом d. В этом методе сообщение делится на блоки по d символов и в каждом блоке производится одна и та же перестановка. Правило, по которому производится перестановка, является ключом и может быть задано некоторой перестановкой первых d натуральных чисел. В результате сами буквы сообщения не изменяются, но передаются в другом порядке.
Например, для d=6 в качестве ключа перестановки можно взять 436215. Это означает, что в каждом блоке из 6 символов четвертый символ становится на первое место, третий – на второе, шестой – на третье и т.д.
Теоретически, если блок состоит из d символов, то число возможных перестановок d!=1*2*...*(d-1)*d. В последнем примере d=6, следовательно, число перестановок равно 6!=1*2*3*4*5*6=720. Таким образом, если противник перехватил зашифрованное сообщение из рассмотренного примера, ему понадобится не более 720 попыток для раскрытия исходного сообщения (при условии, что размер блока известен противнику).
Для повышения криптостойкости можно последовательно применить к шифруемому сообщению две или более перестановки с разными периодами.
Другим примером методов перестановки является перестановка по таблице. В этом методе производится запись исходного текста по строкам некоторой таблицы и чтение его по столбцам этой же таблицы. Последовательность заполнения строк и чтения столбцов может быть любой и задается ключом.
Рассмотрим пример. Пусть в таблице кодирования будет 4 столбца и 3 строки (размер блока равен 3*4=12 символов). Зашифруем такой текст: ЭТО ТЕКСТ ДЛЯ ШИФРОВАНИЯ
Количество символов в исходном сообщении равно 24, следовательно, сообщение необходимо разбить на 2 блока. Запишем каждый блок в свою таблицу по строчкам ( таблица 2.9).
| Таблица 2.9. Шифрование методом перестановки по таблице | |||
Блок
Блок
Затем будем считывать из таблицы каждый блок последовательно по столбцам:
ЭТТТЕ ОКД СЛЯФА РНШОИИВЯМожно считывать столбцы не последовательно, а, например, так: третий, второй, первый, четвертый:
ОКДТЕ ЭТТ СЛШОИ РНЯФАИВЯВ этом случае порядок считывания столбцов и будет ключом.
В случае, если размер сообщения не кратен размеру блока, можно дополнить сообщение какими-либо символами, не влияющими на смысл, например, пробелами. Однако это делать не рекомендуется, так как это дает противнику в случае перехвата криптограммы информацию о размере используемой таблицы перестановок (длине блока). После определения длины блока противник может найти длину ключа (количество столбцов таблицы) среди делителей длины блока.
Существуют и другие способы перестановки, которые можно реализовать программным и аппаратным путем. Например, при передаче данных, записанных в двоичном виде, удобно использовать аппаратный блок, который перемешивает определенным образом с помощью соответствующего электрического монтажа биты исходного n-разрядного сообщения. Так, если принять размер блока равным восьми битам, можно, к примеру, использовать такой блок перестановки, как на рис. 2.7.
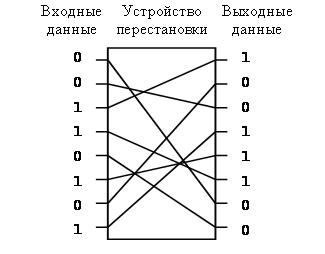
Рис. 2.7. Аппаратный блок перестановки
Для расшифрования на приемной стороне устанавливается другой блок, восстанавливающий порядок цепей.
Аппаратно реализуемая перестановка широко используется на практике как составная часть некоторых современных шифров.
При перестановке любого вида в зашифрованное сообщение будут входить те же символы, что и в открытый текст, но в другом порядке. Следовательно, статистические закономерности языка останутся без изменения. Это дает криптоаналитику возможность использовать различные методы для восстановления правильного порядка символов.
Если у противника есть возможность пропускать через систему шифрования методом перестановки специально подобранные сообщения, то он сможет организовать атаку по выбранному тексту. Так, если длина блока в исходном тексте равна N символам, то для раскрытия ключа достаточно пропустить через шифровальную систему N-1 блоков исходного текста, в которых все символы, кроме одного, одинаковы. Другой вариант атаки по выбранному тексту возможен в случае, если длина блока N меньше количества символов в алфавите. В этом случае можно сформировать одно специальное сообщение из разных букв алфавита, расположив их, например, по порядку следования в алфавите. Пропустив подготовленное таким образом сообщение через шифровальную систему, специалисту по криптоанализу останется только посмотреть, на каких позициях очутились символы алфавита после шифрования, и составить схему перестановки.
Блочные симметричные шифры
Основные сведения
Одной из наиболее известных криптографических систем с закрытым ключом является DES – Data Encryption Standard. Эта система первой получила статус государственного стандарта в области шифрования данных. Она разработана специалистами фирмы IBM и вступила в действие в США 1977 году. Алгоритм DES широко использовался при хранении и передаче данных между различными вычислительными системами; в почтовых системах, в электронных системах чертежей и при электронном обмене коммерческой информацией. Стандарт DES реализовывался как программно, так и аппаратно. Предприятиями разных стран был налажен массовый выпуск цифровых устройств, использующих DES для шифрования данных. Все устройства проходили обязательную сертификацию на соответствие стандарту.
Несмотря на то, что уже некоторое время эта система не имеет статуса государственного стандарта, она по-прежнему широко применяется и заслуживает внимания при изучении блочных шифров с закрытым ключом.
Длина ключа в алгоритме DES составляет 56 бит. Именно с этим фактом связана основная полемика относительно способности DES противостоять различным атакам. Как известно, любой блочный шифр с закрытым ключом можно взломать, перебрав все возможные комбинации ключей. При длине ключа 56 бит возможны 256 разных ключей. Если компьютер перебирает за одну секунду 1 000 000 ключей (что примерно равно 220), то на перебор всех 256 ключей потребуется 236 секунд или чуть более двух тысяч лет, что, конечно, является неприемлемым для злоумышленников.
Однако возможны более дорогие и быстрые вычислительные системы, чем персональный компьютер. Например, если иметь возможность объединить для проведения параллельных вычислений миллион процессоров, то максимальное время подбора ключа сокращается примерно до 18 часов. Это время не слишком велико, и криптоаналитик, оснащенный подобной дорогой техникой, вполне может выполнить вскрытие данных, зашифрованных DES за приемлемое для себя время.
Вместе с этим можно отметить, что систему DES вполне можно использовать в небольших и средних приложениях для шифрования данных, имеющих небольшую ценность. Для шифрования данных государственной важности или имеющих значительную коммерческуюстоимость система DES в настоящее время, конечно, не должна использоваться. В 2001 году после специально объявленного конкурса в США был принят новый стандарт на блочный шифр, названный AES (Advanced Encryption Standard), в основу которого был положен шифр Rijndael, разработанный бельгийскими специалистами.
Основные параметры DES: размер блока 64 бита, длина ключа 56 бит, количество раундов – 16. DES является классической сетью Фейштеля с двумя ветвями. Алгоритм преобразует за несколько раундов 64-битный входной блок данных в 64-битный выходной блок. Стандарт DES построен на комбинированном использовании перестановки, замены и гаммирования. Шифруемые данные должны быть представлены в двоичном виде.
Односторонние функции
Все алгоритмы шифрования с открытым ключом основаны на использовании так называемых односторонних функций. Односторонней функцией (one-way function) называется математическая функция, которую относительно легко вычислить, но трудно найти по значению функции соответствующее значение аргумента. То есть, зная х легко вычислить f(x), но по известному f(x) трудно найти подходящее значение x. Под словом "трудно вычислить" понимают, что для этого потребуется не один год расчетов с использованием ЭВМ. Односторонние функции применяются в криптографии также в качестве хеш-функций. Использовать односторонние функции для шифрования сообщений с целью их защиты не имеет смысла, так как обратно расшифровать зашифрованное сообщение уже не получится. Для целей шифрования используются специальные односторонние функции – односторонние функции с люком (или с секретом) – это особый вид односторонних функций, имеющих некоторый секрет (люк), позволяющий относительно быстро вычислить обратное значение функции.
Для односторонней функции с люком f справедливы следующие утверждения:
1. зная х, легко вычислить f(x),
2. по известному значению f(x) трудно найти x,
3. зная дополнительно некоторую секретную информацию, можно легко вычислить x.
Требования к алгоритмам шифрования с открытым ключом
Рассмотрев основные способы применения алгоритмов шифрования с открытым ключом, изучим требования, которым должен, по мнению основоположников теории шифрования с открытым ключом Диффи и Хеллмана, удовлетворять алгоритм шифрования с открытым ключом. Эти требования следующие:
1. Вычислительно легко создавать пару (открытый ключ, закрытый ключ).
2. Вычислительно легко зашифровать сообщение открытым ключом.
3. Вычислительно легко расшифровать сообщение, используя закрытый ключ.
4. Вычислительно невозможно, зная открытый ключ, определить соответствующий закрытый ключ.
5. Вычислительно невозможно, зная только открытый ключ и зашифрованное сообщение, восстановить исходное сообщение.
Алгоритм RSA
Основные сведения
Алгоритм шифрования с открытым ключом RSA был предложен одним из первых в конце 70-х годов ХХ века. Его название составлено из первых букв фамилий авторов: Р.Райвеста (R.Rivest), А.Шамира (A.Shamir) и Л.Адлемана (L.Adleman). Алгоритм RSA является, наверно, наиболее популярным и широко применяемым асимметричным алгоритмом в криптографических системах.
Алгоритм основан на использовании того факта, что задача разложения большого числа на простые сомножители является трудной. Криптографическая система RSA базируется на следующих двух фактах из теории чисел:
1. задача проверки числа на простоту является сравнительно легкой;
2. задача разложения чисел вида n = pq ( р и q — простые числа); на множители является очень трудной, если мы знаем только n, а р и q — большие числа (это так называемая задача факторизации).
Алгоритм RSA представляет собой блочный алгоритм шифрования, где зашифрованные и незашифрованные данные должны быть представлены в виде целых чисел между 0 и n -1 для некоторого n.
Общие понятия
Электронная подпись (ЭП) – это особый реквизит документа, который позволяет установить отсутствие искажения информации в электронном документе с момента формирования ЭП и подтвердить принадлежность ЭП владельцу. Значение реквизита получается в результате криптографического преобразования информации.
Сертификат электронной подписи – документ, который подтверждает принадлежность открытого ключа (ключа проверки) ЭП владельцу сертификата. Выдаются сертификаты удостоверяющими центрами (УЦ) или их доверенными представителями.
В законе «Об электронной подписи» четко сказано, что такое УЦ:
Удостоверяющий центр — юридическое лицо или индивидуальный предприниматель, осуществляющие функции по созданию и выдаче сертификатов ключей проверки электронных подписей, а также иные функции, предусмотренные настоящим Федеральным законом. (ФЗ «Об электронной подписи»).
Владелец сертификата ЭП – физическое лицо, на чье имя выдан сертификат ЭП в удостоверяющем центре. У каждого владельца сертификата на руках два ключа ЭП: закрытый и открытый.
Закрытый ключ электронной подписи (ключ ЭП) позволяет генерировать электронную подпись и подписывать электронный документ. Владелец сертификат обязан в тайне хранить свой закрытый ключ.
Открытый ключ электронной подписи (ключ проверки ЭП) однозначно связан с закрытым ключом ЭП и предназначен для проверки подлинности ЭП.
Ниже представлены схема подписания электронного документа и схема проверки его неизменности.
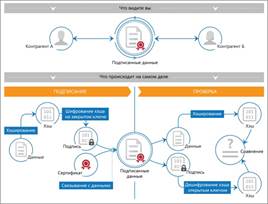
Рис. 13.1. Схема подписания электронного документа и схема проверки электронной подписи
Согласно Федеральному закону №63-ФЗ «Об электронной подписи», имеет место деление на:
¾ простую электронную подпись;
¾ усиленную неквалифицированную электронную подпись;
¾ усиленную квалифицированную электронную подпись.
Простая электронная подпись посредством использования кодов, паролей или иных средств подтверждает факт формирования ЭП определенным лицом.
Усиленную неквалифицированную электронную подпись получают в результате криптографического преобразования информации с использованием закрытого ключа подписи. Данная ЭП позволяет определить лицо, подписавшее электронный документ, и обнаружить факт внесения изменений после подписания электронных документов.
Усиленная квалифицированная электронная подпись соответствует всем признакам неквалифицированной электронной подписи, но для создания и проверки ЭП используются средства криптозащиты, которые сертифицированы ФСБ РФ. Кроме того, сертификаты квалифицированной ЭП выдаются исключительно аккредитованными удостоверяющими центрами (Перечень аккредитованных УЦ).
Согласно ФЗ № 63 «Об электронной подписи» электронный документ, подписанный простой или усиленной неквалифицированной ЭП, признается равнозначным документу на бумажном носителе, подписанному собственноручной подписью. При этом обязательным является соблюдение следующего условия: между участниками электронного взаимодействия должно быть заключено соответствующее соглашение.
Усиленная квалифицированная подпись на электронном документе является аналогом собственноручной подписи и печати на бумажном документе. Контролирующие органы, такие как ФНС, ПФР, ФСС, признают юридическую силу только тех документов, которые подписаны квалифицированной ЭП.
Механизм ЭП
Обратимся непосредственно к механизму ЭП. Наибольшее распространение получили алгоритмы с использованием открытого ключа.
ЭП решает 2 задачи: определение авторства и неизменности документа. Существует множество алгоритмов, но все они направлены на их решение и имеют общую суть.
Предположим, что мы имеем сообщение M, открытый ключ K, закрытый ключ k и функцию f() с обратной ей F().
Рассмотрим механизм подписи.
Так как подпись должна иметь стандартные размеры, а текст может быть подписан любой, при создании подписи используют так называемую функцию хеширования, значение которой для любого уникального массива данных так же уникально и однозначно, но имеет стандартный размер и не позволяет восстановить исходные данные. Обозначим эту функцию H().
Подписание происходит следующим образом:
¾ для данных вычисляется значение хеш-функции h=H(M),
¾ затем это значение шифруется с помощью закрытого ключа s=f(h,k).
Значение s и будет являться ЭП для сообщения M.
Для проверки подписи производятся следующие вычисления:
¾ вычисляется значение хеша для сообщения h=H(M),
¾ после чего с помощью открытого ключа расшифровывается значение s h’=F(s,K).
Если h’ = h, то подпись верна. В противном случае возможны 2 варианта: использовался неверный открытый ключ (то есть, авторство не определено) или сообщение было искажено.
То же самое, но в картинках:
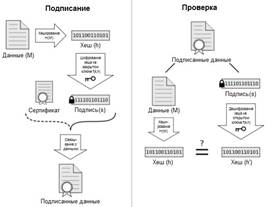
Рис. 13.3. Схема подписания электронного документа и схема проверки электронной подписи
Зачем нужен сертификат?
Зачем нам вообще что-то подписывать? Естественно, чтобы удостоверить, что мы ознакомились с содержимым, согласны (а иногда наоборот, не согласны) с ним. А электронная подпись еще и защищает наше содержимое от подмены.
Итак, мы читаем файл в память, хэшируем прочитанное. И что, уже получаем ЭЦП? Почти. Наш результат с большой натяжкой можно назвать подписью, но, все же, полноценной подписью он не является, потому что:
1. Мы не знаем, кто сделал данную подпись
2. Мы не знаем, когда была сделана подпись
3. Сама подпись не защищена от подмены никак.
4. Хэш функций много, какая из них использовалась для создания этого конкретного хэша?
Вы посылаете ваш файл другому человеку, допустим, по почте, будучи уверенными, что он точно получит и прочитает именно то, что вы послали. Он же, в свою очередь, тоже должен хэшировать ваши данные и сравнить свой результат с вашим. Если они совпали — все хорошо. Но это еще не означает что данные защищены.
Ведь хэшировать может кто угодно и когда угодно, и вы никогда не докажете, что он хэшировал не то, что вы послали. То есть, если данные будут перехвачены по дороге злоумышленником, или же тот, кому вы посылаете данные — не очень хороший человек, то данные могут быть спокойно подменены и прохэшированы. А ваш получатель (ну или вы, если получатель — тот самый нехороший человек) никогда не узнает, что он получил не то, что вы отправляли, или сам подменил информацию от вас для дальнейшего использования в своих нехороших целях.
Поэтому, место для использование чистой хэш функции — транспорт данных в пределах программы или программ, если они умеют общаться между собой. Собственно, с помощью хэш функций вычисляются контрольные суммы. И эти механизмы защищают от случайной подмены данных, но не защищают от специальной.
Но, пойдем дальше. Нам хочется защитить наш результат хеширования от подмены, чтобы каждый встречный не мог утверждать, что это у него правильный результат. Для этого самое очевидное что (помимо мер административного характера)? Правильно, зашифровать. А ведь с помощью шифрования же можно и удостоверить личность того, кто хэшировал данные! И сделать это сравнительно просто, ведь есть ассиметричное шифрование. Плюсы такого действия очевидны — для того, чтобы проверить нашу подпись, надо будет иметь наш открытый ключ, по которому личность зашифровавшего (а значит, и создавшего хэш) можно легко установить.
Суть этого шифрования в следующем: у вас есть закрытый ключ, который вы храните у себя. И есть открытый ключ. Открытый ключ вы можете всем показывать и раздавать, а закрытый — нет. Шифрование происходит с помощью закрытого ключа, а расшифровывание — с помощью открытого.
Приведем аналогию. У Вас есть отличный замок и два ключа к нему. Один ключ замок открывает (открытый), второй — закрывает (закрытый). Вы берете коробочку, кладете в нее какую-то вещь и закрываете ее своим замком. Так, как вы хотите, чтобы закрытую вашим замком коробочку открыл ее получатель, то вы открытый, открывающий замок, ключик спокойно отдаете ему. Но вы не хотите, чтобы вашим замком кто-то закрывал коробочку заново, ведь это ваш личный замок, и все знают, что он именно ваш. Поэтому закрывающий ключик вы всегда держите при себе, чтобы кто-нибудь не положил в вашу коробочку нечто иное и не говорил потом, что это вы это иное туда положили и закрыли своим замком.
И все бы хорошо, но тут сразу же возникает проблема, а, на самом деле, даже не одна.
1. Надо как-то передать наш открытый ключ, при этом его должна понять принимающая сторона.
2. Надо как-то связать этот открытый ключ с нами, чтобы нельзя было его присвоить.
3. Мало того, что ключ надо связать с нами, надо еще и понять, какой зашифрованный хэш каким ключом расшифровывать. А если хэш не один, а их, скажем, сто? Хранить отдельный реестр — очень тяжелая задача.
Все это приводит нас к тому, что и закрытый ключ, и наш хэш надо хранить в каких-то форматах, которые нужно стандартизировать, распространить как можно шире и уже тогда использовать, чтобы у отправителя и получателя не возникало «трудностей перевода».
Надо связать каждый открытый ключ с информацией о том, кому этот ключ принадлежит, и присылать это все одним пакетом. Тогда пакет (а если более правильно, контейнер) с открытым ключом можно будет просто посмотреть и сразу понять его принадлежность (определить владельца закрытого ключа).
Но эту информацию еще надо связать с подписью, пришедшей получателю. Как это сделать? Надо соорудить еще один контейнер, на сей раз для передачи подписи, и в нем продублировать информацию о том, кто эту подпись создавал.
Продолжая нашу аналогию с красивым замком (замок с двумя ключами, один – открывающий, другой - закрывающий), мы пишем на ключе «Этот ключ открывает замок В. Пупкина». А на замке тоже пишем «Замок В. Пупкина». Имея такую информацию, получатель нашей закрытой коробочки не будет каждый из имеющихся у него ключей вставлять наугад в наш замок, а возьмет наш ключ и сразу его откроет.
Теперь, по переданной информации при проверке можно найти контейнер открытого ключа, взять оттуда ключ, расшифровать хэш.
Но для расшифровки хэша необходимо знать, какая хэш-функция применялась для хэша! Решить ее можно достаточно просто: положить эту информацию в контейнер вместе с нашим открытым ключом. Ведь именно связка «хэширование – шифрование результата хеширования» считается процедурой создания цифровой подписи, а ее результат – подписью. А значит, достаточно логичным представляется объединение в связку алгоритма шифрования хэша и хэш-функции, с помощью которой он сформирован. И доставлять эту информацию тоже надо в связке.
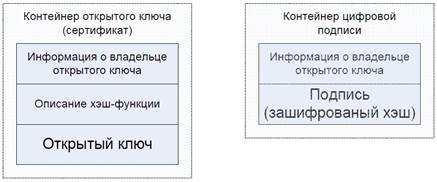
Рис. 13.4. Содержимое сертификата и контейнера цифровой подписи
Теперь, ненадолго вернемся к информации о подписывающем. Какого рода эта информация должна быть? Ее должно быть столько, чтобы совпадение всех параметров, по которым мы идентифицируем человека, было максимально невероятным.
Безусловно, такой пакет информации создать возможно. Вот только, работать с ним уже трудновато. Ведь наши контейнеры открытых ключей надо сортировать, хранить, использовать, в конце концов. А если для каждого использования придется указывать по полсотни параметров, то уже на втором контейнере станет понятно, что что-то надо менять. Решение этой проблемы, конечно же, было найдено.
Чтобы понять, в чем же оно заключалось, обратимся к бумажному документу, который есть у всех нас: к паспорту. В нем можно найти и ФИО, и дату рождения, и пол, и много другой информации. Но, главное, в нем можно найти серию и номер. И именно серия и номер являются той уникальной информацией, которую удобно учитывать и сортировать. Кроме того, они существенно короче всей оставшейся информации вместе взятой, и при этом все так же позволяют опознать человека.
Применяя этот же подход к контейнерам открытых ключей, мы получим, что у каждого контейнера должен быть некий номер, последовательность символов, уникальная для него. Эту последовательность символов принято называть идентификатором, а сами контейнеры – сертификатами, либо просто ключами.
Как мы видим, функции подписи, определенные в начале, выполняются. Но тут возникает следующий вопрос, кто гарантирует, что открытый ключ не был подменен при распространении (для тех, кто понимает, атака Man In The Middle) и мы общаемся с тем кем хотим, а не со злоумышленником, выдающим себя за другого? Ответ напрашивается сам – нам нужен некий авторитет, гарантирующий принадлежность ключей, и механизм их распространения. Данное решение было реализовано в виде инфраструктуры открытых ключей и сертификатов удостоверяющих центров. Тогда с сообщением передается не только подпись, но и сертификат, удостоверяющий её.
Центр сертификации – это место, в которое надо идти за получением ЭП. Процедура получения связана с генерацией заявок и бумажной волокитой. Также необходимо определить права, которые вам нужны в системе.
Инфраструктура открытых ключей (PKI) Инфраструктура открытых ключей призвана обеспечить доверительные отношения между участниками взаимодействия. Участниками и основными элементами PKI являются удостоверяющие центры (УЦ) и конечные пользователи. Никто из конечных пользователей не доверяет друг другу, но каждый из них доверяет УЦ. Каждый пользователь имеет закрытый ключ, который он хранит в секрете, и открытый, который заверяется УЦ с помощью сертификата.
Сертификат представляет собой файл, содержащий открытый ключ пользователя, информацию о нем и подпись УЦ. Схема взаимодействия пользователей выглядит следующим образом:
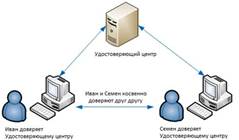
При этом Иван получает сертификат открытого ключа Семена, заверенный УЦ, а Семен – Ивана. Без этого их доверительное взаимодействие невозможно. Для обеспечения взаимного доверия между пользователями разных УЦ последние объединяются в иерархическую структуру:
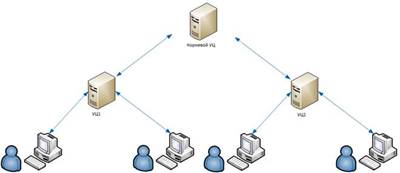
Кроме того, УЦ1 и УЦ2 могут организовать взаимное доверие и обойтись без корневого УЦ.
Кроме сертификатов открытых ключей пользователей УЦ может выпускать списки отзыва тех сертификатов, которые удостоверяют скомпрометированные по тем или иным причинам ключи. Этим самым обеспечивается оперативное реагирование на события, влияющие на надежность и безопасность обмена данными.
Открытые ключи и другая информация о пользователях хранится центрами сертификации в виде цифровых сертификатов, имеющих следующую структуру:
¾ серийный номер сертификата;
¾ объектный идентификатор алгоритма электронной подписи;
¾ имя удостоверяющего центра;
¾ срок действия сертификата;
¾ имя владельца сертификата (имя пользователя, которому принадлежит сертификат);
¾ открытые ключи владельца сертификата (ключей может быть несколько);
¾ объектные идентификаторы алгоритмов, ассоциированных с открытыми ключами владельца сертификата;
¾ электронная подпись, сгенерированная с использованием секретного ключа удостоверяющего центра (подписывается результат хэширования всей информации, хранящейся в сертификате).
Понятие «Проверка подписи» подразумевает проверку соответствия подписи документу, который подписан этой подписью. Если подпись соответствует документу, документ считается подлинным и корректным.
Для проверки подписи используется открытый ключ подписи автора подписи. Но для того, чтобы результат проверки можно было считать надежным, необходимо удостовериться, что сам открытый ключ подписи автора подписи, имеющийся у проверяющего, корректен. Для этого проводится проверка сертификата на этот ключ. Понятие «Проверка сертификата» означает проверку подписи под этим сертификатом. Подпись под сертификатом проверяется на открытом ключе того, кто создал и подписал сертификат — т.е. на открытом ключе удостоверяющего центра. Т.е. для того, чтобы результат проверки подписи под документом можно было считать надежным, кроме собственно проверки подписи и проверки сертификата на ключ подписи необходимо удостовериться также и в корректности сертификата удостоверяющего центра.
Таким образом, в процессе проверки подписи возникает цепочка сертификатов, каждый из которых проверяется на следующем. Такая цепочка сертификатов называется цепочкой доверия.
То же самое происходит и при зашифровании: прежде чем зашифровать сообщение для владельца открытого ключа обмена, необходимо удостовериться, что данный открытый ключ обмена корректен и подлинен. Для этого необходимо проверить подпись под сертификатом на этот ключ, и возникает точно такая же цепочка доверия.
В каждой цепочке доверия рано или поздно встречается сертификат, на котором цепочка заканчивается. Т.е. для этого сертификата нет сертификата, на котором его можно было бы проверить. Такие сертификаты называются корневыми. Очевидно, что корневым сертификатом в цепочке доверия всегда является сертификат удостоверяющего центра (хотя необязательно каждый сертификат удостоверяющего центра будет корневым - могут, например, существовать сертификаты удостоверяющего центра, подписанные на корневом и т.д.). Проверить такой сертификат электронными средствами невозможно. Для проверки этих сертификатов используются бумажные распечатки, содержащие определенную информацию: как правило, так называемые цифровые отпечатки, либо сами открытые ключи. Какая именно информация используется для проверки, зависит от регламента удостоверяющего центра.
Цифровой отпечаток документа - это последовательность символов, соответствующая документу таким образом, что каждому документу соответствует свой отпечаток, и по изменению документа нельзя определить, как изменится цифровой отпечаток. Таким образом, можно быть уверенными, что если цифровой отпечаток документа соответствует документу, документ подлинный и корректный. (Эта идея заложена также в основе формирования ЭП).
Для проверки корневого сертификата удостоверяющего центра необходимо получить в удостоверяющем центре бумажную распечатку, содержащую цифровой отпечаток этого сертификата либо открытый ключ, и заверенную подписью администратора удостоверяющего центра и печатью удостоверяющего центра, и сравнить информацию из распечатки с соответствующей информацией, содержащейся в сертификате (увидеть эту информацию можно при просмотре и при установке сертификата). Если цифровой отпечаток или открытый ключ в распечатке и в сертификате совпадает, корневой сертификат считается корректным. Если цифровой отпечаток или открытый ключ в распечатке и в сертификате не совпадают, значит, файл корневого сертификата искажен. О факте искажения файла сертификата следует немедленно сообщить в удостоверяющий центр—это может означать компрометацию ключей удостоверяющего центра.
Пример настройки рабочего места пользователя в государственной структуре в управлении муниципального заказа для участия в электронных торгах на портале zakupki.gov.ru
1. Устанавливаем криптопровайдер. Запускаем инсталлятор Крипто-про CSP, настраиваем считыватели (т.е. если у вас закрытый ключ будет на дискете, тогда считывателем будет флэш-карта), вводим лицензию, и следуем указанием программы установки.
2. Качаем и устанавливаем объект Capicom версии 2.1.0.2. Он необходим для корректной работы с площадками.
3. Если необходимо, ставим драйвера для корректной работы носителей (Токенов, смарт-карт). Их можно найти на официальных сайтах.
4. Устанавливаем корневые сертификаты. Помещаем их в хранилище корневых центров сертификации.
5. Создаем связку ключей через Крипто-про CSP. Делается это достаточно просто. Запускаем Крипто-про CSP, выбираем “Cервис -> установить личный сертификат”. Указываем открытый ключ, указываем носитель закрытого ключа, вводим пин-код, помещаем сертификат в личное хранилище.
Осталось еще проделать некоторые манипуляции с браузером. Браузер, кстати, для работы с торговыми площадками — только Internet Explorer.
¾ Во-первых, заносим электронную площадку в безопасные узлы.
¾ Во-вторых, для безопасных узлов разрешаем использование всех ActiveX компонентов.
¾ В-третьих, разрешайте все выплывающие окна на площадках.
Класс Activity
Activity – основной класс для взаимодействия с пользователем. Activity разработаны, чтобы обеспечить визуальный интерфейс, через который пользователь может взаимодействовать с приложением. И условно Activity должны быть модулями приложения в том смысле, что каждая Activity, как отдельный модуль, должна поддерживать в фокусе единственную вещь, которую пользователь может сделать с вашим приложением, например просмотр электронного письма или показ экрана входа в систему.
Когда пользователь выполняет свою задачу, он перемещается по цепочке из Аctivity, и Android помогает пользователям в навигации несколькими способами, поддерживая концепцию приложения, обеспечивая временное хранение Activity в стеке (backstack), так что они должным образом могут быть приостановлены и затем возобновлены при возврате из стека.
Таким образом задача (Task) в Android – это ряд связанных Activity. Эти связанные Activity могут, но не должны быть частью одного приложения. Одна задача (Task) может охватить несколько приложений.
Большинство задач запускается с домашнего экрана. Таким образом, когда пользователь запускает приложение с домашнего экрана, обычно запускается новая задача (Task). И когда пользователь нажимает кнопку «Домой», чтобы возвратиться назад к домашнему экрану, текущая задача, по крайней мере временно, приостанавливается.
Стек задачи (Task backstack) работает следующим образом. Когда Activity запущена, она заносится в верхнюю ячейку стека как часть текущей задачи. А когда эта Activity позже будет уничтожена, например, потому что пользователь нажал кнопку «Назад», или потому что Activity сама завершила свою работу программно, или даже потому что сам Android решил уничтожить эту Activity, чтобы освободить занимаемые ей ресурсы, тогда Activity удаляется из верхней ячейки стека задач.
Если же вместо уничтожения Activity будет запущена вторая Activity, то первая Activity продвинется вглубь стека, а ее место в верхней ячейке стека займет вторая Activity. Тогда после окончания работы второй Activity по кнопке «Назад» она будет уничтожена и удалена из стека, а в верхнюю ячейку стека и, соответственно на экран пользователя, вновь вернется первая Activity.

Activity имеют жизненный цикл. И что важно для вас как для разработчика, приложения не контролируют свой жизненный цикл. Некоторые изменения жизненного цикла зависят от выбора, который делает пользователь, например нажатие кнопки «Назад» или кнопки «Домой». Другие изменения жизненного цикла зависят от самого Android. Например, если ваше устройство испытывает нехватку памяти, Android может уничтожить activity, которые в настоящее время приостановлены.
Как только Activity запущена, она может быть в состоянии resumed (возобновленном) или running (выполнения). И в то время как она находится в этом состоянии, Activity видима (на экране) и пользователь может взаимодействовать с ней.
Activity может также быть paused (приостановлена). Например, когда новая Activity начинает раскрываться перед ней. В этой ситуации Activity может все еще быть частично видима, но пользователь не может взаимодействовать с ней, потому что он будет взаимодействовать с новой Activity, которая только что запущена (до версии 3.0 Android мог завершить Activity, как только они вошли в приостановленное состояние).
И, наконец, Activity может быть stopped (остановлена). И когда она остановлена, эта Activity больше не видима, и Android может ее уничтожить. Уничтоженная Activity может быть воссоздана позже, если пользователь перемещается к ней по задаче.
Ваши Activity будут часто вести себя по‑разному во время различных частей их жизненного цикла. Например, если Activity показывает анимацию, но в это время раскрывается частично прозрачное Activity диалога перед ней, то вы захотите приостановить анимацию, пока пользователь отвечает на диалог, а затем перезапустить анимацию, как только Activity диалога закроется.

Чтобы поддерживать сценарии как этот, Android сообщает об изменениях жизненного цикла в Activity, вызывая предопределенные методы (call back) жизненного цикла. И вот некоторые из этих методов:
onCreate, вызывается перед тем как Activity будет создано;
onStart, вызывается перед тем как Activity станет видимым;
onDestroy, вызывается перед тем как Activity будет уничтожена.
И, если вы хотите выполнить некоторые действия, когда ваша Activity изменяет состояние, то вы должны переопределить (override) эти методы в вашей Activity.
Давайте рассмотрим как эти различные методы взаимосвязаны друг с другом. Эта диаграмма изображает последовательность, в которой могут быть вызваны методы жизненного цикла Activity. И важно помнить, что приложения Android не работают полностью сами по себе. Вместо этого есть четко определенное направление взаимодействия между вашим приложением и Android. И вы должны понять правила этого взаимодействия, если хотите, чтобы ваши приложения функционировали должным образом.
Давайте представим простое приложение с одной Activity. Оно запускается, ожидает мгновение, и затем закрывается. В этом простом случае как только приложение будет запущено, Android вызовет (call back) метод onCreate.
Затем Android вызовет свой метод onStart, и затем onResume, после которого пользовательский интерфейс Activity появится на экране устройства, и пользователь сможет взаимодействовать с ним.
Приблизительно после одной минуты наша Activity начнет закрываться. И в этот момент Android вызовет метод onPause. Затем onStop. И, наконец, onDestroy. Теперь Activity абсолютно уничтожена.
Итак, как видите, все время жизни Activity заключено между onCreate при запуске и onDestroy в конце.
Когда эта простая Activity запускалась, сперва она не была видима на экране. В некоторый момент она стала видимой, позже она стала невидимой и затем была удалена с экрана.


Когда Activity становятся видимыми, Android иногда вызывает метод onStart, а иногда – onRestart. Перед тем, как Activity станут невидимыми, Android вызывает метод onStop. Таким образом, время жизни Activity в видимом состоянии длится между запуском вызовов onStart и onStop. И, наконец, в то время как Activity видима на экране, есть отрезки времени, когда пользователь может взаимодействовать с ней, и есть моменты когда не может. Например, это может произойти, когда устройство «засыпает». В этом случае пользователь не может взаимодействовать с Activity даже при том, что эта Activity все еще запущена.
Когда Activity оказывается готова к взаимодействию с пользователем, Android вызывает метод onResume. Когда Activity собирается прекратить взаимодействие с пользователем, Android вызывает метод onPause.
Таким образом время жизни Activity, когда она видима и способна взаимодействовать с пользователем, длится между запуском вызовов onResume и onPause.
Теперь давайте более глубоко рассмотрим эти методы жизненного цикла. Первый метод – onCreate вызывается, когда Activity создается. Обычно onCreate используется, чтобы инициализировать Activity и выполнить следующие четыре функции:
вызов super.onCreate, который сделает часть собственной инициализации Android;
установка content view Activity, которая сообщит Android, каким должен быть пользовательский интерфейс Activity;
получение и сохранение всех необходимых ссылок и соответствий между различными элементами (view) лейаута пользовательского интерфейса и кодом Activity;
конфигурирование элементов пользовательского интерфейса и view.
Давайте рассмотрим метод onCreate приложения «MapLocation». @Override – переопределяет activity.onCreate. В методе onCreate вы видите четыре функции, о которых мы говорили.
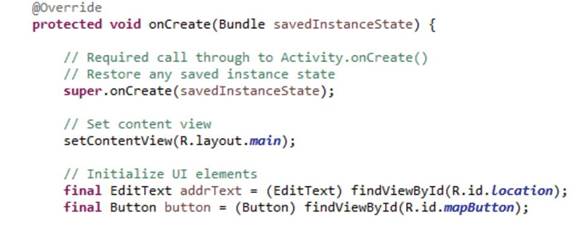
Во-первых, есть вызов super.onCreate. Затем есть вызов setContentView c ID файла лейаута R.layout.main в качестве параметра. После этого Activity сохраняет ссылки на view редактирования текста и на кнопку, которые появляются в пользовательском интерфейсе. И, наконец, onCreate присоединяет «слушателя» кнопки button.setOnClickListener. Android вызывает этот код «слушателя» каждый раз, когда пользователь нажимает на кнопку.
оnRestart – следующий метод жизненного цикла. Он вызывается, если Activity, которая была остановлена, будет запущена снова. И вы можете использовать onRestart, чтобы выполнить некоторые действия, которые необходимы, перед тем, как Activity будет запущена снова.
onStart вызывается перед тем, как Activity станет видимой. Некоторые типичные применения для этого метода – это запрос обновлений датчика положения или загрузка или сброс персистентного состояния приложения.
onResume вызывается перед тем, как Activity начнёт взаимодействовать с пользователем, и уже видима. Действия, которые вы совершаете в этом методе, должны быть запущены на переднем плане приложения. Например, стартовые анимации или воспроизведение фоновой звуковой дорожки.
onPause вызывается пред тем, как Activity потеряет фокус. В этом методе вы можете завершить действия, совершающиеся на переднем плане, например, уничтожить анимации. Кроме этого вы должны сохранить любые изменения, которые совершил пользователь только что.
onStop вызывается, когда Activity больше не видима пользователю. В этой точке предполагается, что Activity может быть опять запущена позже. Так, некоторые типичные действия, которые надо сделать здесь – это кэширование состояния Activity, которое вы захотите восстановить, когда Activity позже перезапустится по вызову onStart. И помните: onStop не всегда вызывается, когда Activity завершается. Например, его нельзя вызвать, если Android уничтожает процесс приложения из‑за нехватки памяти. Поэтому вместо сохранения персистентных данных в этом методе, лучше сделайте это в onPause.
onDestroy вызывается перед тем, как Activity будет уничтожена. Некоторые типичные действия, которые надо сделать в этом методе – высвободить ресурсы, занимаемых этой Activity. Например, закрыть частные потоки, которые были запущены этой Activity. И снова помните, что onDestroy не будет вызван, например, если Android уничтожит приложение из-за нехватки памяти на устройстве.
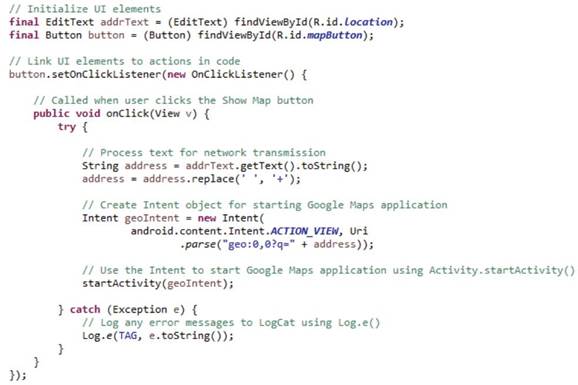
Теперь, когда мы увидели жизненный цикл Activity в действии, давайте рассмотрим как одна Activity может программно запускать другую Activity. Чтобы запустить Activity программно, вы сначала создаете объект Intent (намерение), который определяет Activity, которую вы хотите запустить. И затем вы передаете этот созданный Intent тем методам, которые запускают Activity – startActivity или startActivityForResult. startActivity запустит желаемую Activity, скрывая текущую Activity с переднего плана. startActivityForResult, тоже запустит желаемую Activity, но сделает это с ожиданием того, что запущенная Activity вернет результат для вызывающей Activity.
Давайте рассмотрим как приложение «Map Location» запускает Activity «Google Maps». Каждый раз, когда пользователь кликает кнопкой, вызывается метод onClick. В строковую переменную address помещается географический адрес, считанный из текстового поля addrText. Далее создается Intent geoIntent, содержащий в себе заданный географический адрес, который затем и передается методу startActivity для запуска приложения «Карты» с географической картой, центрированной на указанном адресе.
Но вместо того, чтобы запросить у пользователя ввод адреса через клавиатуру, мы можем позволить ему выбрать контакт из приложения «Контакты» и использовать адресные данные этого контакта как географический адрес, который открыть на карте. Для этого рассмотрим приложение «Map location from contacts».

Отличие от «Map Location» находится в коде OnClickListener, в частности, этот код создает несколько иной Intent, а затем передает его в качестве параметра методу StartActivityForResult. Вторым параметром является requestCode (код запроса), который пригодится позже, когда результат вернется обратно в запускающую Activity.
Как только новая Activity запущена, она ответственна за результат, который должен быть возвращен назад вызывающей Activity. Это делается вызовом Activity.SetResult, передавая в нем код результата (resultCode). Эти коды результата включают некоторые встроенные коды, такие как Result_Canceled (отмененный результат), который указывает, что пользователь принял решение не завершать действие, а отменил его, например, нажав кнопку "Назад", и Result_OK, указывающий, что Activity фактически завершена штатно. Разработчики могут также добавить пользовательские коды результата после встроенного кода результата (Result_First_User).
Перед тем, как Activity завершится, она должна выдать свой результат, вызвав SetResult, и этот результат будет в конечном счете передан назад в вызвавшую Activity и использован в методе onActivityResult.

Как вы видите, его параметры включают начальный код запроса (requestCode), который был передан в StartActivityForResult, код результата (resultCode), используемый запущенной Activity, когда она вызвала SetResult, и Intent, если он был передан в SetResult. onActivityResult обычно начинается c проверки кода результата и кода запроса, чтобы определить, что сделать с полученным результатом.
Следующим шагом необходимо получить данные контакта и проанализировать их, чтобы извлечь почтовый адрес контакта. Как только почтовый адрес был извлечен, «Map location from contacts» обрабатывает данные так, чтобы они были в формате, который ожидают карты Google (строковая переменная formattedAddress), помещает эти данные в Intent и затем вызывает startActivity, передавая ей этот Intent.

Далее рассмотрим обработку изменения конфигурации. Конфигурация устройства относится к характеристикам устройства и приложения, связанным с ресурсами приложения, такими как: используемые языки, размер экрана, доступность клавиатуры и ориентация экрана устройства. Эти характеристики могут измениться во время выполнения приложения и, когда это происходит, Android уничтожает текущую Activity и затем перезапускает ее с ресурсами, соответствующими измененной конфигурации.
Предположим, например, что изменяется ориентация устройства. Если вы поворачиваете устройство из портретного режима в альбомный и назад в портретный, это заставит систему уничтожить текущую Activity и перезапустить ее дважды. Чтобы оптимизировать скорость изменения конфигурации, Android позволяет вам сделать две вещи. Первое, когда происходит изменение конфигурации, вы можете создать и сохранить произвольный объект Java, тем самым сохранив в кэше важную информацию о состоянии. И второе, вы можете вручную обработать изменение конфигурации, избежав завершения и перезапуска Activity в целом.
Итак, чтобы ускорить реконфигурирование, вы можете сохранить данные в объекте Java. И один способ сделать это – переопределить метод onRetainNonConfigurationInstance и вызвать его между onStop и onDestroy. Объект, который вы создаете и возвращаете в onRetainNonConfigurationInstance, может быть получен путём вызова экземпляра getLastNonConfigurationInstance, когда Activity воссоздана. Это обычно делается во время вызова onCreate, когда вы воссоздаете Activity.
И вторая вещь, которую вы можете сделать, чтобы ускорить реконфигурирование, это избежать уничтожения и перезапуска Activity для определенных изменений конфигурации. Чтобы сделать это, вы объявляете в файле androidmanifest.xml те определенные изменения, которые ваша Activity обработает. Например, этот отрывок xml‑файла указывает, что MyActivity вручную обработает изменения в ориентации устройства, размере экрана и доступности клавиатуры.
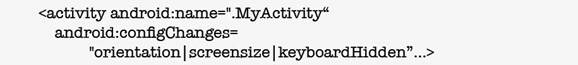
Если вы обрабатываете изменения конфигурации вручную, тогда, как только произойдут изменения конфигурации во время работы приложения, ваша Activity примет вызов onConfigurationChanged, и в качестве параметра этот метод получит объект конфигурации, который детализирует новую конфигурацию. Затем ваш код сможет считать этот объект и внести любые изменения, если необходимо.
Класс Intent
Класс Intent (намерение) – структура данных, которая служит двум целям. Первая – это определить операцию, которую вы хотите выполнить, и вторая – это представить событие, произошедшее в системе, о котором вы хотите уведомить другие компоненты. Мы поговорим о второй из них позже, когда будем рассматривать Broadcast receivers.
Вы можете представить себе Intent как предоставление своего рода языка для определения операций, которые вы хотите выполнить (ваше намерение). В сущности Intent даёт вам простой способ сказать такие вещи как: «я хочу выбрать контакт», «я хочу сделать фотографию», «я хочу набрать телефонный номер» или «я хочу вывести на экран карту». Intent обычно создаётся одной Activity, которой необходимо, чтобы некоторая операция была выполнена, и затем Android использует этот Intent чтобы запустить другую Activity, которая может выполнить желаемую работу.
Теперь о видах информации, которая может быть определена в Intent. Например: action (действие), data (данные), category (категория) и прочие. Action – строковая последовательность, которая представляет или называет операцию, которая будет выполнена. Например, action_dial означает, что я хочу набрать телефонный номер. Action_edit – я хочу вывести на экран некоторые данные для пользователя, чтобы отредактировать. Action_sync – синхронизировать некоторые данные на устройстве с данными на сервере. Action_main – запустить Activity как начальную Activity приложения.
Вы можете установить Action несколькими способами. Например, вы можете передать Action‑строку в качестве параметра конструктору Intent. Как альтернатива, вы можете создать пустой Intent и затем вызвать метод setAction в нем, передав Action‑строку в качестве параметра.

У Intent также есть поле данных (data), которое представляет данные, связанные с намерением. Эти данные отформатированы как Универсальный идентификатор ресурса или URI. Один пример данных Intent – geo URI, который означает данные географической карты.

Другой пример – URI, указывающий телефонный номер, который вы хотите набрать. Обратите внимание на то, что последовательности, которые представляют базовые данные, сначала передаются методу uri.parse, который получает эти последовательности и затем возвращает объект URI.

Вы можете установить данные Intent различными способами. Например, вы можете передать его непосредственно конструктору Intent, или вы можете создать пустой Intent и затем использовать метод setData, чтобы установить данные для этого Intent.
Категория (category) представляет дополнительную информацию о видах компонентов, которые может или должен обработать этот Intent. Некоторые примеры: category_browsable означает, что Activity может быть вызвана браузером через ссылку URI. Другой пример – category_launcher означает, что целевая Activity может быть начальной Activity задачи (task) и описана в средстве запуска приложения верхнего уровня.
У Intent также есть поле Type (тип), которое определяет MIME‑тип данных. Некоторые примеры MIME‑типов включают различные форматы изображений, такие как png или jpg. Есть также различные текстовые форматы, такие как HTML или txt. Если вы не определите MIME‑тип, Android попытается указать его для вас. Вы можете установить MIME‑тип при помощи метода setType, передав его в строковой последовательности, которая представляет желаемый MIME‑тип. Вы можете также установить и данные, и тип вместе, вызвав метод setDataAndType.

Поле Component идентифицирует целевую Activity. Вы можете установить это поле, если знаете точно ту Activity, которая должна всегда получать этот Intent. Вы можете установить Component, используя один из конструкторов Intent, передав его в объекте контекста и объекте класса, который представляет Activity, которая должна выполнить желаемую операцию.

Вы можете также создать пустой Intent и затем использовать один из методов setComponent(), setClass() или setClassName(), чтобы установить целевую Activity.

Поле Extras. Extras хранят дополнительную информацию, связанную с Intent. Extras – это набор пар ключ‑значение. Таким образом, целевая Activity должна знать и имя, и тип любых дополнительных данных (extras), которые она намеревается использовать. Например, класс Intent определяет дополнительные данные (extras) EXTRA_EMAIL, которые используются, чтобы передать список получателей при отправке электронного письма.


Как здесь видно, этот код создает Intent с действием (action) ACTION_SEND. Таким образом, мы хотим послать некоторое электронное письмо. А также добавляет Extras к этому Intent (EXTRA_EMAIL).
Есть несколько различных методов для установки Extras, и форма этих методов будет зависеть от типа данных, которые вы хотите там хранить. Так, например, есть один метод для хранения строковой последовательности, ещё один метод – для хранения массива чисел, и т.д.

Поле флагов (flags). Флаги представляют информацию о том, как Intent должен быть обработан. Некоторые встроенные примеры включают flag_activity_no_history. Что означает, что, когда Activity запущено на основе этого Intent, оно не должно быть помещено в стек.

Другой флаг – FLAG_DEBUG_LOG_RESOLUTION, который говорит Android распечатывать дополнительную информацию о журналировании (log), когда этот Intent обрабатывается, и это – важный инструмент, чтобы его использовать, если ваш Intent не запускает ту Activity, которую вы хотите.
Давайте поговорим о том, как использовать Intent, чтобы запустить Activity. Когда вы используете один из методов startActivity или startActivityForResult, Android должен выяснить, какую конкретно Activity он собирается запустить. И есть два пути, которыми Android это делает.
Первый путь состоит в том, что, если вы явно указали целевую Activity, когда создали Intent (explicit intent), то Android может просто найти и запустить эту определенную Activity.
Второй путь используется, только тогда, когда вы явно не указали целевую Activity, и состоит в том, что Android может неявно определить ее на основе Intent (implicit intent), который использовался, и на основе свойств Activity (или приложений), которые установлены на устройстве.
Давайте рассмотрим приложение, которое явно запускает другую Activity. Это приложение называется «Hello World With Login». Оно состоит из двух Activity. Одна Activity называется LoginActivity, а другая – HelloAndroid. Когда это приложение запущено, первым запускается LoginActivity, оно предоставляет текстовое поле для ввода имени пользователя и поле для ввода пароля. Есть также кнопка Login, которую пользователь нажимает после того как введет имя пользователя и пароль. И затем LoginActivity проверяет введенные данные – пароль и имя пользователя, и если примет их, запустит Activity HelloAndroid, которая выведет на экран слова “HelloAndroid”.
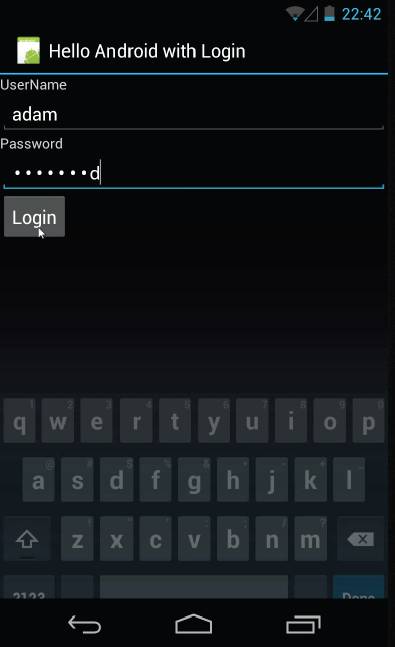
Давайте рассмотрим код, чтобы увидеть как это реализовано. Это класс LoginActivity. Здесь реализован onClickListener («слушатель» кнопки), он присоединен к кнопке Login. Код захватывает имя пользователя и пароль, которое пользователь только что ввел, и затем передает их методу checkPassword. Если checkPassword возвратит true, то код будет выполняться дальше.

Сначала создается Intent (helloAndroidIntent). Вызов конструкторa получает два параметра – контекст и объект класса Activity, которая будет запущена. В этом случае LoginScreen.this используется в качестве контекста.
Контекст (Context) – это интерфейс, который предоставляет доступ к базовым функциям приложения. Так как Activity – это подкласс контекста, то можно использовать .this для этого параметра. Второй параметр – объект класса, в этом случае – HelloAndroid.class. Этот параметр указывает Activity, которая будет запущена вызовом startActivity.
Второй способ запустить Activity – неявная активация. В этой ситуации вы не сообщаете Android, какую Activity запустить, система должна решить это самостоятельно. Android пытается найти соответствие между Intent, который был передан в startActivity или startActivityForResult с возможностями других Activity (или приложений), которые находятся на устройстве. И этот процесс называют intent resolution.
Intent resolution полагается на два вида информации. Во‑первых, Activity создает Intent, описывающий действие, которое должно быть выполнено. Во‑вторых, у некоторых Activity в Android определены Intent‑фильтры (IntentFilters), определяющие виды операций, которые они могут обработать. Эта информация обычно помещается в файл androidmanifest.xml или в приложения, которым эти Activity принадлежат.
Во время выполнения, когда вызван метод startActivity, Android попытается найти соответствие между Intent и известными Intent‑фильтрами. Но он будет использовать только часть информации, содержащейся в Intent. В частности он будет смотреть на поле Action (действие), на Data (данные), включая URI и mime‑тип и на Категорию (Category).
Рассмотрим то, как приложения определяют Intent‑фильтры в своих файлах androidmanifest.xml. Вот отрывок xml, показывающий тег Activity, этот тег содержит в себе тег Intent‑фильтра c соответствующим действием, которое он поддерживает. Например, если Activity может набирать номер телефона, то она должна содержать Intent‑фильтр со стандартным intent.action.dial.

Если ваша Activity обрабатывает определенный тип данных, она может добавить эту информацию к ее Intent‑фильтру, например, Activity может определить mime‑тип данных, которые она обрабатывает. Вы можете также определить схему, хост или номер порта данных UI, которые она обрабатывает. В дальнейшем можно будет ограничить формат данных URI, определив путь, шаблон или префикс пути.
Если Activity хочет объявить, что она может, например, показывать карты, тогда она могла бы содержать Intent‑фильтр, который говорит Android, что она может обработать данные URI со схемой geo.
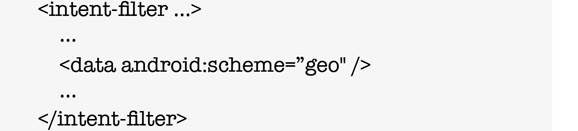
Точно так же Activity могут определить категории для Intent, которые они обрабатывают.
Теперь мы можем предположить или представить на основе тех приложений «Map location», которые мы видели прежде, что «Google Maps» может обработать Intent, которые содержат action_view и которые содержат поле данных со схемой geo. Файл androidmanifest.xml для приложения карт Google выглядит примерно следующим образом. Имеется Activity с Intent‑фильтром. И этот фильтр перечислен в Action intent.action.view. И у него есть данные со схемой geo. Фактически это то, что приложение «Map location» передали в стартовую Activity Google‑карт.

Activity также перечисляет две категории. Одна – category.browsable означает, что Activity может реагировать на ссылки браузера. Другая – cateogry.default. Оказывается, что в большинстве случаев Activity, которые хотят принимать implicit intents, должны включать category.defualt в свои Intent‑фильтры.
Наконец, когда больше чем одна Activity может принять определенный Intent, Android должен будет приостановить исполнение для принятия решения. Один вариант – спросить пользователя, какую Activity (или приложение) он хочет использовать. И второй вариант – это использовать возможность того, что Activity могут определить приоритет, который Android примет во внимание при выборе между двумя различными Activity, которые могут обработать данный Intent. Значения приоритета должны быть между минус 1000 и плюс 1000, более высокие значения имеют более высокий приоритет.
Permissions
Android использует Permissions (полномочия, разрешения), чтобы защитить ресурсы, данные и операции. Приложения могут определять и устанавливать свои собственные полномочия, чтобы ограничить доступ к их ресурсам и информации о пользователе. Например, чтобы ограничить, кто может получить доступ к базе данных приложения, платным услугам, ограничить какие компоненты могут вызвать дорогостоящие операции, такие как исходящие сообщения SMS или MMS, ограничить доступ к системным ресурсам, например, чтобы определить какие компоненты могут использовать камеру устройства для съемки фото или записи видео.
В Android полномочия (Permissions) представлены как строковые последовательности. Приложения включают эти строки в файл androidmanifest.xml. Они могут сделать это, чтобы объявить полномочия, которые они используют сами, и полномочия, которые они требуют от других компонентов, которые хотят использовать их.
Сначала, если приложение должно использовать разрешение (permission), оно объявляет это разрешение тегом uses‑permission в его файле androidmanifest.xml. И когда это приложение будет устанавливаться на устройство, пользователь должен будет согласиться с этим разрешением, иначе произойдут ошибки или отказы доступа.
Рассмотрим кусок файла androidmanifest.xml для гипотетического приложения.

Как видите, для этого приложения нужны полномочия получить доступ к камере устройства, доступ к Интернету и доступ к информации о точном местоположении с приемника GPS.
Вспомним приложение «Map location from contacts». Это приложение позволяет пользователю выбирать контакт из телефонной книги (приложение Contacts) и затем отображать карту, центрируемую на почтовом адресе этого контакта. Если запустить это приложение, я увижу кнопку, которая позволит мне выбрать контакт. Когда я щелкаю по этой кнопке, приложение контактов показывает мне мои контакты и позволяет мне выбрать один из них. Как только я сделаю это, почтовый адрес и другая информация о контакте передается в «Google Maps», которая выводит на экран карту, центрируемую на почтовом адресе выбранного контакта.
Но мой список контактов – частная информация. Android не позволяет любому приложению на моем устройстве просто иметь доступ к списку контактов. Так как «Map location from contacts» получает доступ к нему? Приложение, должно быть, объявило, что использует надлежащее разрешение (permission). И мы можем увидеть подтверждение этому в файле androidmanifest.xml.

В дополнение к объявленным разрешениям, приложения Android могут также определить и установить свои собственные полномочия (permissions).
Предположим, вы написали приложение, которое выполняет некоторую привилегированную или опасную операцию, и вы бы не хотели, чтобы любое приложение имело возможность выполнить эти операции, просто вызвав ваше приложение. Поэтому Android позволяет нам определить и объявить свое собственное специализированное разрешение (permission). И тогда другие приложения должны будут получить ваше разрешение, иначе Android не позволит им использовать ваше приложение.
Рассмотрим это более подробно с простым примером. Представим простое приложение под названием «Бум!» Притворимся, что оно выполняет некоторое опасное действие, которое в реальной жизни могло бы быть, например, операцией форматирования карты памяти. Мы не хотим, чтобы любой был в состоянии просто запустить это приложение. Итак, мы собираемся определить и осуществить наше собственное специализированное разрешение (permission).
Давайте откроем файл androidmanifest.xml, чтобы видеть, как это реализуется. Вы видите тег permission, который определяет новое разрешение – course.examples.permissionexample.boom_perm.

В этом примере тег permission включает два других атрибута: label (метка) и description (описание), которое может быть показано пользователю, когда он устанавливает приложение. Значения для этих строковых последовательностей находятся в файле strings.xml. Далее немного ниже вы видите, что приложение также включает это разрешение как атрибут тега application. Благодаря этому Android удостоверится, что компонентам, которые пытаются запустить это приложение, уже предоставлено разрешение boom_perm. Так как приложение «Бум!» теперь требует наличие разрешения boom_perm, то любое другое приложение должно будет сначала получить это разрешение, если захочет использовать его.
Android также позволяет вам устанавливать полномочия для отдельных компонентов (component permissions). Эти параметры будут иметь приоритет над любыми уровнями разрешений приложения. Давайте рассмотрим некоторые из этих полномочий компонентов.
Activity permissions (полномочия Activity) ограничивают, какие компоненты могут запустить связанную Activity. Эти полномочия проверяются в процессе выполнения методов, таких как startActivity и startActivityForResult, которые вызываются, когда одна Activity пытается запустить другую. И, если требуемое разрешение будет отсутствовать, Android выдаст ошибку безопасности (security exception).
Service permissions (полномочия сервисов или служб) ограничивают, какие компоненты могут запустить связанный Service. Эти полномочия проверяются, когда выполнены запросы на запуск, остановку или подключение к службам, используя такие методы как Context.startService(), Context.stopService() или Context.bindService(). Так же, как и в случае с Activity, Android выдаст security exception (ошибку безопасности), если необходимое полномочие отсутствует.
Broadcast receiver permission ограничивает, какие компоненты могут отправлять и получать широковещательные сообщения. Эти полномочия проверяются различными путями в различное время. Эту тему мы обсудим более подробно позже.
Content provider permissions ограничивает, какие компоненты могут читать и записывать данные, содержавшиеся в Content provider. И это тоже подробнее будет обсуждаться позже.
Класс Fragment
Фрагменты (Fragments) были добавлены в Android версии 3.0, чтобы лучше поддерживать пользовательские интерфейсы для устройств с большими экранами, таких как планшеты. За последние несколько лет популярность планшетов выросла невероятно. На большом дисплее планшета мы можем сделать намного больше, чем мы могли сделать на маленьком телефонном дисплее.
Чтобы быть конкретнее, давайте рассмотрим простое приложение под названием «QuoteViewer». Это приложение состоит из двух Activity. Первая показывает заголовки нескольких пьес Шекспира и позволяет пользователю выбрать один из заголовков. И, когда пользователь выбирает заголовок, запускается вторая Activity, которая выводит на экран одну цитату из выбранной пьесы.
Если я запущу приложение «QuoteViewer», первая Activity покажет нам заголовки трех пьес Шекспира: «Гамлет», «Король Лир» и «Юлий Цезарь». Далее я выберу Hamlet. Запустится вторая Activity, которая покажет мне цитату Горацио: «Now cracks a noble heart. Good night sweet prince, and flights of angels sing thee to thy rest».
Теперь я нажму кнопку «Назад», чтобы возвратиться к заголовкам. То же самое произойдет, если выбрать два других заголовка – будет запущено вторая Activity с цитатой из соответствующей пьесы.
Это прекрасный интерфейс для телефона. Фактически было бы трудно сделать больше и все еще иметь читаемый и простой в использовании интерфейс. На планшете, однако, этот же лейаут (layout) будет выглядеть довольно непрезентабельно. Здесь я покажу эмулированный планшет.

Первое, что вы замечаете, – это неиспользованное пустое белое поле. Заголовки занимают просто немного места на левой стороне дисплея, а остальное пространство в значительной степени потрачено впустую.
Теперь, если кликнуть по любому заголовку, вы увидите, что цитата простирается полностью через весь десятидюймовый экран слева направо, но использует ничтожно мало вертикального пространства.
Давайте рассмотрим более удачный лейаут (layout), который показывает и заголовки, и цитаты одновременно. Когда я кликаю по заголовку, вы видите, что пользовательский интерфейс по существу разделен на две части. Заголовки остаются там, где они были слева, но цитата теперь показана одновременно на правой стороне экрана. Теперь, если я захочу увидеть другую цитату, я просто выбираю новый заголовок пьесы слева. И тогда новая цитата раскрывается справа взамен предыдущей.
Этот лейаут исключает потраченное впустую пространство, и это делает навигацию немного проще, потому что я не должен перемещать палец вниз к нижней части дисплея, чтобы нажать кнопку "Назад", и затем обратно до заголовков, и т.д.
Приложение «QuoteViewer» было составлено из двух Activity. Приложение, которое мы сейчас увидели, составлено из единственной Activity, но с применением двух фрагментов. Фрагменты представляют часть пользовательского интерфейса Activity. У этого приложения есть две таких интерфейсных части. Одна – для заголовков – расположена слева, и одна – для цитат, которая расположена справа. И каждая из этих частей пользовательского интерфейса реализована как фрагмент.
Фрагменты размещены в Activity. Одна Activity может содержать любое количество фрагментов. И один фрагмент может быть использован в любом количестве Activity. Таким образом, фрагменты должны быть загружены в Activity, затем выведены на экран, удалены, и т.д., поскольку Activity изменяет свое состояние. И в результате жизненный цикл фрагмента связан и синхронизирован с жизненным циклом Activity, которая его содержит.
Вместе с тем у фрагментов есть некоторые их собственные call back‑методы жизненного цикла. На данный момент будем говорить о жизненном цикле фрагмента, предполагая, что фрагмент статически связан с Activity. О динамическом добавлении и удалении фрагментов в Activity мы будем говорить немного позже.
Фрагмент может быть в состоянии:
running (выполнение) или resumed (возобновленный) – в этих состояниях фрагмент видим (is visible) в работающей Activity;
paused (приостановлен) – фрагменты будут приостановлены, когда их Activity будет видима, но какая‑либо другая Activity (или другой фрагмент) находится на переднем плане и имеет фокус;
stopped (остановлен) – в этом состоянии фрагмент невидим.
Теперь поговорим о методах обратного вызова (call back) жизненного цикла, которые может получить фрагмент. Мы будем говорить о том, когда эти методы могут быть вызваны относительно состояний жизненного цикла Activity, которая размещает (содержит) фрагмент.
Когда содержащая фрагмент Activity создается, фрагмент может получить несколько вызовов метода жизненного цикла. Во‑первых, когда фрагмент присоединяется к своей Activity, он получает вызов onAttach. Затем фрагмент принимает вызов своего метода onCreate. И отметьте здесь для себя, что речь идет о методе fragment.onCreate, а не activity.onCreate, который вызывается при создании Activity. Вы инициализируете фрагмент в методе фрагмента onCreate, различие между двумя методами в том, что, в отличие от activity.onCreate, пользовательский интерфейс в fragment.onCreate вы не устанавливаете. Это фактически происходит в следующем методе.
Теперь, после onCreate, Android вызывает метод фрагмента onCreateView. Этот метод устанавливает и возвращает лейаут, содержащий пользовательский интерфейс фрагмента. И этот лейаут передается в Activity, чтобы установить его в layout‑иерархии Activity.
И, наконец, после того, как Activity была создана, и пользовательский интерфейс фрагмента был установлен, фрагмент принимает вызов метода onActivityCreated.

Теперь, пока фрагмент присоединен к Activity, его жизненный цикл зависит от жизненного цикла Activity. Когда лейаут пользовательского интерфейса фрагмента, который ранее создавался при вызове onCreateView, отсоединен от Activity, фрагмент принимает вызов onDestroyView. Здесь необходимо очистить ресурсы, связанные с лейаутом интерфейса. Затем, когда фрагмент больше не используется, он принимает вызов метода onDestroy. Здесь необходимо высвободить ресурсы фрагмента. Затем, когда фрагмент больше не присоединен к своей Activity, он примет вызов onDetach. Здесь необходимо обнулить ссылки на Activity фрагмента.
Есть два основных способа, которыми фрагменты добавляются к Activity.
Во-первых, они могут быть статически добавлены к Activity. Например, помещая фрагмент в файл лейаута Activity, который затем используется при вызове setContentView. Во-вторых, можно добавить фрагменты динамически, используя FragmentManager.
В любом случае, как только они будут добавлены, Android вызовет onCreateView. В onCreateView фрагмент может использовать свой собственный лейаут xml, подобно тому, как делают Activity, когда они вызывают setContentView, или фрагменты могут программно создать свои пользовательские интерфейсы.
Как только представление пользовательского интерфейса создано, onCreateView должен возвратить лейаут, расположенный в корне его пользовательского интерфейса. И этот лейаут будет в конечном счете передан в Activity и добавлен к ее пользовательскому интерфейсу.
Давайте рассмотрим приложение «FragmentStaticLayout» и посмотрим, как оно определяет свой лейаут. На левой панели показаны заголовки пьес Шекспира, а на правой панели показаны цитаты из этих пьес. И каждая из этих панелей реализована отдельным фрагментом, один называется TitleFragment, а другой QuoteFragment. И основная Activity этого приложения называется QuoteViewerActivity.
Давайте откроем файл QuoteViewerActivity и посмотрим, как он обрабатывает и создает свой лейаут.
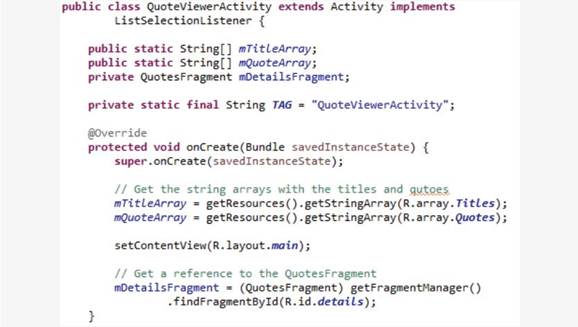
Сначала вы видите, что в методе onCreate есть вызов setContentView со значением параметра R.layout.main. Поэтому давайте посмотрим в каталоге res/layout файл main.xml.
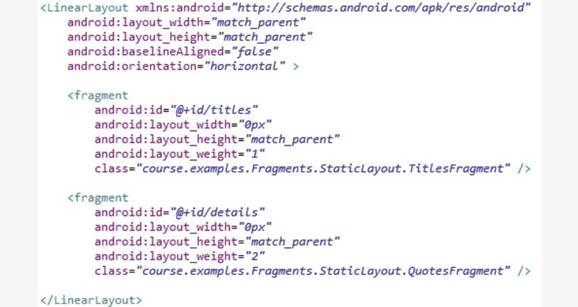
Как видите, весь лейаут состоит из LinearLayout, и что LinearLayout содержит два фрагмента. И в тегах <fragment…/>, есть атрибут, названный class. Значение этого атрибута – это имя класса, который реализует этот фрагмент. В этом случае один фрагмент реализован классом TitleFragment, а другой – классом QuotesFragment.
Когда этот xml-файл считан, Android поймет, что надо создать эти два фрагмента и поместить их в QuoteViewerActivity. Это запустит цепочку вызовов жизненного цикла, о которых мы говорили ранее. Один из этих вызовов будет вызовом onCreateView, в котором фрагмент ответственен за создание его лейаута пользовательского интерфейса.
Давайте рассмотрим один из лейаутов в QuoteFragment, то, как он создает свой пользовательский интерфейс. Имеется класс QuoteFragment и его метод onCreateView.

Этот метод вызывает метод inflate класса LayoutInflater, передавая файл лейаута (quote_fragment.xml) в качестве параметра. Это работает подобно тому, что происходит в setContentView.
Вы можете также добавить фрагменты в Activity без хардкодинга фрагментов в файле лейаута Activity. Для этого, в то время как Activity работает, надо сделать четыре вещи. Первое – получить ссылку на FragmentManager. Второе – начать FragmentTransaction. Третье – добавить фрагмент в Activity. И четвертое – зафиксировать (commit) FragmentTransaction.
Давайте откроем QuoteViewerActivity и посмотрим, как она обрабатывает свой лейаут (layout).

В onCreate есть вызов setContentView со значением параметра R.layout.main. Поэтому давайте посмотрим в каталоге res/layout файл main.xml.
Этот лейаут состоит из LinearLayout с двумя подразделами. Но вместо фрагментов на сей раз подразделы – это FrameLayout. FrameLayout должен зарезервировать некоторое пространство в пользовательском интерфейсе, и мы заполним это пространство позже, когда будем добавлять фрагменты в эту Activity.
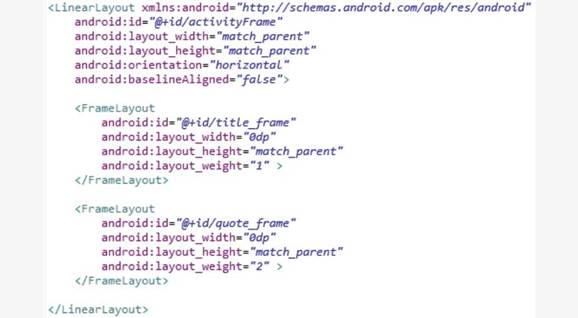
Теперь давайте вернемся к методу onCreate в QuoteViewerActivity и пройдем по тем четырем шагам, добавляя фрагменты в Activity. Во‑первых, получаем ссылку на FragmentManager. Затем вызываем метод beginTransaction. В результате получим FragmentTransaction. Затем вызываем метод add, передавая ID FrameLayout во фрагмент, который будет содержать этот FrameLayout. Это надо сделать и для TitleFragment, и для QuoteFragment. И, наконец, вызовем метод commit, чтобы зафиксировать все изменения.
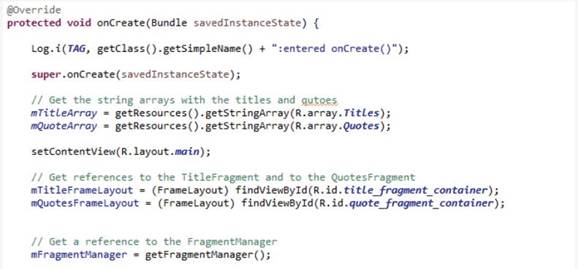
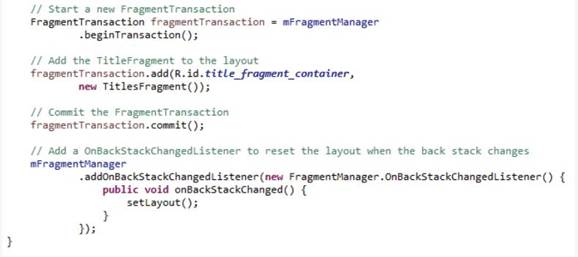
Теперь мы знаем как добавить фрагменты в Activity программно. Но в нашем примере это не имело такого большого значения в том смысле, что даже при том, что мы добавили фрагменты программно, их расположение (лейаут) было статично. Всегда есть только две панели, и это никогда не изменяется.
И один из плюсов способности добавлять фрагменты на лету – то, что она позволяет динамически изменять пользовательский интерфейс во время работы программы. И если делать это правильно, это позволит рационально использовать драгоценное экранное пространство.
Рассмотрим приложение «FragmentProgrammaticLayout», которое демонстрирует некоторые разновидности динамических пользовательских интерфейсов. Приложение иногда будет показывать единственный фрагмент, а иногда – несколько фрагментов.
Сразу после запуска мы видим только TitleFragment с заголовками пьес. Если кликнуть по заголовку, вы увидите справа уже знакомую цитату из Гамлета. В этой точке приложение выводит на экран два фрагмента. Если теперь нажать кнопку "Назад", вы увидите, что мы вернулись к отображению единственного фрагмента.
Теперь рассмотрим код. На сей раз в начале мы добавим только TitleFragment, а фрагмент с цитатами будем добавлять только, если пользователь кликнет по заголовку. Предположим, пользователь действительно кликает по заголовку. Тогда будет вызван метод onListSelection. Рассмотрим этот метод.
Во-первых, мы проверяем, был ли фрагмент с цитатами уже добавлен в layout. И, если нет, то мы добавим его, запуская другой FragmentTransaction.
Далее мы собираемся добавить эту транзакцию в стек задачи (Task backstack) для того, чтобы пользователь вернулся к тому состоянию экрана, который был прежде, до добавления нового фрагмента, когда он нажмет кнопку "Назад". И это надо сделать, потому что по умолчанию в стеке задач изменения фрагментов не отслеживаются.
В конце добавляем вызов FragmentManager.executePendingTransactions. Это вынуждает транзакцию выполниться сразу, а не тогда, когда система посчитает удобным это сделать, и нам пришлось бы ждать, пока обновится экран.
В главе об Activity мы говорили о том, как Activity могут обрабатывать изменения конфигурации вручную используя методы, такие как onRetainNonConfigurationInstance и getLastNonConfigurationInstance.
При изменении конфигурации устройства Android по умолчанию уничтожит Activity и воссоздаст ее. Однако, если вызвать метод setRetainInstance во фрагменте, передав в качестве параметра true, то когда произойдут изменения конфигурации, Android уничтожит Activity, но не уничтожит фрагменты, которые она содержит. Android сохранит состояние фрагмента, отсоединив фрагмент от Activity. И, кроме того, Android не уничтожит этот фрагмент и не воссоздаст его позже, когда Activity будет воссоздана. В результате фрагмент не получит вызова своих методов onDestroy и onCreate.
Давайте рассмотрим другой пример приложения, который демонстрирует это поведение. Это приложение называется «FragmentStaticConfigLayout», и его функциональность совпадает с предыдущими примерами. Различие здесь в том, что добавлен некоторый код, обрабатывающий изменения конфигурации. Когда устройство находится в альбомном режиме, лейаут выглядит так же, как и в предыдущем примере. Оба фрагмента используют большой шрифт или шрифт, независимый от масштаба. TitleFragment занимает приблизительно одну треть горизонтального пространства, в то время как QuoteFragment берет остающиеся две трети пространства. И, если заголовок будет слишком длинным, чтобы поместиться на одной строке в TitleFragment, то текст просто будет перенесен на вторую строку.
Теперь давайте повернем устройство. Когда устройство окажется в портретном режиме, лейаут немного изменится. Оба фрагмента используют меньший шрифт, TitleFragment занимает только одну четверть горизонтального пространства, в то время как QuoteFragment занимает остающиеся три четверти рабочего пространства. И, если заголовок будет слишком длинным, чтобы поместиться на одной строке в TitleFragment, то он будет все же ограничен одной строкой, и мы просто заменим часть текста замещающими знаками.
Заметьте, что даже при том, что Android уничтожил и перезапустил QuoteViewerActivity, заголовок, который был выбран во фрагменте слева, все еще остаётся выбранным, потому что был вызван setRetainInstance с параметром true в обоих фрагментах. В итоге информация о том, что некоторый элемент был выбран, сохранилась.
Давайте рассмотрим, как это работает. Код файла TitleFragment.java приложения «FragmentStaticConfigLayout» главным образом такой же, как тот, что мы видели в других примерах приложений, но есть по крайней мере два различия. Первое различие находится в методе onCreate – добавлен вызов setRetainInstance, true. Еще раз – это означает, что, когда происходят изменения конфигурации, Android не уничтожит этот фрагмент. Второе различие находится в методе onActivityCreated. В конце добавлен некоторый код, который проверяет индекс, означающий, что пользователь ранее выбрал заголовок, и что этот вызов onActivityCreated, вероятно, происходит из-за изменения конфигурации. В этом случае мы хотим удостовериться, что тот заголовок остается выбранным. Такие же изменения внесены и в класс QuoteFragment.
Криптография. Общая схема симметричного шифрования. Примеры симметричных алгоритмов шифрования
Общая схема симметричного шифрования
Классическая, или одноключевая криптография опирается на использование симметричных алгоритмов шифрования, в которых шифрование и расшифрование отличаются только порядком выполнения и направлением некоторых шагов. Эти алгоритмы используют один и тот же секретный элемент (ключ), и второе действие (расшифрование) является простым обращением первого (шифрования). Поэтому обычно каждый из участников обмена может как зашифровать, так и расшифровать сообщение. Схематичная структура такой системы представлена на рис.:
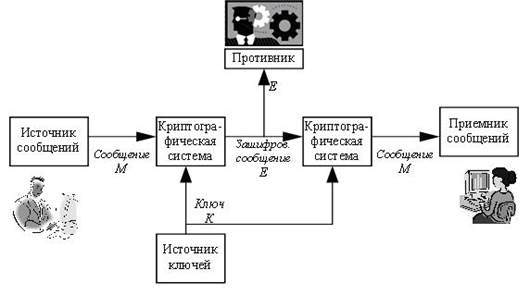
Рис. 2.1. Общая структура секретной системы, использующей симметричное шифрование
На передающей стороне имеются источник сообщений и источник ключей. Источник ключей выбирает конкретный ключ К среди всех возможных ключей данной системы. Этот ключ К передается некоторым способом принимающей стороне, причем предполагается, что его нельзя перехватить, например, ключ передается специальным курьером (поэтому симметричное шифрование называется также шифрованием с закрытым ключом). Источник сообщений формирует некоторое сообщение М, которое затем шифруется с использованием выбранного ключа. В результате процедуры шифрования получается зашифрованное сообщение Е (называемое также криптограммой). Далее криптограмма Е передается по каналу связи. Так как канал связи является открытым, незащищенным, например, радиоканал или компьютерная сеть, то передаваемое сообщение может быть перехвачено противником. На принимающей стороне криптограмму Е с помощью ключа расшифровывают и получают исходное сообщение М.
Если М – сообщение, К – ключ, а Е – зашифрованное сообщение, то можно записать E=f(M,K)
то есть зашифрованное сообщение Е является некоторой функцией от исходного сообщения М и ключа К. Используемый в криптографической системе метод или алгоритм шифрования и определяет функцию f в приведенной выше формуле.
По причине большой избыточности естественных языков непосредственно в зашифрованное сообщение чрезвычайно трудно внести осмысленное изменение, поэтому классическая криптография обеспечивает также защиту от навязывания ложных данных. Если же естественной избыточности оказывается недостаточно для надежной защиты сообщения от модификации, избыточность может быть искусственно увеличена путем добавления к сообщению специальной контрольной комбинации, называемой имитовставкой.
Известны разные методы шифрования с закрытым ключом рис. 2.2. На практике часто используются алгоритмы перестановки, подстановки, а также комбинированные методы.
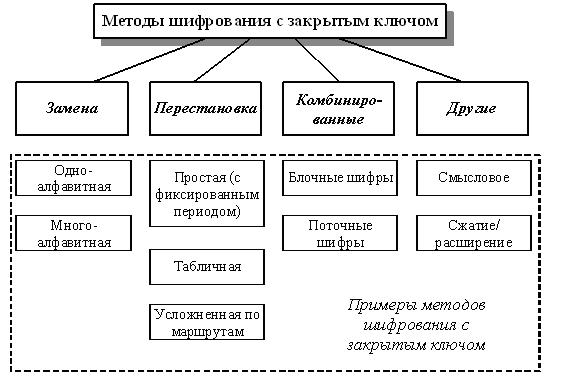
Рис. 2.2. Методы шифрования с закрытым ключом
В методах перестановки символы исходного текста меняются местами друг с другом по определенному правилу. В методах замены (или подстановки) символы открытого текста заменяются некоторыми эквивалентами шифрованного текста. С целью повышения надежности шифрования текст, зашифрованный с помощью одного метода, может быть еще раз зашифрован с помощью другого метода. В этом случае получается комбинированный или композиционный шифр. Применяемые на практике в настоящее время блочные или поточные симметричные шифры также относятся к комбинированным, так как в них используется несколько операций для зашифрования сообщения.
Основное отличие современной криптографии от криптографии "докомпьютерной" заключается в том, что раньше криптографические алгоритмы оперировали символами естественных языков, например, буквами английского или русского алфавитов. Эти буквы переставлялись или заменялись другими по определенному правилу. В современных криптографических алгоритмах используются операции над двоичными знаками, то есть над нулями и единицами. В настоящее время основными операциями при шифровании также являются перестановка или подстановка, причем для повышения надежности шифрования эти операции применяются вместе (комбинируются) и помногу раз циклически повторяются.
Методы замены
Методы шифрования заменой (подстановкой) основаны на том, что символы исходного текста, обычно разделенные на блоки и записанные в одном алфавите, заменяются одним или несколькими символами другого алфавита в соответствии с принятым правилом преобразования.
Одноалфавитная замена
Одним из важных подклассов методов замены являются одноалфавитные (или моноалфавитные) подстановки, в которых устанавливается однозначное соответствие между каждым знаком ai исходного алфавита сообщений A и соответствующим знаком ei зашифрованного текста E. Одноалфавитная подстановка иногда называется также простой заменой, так как является самым простым шифром замены.
Примером одноалфавитной замены является шифр Цезаря, рассмотренный ранее. В рассмотренном в примере первая строка является исходным алфавитом, вторая (с циклическим сдвигом на k влево) – вектором замен.
В общем случае при одноалфавитной подстановке происходит однозначная замена исходных символов их эквивалентами из вектора замен (или таблицы замен). При таком методе шифрования ключом является используемая таблица замен.
Подстановка может быть задана с помощью таблицы, например, как показано на рис. 2.3.
Рис. 2.3. Пример таблицы замен для двух шифров
В таблице на рис. 2.3 на самом деле объединены сразу две таблицы. Одна (шифр 1) определяет замену русских букв исходного текста на другие русские буквы, а вторая (шифр 2) – замену букв на специальные символы. Исходным алфавитом для обоих шифров будут заглавные русские буквы (за исключением букв "Ё" и "Й"), пробел и точка.
Зашифрованное сообщение с использованием любого шифра моноалфавитной подстановки получается следующим образом. Берется очередной знак из исходного сообщения. Определяется его позиция в столбце "Откр. текст" таблицы замен. В зашифрованное сообщение вставляется шифрованный символ из этой же строки таблицы замен.
Полученный таким образом текст имеет сравнительно низкий уровень защиты, так как исходный и зашифрованный тексты имеют одинаковые статистические закономерности. При этом не имеет значения, какие символы использованы для замены – перемешанные символы исходного алфавита или таинственно выглядящие знаки.
Зашифрованное сообщение может быть вскрыто путем так называемого частотного криптоанализа. Для этого могут быть использованы некоторые статистические данные языка, на котором написано сообщение.
Известно, что в текстах на русском языке наиболее часто встречаются символы О, И. Немного реже встречаются буквы Е, А. Из согласных самые частые символы Т, Н, Р, С. В распоряжении криптоаналитиков имеются специальные таблицы частот встречаемости символов для текстов разных типов – научных, художественных и т.д.
Криптоаналитик внимательно изучает полученную криптограмму, подсчитывая при этом, какие символы сколько раз встретились. Вначале наиболее часто встречаемые знаки зашифрованного сообщения заменяются, например, буквами О. Далее производится попытка определить места для букв И, Е, А. Затем подставляются наиболее часто встречаемые согласные. На каждом этапе оценивается возможность "сочетания" тех или иных букв. Например, в русских словах трудно найти четыре подряд гласные буквы, слова в русском языке не начинаются с буквы Ы и т.д. На самом деле для каждого естественного языка (русского, английского и т.д.) существует множество закономерностей, которые помогают раскрыть специалисту зашифрованные противником сообщения.
Возможность однозначного криптоанализа напрямую зависит от длины перехваченного сообщения. Если же в руки криптоаналитиков попадает достаточно длинное сообщение, зашифрованное методом простой замены, его обычно удается успешно дешифровать. На помощь специалистам по вскрытию криптограмм приходят статистические закономерности языка. Чем длиннее зашифрованное сообщение, тем больше вероятность его однозначного дешифрования.
Интересно, что если попытаться замаскировать статистические характеристики открытого текста, то задача вскрытия шифра простой замены значительно усложнится. Например, с этой целью можно перед шифрованием "сжимать" открытый текст с использованием компьютерных программ-архиваторов.
С усложнением правил замены увеличивается надежность шифрования. Можно заменять не отдельные символы, а, например, двухбуквенные сочетания – биграммы. Таблица замен для такого шифра может выглядеть, как в таблице 2.3.
| Таблица 2.3. Пример таблицы замен для двухбуквенных сочетаний | |||
| Откр. текст | Зашифр. текст | Откр. текст | Зашифр. текст |
| аа | кх | бб | пш |
| аб | пу | бв | вь |
| ав | жа | ... | ... |
| ... | ... | яэ | сы |
| ая | ис | яю | ек |
| ба | цу | яя | рт |
Оценим размер такой таблицы замен. Если исходный алфавит содержит N символов, то вектор замен для биграммного шифра должен содержать N2 пар "откр. текст – зашифр. текст". Таблицу замен для такого шифра можно также записать и в другом виде: заголовки столбцов соответствуют первой букве биграммы, а заголовки строк – второй, причем ячейки таблицы заполнены заменяющими символами. В такой таблице будет N строк и N столбцов (таблица 2.4).
| Таблица 2.4. Другой вариант задания таблицы замен для биграммного шифра | ||||
| а | б | ... | я | |
| а | кх | цу | ... | ... |
| б | пу | пш | ... | ... |
| в | жа | вь | ... | ... |
| ... | ... | ... | ... | ... |
| ю | ... | ... | ... | ек |
| я | ис | ... | ... | рт |
Возможны варианты использования триграммного или вообще n-граммного шифра. Такие шифры обладают более высокой криптостойкостью, но они сложнее для реализации и требуют гораздо большего количества ключевой информации (большой объем таблицы замен). В целом, все n-граммные шифры могут быть вскрыты с помощью частотного криптоанализа, только используется статистика встречаемости не отдельных символов, а сочетаний из n символов.
Пропорциональные шифры
К одноалфавитным методам подстановки относятся пропорциональные или монофонические шифры, в которых уравнивается частота появления зашифрованных знаков для защиты от раскрытия с помощью частотного анализа. Для знаков, встречающихся часто, используется относительно большое число возможных эквивалентов. Для менее используемых исходных знаков может оказаться достаточным одного или двух эквивалентов. При шифровании замена для символа открытого текста выбирается либо случайным, либо определенным образом (например, по порядку).
При использовании пропорционального шифра в качестве замены символам обычно выбираются числа. Например, поставим в соответствие буквам русского языка трехзначные числа, как указано в таблице 2.5.
| Таблица 2.5. Таблица замен для пропорционального шифра | |||||||||||
| Символ | |||||||||||
Варианты замены
Варианты замены
В этом случае сообщение
БОЛЬШОЙ СЕКРЕТможет быть зашифровано следующим образом:
101757132562103213762751800761754134130759В данном примере варианты замен для повторяющихся букв (например, "О") выбирались по порядку.
Пропорциональные шифры более сложны для вскрытия, чем шифры простой одноалфавитной замены. Однако, если имеется хотя бы одна пара "открытый текст – шифротекст", вскрытие производится тривиально. Если же в наличии имеются только шифротексты, то вскрытие ключа, то есть нахождение таблицы замен, становится более трудоемким, но тоже вполне осуществимым.
Многоалфавитные подстановки
В целях маскирования естественной частотной статистики исходного языка применяется многоалфавитная подстановка, которая также бывает нескольких видов. В многоалфавитных подстановках для замены символов исходного текста используется не один, а несколько алфавитов. Обычно алфавиты для замены образованы из символов исходного алфавита, записанных в другом порядке.
Примером многоалфавитной подстановки может служить схема, основанная на использовании таблицы Вижинера. Этот метод, известный уже в XVI веке, был описан французом Блезом Вижинером в "Трактате о шифрах", вышедшем в 1585 году. В этом методе для шифрования используется таблица, представляющая собой квадратную матрицу с числом элементов NxN, где N — количество символов в алфавите ( таблица 2.6). В первой строке матрицы записывают буквы в порядке очередности их в исходном алфавите, во второй — ту же последовательность букв, но с циклическим сдвигом влево на одну позицию, в третьей — со сдвигом на две позиции и т. д.
| Таблица 2.6. Подготовка таблицы шифрования | |
| АБВГДЕ........ | ..........ЭЮЯ |
| БВГДЕЖ........ | ..........ЮЯА |
| ВГДЕЖЗ........ | ..........ЯАБ |
| ГДЕЖЗИ......... | ..........АБВ |
| ДЕЖЭИК......... | ..........БВГ |
| ЕЖЗИКЛ......... | ..........ВГД |
| ........... | .......... |
| ЯАБВГД......... | ..........ЬЭЮ |
Для шифрования текста выбирают ключ, представляющий собой некоторое слово или набор символов исходного алфавита. Далее из полной матрицы выписывают подматрицу шифрования, включающую первую строку и строки матрицы, начальными буквами которых являются последовательно буквы ключа.
В процессе шифрования под каждой буквой шифруемого текста записывают буквы ключа, повторяющие ключ требуемое число раз, затем шифруемый текст по таблице шифрования заменяют буквами, расположенными на пересечениях линий, соединяющих буквы текста первой строки таблицы и буквы ключа, находящейся под ней.
Рассмотрим на примере процесс расшифрования сообщения по методу Вижинера. Пусть имеется зашифрованное с помощью ключа ВЕСНА сообщение КЕКХТВОЭЦОТССВИЛ (пробелы при шифровании пропущены). Расшифровка текста выполняется в следующей последовательности:
· над буквами шифрованного текста сверху последовательно записывают буквы ключа, повторяя ключ требуемое число раз;
· в строке подматрицы таблицы Вижинера для каждой буквы ключа отыскивается буква, соответствующая знаку шифрованного текста. Находящаяся над ней буква первой строки и будет знаком расшифрованного текста;
· полученный текст группируется в слова по смыслу.
Раскрыть шифр Вижинера, тем же способом, что и шифр одноалфавитной замены, невозможно, так как одни и те же символы открытого текста могут быть заменены различными символами зашифрованного текста. С другой стороны, различные буквы открытого текста могут быть заменены одинаковыми знаками зашифрованного текста.
Особенность данного метода многоалфавитной подстановки заключается в том, что каждый из символов ключа используется для шифрования одного символа исходного сообщения. После использования всех символов ключа, они повторяются в том же порядке. Если используется ключ из десяти букв, то каждая десятая буква сообщения шифруется одним и тем же символом ключа. Этот параметр называется периодом шифра. Если ключ шифрования состоит из одного символа, то при шифровании будет использоваться одна строка таблицы Вижинера, следовательно, в этом случае мы получим моноалфавитную подстановку, а именно шифр Цезаря.
С целью повышения надежности шифрования текста можно использовать подряд два или более зашифрования по методу Вижинера с разными ключами (составной шифр Вижинера).
На практике кроме метода Вижинера использовались также различные модификации этого метода. Например, шифр Вижинера с перемешанным один раз алфавитом. В этом случае для расшифрования сообщения получателю необходимо кроме ключа знать порядок следования символов в таблице шифрования.
Еще одним примером метода многоалфавитной подстановки является шифр с бегущим ключом или книжный шифр. В этом методе один текст используется в качестве ключа для шифрования другого текста. В эпоху "докомпьютерной" криптографии в качестве ключа для шифра с бегущим ключом выбирали какую-нибудь достаточно толстую книгу; от этого и произошло второе название этого шифра. Периодом в таком методе шифрования будет длина выбранного в качестве ключа произведения.
Методы многоалфавитной подстановки, в том числе и метод Вижинера, значительно труднее поддаются "ручному" криптоанализу. Для вскрытия методов многоалфавитной замены разработаны специальные, достаточно сложные алгоритмы. С использованием компьютера вскрытие метода многоалфавитной подстановки возможно достаточно быстро благодаря высокой скорости проводимых операций и расчетов.
В первой половине ХХ века для автоматизации процесса выполнения многоалфавитных подстановок стали широко применять роторные шифровальные машины. Главными элементами в таких устройствах являлись роторы – механические колеса, используемые для выполнения подстановки. Роторная шифровальная машина содержала обычно клавиатуру и набор роторов. Каждый ротор содержал набор символов (по количеству в алфавите), размещенных в произвольном порядке, и выполнял простую одноалфавитную подстановку. После выполнения первой замены символы сообщения обрабатывались вторым ротором и так далее. Роторы могли смещаться, что и задавало ключ шифрования. Некоторые роторные машины выполняли также и перестановку символов в процессе шифрования. Самым известным устройством подобного класса являлась немецкая шифровальная роторная машина Энигма (лат. Enigma — загадка), использовавшаяся во время второй мировой войны. Выпускалось несколько моделей Энигмы с разным числом роторов. В шифрмашине Энигма с тремя роторами можно было использовать 16900 разных алфавитов, и все они представляли собой различные перестановки символов.
Методы гаммирования
Еще одним частным случаем многоалфавитной подстановки является гаммирование. В этом способе шифрование выполняется путем сложения символов исходного текста и ключа по модулю, равному числу букв в алфавите. Если в исходном алфавите, например, 33 символа, то сложение производится по модулю 33. Такой процесс сложения исходного текста и ключа называется в криптографии наложением гаммы.
Пусть символам исходного алфавита соответствуют числа от 0 (А) до 32 (Я). Если обозначить число, соответствующее исходному символу, x, а символу ключа – k, то можно записать правило гаммирования следующим образом: z = x + k (mod N),
где z – закодированный символ, N - количество символов в алфавите, а сложение по модулю N - операция, аналогичная обычному сложению, с тем отличием, что если обычное суммирование дает результат, больший или равный N, то значением суммы считается остаток от деления его на N. Например, пусть сложим по модулю 33 символы Г (3) и Ю (31): 3 + 31 (mod 33) = 1, то есть в результате получаем символ Б, соответствующий числу 1.
Наиболее часто на практике встречается двоичное гаммирование. При этом используется двоичный алфавит, а сложение производится по модулю два. Операция сложения по модулю 2 часто обозначается , то есть можно записать:
Операция сложения по модулю два в алгебре логики называется также "исключающее ИЛИ" или по-английски XOR.
Сложим по модулю два двоичные числа 1110 и 1100:
Исходное число 1 1 1 0Гамма 1 1 0 0Результат 0 0 1 0В результате сложения получили двоичное число 0010. Если перевести его в десятичную форму, получим 2. Таким образом, в результате применения к числу 14 операции гаммирования с ключом 12 получаем в результате число 2.
Каким же образом выполняется расшифрование? Зашифрованное число 2 представляется в двоичном виде и снова производится сложение по модулю 2 с ключом:
Зашифрованное число 0 0 1 0Гамма 1 1 0 0Результат 1 1 1 0Переведем полученное двоичное значение 1110 в десятичный вид и получим 14, то есть исходное число.
Таким образом, при гаммировании по модулю 2 нужно использовать одну и ту же операцию как для зашифрования, так и для расшифрования. Это позволяет использовать один и тот же алгоритм, а соответственно и одну и ту же программу при программной реализации, как для шифрования, так и для расшифрования.
Операция сложения по модулю два очень быстро выполняется на компьютере (в отличие от многих других арифметических операций), поэтому наложение гаммы даже на очень большой открытый текст выполняется практически мгновенно. Благодаря указанным достоинствам метод гаммирования широко применяется в современных технических системах сам по себе, а также как элемент комбинированных алгоритмов шифрования.
Методы перестановки
При использовании шифров перестановки входной поток исходного текста делится на блоки, в каждом из которых выполняется перестановка символов. Перестановки в классической "докомпьютерной" криптографии получались в результате записи исходного текста и чтения шифрованного текста по разным путям геометрической фигуры.
Простейшим примером перестановки является перестановка с фиксированным периодом d. В этом методе сообщение делится на блоки по d символов и в каждом блоке производится одна и та же перестановка. Правило, по которому производится перестановка, является ключом и может быть задано некоторой перестановкой первых d натуральных чисел. В результате сами буквы сообщения не изменяются, но передаются в другом порядке.
Например, для d=6 в качестве ключа перестановки можно взять 436215. Это означает, что в каждом блоке из 6 символов четвертый символ становится на первое место, третий – на второе, шестой – на третье и т.д.
Теоретически, если блок состоит из d символов, то число возможных перестановок d!=1*2*...*(d-1)*d. В последнем примере d=6, следовательно, число перестановок равно 6!=1*2*3*4*5*6=720. Таким образом, если противник перехватил зашифрованное сообщение из рассмотренного примера, ему понадобится не более 720 попыток для раскрытия исходного сообщения (при условии, что размер блока известен противнику).
Для повышения криптостойкости можно последовательно применить к шифруемому сообщению две или более перестановки с разными периодами.
Другим примером методов перестановки является перестановка по таблице. В этом методе производится запись исходного текста по строкам некоторой таблицы и чтение его по столбцам этой же таблицы. Последовательность заполнения строк и чтения столбцов может быть любой и задается ключом.
Рассмотрим пример. Пусть в таблице кодирования будет 4 столбца и 3 строки (размер блока равен 3*4=12 символов). Зашифруем такой текст: ЭТО ТЕКСТ ДЛЯ ШИФРОВАНИЯ
Количество символов в исходном сообщении равно 24, следовательно, сообщение необходимо разбить на 2 блока. Запишем каждый блок в свою таблицу по строчкам ( таблица 2.9).
| Таблица 2.9. Шифрование методом перестановки по таблице | |||
Блок
Блок
Затем будем считывать из таблицы каждый блок последовательно по столбцам:
ЭТТТЕ ОКД СЛЯФА РНШОИИВЯМожно считывать столбцы не последовательно, а, например, так: третий, второй, первый, четвертый:
ОКДТЕ ЭТТ СЛШОИ РНЯФАИВЯВ этом случае порядок считывания столбцов и будет ключом.
В случае, если размер сообщения не кратен размеру блока, можно дополнить сообщение какими-либо символами, не влияющими на смысл, например, пробелами. Однако это делать не рекомендуется, так как это дает противнику в случае перехвата криптограммы информацию о размере используемой таблицы перестановок (длине блока). После определения длины блока противник может найти длину ключа (количество столбцов таблицы) среди делителей длины блока.
Существуют и другие способы перестановки, которые можно реализовать программным и аппаратным путем. Например, при передаче данных, записанных в двоичном виде, удобно использовать аппаратный блок, который перемешивает определенным образом с помощью соответствующего электрического монтажа биты исходного n-разрядного сообщения. Так, если принять размер блока равным восьми битам, можно, к примеру, использовать такой блок перестановки, как на рис. 2.7.
Рис. 2.7. Аппаратный блок перестановки
Для расшифрования на приемной стороне устанавливается другой блок, восстанавливающий порядок цепей.
Аппаратно реализуемая перестановка широко используется на практике как составная часть некоторых современных шифров.
При перестановке любого вида в зашифрованное сообщение будут входить те же символы, что и в открытый текст, но в другом порядке. Следовательно, статистические закономерности языка останутся без изменения. Это дает криптоаналитику возможность использовать различные методы для восстановления правильного порядка символов.
Если у противника есть возможность пропускать через систему шифрования методом перестановки специально подобранные сообщения, то он сможет организовать атаку по выбранному тексту. Так, если длина блока в исходном тексте равна N символам, то для раскрытия ключа достаточно пропустить через шифровальную систему N-1 блоков исходного текста, в которых все символы, кроме одного, одинаковы. Другой вариант атаки по выбранному тексту возможен в случае, если длина блока N меньше количества символов в алфавите. В этом случае можно сформировать одно специальное сообщение из разных букв алфавита, расположив их, например, по порядку следования в алфавите. Пропустив подготовленное таким образом сообщение через шифровальную систему, специалисту по криптоанализу останется только посмотреть, на каких позициях очутились символы алфавита после шифрования, и составить схему перестановки.
Блочные симметричные шифры
Дата: 2019-02-02, просмотров: 468.