Оперативная память (ОП) – это совокупность ОЗУ, объединённых в одну систему, управляемую процессором. Для обеспечение приспосабливаемости ЭВМ к конкретным потребностям пользователей применяют принцип блочного построения ОП. Так, например, на основе блоков ОЗУ ёмкостью 128 и 256 килобайт можно построить ОП любой ёмкости. ОП заданной ёмкости, составленная из нескольких блоков ОЗУ, называется многоблочной ОП.
В функциональном отношении многоблочная ОП рассматривается как одно ОЗУ с емкостью, равной сумме емкостей блоков, и быстродействием, примерно равным быстродействию отдельного блока. Адрес ячеек такой ОП содержит адрес блока и адрес ячейки памяти в заданном блоке ОЗУ.
Устройства, подключённые к ОП, обращаются к ней независимо друг от друга. Принцип обслуживания запросов к ОП – приоритетный. Устройствам присваиваются приоритеты: низший — центральному процессору, более высший – ВЗУ. ОП обслуживает очередной запрос с наивысшим приоритетом, а все остальные запросы от других устройств ожидают момента окончания обслуживания. Такой принцип обслуживания объясняется тем, что ВЗУ не могут долго ждать, так как большое время ожидания приводит к потере информации, записываемой или считываемой с непрерывно движущегося носителя. ОП, ресурсы которой распределяются между несколькими потребителями, называют ОП с многоканальным доступом.
Многоблочная ОП, в которой допускается совместное выполнение обращений к разным блокам ОЗУ называется ОП с расслоением обращений. В такой ОП блоки ОЗУ функционируют параллельно во времени, что возможно, если последующие обращения к ОП адресованы к блокам, не запятым обслуживанием предшествующих запросов. Степень расслоения обращений характеризуется коэффициентом расслоения, равным среднему числу обращений к ОП, которые могут быть приняты на обслуживание одновременно. Чем выше коэффициент расслоения, тем выше производительность.
Из микросхем памяти (RAM – Random Access Memory, память с произвольным доступом) используется два основных типа: статическая (SRAM – Static RAM) и динамическая (DRAM – Dynamic RAM).
Статическое распределение памяти основано на выделении ячеек ОП для массивов (упорядоченная последовательность информационных и управляющих слов образует массив) в процессе анализа и составления программы, т.е. до начала решения задачи и при выполнении программы базисные адреса сохраняют постоянные значения.
Группа ячеек памяти с последовательными номерами 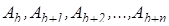 , представляющая массив длиной
, представляющая массив длиной 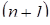 рассматривается как массив ячеек памяти с базовым адресом
рассматривается как массив ячеек памяти с базовым адресом 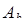 :
:
| Адрес | Оперативная память |
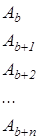
| |
При статическом распределении ячеек памяти в массивах память используется неэффективно, так как в процессе решения задачи количество слов в массиве в большинстве случаев меньше длины массива ячеек с базовым адресом , поэтому этот способ применяется лишь в простейших системах программирования на небольших ЭВМ.
Динамическое распределение памяти основано на выделении ячеек памяти для массивов с учётом их длин в порядке их появления в процессе решения задачи. Оно используется для экономии ячеек памяти в пределах одной программы и при мультипрограммной работе ЭВМ для распределения памяти между программами.
В статической памяти ячейки построены на различных типах триггеров (схем с двумя устойчивыми состояниями). После записи бита в такую ячейку она может пребывать в этом состоянии столь угодно долго – необходимо только наличие питания. При обращении к микросхеме статической памяти на неё подаётся полный адрес, который при помощи внутреннего дешифратора преобразуется в сигналы выборки конкретных ячеек. Ячейки статической памяти имеют малое время срабатывания, однако имеют низкую удельную плотность данных и высокое энергопотребление. Поэтому статическая память используется в основном в качестве кэш-памяти.
В динамической памяти ячейки построены на основе областей с накоплением зарядов (ёмкостные переходы в полевых транзисторах), занимающих гораздо меньшую площадь, чем триггеры, и практически не потребляющих энергии при хранении. При записи бита в такую ячейку в ней формируется электрический заряд, который сохраняется в течение нескольких миллисекунд; для постоянного сохранения заряда ячейки необходимо регенерировать – перезаписывать содержимое для восстановления зарядов. Ячейки микросхем динамической памяти организованы в виде квадратной матрицы; при обращении к микросхеме на её входы вначале подаётся адрес строки матрицы, сопровождаемый сигналом RAS (Row Address Strobe – строб адреса строки), затем, через некоторое время – адрес столбца, сопровождаемый сигналом CAS (Column Address Strobe – строб адреса столбца). При каждом обращении к ячейке регенерируют все ячейки выбранной строки, поэтому для полной регенерации матрицы достаточно перебрать адреса строк. Ячейки динамической памяти имеют большее время срабатывания (десятки- сотни наносекунд), но большую удельную плотность (порядка десятков Мбит на корпус) и меньшее энергопотребление. Динамическая память используется в качестве основной.
Обычные виды SRAM и DRAM называются также асинхронными, потому что установка адреса, подача управляющих сигналов и чтение/запись данных могут выполняться в произвольные моменты времени – необходимо только соблюдение временных соотношений между этими сигналами. В эти временные соотношения включены так называемые охранные интервалы, необходимые для стабилизации сигналов, которые не позволяют достичь теоретически возможного быстродействия памяти. Существуют также синхронные виды памяти, получающие внешний синхросигнал, к импульсам которого жестко привязаны моменты подачи адресов и обмена данными; помимо экономии времени на охранных интервалах, они позволяют более полно использовать внутреннюю конвейеризацию и блочный доступ.
FPM DRAM (Fast Page Mode DRAM – динамическая память с быстрым страничным доступом) активно используется при разработке и производстве ОП в последние несколько лет. Память со страничным доступом отличается от обычной динамической памяти тем, что после выбора строки матрицы и удержании RAS допускает многократную установку адреса столбца, стробируемого CAS, и также быструю регенерацию по схеме "CAS прежде RAS". Первое позволяет ускорить блочные передачи, когда весь блок данных или его часть находятся внутри одной строки матрицы, называемой в этой системе страницей, а второе -снизить накладные расходы на регенерацию памяти.
EDO (Entended Data Out – расширенное время удержания данных на выходе) фактически представляют собой обычные микросхемы FPM, на выходе которых установлены регистры-защёлки данных. При страничном обмене такие микросхемы работают в режиме простого конвейера: удерживают на выходах данных содержимое последней выбранной ячейки, в то время как на их входы уже подаётся адрес следующей выбираемой ячейки. Это позволяет примерно на 15% по сравнению с FPM ускорить процесс считывания последовательных массивов данных. При случайной адресации такая память ничем не отличается от обычной.
BEDO (Burst EDO – EDO с блочным доступом) – память на основе EDO, работающая не одиночными, а пакетными циклами чтения/записи. Современные процессоры, благодаря внутреннему и внешнему кэшированию команд и данных, обмениваются с основной памятью преимущественно блоками слов максимальной ширины. В случае использования памяти BEDO отпадает необходимость постоянной подачи последовательных адресов на входы микросхем с соблюдением необходимых временных задержек – достаточно стробировать переход к очередному слову отдельным сигналом.
SDRAM (Synchronous DRAM – синхронная динамическая память) – это память с синхронным доступом, работающая быстрее обычной асинхронной (EPM/EDO/BEDO). Помимо синхронного метода доступа, SDRAM использует внутреннее разделение массива памяти на два независимых банка, что позволяет совмещать выборку из одного банка с установкой адреса в другом банке. SDRAM также поддерживает блочный обмен. Основная выгода от использования SDRAM состоит в поддержке последовательного доступа в синхронном режиме, где не требуется дополнительных тактов ожидания. При случайном доступе SDRAM работает практически с той же скоростью, что и FPM/EDO.
PB SRAM (Pipelined Burst SRAM – статическая память с блочным конвейерным доступом) – разновидность синхронных SRAM с внутренней конвейеризацией, за счет которой примерно вдвое повышается скорость обмена данными.
Микросхемы памяти имеют 4 основные характеристики: тип, объём, структуру и время доступа. Тип обозначает статическую или динамическую память, объем показывает общую емкость микросхемы, а структура – количество ячеек памяти и разрядность каждой ячейки.
Например, 28/32–выводные DIP–микросхемы SRAM имеют восьмиразрядную структуру 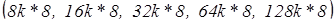 и кэш для 486 объемом 256 кб будет состоять из восьми микросхем
и кэш для 486 объемом 256 кб будет состоять из восьми микросхем 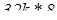 или четырех микросхем
или четырех микросхем 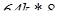 (речь идет об области данных, дополнительные микросхемы для хранения признаков (tag) могут иметь другую структуру). Две микросхемы по 128k*8 поставить уже нельзя, так как нужна 32- разрядная шина данных, что могут дать только четыре параллельных микросхемы. Распространенные РB SRAM в 100- выводных корпусах PQFP имеют 32-разрядную структуру 32k*32 или 64k*32 и используются по две или по четыре в платах для Pentuim.
(речь идет об области данных, дополнительные микросхемы для хранения признаков (tag) могут иметь другую структуру). Две микросхемы по 128k*8 поставить уже нельзя, так как нужна 32- разрядная шина данных, что могут дать только четыре параллельных микросхемы. Распространенные РB SRAM в 100- выводных корпусах PQFP имеют 32-разрядную структуру 32k*32 или 64k*32 и используются по две или по четыре в платах для Pentuim.
RAID – массивы
RAID (Redundant Array of Independent Disks – избыточный массив независимых дисков) – это совокупность средств, с помощью которых независимые диски организуются в группы с целью повышения производительности и/или надёжности. RAID был впервые предложен Паттерсоном, Гибсоном и Кацем. В их статье в аббревиатуре RAID литера I обозначала Inexpensive – «недорогой», но это значение было позже изменено на Independent – «независимый», поскольку в последние годы для реализации RAID весьма часто используются дорогие высокопроизводительные накопители.
Авторы статьи заметили, что быстродействие процессоров, объем оперативной памяти объёмы внешних накопителей росли быстро, а скорости ввода/вывода (особенно для дисковых накопителей) – намного медленнее. Компьютерные системы становились все более зависимыми от ввода/вывода – они не могли выполнять запросы на ввод/вывод так быстро, как эта запросы возникали, и не могли передавать данные так быстро, как эти данные потреблялись. Чтобы увеличить скорость передачи и пропускную способность, авторы предложили создавать массивы дисков, к которым можно будет обращаться одновременно.
В своей статье Паттерсон и его коллеги предложили пять различных организаций, или уровней (disk levels) дисковых массивов. Каждый уровень RAID-массива характеризуется разделением данных (data striping) и избыточностью (redundancy). Разделение данных означает, что пространство устройства хранения делится на блоки фиксированного размера, называемые полосами (strips). Следующие друг за другом блоки файла размещаются на соседних полосах на разных накопителях массива, и запросы к данным файла могут обрабатываться сразу несколькими накопителями, что уменьшает время доступа.
При выборе размера полосы разработчик системы должен принять во внимание средний размер запросов к диску. Полосы небольшого размера, называемые тонкими полосами (fine-grained strips), распределяют данные между несколькими дисками. Соответственно они уменьшают время выполнения запросов и увеличивают скорости передачи, поскольку множество дисков одновременно передают или принимают данные запроса. Пока эти диски выполняют запрос, они не могут выполнять другие запросы в очереди, поддерживаемой системой.
Полосы большого размера, называемые широкими полосами (coarse-grained strips), позволяют небольшим файлам целиком размещаться на одном накопителе. В этом случае некоторые запросы могут целиком вы полниться отдельными накопителями массива. В результате увеличивается вероятность того, что можно будет одновременно выполнять несколько запросов. Однако малые по объёму запросы будут выполняться отдельными накопителями, и скорость передачи для них будет меньше, чем при использовании тонких полос.
Такие системы, как Web-серверы и серверы баз данных, выигрывают от применения широких полос, поскольку при их использовании могут выполняться сразу несколько операций ввода/вывода. Системы класса суперкомпьютеров, требующие быстрого доступа к небольшому числу записей, выигрывают от использования узких полос, поскольку они дают большие скорости передачи при выполнении отдельных запросов.
Увеличение скорости передачи достигается в RAID-массивах немалой ценой. С увеличением количества накопителей в массивах растёт вероятность того, что один из накопителей выйдет из строя. Например, если средняя наработка на отказ (Mean Time To Failure – MTTF) для одиночного накопителя составляет 200 000 часов (около 23 лет), то для массива из 100 накопителей она составит 2 000 часов (около 3 месяцев). Если один из накопителей откажет, то будут повреждены все файлы, полосы которых размещены на этом накопителе. В системах, решающих критичные, жизненно важные задачи, потеря данных может иметь катастрофические последствия. Поэтому RAID-массивы должны хранить дополнительную информацию, которая позволит восстановить данные в случае появления ошибок – подход, называемый избыточностью, RAID-массивы используют избыточность для достижения отказоустойчивости.
Прямолинейный подход к обеспечению избыточности – дублирование дисков (disk mirroring), при котором каждый уникальный элемент данных записывается на двух накопителях. Недостаток этого подхода в том, что только половина ёмкости массива используется непосредственно для хранения уникальных данных.
Чтобы совместить улучшение производительности с избыточностью, система должна эффективно разделять файлы на полосы, формировать файлы из полос, определять местоположение полос в массивах и обеспечивать поддержку избыточности. Использование для выполнения этих операций процессора общего назначения может существенно снизить производительность, отнимая заметную часть процессорного времени. Поэтому во многих RAID-массивах для быстрого выполнения нужных операций используется специальный аппаратно реализованный RAID-контроллер (RAID controller). Аппаратные RAID-контроллеры также упрощают реализацию RAID-массивов, позволяя системе просто передавать им запросы на чтение и запись данных, причём контроллеры сами выполняют разделение данных на полосы и поддержку избыточности информации. Однако аппаратные RAID-контроллеры могут заметно повысить стоимость системы.
RAID 0 (striping – «чередование») – дисковый массив из двух или более жёстких дисков с отсутствием резервирования. Информация разбивается на блоки данных ( 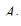 ) и записывается на оба/несколько дисков одновременно.
) и записывается на оба/несколько дисков одновременно.
(+): За счёт этого существенно повышается производительность (от количества дисков зависит кратность увеличения производительности).
(−): Страдает надёжность всего массива (при выходе из строя любого из входящих в RAID 0 винчестеров вся содержащаяся на них информация становится недоступной).
Надёжность массива RAID 0 заведомо ниже надёжности любого из дисков в отдельности. Вероятность отказа такой системы из двух дисков примерно равна удвоенной вероятности отказа одного из дисков, т. к. отказ любого из дисков приводит к неработоспособности всего массива, и растёт с увеличением количества входящих в RAID 0 дисков.
RAID 1 (mirroring – «зеркалирование»). Минимальное количество, для построения «зеркального» RAID 1 – два диска.
(+): Обеспечивает приемлемую скорость записи и выигрыш по скорости чтения при распараллеливании запросов.
(+): Имеет высокую надёжность – работает до тех пор, пока функционирует хотя бы один диск в массиве. Вероятность выхода из строя сразу двух дисков равна произведению вероятностей отказа каждого диска (см. Вероятность пересечения событий). На практике при выходе из строя одного из дисков следует срочно принимать меры – вновь восстанавливать избыточность. Для этого с любым уровнем RAID (кроме нулевого) рекомендуют использовать диски горячего резерва. Достоинство такого подхода – поддержание постоянной надёжности.
(–): Недостаток заключается в том, что приходится выплачивать стоимость двух жёстких дисков, получая полезный объем одного жёсткого диска (классический случай, когда массив состоит из двух дисков).
Зеркало на многих дисках – RAID 1+0 или RAID 0+1. Под RAID 1+0 имеют в виду вариант RAID 10, когда два RAID 1 объединяются в RAID 0. Вариант, когда два RAID 0 объединяются в RAID 1 называется RAID 0+1, и "снаружи" представляет собой тот же RAID 10. Достоинства и недостатки такие же, как и у уровня RAID 0. Как и в других случаях, рекомендуется включать в массив диски горячего резерва из расчёта один резервный на пять рабочих.
RAID 2
В массивах такого типа диски делятся на две группы – для данных и для кодов коррекции ошибок, причём если данные хранятся на n дисках, то для хранения кодов коррекции необходимо n-1 дисков. Данные записываются на соответствующие диски так же, как и в RAID 0, они разбиваются на небольшие блоки по числу дисков, предназначенных для хранения информации. Оставшиеся диски хранят коды коррекции ошибок, по которым в случае выхода какого-либо жёсткого диска из строя возможно восстановление информации. Метод Хемминга давно применяется в памяти типа ECC и позволяет на лету исправлять однократные и обнаруживать двукратные ошибки.
(-): Для функционирования RAID 2 нужна структура из почти двойного количества дисков, поэтому такой вид массива не получил распространения.
RAID 3
В массиве RAID 3 из n дисков данные разбиваются на блоки размером 1 байт и распределяются по n-1 дискам. Ещё один диск используется для хранения блоков чётности. В RAID 2 для этой цели применялся n-1 диск, но большая часть информации на контрольных дисках использовалась для коррекции ошибок на лету, в то время как большинство пользователей удовлетворяет простое восстановление информации в случае поломки диска, для чего хватает информации, умещающейся на одном выделенном жёстком диске.
Отличия RAID 3 от RAID 2: невозможность коррекции ошибок на лету и меньшая избыточность.
(+): скорость чтения и записи данных высока;
(+): минимальное количество дисков для создания массива равно трём.
(-): массив этого типа хорош только для однозадачной работы с большими файлами, так как время доступа к отдельному сектору, разбитому по дискам, равно максимальному из интервалов доступа к секторам каждого из дисков. Для блоков малого размера время доступа намного больше времени чтения.
(-): большая нагрузка на контрольный диск, и, как следствие, его надёжность сильно падает по сравнению с дисками, хранящими данные.
RAID 4
RAID 4 похож на RAID 3, но отличается от него тем, что данные разбиваются на блоки, а не на байты. Таким образом, удалось отчасти «победить» проблему низкой скорости передачи данных небольшого объёма. Запись же производится медленно из-за того, что чётность для блока генерируется при записи и записывается на единственный диск. Из систем хранения широкого распространения RAID 4 применяется на устройствах хранения компании NetApp (NetApp FAS), где его недостатки успешно устранены за счёт работы дисков в специальном режиме групповой записи, определяемом используемой на устройствах внутренней файловой системой WAFL.
RAID 5
Основным недостатком уровней RAID от 2-го до 4-го является невозможность производить параллельные операции записи, так как для хранения информации о чётности используется отдельный контрольный диск. RAID 5 не имеет этого недостатка. Блоки данных и контрольные суммы циклически записываются на все диски массива, нет асимметричности конфигурации дисков. Под контрольными суммами подразумевается результат операции XOR (исключающее или). XOR обладает особенностью, которая применяется в RAID 5, которая даёт возможность заменить любой операнд результатом, и применив алгоритм XOR, получить в результате недостающий операнд. Например: A XOR B = C (где A, B, C – три диска рейд-массива), в случае если A откажет, мы можем получить его, поставив на его место C и проведя XOR между C и B: C XOR B = A. Это применимо вне зависимости от количества операндов: A XOR B XOR C XOR D = E. Если отказывает C тогда E встаёт на его место и проведя XOR в результате получаем C: A XOR B XOR E XOR D = C. Этот метод по сути обеспечивает отказоустойчивость 5 версии. Для хранения результата XOR требуется всего 1 диск, размер которого равен размеру любого другого диска в raid.
(+): RAID5 получил широкое распространение, в первую очередь, благодаря своей экономичности. Объем дискового массива RAID5 рассчитывается по формуле 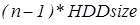 , где n – число дисков в массиве, а HDDsize – размер наименьшего диска. Например, для массива из 4-х дисков по 80 гигабайт общий объем будет (4-1)*80=240 гигабайт. На запись информации на том RAID 5 тратятся дополнительные ресурсы и падает производительность, так как требуются дополнительные вычисления и операции записи, зато при чтении (по сравнению с отдельным винчестером) имеется выигрыш, потому что потоки данных с нескольких дисков массива могут обрабатываться параллельно.
, где n – число дисков в массиве, а HDDsize – размер наименьшего диска. Например, для массива из 4-х дисков по 80 гигабайт общий объем будет (4-1)*80=240 гигабайт. На запись информации на том RAID 5 тратятся дополнительные ресурсы и падает производительность, так как требуются дополнительные вычисления и операции записи, зато при чтении (по сравнению с отдельным винчестером) имеется выигрыш, потому что потоки данных с нескольких дисков массива могут обрабатываться параллельно.
(-): Производительность RAID 5 заметно ниже, в особенности на операциях типа Random Write (записи в произвольном порядке), при которых производительность падает на 10-25% от производительности RAID 1 (или RAID 10), так как требует большего количества операций с дисками (каждая операция записи сервера заменяется на контроллере RAID на три – одну операцию чтения и две операции записи). Недостатки RAID 5 проявляются при выходе из строя одного из дисков – весь том переходит в критический режим (degrade), все операции записи и чтения сопровождаются дополнительными манипуляциями, резко падает производительность. При этом уровень надёжности снижается до надёжности RAID-0 с соответствующим количеством дисков (то есть в n раз ниже надёжности одиночного диска). Если до полного восстановления массива произойдёт выход из строя, или возникнет невосстановимая ошибка чтения хотя бы на ещё одном диске, то массив разрушается, и данные на нем восстановлению обычными методами не подлежат. Следует также принять во внимание, что процесс RAID Reconstruction (восстановления данных RAID за счёт избыточности) после выхода из строя диска вызывает интенсивную нагрузку чтения с дисков на протяжении многих часов непрерывно, что может спровоцировать выход какого-либо из оставшихся дисков из строя в этот наименее защищённый период работы RAID, а также выявить ранее необнаруженные сбои чтения в массивах cold data (данных, к которым не обращаются при обычной работе массива, архивные и малоактивные данные), что повышает риск сбоя при восстановлении данных.
Минимальное количество используемых дисков равно трём.
RAID 6
RAID 6 похож на RAID 5, но имеет более высокую степень надёжности – под контрольные суммы выделяется ёмкость 2-х дисков, рассчитываются 2 суммы по разным алгоритмам. Требует более мощный RAID-контроллер. Обеспечивает работоспособность после одновременного выхода из строя двух дисков – защита от кратного отказа. Для организации массива требуется минимум 4 диска. Обычно использование RAID 6 вызывает примерно 10-15% падение производительности дисковой группы, по сравнению с аналогичными показателями RAID 5, что вызвано большим объёмом обработки для контроллера (необходимость рассчитывать вторую контрольную сумму, а также прочитывать и перезаписывать больше дисковых блоков при записи каждого блока).
RAID 7
RAID 7 не является уровнем RAID, и является зарегистрированной торговой маркой компании Storage Computer Corporation. Структура массива такова: на n−1 дисках хранятся данные, один диск используется для складирования блоков чётности. Запись на диски кэшируется с использованием оперативной памяти, сам массив требует обязательного ИБП; в случае перебоев с питанием происходит повреждение данных.
RAID 10
RAID уровня 10 – набор зеркально отображённых данных (уровень 1), разделённый на полосы в другом наборе дисков (уровень 0), для чего требуется минимум четыре накопителя.
(+): Наследует надёжность от RAID 1, производительность как на чтение, так и на запись от RAID 0
(+): В некоторых случаях RAID 10 может выдержать одновременный отказ нескольких дисков
(+): Отличное решение для сайтов, которые бы в противном случае использовали RAID 1, но для этого потребуются некоторые дополнительные увеличения производительности
RAID 0+1
RAID уровня 0+1 – набор накопителей с разделёнными на полосы данными (уровень 0), зеркально отображённый на другой набор накопителей (уровень 1).
(+): RAID 0+1 имеет такую же отказоустойчивость, как RAID уровня 5
(+): Имеет те же накладные расходы на обеспечение отказоустойчивости что и зеркальное отображение
(+): Высокие показатели ввода / вывода достигаются благодаря нескольким сегментам полосы
(+): Отличное решение для сайтов, которым нужна высокая производительность, но не связаны с достижением максимальной надёжности
Matrix RAID
Принципы работы Matrix RAID достаточно просты. Напомним основы организации классических RAID-массивов: мы оперируем целыми жёсткими дисками как таковыми. Из этих двух организуем RAID уровня 0, из тех трех-четырёх – RAID уровня 5. Все операции по организации и управлению массивами реализуются на аппаратном уровне с помощью BIOS системной платы или выделенного RAID-контроллера – без вмешательства операционной системы.
Очень важно, что Matrix RAID, в отличие от привычных методов организации массивов хранения данных, не является программно-независимым. Matrix RAID является, скорее, не аппаратной, а программно-аппаратной технологией. Причина тому – использование не только контроллера-концентратора ввода-вывода ICH 6 R, но и утилиты Intel Application Accelerator версии 4.х, являющейся на самом деле «сборной солянкой» из драйвера и управляющего ПО, с помощью которого и производится разбивка физических жёстких дисков на тома, определение их ролей и т. д.
Организация такого «псевдо»-RAID массива при помощи Intel Application Accelerator выглядит несложно – пользователь создаёт первый том необходимого размера, определяя и его роль – то есть в каком режиме (0 или 1) он будет функционировать. Оставшееся свободное место выделяется под второй том, также с возможностью выбора режима функционирования. После завершения этих нехитрых процедур в системе появляется два жёстких диска – на одном встроенном в южный мост контроллере и двух физических накопителях SerialATA мы получаем искомую скорость и стабильность. На данном этапе недостаток состоит в том, что размеры томов фиксированы – пользователь не имеет возможности впоследствии что-либо изменить, поэтому стоит заблаговременно определить необходимые размеры.
Как уже упоминалось, Intel поддерживает RAID-организацию только для двух дисков, несмотря на то, что южный мост ICH 6 R имеет четыре порта SerialATA 150/RAID. Теоретически можно организовать два Matrix RAID-массива, но они будут независимыми друг относительно друга. Компания Intel особо подчёркивает возможность апгрейда системы до Matrix RAID, для этого требуется к имеющемуся в системе SerialATA-винчестеру добавить второй. В принципе это понятно, однако приятно, что при организации массивов данные не теряются – Intel Application Accelerator способен выполнить необходимые действия в фоновом режиме.
(+): наличие четырёхпортового контроллера SATA RAID, подразумевающего возможность создания Matrix RAID массива;
(+): RAID BIOS ROM – интегрированную в системный BIOS часть, отвечающую за создание, именование и удаление массивов;
(+): Intel RAID Migration Technology – технологию, позволяющую производить апгрейд подсистемы хранения данных до Matrix RAID;
(+): интерфейс SerialATA AHCI с поддержкой NCQ и горячего подключения (Advanced Host Controller Interface, присутствует только в Intel 915/925);
(+): полное программное управление массивами Matrix RAID.
(-): отсутствие возможности динамического изменения объемов томов.
Комбинированные уровни RAID 1+0, RAID 5+0, RAID 1+5
Помимо базовых уровней RAID 0 – RAID 5, описанных в стандарте, существуют комбинированные уровни RAID 1+0, RAID 3+0, RAID 5+0, RAID 1+5, которые различные производители интерпретируют каждый по-своему.
RAID 1+0 – это сочетание зеркалирования и чередования (см. выше).
RAID 5+0 – это чередование томов 5-го уровня.
RAID 1+5 – RAID 5 из зеркалированных пар.
Комбинированные уровни наследуют как преимущества, так и недостатки своих «родителей»: появление чередования в уровне RAID 5+0 нисколько не добавляет ему надёжности, но зато положительно отражается на производительности. Уровень RAID 1+5, наверное, очень надёжный, но не самый быстрый и, к тому же, крайне неэкономичный: полезная ёмкость тома меньше половины суммарной ёмкости дисков.
Стоит отметить, что количество жёстких дисков в комбинированных массивах также изменится. Например для RAID 5+0 используют 6 или 8 жёстких дисков, для RAID 1+0 – 4, 6 или 8.
Дата: 2019-02-02, просмотров: 545.