Организация ЭВМ и систем
Никольский Александр Николаевич
Основные понятия структуры и архитектуры ЭВМ. Понятия
Основные характеристики ЭВМ
Быстродействие – это число команд, выполняемых ЭВМ за 1 секунду. Быстродействие измеряется во флопсах (FLOPS - Floating point Operation Per Second). В системе СИ используются: килофлопс KFLOPS, мегафлопс MFLOPS, гигафлопс GFLOPS, терафлопс TFLOPS, петафлопс - PFLOPS, эксафлопс - EFLOPS.
Величина FLOPS используется для определения быстродействия современных ЭВМ в программе LINPACK. LINPACK – это библиотека, написанная на языке FORTRAN, которая содержит набор подпрограмм для решения СЛАУ.
Для тестирования современных ЭВМ применяются другие библиотеки – Lapack, Linpack benchmark и т.д.
Сравнения по быстродействию различных типов ЭВМ не обеспечивают достоверных оценок, поэтому вместо характеристики быстродействия используют связанную с ней характеристику "производительность".
Производительность – это объём работ, осуществляемых ЭВМ в единицу времени. Производительность зависит от большого числа факторов:
· Скорости выполнения элементарных операций
· Скорости обмена информации по каналам
· Структуры памяти
· Характеристик периферийных устройств
· Структуры и настроек ОС и приоритетов
· Характеристик алгоритмов и выбранных дисциплин обслуживания и т.д.
Ёмкость запоминающих устройств.
Ёмкость памяти измеряется количеством структурных единиц информации, которые могут одновременно находиться в памяти. Этот показатель позволяет определить, какой набор программ и данных может быть одновременно размещён в памяти.
Ёмкость памяти измеряется в байтах, килобайтах (КБ), мегабайтах (МБ), гигабайтах (ГБ), терабайтах (ТБ).
Ёмкость ОЗУ и ёмкость ВЗУ характеризуется отдельно для определения, какие ПП и их приложения могут одновременно обрабатываться в машине.
Надёжность – это способность ЭВМ при определённых условиях выполнять требуемые функции в течение заданного периода времени. На это существует международный стандарт ISO 2382/14-78. Высокая надёжность ЭВМ закладывается в процессе её проектирования и производства. Применение СБИС резко сокращают число используемых интегральных схем, а значит и число их соединений друг с другом.
Модульный принцип построения позволяет легко проверять и контролировать работу всех устройств, проводить диагностику и устранение неисправностей.
Точность – это возможность различать почти равные значения. Для этого существует ещё один международный стандарт ISO 2382/2-76. Точность получения результатов обработки в основном определяется разрядностью ЭВМ, а также используемыми структурными единицами представления информации (байтом, словом, двойным словом)
Достоверность – это свойство информации быть правильно воспринятой. Достоверность характеризуется вероятностью получения безошибочных результатов. Заданный уровень достоверности обеспечивается аппаратно-программными средствами контроля самой ЭВМ. Возможные методы контроля достоверности путём решения эталонных задач и повторных расчётов. В особо ответственных случаях проводятся контрольные решения на других ЭВМ и сравнения результатов.
Классификация ЭВТ
В настоящее время выпускается в основном три класса ЭВМ:
1. Большие ЭВМ, которые представляют собой многопользовательские машины с центральной обработкой, с большими возможностями для работы с базами данных, с различными формами удалённого доступа.
2. Средние ЭВМ, предназначенные в первую очередь для работы в финансовых структурах. В этих машинах особое внимание уделяется сохранению и безопасности данных, программной совместимости и т.д. Также они могут использоваться в качестве серверов в локальных сетях.
3. Персональные ЭВМ.
Кроме перечисленных классов ЭВТ необходимо отметить ВС под названием Супер-ЭВМ. Особенно эффективно использовать Супер-ЭВМ при решении задач проектирования, в которых натуральные эксперименты оказываются дорогостоящими, недоступными или практически неосуществимыми. В этом случае ЭВМ позволяет методами численного моделирования получить результаты экспериментов, обеспечивая приемлемое время и точность решения (задача моделирования климата, разработка нефтяных месторождений, расчёт галактик, разработка новых лекарств).
Дальнейшее развитие Супер-ЭВМ связывается с использованием массового параллелизма, при котором одновременно могут работать сотни и десятки тысяч процессоров.
Также необходимо отметить ещё один класс массовых средств ЭВТ – встраиваемые микропроцессоры. Успехи микроэлектроники позволяют создавать миниатюрные вычислительные устройства вплоть до однокристальных ЭВМ. Эти устройства, универсальные по характеру применения, могут встраиваться в отдельные машины, объекты и системы.
Таким образом можно предложить следующую классификацию ЭВТ, в основу которой положено их разделение по быстродействию:
1. Супер-ЭВМ (мейнфрейм) – для решения крупномасштабных вычислительных задач, для обслуживания крупнейших информационных банков данных.
2. Большие ЭВМ – для территориальных и региональных вычислительных центров и работы с БД.
3. Средние ЭВМ широкого назначения – для управления сложными технологическими производственными процессами, а также для управления распределённой обработкой информации (модель клиент-сервер в качестве сетевых серверов)
4. Персональные и профессиональные ЭВМ позволяющие удовлетворять индивидуальные потребности пользователей. На базе этого класса ЭВМ строятся АРМ'ы (автоматизированное рабочее место) для специалистов различного уровня.
5. Встраиваемые микропроцессоры, осуществляющие автоматизацию управления отдельными устройствами и механизмами.
Высокие скорости вычислений ЭВМ различных классов позволяют перерабатывать и выдавать всё большее количество информации, что в свою очередь порождает потребности в создании связей между отдельными ЭВМ.
Поэтому все современные ЭВМ в настоящее время имеют средства подключения к сетям связи и комплексирования в системы.
Поколения ЭВМ
Современная история ЭВТ отсчитывается с опубликования работы Джона фон Неймана в 1945 году. Впервые возможность построения цифровой ВМ была доказана английским математиком Аланом Тьюрингом в 1936 году. Он показал, что любой алгоритм реализуется с помощью его дискретного автомата, который был назван "машиной Тьюринга". Независимо от него то же самое доказал Пост ("машина Поста").
Первые машины были сконструированы Конродом Сузе (Z1, Z2, Z3, Z4). Попытка построения универсальной ЭВМ была предпринята США при постройке машины Марк-1 в Гарвардском университете.
Характеристики Марк-1:
1. Работала с 23-х разрядными десятичными цифрами.
2. Программа вводилась покомандно с перфоленты.
3. Сложение двух чисел - 0,3 секунды.
4. Умножение двух чисел - 6 секунд.
5. Деление двух чисел - 11 секунд.
Релейная база этой машины была ненадёжна. Для увеличения её надёжности были разработаны специальные реле, на которых была построена ЭВМ Марк-2.
Реальный отсчёт ЭВТ ведётся с момента перехода от реле к триггерам (Триггер был изобретён в СССР Бончем Бреувичем в 1918 году в Нижнем Новгороде).
Первая ЭВМ, разработанная на базе электронных компонентов, была построена в 1942 году, назвалась ENIAC. Разработана в Пенсильванском университете под руководством Моушли и Эккера.
В 1943 году под руководством Тьюринга в Англии была построена ЭВМ Колосс.
Первое поколение ЭВМ – элементная база ЛАМПЫ – 1950 год.
В СССР началом выпуска серийных ЭВМ считают выпуск МЭСМ, которая разработана под руководством Лебедева. В 1952-1953 году под руководством Мельникова и Бурцева была разработана БЭСМ-1 и на её основе выпускалась серийная машина БЭСМ-2, в которой использовались 2 новых принципа – стек и конвейеризация. Быстродействие АЛУ достигало 10000 операций в секунду.
В 1953 году была разработана машина Стрела под руководством Василевского. Также в Московском Энергетическом Институте под руководством академика Исаака Семёновича Брука была разработана ЭВМ под названием М-1. в это же время в Минске был создан завод по производству ЭВМ под названием Минск.
В Пензе было создано КБ под руководством академика Рамеева, где разработали и серийно выпускали ЭВМ Урал.
Также в это же время в США выпускают ЭВМ EDVAC и другие машины. Структура ЭВМ первого поколения полностью соответствовала машине фон Неймана и их технические характеристики были значительно ниже характеристик современных ПК.
Второе поколение ЭВМ – элементная база ТРАНЗИСТОРЫ – начало 1960-х.
Транзисторы позволили обеспечить большую надёжность, быстродействие, меньшее энергопотребление (наработка на отказ – 100 часов), переход к печатному монтажу. В это же время начинается бурное развитие математического и программного обеспечения. Создаются языки ALGOL и FORTRAN. Создаются простейшие компиляторы и интерпретаторы. Работа пользователя у пульта управления становится нецелесообразной. Основным режимом становится работа через операторов.
Применяется многопрограммное ЭВМ. Для работы в пакетном режиме создаются первые мониторы. Вследствие чего происходит резкое увеличение использования ЭВМ второго поколения.
Третье поколение ЭВМ - элементная база ИНТЕГРАЛЬНЫЕ МИКРОСХЕМЫ – начало 1970-х
В данном поколении ЭВМ произошли некоторые архитектурные изменения и увеличение надёжности. В машинах третьего поколения формируется концепция канала, начинается работа с распараллеливанием процессора. Появляется микропрограммное управление, иерархируется память и впервые вводится понятие агрегатирования.
Каналы делились на мультиплексные (для подключения медленных устройств) и селекторные (высокоскоростные устройства). В данной архитектуре канал является основным структурным элементом и фактически представлял собой процессор управления.
В структуре процессора и ОП появляются специальные устройства, которые организуют адресные механизмы, обеспечивающие адресацию, перемещение программы в памяти, взаимную защиту. В процессорах появляется несколько АЛУ (целочисленные, плавающие, для работы с адресами). Эти АЛУ параллельно не работают, но для выполнения той или иной обработки выбирается определённое АЛУ.
В памяти чётко выделяется основная память, к которой процессор обращается непосредственно, и массовая память, ёмкость которой значительно больше основной памяти, но непосредственно процессору она недоступна, также как и данные с ВЗУ.
Так как память иерархична, то создаются механизмы для управления памятью. Появляется концепция управления виртуальной памятью, развиваются внешние устройства.
Самое главное в ЭВМ 3 поколения – что ЭВМ начинают выпускаться сериями, или семействами, или совместимыми моделями.
Дальнейшее развитие математического и ПО приводит к созданию пакетных программ для решения типовых задач, проблемно-ориентированных программных языков. Впервые создаются универсальные программные комплексы - операционная система.
Четвёртое поколение ЭВМ
В четвёртом поколении ЭВМ (середина 70-х-80-х годов) характерно применение БИС и СБИС, более тесной становится связь структуры ЭВМ и её ПО, особенно ОС. Отчётливо проявляется тенденция к унификации ЭВМ, созданию машин, представляющих собой единую систему: ЕС-ЭВМ-1010, 1015, 1020, 1030, …, 1052. Аналог машин IBM 360/370.
Режим разделения времени
Является более развитой формой многопрограммной работы ЭВМ. В этом режиме, обычно совмещённым с фоновым режимом классического мультипрограммирования, отдельные приоритетные программы пользователей выделяются в одну или несколько групп. Для каждой такой группы устанавливается круговое циклическое обслуживание, при котором каждая программа группы периодически получает для обслуживания достаточно короткий интервал времени - время кванта.
Это создаёт у пользователя впечатление кажущейся одновременности их программ. Для реализации режима разделения времени необходимо, чтобы ЭВМ имела в своём составе развитую систему измерения времени – интервальный таймер, таймер процессора, электронные часы и т.д. Это позволяет формировать группы программ с постоянным или переменным квантом времени. Разделение времени находит широкое применение при обслуживании ЭВМ сети абонентских пунктов.
Режим реального времени
Это более сложный режим со своими специфическими особенностями:
1. Поток заявок от абонентов носит случайный, непредсказуемый характер.
2. Потери поступающих на вход ЭВМ заявок и данных не допускаются, поскольку их не всегда можно восстановить.
3. Время реакции ЭВМ на внешние воздействия, а также время выдачи результатов i-той задачи должны находиться в жёстких рамках.
Специфические особенности режима реального времени требуют наиболее сложных ОС. Именно на базе этого режима строятся так называемые диалоговые системы, обеспечивающие одновременную работу нескольких пользователей с ЭВМ.
Диалоговые системы могут иметь различное содержание: системы, обслуживающие наборы данных, системы разработки документов, программ, схем, чертежей, системы выполнения программ в комплексе "человек-машина".
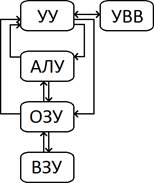
Модель УУ.
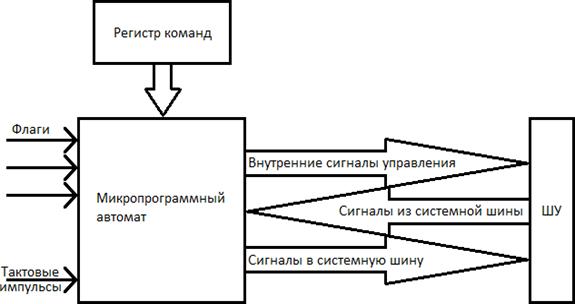
Для выполнения своих функций УУ должно иметь входы, позволяющие определить состояние управляемой системы, и выходы, через которые реализуется управление поведением системы.
Входной информацией служат тактовые импульсы – с каждым тактовым импульсом УУ инициирует выполнение одной или нескольких микроопераций. Код операции текущей команды поступает из регистра команды и используется, чтобы определить, какие микрооперации должны выполняться в течение машинного цикла. Флаги требуются УУ для оценки состояния ЦП и результата предшествующей операции, что необходимо при выполнении команд условного перехода. Сигналы из системной шины – это часть сигналов системной шины, обеспечивающая передачу в УУ запросов прерывания, подтверждений и т.п.
В свою очередь УУ, а точнее микропрограммный автомат, формирует следующую выходную информацию. Внутренние сигналы управления воздействуют на внутренние схемы МП и относятся к одному из двух типов: тем, которые вызывают перемещение данных из регистра в регистр, и тем, что инициируют определённые функции операционного устройства ЭВМ.
Сигналы в системную шину также относятся к одному из двух типов: управляющие сигналы в память и управляющие сигналы в модули ввода-вывода.
Структура УУ.
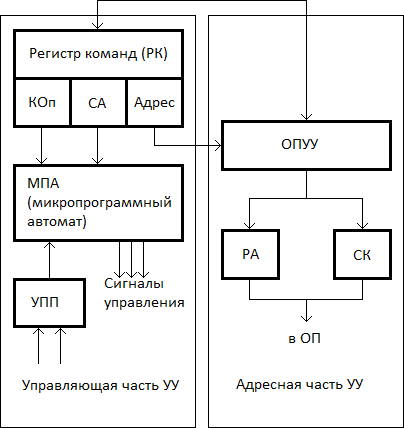
Процесс функционирования ЭВМ состоит из последовательности элементарных действий в её узлах. Такие элементарные преобразования информации, выполняемые в течение одного такта сигналов синхронизации, называются микрооперациями (МО).
Совокупность сигналов управления, вызывающих одновременно выполняемые микрооперации образуют микрокоманды (МК). В свою очередь, последовательность микрокоманд, определяющую содержание и порядок реализации машинного цикла принято называть микропрограммой.
Сигналы управления вырабатываются УУ, а точнее одним из его узлов – микропрограммным автоматом (МПА). Название отражает то, что МПА определяет микропрограмму как последовательность выполнения микроопераций.
Микропрограммы реализации перечисленных ранее целевых функций инициируются задающим оборудованием, которое вырабатывает требуемую последовательность сигналов управления и входит в состав управляющей части УУ.
Микропрограммы выполняются исполнительным оборудованием, входящим в состав основной памяти для ЦФ-ВК и ЦФ-ВО и операционного устройства для ЦФ-ИО. Исполнительным оборудованием для ЦФ-ФИА служит адресная часть УУ.
Управляющая часть УУ предназначена для координирования работы операционного блока ЭВМ, адресной части УУ, основной памяти и других узлов ЭВМ.
Адресная часть УУ обеспечивает формирование адресов команд и исполнительных адресов операндов в основной памяти.
В состав управляющей части УУ входит:
1. Регистр команды (РК), состоящий из адресной (АДРЕС) и операционной части (КОп – код операции, СА – способ адресации)
2. Микропрограммный автомат (МПА)
3. Узел Прерываний и Приоритетов (УПП)
Регистр команды (РК) предназначен для приёма очередной команды из запоминающего устройства. МПА на основании расшифровки операционной части команды (КОп) СА вырабатывает определённую последовательность микрокоманд, вызывающих выполнение всех целевых функций УУ.
В зависимости от способа формирования микрокоманд различают следующие МПА:
1. С жёсткой или аппаратной логикой
2. С программируемой логикой
Узел прерываний и приоритетов позволяет реагировать на различные ситуации, связанные как с выполнением рабочих программ, так и состоянием ЭВМ.
Адресная часть УУ включает в себя:
1. ОПУУ - Операционный Узел Устройства Управления
2. РА - Регистр Адреса
3. СК - Счётчик Команд
Регистр адреса используется для хранения исполнительных адресов операндов, а счётчик команд - для выработки и хранения адресов команд. Содержимое РА и СК посылается в регистр адреса основной памяти для выборки операндов и команд соответственно.
Операционный узел УУ, называемый иначе узлом индексной арифметики или узлом адресной арифметики обрабатывает адресные части команд, формируя исполнительные адреса операндов, а также подготавливает адрес следующей команды при выполнении команд перехода.
Состав ОПУУ может быть аналогичен составу основного операционного устройства ЭВМ (простейших ЭВМ с целью экономии совмещается с основным операционным устройством).
В состав УУ также входит могут входить дополнительные узлы в частности узел организации прямого доступа к памяти. Обычно этот узел реализуется в виде самостоятельного устройства – контроллера прямого доступа к памяти, который обеспечивает совмещение во времени работы операционного устройства с процессом обмена информацией между ОП и другими устройствами ЭВМ, минуя процессор.
Довольно часто регистры различных узлов УУ объединяют в отдельный узел управляющих (специальных) регистров УУ (регистр флагов, регистр-защёлка, регистр команд и т.п.)
Рассмотрим подробно работу МПА с жёсткой и программируемой логикой.
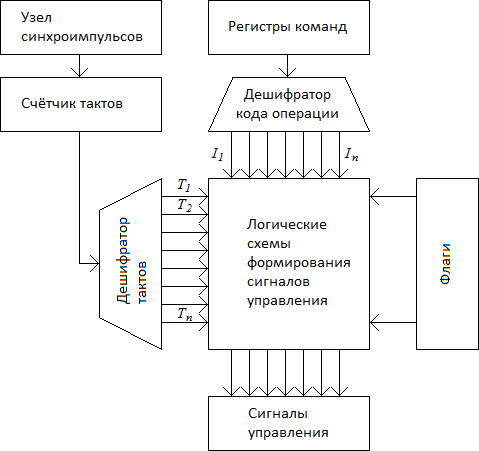
Обычно тип МПА, формирующего сигналы управления, определяет название всего УУ. Так УУ с жёсткой логикой управления имеет в своём составе МПА с жёсткой (аппаратной) логикой. При создании такого МПА выходные сигналы управления реализуются за счёт однажды соединённых между собой логических схем.
Исходной информацией для УУ служат: содержимое регистров команды, флаги, тактовые импульсы и сигналы, поступающие с шины управления.
Код операции, хранящийся в РК, используется для определения того, какие сигналы управления (СУ) и в какой последовательности должны формироваться, при этом с целью упрощения логики управления желательно иметь в УУ отдельный логический сигнал для каждого кода операции (I0, I1, …, Ik). Это может быть реализовано с помощью дешифратора.
Дешифратор кода операции преобразует код с J-ой операцией, поступающий из регистра команды РК в единичный сигнал на J-том выходе.
Машинный цикл выполнения любой команды состоит из нескольких тактов. Сигналы управления, по которым выполняется каждая микрооперация, должны вырабатываться строго в определённые моменты времени, поэтому все СУ "привязаны" к импульсам синхронизации (СИ), формируемым узлом синхроимпульсов. Период СИ должен быть достаточным для того, чтобы сигналы успели распространиться по ШД и другим цепям.
Каждый сигнал управления ассоциируется с одним из тактовых периодов в рамках машинного цикла. Формирование сигналов, отмечающих начало очередного тактового периода, возлагается на синхронизатор. Синхронизатор содержит счётчик тактов, осуществляющих подсчёт СИ.
Узел синхроимпульсов после завершения очередного такта работы добавляет к содержимому счётчика тактов единицу. К выходам счётчика подключён дешифратор тактов, с которого и снимаются сигналы тактовых периодов T1, T2, …, Tn.
В i-ом состоянии счётчика тактов, т.е. во время I-ого такта дешифратор тактов вырабатывает единичный сигнал на своём I-ом выходе. При такой организации УУ должна быть предусмотрена обратная связь, с помощью которой по окончании цикла команды счётчик тактов опять устанавливается в состояние T1.
Микропрограммный автомат
Способы адресации
Вопрос о том, каким образом в адресном поле команды может быть указано местоположение операндов считается одним из центральных при изучении организации ЭВМ. С точки зрения сокращения аппаратурных затрат очевидно стремление разработчиков уменьшить длину адресного поля при сохранении возможностей доступа ко всему адресному пространству. С другой стороны, способ задания адресов должен способствовать максимальному сближению конструкторов языков программирования высокого уровня и машинных команд. Всё это привело к тому, что в архитектуре системы команд любой ВМ предусмотрены различные способы адресации операндов.
Рассмотрим следующие понятия:
1. Исполнительный адрес операнда (A_исп) – это двоичный код номера ячейки памяти, служащий источником или приёмником операнда. Этот код подаётся на адресные входы ЗУ и по нему происходит фактическое обращение к указанной ячейке. Если операнд хранится не в ЗУ, а в регистре ЦП, его исполнительным адресом будет номер регистра.
2. Адресный код команды (АК) – это двоичный код в адресном поле команды, из которого необходимо сформировать исполнительный адрес операнда.
В современных ЭВМ исполнительный адрес и адресный код, как правило, не совпадают, и для доступа к данным требуется соответствующее преобразование.
Способ адресации – это способ формирования исполнительного адреса операнда по адресному полю команды. Способ адресации существенно влияет на параметры процесса обработки информации. Одни способы позволяют увеличить ёмкость адресуемой памяти без удлинения команды, но снижают скорость выполнения операции, другие ускоряют операции над массивами данных, третьи упрощают работу с подпрограммами и т.д.
В современных ЭВМ имеется возможность приложения нескольких различных способов адресации операндов к одной и той же операции. Чтобы УУ ВМ могло определить какой именно способ адресации принят в данной команде, в разных ВМ используются различные приёмы.
Часто разным способам адресации соответствуют и разные коды операции. Другой подход – это добавление в состав команды специального поля способа адресации, содержимое которого определяет, какой из способов адресации должен быть применён. Иногда в команде имеется несколько полей, по одному на каждый адрес.
Также возможен вариант, когда в команде вообще отсутствует адресная информация, т.е. имеет место неявная адресация.
При неявной адресации адресного поля либо просто нет, либо оно содержит не все необходимые адреса – отсутствующий адрес подразумевается кодом операции. Неявная адресация применяется достаточно широко, поскольку позволяет сократить длину команды.
Выбор способов адресации является одним из важнейших вопросов разработки системы команд и всей ВМ в целом, при этом существенное значение имеет не только удобство программирования, но и эффективность способа.
В настоящее время используются различные виды адресации, наиболее распространённые из которых мы и рассмотрим.
Способ: прямая адресация
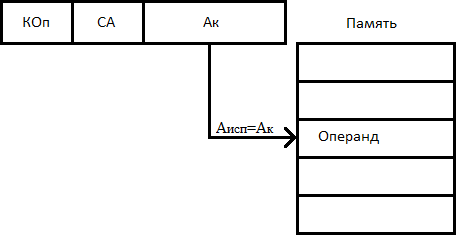
При прямой, или абсолютной адресации адресный код прямо указывает номер ячейки памяти, к которой производится обращение, то есть адресный код совпадает с исполнительным адресом. При всей простоте использования способ имеет существенный недостаток – ограниченный размер адресного пространства, т.к. для адресации к памяти большой ёмкости нужно "длинное" адресное поле. Однако самым существенным недостатком можно считать то, что адрес, указанный в команде, не может быть изменён в процессе вычислений (во всяком случае, такое изменение не рекомендуется). Это ограничивает возможности по произвольному размещению программы в памяти.
Способ: косвенная адресация
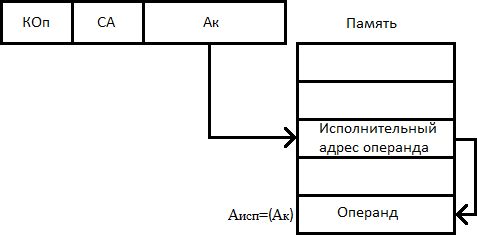
Одним из путей преодоления проблем, свойственных прямой адресации, может служить прием, когда с помощью ограниченного адресного поля команды указывается адрес ячейки, в свою очередь, содержащей полноразрядный адрес операнда. Этот способ известен как косвенная адресация. Запись 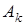 означает содержимое ячейки, адрес которой указан в скобках.
означает содержимое ячейки, адрес которой указан в скобках.
При косвенной адресации содержимое адресного поля команды остается неизменным, в то время как косвенный адрес в процессе выполнения программы можно изменять. Это позволяет проводить вычисления, когда адреса операндов заранее неизвестны и появляются лишь в процессе решения задачи. Дополнительно такой прием упрощает обработку массивов и списков, а также передачу параметров подпрограммам.
Недостатком косвенной адресации является необходимость в двукратном обращении к памяти: сначала для извлечения адреса операнда, а затем для обращения к операнду. Сверх того задействуется лишняя ячейка памяти для хранения исполнительного адреса операнда.
В качестве варианта косвенной адресации, правда, достаточно редко используемого, можно упомянуть многоуровневую или каскадную косвенную адресацию
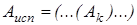
когда к исполнительному адресу ведёт цепочка косвенных адресов. В этом случае один из битов в каждом адресе служит признаком косвенной адресации. Состояние бита указывает, является ли содержимое ячейки очередным адресом в цепочке адресов или это уже исполнительный адрес операнда. Особых преимуществ у такого подхода нет, но в некоторых специфических ситуациях он оказывается весьма удобным, например при обработке многомерных массивов. В то же время очевиден и его недостаток – для доступа к операнду требуется три и более обращений к памяти.
Способ: индексная адресация
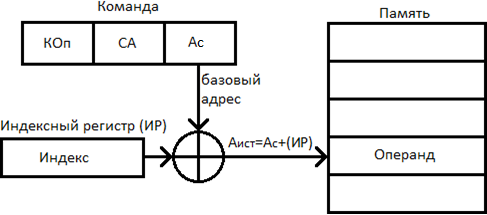
При индексной адресации (ИА) подполе 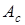 содержит адрес ячейки памяти, а регистр (указанный явно или неявно) – смещение относительно этого адреса. Как видно, этот способ адресации похож на базовую регистровую адресацию. Поскольку при индексной адресации в поле
содержит адрес ячейки памяти, а регистр (указанный явно или неявно) – смещение относительно этого адреса. Как видно, этот способ адресации похож на базовую регистровую адресацию. Поскольку при индексной адресации в поле 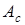 находится полноразрядный адрес ячейки памяти, играющий роль базы, длина этого поля больше, чем при базовой регистровой адресации. Тем не менее, вычисление исполнительного адреса операнда производится идентично.
находится полноразрядный адрес ячейки памяти, играющий роль базы, длина этого поля больше, чем при базовой регистровой адресации. Тем не менее, вычисление исполнительного адреса операнда производится идентично.
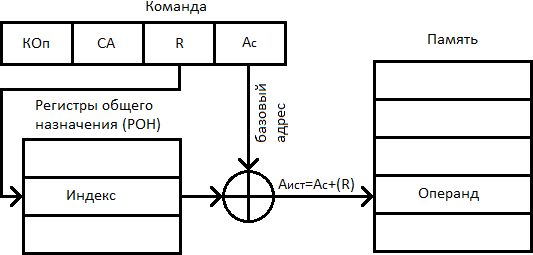
Индексная адресация предоставляет удобный механизм для организации итеративных вычислений. Пусть, например, имеется массив чисел, расположенных в памяти последовательно, начиная с адреса 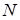 , и мы хотим увеличить на единицу все элементы данного массива. Для этого требуется извлечь каждое число из памяти, прибавить к нему 1 и вернуть обратно, а последовательность исполнительных адресов будет следующей:
, и мы хотим увеличить на единицу все элементы данного массива. Для этого требуется извлечь каждое число из памяти, прибавить к нему 1 и вернуть обратно, а последовательность исполнительных адресов будет следующей:
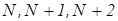
и т. д., вплоть до последней ячейки, занимаемой рассматриваемым массивом. Значение  берется из подполя команды, а в выбранный регистр, называемый индексным регистром, сначала заносится 0. После каждой операции содержимое индексного регистра увеличивается на 1.
берется из подполя команды, а в выбранный регистр, называемый индексным регистром, сначала заносится 0. После каждой операции содержимое индексного регистра увеличивается на 1.
Так как это стандартный случай, в большинстве ЭВМ увеличение или уменьшение содержимого индексного регистра до или после обращения к нему осуществляется автоматически как часть машинного цикла. Такой прием называется автоиндексированием. Если для индексной адресации используются специально выделенные регистры, автоиндексирование может производиться неявно и автоматически. При задействовании для хранения индексов регистров общего назначения необходимость операции автоиндексирования должна указываться в команде специальным битом.
Автоиндексирование с увеличением содержимого индексного регистра носит название автоинкрементной адресации и может быть описано следующим образом:
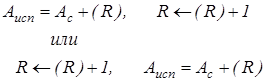
В первом варианте увеличение содержимого индексного регистра происходит после формирования исполнительного адреса, и этот способ называется постинкрементным автоиндексированием. Во втором случае сначала производится увеличение содержимого индексного регистра, и уже новое значение используется для формирования исполнительного адреса. Тогда говорят о преинкрементном автоиндексировании. Автоиндексирование с уменьшением содержимого индексного регистра носит название автодекрементной адресации и может быть описано так:
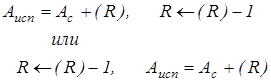
Здесь также возможны два варианта, отличающиеся последовательностью выполнения операций уменьшения содержимого индексного регистра и вычисления исполнительного адреса: постдекрементное автоиндексирование и предекрементное автоиндексирование. Интересным и весьма полезным является еще один вариант индексной адресации – индексная адресация с масштабированием и смещением: содержимое индексного регистра умножается на масштабный коэффициент и суммируется с  . Масштабный коэффициент может принимать значения: 1, 2, 4, 8, для чего в адресной части команды выделяется дополнительное поле. Описанный способ адресации реализован, например, в микропроцессорах фирмы Intel. Следует особо отметить, что система команд многих ВМ предоставляет возможность различным образом сочетать базовую и индексную адресации в качестве дополнительных способов адресации.
. Масштабный коэффициент может принимать значения: 1, 2, 4, 8, для чего в адресной части команды выделяется дополнительное поле. Описанный способ адресации реализован, например, в микропроцессорах фирмы Intel. Следует особо отметить, что система команд многих ВМ предоставляет возможность различным образом сочетать базовую и индексную адресации в качестве дополнительных способов адресации.
Способ: страничная адресация (СТА)
Страничная адресация предполагает разбиение адресного пространства на страницы. Страница определяется своим начальным адресом, выступающим в качестве базы. Старшая часть этого адреса хранится в специальном регистре – регистре адреса страницы (РАС). В адресном коде команды указывается смещение внутри страницы, рассматриваемое как младшая часть исполнительного адреса. Исполнительный адрес образуется конкатенацией (присоединением)  к РАС.
к РАС.
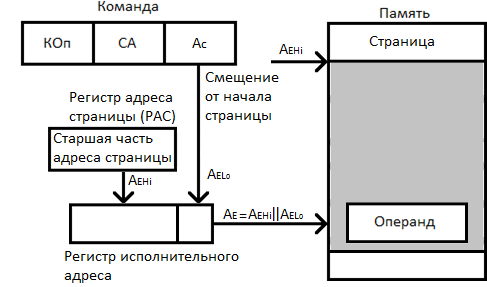
Способ: блочная адресация
Блочная адресация используется в командах, для которых единицей обработки служит блок данных, расположенных в последовательных ячейках памяти. Этот способ очень удобен при работе с внешними запоминающими устройствами и в операциях с векторами. Для описания блока обычно берётся адрес ячейки, где хранится первый или последний элемент блока и общее количество элементов блока, заданное числом байтов или ячеек. Вместо длины блока может использоваться специальный признак «конец блока», помещаемый за последним элементом блока.
Способ: стековая адресация
Во всех современных процессорах аппаратно поддерживается стек, т.е. область оперативной памяти, предназначенная для временного хранения любой операции. Рассмотрим безадресное кодирование команд при стековой организации памяти.
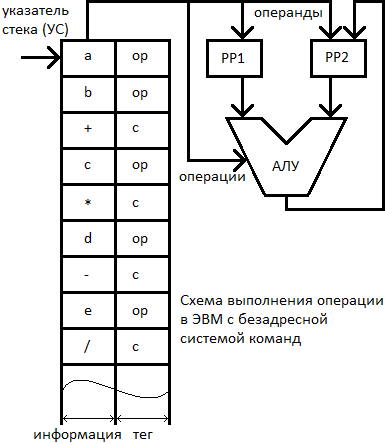
Обращение к ячейкам такой памяти производится последовательно с помощью специального указателя стека (УС), определяющего работающую в данный момент ячейку. Каждая ячейка снабжена тегом – специальным признаком хранимой информации. В состав такой ЭВМ, помимо АЛУ, входят два специальных регистра РР1 и РР2. Здесь значения тегов следующие: ОР (OPerand) – в данной ячейке хранится операнд; С (Command) – признак кода операции.
Рассмотрим работу такой ЭВМ на примере выражения:
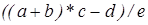
На первых двух тактах работы из памяти извлекаются операнды a и b и помещаются в рабочие регистры РР1 и РР2. Считав следующую ячейку стековой памяти, УУ по её тегу определяет, что данная информация представляет собой код операции. Этот код отправляется в АЛУ, где и проводится сложение хранящихся в регистре операндов с записью результата в один из рабочих регистров. Т.к. в следующей ячейке хранится операнд, то он направляется в РР, свободный от записанного результата. После этого производится выполнение следующей операции и т.д.
Для стека характерны две операции:
· PUSH – протолкнуть (поместить элемент в стек);
· POP – вытолкнуть (извлечь элемент из стека).
При этом поддерживается известная процедура «Last In – First Out» (LIFO).
Приоритеты прерываний
Программы, выполнявшиеся до появления запросов прерывания, называют прерываемыми программами. Программы, затребованные запросами прерывания – прерывающими программами.
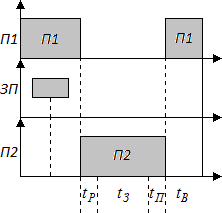
На рисунке приведена временная диаграмма прерывания текущей программы 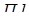 . При поступлении запроса прерывания (
. При поступлении запроса прерывания ( 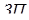 ) процессор переходит к прерывающей программе
) процессор переходит к прерывающей программе 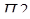 не сразу, так как требуется время на анализ системы на запрос прерывания. После перехода к прерывающей программе
не сразу, так как требуется время на анализ системы на запрос прерывания. После перехода к прерывающей программе 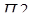 в течение происходит запоминание состояния прерванной программы , а затем в течение исполняется прерывающая программа
в течение происходит запоминание состояния прерванной программы , а затем в течение исполняется прерывающая программа  . Сразу после ее окончания в течение восстанавливается состояние прерванной программы и ей передается управление. Сумма времени, затрачиваемого на запоминание состояния прерванной программы и на возврат к ней, называют временем обслуживания программы. Время реакции и обслуживания характеризуют потери машинного времени на организацию процесса прерывания и быстродействия ЭВМ по обслуживанию запросов прерывания.
. Сразу после ее окончания в течение восстанавливается состояние прерванной программы и ей передается управление. Сумма времени, затрачиваемого на запоминание состояния прерванной программы и на возврат к ней, называют временем обслуживания программы. Время реакции и обслуживания характеризуют потери машинного времени на организацию процесса прерывания и быстродействия ЭВМ по обслуживанию запросов прерывания.
Максимальное количество программ, прерывающих друг друга вновь возникающими запросами, называют глубиной прерывания. Степень важности запросов на прерывание зависит от времени их поступления в систему прерывания программ и характера источников запросов. Поэтому каждому источнику запросов на прерывания присваивается постоянный, как правило, уровень приоритетности, или глубина прерывании. Наивысшим приоритетом (нулевой уровень) прерывания обладают прерывания от схем контроля ЭВМ. Прерывания нулевого уровня могут прервать любую из программ, отвечающих, уровням при выделении уровней.
Первый уровень присваивается прерываниям от устройств ввода-вывода. Второй уровень – внешние прерывания ("закончилась бумага в принтере"). Третий уровень – программные прерывания и прерывания при обращении к управляющей программе – диспетчеру. Эти два класса прерываний исключают взаимно друг друга и поэтому имеют одинаковый приоритет.
Прерывания первого уровня могут прервать любую из программ второго и третьего уровней приоритетности, но не могут прервать программу с нулевым уровнем приоритетности.
Определение исполнения программ в системе с учётом приоритетности запросов прерывания:
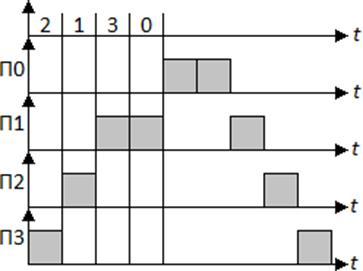
На рисунке показано обслуживание запросов  с учётом их приоритетности. В связи с введением приоритетов время реакции
с учётом их приоритетности. В связи с введением приоритетов время реакции  на отдельные запросы увеличивается.
на отдельные запросы увеличивается.
Защита от прерывания. Время реакции процессора на запрос прерывания
Время реакции – это время между появлением сигнала запроса прерывания и началом выполнения прерывающей программы (обработчика прерывания) в том случае, если данное прерывание разрешено к обслуживанию. Время реакции зависит от момента, когда ЦП определяет факт наличия запроса прерывания.
Существуют два подхода к опросу запросов прерываний. Опрос запросов прерываний может проводиться либо по окончании выполнения очередного этапа команды (например, считывания команды, считывания первого операнда и т.д.), либо после завершения каждой команды программы.
Первый подход обеспечивает более быструю реакцию, но при этом необходимо при переходе к обработчику прерывания сохранить большой объём информации по прерываемой программе, включающий состояние буферных регистров процессора, номера завершившегося этапа и т.д. При возврате из обработчика также необходимо выполнить большой объём работы по восстановлению состояния процессора.
Во втором случае время реакции может быть достаточно большим, однако при переходе к обработчику прерывания требуется запоминание минимального контекста прерываемой программы (обычно это счётчик команд и регистр флагов). В настоящее время в компьютерах чаще используется распознавание запроса прерывания после завершения очередной команды (первый подход). Время реакции определяется для запроса с наивысшим приоритетом.
Глубина прерывания – максимальное число программ, которые могут прерывать друг друга. Глубина прерывания обычно совпадает с числом уровней приоритетов, распознаваемых системой прерываний. Каждому запросу прерывания в компьютере присваивается свой номер (тип прерывания), используемый для определения адреса обработчика прерываний.
Последовательность действий, выполняемых компьютером или процессором при поступлении прерывания
1. Определение наиболее приоритетного незамаскированного запроса на прерывание, если одновременно поступило несколько запросов.
2. Определение типа выбранного запроса.
3. Сохранение текущего состояние счётчика команд и регистров-флагов.
4. Определение адреса обработчика прерывания по типу прерывания и передача управления первой команде этого обработчика.
5. Выполнение программы-обработчика прерывания.
6. Восстановление исходных значений счётчика команд и регистров-флагов, прерванных программой.
7. Продолжение выполнение прерванной программы.
Этапы 1-4 выполняются автоматически при появлении запроса прерывания.
Этап 6 также выполняется аппаратно по команде возврата из обработчика прерывания.
Защита от прерывания
Процессор должен обеспечивать такой подход к запросам на прерывание, при котором прерывание по отдельным причинам может быть запрещено в течение некоторого промежутка времени, в то время как для других запросов прерывание разрешается. В современных ЭВМ наибольшее распространение получило программное управление приоритетом на основе маски-кода защиты от прерываний, представляющего собой двоичное число, разряды которого соответствуют отдельным причинам или уровням прерывания.
Если разряд маски имеет значение 0, то соответствующая причина прерывания замаскирована и процессор не реагирует на данный запрос на прерывание. Если разряд маски равен 1, то соответствующая причина прерывания не замаскирована и процессор воспринимает данный запрос на прерывание.
С замаскированным запросом в зависимости от причины прерывания поступают двояким образом: или он игнорируется, или запоминается с тем, чтобы осуществить затребованные действия, когда запрет будет снят. Например, если прерывание вызвано окончанием операции в периферийном устройстве, то его следует, как правило, запомнить, иначе ЭВМ остаётся неосведомлённой о том, что периферийное устройство освободилось.
Прерывание, вызванное переполнением разрядной сетки при выполнении арифметической операции, следует в случае его маскирования игнорировать, так как запоминание этого запроса может привести к искажению результата этой программы.
Реализация прерываний в современных ЭВМ осуществляется аппаратными и программными средствами, совокупность которых получила название системы прерывания. С помощью аппаратных средств обнаруживаются сигналы запроса прерывания, организуется запоминание информации , необходимой для начала функционирования программных средств, а также для передачи управления программе прерываний и восстановления старой программы. С помощью программных средств производится запись в память содержимого большинства регистров и информации о состоянии процессора. Все обслуживания прерываний, включая определение номера и типа устройства, вида ошибки, возлагаются полностью на ПО, которое иногда определяет и метод возвращения к старой (прерванной) программе.
Различают два метода обработки прерываний: с опросом и по вектору.
1. Прерывание с опросом. При помощи аппаратных и программных средств осуществляется опрос каждого периферийного устройства, пока не обнаружится то, которое запрашивает прерывание, после чего осуществляется переход на соответствующую подпрограмму обслуживания прерывания, которая и выполняет затребованные действия. При этом приоритет периферийного устройства определяется его местом в последовательности опроса.
2. Прерывание по вектору. Запрос непосредственно передаётся на соответствующую подпрограмму, т.е. все периферийные устройства обладают одинаковым приоритетом. Поскольку в данном случае опроса не требуется, время реализации прерывания меньше, чем при выполнении с опросом.
Достоинство системы прерывания заключается в том, что для обеспечение прерываний не нужно принимать никаких мер на уровне рабочей программы пользователя. Составляя свою программу, программист может даже ничего не знать о системе прерываний. Однако системному программисту возможно потребуется разработать особые программы обслуживания прерываний, специфичные для данного устройства, если таких программ может не оказаться в средствах ПО, созданных разработчиками этих средств.Примеры реализации прерываний ЭВМ
Распознавание наличия сигналов запроса прерывания и определение наиболее приоритетного из них может проводиться различными методами. Рассмотрим один из них.
Цепочечная однотактная система определения приоритета запроса прерывания.
Схема определения номера приоритетного запроса прерывания.
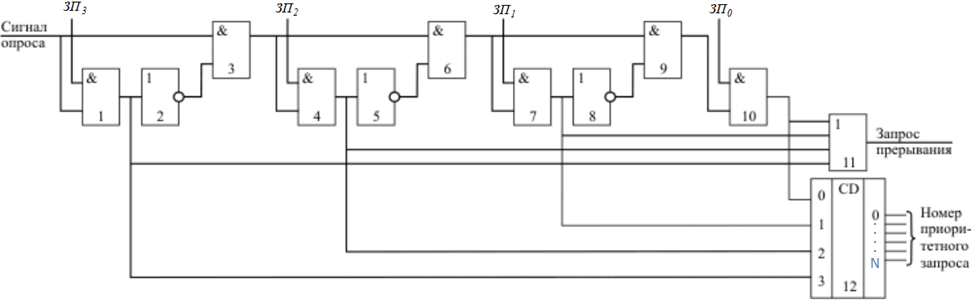
Данная схема используется для анализа запросов аппаратных прерываний. Приоритет запросов прерываний 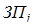 уменьшается с уменьшением номера запроса. В тот момент, когда компьютер должен определить наличие и приоритет внешнего аппаратного прерывания процессор выдаёт сигнал опроса.
уменьшается с уменьшением номера запроса. В тот момент, когда компьютер должен определить наличие и приоритет внешнего аппаратного прерывания процессор выдаёт сигнал опроса.
Если на входе 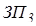 присутствует сигнал высокого уровня (есть запрос), то на элементе 11 формируется общий сигнал наличия запроса прерывания и дальнейшее прохождение сигнала опроса блокируется.
присутствует сигнал высокого уровня (есть запрос), то на элементе 11 формируется общий сигнал наличия запроса прерывания и дальнейшее прохождение сигнала опроса блокируется.
Если 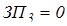 , то анализируется сигнал
, то анализируется сигнал  и так далее.
и так далее.
На шифраторе элемент 12 формируется номер поступившего запроса прерывания. Этот номер передаётся в процессор только при наличии общего сигнала запроса прерывания.
Такая структура позволяет быстро анализировать наличие сигнала запроса прерывания и определять наиболее приоритетный запрос из нескольких присутствующих в данный момент.
Распределение приоритетов запросов прерываний внешних устройств осуществляется путём их физической коммутации по отношению к процессору. Указание приоритетов - жёсткое и не может быть программно изменено. Изменение приоритетов возможно только путём физической перекоммутации устройств.
Обработка прерываний ПК
Микропроцессоры типа i386 имеют два входа внешних аппаратных прерываний:
· NMI - немаскируемое прерывание, используется обычно для запросов прерываний по нарушению питания.
· INT - маскируемое прерывание, запрос от которого можно программным образом замаскировать путём сброса флага IF в регистре флагов.
Единственный вход запроса маскируемых прерываний микропроцессора не позволяет подключить к нему напрямую сигналы запросов от большого числа различных внешних устройств, которые входят в состав современного компьютера: таймеры, клавиатуры, мыши, принтеры, сетевые карты и т.д. для их подключения к одному входу INT микропроцессора используется контроллер приоритетных прерываний.
Структура контроллера приоритетных прерываний:
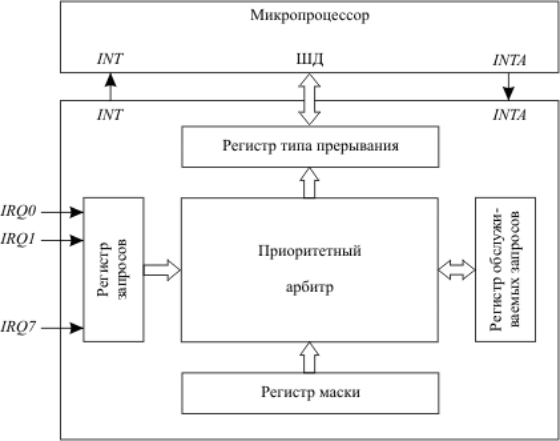
Обработка прерываний ПК
Функции контроллера приоритетных прерываний:
· Восприятие и фиксация запросов прерывания от внешних устройств.
· Определение незамаскированных запросов среди поступивших запросов.
· Проведение арбитража: выделение наиболее приоритетного запроса из незамаскированных запросов в соответствии с установленным механизмом назначения приоритетов.
· Сравнение приоритета выделенного запроса с приоритетом запроса, который в данный момент может обрабатываться в микропроцессоре, формирование сигнала запроса на вход INT микропроцессора в том случае, если приоритет нового запроса выше.
· Передача в микропроцессор по шине данных типа прерывания, выбранного в процессе арбитража, для запуска соответствующей программы – обработчика прерывания. Это действие выполняется по сигналу разрешения прерывания INTA от микропроцессора, который выдаётся в случае, если прерывания в регистре флагов процессора не замаскированы (IF = 1).
Организация памяти ЭВМ
В основе реализации иерархии памяти современных ЭВМ лежат два принципа:
· Принцип локальности обращений
· Соотношение «стоимость/производительность»
Принцип локальности обращений говорит о том, что большинство программ, к счастью, не выполняют обращений ко всем своим командам и данным равновероятно, а оказывают предпочтение некоторой части своего адресного пространства.
Иерархия памяти в современных ЭВМ строится на нескольких уровнях, причём более высокий уровень меньше по объёму, быстрее и имеет большую стоимость в пересчёте на байт, чем более низкий уровень, и меньшую скорость передачи. Уровни иерархии взаимосвязаны: все данные на одном уровне могут быть также найдены на более низком уровне, и все данные на этом более низком уровне могут быть найдены на следующем нижележащем уровне и так далее, пока мы не достигнем основания иерархии. В каждый момент времени мы имеем дело с двумя близлежащими уровнями.
Память – это совокупность отдельных устройств, которые запоминают, хранят и выдают информацию. Отдельные устройства памяти называют запоминающими устройствами.
Производительность ЭВМ в значительной мере определяется составом и характеристиками отдельных ЗУ, которые различаются по принципу действия, техническим характеристикам, назначению.
Основные операции с памятью:
· Процедура записи
· Процедура чтения (выборки)
Процедуры записи и чтения также называют обращением к памяти.
За одно обращение к памяти «обрабатывается» для различных устройств различные единицы данных (байт, слово, длинное слово, блок). Основные технические характеристики памяти: Ёмкость, быстродействие (время обращения к ЗУ).
В некоторых ЗУ считывание данных сопровождается их разрушением. В этом случае цикл обращения к памяти должен содержать функцию «регенерация данных» (для ЗУ динамического типа).
Этот цикл состоит из трёх шагов:
· Время от начала операции обращения до момента, как данные станут доступны (время доступа)
· Считывание после обращения
· Регенерация
Процедура записи имеет:
· Время доступа
· Время подготовки (приведение в исходное состояние поверхности магнитного диска при записи)
· Запись
Максимальная длительность чтения-записи называется временем обращения к памяти.
По физическим основам все ЗУ делятся на полупроводниковые, магнитные, магнитооптические, оптические и т.д.
В зависимости от вида реализуемых операций память бывает двусторонней (память с любым обращением чтение-запись) и односторонней (или только чтение, или только запись).
По способу организации доступа к данным все ЗУ делятся на:
· ЗУ с произвольным доступом
· ЗУ с прямым или циклическим доступом
· ЗУ с последовательным доступом
Организация кэш-памяти
Рассмотрим организацию кэш-памяти более детально, отвечая на 4 вопроса об иерархии памяти.
Принципы размещения блоков в кэш-памяти определяют три основных типа их организации:
1. Если каждый блок основной памяти имеет только одно фиксированное место, на котором он может появиться в кэш-памяти, то такая кэш-память называется кэшем с прямым отображением (direct mapping). Это наиболее простая организация кэш-памяти, при которой для отображения адресов блоков основной памяти на адреса кэш-памяти просто используются младшие разряды адреса блока. Таким образом все блоки основной памяти, имеющие одинаковые младшие разряды в своём адресе попадают в один блок кэш-памяти.
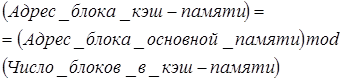
2. Если некоторый блок основной памяти может располагаться на любом месте кэш-памяти, то кэш называется полностью ассоциативным (fully associative).
3. Если некоторый блок основной памяти может располагаться на ограниченном множестве мест в кэш-памяти, то кэш называется множественно-ассоциативным (set associative). Обычно множество представляет собой группу из двух или большего числа блоков в кэше. Если множество состоит из n блоков, то такое размещение называется множественно-ассоциативным с n каналами (n-way set associative). Для размещения блока прежде всего необходимо определить множество. Множество определяется младшими разрядами адреса блока памяти (индексом):
Далее блок может размещаться на любом месте данного множества.
Диапазон возможных организаций кэш-памяти очень широк: кэш-память с прямым отображением есть просто одноканальная множественно-ассоциативная кэш-память, а полностью ассоциативная кэш-память с 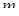 блоками может быть названа -канальной множественно-ассоциативной. В современных процессорах как правило используется либо кэш-память с прямым отображением, либо двух- (четырех-) канальная множественно-ассоциативная кэш-память.
блоками может быть названа -канальной множественно-ассоциативной. В современных процессорах как правило используется либо кэш-память с прямым отображением, либо двух- (четырех-) канальная множественно-ассоциативная кэш-память.
У каждого блока в кэш-памяти имеется адресный тэг, указывающий, какой блок в основной памяти данный блок кэш-памяти представляет. Эти тэги обычно одновременно сравниваются с выработанным процессором адресом блока памяти.
Кроме того, необходим способ определения того, что блок кэш-памяти содержит достоверную или пригодную для использования информацию. Наиболее общим способом решения этой проблемы является добавление к тэгу так называемого бита достоверности (valid bit).
Адресация множественно-ассоциативной кэш-памяти осуществляется путём деления адреса, поступающего из процессора на три части:
1. Поле смещения – используется для выбора байта внутри блока кэш-памяти
2. Поле индекса – определяет номер множества
3. Поле тэга – используется для сравнения
Если общий размер кэш-памяти зафиксировать, то увеличение степени ассоциативности приводит к увеличению количества блоков в множестве, при этом уменьшается размер индекса и увеличивается размер тэга.
При возникновении промаха контроллер кэш-памяти должен выбрать подлежащий замещению блок. Польза от использования организации с прямым отображением заключается в том, что аппаратные решения здесь простые. Выбирать просто нечего в данном случае, так как на попадание проверяется только один блок и только этот блок может быть замещён.
При полностью ассоциативной и множественно-ассоциативной организации кэш-памяти имеются несколько блоков из которых надо выбрать кандидата в случае промаха. Как правило, для замещения блоков используются две основные стратегии – случайная и LRU (Last Recently Used – алгоритм удаления наиболее давно не использующихся элементов).
В первом случае чтобы иметь равномерное распределение блоки-кандидаты выбираются случайно. В некоторых системах чтобы получить воспроизводимое поведение, которое особенно полезно во время отладки аппаратуры, используют псевдослучайный алгоритм замещения.
Во втором случае, чтобы уменьшить вероятность выбрасывания информации, которая скоро может потребоваться, все обращения к блокам фиксируются и заменяется тот блок, который не использовался дольше всех (LRU).
Достоинство случайного способа заключается в том, что его проще реализовать в аппаратуре. Когда количество блоков для поддержания трассы увеличивается, алгоритм LRU становится всё более дорогим и часто только приближённым.
При обращениях к кэш-памяти на реальных программах преобладают обращения по чтению. Все обращения за командами являются обращениями по чтению и большинство команд не пишут в память. Обычно операции записи составляют менее 10% общего трафика памяти. Желание сделать общий случай более быстрым означает оптимизацию кэш-памяти для выполнения операций чтения, однако при реализации высокопроизводительной обработки данных нельзя пренебрегать и скоростью операций записи.
К счастью, общий случай является и более простым. Блок из кэш-памяти может быть прочитан в то же самое время, когда читается и сравнивается его тэг. Таким образом, чтение блока начинается сразу как только становится доступным адрес блока. Если чтение происходит с попаданием, то блок немедленно направляется в процессор. Если же происходит промах, то от заранее считанного блока нет никакой пользы и никакого вреда.
RAID – массивы
RAID (Redundant Array of Independent Disks – избыточный массив независимых дисков) – это совокупность средств, с помощью которых независимые диски организуются в группы с целью повышения производительности и/или надёжности. RAID был впервые предложен Паттерсоном, Гибсоном и Кацем. В их статье в аббревиатуре RAID литера I обозначала Inexpensive – «недорогой», но это значение было позже изменено на Independent – «независимый», поскольку в последние годы для реализации RAID весьма часто используются дорогие высокопроизводительные накопители.
Авторы статьи заметили, что быстродействие процессоров, объем оперативной памяти объёмы внешних накопителей росли быстро, а скорости ввода/вывода (особенно для дисковых накопителей) – намного медленнее. Компьютерные системы становились все более зависимыми от ввода/вывода – они не могли выполнять запросы на ввод/вывод так быстро, как эта запросы возникали, и не могли передавать данные так быстро, как эти данные потреблялись. Чтобы увеличить скорость передачи и пропускную способность, авторы предложили создавать массивы дисков, к которым можно будет обращаться одновременно.
В своей статье Паттерсон и его коллеги предложили пять различных организаций, или уровней (disk levels) дисковых массивов. Каждый уровень RAID-массива характеризуется разделением данных (data striping) и избыточностью (redundancy). Разделение данных означает, что пространство устройства хранения делится на блоки фиксированного размера, называемые полосами (strips). Следующие друг за другом блоки файла размещаются на соседних полосах на разных накопителях массива, и запросы к данным файла могут обрабатываться сразу несколькими накопителями, что уменьшает время доступа.
При выборе размера полосы разработчик системы должен принять во внимание средний размер запросов к диску. Полосы небольшого размера, называемые тонкими полосами (fine-grained strips), распределяют данные между несколькими дисками. Соответственно они уменьшают время выполнения запросов и увеличивают скорости передачи, поскольку множество дисков одновременно передают или принимают данные запроса. Пока эти диски выполняют запрос, они не могут выполнять другие запросы в очереди, поддерживаемой системой.
Полосы большого размера, называемые широкими полосами (coarse-grained strips), позволяют небольшим файлам целиком размещаться на одном накопителе. В этом случае некоторые запросы могут целиком вы полниться отдельными накопителями массива. В результате увеличивается вероятность того, что можно будет одновременно выполнять несколько запросов. Однако малые по объёму запросы будут выполняться отдельными накопителями, и скорость передачи для них будет меньше, чем при использовании тонких полос.
Такие системы, как Web-серверы и серверы баз данных, выигрывают от применения широких полос, поскольку при их использовании могут выполняться сразу несколько операций ввода/вывода. Системы класса суперкомпьютеров, требующие быстрого доступа к небольшому числу записей, выигрывают от использования узких полос, поскольку они дают большие скорости передачи при выполнении отдельных запросов.
Увеличение скорости передачи достигается в RAID-массивах немалой ценой. С увеличением количества накопителей в массивах растёт вероятность того, что один из накопителей выйдет из строя. Например, если средняя наработка на отказ (Mean Time To Failure – MTTF) для одиночного накопителя составляет 200 000 часов (около 23 лет), то для массива из 100 накопителей она составит 2 000 часов (около 3 месяцев). Если один из накопителей откажет, то будут повреждены все файлы, полосы которых размещены на этом накопителе. В системах, решающих критичные, жизненно важные задачи, потеря данных может иметь катастрофические последствия. Поэтому RAID-массивы должны хранить дополнительную информацию, которая позволит восстановить данные в случае появления ошибок – подход, называемый избыточностью, RAID-массивы используют избыточность для достижения отказоустойчивости.
Прямолинейный подход к обеспечению избыточности – дублирование дисков (disk mirroring), при котором каждый уникальный элемент данных записывается на двух накопителях. Недостаток этого подхода в том, что только половина ёмкости массива используется непосредственно для хранения уникальных данных.
Чтобы совместить улучшение производительности с избыточностью, система должна эффективно разделять файлы на полосы, формировать файлы из полос, определять местоположение полос в массивах и обеспечивать поддержку избыточности. Использование для выполнения этих операций процессора общего назначения может существенно снизить производительность, отнимая заметную часть процессорного времени. Поэтому во многих RAID-массивах для быстрого выполнения нужных операций используется специальный аппаратно реализованный RAID-контроллер (RAID controller). Аппаратные RAID-контроллеры также упрощают реализацию RAID-массивов, позволяя системе просто передавать им запросы на чтение и запись данных, причём контроллеры сами выполняют разделение данных на полосы и поддержку избыточности информации. Однако аппаратные RAID-контроллеры могут заметно повысить стоимость системы.
RAID 0 (striping – «чередование») – дисковый массив из двух или более жёстких дисков с отсутствием резервирования. Информация разбивается на блоки данных ( 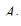 ) и записывается на оба/несколько дисков одновременно.
) и записывается на оба/несколько дисков одновременно.
(+): За счёт этого существенно повышается производительность (от количества дисков зависит кратность увеличения производительности).
(−): Страдает надёжность всего массива (при выходе из строя любого из входящих в RAID 0 винчестеров вся содержащаяся на них информация становится недоступной).
Надёжность массива RAID 0 заведомо ниже надёжности любого из дисков в отдельности. Вероятность отказа такой системы из двух дисков примерно равна удвоенной вероятности отказа одного из дисков, т. к. отказ любого из дисков приводит к неработоспособности всего массива, и растёт с увеличением количества входящих в RAID 0 дисков.
RAID 1 (mirroring – «зеркалирование»). Минимальное количество, для построения «зеркального» RAID 1 – два диска.
(+): Обеспечивает приемлемую скорость записи и выигрыш по скорости чтения при распараллеливании запросов.
(+): Имеет высокую надёжность – работает до тех пор, пока функционирует хотя бы один диск в массиве. Вероятность выхода из строя сразу двух дисков равна произведению вероятностей отказа каждого диска (см. Вероятность пересечения событий). На практике при выходе из строя одного из дисков следует срочно принимать меры – вновь восстанавливать избыточность. Для этого с любым уровнем RAID (кроме нулевого) рекомендуют использовать диски горячего резерва. Достоинство такого подхода – поддержание постоянной надёжности.
(–): Недостаток заключается в том, что приходится выплачивать стоимость двух жёстких дисков, получая полезный объем одного жёсткого диска (классический случай, когда массив состоит из двух дисков).
Зеркало на многих дисках – RAID 1+0 или RAID 0+1. Под RAID 1+0 имеют в виду вариант RAID 10, когда два RAID 1 объединяются в RAID 0. Вариант, когда два RAID 0 объединяются в RAID 1 называется RAID 0+1, и "снаружи" представляет собой тот же RAID 10. Достоинства и недостатки такие же, как и у уровня RAID 0. Как и в других случаях, рекомендуется включать в массив диски горячего резерва из расчёта один резервный на пять рабочих.
RAID 2
В массивах такого типа диски делятся на две группы – для данных и для кодов коррекции ошибок, причём если данные хранятся на n дисках, то для хранения кодов коррекции необходимо n-1 дисков. Данные записываются на соответствующие диски так же, как и в RAID 0, они разбиваются на небольшие блоки по числу дисков, предназначенных для хранения информации. Оставшиеся диски хранят коды коррекции ошибок, по которым в случае выхода какого-либо жёсткого диска из строя возможно восстановление информации. Метод Хемминга давно применяется в памяти типа ECC и позволяет на лету исправлять однократные и обнаруживать двукратные ошибки.
(-): Для функционирования RAID 2 нужна структура из почти двойного количества дисков, поэтому такой вид массива не получил распространения.
RAID 3
В массиве RAID 3 из n дисков данные разбиваются на блоки размером 1 байт и распределяются по n-1 дискам. Ещё один диск используется для хранения блоков чётности. В RAID 2 для этой цели применялся n-1 диск, но большая часть информации на контрольных дисках использовалась для коррекции ошибок на лету, в то время как большинство пользователей удовлетворяет простое восстановление информации в случае поломки диска, для чего хватает информации, умещающейся на одном выделенном жёстком диске.
Отличия RAID 3 от RAID 2: невозможность коррекции ошибок на лету и меньшая избыточность.
(+): скорость чтения и записи данных высока;
(+): минимальное количество дисков для создания массива равно трём.
(-): массив этого типа хорош только для однозадачной работы с большими файлами, так как время доступа к отдельному сектору, разбитому по дискам, равно максимальному из интервалов доступа к секторам каждого из дисков. Для блоков малого размера время доступа намного больше времени чтения.
(-): большая нагрузка на контрольный диск, и, как следствие, его надёжность сильно падает по сравнению с дисками, хранящими данные.
RAID 4
RAID 4 похож на RAID 3, но отличается от него тем, что данные разбиваются на блоки, а не на байты. Таким образом, удалось отчасти «победить» проблему низкой скорости передачи данных небольшого объёма. Запись же производится медленно из-за того, что чётность для блока генерируется при записи и записывается на единственный диск. Из систем хранения широкого распространения RAID 4 применяется на устройствах хранения компании NetApp (NetApp FAS), где его недостатки успешно устранены за счёт работы дисков в специальном режиме групповой записи, определяемом используемой на устройствах внутренней файловой системой WAFL.
RAID 5
Основным недостатком уровней RAID от 2-го до 4-го является невозможность производить параллельные операции записи, так как для хранения информации о чётности используется отдельный контрольный диск. RAID 5 не имеет этого недостатка. Блоки данных и контрольные суммы циклически записываются на все диски массива, нет асимметричности конфигурации дисков. Под контрольными суммами подразумевается результат операции XOR (исключающее или). XOR обладает особенностью, которая применяется в RAID 5, которая даёт возможность заменить любой операнд результатом, и применив алгоритм XOR, получить в результате недостающий операнд. Например: A XOR B = C (где A, B, C – три диска рейд-массива), в случае если A откажет, мы можем получить его, поставив на его место C и проведя XOR между C и B: C XOR B = A. Это применимо вне зависимости от количества операндов: A XOR B XOR C XOR D = E. Если отказывает C тогда E встаёт на его место и проведя XOR в результате получаем C: A XOR B XOR E XOR D = C. Этот метод по сути обеспечивает отказоустойчивость 5 версии. Для хранения результата XOR требуется всего 1 диск, размер которого равен размеру любого другого диска в raid.
(+): RAID5 получил широкое распространение, в первую очередь, благодаря своей экономичности. Объем дискового массива RAID5 рассчитывается по формуле 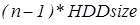 , где n – число дисков в массиве, а HDDsize – размер наименьшего диска. Например, для массива из 4-х дисков по 80 гигабайт общий объем будет (4-1)*80=240 гигабайт. На запись информации на том RAID 5 тратятся дополнительные ресурсы и падает производительность, так как требуются дополнительные вычисления и операции записи, зато при чтении (по сравнению с отдельным винчестером) имеется выигрыш, потому что потоки данных с нескольких дисков массива могут обрабатываться параллельно.
, где n – число дисков в массиве, а HDDsize – размер наименьшего диска. Например, для массива из 4-х дисков по 80 гигабайт общий объем будет (4-1)*80=240 гигабайт. На запись информации на том RAID 5 тратятся дополнительные ресурсы и падает производительность, так как требуются дополнительные вычисления и операции записи, зато при чтении (по сравнению с отдельным винчестером) имеется выигрыш, потому что потоки данных с нескольких дисков массива могут обрабатываться параллельно.
(-): Производительность RAID 5 заметно ниже, в особенности на операциях типа Random Write (записи в произвольном порядке), при которых производительность падает на 10-25% от производительности RAID 1 (или RAID 10), так как требует большего количества операций с дисками (каждая операция записи сервера заменяется на контроллере RAID на три – одну операцию чтения и две операции записи). Недостатки RAID 5 проявляются при выходе из строя одного из дисков – весь том переходит в критический режим (degrade), все операции записи и чтения сопровождаются дополнительными манипуляциями, резко падает производительность. При этом уровень надёжности снижается до надёжности RAID-0 с соответствующим количеством дисков (то есть в n раз ниже надёжности одиночного диска). Если до полного восстановления массива произойдёт выход из строя, или возникнет невосстановимая ошибка чтения хотя бы на ещё одном диске, то массив разрушается, и данные на нем восстановлению обычными методами не подлежат. Следует также принять во внимание, что процесс RAID Reconstruction (восстановления данных RAID за счёт избыточности) после выхода из строя диска вызывает интенсивную нагрузку чтения с дисков на протяжении многих часов непрерывно, что может спровоцировать выход какого-либо из оставшихся дисков из строя в этот наименее защищённый период работы RAID, а также выявить ранее необнаруженные сбои чтения в массивах cold data (данных, к которым не обращаются при обычной работе массива, архивные и малоактивные данные), что повышает риск сбоя при восстановлении данных.
Минимальное количество используемых дисков равно трём.
RAID 6
RAID 6 похож на RAID 5, но имеет более высокую степень надёжности – под контрольные суммы выделяется ёмкость 2-х дисков, рассчитываются 2 суммы по разным алгоритмам. Требует более мощный RAID-контроллер. Обеспечивает работоспособность после одновременного выхода из строя двух дисков – защита от кратного отказа. Для организации массива требуется минимум 4 диска. Обычно использование RAID 6 вызывает примерно 10-15% падение производительности дисковой группы, по сравнению с аналогичными показателями RAID 5, что вызвано большим объёмом обработки для контроллера (необходимость рассчитывать вторую контрольную сумму, а также прочитывать и перезаписывать больше дисковых блоков при записи каждого блока).
RAID 7
RAID 7 не является уровнем RAID, и является зарегистрированной торговой маркой компании Storage Computer Corporation. Структура массива такова: на n−1 дисках хранятся данные, один диск используется для складирования блоков чётности. Запись на диски кэшируется с использованием оперативной памяти, сам массив требует обязательного ИБП; в случае перебоев с питанием происходит повреждение данных.
RAID 10
RAID уровня 10 – набор зеркально отображённых данных (уровень 1), разделённый на полосы в другом наборе дисков (уровень 0), для чего требуется минимум четыре накопителя.
(+): Наследует надёжность от RAID 1, производительность как на чтение, так и на запись от RAID 0
(+): В некоторых случаях RAID 10 может выдержать одновременный отказ нескольких дисков
(+): Отличное решение для сайтов, которые бы в противном случае использовали RAID 1, но для этого потребуются некоторые дополнительные увеличения производительности
RAID 0+1
RAID уровня 0+1 – набор накопителей с разделёнными на полосы данными (уровень 0), зеркально отображённый на другой набор накопителей (уровень 1).
(+): RAID 0+1 имеет такую же отказоустойчивость, как RAID уровня 5
(+): Имеет те же накладные расходы на обеспечение отказоустойчивости что и зеркальное отображение
(+): Высокие показатели ввода / вывода достигаются благодаря нескольким сегментам полосы
(+): Отличное решение для сайтов, которым нужна высокая производительность, но не связаны с достижением максимальной надёжности
Matrix RAID
Принципы работы Matrix RAID достаточно просты. Напомним основы организации классических RAID-массивов: мы оперируем целыми жёсткими дисками как таковыми. Из этих двух организуем RAID уровня 0, из тех трех-четырёх – RAID уровня 5. Все операции по организации и управлению массивами реализуются на аппаратном уровне с помощью BIOS системной платы или выделенного RAID-контроллера – без вмешательства операционной системы.
Очень важно, что Matrix RAID, в отличие от привычных методов организации массивов хранения данных, не является программно-независимым. Matrix RAID является, скорее, не аппаратной, а программно-аппаратной технологией. Причина тому – использование не только контроллера-концентратора ввода-вывода ICH 6 R, но и утилиты Intel Application Accelerator версии 4.х, являющейся на самом деле «сборной солянкой» из драйвера и управляющего ПО, с помощью которого и производится разбивка физических жёстких дисков на тома, определение их ролей и т. д.
Организация такого «псевдо»-RAID массива при помощи Intel Application Accelerator выглядит несложно – пользователь создаёт первый том необходимого размера, определяя и его роль – то есть в каком режиме (0 или 1) он будет функционировать. Оставшееся свободное место выделяется под второй том, также с возможностью выбора режима функционирования. После завершения этих нехитрых процедур в системе появляется два жёстких диска – на одном встроенном в южный мост контроллере и двух физических накопителях SerialATA мы получаем искомую скорость и стабильность. На данном этапе недостаток состоит в том, что размеры томов фиксированы – пользователь не имеет возможности впоследствии что-либо изменить, поэтому стоит заблаговременно определить необходимые размеры.
Как уже упоминалось, Intel поддерживает RAID-организацию только для двух дисков, несмотря на то, что южный мост ICH 6 R имеет четыре порта SerialATA 150/RAID. Теоретически можно организовать два Matrix RAID-массива, но они будут независимыми друг относительно друга. Компания Intel особо подчёркивает возможность апгрейда системы до Matrix RAID, для этого требуется к имеющемуся в системе SerialATA-винчестеру добавить второй. В принципе это понятно, однако приятно, что при организации массивов данные не теряются – Intel Application Accelerator способен выполнить необходимые действия в фоновом режиме.
(+): наличие четырёхпортового контроллера SATA RAID, подразумевающего возможность создания Matrix RAID массива;
(+): RAID BIOS ROM – интегрированную в системный BIOS часть, отвечающую за создание, именование и удаление массивов;
(+): Intel RAID Migration Technology – технологию, позволяющую производить апгрейд подсистемы хранения данных до Matrix RAID;
(+): интерфейс SerialATA AHCI с поддержкой NCQ и горячего подключения (Advanced Host Controller Interface, присутствует только в Intel 915/925);
(+): полное программное управление массивами Matrix RAID.
(-): отсутствие возможности динамического изменения объемов томов.
Комбинированные уровни RAID 1+0, RAID 5+0, RAID 1+5
Помимо базовых уровней RAID 0 – RAID 5, описанных в стандарте, существуют комбинированные уровни RAID 1+0, RAID 3+0, RAID 5+0, RAID 1+5, которые различные производители интерпретируют каждый по-своему.
RAID 1+0 – это сочетание зеркалирования и чередования (см. выше).
RAID 5+0 – это чередование томов 5-го уровня.
RAID 1+5 – RAID 5 из зеркалированных пар.
Комбинированные уровни наследуют как преимущества, так и недостатки своих «родителей»: появление чередования в уровне RAID 5+0 нисколько не добавляет ему надёжности, но зато положительно отражается на производительности. Уровень RAID 1+5, наверное, очень надёжный, но не самый быстрый и, к тому же, крайне неэкономичный: полезная ёмкость тома меньше половины суммарной ёмкости дисков.
Стоит отметить, что количество жёстких дисков в комбинированных массивах также изменится. Например для RAID 5+0 используют 6 или 8 жёстких дисков, для RAID 1+0 – 4, 6 или 8.
Клеточные и ДНК процессоры
В настоящее время в поисках реальной альтернативы полупроводниковой технологии (ПП технологиям) создание новых ВС учёные обращают всё большее внимание, на биотехнологии или биокомпьютинг, который представляет собой гибрид информационных, молекулярных технологий, а также биохимии.
Биокомпьютинг позволяет решать сложные вычислительные задачи пользуясь методами, принятыми в биохимии и молекулярной биологии, организуя вычисления при помощи живых тканей, клеток, вирусов и биомолекул. Наибольшее распространение получил подход, где в качестве основного элемента процессора используются молекулы дезоксирибонуклеиновой кислоты.
Центральное место в этом подходе занимает так называемый ДНК-процессор. Кроме ДНК в качестве биопроцессора могут быть использованы белковые молекулы и биологические мембраны.
Так же, как и любой другой процессор, ДНК-процессор характеризуется структурой и набором команд. В нашем случае структура процессора – это структура молекулы ДНК. А набор команд – это перечень биохимических операций с молекулами. Принцип устройства компьютерной ДНК-памяти основан на последовательном соединении четырех нуклеотидов (основных кирпичиков ДНК-цепи). Три нуклеотида, соединяясь в любой последовательности, образуют элементарную ячейку памяти – кодон, совокупность которых формирует затем цепь ДНК.
Основная трудность в разработке ДНК-компьютеров связана с проведением избирательных однокодонных реакций (взаимодействий) внутри цепи ДНК. Однако прогресс есть уже и в этом направлении. Существует экспериментальное оборудование, позволяющее работать с одним из 1020 кодонов или молекул ДНК.
Другой проблемой является самосборка ДНК, приводящая к потере информации. Ее преодолевают введением в клетку специальных ингибиторов – веществ, предотвращающих химическую реакцию самосшивки.
Использование молекул ДНК для организации вычислений – это не слишком новая идея. Теоретическое обоснование подобной возможности было сделано еще в 50-х годах прошлого века (Р.П. Фейманом). В деталях эта теория была проработана в 70-х годах Ч. Бенеттом и в 80-х М. Конрадом.
Первый компьютер на базе ДНК был создан еще в 1994 г. американским ученым Леонардом Адлеманом. Он смешал в пробирке молекулу ДНК, в которой были закодированы исходные данные, и специальным образом подобранные ферменты. В результате химической реакции структура ДНК изменилась таким образом, что в ней в закодированном виде был представлен ответ задачи. Поскольку вычисления проводились в ходе химической реакции с участием ферментов, на них было затрачено очень мало времени.
Вслед за работой Адлемана последовали другие. Ллойд Смит из Университета Висконсин решил с помощью ДНК задачу доставки четырех сортов пиццы по четырем адресам, которая подразумевала 16 вариантов ответа. Ученые из Принстонского университета решили комбинаторную шахматную задачу: при помощи РНК нашли правильный ход шахматного коня на доске из девяти клеток (всего их 512 вариантов).
Ричард Липтон из Принстона первым показал, как, используя ДНК, кодировать двоичные числа и решать проблему удовлетворения логического выражения. Суть ее в том, что, имея некоторое логическое выражение, включающее n логических переменных, нужно найти все комбинации значений переменных, делающих выражение истинным. Задачу можно решить только перебором 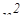 комбинаций. Все эти комбинации легко закодировать с помощью ДНК, а дальше действовать по методике Адлемана. Липтон предложил также способ взлома шифра DES (американский криптографический), трактуемого как своеобразное логическое выражение.
комбинаций. Все эти комбинации легко закодировать с помощью ДНК, а дальше действовать по методике Адлемана. Липтон предложил также способ взлома шифра DES (американский криптографический), трактуемого как своеобразное логическое выражение.
Первую модель биокомпьютера, (в виде механизма из пластмассы) в 1999 г. создал Ихуд Шапиро из Вейцмановского института естественных наук. Она имитировала работу "молекулярной машины" в живой клетке, собирающей белковые молекулы по информации с ДНК, используя РНК в качестве посредника между ДНК и белком.
А в 2001 г. Шапиро удалось реализовать вычислительное устройство на основе ДНК, которое может работать почти без вмешательства человека. Система имитирует машину Тьюринга – одну из фундаментальных концепций вычислительной техники. Машина Тьюринга шаг за шагом считывает данные и в зависимости от их значений принимает решения о дальнейших действиях. Теоретически она может решить любую вычислительную задачу.
По своей природе молекулы ДНК работают аналогичным образом, распадаясь и рекомбинируясь в соответствии с информацией, закодированной в цепочках химических соединений.
Разработанная в Вейцмановском институте установка кодирует входные данные и программы в состоящих из двух цепей молекулах ДНК и смешивает их с двумя ферментами. Молекулы фермента выполняли роль аппаратного, а молекулы ДНК – программного обеспечения. Один фермент расщепляет молекулу ДНК с входными данными на отрезки разной длины в зависимости от содержащегося в ней кода. А другой рекомбинирует эти отрезки в соответствии с их кодом и кодом молекулы ДНК с программой. Процесс продолжается вдоль входной цепи, и, когда доходит до конца, получается выходная молекула, соответствующая конечному состоянию системы.
Этот механизм может использоваться для решения самых разных задач. Хотя на уровне отдельных молекул обработка ДНК происходит медленно, со скоростью от 500 до 1000 бит/с, что во много миллионов раз медленнее современных кремниевых процессоров, по своей природе она допускает массовый параллелизм. По оценкам Шапиро и его коллег, в одной пробирке может одновременно происходить триллион процессов, так что при потребляемой мощности в единицы нановатт может выполняться миллиард операций в секунду.
В конце февраля 2002 г. появилось сообщение, что фирма Olympus Optical претендует на первенство в создании коммерческой версии ДНК-компьютера, предназначенного для генетического анализа. Машина была создана в сотрудничестве с доцентом Токийского университета Акирой Тояма.
Компьютер, построенный Olympus Optical, имеет молекулярную и электронную составляющие. Первая осуществляет химические реакции между молекулами ДНК, обеспечивает поиск и выделение результата вычислений. Вторая – обрабатывает информацию и анализирует полученные результаты.
Возможностями биокомпьютеров заинтересовались и военные. Американское агентство по исследованиям в области обороны DARPA выполняет проект, получивший название Bio-Comp (Biological Computations, биологические вычисления). Его цель – создание мощных вычислительных систем на основе ДНК.
Пока до практического применения компьютеров на базе ДНК еще очень далеко. Однако в будущем их смогут использовать не только для вычислений, но и как своеобразные нанофабрики лекарств. Поместив подобное "устройство" в клетку, врачи смогут влиять на ее состояние, исцеляя человека от самых опасных недугов.
Клеточные компьютеры представляют собой самоорганизующиеся колонии различных "умных" микроорганизмов, в геном которых удалось включить некую логическую схему, которая могла бы активизироваться в присутствии определенного вещества. Для этой цели идеально подошли бы бактерии, стакан с которыми и представлял бы собой компьютер. Такие компьютеры очень дешевы в производстве. Им не нужна стерильная атмосфера, как при производстве полупроводников.
Главное свойство такого компьютера состоит в том, что каждая его клетка представляет собой миниатюрную химическую лабораторию. Если биоорганизм запрограммирован, то он просто производит нужные вещества. Достаточно вырастить одну клетку, обладающую заданными качествами, и можно легко и быстро вырастить тысячи клеток с такой же программой.
Основная проблема, с которой сталкиваются создатели клеточных биокомпьютеров – организация всех клеток в единую работающую систему. На сегодня практические достижения в области клеточных компьютеров напоминают достижения 20-х годов в области ламповых и полупроводниковых компьютеров. Сейчас в Лаборатории искусственного интеллекта Массачусетского технологического университета создана клетка, способная хранить на генетическом уровне 1 бит информации. Также разрабатываются технологии, позволяющие единичной бактерии отыскивать своих соседей, образовывать с ними упорядоченную структуру и осуществлять массив параллельных операций.
В 2001 г. американские ученые создали трансгенные микроорганизмы (т. е. микроорганизмы с искусственно измененными генами), клетки которых могут выполнять логические операции И и ИЛИ.
Специалисты лаборатории Оук-Ридж, штат Теннесси, использовали способность генов синтезировать тот или иной белок под воздействием определенной группы химических раздражителей. Ученые изменили генетический код бактерий Pseudomonas putida таким образом, что их клетки обрели способность выполнять простые логические операции. Например, при выполнении операции И в клетку подаются два вещества (по сути – входные операнды), под влиянием которых ген вырабатывает определенный белок. Теперь ученые пытаются создать на базе этих клеток более сложные логические элементы, а также подумывают о возможности создания клетки, выполняющей параллельно несколько логических операций.
Потенциал биокомпьютеров очень велик. К достоинствам, выгодно отличающим их от компьютеров, основанных на кремниевых технологиях, относятся:
· более простая технология изготовления, не требующая для своей реализации столь жестких условий, как при производстве полупроводников;
· использование не бинарного, а тернарного кода (информация кодируется тройками нуклеотидов), что позволит за меньшее количество шагов перебрать большее число вариантов при анализе сложных систем;
· потенциально исключительно высокая производительность, которая может составлять до 1014 операций в секунду за счет одновременного вступления в реакцию триллионов молекул ДНК;
· возможность хранить данные с плотностью, в триллионы раз превышающей показатели оптических дисков;
· исключительно низкое энергопотребление.
Однако, наряду с очевидными достоинствами, биокомпьютеры имеют и существенные недостатки, такие как:
· сложность со считыванием результатов – современные способы определения кодирующей последовательности несовершенны, сложны, трудоемки и дороги;
· низкая точность вычислений, связанная с возникновением мутаций, прилипанием молекул к стенкам сосудов и т.д.;
· невозможность длительного хранения результатов вычислений в связи с распадом ДНК в течение времени.
Хотя до практического использования биокомпьютеров еще очень далеко, и они вряд ли будут рассчитаны на широкие массы пользователей, предполагается, что они найдут достойное применение в медицине и фармакологии, а также с их помощью станет возможным объединение информационных и биотехнологий.
Также существуют клеточные, оптические, нейронные и другие компьютеры.
Организация ЭВМ и систем
Никольский Александр Николаевич
Основные понятия структуры и архитектуры ЭВМ. Понятия
физической, логической и программной структур.
Создание ЭВМ представляет собой одно из выдающихся достижений научной и технической мысли середины 20 столетия. В течение полувека ЭВМ совершили бурный скачок в своём развитии от первых громоздких и малонадёжных моделей до современных мейнфреймов, серверов, ПК, контроллеров технологического оборудования, локальных и глобальных сетей ЭВМ и т.д.
ЭВМ используются везде, где решаемые задачи могут быть формализованы или, как говорят, алгоритмизированы.
Алгоритмом называется система формальных правил, чётко и однозначно определяющих процесс выполнения заданной работы посредством конечного числа операций.
Основные понятия:
1. Электронная вычислительная машина (ЭВМ) – комплекс технических и программных средств, предназначенный для автоматизации подготовки и решения задач пользователей. Технические и программные средства Вычислительной Техники взаимосвязаны и объединяются в одну структуру.
2. Вычислительная система (ВС) – это совокупность взаимосвязанных и взаимодействующих процессоров или ЭВМ, периферийных устройств и ПО, предназначенная для решения задач пользователей.
3. Структура – это совокупность элементов и их связей. Различают структуры технических, программных и аппаратно-программных средств. Структуру ЭВМ определяют:
a)Технические и эксплуатационные характеристики ЭВМ (быстродействие и производительность, показатели надёжности, достоверности, точности, ёмкость ОЗУ и ВЗУ, габаритные размеры, стоимость технических и программных средств, особенности эксплуатации и т.д. )
b) Характеристики и состав функциональных модулей базовой конфигурации ЭВМ; возможность расширения состава технических и программных средств; возможность изменения структуры.
c)Состав ПО ЭВМ и сервисных услуг (ОС или среда, ППП, средства автоматизации программирования).
4. Архитектура ЭВМ – это многоуровневая иерархия программно-аппаратных средств, из которых строится ЭВМ. Каждый из уровней допускает многовариантное построение и применение. Конкретная реализация уровней определяет особенности структурного построения ЭВМ. Термин "архитектура системы" часто употребляется как в узком, так и в широком смысле этого слова. В узком смысле "архитектурой" понимается архитектура набора команд. Архитектура набора команд служит границей между аппаратурой и ПО и представляет ту часть систем, которая видна программисту или разработчику компилятора. Следует отметить, что это наиболее частое употребление термина "архитектура". В широком смысле архитектура охватывает понятие организации системы, включающие такие высокоуровневые аспекты разработки компьютера, как систему памяти, структуру системной шины, организацию ввода-вывода и т.п. Наиболее строгое определение понятия "архитектура систем" дано Э.Я. Якубайтисом в книге "Архитектура вычислительных систем". Архитектура системы является ёмким понятием, включающим три важнейших вида взаимосвязанных структур: физическую, логическую и программную. Кроме того, анализируя другие аспекты архитектуры часто рассматривают структуры административного управления, обслуживания и ремонта. Каждая из этих структур определяется набором элементов и характеров их взаимосвязей. Связь структур друг с другом образует архитектуру рассматриваемой системы.
Элементами физической структуры являются технические объекты. В зависимости от того, какие задачи решаются, этими объектами могут быть:
· Полупроводниковые кристаллы
· Части вычислительных систем, а также комплексы, составленные из них.
Элементами логической структуры являются функции, определяющие основные операции.
Элементы программной структуры. Эту структуру образуют взаимосвязанные программы: ОС, обработка информации и др.
Таким образом, архитектурой системы (Вычислительной сети, терминального комплекса, ЭВМ, полупроводникового кристалла) является концепция взаимосвязей большого числа различного типа элементов. Она в основном характеризуется переплетением физической, логической и программной структур этой системы.
Детализацией архитектурного и структурного построения ЭВМ занимаются различные категории специалистов IT.
Инженеры-схемотехники проектируют отдельные технические устройства и разрабатывают их методы сопряжения друг с другом.
Системные программисты создают программы управления техническими средствами, информационного взаимодействия между уровнями, организации вычислительного процесса.
Прикладные программисты разрабатывают пакеты программ более высокого уровня, которые обеспечивают взаимодействие пользователя с ЭВМ и необходимый сервис при решении задач.
Основные характеристики ЭВМ
Быстродействие – это число команд, выполняемых ЭВМ за 1 секунду. Быстродействие измеряется во флопсах (FLOPS - Floating point Operation Per Second). В системе СИ используются: килофлопс KFLOPS, мегафлопс MFLOPS, гигафлопс GFLOPS, терафлопс TFLOPS, петафлопс - PFLOPS, эксафлопс - EFLOPS.
Величина FLOPS используется для определения быстродействия современных ЭВМ в программе LINPACK. LINPACK – это библиотека, написанная на языке FORTRAN, которая содержит набор подпрограмм для решения СЛАУ.
Для тестирования современных ЭВМ применяются другие библиотеки – Lapack, Linpack benchmark и т.д.
Сравнения по быстродействию различных типов ЭВМ не обеспечивают достоверных оценок, поэтому вместо характеристики быстродействия используют связанную с ней характеристику "производительность".
Производительность – это объём работ, осуществляемых ЭВМ в единицу времени. Производительность зависит от большого числа факторов:
· Скорости выполнения элементарных операций
· Скорости обмена информации по каналам
· Структуры памяти
· Характеристик периферийных устройств
· Структуры и настроек ОС и приоритетов
· Характеристик алгоритмов и выбранных дисциплин обслуживания и т.д.
Ёмкость запоминающих устройств.
Ёмкость памяти измеряется количеством структурных единиц информации, которые могут одновременно находиться в памяти. Этот показатель позволяет определить, какой набор программ и данных может быть одновременно размещён в памяти.
Ёмкость памяти измеряется в байтах, килобайтах (КБ), мегабайтах (МБ), гигабайтах (ГБ), терабайтах (ТБ).
Ёмкость ОЗУ и ёмкость ВЗУ характеризуется отдельно для определения, какие ПП и их приложения могут одновременно обрабатываться в машине.
Надёжность – это способность ЭВМ при определённых условиях выполнять требуемые функции в течение заданного периода времени. На это существует международный стандарт ISO 2382/14-78. Высокая надёжность ЭВМ закладывается в процессе её проектирования и производства. Применение СБИС резко сокращают число используемых интегральных схем, а значит и число их соединений друг с другом.
Модульный принцип построения позволяет легко проверять и контролировать работу всех устройств, проводить диагностику и устранение неисправностей.
Точность – это возможность различать почти равные значения. Для этого существует ещё один международный стандарт ISO 2382/2-76. Точность получения результатов обработки в основном определяется разрядностью ЭВМ, а также используемыми структурными единицами представления информации (байтом, словом, двойным словом)
Достоверность – это свойство информации быть правильно воспринятой. Достоверность характеризуется вероятностью получения безошибочных результатов. Заданный уровень достоверности обеспечивается аппаратно-программными средствами контроля самой ЭВМ. Возможные методы контроля достоверности путём решения эталонных задач и повторных расчётов. В особо ответственных случаях проводятся контрольные решения на других ЭВМ и сравнения результатов.
Дата: 2019-02-02, просмотров: 572.