МОСКОВСКИЙ АВИАЦИОННЫЙ ИНСТИТУТ
( Государственный технический университет )
Направление 220300- Информационные системы и технологии
Склеймин Ю.Б.
УПРАВЛЕНИЕ БАЗАМИ ДАННЫХ
(конспект лекций)
4 семестр
Лекции- 32 часа
Лабораторные работы – 16 часов
2010г.
Лекция 1
Язык для взаимодействия с БД SQL появился в середине 70-х и был разработан в рамках проекта экспериментальной реляционной СУБД System R. Исходное название языка SEQUEL (Structered English Query Language) только частично отражает суть этого языка. Конечно, язык был ориентирован главным образом на удобную и понятную пользователям формулировку запросов к реляционной БД, но на самом деле уже являлся полным языком БД, содержащим помимо операторов формулирования запросов и манипулирования БД средства определения и манипулирования схемой БД; определения ограничений целостности и триггеров; представлений БД; возможности определения структур физического уровня, поддерживающих эффективное выполнение запросов; авторизации доступа к отношениям и их полям; точек сохранения транзакции и откатов. В языке отсутствовали средства синхронизации доступа к объектам БД со стороны параллельно выполняемых транзакций: с самого начала предполагалось, что необходимую синхронизацию неявно выполняет СУБД. Рассмотрим эти свойства языка немного более подробно.
В настоящее время SQL переживает новый подъем. В качестве коммерческого продукта язык был впервые реализован в Oracle в 1976 году, но официального стандарта SQL не существовало до 1986 года, когда он был опубликован как результат объединенных усилий ANSI (the American National Standards Institute) и ISO (International Standards Organization). Поскольку ANSI является частью ISO, в данном приложении мы ссылаемся на обе эти организации как на ISO. Стандарт 1986 года был пересмотрен в 1989 году, в него были введены средства, обеспечивающие ссылочную целостность (referential integrity).
К тому времени, когда появился стандарт 86, ряд программных продуктов уже использовал SQL, и ISO попытался закрепить в стандарте наиболее общие черты этих реализаций для того, чтобы ввод стандарта не отразился слишком болезненно на готовых программных продуктах. ISO проанализировал все основные характеристики существовавших к тому времени программных реализаций и определил весьма минимальный стандарт. Некоторые существенные характеристики, например, как уничтожение объектов и передача привилегий, были опущены из стандарта полностью. Теперь, когда многообразный компьютерный мир стал столь коммуникабельным, разработчики и пользователи хотят без особых проблем взаимодействовать с множеством баз данных, разработанных индивидуально. В результате возникла потребность в стандартизации тех характеристик, которые ранее были отданы на усмотрение разработчика. Несколько лет эксплуатации конкретных систем и теоретических исследований дали новые идеи, которые требуют единообразия при воплощении в программных продуктах. Для удовлетворения этих потребностей ISO разработал новый стандарт SQL 92.
Стандарт SQL 92 превышает первый стандарт SQL по объему примерно в пять раз. В нем значительно расширена область стандартизации, а также определен стандарт для ряда существовавших характеристик, которые до этого были отданы на волю разработчика, включены те моменты, которые ранее были опущены. Поскольку стандарт SQL 92, включает как подмножество стандарт 89, можно ссылаться на стандарт 92, если программный продукт удовлетворяет требованиям стандарта 89 или некоторым промежуточным требованиям.
Естественно, те продукты, которые используются, могут по-своему расширять стандарт. Для того чтобы прикладной программист мог выделять все специфические моменты, имея дело с такими расширениями, новый стандарт требует применения флаггера (flagger) – программы, проверяющей основной код и помечающей (маркирующей) все предложения SQL, не соответствующие стандарту 92. Непомеченные предложения ведут себя так, как описано в стандарте. Для помеченных предложений следует применять системную документацию. Возможна ситуация, при которой предложение соответствует стандарту, а его поведение – нет. Такое предложение также помечается. В любом случае, этот стандарт более полон, чем предыдущий.
Роль SQL
В настоящее время, SQL выполняет много различных функций:
• SQL — язык интерактивных запросов. Пользователи вводят команды SQL в интерактивных программах с целью выборки данных и отображения их на экране. Это удобный способ выполнения специальных запросов.
• SQL — язык программирования баз данных. Чтобы получить доступ к базе данных, программисты вставляют в свои программы команды SQL. Эта методика используется как в программах, написанных пользователями, так и в служебных программах баз данных (таких как генераторы отчетов).
• SQL — язык администрирования баз данных. Администратор базы данных, находящейся на рабочей станции или на сервере, использует SQL для определения структуры базы данных и управления доступом к данным.
• SQL — язык создания приложений клиент/сервер. В программах для персональных компьютеров SQL используется как средство организации связи по локальной сети с сервером баз данных, в которой хранятся совместно используемые данные. Архитектура клиент/сервер весьма популярна в приложениях корпоративного уровня.
• SQL — язык доступа к данным в среде Internet . На Web-серверах SQL используется как стандартный язык для доступа к корпоративным базам данных.
• SQL — язык распределенных баз данных. В системах управления распределенными базами данных SQL помогает распределять данные среди нескольких взаимодействующих вычислительных систем. Программное обеспечение каждой системы посредством SQL связывается с другими системами, посылая им запросы на доступ к данным.
• SQL — язык шлюзов баз данных. В вычислительных сетях с различными СУБД SQL часто используется в шлюзовой программе, которая позволяет СУБД одного типа связываться с СУБД другого типа.
Таким образом, SQL превратился в полезный и мощный инструмент, обеспечивающий пользователям, программам и вычислительным системам доступ к информации, содержащейся в реляционных базах данных.
Преимущества SQL
SQL — это легкий для понимания язык и в то же время универсальное программное средство управления данными.
Успех языку SQL принесли следующие его особенности:
• независимость от конкретных СУБД;
• межплатформенная переносимость;
• наличие стандартов;
• одобрение компанией IBM (СУБД DB2);
• поддержка со стороны компании Microsoft (протокол ODBC и технология ADO);
• реляционная основа;
• высокоуровневая структура, напоминающая английский язык;
• возможность выполнения специальных интерактивных запросов;
• обеспечение программного доступа к базам данных;
• возможность различного представления данных;
• полноценность как языка, предназначенного для работы с базами данных;
• возможность динамического определения данных;
• поддержка архитектуры клиент/сервер;
• расширяемость и поддержка объектно-ориентированных технологий;
• возможность доступа к данным в среде Internet;
• интеграция с языком Java (протокол JDBC).
Все перечисленные выше факторы явились причиной того, что SQL стал стандартным инструментом для управления данными на персональных компьютерах, рабочих станциях и крупных серверах. Ниже эти факторы рассмотрены более подробно.
Стандарты языка SQL
Официальный стандарт языка SQL был опубликован Американским национальным институтом стандартов (American National Standards Institute — ANSI) и Международной организацией по стандартизации (International Standards Organization — ISO) в 1986 году, расширен в 1989 году, а затем — в 1992 году. Кроме того, SQL является федеральным стандартом США в области обработки информации (FIPS — Federal Information Processing Standard) и, следовательно, соответствие ему является одним из основных требований, содержащихся в больших правительственных контрактах на разработки в компьютерной промышленности. В течение последних десяти лет многие другие международные, правительственные и промышленные группы вносили свой вклад в стандартизацию различных составляющих SQL, таких как интерфейсы программирования и объектно-ориентированные расширения. Со временем многие из подобных инициатив стали составной частью стандарта ANSI/ISO Все эти стандарты служат как бы официальной печатью, одобряющей SQL, и от ускорили завоевание им рынка.
Реляционная основа
SQL является языком реляционных баз данных, поэтому он стал популярным тогда, когда популярной стала реляционная модель представления данных. Табличная структура реляционной базы данных интуитивно понятна пользователям, поэтому язык SQL является простым и легким для изучения. Реляционная модель имеет солидный теоретический фундамент, послуживший основой для эволюции и реализации реляционных баз данных. На волне популярности, вызванной успехом реляционной модели, SQL стал единственным языком для реляционных баз данных.
Интерактивные запросы
SQL является языком интерактивных запросов, который обеспечивает пользователям немедленный доступ к данным. С помощью SQL пользователь может в интерактивном режиме получить ответы на самые сложные запросы в считанные минуты или секунды, тогда как программисту потребовались бы дни или недели, чтобы написать для пользователя соответствующую программу. Из-за того что SQL допускает интерактивное формирование запросов, данные становятся более доступными и могут помочь в принятии решений, делая их более обоснованными.
Архитектура клиент/сервер
SQL — естественное средство для реализации приложений клиент/сервер. В этой роли SQL служит связующим звеном между клиентской системой, взаимодействующей с пользователем, и серверной системой, управляющей базой данных, позволяя каждой системе сосредоточиться на выполнении своих функций. Кроме того, SQ дает возможность персональным компьютерам функционировать в качестве клиента по отношению к сетевым серверам или более крупным базам данных, установленных на мэйнфреймах; это позволяет получать доступ к корпоративным данным из приложений, работающих на персональных компьютерах.
Лекция 2
SQL и сети
Рост популярности компьютерных сетей оказал большое влияние на управление базами данных и придал SQL новые возможности. По мере распространения сетей приложения, которые раньше работали на центральном мини-компьютере или мэйнфрейме, переводятся на серверы и рабочие станции ЛВС. В таких сетях SQL играет важнейшую роль и связывает приложение, выполняющееся на рабочей станции, и СУБД, управляющую совместно используемыми данными на сервере. Недавний взрыв популярности Internet и WWW еще больше усилил влияние SQL в сфере сетевых технологий. С появлением трехуровневой архитектуры Internet язык SQL стал связующим звеном между управляющим приложением (второй уровень — сервер приложений или Web-сервер) и сервером баз данных (третий уровень). В следующих параграфах мы поговорим о развитии архитектур сетевого управления базами данных и о роли, которую SQL играет в каждой из них.
Инструкции
В SQL существует приблизительно сорок инструкций. Каждая из них ''просит" СУБД выполнить определенное действие, например извлечь данные, создать таблицу или добавить в таблицу новые данные.
Каждая инструкция SQL начинается с команды, т.е. ключевого слова, описывающего действие, выполняемое инструкцией. Типичными командами являются create (создать), insert (добавить), delete (удалить) и commit (зафиксировать). После команды идет одно или несколько предложений. Предложение описывает данные, с которыми работает инструкция, или содержит уточняющую информацию о действии, выполняемом инструкцией. Каждое предложение также начинается с ключевого слова, такого как where (где), from (откуда), into (куда) и having (имеющий). Одни предложения в инструкции являются обязательными, а другие — нет. Конкретная структура и содержимое предложения могут изменяться. Многие предложения содержат имена таблиц или столбцов; некоторые из них могут содержать дополнительные ключевые слова, константы и выражения.
В стандарте ANSI/ISO определены ключевые слова, которые применяются в качестве команд и в предложениях инструкций. В соответствии со стандартом эти ключевые слова нельзя использовать для именования объектов базы данных, таких как таблицы, столбцы и пользователи. Во многих СУБД этот запрет ослаблен, однако следует избегать использования ключевых слов в качестве имен таблиц и столбцов. В табл. 5.2 перечислены ключевые слова, включенные в стандарт SQL2. Их почти в три раза больше, чем в SQL1. В стандарте SQL2 определен также список "потенциальных" ключевых слов, которые могут стать таковыми в будущих версиях стандарта (табл. 5.3).
Имена
У каждого объекта в базе данных есть уникальное имя. Имена используются в инструкциях SQL и указывают, над каким объектом базы данных инструкция должна выполнить действие. Основными именованными объектами в реляционной базе данных являются таблицы, столбцы и пользователи; правила их именования были определены еще в стандарте SQL1. В стандарте SQL2 этот список значительно расширен и включает схемы (коллекции таблиц), ограничения (ограничительные условия, накладываемые на содержимое таблиц и их отношения), домены (допустимые наборы значений, которые могут быть занесены в столбец) и ряд других объектов. Во многих СУБД существуют дополнительные виды именованных объектов, например хранимые процедуры (Sybase и SQL Server), отношения "первичный ключ — внешний ключ" (DB2) и формы для ввода данных (Ingres).
В соответствии со стандартом ANSI/ISO имена в SQL должны содержать от 1 до 18 символов, начинаться с буквы и не содержать пробелов или специальных символов пунктуации. В стандарте SQL2 максимальное число символов в имени увеличено до 128. На практике поддержка имен в различных СУБД реализована по-разному. В DB2, к примеру, имена пользователей не могут превышать 8 символов, но имена таблиц и столбцов могут быть более длинными. Кроме того, в различных СУБД существуют разные подходы к использованию в именах таблиц специальных символов. Поэтому для повышения переносимости лучше делать имена сравнительно короткими и избегать употребления в них специальных символов.
Имена таблиц
Если в инструкции указано имя таблицы, СУБД предполагает, что происходит обращение к одной из ваших собственных таблиц (т.е. таблиц, которые создали вы). Обычно таблицам присваиваются короткие, но описательные имена. В небольших базах данных, предназначенных для личного или группового использования, выбор имен зависит от разработчика базы данных. В более крупных, корпоративных базах данных могут существовать определенные корпоративные стандарты именования таблиц, позволяющие избежать конфликтов имен.
Большинство СУБД позволяют различным пользователям создавать таблицы с одинаковыми именами. Имея соответствующее разрешение, можно обращаться к таблицам, владельцами которых являются другие пользователи, с помощью полного имени таблицы. Оно состоит из имени владельца таблицы и собственно ее имени, разделенных точкой. Например, полное имя таблицы birthdays, владельцем которой является пользователь по имени sam, имеет следующий вид:
SAM.BIRTHDAYS
Полное имя таблицы можно использовать вместо короткого имени во всех инструкциях SQL.
Стандарт SQL2 еще больше обобщает понятие полного имени таблицы. Он разрешает создавать именованное множество таблиц, называемое схемой. Для доступа к таблице в схеме также применяется полное имя. Например, обращение к таблице birthdays, помещенной в схему employeeinfo, записывается так:
EMPLOYEEINFO.BIRTHDAYS
Имена столбцов
Если в инструкции задается имя столбца, СУБД сама определяет, в какой из указанных в этой же инструкции таблиц содержится данный столбец. Однако если в инструкцию требуется включить два столбца из различных таблиц, но с одинаковыми именами, необходимо указать полные имена столбцов, которые однозначно определяют их местонахождение. Полное имя столбца состоит из имени таблицы, содержащей столбец, и имени столбца (короткого имени), разделенных точкой. Например, полное имя столбца sales из таблицы salesreps имеет следующий вид:
SALESREPS.SALES
Если столбец находится в таблице, владельцем которой является другой пользователь, то в полном имени столбца следует указывать полное имя таблицы. Например, полное имя столбца вirth_date в таблице birthdays, владельцем которой является пользователь SAM, имеет следующий вид:
SAM.BIRTHDAYS.BIRTH_DATE
Полное имя столбца можно использовать вместо короткого имени во всех инструкциях SQL; об исключениях говорится при описании конкретных инструкций.
Контрольные вопросы
1. Стандарт SQL и переносимость приложений.
2. Перечислите основные проблемы переносимости.
3. Сформулируйте правила формирования имен объектов в SQL.
Лекция 3
Общее описание типов данных
В стандарте SQL1 был описан лишь минимальный набор типов данных, которые можно использовать для представления информации в реляционной базе данных. Они поддерживаются во всех коммерческих СУБД. Стандарт SQL2 добавил в этот список строки переменной длины, значения даты и времени и др. Современные СУБД позволяют обрабатывать данные самых разнообразных типов, среди которых наиболее распространенными являются:
• Целые числа. В столбцах, имеющих этот тип данных, обычно хранятся данные о ценах, количествах, возрасте сотрудников и т.д. Целочисленные столбцы часто используются также для хранения идентификаторов, таких как идентификатор клиента, служащего или заказа.
• Десятичные числа. В столбцах данного типа хранятся числа, имеющие дробную часть, но которые необходимо вычислять точно, например курсы валют и проценты. Кроме того, в таких столбцах часто хранятся денежные величины.
• Числа с плавающей запятой. Столбцы этого типа используются для хранения величин, которые можно вычислять приблизительно, например значения весов и расстояний. Числа с плавающей запятой могут представлять больший диапазон значений, чем десятичные числа, однако при вычислениях возможны погрешности округления.
• Строки символов постоянной длины. В столбцах, имеющих этот тип данных, обычно хранятся имена людей и компаний, адреса и т.п.
• Строки символов переменной длины. Столбцы этого типа позволяют хранить строки символов, длина которых изменяется в некотором диапазоне. В стандарте SQL1 были определены только строки постоянной длины, которые проще обрабатывать, но они требуют больше места для хранения.
Денежные величины. Во многих СУБД поддерживается тип данных money или CURRENCY, который обычно хранится в виде десятичного числа или числа с плавающей запятой. Наличие отдельного типа данных для представления денежных величин позволяет правильно форматировать их при выводе на экран.
Дата и время. Поддержка значений даты/времени также широко распространена в различных СУБД, хотя способы ее реализации довольно сильно отличаются друг от друга. Как правило, над значениями этого типа данных можно выполнять различные операции. Стандарт SQL2 включает определение типов данных date, time, timestamp и interval, а также поддержку часовых поясов и возможность указания точности представления времени (например, десятые или сотые доли секунды).
Булевы величины. Некоторые СУБД, например Informix Universal Server, явным образом поддерживают логические значения (TRUE или false), а другие СУБД разрешают выполнять в инструкциях SQL логические операции (сравнение, логическое И/ИЛИ и др.) над данными.
Длинный текст. Многие СУБД поддерживают столбцы, в которых хранятся длинные текстовые строки (обычно длиной до 32000 или 65000 символов, а в некоторых случаях и больше). Это позволяет хранить в базе данных целые документы. Как правило, СУБД запрещает использовать эти столбцы в интерактивных запросах.
Неструктурированные потоки байтов. Современные СУБД позволяют хранить и извлекать неструктурированные потоки байтов переменной длины. Столбцы, имеющие этот тип данных, обычно используются для хранения графических и видеоизображений, исполняемых файлов и других неструктурированных данных. К примеру, тип данных image в SQL Server позволяет хранить потоки данных размером до 2 миллиардов байтов.
Азиатские символы. В последнее время все больше поставщиков СУБД стали включать в свои продукты поддержку строк переменной и постоянной длины, содержащих символы азиатских алфавитов. Однако над такими строками, как правило, нельзя выполнять операции поиска и сортировки. В табл. 5.4 перечислены типы данных, определенные в стандарте ANSI/ISO.
Типы данных, появившиеся в SQL2
Различия в поддержке типов данных в разных СУБД существенно препятствуют переносимости приложений, в которых используется SQL. Причины подобных различий следует искать в самом пути, по которому развивались реляционные базы данных. Вот типичная схема:
• Поставщик СУБД добавил в свой продукт поддержку нового типа данных, который обеспечивает новые полезные возможности для определенной группы пользователей.
• Другой поставщик, оценив идею, ввел поддержку того же типа данных, но с небольшими модификациями, чтобы его нельзя было обвинить в слепом копировании.
• Если идея оказалась удачной, то по прошествии нескольких лет рассматриваемый тип данных появляется в большинстве ведущих СУБД, став частью "джентльменского набора" базовых типов данных.
• Далее этой идеей начинают интересоваться комитеты по стандартизации, чьей задачей является устранение произвольных различий в реализации идеи в ведущих СУБД. Но чем больше таких различий, тем труднее найти компромисс. Как правило, результатом деятельности комитета является вариант, который несоответствует ни одной из реализаций.
• Поставщики СУБД начинают внедрять поддержку полученного стандартизированного типа данных, но поскольку они располагают обширной базой уже инсталлированных продуктов, то вынуждены сопровождать и старый вариант типа данных.
• По прошествии длительного периода времени (обычно включающего выпуск нескольких новых версий СУБД) пользователи, наконец, полностью переходят к использованию стандартного варианта рассматриваемого типа данных, и поставщик СУБД начинает процесс исключения поддержки старого варианта из своего продукта.
В качестве примера рассмотрим форматы представления даты и времени в различных СУБД. Например, в DB2 существует сразу три типа данных:
• date — представляет дату, например "June 30, 1990";
• TIME — представляет время суток, например ''12:30 P.M.";
• timestamp — представляет конкретный момент времени с точностью до наносекунд.
Значения даты и времени можно представлять в виде строковых констант. Кроме того, поддерживаются арифметические операции над значениями даты. Ниже приведен пример допустимого запроса для СУБД DB2, в котором предполагается, что в столбце hire_date содержатся данные типа date:
SELECT NAME, HIRE_DATE
FROM SALESREPS WHERE HIRE_DATE >= '05/30/1990' + 15 DAYS
В СУБД SQL Server имеется единый тип данных для представления даты и времени — datetime, который напоминает тип данных timestamp из DB2. Если бы столбец hire_date имел тип datetime, в этой СУБД можно было бы выполнить такой запрос:
SELECT NAME, HIREJDATE
FROM SALESREPS WHERE HIRE_DATE >= '06/14/1990'
Поскольку в запросе не указано конкретное время, SQL Server по умолчанию примет, что время соответствует полуночи. Таким образом, запрос для SQL Server в действительности означает:
SELECT NAME, HIRE_DATE
FROM SALESREPS WHERE HIRE_DATE >= '06/14/1990 12:00AM’
Если информация о дате приема служащего на работу была сохранена в базе данных в полдень 14 июня 1990 года, то строка, содержащая сведения об этом человеке, не попадет в результаты запроса в SQL Server, однако попадет в результаты запроса в DB2 (поскольку эта СУБД оперировала бы только датой). Кроме того, SQL Server поддерживает арифметические операции над датами с помощью набора встроенных функций. Так, рассматривавшийся выше запрос из DB2 можно переписать для SQL Server следующим образом:
SELECT NAME^ HIRE_DATE
FROM SALESREPS WHERE HIRE__DATE >= DATEADD(DAY, 15, '05/30/1990')
Это, конечно же, значительно отличается от синтаксиса DB2.
СУБД Oracle также поддерживает единственный тип данных для представления даты и времени, который называется date. Как и тип данных datetime в SQLServer, тип данных date в Oracle фактически соответствует типу данных time stamp из DB2. Аналогично SQL Server, временная часть значения типа date по умолчанию принимается равной полуночи. Формат даты, принятый в Oracle по умолчанию, отличается от форматов, принятых в DB2 и SQL Server.
Типы данных
В языке SQL/89 поддерживаются следующие типы данных: CHARACTER, NUMERIC, DECIMAL,INTEGER, SMALLINT, FLOAT, REAL, DOUBLE PRECISION. Эти типы данных классифицируются на типы строк символов, точных чисел и приблизительных чисел. К первому классу относится CHARACTER. Спецификатор типа имеет вид CHARACTER (lenght), где lenght задает длину строк данного типа. Заметим, что в SQL/89 нет типа строк переменного размера, хотя во многих реализациях они допускаются. Литеральные строки символов изображаются в виде 'последовательность символов' (например, 'example'). Представителями второго класса типов являются NUMERIC, DECIMAL (или DEC), INTEGER (или INT) и SMALLINT. Спецификатор типа NUMERIC имеет вид NUMERIC [(precision [, scale]). Специфицируются точные числа, представляемые с точностью precision и масштабом scale. Здесь и далее, если опущен масштаб, то он полагается равным 0, а если опущена точность, то ее значение по умолчанию определяется в реализации.
Спецификатор типа DECIMAL (или DEC) имеет вид NUMERIC [(precision [, scale]). Специфицируются точные числа, представленные с масштабом scale и точностью, равной или большей значения precision. INTEGER специфицирует тип данных точных чисел с масштабом 0 и определяемой в реализации точностью. SMALLINT специфицирует тип данных точных чисел с масштабом 0 и определяемой в реализации точностью, не большей, чем точность чисел типа INTEGER. Литеральные значения точных чисел в общем случае представляются в форме
[+|-] <целое-без-знака> [.<целое-без-знака>].
Наконец, в классу типов данных приблизительных чисел относятся типы FLOAT, REAL и DOUBLE PRECISION. Спецификатор типа FLOAT имеет вид FLOAT [(precision)]. Специфицируются приблизительные числа с двоичной точностью, равной или большей значения precision.
REAL специфицирует тип данных приблизительных чисел с точностью, определенной в реализации. DOUBLE PRECISION специфицирует тип данных приблизительных чисел с точностью, определенной в реализации, большей, чем точность типа REAL. Литеральные значения приблизительных чисел в общем случае представляются в виде
<литеральное-значение-точного-числа> E <целое-со-знаком>.
Заметим, что хотя с использованием языка SQL можно определить схему БД, содержащую данные любого из перечисленных типов, возможность использования этих данных в прикладных системах зависит от применяемого языка программирования. Весь набор типов данных можно использовать, только если программировать на ПЛ/1. Поэтому в некоторых реализациях SQL типы данных с масштабом и точностью вообще не поддерживаются.
Хотя правила встраивания SQL в программы на языке Си не определены в SQL/89, в большинстве реализаций, поддерживающих такое встраивание, имеется следующее соответствие между типами данных SQL и типами данных Си: CHARACTER соответствует строкам Си; INTEGER соответствует long; SMALLINT соответствует short; REAL соответствует float; DOUBLE PRECISION соответствует double(именно такое соответствие утверждено в стандарте SQL/92).
Заметим еще, что в большинстве реализаций SQL поддерживаются некоторые дополнительные типы данных, например, DATE, TIME, INTERVAL, MONEY. Некоторые из этих типов специфицированы в стандарте SQL/92, но в текущих реализациях синтаксические и семантические свойства таких типов могут различаться.
В качестве примера практической реализации стандарта, рассмотрим типы данных поддерживаемых СУБД SQL Anywhere.
В SQL Anywhere типы хранимых данных можно объединить в следующие категории :
Символьные типы данных: для хранения строк символов и цифр .
Типы данных Character
CHAR [ ( max-length ) ]
| CHARACTER [ ( max-length ) ]
| CHARACTER VARYING [ ( max-length ) ]
| LONG VARCHAR
| VARCHAR [ ( max-length ) ]
Описание
CHAR [(max-length)] Символьные данные с длиной не превышающей max-length. Если max-length не указана, по умолчанию принимается 1. Максимальное значение 32,767.
CHARACTER [(max-length)] Тоже что CHAR[(max-length)].
VARCHAR [(max-length)] Тоже что CHAR[(max-length)].
CHARACTER VARYING[(max-length)] Тоже что CHAR[(max-length)].
LONG VARCHAR Символьные данные произвольной длины. Максимальный размер ограничен размером файла базы данных (2GB для версии 5.5).
Числовые типы данных - для хранения числовых данных.
Типы данных Numeric
DECIMAL [ ( длина [ , точность ] ) ]
| DOUBLE
| FLOAT [ (длина ) ]
| INT
| INTEGER
| NUMERIC [ (длина [ , точность ] ) ]
| REAL
| SMALLINT
Описание
INT Целое число со знаком максимальное значение 2,147,483,647 занимает 4 байта.
INTEGER Тоже что INT.
SMALLINT Целое число со знаком максимальное значение 32,767 занимает 2 байта.
DECIMAL [ ( длина [ , точность ] )] Десятичное число из <длина> цифр и <точность> - число знаков после десятичной точки. Значения по умолчанию <точность> = 6 and <длина> = 30.
Количество требуемой памяти можно вычислить по формуле:
2 + int( (before+1) / 2 ) + int( (after+1)/2 )
NUMERIC [ (длина [ , точность ] ) ] Тоже что DECIMAL.
FLOAT [ ( длина ) ] Если длина не указана, тип дынных FLOAT аналогичен типу REAL. Если <длина> указана, тип FLOAT аналогичен REAL или DOUBLE , в зависимости от значения <длины>.
Тип FLOAT поддерживается на всех платформах. Типы REAL и DOUBLE зависят от реализации .
DOUBLE занимает 8 байт. Диапазон значений от 2.22507385850720160e-308 до 1.79769313486231560e+308. Точность DOUBLE до 15 значащих цифр.
REAL Занимает 4 байта. Диапазон значений от 1.175494351e-38 до 3.402823466e+38. Точность REAL до 6 значащих цифр.
Типы данных для хранения даты и времени.
Типы данных Date и time
DATE
| TIME
| TIMESTAMP
Описание:
DATE – предназначен для хранения календарной даты. Значение года может быть от 0001 до 9999. Тип DATE требует 4 байта.
TIMESTAMP – “момент времени” – содержит год, месяц, день, час, минуты, секунды и доли секунд. Тип DATE требует 8 байт памяти.
Типы данных Binary data
Бинарные(Двоичные) типы данных - для хранения двоичных данных, таких как изображения, документы и другие данные которые не интерпретируются СУБД(передаются пользователю только как единое целое для обработки).
BINARY [ ( max-length ) ]
| LONG BINARY
Описание
BINARY [(max-length)] Бинарные данные длиной не более max-length (в байтах). Если размер не указан, по умолчанию принимается 1. Максимально допустимый размер 32767. Тип BINARY аналогичен типу CHAR исключая операции сравнения.
LONG BINARY Двоичные данные произвольной длины. Максимальный размер ограничен размером файла БД (2 GB для файловой системы файл).
Тип данных определенные пользователем (User-defined)
Типы данных определенные пользователем (иногда называемые доменами). Являются псевдонимами для встроенных типов данных, включая длину и количество знаков после запятой (длину символьного выражения и тд). Дополнительно могут быть указаны DEFAULT -значения условия проверки CHECK. (И ограничения NOT Null)
Создаются оператором Create datatype.
Пример: создается тип данных street_address, который является символьными строками длиной 35 символов.
CREATE DATATYPE street_address CHAR( 35 )
Созданный тип данных может использоваться также как все встроенные типы данных.
Для удаления пользовательского типа данных используется оператор DROP DATATYPE :
DROP DATATYPE street_address
Контрольные вопросы
1. Типы данных поддерживаемые в различных стандартах SQL.
2. Перечислите числовые типы данных.
3. Перечислите типы данных для хранения символьных строк.
4. Типы данных для хранения календарных дат и времени.
Лекция 4
Лекция 5
<between predicate> ::=
<value expression>
[NOT] BETWEEN <value expression1> AND <value expression2>
Другой формой условия отбора является проверка на принадлежность диапазону значений (оператор between. . .and). При этом проверяется, находится ли элемент данных между двумя заданными значениями. В условие отбора входят три выражения. Первое выражение определяет проверяемое значение; второе и третье выражения определяют верхний и нижний пределы проверяемого диапазона. Типы данных трех выражений должны быть сравнимыми.
При проверке на принадлежность диапазону верхний и нижний пределы считаются частью диапазона.
Инвертированная версия проверки на принадлежность диапазону позволяет выбрать значения, которые лежат за пределами диапазона, используя NOT BETWEEN.
Поверяемое выражение, заданное в операторе between. . .and, может быть любым допустимым выражением, однако на практике оно обычно представляет собой короткое имя столбца.
В стандарте ANSI/ISO определены относительно сложные правила обработки значений null в проверке between:
• если проверяемое выражение имеет значение null либо если оба выражения, определяющие диапазон, равны null, то проверка between возвращает "unknown";
• если выражение, определяющее нижнюю границу диапазона, имеет значение null, то проверка between возвращает false, когда проверяемое значение больше верхней границы диапазона, и "unknown" в противном случае;
• если выражение, определяющее верхнюю границу диапазона, имеет значение null, то проверка between возвращает false, когда проверяемое значение меньше нижней границы диапазона, и "unknown" в противном случае.
Однако прежде чем полагаться на эти правила, неплохо провести эксперименты со своей СУБД.
Необходимо отметить, что проверка на принадлежность диапазону не расширяет возможности SQL, поскольку ее можно выразить в виде двух сравнений.
Тем не менее, проверка between является более простым способом выразить условие отбора в терминах диапазона значений.
<in predicate> ::=
<value expression> [NOT] IN { <subquery> | (<in value list>) }
<in value list> ::=
<value specification>
{ ,<value specification> }...
Еще одним распространенным условием отбора является проверка на членство в множестве (оператор IN). В этом случае проверяется, соответствует ли элемент данных какому-либо значению из заданного списка.
С помощью проверки not in можно убедиться в том, что элемент данных не является членом заданного множества. Проверяемое выражение в операторе in может быть любым допустимым выражением, однако обычно оно представляет собой короткое имя столбца, как в предыдущих примерах. Если результатом проверяемого выражения является значение null, то проверка IN возвращает "unknown". Все элементы в списке заданных значений должны иметь один и тот же тип данных, который должен быть сравним с типом данных проверяемого выражения.
Как и проверка between, проверка IN не добавляет в возможности SQL ничего нового, поскольку условие
X IN (А, В, С)
полностью эквивалентно условию
(X = A) OR (X = В) OR (X = С)
Однако проверка in предлагает гораздо более эффективный способ выражения условия отбора, особенно если множество содержит большое число элементов. В стандарте ANSI/ISO не определено максимальное количество элементов множества, и в большинстве СУБД не задан явно верхний предел. По соображениям переносимости лучше избегать множеств, содержащих один элемент, наподобие такого:
CITY IN ('New York1)
Их следует заменять следующим простым сравнением:
CITY = 'New York'
<like predicate> ::=
<column specification> [NOT] LIKE <pattern>
[ESCAPE <escape character>]
<pattern> ::=
<value specification>
< escape character > ::=
< value specification >
Для выборки строк, в которых содержимое некоторого текстового столбца совпадает с заданным текстом, можно использовать простое сравнение.
Проверка на соответствие шаблону позволяет выбрать из базы данных строки на основе их частичного соответствия.
Поверка на соответствие шаблону (оператор like), соответствует ли значение данных в столбце некоторому шаблону. Шаблон представляет собой строку, в которую может входить один или более подстановочных знаков(символов обобщения). Эти знаки интерпретируются особым образом.
Подстановочные знаки
Подстановочный знак % совпадает с любой последовательностью из нуля или более символов.
Оператор like указывает СУБД, что необходимо сравнивать содержимое указанного столбца с шаблоном заданным символьной строкой.
Подстановочный знак _ (символ подчеркивания) совпадает с любым отдельным символом в указанной позиции в строке.
Подстановочные знаки можно помещать в любое место строки шаблона, и в одной строке может содержаться несколько подстановочных знаков.
С помощью формы not like можно находить строки, которые не соответствуют шаблону. Проверку like можно применять только к столбцам, имеющим строковый тип данных. Если в столбце содержится значение null, то результатом проверки like будет "unknown".
Вероятно, вы уже встречались с проверкой на соответствие шаблону в операционных системах, имеющих интерфейс командной строки (Unix, MS-DOS). В этих системах звездочка (*) используется для тех же целей, что и символ процента (%) в SQL, а вопросительный знак (?) соответствует символу подчеркивания (_) в SQL, но в целом возможности работы с шаблонами строк в них такие же
Символы пропуска
При проверке строк на соответствие шаблону может оказаться, что подстановочные знаки входят в строку символов в качестве литералов. Например, нельзя проверить, содержится ли знак процента в строке, просто включив его в шаблон, поскольку СУБД будет считать этот знак подстановочным. Как правило, это не вызывает серьезных проблем, поскольку подстановочные знаки довольно редко встречаются в именах, названиях товаров и других текстовых данных, которые обычно хранятся в базе данных.
В стандарте ANSI/ISO определен способ проверки наличия в строке литералов, использующихся в качестве подстановочных знаков. Для этого применяются символы пропуска. Когда в шаблоне встречается такой символ, то символ, следующий непосредственно за ним, считается не подстановочным знаком, а литералом (происходит пропуск символа ) Непосредственно за символом пропуска может следовать либо один из двух подстановочных знаков, либо сам символ пропуска, поскольку он тоже приобретает в шаблоне особое значение.
Символ пропуска определяется в виде строки, состоящей из одного символа, и предложения escape. Ниже приведен пример использования знака доллара ($) в качестве символа пропуска:
Найти товары, коды которых начинаются с четырех букв "А%ВС\
SELECT ORDER_NUM, PRODUCT
FROM ORDERS WHERE PRODUCT LIKE 'A$%BC%' ESCAPE '$'
Первый символ процента в шаблоне, следующий за символом пропуска, считается литералом, второй — подстановочным знаком
Символы пропуска часто используются при проверке на соответствие шаблону, именно поэтому они были включены в стандарт ANSI/ISO. Однако они не входили в первые реализации SQL и поэтому не очень распространены. Для обеспечения переносимости приложений следует избегать использования предложения escape.
< null predicate > ::=
< column specification > IS [ NOT ] NULL
Значения null обеспечивают возможность применения трехзначной логики в условиях отбора. Для любой заданной строки результат применения условия отбора может быть true, false или null (в случае, когда в одном из столбцов содержится значение null) Иногда бывает необходимо явно проверять значения столбцов на равенство null и непосредственно обрабатывать их. Для этого в SQL имеется специальная проверка is null.
В следующем запросе проверка на null используется для нахождения в учебной базе данных служащего, который еще не был закреплен за офисом:
Найти служащего, который еще не закреплен за офисом.
SELECT NAME
FROM SALESREPS WHERE REP_OFFICE IS NULL
Инвертированная форма проверки на null (is not null) позволяет отыскать строки, которые не содержат значений null.
В отличие от условий отбора, описанных выше, проверка на null не может возвратить значение "unknown" в качестве результата. Она всегда возвращает true или false
Может показаться странным, что нельзя проверить значение на равенство null с помощью операции сравнения, например-
select name
from salespers where rep_office = null
Ключевое слово null здесь нельзя использовать, поскольку на самом деле это не настоящее значение; это просто сигнал о том, что значение неизвестно. Даже если бы сравнение
REP_OFFICE = NULL
было возможно, правила обработки значений null в сравнениях привели бы к тому, что оно вело бы себя не так, как ожидается. Если бы СУБД обнаружила строку, в которой столбец rep_office содержит значение null, выполнилась бы следующая проверка:
NULL = NULL
Что будет результатом этого сравнения: true или FALSE? Так как значения по обе стороны знака равенства неизвестны, то, в соответствии с правилами логики SQL, условие отбора должно вернуть значение "unknown". Поскольку условие отбора возвращает результат, отличный от true, строка исключается из таблицы результатов запроса. Из-за правил обработки значений null в SQL необходимо использовать проверку is null.
<quantified predicate> ::=
<value expression>
<comp op> <quantifier> <subquery>
<quantifier> ::=
<all> | <some>
<all> ::= ALL
<some> ::= SOME | ANY
Многократное сравнение (предикаты ANY и ALL) *
В проверке in выясняется, не равно ли некоторое значение одному из значений, содержащихся в столбце результатов подчиненного запроса. В SQL имеются также две разновидности многократного сравнения — any и all, расширяющие предыдущую проверку до уровня других операторов сравнения, таких как больше (>) или меньше (<). Обе этих проверки сравнивают некоторое значение со столбцом данных, отобранных подчиненным запросом.
Предикат ANY.
В проверке ANY, для того чтобы сравнить проверяемое значение со столбцом данных, отобранных подчиненным запросом, используется один из шести операторов сравнения (=, <>, <, <=, >, >=). Проверяемое значение поочередно сравнивается с каждым элементом, содержащимся в столбце. Если любое из этих сравнений дает результат true, то проверка any возвращает значение true.
В соответствии со стандартом ANSI/ISO вместо предиката ANY можно использовать предикат some. Обычно можно употреблять любой из них, но некоторые СУБД не поддерживают предикат SOME.
Иногда проверка any может оказаться трудной для понимания, поскольку включает в себя не одно сравнение, а несколько.
Если подчиненный запрос в проверке ANY не создает ни одной строки или если столбец результатов содержит значения NULL, то в различных СУБД проверка ANY может выполняться по-разному. В стандарте ANSI/ISO для языка SQL содержатся подробные правила, определяющие результаты проверки any, когда проверяемое значение сравнивается со столбцом результатов подчиненного запроса.
• Если подчиненный запрос возвращает результат в виде пустого столбца, то проверка any возвращает значение false (в результате выполнения подчиненного запроса не получено ни одного значения, для которого выполнялось бы условие сравнения).
• Если операция сравнения имеет значение TRUE хотя бы для одного значения в столбце, то проверка any возвращает значение true (имеется некоторое значение, полученное подчиненным запросом, для которого условие сравнения выполняется).
• Если операция сравнения имеет значение FALSE для всех значений в столбце, то проверка ANY возвращает значение FALSE (можно утверждать, что ни для одного значения, возвращенного подчиненным запросом, условие сравнения не выполняется).
• Если операция сравнения не имеет значение TRUE ни для одного значения в столбце, но в нем имеется одно или несколько значений NULL, то проверка ANY возвращает результат "unknown". (В этой ситуации невозможно с определенностью утверждать, существует ли полученное подчиненным запросом значение, для которого выполняется условие сравнения; может быть, существует, а может и нет — все зависит от "настоящих" значений неизвестных данных.)
На практике проверка ANY иногда может приводить к ошибкам, которые трудно выявить, особенно когда применяется оператор сравнения "не равно" (<>).
Запрос с предикатом ANY всегда можно преобразовать в запрос с предикатом exists, перенося операцию сравнения внутрь условия отбора подчиненного запроса. Обычно так и следует поступать, поскольку в этом случае исключаются ошибки.
Предикат ALL
В проверке all, как и в проверке any, используется один из шести операторов (=> <>, <, <=, >, >=) для сравнения проверяемого значения со столбцом данных, отобранных подчиненным запросом. Проверяемое значение поочередно сравнивается с каждым элементом, содержащимся в столбце. Если все сравнения дают результат true, то проверка all возвращает значение true.
Проверка all, подобно проверке any, может оказаться трудной для понимания, поскольку включает в себя не одно сравнение, а несколько. Опять-таки, если читать условие сравнения немного иначе, то это помогает понять его смысл. Например, проверку
WHERE X < ALL (SELECT Y...)
следует читать не как
"где X меньше, чем все выбранные Y..." а так'
"где для всех Y X меньше, чем Y...".
Если подчиненный запрос в проверке all не возвращает ни одной строки или если столбец результатов запроса содержит значения null, то в различных СУБД проверка all может выполняться по-разному. В стандарте ANSI/ISO для языка SQL содержатся подробные правила, определяющие результаты проверки all, когда проверяемое значение сравнивается со столбцом результатов подчиненного запроса.
• Если подчиненный запрос возвращает результат в виде пустого столбца, то проверка all возвращает значение true. Считается, что условие сравнения выполняется, даже если результаты подчиненного запроса отсутствуют.
• Если операция сравнения дает результат true для каждого значения в столбце, то проверка ALL возвращает значение TRUE. Условие сравнения выполняется для каждого значения, возвращенного подчиненным запросом.
• Если операция сравнения дает результат false для какого-нибудь значения в столбце, то проверка all возвращает значение false. В этом случае можно утверждать, что условие сравнения выполняется не для каждого значения, возвращенного подчиненным запросом.
• Если операция сравнения не дает результат FALSE ни для одного значения в столбце, но для одного или нескольких значений дает результат null, то проверка all возвращает значение "unknown". В этой ситуации нельзя с определенностью утверждать, для всех ли значений, возвращенных подчиненным запросом, справедливо условие сравнения; может быть, для всех, а может и нет — все зависит от "настоящих" значений неизвестных данных.
Ошибки, которые могут случиться, если проверка ANY содержит оператор сравнения "не равно" (<>), происходят и в проверке all. Проверку all, так же как и проверку any, всегда можно преобразовать в эквивалентную проверку на существование (exists), перенеся операцию сравнения в подчиненный запрос.
< exists predicate > ::=
EXISTS < subquery >
Проверка на существование (предикат EXISTS)
В результате проверки на существование (предикат EXISTS) можно выяснить, содержится ли в таблице результатов подчиненного запроса хотя бы одна строка. Аналогичной простой проверки не существует. Проверка на существование допустима только в подчиненных запросах.
Вот пример запроса, который можно легко сформулировать, используя проверку на существование:
"Вывести список товаров, на которые получен заказ стоимостью $25000 или больше".
Теперь перефразируем этот запрос таким образом:
"Вывести список товаров, для которых в таблице ORDERS существует по крайней мере один заказ, удовлетворяющий условиям: а) является заказом на данный товар; б) имеет стоимость не менее чем $25000".
Инструкция SELECT, используемая для получения требуемого списка товаров, приведена ниже:
SELECT DESCRIPTION
FROM PRODUCTS WHERE EXISTS (SELECT ORDER_NOM
FROM ORDERS
WHERE PRODUCT = PRODUCT_ID AND MFR = MFR_ID AND AMOUNT >= 25000.00)
Главный запрос последовательно перебирает все строки таблицы products, и для каждого товара выполняется подчиненный запрос. Результатом подчиненного запроса является столбец данных, содержащий номера всех заказов "текущего" товара на сумму не меньше чем $25000. Если такие заказы есть (т.е. столбец не пустой), то проверка exists возвращает true. Если подчиненный запрос не дает ни одной строки заказов, проверка exists возвращает значение false. Эта проверка не может возвращать null.
Можно изменить логику проверки exists и использовать форму not exists. Тогда в случае, если подчиненный запрос не создает ни одной строки результата, проверка возвращает true, в противном случае — false.
Обратите внимание на то, что предикат EXISTS в действительности вовсе не использует результаты подчиненного запроса. Проверяется только наличие результатов. По этой причине в SQL смягчается правило, согласно которому "подчиненный запрос должен возвращать один столбец данных", и в подчиненном запросе проверки exists допускается использование формы select *. Поэтому предыдущий запрос можно переписать/следующим образом:
Вывести список товаров, на которые получен заказ стоимостью $25000 или больше .
SELECT DESCRIPTION
FROM PRODUCTS
WHERE EXISTS (SELECT *
FROM ORDERS
WHERE PRODUCT = PRODUCT_ID
AND MFR = MFR_ID
AND AMOUNT >= 25000.00)
На практике при использовании подчиненного запроса в проверке exists всегда применяется форма select *.
Отметим, что в приведенном примере подчиненный запрос содержит внешнюю ссылку на столбец таблицы из главного запроса. На практике в подчиненном запросе проверки exists всегда имеется внешняя ссылка, "связывающая" подчиненный запрос со строкой, проверяемой в настоящий момент главным запросом.
Контрольные вопросы
1. Назначение предиката Between в инструкции Where.
2. Назначение предиката In в инструкции Where.
3. Назначение предиката Like в инструкции Where, как используются замещающие символы.
4. Функции выполняемые предикатом Exists.
Лекция 6
Составные условия отбора (AND OR NOT)
Для образования сложных условий отбора данных рассмотренные выше предикаты могут объединяться с использованием логических операций (AND OR NOT).
Т.к. в SQL принята трехзначная логика рассмотрим таблицы истинности этих операций для различных сочетаний аргументов.
| AND | T | F | Null |
| T | T | F | U |
| F | F | F | F |
| Null | U | F | U |
| OR | T | F | Null |
| T | T | T | T |
| F | T | F | U |
| Null | T | U | U |
| NOT | T | F | Null |
| F | T | U |
Агрегатные функции в предложении select
Агрегатные функции применяются для обобщения значений 1-го поля, они дают единственное значение для целой группы строк таблицы.
Функции: COUNT() - определяет количество строк или значений поля, выбранных посредством запроса и не являющихся NULL - значениями.
COUNT(*) - общее количество строк, включая строки являющиеся NULL - значениями.
SUM(<имя поля>) - вычисляет арифметическую сумму всех выбранных значений данного поля.
AVG(<имя поля>) - вычисляет среднее значение для всех выбранных значений данного поля.
MAX(<имя поля>) - вычисляет наибольшее из всех выбранных значений данного поля.
MIN(<имя поля>) - вычисляет наименьшее для всех выбранных значений данного поля.
Функции агрегирования используются как имена полей в предложении SELECT, имена столбцов таблиц используются как аргументы этих функций.
Функции AVG, SUM работают только с числовыми типами данных. Функции COUNT, MAX, MIN могут использовать числовые и символьные поля в качестве аргументов. В случае применения MIN или MAX к символьным полям MIN выбирает 1-е значение (наименьшее) в соответствии с алфавитным порядком, MAX - последнее(наибольшее) значение в соответствии с алфавитным порядком.
EX:
Найти суммарный вес всех деталей:
SELECT SUM(Weight) From Parts
Агрегатные функции и Null значения
Лекция 7
Подзапрос должен выбирать только одну (или ни одной - значение предиката -unknown) записи если выбирается несколько записей - подзапрос оценивается как ошибочный;
Предикаты с подзапросами являются неперемещаемыми.
Предикаты, включающие подзапросы, используют форму <скалярное выражение> <оператор сравнения> <подзапрос>.
Конструкции <подзапрос> <оператор> <скалярное выражение> или <подзапрос> <оператор> <подзапрос> недопустимы.
Использование агрегатных функций в подзапросах.
Одним из видов функций, которые автоматически выдают единственное значение для любого количества строк - являются агрегатные функции. Любой запрос, использующий единственную агрегатную функцию без предложения GROUP BY, дает в результате единственное значение для использования его в основном предикате.
EX ?
SELECT * FROM Orders
WHERE amt >
(SELECT AVG(amt)
FROM Orders
WHERE Odate = 02/28/2011)
При применении предложения GROUP BY агрегатные функции могут дать в результате множество значений. Поэтому их нельзя применять в подзапросах.
Такие команды отвергаются в принципе(при синтаксическом разборе запроса - без выборки данных). Несмотря на то, что применение GROUP BY и HAVING в некоторых случаях дает единственную группу в качестве результата подзапроса.
Использование подзапросов возвращающих более одной строки.
Для использования подзапросов возвращающих более одной записи можно применить оператор IN во внешнем запросе. (Нельзя применять BEETWEEN, LIKE, IS NULL) . IN - определяет множество значений, которые тестируются на совпадение с другими значениями для определения истинности предиката. Когда IN применяется
с подзапросом SQL строит это множество из выходных данных этого подзапроса.
Orders
| U_id | Sl_num | Part | Amt | Odate | Client_num |
| N10 | N5 | N5 | N10.2 | D8 | N5 |
Структура справочников:
| Clients | |
| client_num | N4 |
| Nam_val | C15 |
| Sales_p | |
| Sl_num | N6 |
| Sl_nam | C15 |
| Sl_city | C20 |
Найти все заказы для продавцов из Москвы
SELECT *
FROM Orders
WHERE Sl_num IN
(SELECT sl_num
FROM Sales_p
WHERE Sl_city=‘Москва’)
Данную задачу можно решить с использованием Join
SELECT Orders.U_id, Orders.part, Sales_p.sl_nam
FROM Orders, Sales_p
WHERE Orders.Sl_num = Sales_p.sl_num
AND Sales_p.Sl_city = ‘Москва’
(Достоинства и недостатки: результаты запроса непосредственно не видны и если есть ошибки в данных обнаружить их будет трудно).
Результат работы этих запросов должен быть одинаковым (с точностью до столбцов).
Эффективность: оптимизатор, зависящий от реализации, join -> подзапрос
Общим во всех рассмотренных подзапросах было использование в качестве результата единственного столбца. Это необходимо - поскольку выходные данные подзапроса сравниваются с единственным значением. Следовательно, вариант SELECT * нельзя использовать в подзапросе. (Исключением являются подзапросы с оператором EXISTS)
Связанные подзапросы
При использовании подзапросов во внутреннем запросе можно ссылаться на таблицу, имя которой указано в предложении FROM внешнего запроса. В этом случае внутренний подзапрос называется связанным подзапросом. При выполнении оператора подзапрос выполняется для каждой строки таблицы из основного запроса.
Строка внешнего запроса, для которой выполняется внутренний запрос, называется текущей строкой - кандидатом.
Алгоритм выполнения связанного подзапроса состоит в следующем:
1. Выбрать строку из таблицы, имя которой указано во внешнем запросе. Это текущая строка-кандидат.
2. Сохранить значения этой строки в алиасе, имя которого указано в предложении FROM внешнего запроса.
3. Выполнить подзапрос. Использование в подзапросе значения из строки-кандидата внешнего запроса называется внешней ссылкой.
4. Оценить предикат внешнего запроса на основе результатов подзапроса, выполненного на шаге 3. Это позволяет определить, будет ли строка кандидат включена в состав выходных данных.
5. Повторять процедуру для следующей строки-кандидата таблицы до тех пор, пока не будут проверены все строи в таблице.
Найти всех клиентов сделавших заказы 26.02.11
SELECT * FROM Clients as outer
WHERE 26/02/2011 IN
(SELECT Odate FROM Orders as inner
WHERE inner.Client_num =outer.Client_num )
Orders
| U_id | Sl_num | Part | Amt | Odate | Client_num |
| N10 | N5 | N5 | N10.2 | D8 | N5 |
Структура справочников:
| Clients | |
| client_num | N4 |
| Nam_val | C15 |
| Sales_p | |
| Sl_num | N6 |
| Sl_nam | C15 |
| Sl_city | C20 |
insert into secondpart (uniq_id)
select firstpart.uniq_id from firstpart
where
not exists
(Select seconpart.uniq_id from secondpart Where
firstpart.uniq_id = secondpart.uniq_id )
Рассмотрим в подробностях пример записанный выше.
Добавляет записи во вторую таблицу с кодом uniq_id - такие что, записи с этим uniq_id существуют в первой части (first_part) и не существуют во второй.
Оператор Select используемый в операторе Insert в свою очередь использует связанный подзапрос для нахождения таких строк из первой таблицы для которых нет соответствия во второй. Результатом выполнения оператора Select является столбец из uniq_id’ов которые добавляются во вторую таблицу. Для оценки результатов самого внутреннего запроса используется оператор EXISTS.
EXISTS - оператор, применяемый для образования предиката, фиксирующего будет ли подзапрос генерировать выходные данные.
EXISTS - принимает значение “истина” если подзапрос используемый в качестве аргумента генерирует выходные данные, и “ложь” в противном случае. В отличии от прочих операторов и предикатов, он не может принимать значения “неизвестно” (unknown). В примере EXISTS выбирает один столбец, аналогично предыдущим примерам. На самом деле несущественно сколько столбцов извлекает EXISTS поскольку он не применяет полученных значений, а только фиксирует наличие данных.
При применении связанных подзапросов предложение EXISTS оценивается отдельно для каждой строки таблицы на которую есть ссылка во внешнем запросе.
Объединение результатов множества запросов в один.
Все предшествующие примеры показывают различные варианты запросов с расположением “один внутри другого”. Существует другой способ объединения множества запросов - их объединение с использованием предложения UNION.
Объединения (unions) отличаются от подзапросов тем, что любой из запросов не может управлять другим запросом. В объединении все запросы выполняются независимо, но их выходные данные затем объединяются. UNION объединяет выходные данные двух или более SQL - запросов в единое множество строк и столбцов.
Для выполнения команды UNION столбцы запросов входящие в состав выходных данных должны быть совместимы по объединению (union compatible).
- одинаковое количество столбцов (столбцы должны быть сравнимы по объединению)
Одинаковые типы данных(тип и длина - числовые)
Для символьных данных (тип и длина - строгость ограничений зависит от конкретного продукта )
Если для одного столбца установлено ограничение NOT NULL то это ограничение должно быть у соответствующих столбцов других запросов.
Синтаксис:
select -without-order-by
... UNION [ALL] select-without-order-by
... [ UNION [ALL] select-without-order-by ] ...
... [ ORDER BY integer [ ASC | DESC ], ... ]
Для повышения наглядности (и удобства) (например, комментарии из какого конкретно запроса получена данная строка) можно вставлять константы и выражения в операторы select использующие Union. При этом константы должны удовлетворять условиям сравнимости.
alter procedure
yura.get_param(in sta_ char(15),in typ char(20),in metall char(15),in otpr char(20),in pol char(20),in otvets char(20),in from_ char(20),in to_ char(20),in stn_o char(20),in stn_n char(20),in kontr char(20))
result(stats smallint,"\\x27num_fr\\x27" char(6))
begin
(select status.stats,'status' from status
where status.name_s=sta_
union
select types.typ_num,'types ' from types
where types.name_t=typ
union
select owners.own_num,'owners' from owners
where owners.name_otv=otvets
order by 2 asc
Команды изменения данных DML
Команда добавления новых записей в таблицу.
Format 1
INSERT INTO [ owner.]table-name [( column-name, ... )]
... VALUES ( expression | DEFAULT, ... )
Format 2
INSERT INTO [ owner.]table-name [( column-name, ... )]
... select-statement
Назначение
Для добавления одной записи используется формат 1.
Предложение DEFAULT может быть использовано для присвоения столбцу значений заданных для него по умолчанию. Если необязательный список имен столбцов задан то, значения из списка переносятся в указанные столбцы. Если список столбцов не указан - значения записываются в столбцы в том порядке в котором они были созданы ( такой же порядок получается при использовании SELECT *). Записи добавляются в таблицу в произвольную позицию. (В реляционных БД таблицы не упорядочены.)
Insert в формате 2 используется для добавления результатов запроса в указанную таблицу.
Ограничения доступа:
Пользователь должен иметь доступ по INSERT к указанной таблице table.
Формат 2 позволяет пользователю одной операцией добавлять в таблицу результаты сгенерированные оператором SELECT общего вида(без ограничений).Записи добавляются в произвольном порядке вне зависимости от того содержит ли оператор SELECT предложение ORDER BY. Столбцы в операторе SELECT должны совпадать со столбцами указанными в списке оператора INSERT или физическому порядку столбцов в таблице.( порядку в котором они были созданы ( такой же порядок получается при использовании SELECT *)).
Examples
Insert into Fam Values (123,’Склеймин’)
Вставка NULL значений
В команде Insert могут быть указаны имена столбцов:
Insert into Fam(fam_cod,fam_val) Values (123,’Склеймин’)
INSERT INTO department ( dept_id, dept_name )
VALUES ( 230, 'Eastern Sales' )
Команда обновления значений столбцов
UPDATE table-list
... SET column-name = expression, ...
... [ WHERE search-condition ]
... [ ORDER BY expression [ ASC | DESC ] ,... ]
Ограничение по правам доступа:
Для пользователя д.б. разрешено выполнения UPDATE для тех столбцов которые он пытается модифицировать..
Оператор UPDATE используется для изменения строк одной или более таблиц.(в новых стандартах и реализациях)
Стандарт SQL(старый) не допускает изменения нескольких таблиц одной командой Update, т.к. в выражении <column-name> нельзя указывать имя таблицы.
Каждый указанный столбец принимает значение выражения указанного справа от знака равенства. Структура выражения никак не ограничена. <column-name> может быть использовано в выражении — существующие значение будет использовано.
Если предложение Where не указано будут изменены все записи в таблице.
Если Where присутствует в команде - будут обновлены только те записи которые удовлетворяют предикату <search-cond>.
Предложение ORDER BY -используется редко,- в специальных случаях -например увеличение на 1 первичного ключа(для избежания ошибки дублирования значения первичного ключа) .
Update разрешает использование подзапросов внутри предиката.
Счета в таблице нумеруются начиная с ID 2001.
Запрос перенумеровывает все существующие счета вычитанием 2000 из поля id.
UPDATE sales_order_items AS items ,
sales_order AS orders
SET items.id = items.id - 2000,
orders.id = orders.id - 2000 ;
Update cust Set raiting=200
Обновление нескольких столбцов одной командой
Update cust Set raiting=200, city=‘Москва’ WHERE snum=101
В команде можно использовать выражения для вычисления значений которые будут присвоены указанным столбцам.
Контрольные вопросы
1. В чем особенность выражений с подзапросами?
2. Каковы преимущества использования агрегатных функций в подзапросах?
3. Сформулируйте алгоритм выполнения связанных подзапросов.
4. Перечислите ограничения при выполнении оператора Union.
5. Перечислите операторы изменяющие данные в таблицах.
Лекция 8
Команда удаления строк DELETE
Syntax
DELETE [FROM] [ owner.]table-name
... [FROM table-list]
... [WHERE search-condition]
Применение
Для удаления записей из БД.
Ограничения
Пользователь должен иметь доступ DELETE для указанной таблицы.
Оператор DELETE удаляет все записи удовлетворяющие условию WHERE из указанной таблицы. Если WHERE не указано, все записи в таблице будут удалены.
Удаляет строки целиком - не может быть использована для удаления значений отдельных полей.(Не нужно указывать имя поля).
Примеры
Удаляет поставщика из таблицы (по значению emp_id)
DELETE
FROM employee
WHERE emp_id = 105
Удаляет записи из таблицы fin_data в которых значение поля year меньше 1993
DELETE
FROM fin_data
WHERE year < 1993
Удаляет записи из таблицы contact, если такие записи уже есть в таблице customer.
DELETE
FROM contact
FROM contact, customer
WHERE contact.last_name = customer.lname
AND contact.first_name = customer.fname
Delete From Fam
Для удаления конкретных строк используется предикат(мб с подзапросом)
Delete From Fam WHERE fam_cod=103
Указание в предикате первичного ключа - гарантия удаления одной строки.
Рассмотрим дополнительные объекты, которые могут храниться в базе данных.
Представления ( View )
Определение представлений
Механизм представлений (view) является мощным средством языка SQL, позволяющим скрыть реальную структуру БД от некоторых пользователей за счет определения представления БД, которое реально является некоторым хранимым в БД запросом с именованными столбцами, а для пользователя ничем не отличается от базовой таблицы БД (с учетом технических ограничений). Любая реализация должна гарантировать, что состояние представляемой таблицы точно соответствует состоянию базовых таблиц, на которых определено представление. Обычно вычисление представляемой таблицы (материализация соответствующего запроса) производится каждый раз при использовании представления.
Представления используются по нескольким причинам:
• они позволяют сделать так, что разные пользователи базы данных будут видеть ее по-разному;
• с их помощью можно ограничить доступ к данным, разрешая пользователям видеть только некоторые из строк и столбцов таблицы;
• они упрощают доступ к базе данных, показывая каждому пользователю структуру хранимых данных в наиболее подходящем для него виде.
После определения представления к нему можно обращаться с помощью инструкции SELECT как к обычной таблице.
Имя представления указывается в предложении FROM как имя обычной таблицы, а ссылка на столбцы представления в инструкции SELECT осуществляется точно так же, как на столбцы таблицы. К некоторым представлениям можно применять инструкции insert, delete и update для изменения данных. Таким образом, представление можно использовать в инструкциях SQL так, как будто оно является обычной таблицей.
Преимущества представлений
Использование представлений в базах данных различных типов может оказаться полезным в самых разнообразных ситуациях В базах данных на персональных компьютерах представления применяются для удобства и позволяют упрощать запросы к базе данных В промышленных базах данных представления играют главную роль в создании собственной структуры базы данных для каждого пользователя и обеспечении ее безопасности Основные преимущества представлений перечислены ниже:
• Безопасность. Каждому пользователю можно разрешить доступ к небольшому числу представлений, содержащих только ту информацию, которую ему позволено знать. Таким образом, можно осуществить ограничение доступа пользователей к хранимой информации;
• Простота запросов. С помощью представления можно извлечь данные из нескольких таблиц и представить их как одну таблицу, превращая тем самым запрос ко многим таблицам в однотабличный запрос к представлению;
• Простота структуры. С помощью представлений для каждого пользователя можно создать собственную "структуру" базы данных, определив ее как множество доступных пользователю виртуальных таблиц;
• Защита от изменении. Представление может возвращать непротиворечивый и неизменный образ структуры базы данных, даже если исходные таблицы разделяются, реструктуризируются или переименовываются;
• Целостность данных. Если доступ к данным или ввод данных осуществляется с помощью представления, СУБД может автоматически проверять, выполняются ли определенные условия целостности.
Недостатки представлений
Наряду с перечисленными выше преимуществами, представления обладают и двумя существенными недостатками.
• Производительность. Представление создает лишь видимость существования соответствующей таблицы, и СУБД приходится преобразовывать запрос к представлению в запрос к исходным таблицам. Если представление отображает многотабличный запрос, то простой запрос к представлению становится сложным объединением и на его выполнение может потребоваться много времени
• Ограничения на обновление. Когда пользователь пытается обновить строки представления, СУБД должна установить их соответствие строкам исходных таблиц, а также обновить последние. Это возможно только для простых представлений, сложные представления обновлять нельзя, они доступны только для выборки. Указанные недостатки означают, что не стоит без разбора применять представления вместо исходных таблиц. В каждом конкретном случае необходимо учитывать перечисленные преимущества и недостатки представлений.
Лекция 9
Удаление представления
Во всех основных СУБД существует возможность удаления представлений. Поскольку представления подобны таблицам и не могут иметь совпадающие с ними имена, во многих СУБД для удаления представлений используется инструкция drop table. В других СУБД этой же цели служит отдельная инструкция drop view.
В стандарте SQL2 было формально закреплено использование инструкции drop view для удаления представлений. В нем также детализированы правила удаления представлений, на основе которых были созданы другие представления.
Согласно стандарту SQL2, инструкция drop view удалит из базы данных оба представления:
DROP VIEW EASTREPS CASCADE
Параметр CASCADE означает, что СУБД должна удалить не только указанное в инструкции представление, но и все представления, созданные на его основе. В противоположность этому, следующая инструкция DROP view:
DROP VIEW EASTREPS RESTRICT
выполнится с ошибкой, так как параметр restrict означает, что СУБД должна удалить представление только в том случае, если нет других представлений, созданных на его основе. Это служит дополнительной защитой от случайных побочных эффектов при применении инструкции drop view. Стандарт SQL2 требует, чтобы в инструкции drop view обязательно присутствовал или параметр restrict, или cascade, но в большинстве коммерческих СУБД используется инструкция drop view без каких-либо явно заданных параметров. Это сделано для поддержания обратной совместимости с теми продуктами, которые были выпущены до публикации стандарта SQL2. Работа инструкции drop view в таком случае зависит от СУБД.
СНИМКИ ( SNAPSHOT )
Снимки в действительности имеют много общего с представлениями, но не следует путать эти понятия. Как и представления, снимки — это производные переменные отношения, но, в отличие от представлений, снимки реальны, а не виртуальны, т.е. снимки представлены в базе данных не только в виде собственных определений в терминах других переменных отношения, но и (по крайней мере, концептуально) в виде собственной материализованной копии данных.
Определение снимка во многом подобно выполнению запроса, за исключением следующего.
1)- Результат выполнения этого запроса хранится в базе данных под указанным именем как отношение, доступ к которому разрешен только для чтения (не считая операции периодического обновления; см. пункт 2).
2)- Периодически содержание снимка обновляется, т.е. текущие данные аннулируются и запрос выполняется повторно, после чего полученный результат запроса записывается в качестве нового значения снимка.
Суть самой идеи снимков состоит в том, что для многих приложений (возможно да для большинства) допустимо или даже необходимо использовать для обработки данных в том состоянии, в котором они находились в определенный момент времени. В частности к этой категории приложений относятся многие приложения для создания отчетов и ведения бухгалтерского учета. Подобные приложения обычно требуют фиксации состояния данных в установленное время (например, на конец периода отчетности), и концепция снимков позволяет выполнить такую фиксацию, не влияя на работу других транзакций обновляющих рассматриваемые данные в режиме реального времени (т.е. обновляющих реальные данные). Аналогичным образом может потребоваться зафиксировать состояние большого объема данных, которые используются для выполнения сложного запроса или приложения, не требующего модификации исходных данных, опять же, чтобы избегать блокирования обновления данных на время их выполнения или изменения этих данных
Примечание. Эта идея становится еще привлекательнее в среде распределенных баз данных или приложений поддержки принятия решений. Отметим также, что снимки представляют важный частный случай контролируемой избыточности, а процедура обновления снимка— это соответствующий процесс распространения обновления.
В общем случае определение снимка имеет следующий синтаксис.
VAR <relvar name> SNAPSHOT <relation exp> <candidate key def list> REFRESH EVERY <now and then> ;
В этом определении для указания периода обновления снимка используется параметр <now and then>, который может принимать, например, следующие значения: MONTH (Месяц), WEEK (Неделя), HOUR (Час), n MINUTES (n минут), MONDAY (Понедельник), WEEKDAY (День недели) и т.п. Следует особо отметить, что для поддержки постоянной синхронизации снимка с одной или несколькими переменными отношения, на основании которых он был создан, может использоваться спецификация в форме REFRESH
[ON] EVERY UPDATE.
Ниже приведен синтаксис оператора DROP, применяемого для удаления определения снимка.
DROP VAR <relvar name> ;
Здесь параметр <relvar name> задает имя удаляемого снимка.
Примечание. Подразумевается, что операция удаления снимка завершится неудачно, если какая-либо переменная отношения в данный момент ссылается на удаляемый снимок. Альтернативным решением может быть расширение приведенного выше определения снимка за счет включения опций RESTRICT и CASCADE. Здесь мы не будем обсуждать эту возможность.
Примечание, касающееся терминологии. Первоначально снимки были известны не под их современным названием, а именовались (фактически почти исключительно) материализованными представлениями. Однако этот термин является крайне неудачным, и, до сих пор некоторые авторы (но не все) применяют термин "материализованное представление" исключительно для обозначения снимков, в отношении которых можно гарантировать, что они всегда будут оставаться актуальными (т.е. для создания которых применяется оператор REFRESH ОN EVERY UPDATE).
Встроенные процедуры и триггеры
В архитектуре современных систем обработки данных неуклонно возрастает роль серверных СУБД. Дореляционные СУБД отвечали главным образом за доступ к данным и их хранение, предоставляя приложениям возможность перемещаться по базе данных как им угодно, а также сортировать, отбирать и обрабатывать информацию. Однако с появлением реляционных СУБД и SQL ситуация коренным образом изменилась Операции поиска и сортировки стали командами языка SQL, выполняемыми исключительно самой СУБД, и ею же производится вычисление итоговых данных. Теперь явная навигация по базе данных больше не нужна. Последующие расширения SQL, такие как первичные и внешние ключи, ограничения на значения продолжают эту тенденцию, вытесняя функции проверки данных и обеспечения целостности базы данных, которые раньше были неотъемлемой частью клиентских приложений. А конечная цель этой тенденции проста: чем больше ответственности берет на себя серверная СУБД, тем более эффективной и надежной становится система в целом благодаря централизованному управлению базой данных и снижению вероятности разрушения данных из-за ошибок в клиентских приложениях
Общую тенденцию к расширению функций СУБД продолжают еще две важные возможности, которыми обладают практически все современные реляционные СУБД масштаба предприятия: поддержка хранимых процедур и триггеров
Хранимые проце дуры позволяют переносить часть прикладных функций, связанных с обработкой данных, в саму базу данных. Например, хранимая процедура может управлять приемом заказа или переводом денег с одного банковского счета на другой
Триггеры служат для автоматического выполнения хранимых процедур при возникновении в базе данных определенных условий. Например, триггер может автоматически переводить деньги со сберегательного счета на чековый, когда остаток последнего исчерпывается. С появлением хранимых процедур и триггеров SQL превратился в настоящий язык программирования.
Концепции хранимых процедур
В своей исходной форме SQL не был полноценным языком программирования. Он задумывался и создавался как язык, предназначенный для выполнения операций над базами данных — создания их структуры, ввода и обновления данных — и особенно для выполнения запросов, SQL может использоваться как интерактивный командный язык: пользователь по очереди вводит инструкции SQL с клавиатуры, а СУБД их выполняет. В этом случае последовательность операций над базой данных определяется ее пользователем. Инструкции SQL могут встраиваться в программы, написанные на других языках программирования, например на С , и тогда последовательность операций над базой данных определяется приложением
С появлением хранимых процедур язык SQL обогатился рядом дополнительных базовых возможностей, обеспечиваемых практически всеми языками программирования, что позволило писать на "расширенном SQL" настоящие программы и процедуры.
Конкретные детали зависят от реализации языка, но в целом эти возможности можно описать так:
• Условное выполнение. Конструкция if. . .then. . .else позволяет SQL-процедуре проверить условие и в зависимости от результата выполнить различные действия.
• Циклы. Цикл while или for либо другая подобная структура позволяет многократно выполнять последовательность инструкций SQL до тех пор, пока не выполнится заданное условие окончания цикла. В некоторые реализации языка SQL включены специальные циклы для прохода по всем строкам в таблице результатов запроса.
• Блоки инструкций. Последовательность инструкций SQL может быть сгруппирована в единый блок и использована в других управляющих конструкциях как одна инструкция.
• Именованные переменные. SQL-процедура может сохранить вычисленное, извлеченное из базы данных или полученное любым другим способом значение в переменной, а когда оно понадобится снова — извлечь его из этой переменой.
• Именованные процедуры. Последовательность инструкций SQL можно объединить в группу, дать ей имя и назначить формальные входные и выходные параметры, так что получится обычная подпрограмма или функция, какие используются в традиционных языках программирования. Созданную таким образом процедуру можно вызывать по имени, передавая ей нужные значения в качестве входных параметров. Если она является функцией, возвращающей значение, то его можно использовать в выражениях.
Набор элементов, реализующих все эти возможности, составляет язык хранимых процедур (SPL — Stored Procedure Language). Впервые механизм хранимых процедур был предложен компанией Sybase в ее популярном продукте Sybase SQL Server. С тех пор их поддержка была встроена во многие СУБД. Одни компании смоделировали в своих продуктах конструкции языков С или Pascal, тогда как другие предпочли сохранить исходный стиль языка SQL, чтобы все его инструкции, как языков DDL и DML, так и языка хранимых процедур, были единообразны. В результате концепция хранимых процедур во всех диалектах SQL одна, а вот их синтаксис очень отличается.
Создание хранимой процедуры
Во многих распространенных диалектах для создания хранимой процедуры применяется инструкция create procedure. Эта инструкция назначает новой процедуре имя, по которому в дальнейшем процедуру можно будет вызывать. Имя процедуры должно соответствовать общим правилам для идентификаторов SQL. Хранимая процедура может принимать ноль или более параметров. Обычно значения параметров указываются в виде разделенного запятыми списка, заключенного в скобки и следующего за именем вызываемой процедуры. Заголовок хранимой процедуры содержит имена параметров и типы их данных. Для параметров хранимых процедур могут использоваться те же типы данных, которые поддерживаются в СУБД для столбцов таблиц.
Параметры процедуры могут быть входными, при использовании ключевого слова IN, следующего за их именами в заголовке процедуры. Когда процедура вызывается, переданные ей аргументы присваиваются ее параметрам и начинается выполнение тела процедуры. Имена параметров могут использоваться в теле процедуры (и, в частности, в составляющих ее стандартных инструкциях SQL) везде, где допускается наличие констант. Встретив имя параметра, СУБД подставляет на его место текущее значение этого параметра.
В дополнение к входным параметрам некоторые диалекты SPL поддерживают выходные параметры, с помощью которых хранимые процедуры могут возвращать значения, вычисленные в ходе выполнения процедуры. При интерактивном вызове хранимых процедур от выходных параметров мало пользы, а вот если одна хранимая процедура вызывает другую, выходные параметры позволяют им эффективно обмениваться информацией. Некоторые диалекты SPL поддерживают параметры, которые одновременно являются и входными, и выходными, т.е. их значения передаются хранимой процедуре, та их меняет, и результирующие значения возвращаются вызывающей процедуре.
Параметрам процедуры могут быть назначены значения по умолчанию в операторе CREATE PROCEDURE. Значения по умолчанию должны быть константами (константы могут принимать значения NULL). В качестве примера показана процедура использующая по умолчанию значение NULL для параметра IN, для того чтобы не выполнять запрос, не имеющий смысла (без указания параметра).
CREATE PROCEDURE
CustomerProducts( IN customer_id INTEGER DEFAULT NULL )
RESULT ( product_id INTEGER, quantity_ordered INTEGER )
BEGIN
IF customer_id IS NULL THEN
RETURN;
ELSE
SELECT product.id,
sum( sales_order_items.quantity )
FROM product,
sales_order_items,
sales_order
WHERE sales_order.cust_id = customer_id
AND sales_order.id = sales_order_items.id
AND sales_order_items.prod_id=product.id
GROUP BY product.id;
END IF;
END
Во всех диалектах, в которых используется инструкция create procedure, хранимая процедура может быть удалена соответствующей инструкцией drop procedure.
Хранимую процедуру можно вызывать по-разному из приложения с помощью соответствующей инструкции SQL, из другой хранимой процедуры, а также в интерактивном режиме Синтаксис вызова хранимых процедур зависит от используемого диалекта.
Передаваемые процедуре параметры задаются в том порядке, в каком они объявлены, в виде списка, заключенного в скобки При вызове из другой хранимой процедуры или триггера ключевое слово EXECUTE может быть опущено, тогда вся инструкция чуть упрощается.
В диалекте Watcom-SQL процедуры вызываются с помощью оператора CALL и используют параметры для приема значений и передачи результатов. Процедуры могут вызывать другие процедуры и вызывать срабатывание триггеров. Для вызова процедуры необходимо быть владельцем процедуры или иметь право на ее выполнение (или обладать правами DBA).
Список аргументов может быть либо в позиционном формате или в формате с указанием имен параметров.
Контрольные вопросы
1. Какой вид контроля целостности представления задается с помощью предложения with CHECK OPTION:
2. Команда удаления представлений и ее особенности.
3. Определение снимка (Snapshot), его сравнение с представлением.
4. Дайте определение хранимой процедуры.
Лекция 10
Условное выполнение
Одним из базовых элементов хранимых процедур является конструкция IF. . . THEN. . .ELSE, используемая для организации ветвлений внутри процедуры.
Все диалекты SPL допускают создание вложенных инструкций if. В некоторых диалектах даже имеются специальные разновидности условных конструкций, позволяющие организовывать множественное ветвление.
IF search-condition THEN statement-list
... [ ELSEIF search-condition THEN statement-list ] ...
... [ ELSE statement-list ]
... END IF
Циклы
Еще одним базовым элементом хранимых процедур является конструкция для многократного выполнения группы инструкций — проще говоря, цикл. Циклы могут быть разными: в зависимости от используемого диалекта SPL могут поддерживаться циклы FOR со счетчиком итераций (в которых значение целочисленной переменной уменьшается или увеличивается при каждом проходе цикла, пока не достигнет заданного предела) или циклы while, в которых условие продолжения цикла вычисляется в начале или конце группы составляющих его инструкций.
Второй распространенной формой цикла является выполнение последовательности инструкций до тех пор, пока остается или пока не станет истинным заданное условие. Ниже дан примеры такого цикла в Sybase SQL Anywhere. Чтобы этот цикл когда-нибудь остановился, внутри его тела должна осуществляться проверка условия окончания цикла, и если это условие истинно, должна выполняться команда выхода из цикла:
[ statement-label : ]
...[ WHILE search-condition ] LOOP
... statement-list
...END LOOP [ statement-label ]
...
SET i = 1 ;
WHILE i <= 10 LOOP
INSERT INTO Counters( number ) VALUES ( i ) ;
SET i = i + 1 ;
END LOOP ;
...
Или
SET i = 1;
lbl:
LOOP
INSERT INTO Counters( number ) VALUES ( i ) ;
IF i >= 10 THEN
LEAVE lbl ;
END IF ;
SET i = i + 1 ;
END LOOP lbl
В различных диалектах SPL используются и другие варианты создания циклов, но их возможности и синтаксис аналогичны описанным в этих примерах.
Обработка ошибок
Когда приложение работает с базой данных через интерфейс встроенного SQL или SQL API, оно само отвечает за обработку возникающих при этом ошибок. Коды ошибок возвращаются приложению сервером баз данных, а дополнительную информацию можно получить, вызвав дополнительные API-функции или обратившись к специальной структуре, содержащей диагностическую информацию. Если же операции над данными выполняются хранимой процедурой, она же и должна обрабатывать ошибки
В Transact-SQL информацию о произошедших ошибках можно получить из специальных системных переменных. Имеется огромное количество глобальных системных переменных, хранящих информацию о состоянии сервера и транзакции, открытых подключениях и т.п. Однако для обработки ошибок чаще всего используются только две из них: @@error — код ошибки, произошедшей при выполнении последней инструкции SQL;
@@sqlstatus — состояние последней операции FETCH.
Признаком "нормального завершения" в обеих переменных является значение 0. Другие значения указывают на ошибки или нестандартные ситуации. В хранимых процедурах Transact-SQL глобальные переменные используются точно так же, как локальные. В частности, их можно применять в условиях циклов и в инструкции if.
Лекция 11
Примеры реализации операторов SPL в различных СУБД
Управляющие операторы используемые в процедурах и триггерах (WATCOM SQL)
Составной оператор: BEGIN [ ATOMIC ]
statement-list
END
Оператор проверки условия: IF
IF condition THEN
statement-list
ELSEIF condition THEN
statement-list
ELSE statement-list
END IF
Выбор одного варианта среди множества альтернатив: оператор CASE
CASE value-expression
... WHEN [ constant | NULL ] THEN
statement-list ...
... [ WHEN [ constant | NULL ] THEN statement-list ] ...
... ELSE statement-list
... END CASE
Операторы циклов.
Цикл с предусловием: WHILE, LOOP
Повторяет набор операторов до тех пор пока истинно условие.
WHILE condition LOOP
statement-list
END LOOP
Оператор цикла FOR
Выполняет набор операторов для каждой записи курсора.
[ statement-label : ]
. . .FOR for-loop-name AS cursor-name
. . . CURSOR FOR statement
. . .[ FOR UPDATE | FOR READ ONLY ]
. . . DO statement-list
. . . END FOR [ statement-label ]
Оператор FOR эквивалентен составному оператору с оператором DECLARE для определения курсора и оператора DECLARE для каждого столбца результирующего набора. Оператор выбирает записи из курсора в локальные переменные и выполняет операторы для каждой записи.
Оператор LEAVE
Оператор LEAVE прерывает выполнение составного оператора или оператора цикла.
Оператор CALL – выполняет вызов хранимой процедуры.
[variable = ] CALL procedure-name ( [ expression ,... ] )
[variable = ] CALL procedure-name ( [ parameter-name = expression ,... ] )
Для вызова процедуры необходимо быть владельцем процедуры или иметь право на ее выполнение (или обладать правами DBA).
Список аргументов может быть либо в позиционном формате или в формате с указанием имен параметров.
Процедуры могут возвращать значение (например, как индикатор статуса) используя оператор RETURN. Полученное значение можно присвоить переменной для дальнейшего использования.
CREATE VARIABLE returnval INT ;
returnval = CALL proc_integer ( arg1 = val1, ... )
Управляющие операторы Transact-SQL
Управляющие операторы - необходимый инструмент любого языка программирования Очень часто нужно иметь возможность в зависимости от ситуации выбрать код, который будет выполняться. T-SQL предлагает несколько классических вариантов управления холл выполнения процедур:
BEGIN … END
IF...ELSE
GOTO
WHILE
WAITFOR
Существуют также CASE-конструкции (наподобие SELECT CASE, DO CASE, SWITCH/BREAK в других языках), но они не предоставляют достаточных возможностей управления, как это имеет место в других языках программирования.
Оператор CASE
Оператор CASE имеет свои аналоги в других языках программирования. Вот примеры операторов процедурных языков, которые используются аналогично оператору CASE:
Switch - С, C++, Delphi;
Select Case - Visual Basic;
Do Case - Xbase;
Evaluate - COBOL.
У оператора CASE в T-SQL есть существенный недостаток: во многих отношениях он является оператором подстановки, а не управляющим оператором.
Eстъ два варианта оператора CASE - с исходным и с булевым выражением. В первом варианте исходное выражение сравнивается с выражением, указанным в каждом элементе WHEN. В документации к SQL Server такой вариант называется простой CASE (simple):
CASE <исходное_выражение>
WHEN <when_выражение> THEN <выражение_результат>
[…n]
[ELSE <выражение_результат>]
END
В рамках второго варианта условное выражение в каждом элементе WHEN оценивается как булево (TRUE или FALSE). В документации этот вариант упоминается как анализируемый CASE (searched):
CASE
WHEN <булево_выражение> THEN <выражение_результат>
[…n]
[ELSE < выражение_резулътат>]
END
Допускается использование оператора CASE внутри оператора SELECT. Эта возможность служит основой эффективного программирования.
Простой оператор CASE
В простом операторе CASE результатом проверки условия является булево значение. Давайте сразу начнем с примера:
USE Northwind
GO
SELECT TOP 10 OrderID, OrderlD % 10 AS 'Последняя цифра', Position =
CASE OrderID % 10
WHEN 1 THEN 'Единица’
WHEN 2 THEN 'Двойка'
WHEN 3 THEN 'Тройка'
WHEN 4 THEN 'Четверка'
ELSE 'Какая-то другая'
END D
FROM Orders
Создание циклов с помощью оператора WHILE
Оператор WHILE устроен точно так же, как и в других языках программирования. Условие проверяется каждый раз в начале .цикла. Цикл повторяется до тех пор, пока условие истинно.
Синтаксис:
WHILE <булево выражение>
<SQL-оператор> |
[BEGIN
<блок_операторов>
[BREAK]
<sql-oператор> | <блок_операторов>
[CONTINUE]
END]
Конечно, можно использовать простой оператор WHILE с одним исполняемым sql-оператором также как это можно делать и с оператором IF), однако на практике этот оператор почти всегда используется с блоком операторов внутри BEGIN...END.
оператор BREAK используется для немедленного выхода из цикла, не дожидаясь его конца.
Использование оператора BREAK относится к образцам плохого стиля программирования.
Оператор CONTINUE является противоположностью оператора BREAK. Он указывает, что нужно вернуться в начало цикла. Независимо от того, где вы находились в момент выполнения этого оператора, вы немедленно возвращаетесь в начало. При этом опять производится проверка условия на истинность (выход из цикла происходит после того, как условие перестает выполняться).
Оператор WAITFOR
Иногда необходимо сделать паузу и приостановить выполнение кода на некоторое время при этом хочется, чтобы пауза завершалась автоматически без какого-либо вмешательства пользователя.
Для этого используется оператор WAITFOR.
Синтаксис этого оператора очень прост:
WAITFOR
DELAY <'время'> | TIME <'время'>
В качестве параметра можно указывать время суток, когда следует выполнить некоторую операцию (вариант TIME), или просто промежуток времени, по истечении которого должно совершиться какое-либо действие (вариант DELAY).
Параметр DELAY
Параметр DELAY определяет промежуток времени, истечения которого необходимо ждать. Нельзя указывать время в днях - только часы, минуты, секунды. Максимальная задержка может составлять 24 часа. Например, можно написать:
• WAITFOR DELAY '01:00'
В результате код сценария будет выполняться вплоть до оператора WAITFOR, затем будет останов на 1 час, после этого выполнение кода будет продолжено со следующего оператора.
Параметр TIME
Параметр TIME определяет время суток, которого следует ждать. Опять же, нельзя указывать дату - только время суток в 24-часовом формате. Отсюда следует, что продолжительность задержки не может быть больше одних суток. Например:
WAITFOR TIME '01:00'
До оператора WAITFOR будет выполняться любой код, затем будет останов до 1 часа ночи, после этого выполнение кода будет продолжено с оператора, следующего после оператора WAITFOR.
Подтверждение удачного или неудачного выполнения процедуры
с помощью возвращаемого значения
На практике ваша программа получает возвращаемое значение, независимо от того генерируете вы его или нет. При завершении процедуры SQL Server по умолчанию возвращает нулевое значение.
Для того чтобы передать из процедуры возвращаемое значение вызывавшему коду, нужно просто использовать в процедуре оператор RETURN:
RETURN [ <целое_возвращаемое_значение>]
Триггеры
Триггер — это особая хранимая процедура, которая вызывается в ответ на модификацию содержимого базы данных. В отличие от хранимых процедур, созданных с помощью инструкции create procedure, триггер нельзя выполнить с помощью инструкции call или EXECUTE. Каждый триггер связывается с определенной таблицей базы данных, и СУБД сама выполняет его, когда данные в таблице изменяются инструкцией INSERT, DELETE ИЛИ UPDATE).
Триггеры могут использоваться для автоматического обновления информации в базе данных и поддержания ссылочной целостности в случаях, когда ограничения декларативной ссылочной целостности недостаточны.
Инструкция create trigger используется в большинстве ведущих СУБД для создания нового триггера, включаемого в базу данных. Она назначает триггеру имя, указывает, с какой таблицей его следует связать и в ответ на какие события он должен вызываться. Далее следует тело триггера, которое, как и у обычных хранимых процедур, определяет последовательность инструкций, выполняемых при его вызове.
Контрольные вопросы
1. Особенности языка SPL в диалекте Watcom-SQL.
2. Особенности языка SPL в диалекте Transact-SQL.
3. Особенности оператора CASE в Transact-SQL.
4. Дайте определения триггера.
Лекция 12
Лекция 13
Триггеры выполняются автоматически при выполнении операций INSERT, UPDATE, или DELETE для таблиц, с которыми они связаны. Триггеры уровня записи выполняются для каждой изменяемой записи, триггеры уровня оператора выполняются один раз для соответствующего оператора вне зависимости от количества изменяемых записей.
Когда срабатывают INSERT, UPDATE, или DELETE триггеры, порядок выполнения операций следующий:
1 Выполняется какой-либо BEFORE триггер.
2 Выполняются действия определенные правилами ссылочной целостности.
3 Выполняется соответствующая операция.
4 Выполняются триггеры типа AFTER.
Если на любом шаге обнаруживается ошибка, которая не обрабатывается процедурой или триггером все сделанные изменения отменяются, последующие шаги не выполняются и операция, вызвавшая срабатывание триггера завершается неудачей.
Интерфейсы взаимодействия с БД
Протокол ODBC и стандарт SQL/CLI
Функции SQL/CLI и их группировка
Структура протокола ODBC
Функции ODBC и расширенные возможности ODBC.
Протокол ODBC и стандарт SQL/CLI
ODBC (Open Database Connectivity — открытый доступ к базам данных) – это разработанный компанией Microsoft универсальный программный интерфейс для доступа к базам данных. Хотя в современном компьютерном мире Microsoft играет важную роль как производитель программного обеспечения для баз данных, все же в первую очередь, она один из ведущих производителей операционных систем, именно это послужило мотивом создания ODBC: Microsoft захотела облегчит разработчикам приложений Windows доступ к базам данных. Все дело в том, что различные СУБД существенно отличаются друг от друга, как и их программные интерфейсы. Если разработчику нужно было написать приложение, работающее базами данных нескольких СУБД, для каждой из них приходилось писать отдельный интерфейсный модуль (обычно называемый драйвером). Чтобы избавить программистов от выполнения одной и той же рутинной и достаточно сложной работы, Microsoft решила на уровне операционной системы стандартизировать интерфейс взаимодействия между приложениями и СУБД, благодаря чему во всех программах мог бы использоваться один и тот же универсальный набор функций, поддерживаемый всеми производителями СУБД. Таким образом, от внедрения ODBC выиграли и разработчики приложений, и производители СУБД, для которых также решалась проблема совместимости.
Формирование стандарта SQL/CLI
Даже если бы протокол ODBC был всего лишь собственным стандартом компании Microsoft, его значение все равно было бы очень велико. Однако Microsol постаралась сделать его независимым от конкретной СУБД. Одновременно ассоциация производителей СУБД (SQL Access Group) работала над стандартизацией протоколов удаленного доступа к базам данных в архитектуре клиент/сервер. Microsoft убедила ассоциацию принять ODBC в качестве независимого стандарта доступа базам данных. В дальнейшем этот стандарт перешел в ведение другой организации, Европейского консорциума Х/Open, и был включен в ее комплект стандартов САЕ (Common Application Environment — единая прикладная среда).
С ростом популярности программных интерфейсов доступа к базам данных организации, ответственные за принятие официальных стандартов, стали уделять этому аспекту SQL все более пристальное внимание. На основе стандарта Х/Open (базировавшегося на ной версии ODBC, разработанной компанией Microsoft) с небольшими модификациями - был разработан официальный стандарт ANSI/ISO. Этот стандарт, известный SQL/CLI (SQL/Call Level Interface — интерфейс уровня вызовов функций), был опубликован в 1995 году под названием ANSI/ISO/IEC 9075-3-1995. Он представляет собой Часть 3 разрабатываемого многоуровневого стандарта SQL3, который является развитием опубликованного в 1992 году стандарта SQL2.
Microsoft привела ODBC в соответствие со стандартом SQL/CLI, реализация которого составляет ядро последней версии ее протокола - ODBC 3. Однако полный набор высокоуровневых функций ODBC 3 выходит далеко за рамки спецификации CLI: он предоставляет разработчикам приложений гораздо более широкие возможности и решает ряд специфических задач, связанных с использованием ODBC как части операционной системы Windows.
Преимущества связки ODBC/CLI как для разработчиков приложений, так и для производителей СУБД были настолько очевидны, что оба стандарта очень быстро получили самую широкую поддержку. Практически все производители реляционных СУБД включили в свои продукты соответствующие интерфейсы. ODBC и CLI Поддерживаются тысячами приложений, включая ведущие пакеты инструментальных средств разработки.
Стандартом SQL/CLI определяется около сорока функций (см. табл.). Они служат подключения к серверу баз данных, выполнения инструкций SQL, обработки результатов запросов, а также обработки ошибок, произошедших в ходе выполнения инструкций. Эти функции обеспечивают полный набор возможностей, предоставляемых встроенным SQL, включая как статический, так и динамический SQL.
Функции SQL/CLI
Функция Описание
Управление ресурсами и подключением к базе данных
SQLAllocHandle() Выделяет ресурсы для среды SQL; сеанса подключения к базе данных, описателя CLI или инструкции
SQLFreeHandle () Освобождает ранее выделенные ресурсы
SQLAllocEnv () Выделяет ресурсы для среды SQL
SQLFreeEnv () Освобождает ресурсы, выделенные для среды SQL
SQLAllocConnect () Выделяет ресурсы для сеанса подключения к базе данных
SQLFreeConnect () Освобождает ресурсы, выделенные для сеанса подключения к базе данных
SQLAllocstmt () Выделяет ресурсы для инструкции SQL
SQLFreeStmt() Освобождает ресурсы, выделенные для инструкции SQL
SQLConnect () Устанавливает соединение с базой данных
SQLDisconnect() Разрывает соединение с базой данных
Выполнение инструкций SQL
SQLExecDirect() Непосредственно выполняет инструкцию SQL
SQLPrepare() Подготавливает инструкцию SQL к последующему выполнению SQLExecute() Выполняет ранее подготовленную инструкцию SQL
SQLRowCount() Возвращает количество строк, обработанных последней инструкцией SQL
Управление транзакциями
SQLEndTran() Завершает или отменяет транзакцию
SQLCancel() Отменяет выполнение текущей инструкции SQL
Обработка параметров
SQLBindParam() Связывает параметр инструкции SQL с адресом программного буфера
SQLParamData() Сообщает приложению адрес параметра подготавливаемой инструкции, для которого необходимо предоставить данные, прежде чем инструкция сможет быть выполнена
SQLPutData() Предоставляет данные для параметра подготавливаемой инструкции; эта функция может вызываться многократно, чтобы передавать данные по частям
Обработка результатов запроса
SQLSetCursorName() Назначает имя набору записей
SQLGetCursorName() Возвращает имя набора записей
SQLBindCol() Связывает столбец в таблице результатов запроса с программным буфером
SQLFetch() Возвращает следующую строку из таблицы результатов запроса SQLFetchScroll() Возвращает указанную строку из таблицы результатов запроса SQLCloseCursor() Закрывает набор записей
SQLGetData() Возвращает значение указанного столбца из таблицы результатов запроса
Описание результатов запроса
SQLNumResultCols() Возвращает количество столбцов в таблице результатов запроса
SQLDescribeCol() Возвращает описание указанного столбца в таблице результатов запроса
SQLColAttribute() Возвращает информацию об указанном атрибуте заданного столбца в таблице результатов запроса
SQLGetDescField() Возвращает значение указанного поля из описателя CLI SQLSetDescField() Устанавливает значение указанного поля в описателе CLI SQLGetDescRec() Возвращает значения набора полей из описателя CLI SQLSetDescRec() Устанавливает значения набора полей в описателе CLI
SQLCopyDesc() Копирует содержимое одного описателя CLI в другой
Обработка ошибок
SQLError() Возвращает информацию об ошибке, произошедшей во время последнего вызова функции CL1
SQLGetDiagField() Возвращает значение указанного поля из специальной структуры CLI, содержащей диагностическую информацию
SQLGetDiagRec() Возвращает значения набора полей из специальной структуры CLI, содержащей диагностическую информацию
Управление атрибутами
SQLSetEnvAttr() Устанавливает значение указанного атрибута среды SQL SQLGetEnvAttr() Возвращает значение указанного атрибута среды SQL
SQLSetConnectAttr() Устанавливает значение указанного атрибута сеанса подключения к базе данных
SQLGetConnectAttr() Возвращает значение указанного атрибута сеанса подключения к базе данных
SQLSetStmtAttr() Устанавливает значение указанного атрибута инструкции SQL SQLGetStmtAttr() Возвращает значение указанного атрибута инструкции SQL
Управление драйвером
SQLDataSources() Возвращает список доступных серверов баз данных
SQLGetFunctions() Возвращает информацию о функциях CLI, поддерживаемых текущим драйвером
SQLGetlnfо() Возвращает общую информацию об источнике данных и драйвере, которые связаны с указанным сеансом подключения к базе данных
SQLGetTypelnfо() Возвращает информацию о поддерживаемых типах данных
Большинство программ использующих функции CLI выполняют последовательность действий показанную ниже:
- программа подключается к библиотеке CLI и выделяет память под структуры данных, используемые функциями этой библиотеки;
- программа подключается к конкретному серверу баз данных;
- программа формирует инструкции SQL в собственных буферах памяти;
- программа вызывает функции CLI, с помощью которых она просит сервер выполнить инструкции SQL и узнает о завершении этих инструкций;
- в случае успешного выполнения инструкций SQL программа с помощью еще одной функции CLI просит сервер завершить транзакцию;
- программа отключается от сервера баз данных и освобождает память, занимаемую структурами данных.
Все функции CLI возвращают код состояния. Это значение показывает код ошибки или предупреждения. В реальных программах коды состояния необходимо проверять, чтобы убедиться, что каждая вызываемая функция CLI выполнена успешно.
Протокол ODBC. Структура ODBC.
Структура протокола ODBC изображена на рис. Программное обеспечение ODBC состоит из трех основных уровней:
Интерфейс вызовов функций. На самом верхнем уровне ODBC находится единый программный интерфейс, который может использоваться всеми приложениями. Этот API реализован в виде библиотеки динамической компоновки (DLL), которая является неотъемлемой частью Windows.
Драйверы ODBC. На нижнем уровне располагается набор драйверов: по одному драйверу для каждой поддерживаемой СУБД. Задачей драйвера является трансляция стандартных вызовов функций ODBC в вызовы соответствующих функций, поддерживаемых конкретной СУБД (их может быть и несколько для одной функции ODBC). Каждый драйвер устанавливается в операционной системе независимо. Это позволяет производителям СУБД разрабатывать для своих продуктов собственные драйверы и распространять их независимо от Microsoft. Если СУБД располагается в той же системе, что и драйвер ODBC, то драйвер обычно напрямую вызывает внутренние API-функции СУБД. Если же доступ к базе данных осуществляется: по сети, то драйвер может: а) направлять все вызовы в клиентскую часть СУБД; которая будет переадресовывать их на сервер; б) самостоятельно управлять сеансом сетевого подключения к удаленной базе данных.
Диспетчер драйверов. Средний уровень занят диспетчером драйверов ODBC, который отвечает за загрузку и выгрузку драйверов по запросам приложений, а также за направление вызовов функций ODBC, производимых приложениями соответствующим драйверам для выполнения.
Когда приложению нужно получить доступ к базе данных посредством ODBC оно выполняет ту же самую последовательность начальных действий, которая предусматривается стандартом SQL/CLI. Прежде всего, программа получает дескрипторы среды и сеанса, а затем вызывает функцию SQLConnect(), указав конкретный источник данных, с которым она хочет работать. В ответ на это диспетчер драйверов ODBC анализирует переданную программой информацию о подключении и определяет, какой драйвер ей нужен. Диспетчер загружает этот драйвер в память, если только к настоящему времени драйвер не используется никакой другой программой. Все последующие вызовы функций в пределах данного сеанса обрабатываются этим драйвером. Программа может затем вызывать функцию SQLConnect() для подключения к другим источникам данных, что вызовет загрузку дополнительных драйверов; но, тем не менее, обращения к различным базам данных и различным СУБД будут производиться посредством единого набора функций.
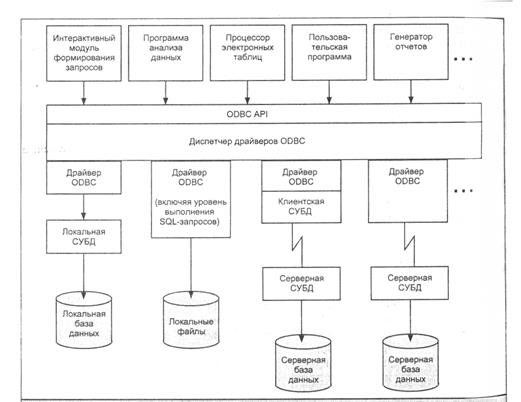
Независимое взаимодействие с различными СУБД
Разработав универсальный программный интерфейс и многоуровневую архитектуру ODBC с диспетчеризацией вызовов, Microsoft значительно продвинулась в направлении независимого от СУБД доступа к базам данных, но сделать доступ абсолютно "прозрачным" вряд ли возможно. Драйверы ODBC для различных СУБД могут легко замаскировать незначительные отличия их программных интерфейсов и диалектов SQL, но более фундаментальные отличия скрыть трудно или даже невозможно. ODBC частично решает эту проблему, разделяя полный набор предлагаемых возможностей на несколько функциональных уровней и вводя набор функций, позволяющих драйверу ODBC "рассказать" о себе приложению: предоставить ему информацию о своих возможностях, наборе поддерживаемых функций и типов данных. Однако само наличие нескольких уровней функциональных возможностей драйверов и выборочная поддержка драйверами этих возможностей ставит приложение в зависимость от СУБД, хотя и на другом уровне. Поэтому на практике большинство приложений использует только базовые функции ODBC.
Контрольные вопросы
1. Определите назначение протокола ODBC.
2. Перечислите группы функций входящие в протокола ODBC.
3. Опишите структуру ODBC.
4. Сформулируйте преимущества использования ODBC.
Лекция 14
Функции ODBC для работы с системными каталогами.
Одной из областей, в которых ODBC предлагает возможности, выходящие за рамки стандарта SQL/CLI, является получение информации о структуре базы данных из системного каталога. Стандарт ODBC не считает обязательным наличие в базе данных информационной схемы. Взамен этот протокол включает набор специальных функций, которые предоставляют приложению информацию о структуре источника данных. Вызывая эти функции, приложение может в процессе своего выполнения получать информацию о таблицах, столбцах, привилегиях, первичных и внешних ключах и хранимых процедурах, составляющих структуру источника данных.
Функции ODBC, предназначенные для работы с системными каталогами, обычно не нужны в специализированных приложениях, а вот программам общего назначения, таким как модули формирования запросов, генераторы отчетов и утилиты анализа данных, без подобных функций обойтись. Эти функции можно вызывать в любое время после подключения к источнику данных. Например, генератор отчетов может вызвать функцию SQLConnect() и сразу же вслед за ней - функцию SQLTables(), чтобы узнать, какие таблицы имеются в базе данных.
Все функции, работающие с каталогами, возвращают информацию в виде таблицы результатов запроса. Для получения этой информации приложения применяют же методы, которые используются для получения результатов обычных запросов, выполняемых посредством CLI. Например, набор записей, сформированный функцией SQLTables(), будет содержать по одной записи для каждой таблицы базы данных.
Функции ODBC, предназначенные для работы с системным каталогами
Функция Описание
SQLTables() Возвращает список таблиц заданного каталога (каталогов) и схемы (схем)
SQLTablePrivileges () Возвращает список привилегий заданной таблицы (таблиц)
SQLColumns() Возвращает список имен столбцов заданной таблицы (таблиц)
SQLColumnPrivileges() Возвращает список привилегий на указанные столбцы заданной таблицы
SQLPrimaryKeys() Возвращает список имен столбцов, составляющих первичный ключ заданной таблицы
SQLForeignKeys() Возвращает список внешних ключей заданной таблицы и список внешних ключей других таблиц, которые связаны с заданной таблицей
SQLSpecialColumns() Возвращает список столбцов, которые однозначно идентифицируют строку таблицы, или столбцов, которые автоматически обновляются при обновлении строки
SQLStatistics() Возвращает статистические данные о таблице и ее индексах
SQLProcedures() Возвращает список хранимых процедур заданного источника данных
SQLProcedureColumns() Возвращает список входных и выходных параметров и имена возвращаемых столбцов для заданной хранимой процедуры (процедур)
Расширенные возможности ODBC
Как уже упоминалось, ODBC предоставляет дополнительные возможности помимо тех, что определены стандартом SQL/CLI. Многие из них предназначены, для повышения производительности приложений, использующих ODBC, за счет минимизации количества вызовов функций ODBC, необходимых для выполнения типичных задач, а также за счет сокращения сетевого трафика при работе с ODBC. Кроме того, ODBC предоставляет ряд возможностей, обеспечивающих большую независимость приложения от конкретной СУБД и помогающих приложению устанавливать соединение с источником данных. Часть дополнительных возможностей ODBC реализована в виде функций, показанных ниже. Остальные управляются атрибутами инструкций и сеансов. Многие из расширенных возможностей ODBC появились в версии 3.0 этого протокола и еще не все драйвера их поддерживают.
Некоторые дополнительные функции ODBC
Функция Описание
SQLBrowseConnect() Возвращает информацию об атрибутах указанного источника данных ODBC, которые необходимо задать для подключения к источнику
SQLDrivers() Возвращает список доступных драйверов и имен их атрибутов
SQLDriverConnect() Расширенная форма функции SQLConnect(), предназначенная для передачи ODBC дополнительной информации о сеансе подключения
SQLNumParams() Возвращает количество параметров последней подготовленной инструкции SQL
SQLBindParameter() Дополняет возможности функции SQLBindParam() SQLDescribeParam() Возвращает информацию о параметре инструкции SQL
SQLBulkOperations() Выполняет пакетные операции с использованием механизма закладок
SQLMoreResults() Определяет, остались ли еще необработанные записи в таблице результатов запроса
SQLSetPos() Задает позицию указателя в результирующем наборе записей, разрешая приложению выполнять позиционные операции над этим набором
SQLNativeSQL() Возвращает перевод заданной инструкции SQL на “родной” диалект SQL той СУБД, с которой ведется работа
| Функция | Параметры | Действие |
| SQLCONNECT([DataSourceName, cUserID, cPassword | cConnectionName]) | DataSourceName – имя источника данных, cUserID – имя пользователя, cPassword | cConnectionName]) – пароль или имя соединения | Устанавливает соединение с указанным источником данных ODBC. Возвращает положительное целое число в случае успеха, -1 – при неудаче. |
| SQLSETPROP(nConnectionHandle, cSetting [, eExpression]) | nConnectionHandle – указатель на соединение с источником данных полученный от Sqlconnect(), cSetting – имя параметра, eExpression – значение параметра; Возможные значения для cSetting Asynchronous BatchMode ConnectBusy ConnectString ConnectTimeOut DataSource DispLogin DispWarnings IdleTimeout ODBChdbc ODBChstmt PacketSize Password QueryTimeOut Transactions WaitTime | Для заданного соединения с источником данных устанавливает значения различных параметров. |
| SQLEXEC(nConnectionHandle, [cSQLCommand, [CursorName]]) | nConnectionHandle – указатель на соединение с источником данных полученный от Sqlconnect(), cSQLCommand – оператор SQL передаваемый источнику данных, CursorNam e – имя курсора куда будет помещен результат, по умолчанию- SQLRESULT. | |
| SQLPREPARE(nConnectionHandle, cSQLCommand, [CursorName]) SQLEXECUTE(nConnectionHandle, cSQLCommand, [CursorName]) | Подготавливает оператор SQL к выполнению функцией SQLEXEC() | |
| SQLGETPROP(nConnectionHandle, cSetting) | Возвращает текущие значения или значения по умолчанию для активного соединения. | |
| SQLSTRINGCONNECT([cConnectString]) | Устанавливает соединение с источником данных через строку соединения | |
| SQLCOMMIT(nConnectionHandle) | Завершает транзакцию | |
| SQLROLLBACK(nConnectionHandle) | Отменяет любые изменения сделанные в текущей транзакции | |
| SQLMORERESULTS(nConnectionHandle) | Копирует следующий набор данных в курсор VFP (если такой набор данных существует) | |
| SQLDISCONNECT(nConnectionHandle) | ||
| SQLCANCEL(nConnectionHandle) | Прерывает выполнение текущего SQL оператора. | |
| SQLTABLES(nConnectionHandle [, cTableTypes] [, cCursorName]) | Сохраняет имена таблиц в источнике данных в курсор VFP | |
| SQLCOLUMNS(nConnectionHandle, TableName [, “FOXPRO” | “NATIVE”] [, CursorName]) | Сохраняет список имен столбцов и информацию о каждом столбце таблицы в источнике данных в курсор VFP | |
Управление сеансами
Две из расширенных возможностей ODBC связаны с организацией сеансов. Механизм просмотра информации о подключении предназначен для упрощения процесса подключения к источнику данных. В основе этого механизма лежит функция SQLBrowseConnect(). Сначала приложение вызывает эту функцию, указывая имя источника данных, и в ответ получает описание необходимых для подключения атрибутов (таких как имя пользователя и пароль). Программа собирает нужную информацию (например, запросив ее у пользователя) и передает ее функции SqlBrowseConnect(), которая возвращает описание последующих атрибутов. Цикл одолжается до тех пор, пока приложение не предоставит ODBC всю информацию, обходимую для подключения к заданному источнику данных. Как только это будет сделано, соединение будет установлено.
Механизм группировки подключений предназначен для более эффективного управления процессами установления/разрыва соединения в среде клиент/сервер. Когда режим группировки подключений активизирован, ODBC, получив вызов функции SQLDisconnect(), не завершает сеанс подключения. Он остается в неактивном состоянии в течение некоторого времени, и если за это время поступит новый вызов функции SQLConnect(), ODBC просто активизирует имеющееся подключение (если, конечно, приложению нужен тот же источник данных). Повторное использование подключений позволяет существенно снизить расходы, связанные с многократным входом в серверную систему (и последующим выходом из нее) в приложениях, выполняющих большое число коротких транзакций.
Лекция 15
Дублирование таблиц
Доступ к удаленным базам данных из локальных СУБД очень удобен при выполнении небольших запросов и нерегулярном доступе к данным. Если же приложению требуется интенсивный и частый доступ к удаленной базе данных, тогда коммуникационные издержки описанной ранее схемы работы могут оказаться неприемлемыми. Когда интенсивность и частота операций удаленного доступа превышает определенный предел, более эффективным оказывается использование локальной копии удаленных данных. Многие производители СУБД предоставляют специальные средства для упрощения процесса извлечения и распространения данных. В простейшем случае содержимое таблицы извлекается из "главной" базы данных, пересылается по сети другой системе и помещается в соответствующую таблицу-реплику в "подчиненной” базе данных (рис. ). Эта процедура обычно выполняется периодически во время наименьшей загрузки системы.
Такой подход очень удобен в тех случаях, когда данные в реплицируемых таблицах изменяются редко или изменения выполняются в пакетном режиме. Предположим, например, что несколько таблиц нашей учебной базы данных, расположенные в главной системе, должны быть реплицированы в локальные базы данных. Содержимое таблицы OFFICES практически никогда не меняется. Поэтому она будет прекрасным кандидатом для репликации в рабочие базы данных дистрибьюторских центров и торговых менеджеров. После того как локальные таблицы-реплики соответствующим образом созданы и заполнены данными из главной таблицы, их можно обновлять раз в месяц или не обновлять вовсе, пока не будет открыт какой-нибудь новый офис.
Описанную стратегию репликации можно реализовать вообще без поддержки со стороны СУБД. Вы можете написать приложение со встроенным SQL, которое будет работать на мэйнфрейме и извлекать данные о ценах на товары из базы данных, помещая их в файл. Еще одна программа может пересылать этот файл в дистрибьюторские центры, где третья программа будет считывать его содержимое и генерировать соответствующие инструкции DROP TABLE, CREATE TABLE и INSERT для заполнения таблиц-реплик.
Первым шагом в направлении автоматизации этой стратегии стала разработка высокоскоростных программ для извлечения и загрузки данных. В этих утилитах, предлагаемых многими производителями современных СУБД, обычно используются специализированные низкоуровневые технологии доступа к базам данных, поэтому выборка и загрузка данных в них выполняется гораздо быстрее, чем при использовании обычных инструкций SELECT и INSERT. Позднее стали появляться аналогичные программные продукты независимых производителей. Определилась новая категория программного обеспечения, получившая название "ПО для интеграции приложений масштаба предприятия" (Enterprise Application Integration — EAI). Задачей программных продуктов этой категории является интеграция различных компьютерных систем, СУБД, других программных комплексов и файлов различных форматов. Связь нескольких СУБД — это лишь малая часть комплексного решения, предлагаемого ты личной EAI-системой, исключительно гибко настраиваемой для нужд конкретного предприятия. Обычно EAI-системы включают графический интерфейс для определения процедуры извлечения данных, набор средств для переформатирования данных в соответствии с требованиями системы-получателя и подсистему для пересылки данных по сети, включающую возможность временного сохранения данных до и после пересылки, а также утилиты для управления всем процессом и его мониторинга.
Двунаправленная репликация
В простейшем случае (см. рис.) таблица связана с каждой своей репликой строгим соотношением "главная/подчиненная". Центральная (главная) таблица содержит "реальные" данные. Это всегда самая последняя информация, и она должна обновляться приложениями только в главной таблице. Копии периодически обновляются в пакетном режиме самой СУБД. В промежутках между обновлениями их информация может оказаться несколько устаревшей, но если база данных сконфигурирована таким образом, значит, это приемлемая плата за преимущество использования локальных копий данных. Приложениям не разрешается обновлять данные, содержащиеся в копиях реплицированной таблицы. В случае подобной попытки СУБД генерирует ошибку.
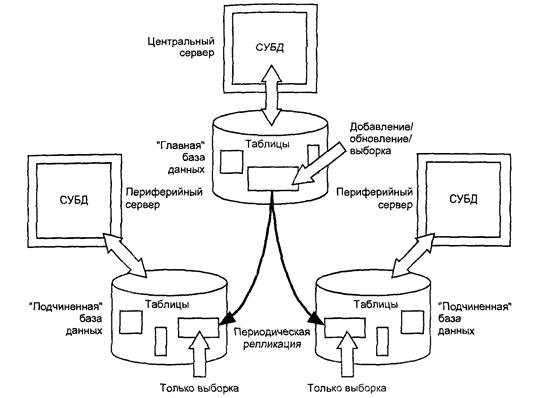
В схеме репликации Microsoft SQL Server иерархическая связь реплик является неявной. SQL Server определяет главную таблицу как "издателя" данных, а подчиненные таблицы — как их "подписчиков". В создаваемой по умолчанию конфигурации существует один обновляемый издатель и несколько подписчиков, данные в которых доступны только для выборки. Развивая эту аналогию, SQL Server поддерживает два вида обновлений: подписка (когда издатель сам отправляет обновленные данные подписчикам) и запрос (когда вся ответственность за получение обновленных данных лежит на подписчиках).
Однако существуют такие типы приложений, для которых технология табличной репликации очень удобна, но иерархическое отношение между репликами к ним неприменимо. Например, в приложениях, от которых требуется очень высокая степень надежности, часто поддерживаются две идентичные копии данных в двух компьютерных системах. Если одна система выходит из строя, вторая используется для продолжения работы. Другим примером может быть Internet-приложение с большим количество;* пользователей, выполняющее очень интенсивный обмен с базой данных. Для обеспечения приемлемой эффективности работы пользователей такого приложения его рабоч* нагрузка может быть распределена между несколькими компьютерными системами с отдельными синхронизируемыми копиями данных. Или еще один пример. В торговой компании может существовать одна центральная таблица клиентов и сотни ее реплик в портативных компьютерах торговых менеджеров. При этом все менеджеры должны иметь возможность вводить в свои реплики информацию о новых клиентах или изменять данные о старых клиентах. Для всех этих (и многих других) типов приложений наиболее эффективной является схема, при которой все реплики допускают модификацию своего содержимого.
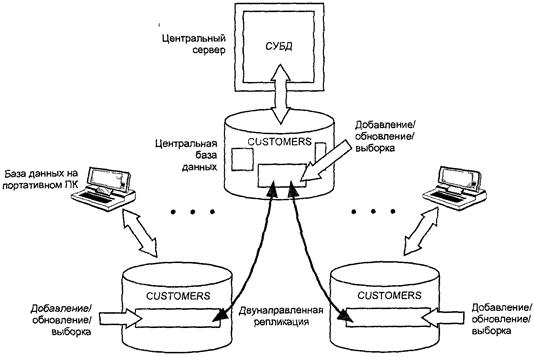
Репликация
Двунаправленная репликация
Схема: Издатель - подписчики
Горизонтальная репликация(по строкам)
Вертикальная репликация (по столбцам)
Зеркальная репликация(таблицы полностью идентичны)
Схема: Издатель - подписчики
|
|
Создание новой публикации (подписки)
Указываются таблицы, которые необходимо реплицировать.
Для каждой таблицы можно определить набор столбцов включенных в публикацию
И определить условие where для выборки необходимых строк.
Затем создается новый пользователь(так называемый удаленный пользователь)
Для которого определяется способ передачи информации в центральную(consolidated) базу данных(file, mapi, smtp, vim, ftp) и периодичность обмена (по запросу(send and close), каждые nn:mm часов, ежедневно в указанное время)
Далее удаленный пользователь подписывается на ранее созданную публикацию и для него выгружается его локальная база данных. В ней будут только те данные, которые разрешены публикацией, на которую подписан этот пользователь.
|
|

|
|
|
|
|
|
Контрольные вопросы
1. Опишите механизм репликации БД на основе дублирования таблиц.
2. Опишите механизм двунаправленной репликации БД.
3. Поясните схему репликации “Издатель-Подписчики”.
4. Перечислите шаги необходимые для создания распределенной БД средствами Sybase SQL Anywhere.
Лекция 16
Концепции хранилищ данных
В основе технологии хранилищ данных лежит идея о том, что базы данных ориентированные на оперативную обработку транзакций (Onlinе Transaction Рrocessing – OLTP), и базы данных, предназначенные для делового анализа, используются совершенно по-разному и служат разным целям. Первые – это средство производства, основа каждодневного функционирования предприятия. На производственном предприятии подобные базы данных поддерживают процессы принятия заказов клиентов, учета сырья, складского учета и оплаты продукции, т.е. выполняют главным образом учетные функции. С такими базами данных, как правило, работают клиентские приложения, используемые производственным персоналом, работниками складов т.п. В противоположность этому базы данных второго типа используются для принятия решений на основе сбора и анализа информации. Их главные пользователи – это менеджеры, служащие планового отдела и отдела маркетинга.
Ключевые отличия аналитических и OLTP-приложений, с точки зрения взаимодействия с базами данных, перечислены в табл.
Рабочая нагрузка баз данных, используемых в аналитических и OLTP - приложениях, настолько различна, что очень трудно или даже невозможно подобрать одну СУБД, которая наилучшим образом удовлетворяла бы требованиям приложений обоих типов.
| Характеристика | OLTP | База хранилища данных |
| Типичный размер таблиц | Тысячи строк | Миллионы строк |
| Схема доступа | Предопределена для каждого типа обрабатываемых транзакций | Произвольная; зависит от того, какая именно задача стоит перед пользователем в данный момент и какие средства нужны для ее решения |
| Количество строк, к которым обращается один запрос | Десятки | От тысяч до миллионов |
| С какими данными работает приложение | С отдельными строками | С группами строк (итоговые запросы) |
| Интенсивность Обращений к базе данных | Большое количество транзакций в минуту или в секунду | На выполнение запроса требуется время: минуты или даже часы |
| Тип доступа | Выборка, вставка и обновление | Преимущественно выборка |
| Чем определяется Производительность | Время выполнения Транзакции | Время выполнения запроса |
Компоненты хранилища данных
На рис. изображена архитектура хранилища данных. Выделим три ее основных компонента:
средства наполнения хранилища – это программный комплекс, отвечающий за извлечение данных из корпоративных OLTP-систем (реляционных баз данных, и других систем, их обработку и загрузку в хранилище; этот процесс обычно требует предварительной обработки извлекаемых данных, их фильтрации и переформатирования, причем записи загружаются в хранилище не по одной, а целыми пакетами;
база данных хранилища – обычно это реляционная база данных, оптимизированная для хранения огромных объемов данных, их очень быстрой пакетной загрузки и выполнения сложных аналитических запросов;
средства анализа данных – это программный комплекс, выполняющий статистический и временной анализ, анализ типа "что если" и представление результатов в графической форме.
Современные хранилища преимущественно управляются специализированными реляционными СУБД ведущих производителей рынка корпоративных баз данных.
Архитектура баз данных для хранилищ.
Структура базы данных для хранилища обычно разрабатывается таким образом, чтобы максимально облегчить анализ информации, ведь это основная функция хранилища. Данные должно быть удобно "раскладывать" по разным направлениям (называемым измерениями). Структура базы данных должна обеспечивать проведение всех типов анализа, позволяя выделять данные, соответствующие заданному набору измерений.
Кубы фактов
В большинстве случаев информация в базе данных хранилища может быть представлена в виде N-мерного куба фактов, отражающих деловую активность компании в течение определенного времени: Простейший трехмерный куб данных о продажах изображен на рис.
Каждая его ячейка представляет один "факт" - объем продаж в стоимостном или натуральном выражении. Вдоль одной грани куба (одного измерения) располагаются месяцы, в течение которых выполнялись отражаемые кубом продажи. Второе измерение составляют категории товаров, а третье – регионы продаж. В каждой ячейке содержится объем продаж для соответствующей комбинации значений по всем трем измерениям.
В реальных приложениях используются гораздо более сложные кубы с десятью и более измерений.
Схема "звезда"
Для большинства хранилищ данных самым эффективным способом моделирования
N-мерного куба фактов является схема "звезда". На рис. изображено, как выглядит такая схема для хранилища данных коммерческой компании, описанного выше.
Для каждого значения измерения, таблице имеется отдельная строка.
Многоуровневые измерения
В схеме "звезда", каждое измерение имеет только один уровень. На практике же довольно распространена более сложная структура базы данных, в которой измерения могу иметь по несколько уровней.
Расширения SQL для хранилищ данных
Теоретически реляционная база данных звездообразной структуры обеспечивает хороший фундамент для выполнения запросов из области делового анализа. Возможность находить не представленную в базе данных в явном виде информацию на основе анализа содержащихся в ней значений как нельзя лучше подходит для произвольных, непрограммируемых запросов, свойственных аналитическим приложениям. Однако между типичными аналитическими запросами и возможностями базового языка SQL имеются серьезные несоответствия. Например:
Сортировка данных. Многие аналитические запросы явно или неявно требуют предварительной сортировки данных. Возможны такие критерии отбора информации, как "первые десять процентов", "первая десятка", и т.п. Однако SQL оперирует неотсортированными наборами записей. Единственным средством сортировки данных в нем является предложение order by в инструкции select, причем сортировка выполняется в самом конце процесса, когда данные уже отобраны и обработаны.
Хронологические последовательности. Многие запросы к хранилищам данных предназначены для анализа изменения некоторых показателей во времени: они сравнивают результаты этого года с результатами прошлого, результаты этого месяца с результатами того же месяца в прошлом году, показывают динамику роста годовых показателей в течение ряда лет и т.п. Однако очень трудно, а иногда и просто невозможно получить сравнительные данные за разные периоды времени в одной строке, возвращаемой стандартной инструкцией SQL. В общем случае это зависит от структуры базы данных.
Сравнениение с итоговыми данными. Многие аналитические запросы сравнивают значения отдельных элементов (например, объемы продаж отдельных офисов) с итоговыми данными (например, объемами продаж по регионам). Такой запрос трудно выразить на стандартном диалекте SQL.
Пытаясь решить все этих проблемы, производители СУБД для хранилищ данных обычно расширяют в своих продуктах возможности языка SQL, добавляя такие расширения:
диапазоны — позволяют формулировать запросы вида "отобрать первые десять записей";
перемещение итогов и средних – используется для хронологического анализа, требующего предварительной обработки исходных данных;
расчет текущих итогов и средних – позволяет получать данные по отдельны месяцам, плюс годовой итог на текущую дату и выполнять другие подобные запросы;
сравнительные коэффициенты – позволяют создавать запросы, выражающие отношение отдельных значений к общим и промежуточным итогам без использования сложных подчиненных запросов;
декодирование – упрощает замену кодов из таблиц измерений понятными именами (например, замену кодов товаров их названиями);
промежуточные итоги – позволяют получать результаты запросов, в которых объединена детализированная и итоговая информация, причем с несколькими уровнями итогов.
Многие разработчики СУБД для хранилищ данных используют аналогичные расширения или встраивают в свои продукты специальные функции для получения нетипичных для SQL. данных. Как и в случае с другими расширениями SQL., их концептуальные возможности, предлагаемые различными разработчиками, сходны, а реализация зачастую совершенно разная.
Контрольные вопросы
1. Концепция хранилищ данных. OLTP системы и OLAP системы.
2. Сравните рабочие нагрузки OLTP и OLAP систем.
3. Перечислите типовые компоненты хранилища данных.
4. Какая архитектура БД используется для организации хранилища данных.
5. Расширения языка SQL используемые в хранилищах данных.
Литература
1) К.Дж. Дейт Введение в системы баз данных, 8-е издание.: Пер. с англ. — Москва: Издательский дом "Вильяме", 2005.
2)М. Ричардс и др. “ORACLE 7.3 Энциклопедия пользователя”.
Киев, изд. Диасофт, 1997г
3)Омельченко Л. Н., Шевякова Д. А. Самоучитель Visual FoxPro 9.0.
СПб: БХВ-Петербург, 2005г.
4)Дж. Грофф, П. Вайнберг. SQL: Полное руководство; Пер. с англ., Киев: Издательская группа BHV, 2001г.
Оглавление
Лекция 1. 2
Лекция 2. 10
Лекция 3. 15
Лекция 4. 24
Лекция 5. 30
Лекция 6. 39
Лекция 7. 44
Лекция 8. 53
Лекция 9. 60
Лекция 10. 69
Лекция 11. 77
Лекция 12. 84
Лекция 13. 93
Лекция 14. 96
Лекция 15. 96
Лекция 16. 96
Литература.. 96
МОСКОВСКИЙ АВИАЦИОННЫЙ ИНСТИТУТ
( Государственный технический университет )
Направление 220300- Информационные системы и технологии
Склеймин Ю.Б.
УПРАВЛЕНИЕ БАЗАМИ ДАННЫХ
(конспект лекций)
4 семестр
Лекции- 32 часа
Лабораторные работы – 16 часов
2010г.
Лекция 1
Язык для взаимодействия с БД SQL появился в середине 70-х и был разработан в рамках проекта экспериментальной реляционной СУБД System R. Исходное название языка SEQUEL (Structered English Query Language) только частично отражает суть этого языка. Конечно, язык был ориентирован главным образом на удобную и понятную пользователям формулировку запросов к реляционной БД, но на самом деле уже являлся полным языком БД, содержащим помимо операторов формулирования запросов и манипулирования БД средства определения и манипулирования схемой БД; определения ограничений целостности и триггеров; представлений БД; возможности определения структур физического уровня, поддерживающих эффективное выполнение запросов; авторизации доступа к отношениям и их полям; точек сохранения транзакции и откатов. В языке отсутствовали средства синхронизации доступа к объектам БД со стороны параллельно выполняемых транзакций: с самого начала предполагалось, что необходимую синхронизацию неявно выполняет СУБД. Рассмотрим эти свойства языка немного более подробно.
В настоящее время SQL переживает новый подъем. В качестве коммерческого продукта язык был впервые реализован в Oracle в 1976 году, но официального стандарта SQL не существовало до 1986 года, когда он был опубликован как результат объединенных усилий ANSI (the American National Standards Institute) и ISO (International Standards Organization). Поскольку ANSI является частью ISO, в данном приложении мы ссылаемся на обе эти организации как на ISO. Стандарт 1986 года был пересмотрен в 1989 году, в него были введены средства, обеспечивающие ссылочную целостность (referential integrity).
К тому времени, когда появился стандарт 86, ряд программных продуктов уже использовал SQL, и ISO попытался закрепить в стандарте наиболее общие черты этих реализаций для того, чтобы ввод стандарта не отразился слишком болезненно на готовых программных продуктах. ISO проанализировал все основные характеристики существовавших к тому времени программных реализаций и определил весьма минимальный стандарт. Некоторые существенные характеристики, например, как уничтожение объектов и передача привилегий, были опущены из стандарта полностью. Теперь, когда многообразный компьютерный мир стал столь коммуникабельным, разработчики и пользователи хотят без особых проблем взаимодействовать с множеством баз данных, разработанных индивидуально. В результате возникла потребность в стандартизации тех характеристик, которые ранее были отданы на усмотрение разработчика. Несколько лет эксплуатации конкретных систем и теоретических исследований дали новые идеи, которые требуют единообразия при воплощении в программных продуктах. Для удовлетворения этих потребностей ISO разработал новый стандарт SQL 92.
Стандарт SQL 92 превышает первый стандарт SQL по объему примерно в пять раз. В нем значительно расширена область стандартизации, а также определен стандарт для ряда существовавших характеристик, которые до этого были отданы на волю разработчика, включены те моменты, которые ранее были опущены. Поскольку стандарт SQL 92, включает как подмножество стандарт 89, можно ссылаться на стандарт 92, если программный продукт удовлетворяет требованиям стандарта 89 или некоторым промежуточным требованиям.
Естественно, те продукты, которые используются, могут по-своему расширять стандарт. Для того чтобы прикладной программист мог выделять все специфические моменты, имея дело с такими расширениями, новый стандарт требует применения флаггера (flagger) – программы, проверяющей основной код и помечающей (маркирующей) все предложения SQL, не соответствующие стандарту 92. Непомеченные предложения ведут себя так, как описано в стандарте. Для помеченных предложений следует применять системную документацию. Возможна ситуация, при которой предложение соответствует стандарту, а его поведение – нет. Такое предложение также помечается. В любом случае, этот стандарт более полон, чем предыдущий.
Роль SQL
В настоящее время, SQL выполняет много различных функций:
• SQL — язык интерактивных запросов. Пользователи вводят команды SQL в интерактивных программах с целью выборки данных и отображения их на экране. Это удобный способ выполнения специальных запросов.
• SQL — язык программирования баз данных. Чтобы получить доступ к базе данных, программисты вставляют в свои программы команды SQL. Эта методика используется как в программах, написанных пользователями, так и в служебных программах баз данных (таких как генераторы отчетов).
• SQL — язык администрирования баз данных. Администратор базы данных, находящейся на рабочей станции или на сервере, использует SQL для определения структуры базы данных и управления доступом к данным.
• SQL — язык создания приложений клиент/сервер. В программах для персональных компьютеров SQL используется как средство организации связи по локальной сети с сервером баз данных, в которой хранятся совместно используемые данные. Архитектура клиент/сервер весьма популярна в приложениях корпоративного уровня.
• SQL — язык доступа к данным в среде Internet . На Web-серверах SQL используется как стандартный язык для доступа к корпоративным базам данных.
• SQL — язык распределенных баз данных. В системах управления распределенными базами данных SQL помогает распределять данные среди нескольких взаимодействующих вычислительных систем. Программное обеспечение каждой системы посредством SQL связывается с другими системами, посылая им запросы на доступ к данным.
• SQL — язык шлюзов баз данных. В вычислительных сетях с различными СУБД SQL часто используется в шлюзовой программе, которая позволяет СУБД одного типа связываться с СУБД другого типа.
Таким образом, SQL превратился в полезный и мощный инструмент, обеспечивающий пользователям, программам и вычислительным системам доступ к информации, содержащейся в реляционных базах данных.
Преимущества SQL
SQL — это легкий для понимания язык и в то же время универсальное программное средство управления данными.
Успех языку SQL принесли следующие его особенности:
• независимость от конкретных СУБД;
• межплатформенная переносимость;
• наличие стандартов;
• одобрение компанией IBM (СУБД DB2);
• поддержка со стороны компании Microsoft (протокол ODBC и технология ADO);
• реляционная основа;
• высокоуровневая структура, напоминающая английский язык;
• возможность выполнения специальных интерактивных запросов;
• обеспечение программного доступа к базам данных;
• возможность различного представления данных;
• полноценность как языка, предназначенного для работы с базами данных;
• возможность динамического определения данных;
• поддержка архитектуры клиент/сервер;
• расширяемость и поддержка объектно-ориентированных технологий;
• возможность доступа к данным в среде Internet;
• интеграция с языком Java (протокол JDBC).
Все перечисленные выше факторы явились причиной того, что SQL стал стандартным инструментом для управления данными на персональных компьютерах, рабочих станциях и крупных серверах. Ниже эти факторы рассмотрены более подробно.
Дата: 2019-02-02, просмотров: 722.