Использование разветвлений позволяет моделировать жизненные ситуации, в которых выполнение некоторых действий зависит от каких-либо условий. Например, если идет дождь, то надо взять с собой зонтики, а если говорить о программировании, то использование разветвлений позволяет менять порядок выполнения операторов.
Выделяют несколько типов разветвлений. Их схемы алгоритмов приведены на рис. 3.1а,б,в,г.

Рис. 3.1.Типы разветвлений
В каждой из них есть оператор, в котором записано логическое выражение. Почему выражение называется логическим? По типу результата. Логический тип имеет всего два значения – истина (True) или ложь (false). В зависимости от значения логического выражения выполняется одна или другая ветвь разветвления. Таким образом и меняется порядок выполнения операторов в программе.
На рис. 3.1а приведена блок-схема стандартного разветвления: в каждой ветви стоит по одному оператору. На рис. 3.1б приведена блок-схема усеченного разветвления: в одной из ветвей нет операторов. Желательно, чтобы операторов не было в ветви «нет». На рис. 3.1в приведена блок-схема вложенного разветвления: одно разветвление вложено в другое. На рис. 3.1г приведена блок-схема разветвления с группированием операторов: в ветвях стоят несколько операторов.
В языке C# для реализации разветвлений используется условный оператор и оператор выбора.
Синтаксис условного оператора в C# имеет следующий вид:
If (логическое выражение) оператор1;
else оператор2;
Он работает так: вычисляется логическое выражение. Оно имеет значение типа bool. Если значение логического выражения имеет значение true, то выполняется оператор1 и на этом выполнение оператора заканчивается. Если значение логического выражения принимает значение false , то выполняется оператор2. Такой оператор реализует стандартное разветвление (рис. 3.1а).
Как реализуется усеченное разветвление (рис. 3.1б)? Используя такие слова: ветви else может и не быть. В этом случае при значении логического выражения false оператор заканчивается. Тогда условный оператор имеет вид
If (логическое выражение) оператор1;
Как реализуется вложенное разветвление (рис. 3.1в). Говорят, что оператор1 и оператор2 – это любые операторы языка, в том числе и условный оператор. И всё.
If (логическое выражение) оператор1;
If (логическое выражение) оператор1;
else оператор2;
else оператор3;
Остался оператор с группированием операторов (рис. 3.1.г). Это реализовано так: если в ветвях условного оператора необходимо выполнить несколько операторов, они объединяются в программный блок с использованием пары скобок {…}.
If (логическое выражение)
{
Оператор1;
…
ОператорN;
}
Else
{
оператор2;
}
В программировании различают простые и сложные операторы. В сложных операторах используются другие операторы. В простых не используются. Условный оператор - это сложный оператор.
Нужны примеры. Но сначала займемся алгоритмизацией на уровне схем алгоритмов.
Пример 3.1. Вычислить значение максимума из двух чисел.
Решение представлено на рис. 3.2 в двух вариантах
а) б)
Рис. 3.2. Два варианта поиска максимума из двух значений
На рис. 3.2а в логическом выражении сравниваются значения (a > b). Если результат сравнения истина ( true или да), то переменной max присваивается значение переменной a: max = a, иначе в переменную max скидывается значение переменной b: max=b.
На рис. 3.2б сделано по-другому. Сначала в переменную max скидывают значение переменной a, то есть сначала предполагают, что максимальное значение - это значение переменной a. А потом проверяют эту гипотезу следующим образом: max < b. Если это условие выполняется, это значит, что есть еще большее значение чем max, значит max надо менять (m ax= b). А если это условие ложно, то max менять не надо (ничего не делать).
Давайте разовьем задачу: найдем максимум из трех чисел a, b и c.
Как её решать? Сведём решение этой задачи к предыдущей, ведь максимум из двух чисел, надо надеяться, искать умеем. Как? Найдем максимум из двух первых чисел, получим результат сравнения двух чисел, а дальше этот результат сравним с третьим числом. Получим результат сравнения трех чисел (рис. 3.3). Именно так и следует решать эту задачу!
Рис. 3.3. Поиск максимума из трех значений
Теперь решим более сложную, а главное объемную задачу, в которой продемонстрируем структурный стиль создания блок-схем. Этот стиль требует, чтобы у каждого оператора был один вход и один выход, причем выход должен находиться строго под входом. Затем создадим консольное приложение, в котором будет всего лишь один метод, полностью решающий задачу (конечно, кроме метода Main). В этом методе не будем использовать методы m ax и min из класса Math. Почему? Чтобы продемонстрировать структурный стиль написания исходного текста программы, в котором используются уступы, то есть отступы на 2-3 пробела вправо.
Принцип расстановки уступов в программном коде простой: операторы, которые вложены в другие операторы, пишутся с уступом. Операторы, выполняющиеся последовательно, пишутся на одном уровне.
Пример 3.2. Вычислить значение y при вводимых значениях a и х.
y= 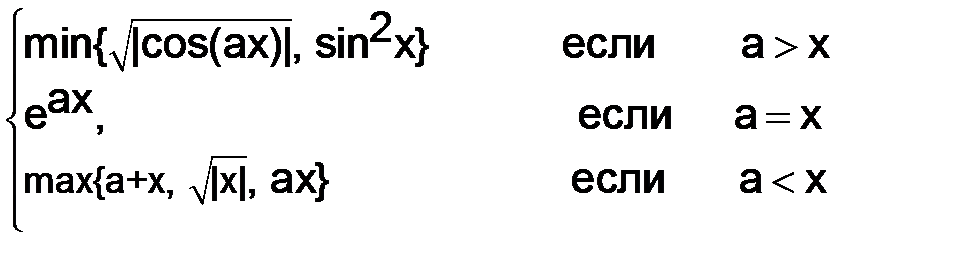
|
Понятно, что здесь будет много сравнений, реализованных с использованием условных операторов. С чего надо начинать? Представляется, что сначала надо разбить задачу на три ветки, а потом уже в каждой ветке решать свою задачу.
Рис. 3.4. Схема алгоритма примера 3.2
На рис. 3.4 представлена схема алгоритма метода решения задачи с «ручным» поиском максимума из трех чисел и минимума из двух чисел. На блок-схеме наглядно видны вложенные операторы, которые должны быть выделены в исходном тексте уступами. Видны также и операторы, выполняющиеся последовательно. Они должны быть записаны на одном уровне исходного текста.
Почему важно использовать структурный стиль составления блок-схем и записи исходных текстов программ. В этом случае блок-схемы и программы получаются наглядными и легко читаемыми. В конечном счете это приводит к тому, что в них будет меньше ошибок, а если ошибки и будут, то найти их будет значительно проще. При написании кода интеллектуальный текстовый редактор VS сам расставляет пробелы, однако при редактировании уже написанного исходного кода может ошибаться. Следите за этим! Несоблюдение правил структурного написания кода и составления блок-схем может привести к алгоритмическим ошибкам, и, как следствие, приведет к большой потере времени для поиска ошибок.
В примере 3.1 представлен исходный текст приложения, реализующего схему алгоритма, представленного на рис. 3.4, а на рис. 3.5 – результаты работы программы.
Пример 3.3.
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
namespace ConsoleApplication1
{
class Program
{
static void Main(string[] args)
{
Console.WriteLine("VVedite x,a");
double x = Convert.ToDouble(Console.ReadLine());
double a = Convert.ToDouble(Console.ReadLine());
double y = RazvMaxMin(x, a);
Console.WriteLine("Dly x=" + x + " a=" + a);
Console.WriteLine("Result y=" + y);
Console.ReadLine();
}
static double RazvMaxMin(double x, double a)
{
double y;
if (a > x)
{
double y1=Math.Sqrt(Math.Abs(Math.Cos(a*x)));
double y2=Math.Pow(Math.Sin(x),2);
double min;
if (y1 < y2)
min=y1;
else
min=y2;
y=min;
}
else
if (a == x)
y=Math.Exp(a*x);
else
{
double max=a+x;
if (max < Math.Sqrt(Math.Abs(x))) max=Math.Sqrt(Math.Abs(x));
if (max < a*x) max=a*x;
y=max;
}
return y;
}
}
}
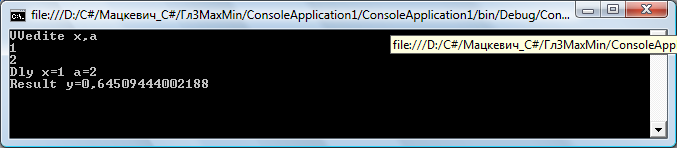
Рис. 3.5. Результат работы программы примера 3.3
Интересно, по какой из трех ветвей пошла программа? Сделайте, хотя бы мысленно, так, чтобы на экран выводилась информация об этом.
Может, сюда вставить пример из геометрии? Он покажет использование логических операций и поможет детям в аналитической геометрии.
Оператор выбора switch позволяет сделать несколько альтернативных вариантов выбора дальнейшего выполнения программы. В принципе этот выбор можно сделать и с помощью набора условных операторов, но с использованием оператора switch это будет нагляднее, а значит и надежнее в смысле меньшего числа ошибок.
Форма записи оператора выбора следующая:
switch (выражение)
{
case константа1:
последовательность операторов
break ;
case константа2:
последовательность операторов
break ;
. . .
case константа N:
последовательность операторов
break ;
default :
последовательность операторов
break ;
}
Где выражение должно быть такого типа, значения которого известны точно, например типа int, byte, short, char, string. Нельзя использовать типы для действительных чисел (double, single, …), так как их значения представлены в двоичном коде с конечной точностью и это есть существенное ограничение в использовании оператора выбора switch. Константы должны иметь тип, совместимый с типом выражения. Не допускается наличия двух одинаковых по значению констант выбора. Ветка default выполняется в том случае, если не одна константа не совпадает с значением выражения. Эта ветка необязательна. Если значение выражения совпало с одной из констант, то выполняется соответствующая последовательность оператора вплоть до оператора break, по которому заканчивается оператор выбора.
Пример 3.4. Написать фрагмент программного кода, в котором проверяется значение переменной на возможные значения 1, 2, 3, 4.
Пример 3.5.
. . .
switch (i)
{
case 1:
Console.WriteLine("i=1");
break;
case 2:
Console.WriteLine("i=2");
break;
case 3:
Console.WriteLine("i=3");
break;
case 4:
Console.WriteLine("i=4");
break;
default:
Console.WriteLine("не то !!!!!");
break;
}
. . .
В операторе выбора switch не каждая ветвь должна заканчиваться оператором break. Можно организовать работу swicht так, что несколько веток будут ссылаться на одну и ту же последовательность операторов (пример 3.6).
Пример 3.6.
. . .
switch (i)
{
case 1:
case 2:
case 3:
Console.WriteLine("i=1 или 2 или 3");
break;
case 4:
Console.WriteLine("i=4");
break;
default:
Console.WriteLine("не то !!!!!");
break;
}
. . .
Сокращенная проверка
В C# существует сокращенная проверка, которая удобна, если проверку надо проводить внутри какого-то кода.
Её синтаксис такой:
Условие ? Действие1 : Действие2
Как это работает? Пишем условие, которое должно проверяться. После символа «?» пишется действие, которое должно выполняться в случае истинного результата проверки, а после символа «:» записываем действие, которое должно быть выполнено в случае неудачной проверки.
Пример 3.6.
int i=10;
Console.WriteLine( i==10 ? " i=10":" i != 10");
Console.WriteLine( i==20 ? " i=20":" i != 20");

Рис. 3.6. Результат программы примера 3.6 сокращенной проверкой
Лекция 4. Введение в ООП
До эпохи объектно-ориентированного программирования (ООП) в универсальных алгоритмических языках преобладал процедурный метод программирования, в котором реализованы принципы структурного программирования. Согласно этим принципам, задача разбивается на подзадачи, эти подзадачи разбиваются еще на подзадачи и так делается до тех пор, пока каждая из подзадач не станет простой. Этот этап проектирования называется нисходящим программированием. Получившиеся простые подзадачи реализуются в виде процедур. Напоминаю, что соответствии с принципами ООП процедуры начали называть методами. Кроме того использовался этап, который называется восходящим программированием, то есть реализуются процедуры, в которых вызываются уже написаные процедуры. И так далее, пока не будет написана процедура (метод), которая решает поставленную задачу. Все эти подпрограммы работают с данными. Где размещаются эти данные, и кто контролирует эти данные? Те данные, которые описаны в подпрограммах, доступны только внутри них. А есть еще данные, которые доступны всем подпрограммам. К ним доступ имеют все, и нет никакого контроля за их изменением. В этом случае приложение можно представить в виде совокупности процедур (рис. 4.1).
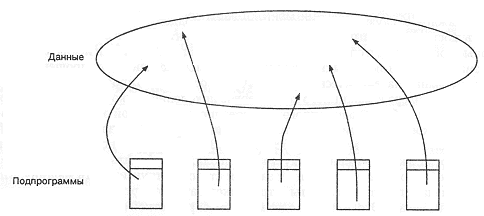
Рис. 4.1. Приложение (совокупность процедур), реализованное по принципам процедурного программирования
В какой-то исторический момент стало понятно, что это является существенным недостатком такого подхода. Более того, организация программы в виде набора подпрограмм недостаточно эффективна в плане структуризации задачи. Надо более строго и вдумчиво заниматься проектированием программы – до написания самого кода. Это и реализуется в ООП.
По большому счету, программирование – это моделирование реального мира. На разных этапах развития программирования уровень этого моделирования был разным. Например, при использовании только последовательных программ возможно было моделировать ситуации, в которых последовательно выполнялись точно определенные действия. При использовании разветвлений уже можно было рассматривать разные варианты поведения. В основе ООП лежит принцип, в котором реальный мир рассматривается как мир, состоящий из объектов. Объектами могут выступать любые элементы (части) реального мира, в которых можно семантически (в соответствии со здравым смыслом) объединить некоторые свойства объектов и некоторые действия над ними. Например: предметы из окружающего мира имеют вес, цвет и т.п. – это свойства. Ими можно пользоваться: телевизор можно включить, можно регулировать звук, яркость – это методы. Животные, люди – это тоже объекты. Город, деревня, страна – объекты. Задача, которую решали в теме разветвления – объект: входные данные, которые необходимы для ее решения – это ее свойства; алгоритм, решающий задачу – метод объекта. Далее, в зависимости от задачи, можно акцентировать внимание на одних или других свойствах и методах. Например, если телевизор работает, то важны одни его характеристики – сколько каналов, какова цветопередача и т.д., а если он сломался и его надо выкинуть – совсем другие – сколько он весит, пройдет ли он в дверь или в окно. Так вот, ООП реализует этот объектный принцип посредством некоторых новых формализованных понятий.
Таким образом, основа ООП - это объект, за которым стоят конкретные данные. Как сказать, что объект описывается такими-то данными и имеет такие-то методы? Это делать для каждого объекта отдельно? Вряд ли. Может быть, сказать, что есть некий тип объектов и конкретные объекты принадлежат этому типу. Пример с телевизором: телевизоров конкретного типа много, а вот тип у них один. Так вот, для описания объекта вводится понятие класс ( class ). Это некоторый каркас, или план построения объекта, некоторая логическая абстракция, которая задает структуру объекта.
Далее. В основу ООП заложены три парадигмы программирования: инкапсуляция, наследование и полиморфизм. (Парадигма программирования – это совокупность идей и понятий, определяющих стиль написания программы.)
Кратко остановимся на каждой парадигме.
Инкапсуляция – это идея, которая заключается в том, что объект представляет собой капсулу, в которой: первое – данные объекта объединены с методами в единое целое; второе – эти данные и методы имеют разную степень доступности. Пример инкапсуляции из реального мира: телевизор – это инкапсуляция свойств телевизора, таких как размеры, вес, мощность, набор микросхем, блок питания, устройства регулировки звука, яркости, цвета, уровень звука, яркости, цвета и т.п. Это данные. Зачем здесь их перечисляли так много? Чтобы пояснить разные степени доступности: размеры, вес, мощность доступны, но менять их возможности нет (только для чтения), набор микросхем, блок питания, устройства регулировки пользователю телевизора вообще неинтересны, значит доступ к ним надо разрешить только специалистам, а вот уровни звука, яркости, цвета будут общедоступными. Методы в телевизоре – включение – общедоступный метод, регулировка звука и т.п. – общедоступный метод, а вот регулировка уровня питающего напряжения – это удел специалистов. Две крайние степени уровня доступа в объекте: private – доступно только внутри объекта и public – доступно всем (и внутри и вне объекта). Эти уровни доступа надо выставлять в каждом объекте или в классе? Пример с телевизором – в одном телевизоре разрешить менять уровень питающего напряжения, в другом запретить? Конечно нет! Уровни доступа надо выставлять в классе.
Наследование. Эта идея (парадигма) заключается в том, что каждый (почти каждый) класс есть наследник другого класса. Зачем это в программировании? При такой организации данные или методы, описанные в некотором классе, могут быть использованы при работе с объектом класса, являющегося потомком этого некоторого класса без их повторного описания. При реализации этой парадигмы появляется возможность создания дерева классов, которая (возможность) с успехом реализована в ООП. Во всех языках, поддерживающих идеологию ООП, уже созданы иерархические структуры в виде дерева, классы в которых организованы по принципу от общего к частному. Это дерево имеет один корень, то есть класс, в котором собраны самые общие для всех классов данные и методы. Понятно, что у этого класса предка нет, поэтому он не является ничьим наследником.
Ну и наконец, полиморфизм. Здесь не все так очевидно. Идея состоит в следующем: надо сделать так, чтобы у разных классов были разные по содержанию методы, но с одинаковыми именами. Тогда возникает вопрос – какой из этих методов (метод какого класса) будет работать при вызове метода, ведь эти методы имеют одинаковые имена. Решение такое – все зависит от объекта, с которым будут работать в данный момент. Представляется, что примером полиморфизма может быть следующая ситуация: В Москве готовятся к Дню города. Мэр дает службам города поручение: подготовиться к Дню города. Как понимают это поручение разные службы? По-разному. Электрики занимаются иллюминацией, дворники начинают мести дворы, строители ремонтируют дороги, полицейские усиливают наряды и т.п. Получается полиморфизм – имя метода одно (привести город в порядок), а содержание у объектов разных классов разное.
При использовании принципов ООП основное внимание уделяется не методам, а структурированным данным, которыми являются объекты. Основными логическими строительными блоками программы становятся классы и объекты, а не алгоритмы, как в процедурном программировании. И тогда проект в виде набора классов будет выглядеть, как на рис. 4.2.
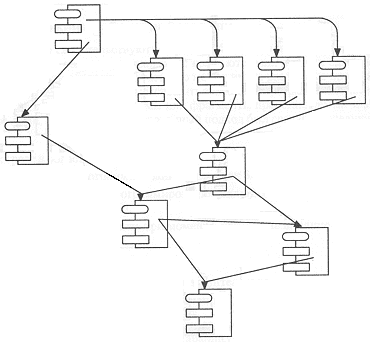
Рис. 4.2. Проект в виде набора классов, созданный на основе ООП
Еще раз о классах и объектах: класс – это образец (каркас), состоящий из данных и методов обработки этих данных. Это всего лишь логическая абстракция. Объект – экземпляр класса, соответствующий данному классу, у которого свои индивидуальные данные и методы, описанные в классе. Это не есть абстракция, это есть конкретика. Под каждый объект надо будет отводить память в ОП.
Здесь можно провести соответствие с типом данных и переменой. Тип - это класс, переменная – объект или экземпляр класса.
Ну, а теперь, как это реализовано на C# ?
В лекции 2, в которой говорилось о методах, был пример, где решалась следующая задача: по сторонам треугольника следует вычислить углы этого треугольника (пример 2.1, исходный код пример 2.4).
Метод, с использованием которого можно решить задачу, уже написан. Его заголовок
double ugol(double a, double b, double c);.
Параметрами метода являются значения сторон треугольника, метод возвращает значение угла, противоположного первому параметру. Вызывая этот метод с разными вариантами фактических параметров, можно вычислить все углы треугольника. Правда, результаты будут возвращены в радианах.
Есть еще метод
double Rad_v_Drad(double x),
который переводит значения из радиан в градусы.
Посмотрите внимательно, что написано до описания этих методов в примере 2.6. Там есть строка
class Program.
Оказывается, что уже в том примере работали в классе, но не акцентировали на этом внимание.
Теперь надо написать свой класс, инициировать объект этого класса и организовать работу с этим объектом.
Итак, в соответствии с парадигмой инкапсуляции, класс – это объединение данных и методов. Данные хранятся в полях класса, методы соответствуют методам в классе. Что должно находиться в полях нашего класса? Данные, которые нужны для решения задачи – исходные данные – это стороны треугольника, а результаты – три угла? То же в полях класса. А какие методы нужно организовать в классе, чтобы получить результаты? Ответ очевиден – метод ugol () и метод Rad_v_Drad(). Пока сделаем и поля, и методы общедоступными, то есть объявим их с директивой public (пример 4.1).
Пример 4.1
class CLUgli
{
public double a, b, c;
public double ua, ub, uc;
public double ugol(double a, double b, double c)
{
double aa;
aa = (b * b + c * c - a * a) / (2 * b * c);
aa = Math.Acos(aa);
return aa;
}
public double Rad_v_Drad(double x)
{
return 180 * x / Math.PI;
}
}
После разбора примера 2.4 и чтения предыдущего абзаца представляется, что здесь и обсуждать почти нечего. Единственое, на что надо обратить внимание, это то, что описание всего класса оформлено, как программный блок ({..}).
Что нужно делать далее? Ведь это только класс, то есть логическая абстракция, каркас для построения объекта. А конкретный треугольник – это объект данного класса. Сколько может быть объектов этого класса? Сколько необходимо, столько и можно. У каждого объекта свои значения полей, а вот методы у всех объектов данного класса одни и те же. Значит, надо завести объект, дальше заполнять поля с исходными данными, вызывать методы, результаты выполнения которых должны заполнить поля с результатами, и в итоге значения этих полей надо будет вывести на экран. Где это будем делать? – в методе Main (пример 4.2).
Пример 4.2
Class Program
{
static void Main(string[] args)
{
CLUgli ugli1 = new CLUgli();
// инициализация объекта ugli1 с помощью вызова конструктора без параметров
ugli1.a = Convert.ToDouble(Console.ReadLine());
// работа с открытыми полями класса
ugli1.b = Convert.ToDouble(Console.ReadLine());
ugli1.c = Convert.ToDouble(Console.ReadLine());
ugli1.ua = ugli1.ugol(ugli1.a, ugli1.b, ugli1.c);
// вызовы открытых методов
ugli1.ua = ugli1.Rad_v_Drad(ugli1.ua);
ugli1.ub = ugli1.ugol(ugli1.b, ugli1.a, ugli1.c);
ugli1.ub = ugli1.Rad_v_Drad(ugli1.ub);
ugli1.uc = ugli1.ugol(ugli1.c, ugli1.a, ugli1.b);
ugli1.uc = ugli1.Rad_v_Drad(ugli1.uc);
// работа с открытыми полями класса
Console . WriteLine ("Класс: для сторон a =" + ugli 1. a + " b =" +
ugli1.b + " c=" + ugli1.c);
Console.WriteLine(" Углы получаются a1=" + ugli1.ua + " a2=" +
ugli1.ub + " a3=" + ugli1.uc);
Console . ReadLine ();
}
}
Теперь надо построчно разобрать работу метода Main из примера 4.2.
Строка CLUgli ugli1 = new CLUgli();
требует особого внимания. Почему? В ней производятся два действия. Первое – объявляется переменная нашего класса CLUgli с именем ugli 1 . Переменная класса – это и есть объект. Еще в этой строке происходит инициализация этого объекта с использованием команды new и вызова специального метода, который называется конструктор. Напомним, что в C# есть значимые и ссылочные типы, и об этом говорилось еще в лекции 1. Для инициализации (выделения памяти в ОП) значимых типов, переменные достаточно объявить (описать). Для переменных ссылочных типов этого мало. Их надо инициализировать «вручную», то есть используя команду new и вызов специального метода, называемого конструктор. Именно это здесь и сделано. Как компилятор определяет, что метод есть конструктор? – его имя совпадает с именем метода. Как компилятор определяет, что это метод, а не класс? За именем есть круглые скобки, значит это метод. Где в нашем классе описание этого метода? Нет! Если описания конструктора нет в классе, будет вызываться конструктор его предка. В описании нашего класса не указан предок. Но все классы являются потомками класса с именем object. Значит, по умолчанию, будет вызван конструктор класса object. Здесь работает парадигма наследования.
Два действия, которые выполняются в этой строке, можно разделить на две команды: отдельным оператором объявить переменную класса, а потом отдельным оператором провести инициализацию этой переменной
Дальше идет работа с полями и методами объекта ugli 1. Работу проводят с использованием точечной идентификации, согласно которой сначала указывается имя объекта и через точку пишется имя поля или имя метода.
В примерах 4.1 и 4.2 приведены фрагменты первого или даже нулевого варианта решения задачи. Основное возражение у тех, кто владеет методикой ООП, может возникнуть из-за того, что поля класса должны быть обязательно закрытыми ( private ), а доступ к ним должен быть реализован только через методы. Пока этого делать не будем. Это будет позже.
Продемонстрируем использование закрытых методов. Напомним, если метод закрытый, то им можно пользоваться (его можно вызывать) только в методах этого класса. Какой из двух методов можно закрыть? Закроем метод Rad_v_Drad(), а его вызов организуем в методе ugol ( double a , double b , double c ). Что при этом изменится? Метод ugol () будет возвращать угол уже в градусах. А попытка вызова метода Rad_v_Drad() в методе Main() приведет к ошибке, которую выявит компилятор на этапе построения решения. В примере 4.3 продемонстрировано все пространсто имен, включающее в себя и класс CLUgli , предназначенный для решения задачи и класс Program , в котором находится метод Main().
Пример 4.3
Дата: 2019-11-01, просмотров: 514.