Лекции по Теории информации
Подготовил В.С. Прохоров
Содержание
Введение
1. Понятие информации. Задачи и постулаты прикладной теории информации
1.1 Что такое информация
1.2 Этапы обращения информации
1.3 Информационные системы
1.4 Система передачи информации
1.5 Задачи и постулаты прикладной теории информации
2. Количественная оценка информации
2.1 Свойства энтропии
2.2 Энтропия при непрерывном сообщении
2.3 Условная энтропия
2.4 Взаимная энтропия
2.5 Избыточность сообщений
3. Эффективное кодирование
4. Кодирование информации для канала с помехами
4.1 Разновидности помехоустойчивых кодов
4.2 Общие принципы использования избыточности
4.3 Связь информационной способности кода с кодовым расстоянием
4.4 Понятие качества корректирующего кода
4.5 Линейные коды
4.6 Математическое введение к линейным кодам
4.7 Линейные коды как пространство линейного векторного пространства
4.8 Построение двоичного группового кода
4.8.1. Составление таблицы опознавателей
4.8.2. Определение проверочных равенств
4.8.3. Мажоритарное декодирование групповых кодов
4.8.4. Матричное представление линейных кодов
4.8.5. Технические средства кодирования и декодирования для групповых кодов
4.9 Построение циклических кодов
4.9.1. Общие понятия и определения
4.9.2. Математическое введение к циклическим кодам
4.9.3. Требования, предъявляемые к многочлену
4.10 Выбор образующего многочлена по заданному объему кода и заданной корректирующей способности
4.10.1. Обнаружение одиночных ошибок
4.10.2. Исправление одиночных или обнаружение двойных ошибок
4.10.3. Обнаружение ошибок кратности три и ниже
4.10.4. Обнаружение и исправление независимых ошибок произвольной кратности
4.10.5. Обнаружение и исправление пачек ошибок
4.10.6. Методы образования циклического кода
4.10.7. Матричная запись циклического кода
4.10.8. Укороченные циклические коды
4.11. Технические средства кодирования и декодирования для циклических кодов
4.11.1. Линейные переключательные схемы
4.11.2. Кодирующие устройства
4.11.3. Декодирующие устройства
Список литературы
Содержание
Введение
Теория информации является одним из курсов при подготовке инженеров, специализирующихся в области автоматизированных систем управления и обработки информации. Функционирование таких систем существенным образом связано с получением, подготовкой, передачей, хранением и обработкой информации, поскольку без осуществления этих этапов невозможно принять правильное решение и осуществить требуемое управляющее воздействие, которое является конечной целью функционирования любой системы.
Возникновение теории информации связывают обычно с появлением фундаментальной работы американского ученого К. Шеннона «Математическая теория связи» (1948). Однако в теорию информации органически вошли и результаты, полученные другими учеными. Например, Р. Хартли, впервые предложил количественную меру информации (1928), акад. В. А. Котельников, сформулировал важнейшую теорему о возможности представления непрерывной функции совокупностью ее значений в отдельных точках отсчета (1933) и разработал оптимальные методы приема сигналов на фоне помех (1946). Акад. А. Н. Колмогоров, внес огромный вклад в статистическую теорию колебаний, являющуюся математической основой теории информации (1941). В последующие годы теория информации получила дальнейшее развитие в трудах советских ученых (А. Н. Колмогорова, А. Я. Хинчина, В. И. Сифорова, Р. Л. Добрушина, М. С. Пинскера, А. Н. Железнова, Л. М. Финка и др.), а также ряда зарубежных ученых (В. Макмиллана, А. Файнстейна, Д. Габора, Р. М. Фано, Ф. М. Вудворта, С. Гольдмана, Л. Бриллюэна и др.).
К теории информации, в ее узкой классической постановке, относят результаты решения ряда фундаментальных теоретических вопросов. Это в первую очередь: анализ вопросов оценки «количества информации»; анализ информационных характеристик источников сообщений и каналов связи и обоснование принципиальной возможности кодирования и декодирования сообщений, обеспечивающих предельно допустимую скорость передачи сообщений по каналу связи, как при отсутствии, так и при наличии помех.
Если рассматривают проблемы разработки конкретных методов и средств кодирования сообщений, то совокупность излагаемых вопросов называют теорией информации и кодирования или прикладной теорией информации.
Попытки широкого использования идей теории информации в различных областях науки связаны с тем, что в основе своей эта теория математическая. Основные ее понятия (энтропия, количество информации, пропускная способность) определяются только через вероятности событий, которым может быть приписано самое различное физическое содержание. Подход к исследованиям в других областях науки с позиций использования основных идей теории информации получил название теоретико-информационного подхода. Его применение в ряде случаев позволило получить новые теоретические результаты и ценные практические рекомендации. Однако не редко такой подход приводит к созданию моделей процессов, далеко не адекватных реальной действительности. Поэтому в любых исследованиях, выходящих за рамки чисто технических проблем передачи и хранения сообщений, теорией информации следует пользоваться с большой осторожностью. Особенно это касается моделирования умственной деятельности человека, процессов восприятия и обработки им информации.
Содержание конспекта лекций ограничивается рассмотрениемвопросов теории и практики кодирования.
Что такое информация
С начала 1950-х годов предпринимаются попытки использовать понятие информации (не имеющее до настоящего времени единого определения) для объяснения и описания самых разнообразных явлений и процессов.
В некоторых учебниках дается следующее определение информации:
Информация - это совокупность сведений, подлежащих хранению, передаче, обработке и использованию в человеческой деятельности.
Такое определение не является полностью бесполезным, т.к. оно помогает хотя бы смутно представить, о чем идет речь. Но с точки зрения логики оно бессмысленно. Определяемое понятие (информация) здесь подменяется другим понятием (совокупность сведений), которое само нуждается в определении.
При всех различиях в трактовке понятия информации, бесспорно, то, что проявляется информация всегда в материально-энергетической форме в виде сигналов.
Информацию, представленную в формализованном виде, позволяющем осуществлять ее обработку с помощью технических средств, называют данными.
Этапы обращения информации
Можно выделить следующие этапы обращения информации:
1) восприятие информации;
2) подготовка информации;
3) передача и хранение информации;
4) обработка информации;
5) отображение информации;
6)воздействие информации.

Рис.1.1 Этапы обращения информации
На этапе восприятия информации осуществляется целенаправленное извлечение и анализ информации о каком-либо объекте (процессе), в результате чего формируется образ объекта, проводится его опознание и оценка. При этом отделяют интересующую информацию от шумов.
На этапе подготовки информации получают сигнал в форме, удобной для передачи или обработки (нормализация, аналого-цифровое преобразование и т.д.).
На этапе передачи и хранения информация пересылается либо из одного места в другое, либо от одного момента времени до другого.
На этапе обработки информации выделяются ее общие и существенные взаимозависимости для выбора управляющих воздействий (принятия решений).
На этапе отображения информации она представляется человеку в форме, способной воздействовать на его органы чувств.
На этапе воздействия информация используется для осуществления необходимых изменений в системе.
Информационные системы
В основе решения многих задач лежит обработка информации. Для облегчения обработки информации создаются информационные системы (ИС). Автоматизированными называют ИС, в которых применяют технические средства, в частности ЭВМ. Большинство существующих ИС являются автоматизированными, поэтому для краткости просто будем называть их ИС. В широком понимании под определение ИС подпадает любая система обработки информации. По области применения ИС можно разделить на системы, используемые в производстве, образовании, здравоохранении, науке, военном деле, социальной сфере, торговле и других отраслях. По целевой функции ИС можно условно разделить на следующие основные категории: управляющие, информационно-справочные, поддержки принятия решений. Заметим, что иногда используется более узкая трактовка понятия ИС как совокупности аппаратно-программных средств, задействованных для решения некоторой прикладной задачи. В организации, например, могут существовать информационные системы, на которые возложены следующие задачи: учет кадров и материально-технических средств, расчет с поставщиками и заказчиками, бухгалтерский учет и т. п. Эффективность функционирования информационной системы (ИС) во многом зависит от ее архитектуры. В настоящее время перспективной является архитектура клиент-сервер. В распространенном варианте она предполагает наличие компьютерной сети и распределенной базы данных, включающей корпоративную базу данных (КБД) и персональные базы данных (ПБД). КБД размещается на компьютере-сервере, ПБД размещаются на компьютерах сотрудников подразделений, являющихся клиентами корпоративной БД. Сервером определенного ресурса в компьютерной сети называется компьютер (программа), управляющий этим ресурсом. Клиентом — компьютер (программа), использующий этот ресурс. В качестве ресурса компьютерной сети могут выступать, к примеру, базы данных, файловые системы, службы печати, почтовые службы. Тип сервера определяется видом ресурса, которым он управляет. Например, если управляемым ресурсом является база данных, то соответствующий сервер называется сервером базы данных. Достоинством организации информационной системы по архитектуре клиент-сервер является удачное сочетание централизованного хранения, обслуживания и коллективного доступа к общей корпоративной информации с индивидуальной работой пользователей над персональной информацией. Архитектура клиент-сервер допускает различные варианты реализации.
Система передачи информации
Информация поступает в систему в форме сообщений. Под сообщением понимают совокупность знаков или первичных сигналов, содержащих информацию.
Источник сообщений в общем случае образует совокупность источника информации (ИИ) (исследуемого или наблюдаемого объекта) и первичного преобразователя (ПП) (датчика, человека-оператора и т.д.), воспринимающего информацию о протекающем в нем процессе.

Рис. 1.2. Структурная схема одноканальной системы передачи информации.
Различают дискретные и непрерывные сообщения.
Дискретные сообщения формируются в результате последовательной выдачи источником сообщений отдельных элементов - знаков.
Множество различных знаков называют алфавитом источника сообщения, а число знаков - объемом алфавита.
Непрерывные сообщения не разделены на элементы. Они описываются непрерывными функциями времени, принимающими непрерывное множество значений (речь, телевизионное изображение).
Для передачи сообщения по каналу связи ему ставят в соответствие определенный сигнал. Под сигналом понимают физический процесс, отображающий (несущий) сообщение.
Преобразование сообщения в сигнал, удобный для передачи по данному каналу связи, называют кодированием в широком смысле слова.
Операцию восстановления сообщения по принятому сигналу называют декодированием.
Как правило, прибегают к операции представления исходных знаков в другом алфавите с меньшим числом знаков, называемых символами. При обозначении этой операции используется тот же термин “кодирование”, рассматриваемый в узком смысле. Устройство, выполняющее такую операцию, называют кодирующим или кодером. Так как алфавит символов меньше алфавита знаков, то каждому знаку соответствует некоторая последовательность символов, которую называют кодовой комбинацией.
Число символов в кодовой комбинации называют ее значностью, число ненулевых символов - весом.
Для операции сопоставления символов со знаками исходного алфавита используют термин “декодирование”. Техническая реализация этой операции осуществляется декодирующим устройством или декодером.
Передающее устройство осуществляет преобразование непрерывных сообщений или знаков в сигналы, удобные для прохождения по линии связи. При этом один или несколько параметров выбранного сигнала изменяют в соответствии с передаваемой информацией. Такой процесс называют модуляцией. Он осуществляется модулятором. Обратное преобразование сигналов в символы производится демодулятором
Под линией связи понимают среду (воздух, металл, магнитную ленту и т.д.), обеспечивающую поступление сигналов от передающего устройства к приемному устройству.
Сигналы на выходе линии связи могут отличаться от сигналов на ее входе (переданных) вследствие затухания, искажения и воздействия помех.
Помехами называют любые мешающие возмущения, как внешние, так и внутренние, вызывающие отклонение приинятых сигналов от переданных сигналов.
Из смеси сигнала с помехой приемное устройство выделяет сигнал и посредством декодера восстанавливает сообщение, которое в общем случае может отличаться от посланного. Меру соответствия принятого сообщения посланному сообщению называют верностью передачи.
Принятое сообщение с выхода системы связи поступает к абоненту-получателю, которому была адресована исходная информация.
Совокупность средств, предназначенных для передачи сообщений, называют каналом связи.
Свойства энтропии
При равновероятности знаков алфавита Рi = 1/m из формулы Шеннона получают:
 .
.
Условная энтропия
До сих пор предполагалось, что все элементы сообщения независимы, т.е. появление каждого данного элемента никак не связано с предшествующими элементами.
Рассмотрим теперь два ансамбля
Х = (х1, x2, ... ,xr)
Y = (y1, y2, ..., ys) ,
которые определяются не только собственными вероятностями р(хi) и p(yj), но и условными вероятностями pxi(yj), pyj(xi), где i = 1, 2, ... , r ; j = 1, 2, ... , s.
Систему двух случайных величин (сообщений) Х, Y можно изобразить случайной точкой на плоскости. Событие, состоящее в попадании случайной точки (X, Y) в область D, принято обозначать в виде (X, Y) Ì D.
Закон распределения системы двух случайных дискретных величин может быть задан с помощью табл. 2.5.
 Таблица 2.5.
Таблица 2.5.
| Y X | y1 | y2 | . . . | ys |
| x1 | Р11 | Р12 | . . . | Р1s |
| x2 | Р21 | Р22 | . . . | Р2s |
| : | : | : | : | : |
| xr | Рr1 | Рr2 | . . . | Рrs |
где Рij - вероятность события, заключающегося в одновременном выполнении равенства Х = xi, Y = yj. При этом
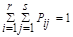 .
.
Закон распределения системы случайных непрерывных величин (Х, Y) задают при помощи функции плотности вероятности р(x, y).
Вероятность попадания случайной точки (Х,Y) в область D определяется равенством
 .
.
Функция плотности вероятности обладает следующими свойствами:
1) р(x,y) ³ 0
2) 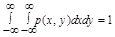
Если все случайные точки (X,Y) принадлежат области D, то
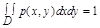 .
.
Условным распределением составляющей Х при Y = yj (yj сохраняет одно и то же значение при всех возможных значениях Х) называют совокупность условных вероятностей Pyj(x1), Pyj(x2), ... , Pyj(xr)
Аналогично определяется условное распределение составляющей Y.
Условные вероятности составляющих X и Y вычисляют соответственно по формулам:

Для контроля вычислений целесообразно убедиться, что сумма вероятностей условного распределения равна единице.
Так как условная вероятность события yj при условии выполнения события xi принимается по определению
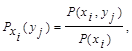
то вероятность совместного появления совокупности состояний
P(xi,yj) = P(xi) Pxi(yj).
Аналогично, условимся вероятность события xi при условии выполнения события yj:
 .
.
Поэтому общую энтропию зависимых ансамблей X и Y определяют по формуле Шеннона:
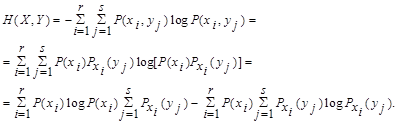
С учетом соотношения 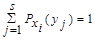 получают
получают
Н(Х,Y) = H(X) + HX(Y), где Н(Х) - энтропия ансамбля Х;
HX(Y) - условная энтропия ансамбля Y при условии, что сообщение ансамбля Х известны:

Для независимых событий Х и Y: Pxi(yj) = P(yj) и поэтому
HX(Y) = Н(Y) и, следовательно, Н(Х,Y) = H(X) + H(Y).
Если Х и Y полностью зависимы, т.е. при появлении xi неизбежно следует yj, то Р(xi,yj) равна единице при i = j и нулю при i ¹ j. Поэтому НX(Y) = 0, и , следовательно, Н(X,Y) = Н(Х), т.е. при полной зависимости двух ансамблей один из них не вносит никакой информации.
Полученное выражение для условной энтропии
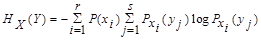
можно использовать и как информативную характеристику одного ансамбля Х, элементы которого взаимно зависимы. Положив Y = X, получим
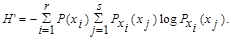
Например, алфавит состоит из двух элементов 0 и 1. Если эти элементы равновероятны, то количество информации, приходящееся на один элемент сообщения: Н0 = log m = log 2 = 1 бит. Если же, например, Р(0)=ѕ, а Р(1) = ј, то

В случае же взаимной зависимости элементов, определяемой, например, условными вероятностями Р0(0) = 2/3; P0(1) = 1/3; P1(0) = 1; P1(1) = 0, то условная энтропия
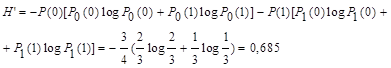
Энтропия при взаимно зависимых элементах всегда меньше, чем при независимых, т.е. H’<H.
Пример9: Задано распределение вероятностей случайной дискретной двумерной величины:
Таблица 2.6.
| Y X | 4 | 5 |
| 3 | 0,17 | 0,10 |
| 10 | 0,13 | 0,30 |
| 12 | 0,25 | 0,05 |
Найти законы распределения составляющих Х и Y.
Решение: 1) Сложив вероятности “по строкам”, получим вероятности возможных значений Х:
Р(3) = 0,17 + 0,10 = 0,27
P(10) = 0,13 +0,30 = 0,43
P(12) = 0,25 + 0,05 = 0,30.
Запишем закон распределения составляющей Х:
Таблица 2.7.
| Х | 3 | 10 | 12 |
| P(xi) | 0,27 | 0,43 | 0,30 |
Контроль: 0,27 + 0,43 + 0,30 = 1
2) Сложив вероятности “по столбцам”, аналогично найдем распределение составляющей Y:
Таблица 2.8.
| Y | 4 | 5 |
| P(yj) | 0,55 | 0,45 |
Контроль: 0,55 + 0,45 = 1
Пример10: Задана случайная дискретная двумерная величина (X,Y):
Таблица 2.9.
| Y X | y1 = 0,4 | y2 = 0,8 |
| x1 = 2 | 0,15 | 0,05 |
| x2 = 5 | 0,30 | 0,12 |
| x3 = 8 | 0,35 | 0,03 |
Найти: безусловные законы распределения составляющих; условный закон распределения составляющей Х при условии, что составляющая Y приняла значение y1 = 0,4; условный закон распределения составляющей Y при условии, что составляющая Х приняла значение х2 = 5
Решение: 1) Сложив вероятности “по строкам”, напишем закон распределения Х.
Таблица 2.10.
| X | 2 | 5 | 8 |
| P(x) | 0,20 | 0,42 | 0,38 |
2) Сложив вероятности “по столбцам”, найдем закон распределения Y.
Таблица 2.11.
| Y | 0,4 | 0,8 |
| P(y) | 0,80 | 0,20 |
3) Найдем условные вероятности возможных значений Х при условии, что составляющая Y приняла значение y1 = 0,4
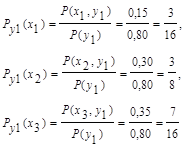
Напишем искомый условный закон распределения Х:
Таблица 2.12.
| X | 2 | 5 | 8 |
| Py1(xi) | 3/16 | 3/8 | 7/16 |
Контроль: 3/16 + 3/8 + 7/16 = 1
Аналогично найдем условный закон распределения Y:
Таблица 2.13.
| Y | 0,4 | 0,8 |
| Px2(yj) | 5/7 | 2/7 |
Контроль: 5/7 + 2/7 = 1.
Пример11: Закон распределения вероятностей системы, объединяющей зависимые источники информации X и Y, задан с помощью таблицы:
Таблица 2.14.
| Y X | y1 | y2 | y3 |
| x1 | 0,4 | 0,1 | 0 |
| x2 | 0 | 0,2 | 0,1 |
| x3 | 0 | 0 | 0,2 |
Определить энтропии Н(Х), H(Y), HX(Y), H(X,Y).
Решение: 1. Вычислим безусловные вероятности Р(xi) и Р(yj) системы:
а) сложив вероятности “по строкам” , получим вероятности возможных значений Х: P(x1) = 0,5
P(x2) = 0,3
P(x3) = 0,2
б) сложив вероятности “по столбцам”, получим вероятности возможных значений Y:
P(y1) = 0,4
P(y2) = 0,3
P(y3) = 0,3
2. Энтропия источника информации Х:
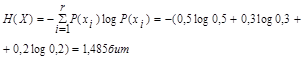
3. Энтропия источника информации Y:

4. Условная энтропия источника информации Y при условии, что сообщения источника Х известны:
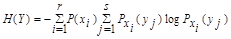
Так как условная вероятность события yj при условии выполнения события хi принимается по определению
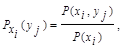
поэтому найдем условные вероятности возможных значений Y при условии, что составляющая Х приняла значение x1:
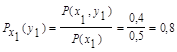
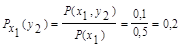
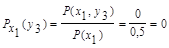
Для х2: 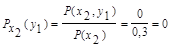
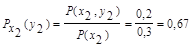
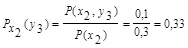
Для х3: 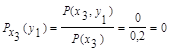
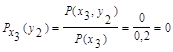
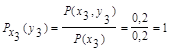
Поэтому: HX(Y) = - [0,5 (0,8 log 0,8 + 0,2 log 0,2) +
+0,3 (0,67 log 0,67 + 0,33 log 0,33) + 0,2 (1 log 1)] = 0,635
5. Аналогично, условная энтропия источника информации Х при условии, что сообщения источника Y известны:
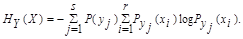
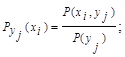
Для у1: 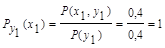
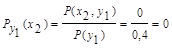
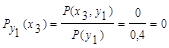
Для у2: 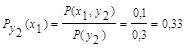
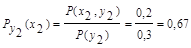
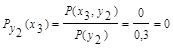
Для у3: 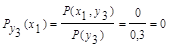
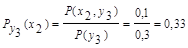

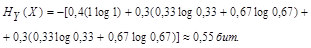
6. Общая энтропия зависимых источников информации Х и Y:
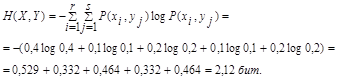
Проверим результат по формуле:
Н(Х,Y) = H(X) +HX(Y) = 1,485 + 0,635 = 2,12 бит
Н(Х,Y) = H(Y) +HY(X) = 1,57 + 0,55 = 2,12 бит
Пример12: Известны энтропии двух зависимых источников Н(Х) = 5бит; Н(Y) = 10бит. Определить, в каких пределах будет изменяться условная энтропия НХ(Y) в максимально возможных пределах.
Решение: Уяснению соотношений между рассматриваемыми энтропиями источников информации способствует их графическое отображение.
При отсутствии взаимосвязи между источниками информации:
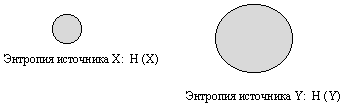
Рис. 2.5.
Если источники информации независимы, то НХ(Y) = Н(Y) = 10 бит, а НY(X) = H(X) = 5 бит, и, следовательно, Н(X,Y) = H(X) + H(Y) = 5 +10 = 15 бит. Т.е., когда источники независимы НХ(Y) = Н(Y) = 10 бит и поэтому принимают максимальное значение.
По мере увеличения взаимосвязи источников НХ(Y) и НY(X) будут уменьшаться:

Рис. 2.6.
При полной зависимости двух источников один из них не вносит никакой информации, т.к. при появлении xi неизбежно следует уj , т.е. Р(xi, уj) равно единице при i = j и нулю при i ¹ j. Поэтому
НY(X) = 0 и, следовательно, Н(X,Y) = НХ(Y) .
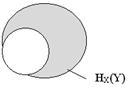
Рис. 2.7.
При этом НХ(Y) = Н(Y) - Н(Х) = 10 - 5 = 5 бит. Поэтому НХ(Y) будет изменяться от 10 бит до 5 бит при максимально возможном изменении Нy(Х) от 5 бит до 0 бит.
Пример13: Определите Н(Х) и НХ(Y), если Р(х1,y1) = 0,3; P(x1,y2) = 0,2;
P(x3,y2) = 0,25; P(x3,y3) = 0,1
Пример14: Определите Н(Х), H(Y), H(X,Y), если Р(х1,y1) = 0,2; P(x2,y1) = 0,4;
P(x2,y2) = 0,25; P(x2,y3) = 0,15
Взаимная энтропия
Пусть ансамбли Х и Y относятся соответственно к передаваемому и принимаемому сообщениям. Различия между Х и Y обуславливаются искажениями в процессе передачи сообщений под воздействием помех.
При отсутствии помех различий между ансамблями Х и Y не будет, а энтропии передаваемого и принимаемого сообщений будут равны: Н(Х) = Н(Y).
Воздействие помех оценивают условной энтропией НY(X). Поэтому получаемое потребителем количество информации на один элемент сообщения равно: Е(Х,Y) = Н(Х) – НY(X)
Величину Е(Х,Y) называют взаимной энтропией.
Если ансамбли Х и Y независимы, то это означает, что помехи в канале привели к полному искажению сообщения, т.е. НY(X) = Н(Х), а получаемое потребителем количество информации на один элемент сообщения:Е(Х,Y)=0.
Если Х и Y полностью зависимы, т.е. помехи в канале отсутствуют, то НY(X) = 0 и Е(Х,Y) = H(Y).
Так как НY(X) = Н(Х,Y) – H(Y), то Е(Х,Y) = H(X) + H(Y) – H(X,Y), или
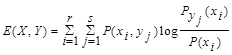 .
.
Пример15: Определите Н(Х) и Е(Х,Y), если Р(х1,y1) = 0,3; P(x1,y2) = 0,2;
P(x2,y3) = 0,1; P(x3,y2) = 0,1; P(x3,y3) = 0,25.
Избыточность сообщений
Чем больше энтропия, тем большее количество информации содержит в среднем каждый элемент сообщения.
Пусть энтропии двух источников сообщений Н1<Н2, а количество информации, получаемое от них одинаковое, т.е. I = n1H1 = n2H2, где n1 и n2 - длина сообщения от первого и второго источников. Обозначим
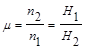
При передаче одинакового количества информации сообщение тем длиннее, чем меньше его энтропия.
Величина m, называемая коэффициентом сжатия, характеризует степень укорочения сообщения при переходе к кодированию состояний элементов, характеризующихся большей энтропией.
При этом доля излишних элементов оценивается коэффициентом избыточности:
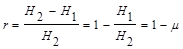
Русский алфавит, включая пропуски между словами, содержит 32 элемента (см. Пример), следовательно, при одинаковых вероятностях появления всех 32 элементов алфавита, неопределенность , приходящаяся на один элемент, составляет Н0 = log 32 = 5 бит
Анализ показывает, что с учетом неравномерного появления различных букв алфавита H = 4,42 бит, а с учетом зависимости двухбуквенных сочетаний H’ = 3,52 бит, т.е. H’< H < H0
Обычно применяют три коэффициента избыточности:
1) частная избыточность, обусловленная взаимосвязью r’ = 1 - H’/H;
2) частная избыточность, зависящая от распределения r’’ = 1 - H/ H0;
3) полная избыточность r0 = 1 - H’/ H0
Эти три величины связаны зависимостью r0 = r’ + r’’ - r’r’’
Вследствие зависимости между сочетаниями, содержащими две и больше букв, а также смысловой зависимости между словами, избыточность русского языка (как и других европейских языков) превышает 50% (r0 =1 - H’/ H0 = 1 - 3,52/5 = 0,30).
Избыточность играет положительную роль, т.к. благодаря ней сообщения защищены от помех. Это используют при помехоустойчивом кодировании.
Вполне нормальный на вид лазерный диск может содержать внутренние (процесс записи сопряжен с появлением различного рода ошибок) и внешние (наличие физических разрушений поверхности диска ) дефекты. Однако даже при наличии физических разрушений поверхности лазерный диск может вполне нормально читаться за счет избыточности хранящихся на нем данных. Корректирующие коды С 1, С 2, Q - и Р - уровней восстанавливают все известные приводы, и их корректирующая способность может достигать двух ошибок на каждый из уровней С 1 и C 2 и до 86 и 52 ошибок на уровни Q и Р соответственно. Но затем, по мере разрастания дефектов, корректирующей способности кодов Рида—Соломона неожиданно перестает хватать, и диск без всяких видимых причин отказывает читаться, а то и вовсе не опознается приводом. Избыточность устраняют построением оптимальных кодов, которые укорачивают сообщения по сравнению с равномерными кодами. Это используют при архивации данных. Действие средств архивации основано на использовании алгоритмов сжатия, имеющих достаточно длинную историю развития, начавшуюся задолго до появления первого компьютера —/еще в 40-х гг. XX века. Группа ученых-математиков, работавших в области электротехники, заинтересовалась возможностью создания технологии хранения данных, обеспечивающей более экономное расходование пространства. Одним из них был Клод Элвуд Шеннон, основоположник современной теории информации. Из разработок того времени позже практическое применение нашли алгоритмы сжатия Хаффмана и Шеннона-Фано. А в 1977 г. математики Якоб Зив и Абрахам Лемпел придумали новый алгоритм сжатия, который позже доработал Терри Велч. Большинство методов данного преобразования имеют сложную теоретическую математическую основу. Суть работы архиваторов: они находят в файлах избыточную информацию (повторяющиеся участки и пробелы), кодируют их, а затем при распаковке восстанавливают исходные файлы по особым отметкам. Основой для архивации послужили алгоритмы сжатия Я. Зива и А. Лемпела. Первым широкое признание получил архиватор Zip. Со временем завоевали популярность и другие программы: RAR , ARJ , АСЕ, TAR , LHA и т. д.В операционной системе Windows достаточно четко обозначились два лидера: WinZip (домашняя страница этой утилиты находится в Internet по адресу http :// www . winzip . com ) и WinRAR, созданный российским программистом Евгением Рошалем (домашняя страница http :// www . rarlab . com ). WinRAR активно вытесняет WinZip так как имеет: удобный и интуитивно понятный интерфейс; мощную и гибкую систему архивации файлов; высокую скорость работы; более плотно сжимает файлы. Обе утилиты обеспечивают совместимость с большим числом архивных форматов. Помимо них к довольно распространенным архиваторам можно причислить WinArj (домашняя страница http :// www . lasoft - oz . com ). Стоит назвать Cabinet Manager (поддерживает формат CAB, разработанный компанией Microsoft для хранения дистрибутивов своих программ) и WinAce (работает с файлами с расширением асе и некоторыми другими). Необходимо упомянуть программы-оболочки Norton Commander, Windows Commander или Far Manager. Они позволяют путем настройки файлов конфигурации подключать внешние DOS-архиваторы командной строки и организовывать прозрачное манипулирование архивами, представляя их на экране в виде обычных каталогов. Благодаря этому с помощью комбинаций функциональных клавиш можно легко просматривать содержимое архивов, извлекать файлы из них и создавать новые архивы. Хотя программы архивации, предназначенные для MS-DOS, умеют работать и под управлением большинства версий Windows (в окне сеанса MS-DOS), применять их в этой операционной системе нецелесообразно. Дело в том, что при обработке файлов DOS-архиваторами их имена урезаются до 8 символов, что далеко не всегда удобно, а в некоторых случаях даже противопоказано.
Выбирая инструмент для работы с архивами, прежде всего, следует учитывать как минимум два фактора: эффективность, т. е. оптимальное соотношение между экономией дискового пространства и производительностью работы, и совместимость, т. е. возможность обмена данными с другими пользователями
Последняя, пожалуй, наиболее значима, так как по достигаемой степени сжатия, конкурирующие форматы и инструменты различаются на проценты, а высокая вычислительная мощность современных компьютеров делает время обработки архивов не столь существенным показателем. Поэтому при выборе программы-архиватора важнейшим критерием становится ее способность "понимать" наиболее распространенные архивные форматы.
При архивации надо иметь в виду, что качество сжатия файлов сильно зависит от степени избыточности хранящихся в них данных, которая определяется их типом. К примеру, степень избыточности у видеоданных обычно в несколько раз больше, чем у графических, а степень избыточности графических данных в несколько раз больше, чем текстовых. На практике это означает, что, скажем, изображения форматов BMP и TIFF , будучи помещенными в архив, как правило, уменьшаются в размере сильнее, чем документы MS Word. А вот рисунки JPEG уже заранее компрессированы, поэтому даже самый лучший архиватор для них будет мало эффективен. Также крайне незначительно сжимаются исполняемые файлы программ и архивы.
Программы-архиваторы можно разделить на три категории.
1. Программы, используемые для сжатия исполняемых файлов, причем все файлы, которые прошли сжатие, свободно запускаются, но изменение их содержимого, например русификация, возможны только после их разархивации.
2. Программы, используемые для сжатия мультимедийных файлов, причем можно после сжатия эти файлы свободно использовать, хотя, как правило, при сжатии изменяется их формат (внутренняя структура), а иногда и ассоциируемая с ними программа, что может привести к проблемам с запуском.
3. 3. Программы, используемые для сжатия любых видов файлов и каталогов, причем в основном использование сжатых файлов возможно только после разархивации. Хотя имеются программы, которые "видят" некоторые типы архивов как самые обычные каталоги, но они имеют ряд неприятных нюансов, например, сильно нагружают центральный процессор, что исключает их использование на "слабых машинах".
Принцип работы архиваторов основан на поиске в файле "избыточной" информации и последующем ее кодировании с целью получения минимального объема. Самым известным методом архивации файлов является сжатие последовательностей одинаковых символов. Например, внутри вашего файла находятся последовательности байтов, которые часто повторяются. Вместо того, чтобы хранить каждый байт, фиксируется количество повторяемых символов и их позиция. Например, архивируемый файл занимает 15 байт и состоит из следующих символов:
В В В В В L L L L L А А А А А
В шестнадцатеричной системе
42 42 42 42 42 4С 4С 4С 4С 4С 41 41 41 41 41
Архиватор может представить этот файл в следующем виде (шестнадцатеричном):
01 05 42 06 05 4С 0А 05 41
Это значит: с первой позиции пять раз повторяется символ "В", с позиции 6 пять раз повторяется символ "L" и с позиции 11 пять раз повторяется символ "А". Для хранения файла в такой форме потребуется всего 9 байт, что на 6 байт меньше исходного.
Описанный метод является простым и очень эффективным способом сжатия файлов. Однако он не обеспечивает большой экономии объема, если обрабатываемый текст содержит небольшое количество последовательностей повторяющихся символов.
Более изощренный метод сжатия данных, используемый в том или ином виде практически любым архиватором, — это так называемый оптимальный префиксный код и, в частности, кодирование символами переменной длины (алгоритм Хаффмана).
Код переменной длины позволяет записывать наиболее часто встречающиеся символы и группы символов всего лишь несколькими битами, в то время как редкие символы и фразы будут записаны более длинными битовыми строками. Например, в любом английском тексте буква Е встречается чаще, чем Z, а X и Q относятся к наименее встречающимся. Таким образом, используя специальную таблицу соответствия, можно закодировать каждую букву Е меньшим числом битов и использовать более длинный код для более редких букв.
Популярные архиваторы ARJ , РАК, PKZIP работают на основе алгоритма Лемпела-Зива. Эти архиваторы классифицируются как адаптивные словарные кодировщики, в которых текстовые строки заменяются указателями на идентичные им строки, встречающиеся ранее в тексте. Например, все слова какой-нибудь книги могут быть представлены в виде номеров страниц и номеров строк некоторого словаря. Важнейшей отличительной чертой этого алгоритма является использование грамматического разбора предшествующего текста с расположением его на фразы, которые записываются в словарь. Указатели позволяют сделать ссылки на любую фразу в окне установленного размера, предшествующего текущей фразе. Если соответствие найдено, текущая фраза заменяется указателем на своего предыдущего двойника.
При архивации, как и при компрессировании, степень сжатия файлов сильно зависит от формата файла. Графические файлы, типа TIF и GIF, уже заранее компрессированы (хотя существует разновидность формата TIFF и без компрессии), и здесь даже самый лучший архиватор мало чего найдет для упаковки. Совсем другая картина наблюдается при архивации текстовых файлов, файлов PostScript, файлов BMP и им подобных.
Формат ВМР
BMP (Windows Device Independent Bitmap) — это один из старейших форматов, к тому же являющийся «родным» форматом Windows. Основная область применения BMP — хранение файлов, использующихся внутри операционной системы (например, обоев для Рабочего стола или иконок программ). Файл, сохраненный в этом формате, прочитает любой графический редактор. Файлы, сохраненные в BMP, могут содержать как 256 цветов, так и 16 700 000 оттенков. BMP - самый простой (если не сказать примитивный) графический формат. Записанный в нем файл представляет собой массив данных, содержащий информацию о цвете каждого пиксела, т. е. изображение размером 1024x768 точек с глубиной цвета 24 бита будет занимать 1024x768x3= 2 359 296 байт (без учета служебной информации об объеме и имени файла, составляющей еще несколько сот байт). Основной недостаток формата, ограничивающий его применение, — большой размер BMP-файлов. Конечно, можно попробовать сохранить изображение в формате BMP со сжатием, однако это часто вызывает проблемы при работе с некоторыми графическими пакетами. Даже при нынешних емкостях жестких дисков хранить коллекцию 2,5-Мбайт графических файлов крайне обременительно. Да и передача графики в формате BMP по сети (по крайней мере, без сжатия с помощью различных архиваторов) — обременительно. 10—20 лет назад возможности «железа» были намного скромнее, поэтому вопрос о разработке методов сжатия графической информации до приемлемых размеров стоял очень остро.
Формат JPEG
Форматы на основе LZW не справлялись с эффективной обработкой фотографий, и потому появилась идея сжатия с потерей качества. Суть его заключается в том, что часть малозаметных для глаза деталей изображения опускается, а восстановленный после сжатия цифровой массив не полностью соответствует оригиналу. Таким образом, можно добиться довольно большой степени сжатия данных — в 10—20 раз вместо двукратного, производимого без потерь.
В 1991 г. группа Joint Photographic Experts Group, опирающаяся на более чем полувековой опыт исследований в области человеческого зрения, представила первую спецификацию формата JPEG. Через три года она была признана индустриальным стандартом кодирования неподвижных изображений, зарегистрированным как ISO/IEC 10918-1. Впоследствии JPEG лег в основу стандарта сжатия видео MPEG.
JPEG (Joint Photographic Experts Group) на сегодняшний день является одним из наиболее популярных форматов. Всеобщего признания он достиг благодаря одноименному алгоритму сжатия, который показал отличные результаты в соотношении размер/качество.
JPEG сжимает файлы весьма оригинальным образом: он ищет не одинаковые пиксели, а вычисляет разницу между соседними квадратами размером 9x9 пикселей.
Информация, не заслуживающая внимания, отбрасывается, а ряд полученных значений усредняется. В результате получают файл в десятки или сотни раз меньшего размера, чем BMP. Естественно, чем выше уровень компрессии, тем ниже качество.
С помощью формата JPEG лучше всего хранить фотографии и другие похожие на них изображения. Скриншоты, схемы и чертежи лучше хранить в формате TIFF, поскольку при сохранении в JPEG неизбежно появятся помехи и «шумы».
Если обрабатывают файл в графическом редакторе, то сохранять его в JPEG нужно лишь после выполнения всех действий по редактированию. В противном случае с каждым сохранением его качество будет ухудшаться, что в конце концов приведет к «размазыванию» изображения.
Процесс обработки графической информации алгоритмом JPEG очень напоминает сжатие звуковых данных в формате МРЗ:
1. Исходное изображение делится на блоки размером 16x16 пикселов. Дальнейшие операции выполняются над каждым из них по отдельности, что дает существенный выигрыш в скорости по сравнению с тем случаем, когда картинка обрабатывается как единый массив.
2. Переход к более подходящему для сжатия способу представления цветов. Привычная модель RGB переводится в YCbCr, где Y — сигнал яркости, а Сb и Сг — насыщенность синего и красного соответственно. Такой способ представления цветов будет предпочтительнее и с точки зрения восприятия изображения человеческим глазом. Как известно, зрительная информация воспринимается с помощью сенсоров двух типов: палочек и колбочек. Первые анализируют яркостную составляющую изображения, вторые — цвет. Палочек в 20 раз больше, чем колбочек, и, следовательно, глаз более восприимчив к изменению яркости, чем цвета.
Если учесть эту особенность человеческого зрения, то из матриц значений насыщенности синего и красного следует отбрасывать все четные строки и столбцы. Таким образом теряется 75% информации о распределении цветов. Матрица отчетов о яркости не изменяется, а делится на четыре части, образуя блоки 8x8.
3. Выполняется дискретное косинусное преобразование (Discrete Cosine Transform, DCT), предложенное В. Ченом в 1981 г. Оно сходно с преобразованием Фурье, только у DCT несколько ниже вероятность возникновения ошибки. Применение этого чисто математического приема объясняется тем, что в реальных изображениях соседние блоки достаточно похожи (коэффициент корреляции — 0,9—0,98). DCT преобразует информацию о цвете и яркости каждого пиксела в информацию о скорости изменения этих величин. Это преобразование является обратимым, и, значит, по новой матрице может быть восстановлена исходная с точностью до погрешности данного метода. DCT позволяет значительно сократить объем данных и размер получаемого файла.
В результате DCT графическое изображение описывается двухмерной функцией, показывающей скорости изменения яркости и цвета. Причем для большинства фотографий характерны плавные, мягкие переходы этих параметров на соседних участках. Как выявили исследования, для корректного восприятия таких изображений глазу важнее низкочастотные компоненты матрицы DCT (плавные переходы), а высокочастотные (резкая смена оттенков и яркости) уже не столь существенны. Поэтому последние кодируются с меньшей детальностью, а при превышении определенной пороговой величины, зависящей от выбранного качества сжатия, вообще принимаются равными нулю. Следовательно, при кодировании файлов с низким качеством резкие цветовые переходы смазываются, а изображение становится несколько мозаичным.
4. Кодирование полученных величин методом Хаффмана — последний этап. Оно заключается в присваивании часто повторяющимся элементам обрабатываемой информации самых коротких кодовых последовательностей, а редко встречающимся — более длинных.
Вследствие этого размер получаемого файла несколько уменьшается.
Такой достаточно сложный алгоритм сжатия графической информации позволил формату JPEG обрабатывать фотографические изображения с большой эффективностью и неплохим качеством. Правда, область применения данного формата лишь фотографиями и ограничивается.
Формат PNG
PNG (Portable Network Graphics) обязан своим появлением на свет формату GIF, а точнее, его коммерческому статусу. Дело в том, что GIF основан на запатентованном алгоритме LZW, принадлежащем фирме Unisys, которая в первые годы существования GIF не предъявляла никаких претензий фирме CompuServe, разработавшей этот формат. Но стремительное развитие Интернета в 1993—1994 гг. внесло свои коррективы во взаимоотношения компаний. И из корыстных целей Unisys инициировала судебный процесс против CompuServe. Решение суда обязывало разработчиков ПО, в котором используется формат GIF, платить фирме Unisys лицензионные отчисления. Таким образом, GIF стал платным.
По традиции любому коммерческому программному продукту рано или поздно будет предложена бесплатная альтернатива. Примерами в данном случае могут служить операционные системы Windows и Linux или форматы сжатия звука МРЗ и OGG, причем этот список можно продолжать довольно долго. GIF также не суждено было удержать статус безальтернативного формата. Днем рождения PNG можно считать 4 января 1995 г., когда Т. Боутелл предложил в ряде конференций Usenet создать свободный формат, который был бы не хуже GIF. И уже через три недели после публикации идеи были разработаны четыре версии нового формата. Вначале он имел название PBF (Portable Bitmap Format), а нынешнее имя получил 23 января 1995 г. Уже в декабре того же года спецификация PNG версии 0.92 была рассмотрена консорциумом W3C, а с выходом 1 октября 1996 г. версии 1.0 PNG был рекомендован в качестве полноправного сетевого формата.
К моменту создания PNG глубина цвета 8 бит, предоставляемая GIF, перестала удовлетворять современным требованиям. Среди предложений довести глубину цвета до 24, 48 и даже до 64 бит был выбран первый вариант.
Как показало время, данное решение оказалось рациональным и отвечающим современным запросам. В заголовке файла формата PNG хранится описание всей палитры. Подстроившись таким образом под реальное количество цветов, можно получить достаточно компактный файл на выходе. Формат PNG имеет массу достоинств, выгодно отличающих его от конкурентов. Самое главное из них — предварительная фильтрация обрабатываемых данных, поскольку большинство алгоритмов сжатия рассчитаны на одну вполне определенную модель информации. Например, формат JPEG «заточен» для изображений с плавными цветовыми переходами, a GIF — с большим количеством однотонных областей. И чем больше структура картинки отличается от эталона, тем ниже эффективность сжатия. Порой изменение всего нескольких бит приводит к тому, что алгоритм начинает работать очень хорошо или, наоборот, очень плохо. Тем временем формат PNG стабильнее воспринимает такие трансформации, и высокий коэффициент сжатия достигается практически для любого рода изображений путем преобразования информации в вид, наиболее приемлемый для обработки.
Формат PNG очень удобен для создания элементов оформления вебстраниц благодаря наличию более совершенного альфа-канала, чем у GIF. Число его уровней доведено до 254 (в большинстве форматов альфа-канал ограничивается всего двумя слоями), а прозрачность каждого из них может варьировать от 0 до 100%. Таким образом, PNG предоставляет веб-дизайнерам очень мощное и удобное средство для построения сложных
многослойных изображений. Единственный тип рисунков, где PNG не может потеснить GIF на вебстраницах, — небольшие кнопки и «смайлики» размером до 700—800 байт в формате GIF. За счет служебной информации и описания палитры такие файлы в формате PNG занимают на 10—30% больше места, да и анимированные картинки этот формат не поддерживает. Кстати, статичные «смайлики» чаще используются на страницах журналов, нежели во Всемирной паутине.
Будучи форматом следующего поколения PNG обладает еще несколькими приятными новшествами по сравнению со «старичками» JPEG и GIF. Во-первых, это несколько модифицированный вариант чересстрочной развертки. В отличие от GIF, где не до конца загруженное изображение отображается крупными строками, в формате PNG такой файл показывается большими точками, т. е. развертку следовало бы называть не чересстрочной, а «чересточечной», хотя первый вариант — уже устоявшийся (произошел от английского interlace).
Во-вторых, нельзя не отметить встроенную в формат гамма-коррекцию. При переносе графического файла с одного компьютера на другой изображение может выглядеть светлее или темнее, чем в оригинале. Ситуация обостряется тогда, когда на компьютерах установлены различные ОС (MS Windows и Linux) или когда машины построены на базе разных платформ (например, PC и Macintosh). Соотношение между цифровой информацией и реально наблюдаемыми на мониторе цветами называется гаммой.
Встроенная в формат PNG гамма-коррекция работает следующим образом: данные о настройках дисплея, видеоплаты и ПО (информация о гамме) записываются в файл, при переносе которого на другой компьютер вид PNG-изображения не изменится.
Формат TIFF
Формат TIFF (Tagged Image File Format) наиболее распространен среди тех пользователей, которые превыше всего ставят качество изображения. Именно TIFF используется в издательствах, поскольку при сохранении изображения в этом формате не происходит потерь качества. К тому же этот формат поддерживают практически все программы как PC, так и Macintosh.
В принципе, TIFF — это наиболее универсальный формат, обеспечивающий среднюю степень сжатия файла. Храня работы в TIFF, можно быть уверенным, что при просмотре файла вы увидите именно то изображение, которое сохраняли. За качество придется расплачиваться достаточно большим объемом файлов. Наиболее актуально это для владельцев цифровых фотоаппаратов, которые сохраняют фотографии на компактные карты памяти. Однако если хотят получить фотографии, которые потом можно будет обработать в Photoshop, сохраняют работы в TIFF.
Формат RAW
Существует еще один формат, о котором хотелось бы упомянуть, — RAW. Его название созвучно английскому слову «raw» («сырой»). Действительно, при сохранении в RAW изображение записывается в самом что ни на есть сыром виде — как последовательность байтов, содержащих цветовую информацию о каждом пикселе. Цветовые значения описываются в шестнадцатеричном формате, где О = черный и 255 = белый. При таком способе записи объем файлов оказывается не просто большим, а огромным. Однако именно формат RAW получил популярность среди профессиональных фотографов.
Использование формата RAW в цифровой фотографии позволяет избежать искажений, вызываемых неверными настройками фотокамеры
Дело в том, что цветовой баланс изображения, сохраняемого на карту памяти, во многом зависит от настроек цифрового фотоаппарата, и в первую очередь от установки баланса белого. Если цветовой баланс задан неверно, «вытянуть» фотографию в графическом редакторе будет очень сложно, поскольку при коррекции одного цвета неизбежно «поплывут» другие. При использовании формата RAW цветовой баланс, установленный на фотоаппарате, не будет иметь никакого значения. Вы получите наиболее точную фотографию, которую можно легко обработать на PC.
КОДИРОВАНИЕ ЗВУКА
Для сохранения звука пользуются специальными программами — кодаками. Хотя качество результата у всех кодаков разное, принцип работы у них один.
Поклонники того или иного кодека не могут прийти к единому мнению, какой же из них лучше. Объясняется это просто: помимо таких объективных параметров, как размер файла и качество кодирования звука, существуют и субъективные факторы — восприятие каждого человека индивидуально.
Существует два основных стандарта, которые используют любители музыки во всем мире: МРЗ и WMA. Если стандарт WMA разрабатывается исключительно фирмой Microsoft, то кодек для сжатия цифрового звука в стандарте МРЗ может создать любой программист. В результате это привело к появлению большого количества алгоритмов кодирования. В условиях конкурентной борьбы за качество МРЗ-файлов на первое место вышел проект нескольких программистов — Lame.
Кодек Lame
Кодек Lame используют с 1998 году, когда с развитием Интернета между пользователями начался активный обмен файлами с данными и возникла проблема передачи звука через Сеть.
Многие фирмы стали разрабатывать программы для кодирования аудиосигнала с наименьшими потерями в качестве. Группа специалистов (MPEG), входящая в состав Международной организации стандартов (ISO), еще в конце 80-х годов разработала стандарт MPEG, на основе которого был создан современный стандарт сжатия звука MPEG 1.0 Audio Layer III — впоследствии он стал известен как МРЗ. Так как изначально утилиты для создания МРЗ-файлов распространялись за деньги, программисты стали искать способ бесплатно использовать алгоритмы работы кодека. Так среди многих других проектов появился кодек Lame, постепенно получивший огромную популярность. Основной особенностью Lame стало то, что разработчики сделали акцент на улучшении алгоритма специальной психоакустической модели. Принцип ее действия заключается в том, что из звукового файла удаляются те частоты, которые человеческое ухо воспринимать не в состоянии.
При кодировании цифрового звука (файлы с расширением WAV) основным параметром, влияющим на качество результата, является величина битрейта. Если использовать максимальное значение этого параметра, то получают звук, наиболее соответствующий оригиналу. Примерно до 2000 года широко использовалось значение битрейта 128 Кбит/с, а затем, с возросшей пропускной способностью современных каналов связи, наиболее распространенным стал битрейт 192 Кбит/с.
Еще один параметр, который может существенно улучшить качество звука, — функция VBR, позволяющая кодировать информацию с переменным битрейтом в зависимости от характера сигнала. Например, если в музыке присутствуют различные высокочастотные звуки (качественно сжать которые труднее всего), кодек принимает решение использовать для них самый высокий битрейт 320 Кбит/с.
Кодек WMA фирмы Microsoft
Кодек WMA был разработан фирмой Microsoft как стандарт хранения сжатой аудиоинформации в операционной системе Windows. Microsoft не стала пользоваться разработками организации MPEG, поэтому стандарт WMA является закрытым для использования другими разработчиками.
Microsoft стремится максимально использовать коммерческий потенциал WMA и поэтому защищает музыку в этом формате от нелегального копирования: WMA-файлы нельзя переконвертировать в файлы с расширением WAV.
Тем не менее популярность WMA растет. Это связано с тем, что при том же качестве звука, что и у стандарта МРЗ (по заявлению самой Microsoft), этот кодек позволяет получить меньший размер файла. Такой результат достигается за счет использования более низкого значения параметров битрейта, чем у МРЗ-файлов.
В последней, девятой, версии кодека создатели значительно переработали психоакустическую модель кодирования аудиоинформации, однако на максимальных значениях битрейта кодек от Microsoft до сих пор не может сравниться по качеству с кодеком Lame.
Выбор кодека для звука
При выборе кодека нужно руководствоавться двумя соображениями: если нужно получить файлы как можно меньшего размера — используют кодек от Microsoft, а если цель — получить максимальное качество звука, невзирая на размер файлов, выбирают Lame.
Другие кодеки для звука
Программистам и компаниям хочется сделать кодек, который станет всеобщим стандартом. Однако до сих пор ни один разработанный формат, отличный от WMA и МРЗ, не смог получить широкого распространения. Это произошло по двум причинам: либо кодек не очень хорошо сжимал аудиофайлы, либо программное обеспечение для его использования было полностью платным. Список кодеков, пытавшихся заменить МРЗ, достаточно велик:
ААС — улучшенный вариант стандарта MPEG по соотношению «размер файла/качество звука». Не получил особого распространения, потому что при кодировании аудиофайлов сильно загружает ресурсы компьютера.
Liquid Audio — коммерческий кодек, в котором содержание файла шифруется для пресечения нелегального копирования. Несмотря на то, что этот кодек по качеству результата превосходит МРЗ, отсутствие бесплатных программ для кодирования файлов помешало распространению этого формата.
МРЗрго — кодек, разработанный фирмой Tomson Multimedia. Был призван улучшить качество формата МРЗ на низких битрейтах. Особой популярности не получил из-за достаточно высокой цены и узкой области применения.
OGG Vorbis — этот сравнительно недавно появившийся кодек стоит особняком среди всех перечисленных форматов. Получаемые с его помощью файлы как по качеству, так и по размеру значительно превосходят стандарт МРЗ, что дает разработчикам право надеяться на то, что в будущем файлы с расширением OGG станут единственным средством хранения и распространения музыки через Интернет. Однако ни один современный портативный МРЗ-плеер не умеет воспроизводить файлы в этом формате — так же, как и большинство программных мультимедийных проигрывателей. TwinVQ — стандарт, разработанный фирмой Yamaha. Предназначался для кодирования звука с очень низким битрейтом и более высоким качеством, чем МРЗ. Не пользовался популярностью из-за больших требований к системным ресурсам как при воспроизведении музыки в этом формате, так и при кодировании файлов.
ФОРМАТ PDF
Часто документ Word «разваливается» на компьютере с другой версией операционной системы или MS Office, так что приходится приводить его в изначальный вид, восстанавливая потерянное форматирование. Но этого можно избежать.
Назначение формата PDF
Portable Document Format или просто PDF, был создан специально для ликвидации проблем с отображением информации в файлах. В чем же его преимущество? Во-первых, документ, сохраненный в формате PDF, будет одинаково выглядеть в любой операционной системе: в Windows XP, в Windows 95, и в Linux. Во-вторых, PDF использует качественные алгоритмы сжатия: если объем файла Word, содержащего пару картинок, вряд ли получится меньше мегабайта, то точно такой же PDF вполне уместится в 300-400 Кбайт. В-третьих, PDF умеет встраивать в себя все используемые в документе шрифты — будь то рукописные, готические или славянская вязь, так что можно забыть о тех случаях, когда какого-либо шрифта не оказывается на компьютере. В-четвертых, в формат PDF можно преобразовать любой электронный документ. А для прочтения и печати PDF понадобится бесплатная программа Acrobat Reader.
Создание PDF-файла
Сделать PDF просто. Первое, что необходимо, — программа Adobe Acrobat Professional, желательно последней версии 6.0. На практике все происходит очень просто, а во всех приложениях Microsoft Office и продуктах Adobe это можно сделать одним нажатием кнопки.
После инсталляции пакета Acrobat Professional в этих программах появится новая Панель инструментов, изначально она содержит три кнопки.
Открывают файл, который нужно преобразовать в PDF-формат, нажимают кнопку Convert to Adobe PDF на вышеуказанной Панели инструментов. В открывшемся окне указывают желаемое Имя создаваемого в формате PDF файла и Путь (месторасположение), где он будет находиться. Нажимают ОК, и через некоторое время новый файл будет готов и автоматически откроется для просмотра. Не сложнее этот процесс и во многих других программах. После установки Acrobat Professional в системе появляется новый виртуальный принтер под названием Adobe PDF —можно увидеть его ярлычк, открыв папку Принтеры через Панель управления. Он называется виртуальным, потому что реально не существует и используется именно для создания PDF-файлов. Поэтому печатают на нем тоже виртуально, но результат при этом будет вполне реальным. Открывают программу, из документа которой нужно получить PDF, и выбирают опцию Файл -> Печать. Далее открывают список доступных принтеров, выбирают Adobe PDF и нажмают ОК. После этого задают имя нового файла и его месторасположение, и через несколько секунд он будет готов.
Эффективное кодирование
При кодировании каждая буква исходного алфавита представляется различными последовательностями, состоящими из кодовых букв (цифр).
Если исходный алфавит содержит m букв, то для построения равномерного кода с использованием k кодовых букв необходимо удовлетворить соотношение m £ kq , где q - количество элементов в кодовой последовательности.
Поэтому

Для построения равномерного кода достаточно пронумеровать буквы исходного алфавита и записать их коды как q - разрядные числа в k-ичной системе счисления.
Например, при двоичном кодировании 32 букв русского алфавита используется q = log232 = 5 разрядов, на чем и основывается телетайпный код.
Кроме двоичных кодов, наибольшее распространение получили восьмеричные коды.
Пусть, например, необходимо закодировать алфавит, состоящий из 64 букв. Для этого потребуется q = log264 = 6 двоичных разрядов или q = log864 = 2 восьмеричных разрядов. При этом буква с номером 13 при двоичном кодировании получает код 001101, а при восьмеричном кодировании 15.
Обще признанным в настоящее время является позиционный принцип образования системы счисления. Значение каждого символа (цифры) зависит от его положения - позиции в ряду символов, представляющих число.
Единица каждого следующего разряда больше единицы предыдущего разряда в m раз, где m - основание системы счисления. Полное число получают, суммируя значения по разрядам:
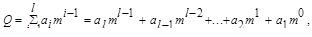
где i - номер разряда данного числа; l - количество рядов; аi - множитель, принимающий любые целочисленные значения в пределах от 0 до m-1 и показывающий, сколько единиц i - ого ряда содержится в числе.
Часто используются двоично-десятичные коды, в которых цифры десятичного номера буквы представляются двоичными кодами. Так, например, для рассматриваемого примера буква с номером 13 кодируется как 0001 0011. Ясно, что при различной вероятности появления букв исходного алфавита равномерный код является избыточным, т.к. его энтропия (полученная при условии, что все буквы его алфавита равновероятны): logkm = H0
всегда больше энтропии H = log m данного алфавита (полученной с учетом неравномерности появления различных букв алфавита, т.е. информационные возможности данного кода используются не полностью).
Например, для телетайпного кода Н0 = logk m = log232 = 5 бит, а с учетом неравномерности появления различных букв исходного алфавита Н » 4,35 бит. Устранение избыточности достигается применением неравномерных кодов, в которых буквы, имеющие наибольшую вероятность, кодируются наиболее короткими кодовыми последовательностями, а более длинные комбинации присваиваются редким буквам. Если i-я буква, вероятность которой Рi, получает кодовую комбинацию длины qi, то средняя длина комбинации
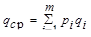
Считая кодовые буквы равномерными, определяем наибольшую энтропию закодированного алфавита как qср log m, которая не может быть меньше энтропии исходного алфавита Н, т.е. qср log m ³ Н.
Отсюда имеем
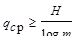
При двоичном кодировании (m=2) приходим к соотношению qср ³ Н, или
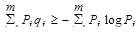
Чем ближе значение qср к энтропии Н, тем более эффективно кодирование. В идеальном случае, когда qср » Н, код называют эффективным.
Эффективное кодирование устраняет избыточность, приводит к сокращению длины сообщений, а значит, позволяет уменьшить время передачи или объем памяти, необходимой для их хранения.
При построении неравномерных кодов необходимо обеспечить возможность их однозначной расшифровки. В равномерных кодах такая проблема не возникает, т.к. при расшифровке достаточно кодовую последовательность разделить на группы, каждая из которых состоит из q элементов. В неравномерных кодах можно использовать разделительный символ между буквами алфавита (так поступают, например, при передаче сообщений с помощью азбуки Морзе).
Если же отказаться от разделительных символов, то следует запретить такие кодовые комбинации, начальные части которых уже использованы в качестве самостоятельной комбинации. Например, если 101 означает код какой-то буквы, то нельзя использовать комбинации 1, 10 или 10101.
Практические методы оптимального кодирования просты и основаны на очевидных соображениях ( метод Шеннона – Фано ).
Прежде всего, буквы (или любые сообщения, подлежащие кодированию) исходного алфавита записывают в порядке убывающей вероятности. Упорядоченное таким образом множество букв разбивают так, чтобы суммарные вероятности этих подмножеств были примерно равны. Всем знакам (буквам) верхней половины в качестве первого символа присваивают кодовый элемент 1, а всем нижним 0. Затем каждое подмножество снова разбивается на два подмножества с соблюдением того же условия равенства вероятностей и с тем же условием присваивания кодовых элементов в качестве второго символа. Такое разбиение продолжается до тех пор, пока в подмножестве не окажется только по одной букве кодируемого алфавита. При каждом разбиении буквам верхнего подмножества присваивается кодовый элемент 1, а буквам нижнего подмножества - 0.
Пример16: Провести эффективное кодирование ансамбля из восьми знаков:
Таблица 3.1.
| Буква (знак) xi | Вероят-ность Рi | Кодовые последовательности | Длина qi | рi qi | -рilog рi | ||||
|
|
| Номер разбиения |
|
| |||||
| 1 | 2 | 3 | 4 | ||||||
| x1 | 0,25 | 1 | 1 | 2 | 0,5 | 0,50 | |||
| x2 | 0,25 | 1 | 0 | 2 | 0,5 | 0,50 | |||
| x3 | 0,15 | 0 | 1 | 1 | 3 | 0,45 | 0,41 | ||
| x4 | 0,15 | 0 | 1 | 0 | 3 | 0,45 | 0,41 | ||
| x5 | 0,05 | 0 | 0 | 1 | 1 | 4 | 0,2 | 0,22 | |
| x6 | 0,05 | 0 | 0 | 1 | 0 | 4 | 0,2 | 0,22 | |
| x7 | 0,05 | 0 | 0 | 0 | 1 | 4 | 0,2 | 0,22 | |
| x8 | 0,05 | 0 | 0 | 0 | 0 | 4 | 0,2 | 0,22 | |
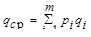 = 2,7
= 2,7
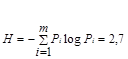
Как видно, qср = H, следовательно, полученный код является оптимальным.
Пример17: Построить код Шеннона - Фано, если известны вероятности: Р(x1) = 0,5; P(x2)= 0,25; P(x3) = 0,125; P(x4) = 0,125
Пример18: Провести эффективное кодирование ансамбля из восьми знаков (m=8), используя метод Шеннона - Фано.
Решение: При обычном (не учитывающем статистических характеристик) двоичном кодировании с использованием k=2 знаков при построении равномерного кода количество элементов в кодовой последовательности будет q ³ logk m = log2 8 = 3, т.е. для представления каждого знака использованного алфавита потребуется три двоичных символа.
Метод Шеннона - Фано позволяет построить кодовые комбинации, в которых знаки исходного ансамбля, имеющие наибольшую вероятность, кодируются наиболее короткими кодовыми последовательностями. Таким образом, устраняется избыточность обычного двоичного кодирования, информационные возможности которого используются не полностью.
Таблица 3.2.
| Знаки (буквы) xi | Вероятность Pi | Кодовые комбинации | |||||||
|
| номер разбиения | ||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | |||
| x1 | 1/2 | 1 | |||||||
| x2 | 1/4 | 0 | 1 | ||||||
| x3 | 1/8 | 0 | 0 | 1 | |||||
| x4 | 1/16 | 0 | 0 | 0 | 1 | ||||
| x5 | 1/32 | 0 | 0 | 0 | 0 | 1 | |||
| x6 | 1/64 | 0 | 0 | 0 | 0 | 0 | 1 | ||
| x7 | 1/128 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | |
| x8 | 1/128 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
Так как вероятности знаков представляют собой отрицательные целочисленные степени двойки, то избыточность при кодировании устранена полностью.
Среднее число символов на знак в этом случае точно равно энтропии. В общем случае для алфавита из восьми знаков среднее число символов на знак будет меньше трех, но больше энтропии алфавита. Вычислим энтропию алфавита:
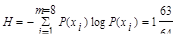
Вычислим среднее число символов на знак:
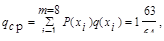
где q(xi) - число символов в кодовой комбинации, соответствующей знаку xi.
Пример19: Определить среднюю длину кодовой комбинации при эффективном кодировании по методу Шеннона - Фано ансамбля - из восьми знаков и энтропию алфавита.
Таблица 3.3.
| Знаки (буквы) xi | Вероятность Pi | Кодовые комбинации | ||||
| номер разбиения | ||||||
| 1 | 2 | 3 | 4 | 5 | ||
| x1 | 0,22 | 1 | 1 | |||
| x2 | 0,20 | 1 | 0 | 1 | ||
| x3 | 0,16 | 1 | 0 | 0 | ||
| x4 | 0,16 | 0 | 1 | |||
| x5 | 0,10 | 0 | 0 | 1 | ||
| x6 | 0,10 | 0 | 0 | 0 | 1 | |
| x7 | 0,04 | 0 | 0 | 0 | 0 | 1 |
| x8 | 0,02 | 0 | 0 | 0 | 0 | 0 |
Решение: 1. Средняя длина кодовых комбинаций
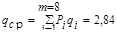
2. Энтропия алфавита
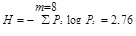
При кодировании по методу Шеннона - Фано некоторая избыточность в последовательностях символов, как правило, остается (qср > H).
Общие сведения
В процессе работы цифрового устройства возникают ошибки, искажающие информацию. Причинами таких ошибок могут быть:
◙ выход из строя какого-либо элемента, из-за чего устройство теряет работоспособность;
◙ воздействие различного рода помех, возникающих из-за проникновения сигналов из одних цепей в другие через различные паразитные связи.
Выход из строя элемента устройства рассматривается как неисправность. При этом в устройстве наблюдается постоянное искажение информации.
Иной характер искажений информации имеет место под воздействием помех. Вызвав ошибку, помехи могут затем в течение длительного времени не проявлять себя. Такие ошибки называют случайными сбоями.
В связи с возникновением ошибок необходимо снабжать цифровые устройства системой контроля правильности циркулирующей в ней информации. Такие системы контроля могут предназначаться для решения задач двух типов:
◙ задачи обнаружения ошибок;
◙ задачи исправления ошибок.
Система обнаружения ошибок, производя контроль информации, способна лишь выносить решения: нет ошибок и есть ошибка, причем в последнем случае она не указывает, какие разряды слов искажены.
Система исправления ошибок сигнализирует о наличии ошибок и указывает, какие из разрядов искажены. При этом непосредственное исправление цифр искаженных разрядов представляет собой уже несложную операцию. Если известно, что некоторый разряд двоичного слова ошибочен, то появление в нем ошибочного лог.0 означает, что правильное значение — лог. 1 и наоборот.
Трудно локализовать ошибку, т.е. указать, в каких разрядах слова она возникла. После решения этой задачи само исправление сводится лишь к инверсии цифр искаженных разрядов, поэтому обычно под исправлением ошибок понимают решение задачи локализации ошибок.
При постоянном нарушении правильности информации, обнаружив ошибку, можно принять меры для поиска неисправного элемента и заменить его исправным. Причины же случайных сбоев обычно выявляются чрезвычайно трудно, и такие изредка возникающие ошибки желательно было бы устранять автоматически, восстанавливая правильное значение слов с помощью системы исправления ошибок. Однако следует иметь в виду, что система исправления ошибок требует значительно большего количества оборудования, чем система обнаружения ошибок.
Ниже раздельно рассматриваются методы контроля:
◙ цифровых устройств хранения и передачи информации;
◙ цифровых устройств обработки информации.
К устройствам первого типа могут быть отнесены запоминающие устройства, регистры, цепи передачи и другие устройства, в которых информация не должна изменяться. На выходе этих устройств информация та же, что и на входе. К устройствам второго типа относятся устройства, у которых входная информация не совпадает с выходной и в тех случаях, когда ошибки не возникают. Примером могут служить арифметические и логические устройства.
Таблица 4.7.
| Номер разряда | Опознаватель | Номер разряда | Опознаватель | Номер разряда | Опознаватель |
| 1 | 00000001 | 6 | 00010000 | 11 | 01101010 |
| 2 | 00000010 | 7 | 00100000 | 12 | 10000000 |
| 3 | 00000100 | 8 | 00110011 | 13 | 10010110 |
| 4 | 00001000 | 9 | 01000000 | 14 | 10110101 |
| 5 | 00001111 | 10 | 01010101 | 15 | 11011011 |
Рассмотрим в качестве примера опознаватели для кодов, предназначенных исправлять единичные ошибки (табл. 4.8).
Таблица 4.8.
| Номер разрядов | Опознаватель | Номер разрядов | Опознаватель | Номер разрядов | Опознаватель |
| 1 | 0001 | 7 | 0111 | 12 | 1100 |
| 2 | 0010 | 8 | 1000 | 13 | 1101 |
| 3 | 0011 | 9 | 1001 | 14 | 1110 |
| 4 | 0100 | 10 | 1010 | 15 | 1111 |
| 5 | 0101 | 11 | 1011 | 16 | 10000 |
| 6 | 0110 |
В принципе можно построить код, усекая эту таблицу на любом уровне. Однако из таблицы видно, что оптимальными будут коды (7, 4), (15, 11), где первое число равно n, а второе k, и другие, которые среди кодов, имеющих одно и то же число проверочных символов, допускают наибольшее число информационных символов.
Усечем эту таблицу на седьмом разряде и найдем номера разрядов, символы которых должны войти в каждое из проверочных равенств.
Предположим, что в результате первой проверки на четность для младшего разряда опознавателя будет получена единица. Очевидно, это может быть следствием ошибки в одном из разрядов, опознаватели которых в младшем разряде имеют единицу. Следовательно, первое проверочное равенство должно включать символы 1, 3, 5 и 7-го разрядов: a1 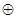 a3 a5 a7=0.
a3 a5 a7=0.
Единица во втором разряде опознавателя может быть следствием ошибки в разрядах, опознаватели которых имеют единицу во втором разряде. Отсюда второе проверочное равенство должно иметь вид a2 a3 a6 a7= 0 .
Аналогично находим и третье равенство: a4 a5 a6 a7= 0 .
Чтобы эти равенства при отсутствии ошибок удовлетворялись для любых значений информационных символов в кодовой комбинации, в нашем распоряжении имеется три проверочных разряда. Мы должны так выбрать номера этих разрядов, чтобы каждый из них входил только в одно из равенств. Это обеспечит однозначное определение значений символов в проверочных разрядах при кодировании. Указанному условию удовлетворяют разряды, опознаватели которых имеют по одной единице. В нашем случае это будут первый, второй и четвертый разряды.
Таким образом, для кода (7, 4), исправляющего одиночные ошибки, искомые правила построения кода, т. е. соотношения, реализуемые в процессе кодирования, принимают вид:
a1=a3 a5 a7,
a2=a3 a6 a7, (4.1)
a4=a5 a6 a7 .
Поскольку построенный код имеет минимальное хэммингово расстояние dmin = 3, он может использоваться с целью обнаружения единичных и двойных ошибок. Обращаясь к табл. 4.8, легко убедиться, что сумма любых двух опознавателей единичных ошибок дает ненулевой опознаватель, что и является признаком наличия ошибки.
Пример 27. Построим групповой код объемом 15 слов, способный исправлять единичные и обнаруживать двойные ошибки.
В соответствии с dи 0 min  r+s+1код должен обладать минимальным хэмминговым расстоянием, равным 4. Такой код можно построить в два этапа. Сначала строим код заданного объема, способный исправлять единичные ошибки. Это код Хэмминга (7, 4). Затем добавляем еще один проверочный разряд, который обеспечивает четность числа единиц в разрешенных комбинациях.
r+s+1код должен обладать минимальным хэмминговым расстоянием, равным 4. Такой код можно построить в два этапа. Сначала строим код заданного объема, способный исправлять единичные ошибки. Это код Хэмминга (7, 4). Затем добавляем еще один проверочный разряд, который обеспечивает четность числа единиц в разрешенных комбинациях.
Таким образом, получаем код (8, 4). В процессе кодирования реализуются соотношения:
a1=a3 a5 a7,
a2=a3 a6 a7,
a4=a5 a6 a7 .
a8=a1 a2 a3 a4 a5 a6 a7,
Обозначив синдром кода (7, 4) через S1, результат общей проверки на четность — через S2(S2 = 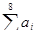 ) и пренебрегая возможностью возникновения ошибок кратности 3 и выше, запишем алгоритм декодирования:
) и пренебрегая возможностью возникновения ошибок кратности 3 и выше, запишем алгоритм декодирования:
при S1= 0 и S2= 0 ошибок нет;
при S1= 0 и S2= 1 ошибка в восьмом разряде;
при S1 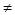 0 и S2= 0 двойная ошибка (коррекция блокируется, посылается запрос повторной передачи);
0 и S2= 0 двойная ошибка (коррекция блокируется, посылается запрос повторной передачи);
при S1 0 и S2= 1 одиночная ошибка (осуществляется ее исправление).
Пример 28. Используя табл. 4.8, составим правила построения кода (8,2), исправляющего все одиночные и двойные ошибки.
Усекая табл. 4.7 на восьмом разряде, найдем следующие проверочные равенства:
a1 a5 a8=0,
a2 a5 a8=0,
a3 a5=0,
a4 a5=0,
a6 a8=0,
a7 a8=0.
Соответственно правила построения кода выразим соотношениями
a1=a5 a8 (4.2 а)
a2=a5 a8 (4.2 б)
a3=a5 (4.2 в)
a4=a5 (4.2 г)
a6=a8 (4.2 д)
a7=a8 (4.2 е)
Отметим, что для построенного кода dmin = 5, и, следовательно, он может использоваться для обнаружения ошибок кратности от 1 до 4.
Соотношения, отражающие процессы кодирования и декодирования двоичных линейных кодов, могут быть реализованы непосредственно с использованием сумматоров по модулю два. Однако декодирующие устройства, построенные таким путем для кодов, предназначенных исправлять многократные ошибки, чрезвычайно громоздки. В этом случае более эффективны другие принципы декодирования.
4.8.3 Мажоритарное декодирование групповых кодов
Для линейных кодов, рассчитанных на исправление многократных ошибок, часто более простыми оказываются декодирующие устройства, построенные по мажоритарному принципу. Это метод декодирования называют также принципом голосования или способом декодирования по большинству проверок. В настоящее время известно значительное число кодов, допускающих мажоритарную схему декодирования, а также сформулированы некоторые подходы при конструировании таких кодов.
Мажоритарное декодирование тоже базируется на системе проверочных равенств. Система последовательно может быть разрешена относительно каждой из независимых переменных, причем в силу избыточности это можно сделать не единственным способом.
Любой символ аi выражается d (минимальное кодовое расстояние) различными независимыми способами в виде линейных комбинаций других символов. При этом может использоваться тривиальная проверка аi = аi. Результаты вычислений подаются на соответствующий этому символу мажоритарный элемент. Последний представляет собой схему, имеющую d входов и один выход, на котором появляется единица, когда возбуждается больше половины его входов, и нуль, когда возбуждается число таких входов меньше половины. Если ошибки отсутствуют, то проверочные равенства не нарушаются и на выходе мажоритарного элемента получаем истинное значение символа. Если число проверок d 2s+ 1 и появление ошибки кратности s и менее не приводит к нарушению более s проверок, то правильное решение может быть принято по большинству неискаженных проверок. Чтобы указанное условие выполнялось, любой другой символ aj(j i) не должен входить более чем в одно проверочное равенство. В этом случае мы имеем дело с системой разделенных проверок.
Пример 29. Построим систему разделенных проверок для декодирования информационных символов рассмотренного ранее группового кода (8,2).
Поскольку код рассчитан на исправление любых единичных и двойных ошибок, число проверочных равенств для определения каждого символа должно быть не менее 5. Подставив в равенства (4.2 а) и (4.2 б) значения а8, полученные из равенств (4.2 д) и (4.2 е) и записав их относительно a5 совместно с равенствами (4.2 в) и (4.2 г) и тривиальным равенством a5 = a5, получим следующую систему разделенных проверок для символа a5:
a5 = a6 a1,
a5 = a7 a2,
а5 = а3,
а5 = a4,
а5 = а5.
Для символа a8 систему разделенных проверок строим аналогично:
a8 = a3 a1,
a8 = a4 a2,
a8 = а6,
a8 = a7,
a8 = а8.
4.8.4 Матричное представление линейных кодов
Матрицей размерности l 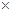 n называют упорядоченное множество l n элементов, расположенных в виде прямоугольной таблицы с l строками и n столбцами:
n называют упорядоченное множество l n элементов, расположенных в виде прямоугольной таблицы с l строками и n столбцами:
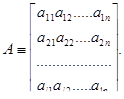
Транспонированной матрицей к матрице А называют матрицу, строками которой являются столбцы, а столбцами строки матрицы А:
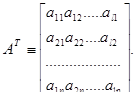
Матрицу размерности n n называют квадратной матрицей порядка n . Квадратную матрицу, у которой по одной из диагоналей расположены только единицы, а все остальные элементы равны нулю, называют единичной матрицей I. Суммой двух матриц А  |аij| и В |bij| размерности l n называют матрицу размерности l n:
|аij| и В |bij| размерности l n называют матрицу размерности l n:
А + В |аij| + |bij| |аij + bij|.
Умножение матрицы А |аij| размерности l n на скаляр с дает матрицу размерности l n: сА c |аij| |c аij|.
Матрицы А |аij| размерности l n и В |bjk| размерности n m могут быть перемножены, причем элементами c ik матрицы — произведения размерности l m являются суммы произведений элементов l-й строки матрицы А на соответствующие элементы k-го столбца матрицы В:
c ik = 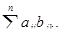
В теории кодирования элементами матрицы являются элементы некоторого поля GF(P), а строки и столбцы матрицы рассматриваются как векторы. Сложение и умножение элементов матриц осуществляется по правилам поля GF(P).
Пример 30. Вычислим произведение матриц с элементами из поля GF (2):
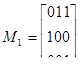
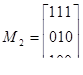
Элементы c ik матрицы произведения М = M1M2 будут равны:
c 11 = (011) (101) = 0 + 0 + 1 = 1
c 12 = (011) (110) = 0 + 1 + 0 = 1
c 13 = (011) (100) = 0 + 0 + 0 = 0
c 21 = (100) (101) = 1 + 0 + 0 = 1
c 22 = (100) (110) = 1 + 0 + 0 = 1
c 23 = (100) (100) = 1 + 0 + 0 = 1
c 31 = (001) (101) = 0 + 0 + 1 = 1
c 32 = (001) (110) = 0 + 0 + 0 = 0
c 33 = (001) (100) = 0 + 0 + 0 = 0
Следовательно, 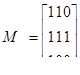
Зная закон построения кода, определим все множество разрешенных кодовых комбинаций. Расположив их друг под другом, получим матрицу, совокупность строк которой является подпространством векторного пространства n-разрядных кодовых комбинаций (векторов) из элементов поля GF(P). В случае двоичного (n, k)-кода матрица насчитывает n столбцов и 2k—1 строк (исключая нулевую). Например, для рассмотренного ранее кода (8,2), исправляющего все одиночные и двойные ошибки, матрица имеет вид

При больших n и k матрица, включающая все векторы кода, слишком громоздка. Однако совокупность векторов, составляющих линейное пространство разрешенных кодовых комбинаций, является линейно зависимей, так как часть векторов может быть представлена в виде линейной комбинации некоторой ограниченной совокупности векторов, называемой базисом пространства.
Совокупность векторов V1, V2, V3, ..., Vn называют линейно зависимой, когда существуют скаляры с1,..сn (не все равные нулю), при которых
c 1V1 + c 2V2+…+ cnVn= 0
В приведенной матрице, например, третья строка представляет собой суммы по модулю два первых двух строк. Для полного определения пространства разрешенных кодовых комбинаций линейного кода достаточно записать в виде матрицы только совокупность линейно независимых векторов. Их число называют размерностью векторного пространства.
Среди 2k – 1 ненулевых двоичных кодовых комбинаций — векторов их только k. Например, для кода (8,2)
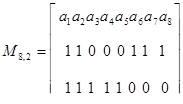
Матрицу, составленную из любой совокупности векторов линейного кода, образующей базис пространства, называют порождающей (образующей) матрицей кода.
Если порождающая матрица содержит k строк по n элементов поля GF(q), то код называют (n, k)-кодом. В каждой комбинации (n, k)-кода k информационных символов и n – k проверочных. Общее число разрешенных кодовых комбинаций (исключая нулевую) Q = qk-1.
Зная порождающую матрицу кода, легко найти разрешенную кодовую комбинацию, соответствующую любой последовательности Аki из k информационных символов.
Она получается в результате умножения вектора Аki на порождающую матрицу Мn,k:
Аni = Аki • Мn,k .
Найдем, например, разрешенную комбинацию кода (8,2), соответствующую информационным символам a5=l, a8 = 1:
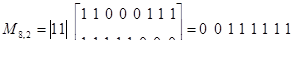 .
.
Пространство строк матрицы остается неизменным при выполнении следующих элементарных операций над строками: 1) перестановка любых двух строк; 2) умножение любой строки на ненулевой элемент поля; 3) сложение какой-либо строки с произведением другой строки на ненулевой элемент поля, а также при перестановке столбцов.
Если образующая матрица кода M2 получена из образующей матрицы кода M1 с помощью элементарных операций над строками, то обе матрицы порождают один и тот же код. Перестановка столбцов образующей матрицы кода приводит к образующей матрице эквивалентного кода. Эквивалентные коды весьма близки по своим свойствам. Корректирующая способность таких кодов одинакова.
Для анализа возможностей линейного (n, k)-кода, а также для упрощения процесса кодирования удобно, чтобы порождающая матрица (Мn,k) состояла из двух матриц: единичной матрицы размерности k k и дописываемой справа матрицы-дополнения (контрольной подматрицы) размерности k • (n – k), которая соответствует n – k проверочным разрядам:
 (4.3)
(4.3)
Разрешенные кодовые комбинации кода с такой порождающей матрицей отличаются тем, что первые k символов в них совпадают с исходными информационными, а проверочными оказываются (n - k) последних символов. Действительно, если умножим вектор-строку Ak,i = = (a1 a2…ai...ak) на матрицу Мn,k= [IkPk,n-k], получим вектор
An,i = (a1a2...ai...ak...ak+1...aj...an),
где проверочные символы аj(k +1 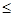 j n) являются линейными комбинациями информационных:
j n) являются линейными комбинациями информационных:
 (4.4)
(4.4)
Коды, удовлетворяющие этому условию, называют систематическими. Для каждого линейного кода существует эквивалентный систематический код. Как следует из (4.3), (4.4), информацию о способе построения такого кода содержит матрица-дополнение. Если правила построения кода (уравнения кодирования) известны, то значения символов любой строки матрицы-дополнения получим, применяя эти правила к символам соответствующей строки единичной матрицы.
Пример 31. Запишем матрицы Ik, Рk,n-k_и Mn,k для двоичного кода (7,4).
Единичная матрица на четыре разряда имеет вид

Один из вариантов матрицы дополнения можно записать, используя соотношения (4.1)
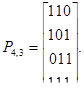
Тогда для двоичного кода Хэммннга имеем:


Запишем также матрицу для систематического кода (7,4):
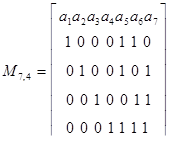
В свою очередь, по заданной матрице-дополнению Pk,n-k можно определить равенства, задающие правила построения кода. Единица в первой строке каждого столбца указывает на то, что в образовании соответствующего столбцу проверочного разряда участвовал первый информационный разряд. Единица в следующей строке любого столбца говорит об участии в образовании проверочного разряда второго информационного разряда и т, д.
Так как матрица-дополнение содержит всю информацию о правилах построения кода, то систематический код с заданными свойствами можно синтезировать путем построения соответствующей матрицы-дополнения.
Так как минимальное кодовое расстояние d для линейного кода равно минимальному весу его ненулевых векторов, то в матрицу-дополнение должны быть включены такие k строк, которые удовлетворяли бы следующему общему условию: вектор-строка образующей матрицы, получающаяся при суммировании любых l (1 l k) строк, должна содержать не менее d – l отличных от нуля символов.
Действительно, при выполнении указанного условия любая разрешенная кодовая комбинация, полученная суммированием l строк образующей матрицы, имеет не менее d ненулевых символов, так как l ненулевых символов она всегда содержит в результате суммирования строк единичной матрицы. Синтезируем таким путем образующую матрицу двоичного систематического кода (7,4) с минимальным кодовым расстоянием d = 3. В каждой вектор-строке матрицы-дополнения согласно сформулированному условию (при l=1) должно быть не менее двух единиц. Среди трехразрядных векторов таких имеется четыре: 011, 110, 101, 111.
Эти векторы могут быть сопоставлены со строками единичной матрицы в любом порядке. В результате получим матрицы систематических кодов, эквивалентных коду Хэмминга, например:
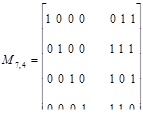
Нетрудно убедиться, что при суммировании нескольких строк такой матрицы (l>1) получим вектор-строку, содержащую не менее d=3 ненулевых символов.
Имея образующую матрицу систематического кода Мn,k= [IkPk,n-k], можно построить так называемую проверочную (контрольную) матрицу Н размерности (n – k) n:
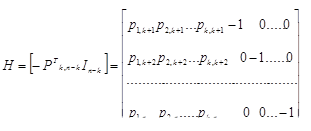
При умножении неискаженного кодового вектора Аni на матрицу, транспонированную к матрице Н, получим вектор, все компоненты которого равны нулю:
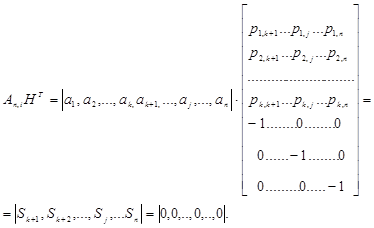
Каждая компонента Sj является результатом проверки справедливости соответствующего уравнения декодирования:
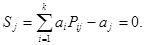
В общем случае, когда кодовый вектор Аni =(a1, a2,…, ai,…,ak,ak+1,…,aj,…,an) искажен вектором ошибки ξni =(ξ1, ξ2,…, ξi,…,ξk,aξk+1,…,ξj,…,ξn), умножение вектора (Аni + ξni) на матрицу Нт дает ненулевые компоненты:

Отсюда видно, что Sj(k +1 j n) представляют собой символы, зависящие только от вектора ошибки, а вектор S = (Sk + 1, Sk + 2, ...,, Sj, ..., Sn) является не чем иным, как опознавателем ошибки (синдромом).
Для двоичных кодов (операция сложения тождественна операции вычитания) проверочная матрица имеет вид
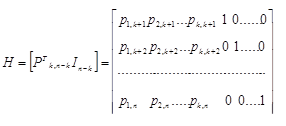
Пример 32. Найдем проверочную матрицу Н для кода (7,4) с образующей матрицей М:
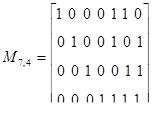
Определим синдромы в случаях отсутствия и наличия ошибки в кодовом векторе 1100011.
Выполним транспонирование матрицы P4,3
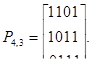
Запишем проверочную матрицу:
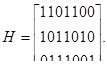
Умножение на Нт неискаженного кодового вектора 1100011 дает нулевой синдром:

При наличии в кодовом векторе ошибки, например, в 4-м разряде (1101011) получим:
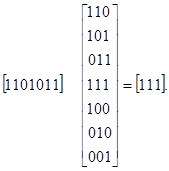
Следовательно, вектор-строка 111 в данном коде является опознавателем (синдромом) ошибки в четвертом разряде. Аналогично можно найти и синдромы других ошибок. Множество всех опознавателей идентично множеству опознавателей кода Хэмминга (7,4), но сопоставлены они конкретным векторам ошибок по-иному, в соответствии с образующей матрицей данного (эквивалентного) кода.
4.8.5 Технические средства кодирования и декодирования для групповых кодов
Кодирующее устройство строится на основании совокупности равенств, отражающих правила построения кода. Определение значений символов в каждом из n – k проверочных разрядов в кодирующем устройстве осуществляется посредством сумматоров по модулю два.
На каждый разряд сумматора (кроме первого) используется четыре элемента И (вентиля) и два элемента ИЛИ.
Сумматор по модулю два выпускают в виде отдельного логического элемента, который на схеме изображается прямоугольником с надписью внутри - М2. Приведем несколько примеров реализации кодирующих и декодирующих устройств групповых кодов.
Пример 33. Рассмотрим техническую реализацию кода (7,4), имеющего целью исправление одиночных ошибок.
Правила построения кода определяются равенствами
a1=a3 a5 a7,
a2=a3 a6 a7,
a4=a5 a6 a7.
Схема кодирующего устройства приведена на рис. 4.6.
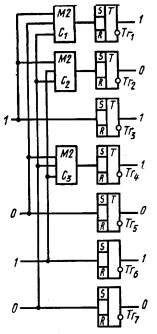
Рис. 4.6.
При поступлении импульса синхронизации со схемы управления подлежащая кодированию k-разрядная комбинация неизбыточного кода переписывается, например, с аналого-кодового преобразователя в информационные разряды n-разрядного регистра. Предположим, что в результате этой операции триггеры регистра установились в состояния, указанные в табл. 4.9.
С некоторой задержкой формируются выходные импульсы сумматоров С1, С2 С3, которые устанавливают триггеры проверочных разрядов в положение 0 или 1 в соответствии с приведенными выше равенствами. Например, в нашем случае ко входам сумматора C1 подводится информация, записанная в 3, 5 и 7-разрядах и, следовательно, триггер Тг1 первого проверочного разряда устанавливается в положение 1, аналогично триггер Тг2 устанавливается в положение 0, а триггер Тг4 — в положение 1.
Сформированная в регистре разрешенная комбинация (табл. 4.10) импульсом, поступающим с блока управления, последовательно или параллельно считывается в линию связи. Далее начинается кодирование следующей комбинации.
Рассмотрим теперь схему декодирования и коррекции ошибок (рис. 4.7), строящуюся на основе совокупности проверочных равенств. Для кода (7, 4) они имеют вид:
a1 a3 a5 a7= 0 ,
a2 a3 a6 a7= 0,
a4 a5 a6 a7= 0 .
Таблица 4.9.
| Тr1 | Тr2 | Tr3 | Тr4 | Тr5 | Tr6 | Тr7 |
| — | — | 1 | — | 0 | 1 | 0 |
Кодовая комбинация, возможно содержащая ошибку, поступает на n-разрядный приемный регистр (на рис. 4.7 триггеры Тг1 –Тг7). По окончании переходного процесса в триггерах с блока управления на каждый из сумматоров (C1 – С3) поступает импульс опроса.
Таблица 4.10.
| Тг1 | Тг2 | Тг3 | Тг4 | Тг5 | Tг6 | Тг7 |
| 1 | 0 | 1 | 1 | 0 | 1 | 0 |
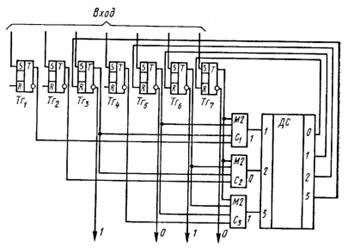
Рис. 4.7.
Выходные импульсы сумматоров устанавливают в положение 0 или 1 триггеры регистра опознавателей. Если проверочные равенства выполняются, все триггеры регистра опознавателей устанавливаются в положение 0, что соответствует отсутствию ошибок. При наличии ошибки в регистр опознавателей запишется опознаватель этого вектора ошибки. Дешифратор ошибки DC ставит в соответствие множеству опознавателей множество векторов ошибок. При опросе выходных вентилей дешифратора сигналы коррекции поступают только на те разряды, в которых вектор ошибки, соответствующий записанному на входе опознавателю, имеет единицы. Сигналы коррекции воздействуют на счетные входы триггеров. Последние изменяют свое состояние, и, таким образом, ошибка исправлена. На триггеры проверочных разрядов импульсы коррекции можно не посылать, если после коррекции информация списывается только с информационных разрядов. Для кода Хэмминга (7,4) любой опознаватель представляет собой двоичное трехразрядное число, равное номеру разряда приемного регистра, в котором записан ошибочный символ.
Предположим, что сформированная ранее в кодирующем устройстве комбинация при передаче исказилась и на приемном регистре была зафиксирована в виде, записанном в табл. 4.11.
Таблица 4.11.
| Тг1 | Тг2 | Тг3 | Тг4 | Тг5 | Тг6 | Tг7 |
| 1 | 0 | 1 | 1 | 1 | 1 | 0 |
По результатам опроса сумматоров получаем:
на выходе С1 a1 a3 a5 a7= 1+1+1+0=1,
на выходе С2 a2 a3 a6 a7= 0+1+1+0=0,
на выходе С3 a4 a5 a6 a7= 1+1+1+0=1 .

Рис. 4.8.
Следовательно, номер разряда, в котором произошло искажение, 101 или 5. Импульс коррекции поступит на счетный вход триггера Тг5, и ошибка будет исправлена.
Пример 34. Реализуем мажоритарное декодирование для группового кода (8,2), рассчитанного на исправление двойных ошибок.
В случае мажоритарного декодирования сигналы с триггеров приемного регистра поступают непосредственно или после сложения по модулю два в соответствии с уравнениями системы разделённых проверок на мажоритарные элементы М, формирующие скорректированные информационные символы.
Схема декодирования представлена на рис. 4.8. На входах мажоритарных элементов указаны сигналы, соответствующие случаю поступления из канала связи кодовой информации, искаженной в обоих информационных разрядах (5-м и 8-м). Реализуя принцип решения «по большинству», мажоритарные элементы восстанавливают на выходе правильные значения информационных символов.
Требования, предъявляемые к образующему многочлену
Согласно определению циклического кода все многочлены, соответствующие его кодовым комбинациям, должны делиться на g ( x ) без остатка. Для этого достаточно, чтобы на g ( x ) делились без остатка многочлены, составляющие образующую матрицу кода. Последние получаются циклическим сдвигом, что соответствует последовательному умножению g ( x ) на х с приведением по модулю xn + 1.
Следовательно, в общем случае многочлен gi ( x ) является остатком от деления произведения g ( x )·х i на многочлен xn + 1 и может быть записан так:
gi(x)=g(x)xi + c(xn + 1)
где с =1, если степень g ( x ) х i превышает п-1; с = 0, если степень g ( x ) х i не превышает п-1.
Отсюда следует, что все многочлены матрицы, а поэтому и все многочлены кода будут делиться на g ( x ) без остатка только в том случае, если на g ( x ) будет делиться без остатка многочлен xn + 1.
Таким образом, чтобы g ( x ) мог породить идеал, а, следовательно, и циклический код, он должен быть делителем многочлена xn + 1.
Поскольку для кольца справедливы все свойства группы, а для идеала - все свойства подгруппы, кольцо можно разложить на смежные классы, называемые в этом случае классами вычетов по идеалу.
Первую строку разложения образует идеал, причем нулевой элемент располагается крайним слева. В качестве образующего первого класса вычетов можно выбрать любой многочлен, не принадлежащий идеалу. Остальные элементы данного класса вычетов образуются путем суммирования образующего многочлена с каждым многочленом идеала.
Если многочлен g ( x ) степени m = n-k является делителем xn + 1, то любой элемент кольца либо делится на g ( x ) без остатка (тогда он является элементом идеала), либо в результате деления появляется остаток r (х), представляющий собой многочлен степени не выше m-1.
Элементы кольца, дающие в остатке один и тот же многочлен ri ( x ), относятся к одному классу вычетов. Приняв многочлены r (х) за образующие элементы классов вычетов, разложение кольца по идеалу с образующим многочленом g ( x ) степени m можно представить табл. 4.12, где f ( x )-произвольный многочлен степени не выше n-m-1.
Таблица 4.12.
| 0 | g(x) | x·g(x) | (x+1)·g(x) | … | f(x)·g(x) |
| r1(x) r2(x) … … rn(x) | g(x) + r1(x) g(x) + r2(x) … … g(x) + rn(x) | x·g(x) + r1(x) x·g(x) + r2(x) … … x·g(x) + rn(x) | (x+1)·g(x) + r1(x) (x+1)·g(x) + r2(x) … … (x+1)·g(x) + rn(x) | … … … … … | f(x)·g(x) + r1(x) f(x)·g(x) + r2(x) … … f(x)·g(x) + rn(x) |
Как отмечалось, групповой код способен исправить столько разновидностей ошибок, сколько различных классов насчитывается в приведенном разложении. Следовательно, корректирующая способность циклического кода будет тем выше, чем больше остатков может быть образовано при делении многочлена, соответствующего искаженной кодовой комбинации, на образующий многочлен кода.
Наибольшее число остатков, равное 2m - 1 (исключая нулевой), может обеспечить только неприводимый (простой) многочлен, который делится сам на себя и не делится ни на какой другой многочлен (кроме 1).
Кодирующие устройства
Все известные кодирующие устройства для любых типов циклических кодов, выполненные на регистрах сдвига, можно свести к двум типам схем согласно рассмотренным ранее методам кодирования.
Таблица 4.16.
| Номер такта | Вход | Состояние ячеек регистра | Номер такта | Вход | Состояние ячеек регистра | ||||
| 1 | 2 | 3 | 1 | 2 | 3 | ||||
| 1 2 3 4 5 6 7 | 1 0 0 1 0 0 0 | 1 0 0 0 1 1 1 | 0 1 0 0 0 1 1 | 0 0 1 1 1 1 0 | 8 9 10 11 12 13 14 | - - - - - - - | 0 1 0 0 1 1 1 | 1 0 1 0 0 1 1 | 1 0 0 1 1 1 0 |
Схемы первого типа вычисляют значения проверочных символов путем непосредственного деления многочлена а(х)хт на образующий многочлен g ( x ). Это делается с помощью регистра сдвига, содержащего n - k разрядов (рис. 4.13).
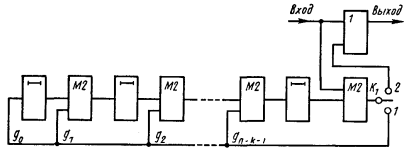
Рис. 4.13.
Схема отличается от ранее рассмотренной тем, что коэффициенты кодируемого многочлена участвуют в обратной связи не через n - k сдвигов, а сразу с первого такта. Это позволяет устранить разрыв между информационными и проверочными символами.
В исходном состоянии ключ К1 находится в положении 1. Информационные символы одновременно поступают как в линию связи, так и в регистр сдвига, где за k тактов образуется остаток. Затем ключ K 1 переходит в положение 2 и остаток поступает в линию связи.
Пример 38. Рассмотрим процесс деления многочлена а(х)хт = (х3 + 1)x3 на многочлен g(x) = x3 + х2+ 1 за k тактов.
Схема кодирующего устройства для заданного g(x) приведена на рис. 4.14. Процесс формирования кодовой комбинации шаг за шагом представлен в табл. 4.17, где черточками отмечены освобождающиеся ячейки, занимаемые новыми информационными символами.
С помощью схем второго типа вычисляют значения проверочных символов как линейную комбинацию информационных символов, т. е. они построены на использовании основного свойства систематических кодов. Кодирующее устройство строится на основе k-разрядного регистра сдвига (рис. 4.15).
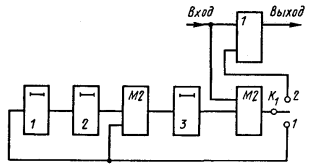
Рис. 4.14.
Таблица 4.17.
| Номер такта | Вход | Состояние ячеек регистра | Выход | ||
| 1 | 2 | 3 | |||
| 1 2 3 4 5 6 7 | 1 0 0 1 0 0 0 | 1 1 1 1 - - - | 0 1 1 1 1 - - | 1 1 0 0 1 1 - | 1 01 001 1001 01001 101001 1101001 |
Выходы ячеек памяти подключаются к сумматору в цепи обратной связи в соответствии с видом генераторного многочлена
h ( x ) = ( xn + 1)/ g ( x ) = h 0 + h 1 x + … + hkxk
В исходном положении ключ К1 находится в положении 1. За первые k тактов поступающие на вход информационные символы заполняют все ячейки регистра. После этого ключ переводят в положение 2. На каждом из последующих тактов один из информационных символов выдается в канал связи и одновременно формируется проверочный символ, который записывается в последнюю ячейку регистра. Через n - k тактов процесс формирования проверочных символов заканчивается и ключ K1 снова переводится в положение 1.
В течение последующих k тактов содержимое регистра выдается в канал связи с одновременным заполнением ячеек новой последовательности информационных символов.
Пример 39. Рассмотрим процесс формирования кодовой комбинации с использованием генераторного многочлена для случая g(x) = x3 + x2 + 1 и а(x) = x3 + 1.
Определяем генераторный многочлен:
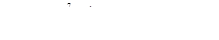
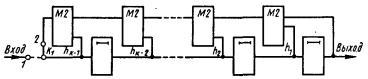
Рис. 4.15.
Рис. 4.16.
Соответствующая h ( x ) схема кодирующего устройства приведена на рис. 4.16. Формирование кодовой комбинации поясняется табл. 4.18. Оно начинается после заполнения регистра информационными символами.
Декодирующие устройства
Декодирование комбинаций циклического кода можно проводить различными методами. Существуют методы, основанные на использовании рекуррентных соотношений, на мажоритарном принципе, на вычислении остатка от деления принятой комбинации на образующий многочлен кода и др. Целесообразность применения каждого из них зависит от конкретных характеристик используемого кода.
Рассмотрим сначала устройства декодирования, в которых для обнаружения и исправления ошибок производится деление произвольного многочлена f ( x ), соответствующего принятой комбинации, на образующий многочлен кода g 0 ( x ). В этом случае при декодировании могут использоваться те же регистры сдвига, что и при кодировании.
Таблица 4.18.
| Номер такта | Состояние ячеек регистра | Выход | |||
| 1 | 2 | 3 | 4 | ||
| 1 2 3 4 5 6 7 | 1 0 1 1 - - - | 0 1 0 1 1 - - - | 0 0 1 0 1 1 - - | 1 0 0 1 0 1 1 - | 1 01 001 1001 01001 101001 1101001 |
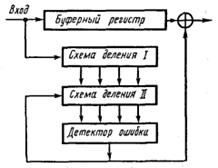
Рис. 4.17.
Декодирующие устройства для кодов, обнаруживающих ошибки, по существу ничем не отличаются от схем кодирующих устройств. В них добавляется лишь буферный регистр для хранения принятого сообщения на время проведения операции деления. Если остатка не обнаружено (случай отсутствия ошибки), то информация с буферного регистра считывается в дешифратор сообщения. Если остаток обнаружен (случай наличия ошибки), то информация в буферном регистре уничтожается и на передающую сторону посылается импульс запроса повторной передачи.
В случае исправления ошибок схема несколько усложняется. Информацию о разрядах, в которых произошла ошибка, несет, как и ранее, остаток. Схема декодирующего устройства представлена на рис. 4.17.
Символы подлежащей декодированию кодовой комбинации, возможно, содержащей ошибку, последовательно, начиная со старшего разряда, вводятся в n-разрядный буферный регистр сдвига и одновременно в схему деления, где за n тактов определяется остаток, который в случае непрерывной передачи сразу же переписывается в регистр второй аналогичной схемы деления.
Начиная с (n + 1)-го такта в буферный регистр и первую схему деления начинают поступать символы следующей кодовой комбинации. Одновременно на каждом такте буферный регистр покидает один символ, а в регистре второй схемы деления появляется новый остаток (синдром). Детектор ошибок, контролирующий состояния ячеек этого регистра, представляет собой комбинаторно-логическую схему, построенную с таким расчетом, чтобы она отмечала все те синдромы («выделенные синдромы»), которые появляются в схеме деления, когда каждый из ошибочных символов занимает крайнюю правую ячейку в буферном регистре. При последующем сдвиге детектор формирует сигнал «1», который, воздействуя на сумматор коррекции, исправляет искаженный символ.
Одновременно по цепи обратной связи с выхода детектора подается сигнал «1» на входной сумматор регистра второй схемы деления. Этот сигнал изменяет выделенный синдром так, чтобы он снова соответствовал более простому типу ошибки, которую еще подлежит исправить. Продолжая сдвиги, обнаружим и другие выделенные синдромы. После исправления последней ошибки все ячейки декодирующего регистра должны оказаться в нулевом состоянии. Если в результате автономных сдвигов состояние регистра не окажется нулевым, это означает, что произошла неисправимая ошибка.
Для декодирования кодовых комбинаций, разнесенных во времени, достаточно одной схемы деления, осуществляющей декодирование за 2n тактов.
Сложность детектора ошибок зависит от числа выделенных синдромом. Простейшие детекторы получаются при реализации кодов, рассчитанных на исправление единичных ошибок.
Выделенный синдром появляется в схеме деления раньше всего в случае, когда ошибка имеет место в старшем разряде кодовой комбинации, так как он первым достигает крайней правой ячейки буферного регистра. Поскольку неискаженная кодовая комбинация делится на g 0 ( x ) без остатка, то для определения выделенного синдрома достаточно разделить на g 0 ( x ) вектор ошибки с единицей в старшем разряде. Остаток, получающийся на n -м такте, и является искомым выделенным синдромом.
В зависимости от номера искаженного разряда после первых тактов будем получать различные остатки (опознаватели соответствующих векторов ошибок). Вследствие этого выделенный синдром будет появляться в регистре схемы деления через различное число последующих тактов, обеспечивая исправление искаженного символа.
В качестве схем деления в декодирующем устройстве могут быть использованы как схемы, определяющие остаток за n тактов (см. рис. 4.11), так и схемы, определяющие остаток за k тактов (рис. 4.13). При использовании схемы деления за k тактов векторам одиночных ошибок ξ (х) будут соответствовать другие остатки на n-м такте, являющиеся результатом деления на образующий многочлен кода векторов ξ(х)хт, а на ξ(x). Поэтому выделенные синдромы, а следовательно, и детекторы ошибок для указанных схем будут различны.
Пример 40. Рассмотрим процесс исправления единичной ошибки при использовании кода (7,4) с образующим многочленом g(x) = х3 + х2 + 1 и применении в декодирующем устройстве схем деления за n и k тактов.
Определим опознаватели ошибок и выделенный синдром для случая использования схемы деления за n тактов:
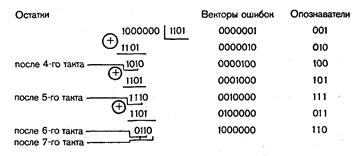
Детектор ошибки, обеспечивающий формирование на выходе сигнала только в случае появления в схеме деления остатка 110, можно реализовать посредством двух логических элементов НЕ и одного логического элемента ИЛИ-НЕ.
На рис. 4.18 приведена схема соответствующего декодирующего устройства. В табл. 4.19 представлен процесс исправления ошибки для случая, когда кодовая комбинация 1001011 (см. табл. 4.18) поступила на вход декодирующего устройства с искаженным символом в 4-м разряде (1000011).
После n (в данном случае 7) тактов в схему деления II переписывается опознаватель ошибки 101.
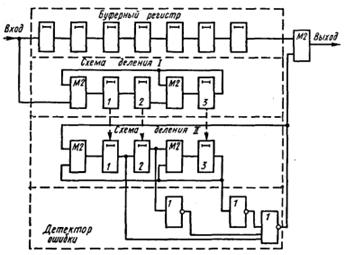
Рис. 4.18.
Таблица 4.19.
| Номер такта | Вход | Состояние ячеек схем деления | Выход после коррекции | ||
| 1 | 2 | 3 | |||
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 | 1 0 0 0 0 1 1 0 0 0 0 0 0 0 | 1 0 0 1 1 0 1 1 1 0 0 0 0 0 | 0 1 0 0 1 1 0 1 1 1 0 0 0 0 | 0 0 1 1 1 0 1 1 0 1 0 0 0 0 | Переписывается в схему деления II 1 01 001 1001 01001 101001 1101001 |
На каждом последующем такте на выходе буферного регистра появляется неискаженный символ корректируемой кодовой комбинации, а в схеме деления II новый остаток. Выделенный синдром появится в схеме деления на 10-м такте, когда искаженный символ займет крайнюю правую ячейку регистра. На следующем такте он попадет в корректирующий сумматор и будет там исправлен импульсом, поступающим с выхода детектора ошибки. Этот же импульс по цепи обратной связи приводит ячейки схемы деления II в нулевое состояние (корректирует выделенный синдром). При использовании схемы деления за k тактов соответствие между векторами ошибок и остатками на n-м такте иное.
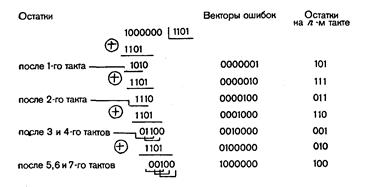
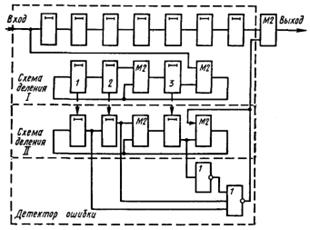
Рис. 4.19.
Таблица 4.20.
| Номер такта | Вход | Состояние ячеек схем деления | Выход после коррекции | ||
| 1 | 2 | 3 | |||
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 | 1 0 0 0 0 1 1 0 0 0 0 0 0 0 | 1 1 1 0 1 1 0 1 0 0 0 0 0 0 | 0 1 1 1 0 1 1 0 1 0 0 0 0 0 | 1 1 0 1 0 1 1 0 0 1 0 0 0 | Переписывается в схему деления II 1 01 001 1001 01001 101001 1101001 |
Детектор для выделенного синдрома 100 можно построить из одного логического элемента НЕ и одного элемента ИЛИ-НЕ.
На рис. 4.19 представлена схема декодирующего устройства для этого случая. Табл. 4.20 позволяет проследить по тактам процесс исправления ошибки в кодовой комбинации 1000011 (искажен символ в 4-м разряде).
Сравнение показывает, что использование в декодирующем устройстве схемы деления за k тактов предпочтительнее, так как выделенный синдром в этом случае при любом объеме кода содержит единицу в старшем и нули во всех остальных разрядах, что приводит к более простому детектору ошибки.
Пример 41. Рассмотрим более сложный случай исправления одиночных и двойных смежных ошибок. Для этой цели может использоваться циклический код (7,3) с образующим многочленом g(x) = (х + 1)(x3 + x2+1).
Ориентируясь на схему деления за k тактов, найдем выделенный синдром для двойных смежных ошибок:
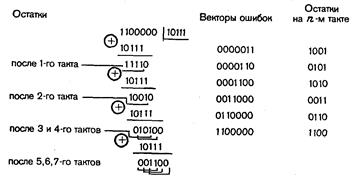
Для одиночных ошибок соответственно получим
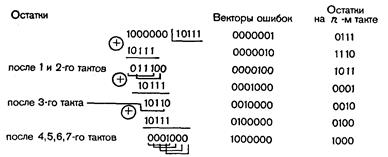
Детектор ошибок в этом случае должен формировать сигнал коррекции при появлении каждого выделенного синдрома. Схема декодирующего устройства представлена на рис. 4.20.
Процесс исправления кодовой комбинации 1000010 с искаженными символами в 4-м и 5-м разрядах поясняется табл. 4.21.
На 9-м такте в схеме деления II появляется первый выделенный синдром 1100. На следующем такте на выходе аналогично обозначенного элемента ИЛИ-НЕ детектора ошибок формируется импульс коррекции, который исправляет 5-й разряд кодовой комбинации и одновременно по цепи обратной связи изменяет остаток в схеме деления II, приводя его в соответствие выделенному синдрому еще не исправленной одиночной ошибки в 4-м разряде (1000). На 11-м такте импульс коррекции формирует элемент ИЛИ-НЕ детектора ошибок, соответствующий указанному выделенному синдрому. Этим импульсом обеспечивается исправление 4-го разряда кодовой комбинации и получение нулевого остатка в схеме деления II.

Рис. 4.20.
Таблица 4.21.
| Номер такта | Вход | Состояние ячеек схем деления | Выход после коррекции | |||
| 1 | 2 | 3 | 4 | |||
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 | 1 0 0 0 1 0 0 0 0 0 0 0 0 0 | 1 0 1 1 1 0 1 0 0 0 0 0 0 0 | 1 1 1 0 0 1 1 1 0 0 0 0 0 0 | 1 1 0 0 1 0 0 1 1 0 0 0 0 0 | 0 1 1 0 0 1 0 0 1 1 0 0 0 0 | Переписывается в схему деления II 1 01 101 1101 11101 011101 0011101 |
Список литературы
2. Дмитриев В.И. Прикладная теория информации. Учебник для студентов ВУЗов по специальности «Автоматизированные системы обработки информации и управления». – М.: Высшая школа, 1989 – 320 с.
Лекции по Теории информации
Подготовил В.С. Прохоров
Содержание
Введение
1. Понятие информации. Задачи и постулаты прикладной теории информации
1.1 Что такое информация
1.2 Этапы обращения информации
1.3 Информационные системы
1.4 Система передачи информации
1.5 Задачи и постулаты прикладной теории информации
2. Количественная оценка информации
2.1 Свойства энтропии
2.2 Энтропия при непрерывном сообщении
2.3 Условная энтропия
2.4 Взаимная энтропия
2.5 Избыточность сообщений
3. Эффективное кодирование
4. Кодирование информации для канала с помехами
4.1 Разновидности помехоустойчивых кодов
4.2 Общие принципы использования избыточности
4.3 Связь информационной способности кода с кодовым расстоянием
4.4 Понятие качества корректирующего кода
4.5 Линейные коды
4.6 Математическое введение к линейным кодам
4.7 Линейные коды как пространство линейного векторного пространства
4.8 Построение двоичного группового кода
4.8.1. Составление таблицы опознавателей
4.8.2. Определение проверочных равенств
4.8.3. Мажоритарное декодирование групповых кодов
4.8.4. Матричное представление линейных кодов
4.8.5. Технические средства кодирования и декодирования для групповых кодов
4.9 Построение циклических кодов
4.9.1. Общие понятия и определения
4.9.2. Математическое введение к циклическим кодам
4.9.3. Требования, предъявляемые к многочлену
4.10 Выбор образующего многочлена по заданному объему кода и заданной корректирующей способности
4.10.1. Обнаружение одиночных ошибок
4.10.2. Исправление одиночных или обнаружение двойных ошибок
4.10.3. Обнаружение ошибок кратности три и ниже
4.10.4. Обнаружение и исправление независимых ошибок произвольной кратности
4.10.5. Обнаружение и исправление пачек ошибок
4.10.6. Методы образования циклического кода
4.10.7. Матричная запись циклического кода
4.10.8. Укороченные циклические коды
4.11. Технические средства кодирования и декодирования для циклических кодов
4.11.1. Линейные переключательные схемы
4.11.2. Кодирующие устройства
4.11.3. Декодирующие устройства
Список литературы
Содержание
Введение
Теория информации является одним из курсов при подготовке инженеров, специализирующихся в области автоматизированных систем управления и обработки информации. Функционирование таких систем существенным образом связано с получением, подготовкой, передачей, хранением и обработкой информации, поскольку без осуществления этих этапов невозможно принять правильное решение и осуществить требуемое управляющее воздействие, которое является конечной целью функционирования любой системы.
Возникновение теории информации связывают обычно с появлением фундаментальной работы американского ученого К. Шеннона «Математическая теория связи» (1948). Однако в теорию информации органически вошли и результаты, полученные другими учеными. Например, Р. Хартли, впервые предложил количественную меру информации (1928), акад. В. А. Котельников, сформулировал важнейшую теорему о возможности представления непрерывной функции совокупностью ее значений в отдельных точках отсчета (1933) и разработал оптимальные методы приема сигналов на фоне помех (1946). Акад. А. Н. Колмогоров, внес огромный вклад в статистическую теорию колебаний, являющуюся математической основой теории информации (1941). В последующие годы теория информации получила дальнейшее развитие в трудах советских ученых (А. Н. Колмогорова, А. Я. Хинчина, В. И. Сифорова, Р. Л. Добрушина, М. С. Пинскера, А. Н. Железнова, Л. М. Финка и др.), а также ряда зарубежных ученых (В. Макмиллана, А. Файнстейна, Д. Габора, Р. М. Фано, Ф. М. Вудворта, С. Гольдмана, Л. Бриллюэна и др.).
К теории информации, в ее узкой классической постановке, относят результаты решения ряда фундаментальных теоретических вопросов. Это в первую очередь: анализ вопросов оценки «количества информации»; анализ информационных характеристик источников сообщений и каналов связи и обоснование принципиальной возможности кодирования и декодирования сообщений, обеспечивающих предельно допустимую скорость передачи сообщений по каналу связи, как при отсутствии, так и при наличии помех.
Если рассматривают проблемы разработки конкретных методов и средств кодирования сообщений, то совокупность излагаемых вопросов называют теорией информации и кодирования или прикладной теорией информации.
Попытки широкого использования идей теории информации в различных областях науки связаны с тем, что в основе своей эта теория математическая. Основные ее понятия (энтропия, количество информации, пропускная способность) определяются только через вероятности событий, которым может быть приписано самое различное физическое содержание. Подход к исследованиям в других областях науки с позиций использования основных идей теории информации получил название теоретико-информационного подхода. Его применение в ряде случаев позволило получить новые теоретические результаты и ценные практические рекомендации. Однако не редко такой подход приводит к созданию моделей процессов, далеко не адекватных реальной действительности. Поэтому в любых исследованиях, выходящих за рамки чисто технических проблем передачи и хранения сообщений, теорией информации следует пользоваться с большой осторожностью. Особенно это касается моделирования умственной деятельности человека, процессов восприятия и обработки им информации.
Содержание конспекта лекций ограничивается рассмотрениемвопросов теории и практики кодирования.
Понятие информации. Задачи и постулаты прикладной теории информации
Что такое информация
С начала 1950-х годов предпринимаются попытки использовать понятие информации (не имеющее до настоящего времени единого определения) для объяснения и описания самых разнообразных явлений и процессов.
В некоторых учебниках дается следующее определение информации:
Информация - это совокупность сведений, подлежащих хранению, передаче, обработке и использованию в человеческой деятельности.
Такое определение не является полностью бесполезным, т.к. оно помогает хотя бы смутно представить, о чем идет речь. Но с точки зрения логики оно бессмысленно. Определяемое понятие (информация) здесь подменяется другим понятием (совокупность сведений), которое само нуждается в определении.
При всех различиях в трактовке понятия информации, бесспорно, то, что проявляется информация всегда в материально-энергетической форме в виде сигналов.
Информацию, представленную в формализованном виде, позволяющем осуществлять ее обработку с помощью технических средств, называют данными.
Этапы обращения информации
Можно выделить следующие этапы обращения информации:
1) восприятие информации;
2) подготовка информации;
3) передача и хранение информации;
4) обработка информации;
5) отображение информации;
6)воздействие информации.
Рис.1.1 Этапы обращения информации
На этапе восприятия информации осуществляется целенаправленное извлечение и анализ информации о каком-либо объекте (процессе), в результате чего формируется образ объекта, проводится его опознание и оценка. При этом отделяют интересующую информацию от шумов.
На этапе подготовки информации получают сигнал в форме, удобной для передачи или обработки (нормализация, аналого-цифровое преобразование и т.д.).
На этапе передачи и хранения информация пересылается либо из одного места в другое, либо от одного момента времени до другого.
На этапе обработки информации выделяются ее общие и существенные взаимозависимости для выбора управляющих воздействий (принятия решений).
На этапе отображения информации она представляется человеку в форме, способной воздействовать на его органы чувств.
На этапе воздействия информация используется для осуществления необходимых изменений в системе.
Информационные системы
В основе решения многих задач лежит обработка информации. Для облегчения обработки информации создаются информационные системы (ИС). Автоматизированными называют ИС, в которых применяют технические средства, в частности ЭВМ. Большинство существующих ИС являются автоматизированными, поэтому для краткости просто будем называть их ИС. В широком понимании под определение ИС подпадает любая система обработки информации. По области применения ИС можно разделить на системы, используемые в производстве, образовании, здравоохранении, науке, военном деле, социальной сфере, торговле и других отраслях. По целевой функции ИС можно условно разделить на следующие основные категории: управляющие, информационно-справочные, поддержки принятия решений. Заметим, что иногда используется более узкая трактовка понятия ИС как совокупности аппаратно-программных средств, задействованных для решения некоторой прикладной задачи. В организации, например, могут существовать информационные системы, на которые возложены следующие задачи: учет кадров и материально-технических средств, расчет с поставщиками и заказчиками, бухгалтерский учет и т. п. Эффективность функционирования информационной системы (ИС) во многом зависит от ее архитектуры. В настоящее время перспективной является архитектура клиент-сервер. В распространенном варианте она предполагает наличие компьютерной сети и распределенной базы данных, включающей корпоративную базу данных (КБД) и персональные базы данных (ПБД). КБД размещается на компьютере-сервере, ПБД размещаются на компьютерах сотрудников подразделений, являющихся клиентами корпоративной БД. Сервером определенного ресурса в компьютерной сети называется компьютер (программа), управляющий этим ресурсом. Клиентом — компьютер (программа), использующий этот ресурс. В качестве ресурса компьютерной сети могут выступать, к примеру, базы данных, файловые системы, службы печати, почтовые службы. Тип сервера определяется видом ресурса, которым он управляет. Например, если управляемым ресурсом является база данных, то соответствующий сервер называется сервером базы данных. Достоинством организации информационной системы по архитектуре клиент-сервер является удачное сочетание централизованного хранения, обслуживания и коллективного доступа к общей корпоративной информации с индивидуальной работой пользователей над персональной информацией. Архитектура клиент-сервер допускает различные варианты реализации.
Система передачи информации
Информация поступает в систему в форме сообщений. Под сообщением понимают совокупность знаков или первичных сигналов, содержащих информацию.
Источник сообщений в общем случае образует совокупность источника информации (ИИ) (исследуемого или наблюдаемого объекта) и первичного преобразователя (ПП) (датчика, человека-оператора и т.д.), воспринимающего информацию о протекающем в нем процессе.
Рис. 1.2. Структурная схема одноканальной системы передачи информации.
Различают дискретные и непрерывные сообщения.
Дискретные сообщения формируются в результате последовательной выдачи источником сообщений отдельных элементов - знаков.
Множество различных знаков называют алфавитом источника сообщения, а число знаков - объемом алфавита.
Непрерывные сообщения не разделены на элементы. Они описываются непрерывными функциями времени, принимающими непрерывное множество значений (речь, телевизионное изображение).
Для передачи сообщения по каналу связи ему ставят в соответствие определенный сигнал. Под сигналом понимают физический процесс, отображающий (несущий) сообщение.
Преобразование сообщения в сигнал, удобный для передачи по данному каналу связи, называют кодированием в широком смысле слова.
Операцию восстановления сообщения по принятому сигналу называют декодированием.
Как правило, прибегают к операции представления исходных знаков в другом алфавите с меньшим числом знаков, называемых символами. При обозначении этой операции используется тот же термин “кодирование”, рассматриваемый в узком смысле. Устройство, выполняющее такую операцию, называют кодирующим или кодером. Так как алфавит символов меньше алфавита знаков, то каждому знаку соответствует некоторая последовательность символов, которую называют кодовой комбинацией.
Число символов в кодовой комбинации называют ее значностью, число ненулевых символов - весом.
Для операции сопоставления символов со знаками исходного алфавита используют термин “декодирование”. Техническая реализация этой операции осуществляется декодирующим устройством или декодером.
Передающее устройство осуществляет преобразование непрерывных сообщений или знаков в сигналы, удобные для прохождения по линии связи. При этом один или несколько параметров выбранного сигнала изменяют в соответствии с передаваемой информацией. Такой процесс называют модуляцией. Он осуществляется модулятором. Обратное преобразование сигналов в символы производится демодулятором
Под линией связи понимают среду (воздух, металл, магнитную ленту и т.д.), обеспечивающую поступление сигналов от передающего устройства к приемному устройству.
Сигналы на выходе линии связи могут отличаться от сигналов на ее входе (переданных) вследствие затухания, искажения и воздействия помех.
Помехами называют любые мешающие возмущения, как внешние, так и внутренние, вызывающие отклонение приинятых сигналов от переданных сигналов.
Из смеси сигнала с помехой приемное устройство выделяет сигнал и посредством декодера восстанавливает сообщение, которое в общем случае может отличаться от посланного. Меру соответствия принятого сообщения посланному сообщению называют верностью передачи.
Принятое сообщение с выхода системы связи поступает к абоненту-получателю, которому была адресована исходная информация.
Совокупность средств, предназначенных для передачи сообщений, называют каналом связи.
Дата: 2019-07-30, просмотров: 418.