Указатель – тип данных, хранящих адрес в памяти других данных. В зависимости от типизации указатель может быть нетипизированным (содержать просто адрес в памяти) и типизированным (указывать только на элемент определенного типа).
Стек – хранилише данных однородного типа с дисциплиной “последним пришел-первым вышел” (LIFO).
| ß | SP | |
|
| ||
|
| ||
|
| ||
|
| ||
Над стеком определены операции PUSH, POP (затолкнуть, извлечь).
При операции PUSH указатель стека SP увеличится на 1, при извлечении уменьшится на 1.
Природа стека делает необходимым соответствие операций PUSH и POP. Если его нет, то возможно 2 ситуации:
а) переполнение – SP вышел за пределы верхнего значения
б) антипереполнение –“- нижнего.
Очередь – структура данных с дисциплиной FIFO – “первым вошел, первым вышел”.
| ßtp | ||
|
| ||
|
| ||
| ßhp | ||
Здесь HP – указатель на последнее значение, tp – номер последнего выбранного элемента. Если HP=TP – очередь пуста.
ENQ x - добавляем в очередь
HP=HP+1
A[HP]=x
DEQ x - извлекаем из очереди
TP=TP+1
x = A[TP]
Особые ситуации - так же как и со стеком.
Для реализации динамических структур данных используют т.н. кучу (heap). Это объем памяти, в котором можно выделить участок для произвольного элемента данных. Для кучи есть 2 операции: выделения памяти ALLOCATE и освобождения FREE. Эти функции не делают никаких действий с собственно памятью. При выделении программист получает адрес, а при освобождении доступный объем кучи становится больше. Одного адреса для этих операций недостаточно, требуется еще и размер элемента данных.
Списки – сложные динамические структуры данных, представляющие собой структуры, содержащие указатели на другие подобные структуры. Если такой указатель в структуре 1 – односвязный список, если 2 – двусвязный, если много – многосвязный. Стек и очередь можно легко представить в виде одно- и двусвязного списка. Списки характеризуются тем, что для них легко реализуется любая дисциплина ввода-вывода за счет простого добавления и удаления элемента.
Для добавления элемента достаточно выделить под него память и присвоить адрес памяти нового элемента соответствующему предыдущему элементу. Для удаления элемента память из-под него освобождается, а указателям на него присваивается некоторое зарезервированное значение NULL – “указатель на ничто”.
   data;
struct s *next; data;
struct s *next;
| data; struct s *next; | data; struct s *next; | NULL |
Односвязный список
    data;
struct s *prev;
struct s *next; data;
struct s *prev;
struct s *next;
| data; struct s *prev; struct s *next; | data; struct s *prev; struct s *next; | NULL |
Двусвязный список
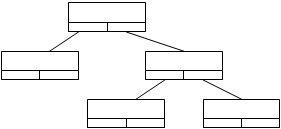
Дерево – структура данных, в которой каждому элементу может соответствовать несколько подчиненных элементов, например, для бинарного дерева – два подчиненных элемента. Структура для представления такого дерева – данные и указатели на левого и правого потомков. На таком списке реализуются все операции по обходу деревьев.
 | |||||||
 | |||||||
 |  | ||||||
NULL NULL
 |  |  |  |
NULL NULL NULL NULL
Структура двоичного дерева. Каждый элемент содержит поле данных и два указателя - на левого и правого потомков.
Способы выделения памяти в программах: абсолютное, статическое, динамическое и автоматическое распределения. Механизм стека и кучи при реализации процессоров языка программирования.
Статическое выделение памяти – выделение памяти под данные внутри сегмента данных программы. Такие данные существуют на протяжении всей жизни программы до ее завершения.
Автоматическое распределение – выделение памяти под данные в стеке. Такие данные существуют на протяжении работы текущей подпрограммы (функции или процедуры), затем уничтожаются.
Динамическое выделение – выделение памяти под данные самой программой, когда это необходимо. Время жизни таких данных зависит от программы.
В стеке размещаются данные для возврата из подпрограмм, а также их аргументы и автоматические данные. Все это может потребовать достаточно большого размера стека. Как правило, программист может определять размер стека в программе.
Куча. Для реализации динамических структур данных используют т.н. кучу (heap). Это объем памяти, в котором можно выделить участок для произвольного элемента данных. Для кучи есть 2 операции: выделения памяти ALLOCATE и освобождения FREE. Эти функции не делают никаких действий с собственно памятью. При выделении программист получает адрес, а при освобождении доступный объем кучи становится больше. Одного адреса для этих операций недостаточно, требуется еще и размер элемента данных. Если указатель типизированный, размер будет получен автматически. В случае нетипизированного указателя размер должен быть передан в функцию.
Для реализации кучи ЯВУ снабжаются диспетчерами памяти, которые выделяют и освобождают память, имеют сведения о ее фрагментации, знают наибольший кусок свободной памяти и ее общее количество и т.п. При ненадобности память должна своевременно освобождаться. При использовании динамической памяти возможноа ситуация образования «мусора» – кусков памяти, на которые утеряны ссылки, но которые не были своевремменно освобождены, поэтому менеджер считает их занятыми. Для оптимизации известна процедура “уборка мусора” – перестройка динамических структур с освобождением памяти из-под тех данных, на которые отсутствуют ссылки.
Дата: 2019-05-29, просмотров: 292.