Первым способом решения проблемы совместного использования информации был централизованный принцип обработки данных с применением многопользовательского режима (70-е года 20 века). В ту эпоху ЭВМ отличались значительной дороговизной и большими габаритами, поэтому экономически обоснованным было приобретение пользователями одной мощной универсальной ЭВМ, на которой решались практически все классы задач. Для обеспечения доступа к ЭВМ как можно большего числа пользователей к ней подключалось несколько терминалов, обычно территориально расположенных в одном большом зале, или в пределах одного здания.
Преимуществом подобной системы является простота внешних устройств, а также концентрация данных и ресурсов общего пользования в одном месте (что, кстати, облегчало обслуживание ЭВМ).
Основными недостатками централизованной обработки данных были:
- низкая надежность – даже кратковременный выход из строя центральной ЭВМ приводил к роковым последствиям для системы в целом;
- низкая производительность – при диалоговой обработке данных в многопользовательском режиме ЭВМ не успевала обслуживать всех пользователей в нужном темпе;
- ограниченная возможность решения разнотипных прикладных задач, т.к. это требовало слишком высокой многофункциональности и универсальности ЭВМ и ОС;
- концентрация большой вычислительной мощности ЭВМ делала компьютеры слишком дорогими и недоступными для одиночных пользователей и небольших предприятий.
С появлением малых ЭВМ, микро-ЭВМ и, наконец, персональных компьютеров возникло логически обоснованное требование перехода к иным информационным технологиям – от использования крупных центральных ЭВМ к распределенной обработке данных. Распределенная обработка данных – обработка данных, выполняемая на независимых, но связанных между собой компьютерах, представляющих собой распределенную систему (т.е. не сосредоточенную в каком-то малом пространстве). Таким образом, имеет место централизация хранения данных и децентрализация вычислительных мощностей по их обработке. В этом заключается важнейшее отличие данных систем от классических многотерминальных систем.
Существуют различные способы объединения нескольких компьютеров в единую систему, отвечающую требованию распределенной обработки. Высшей формой такого объединения является компьютерная сеть.
Под сетью ПЭВМ (или компьютерной сетью) понимают коммуникационную систему, состоящую из двух или более компьютеров и включающую в себя специальные программы и аппаратное обеспечение, используемое для обмена информацией между компьютерами и совместного использования ресурсов. Таким образом, компьютерная сеть представляет собой совокупность трех компонент:
· сети передачи данных (включающей в себя каналы передачи данных и средства коммутации);
· компьютеров, взаимосвязанных сетью передачи данных;
· сетевого программного обеспечения.
Ресурсы сети – это данные, приложения и периферийные устройства, такие, как диск, принтер, модем и т. д. В такой системе любое из подключенных устройств может использовать сеть для передачи или получения информации.
Основными отличиями компьютерной сети от прочих многомашинных вычислительных комплексов являются:
- размерность – сеть может состоять из десятков и даже сотен ЭВМ, расположенных друг от друга на расстоянии от нескольких метров до тысяч километров;
- разделение функций между ЭВМ – в сети одни машины могут выполнять функции обработки или передачи данных, другие – управление системой, третьи – обслуживанием периферийных устройств и т.д.;
- необходимость решения в сети задачи маршрутизации – т.е. определение оптимального маршрута передачи сообщений от одного компьютера другому; состояние каналов связи в крупной сети постоянно изменяется и в каждый момент времени может возникнуть необходимость искать новый маршрут.
Отметим преимущества, получаемые после объединения отдельных ПК в сеть:
- возрастает оперативность работы;
- появляется возможность организовать доступ всех пользователей к единому информационному ресурсу (например, базе данных), расположенному на одном компьютере;
- снижаются затраты на аппаратное обеспечение в расчете на одного пользователя; это достигается за счет совместного использования дискового пространства, дорогих высококачественных внешних устройств (лазерных принтеров, сканеров, плоттеров).
- повышается надежность системы в целом, поскольку при поломке одного устройства исполнение его функций может взять на себя другое.
С появлением компьютерных сетей возникла необходимость формирования новой специальной терминологии. Перечислим основные понятия, использующиеся в сетевых технологиях.
Абоненты сети – объекты, генерирующие или потребляющие информацию в сети. Абонентами сети могут быть отдельные ЭВМ и их комплексы, терминалы, промышленные роботы, станки с числовым управлением и т.д.
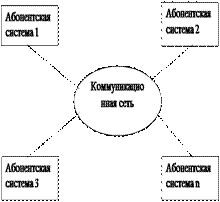
Обобщенная структура компьютерной сети
Любой абонент сети подключается к станции. Станция – аппаратура, которая выполняет функции передачи или приема информации. Совокупность абонента и станции, к которой он подключен, называют абонентской системой. Для организации взаимодействия абонентов необходима физическая передающая среда – линия связи или пространство, в котором распространяются сигналы, и аппаратура передачи данных. На базе физической передающей среды строится коммуникационная сеть, которая обеспечивает передачу информации между абонентами сети. Такой подход позволяет рассматривать любую компьютерную сеть как совокупность абонентских систем и коммуникационной сети (см. рисунок).
Компьютерные сети обладают многими новыми возможностями, недоступными для вычислительных систем на базе одной ЭВМ. Например:
- организация параллельного решения крупной задачи за счет одновременной обработки различных фрагментов данных на разных ЭВМ;
- создание распределенной базы данных, объединяющей информационные ресурсы многих ЭВМ;
- специализация отдельных ЭВМ для эффективного решения определенных классов задач;
- резервирование вычислительных мощностей и средств передачи данных на случай выхода из строя отдельных ЭВМ и устройств;
- перераспределение вычислительных мощностей между пользователями при изменении их потребностей;
- стабилизация уровня загрузки ЭВМ и дорогостоящего периферийного оборудования.
Многомашинные объединения
Кластер представляет собой систему из нескольких компьютеров (в большинстве случаев серийно выпускаемых), имеющих общий разделяемый ресурс для хранения совместно обрабатываемых данных (обычно набор дисков или дисковых массивов) и объединенных высокоскоростной магистралью (рис. 13.3).
В кластерной системе некоторое распределенное приложение параллельно на нескольких узлах обрабатывает общий набор данных, как правило, таким образом, чтобы у пользователя возникла иллюзия работы на одной машине.
Обычно в кластерных системах не обеспечивается единая операционная среда для работы общего набора приложений на всех узлах кластера. То есть каждый компьютер кластера - это автономная система с отдельным экземпляром ОС и своими, принадлежащими только ей системными ресурсами: набором заведенных пользователей, системными буферами, областью свопинга и т. п. Приложение, запущенное на нем, может видеть только общие диски или отдельные участки памяти. На узлах кластера работают специально написанные для такой конфигурации приложения, параллельно обрабатывающие общий набор данных. На каждой из машин они представлены рядом процессов, программ, взаимодействующих с помощью кластерного программного обеспечения. Таким образом, кластерное ПО - это лишь средство для взаимодействия узлов и синхронизации доступа к общим данным. Кластер как параллельная система формируется на прикладном уровне, а не на уровне операционной системы.
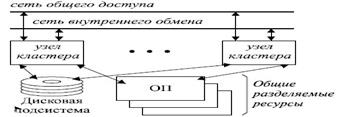
Рис. 13.3. Структура кластера
В настоящее время такие системы имеют две основные области применения: параллельные серверы баз данных и высоконадежные вычислительные комплексы. Рынок параллельных СУБД и есть фактически рынок кластеров приложений. Высоконадежные комплексы представляют собой группу узлов, на которых независимо друг от друга выполняются некоторые важные приложения, требующие постоянной, непрерывной работы. То есть в такой системе на аппаратном уровне фактически поддерживается основной механизм повышения надежности - резервирование. Причем узлы находятся в так называемом "горячем" резерве, и каждый из них в любой момент готов продолжить вычисления при выходе из строя какого-либо узла. При этом все приложения с отказавшего узла автоматически переносятся на другие машины комплекса. Такая система также формально является кластером, хотя в ней отсутствует параллельная обработка общих данных. Эти данные обычно монопольно используются выполняемыми в рамках кластера приложениями и должны быть доступны для всех узлов.
Если в кластере его узлы разделяют некоторые ресурсы, то параллельные системы другого класса - системы вычислений с массовым параллелизмом (MPP) - строятся из отдельных полностью независимых компьютеров, соединенных только высокоскоростной магистральюили коммуникационными каналами (рис. 13.4). Это могут быть либо просто несколько серийно выпускаемых UNIX-машин, соединенных с помощью высокопроизводительной сетевой среды, либо специально сконструированная система из отдельных функциональных блоков, объединенных коммутатором.
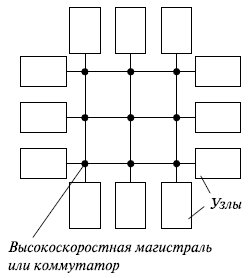
Рис. 13.4. Структура MPP-системы
В такой системе адресное пространство состоит из отдельных адресных пространств, которые логически не связаны между собой и доступ к которым не может быть осуществлен аппаратно другим процессором.
При этом для обмена данными используется механизм передачи сообщений между процессорами. Поэтому эти машины часто называют машинами с передачей сообщений. Пользователь может определить логический номер процессора, к которому он подключен, и организовать обмен сообщениями с другими процессорами.
На машинах MPP-архитектуры используются два варианта работы операционной системы. В одном из них полноценная операционная системаработает только на управляющей машине (front-end); на каждом отдельном модуле функционирует сильно урезанный вариант ОС, обеспечивающий работу только расположенной в нем ветви параллельного приложения. Во втором варианте на каждом модуле работает полноценная, как правило, UNIX-подобная ОС, устанавливаемая отдельно.
Программирование в такой системе - достаточно сложная задача.
Она требует специального инструментария и особого системного программного обеспечения для работы параллельных приложений, которые ориентированы на функционирование параллельных процессов, распределенных по узлам MPP-системы, с обменом сообщениями между ними.
Повышение производительности машин с массовым параллелизмом путем увеличения в них числа процессоров имеет определенные ограничения. Чем большее число процессоров входит в состав MPP-системы, тем длиннее каналы передачи управления и данных, а значит, и тем меньше тактовая частота. Происшедшее возрастание нормы массивности для больших машин до 512 и даже 64К процессоров обусловлено не ростом размеров машины, а увеличением степени интеграции схем, позволившей за последние годы резко повысить плотность размещения элементов в устройствах. Топология сети межпроцессорного обмена в такого рода системах может быть различной.
Главным преимуществом MPP-систем является их хорошая масштабируемость: в отличие от SMP-систем, здесь каждый процессор имеет доступтолько к своей локальной памяти, в связи с чем не возникает необходимости в потактовой синхронизации процессоров. Практически все рекорды по производительности на сегодня устанавливаются на машинах именно такой архитектуры, состоящих из нескольких тысяч процессоров.
Основными недостатками систем данного типа являются следующие:
отсутствие общей памяти заметно снижает скорость межпроцессорного обмена, поскольку нет общей среды для хранения данных, предназначенных для обмена между процессорами;
требуется специальная техника программирования для реализации обмена сообщениями между процессорами;
каждый процессор может использовать только ограниченный объем локального банка памяти;
вследствие указанных архитектурных недостатков требуются значительные усилия для того, чтобы максимально задействовать системные ресурсы, следствием чего является высокая цена программного обеспечения для MPP-систем с раздельной памятью.
Подведем некоторые итоги, касающиеся областей применимости систем параллельной обработки данных различных типов.
SMP-системы потенциально обладают достаточными возможностями для обеспечения необходимой для большинства применений производительности: вполне естественно увеличивать число процессоров, а не ставить рядом еще один компьютер. Добавление одного процессора гарантированно увеличивает производительность, а добавление, например, узла в кластер адекватного ускорения не даст. Более того, в некоторых случаях общая производительность системы может даже упасть, когда узлы кластера начинают активно конкурировать за доступ к общим ресурсам, и взаимные блокировки сводят на нет преимущества параллельной обработки.
NUMA-системы создаются для вполне определенных целей - обеспечения масштабных расчетов. Системы, использующие эту архитектуру, прежде всего применяются для уникальных высококачественных и высокопроизводительных прикладных программ, требующих более восьми процессоров. Однако они имеют высокую стоимость и требуют уникального ПО (прикладные программы и ОС).
Для современных систем помимо вполне традиционных требований по производительности, масштабируемости, цене дополнительные высокие требования предъявляются к надежности их работы. Именно по этим соображениям вычислительные комплексы на основе кластеров или MPP-машин завоевывают все большую популярность.
MPP-системы обладают рядом преимуществ, главным из которых является лучшая среди всех рассмотренных архитектур масштабируемость. Именно поэтому MPP-компьютеры обычно используются при больших ресурсоемких вычислениях. Конечно, они применяются и при построении больших баз данных, и в отказоустойчивых вычислительных комплексах. Но здесь их использование довольно ограничено. Это отчасти связано с тем, что они все-таки дороже кластеров и имеют достаточно большую начальную цену. Кластер же можно построить из относительно дешевых машин произвольной конфигурации.
Приведенная классификация систем параллельной обработки данных достаточно условна. Разработчики вычислительных систем не проектируют машину какого-то специального класса, а стараются создать более производительную архитектуру. Кроме этого, сам пользовательможет с использованием стандартных компонентов спроектировать комплекс, архитектурно и функционально наиболее подходящий для решения конкретной задачи.
Транспьютеры
Для построения многопроцессорных систем могут быть использованы специально разработанные процессоры, называемые транспьютерами. Они были созданы в середине 1980-х годов фирмой INMOS Ltd (ныне - подразделение STMicroelecTRoniCS).
Транспьютер - это микропроцессор со встроенными средствами межпроцессорной коммуникации, предназначенной для построения многопроцессорных систем. Его название происходит от слов TRansfer (передатчик) и computer (вычислитель).
Транспьютер включает в себя средства для выполнения вычислений (ЦП, АЛУ с плавающей точкой, внутрикристальную память) и 4 канала для связи (линка) с другими транспьютерами и/или другими устройствами. Каждый линк представляет собой 2 однонаправленных последовательных канала передачи информации. Встроенный интерфейс позволяет подключать внешнюю память емкостью до 4 Гбайт (рис. 13.5).
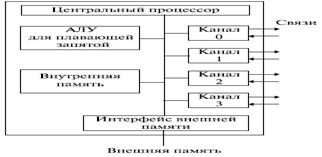
Рис. 13.5. Структура транспьютера
Многопроцессорная система может создаваться из набора транспьютеров, которые функционируют независимо и взаимодействуют через последовательные каналы связи (рис. 13.6).
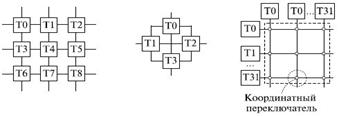
Рис. 13.6. Структуры многопроцессорных систем на базе транспьютеров
Организация транспьютеров и многопроцессорных систем на их основе базируется на языке Occam, специально разработанном в начале 1980-х годов группой ученых из Оксфорда под руководством Дэвида Мэя по заданию компании INMOS в рамках работ по созданию транспьютеров. Отметим основные характеристики этого языка с точки зрения его применения для программирования транспьютерных систем:
выполнение задачи разбивается на процессы, которые могут выполняться параллельно;
размещение процессов не привязано к конкретному оборудованию: необязательно каждому процессу должен ставиться в соответствие свой транспьютер - несколько процессов могут выполняться на одном транспьютере;
язык позволяет описать размещение процессов по оборудованию;
язык позволяет описать, как эти процессы обмениваются между собой данными (какой процесс принимает информацию, от какого процесса и в каком объеме).
При передаче данных в линк процесс должен исполнить команду вывода. Процесс, исполнивший такую команду, задерживается до тех пор, пока все данные не будут переданы. Аналогично, при приеме данных из линка процесс должен исполнить команду ввода. При исполнении такой команды процесс блокируется до тех пор, пока буфер не будет заполнен данными. Взаимодействие с внешним устройством через линкпозволяет транспьютеру синхронизовать свою деятельность с этими устройствами без использования механизма прерываний.
Использование такого подхода позволило организовать виртуальные каналы связи между процессами, которые могли размещаться как на единственном транспьютере, так и на нескольких транспьютерах, и виртуальные линки между процессами. Любой транспьютер может одновременно образовывать любое число параллельных процессов. Он имеет специальный планировщик, который производит распределение процессорного времени между этими процессами. Тем самым появляется возможность, имея всего лишь один транспьютер, написать параллельную программу, которая полностью выполняется на нем. Задача разбивается на ряд процессов, и все эти процессы параллельно протекают внутри одного транспьютера, периодически останавливаясь для получения данных друг от друга. Систему можно расширить другими транспьютерами и перенести на них ряд процессов. При этом нужно просто переопределить таблицу связей процессов, указав, на каком транспьютере теперь выполняется тот или иной процесс. Сама же программа изменений не претерпевает, а вычислительная мощность системы, естественно, увеличивается.
Помимо интересных возможностей, связанных с построением мультипроцессорных систем без привлечения дополнительного оборудования, в транспьютерах были реализованы идеи, направленные на повышение их вычислительной мощности. Среди них хотелось бы отметить то, что блок регистров транспьютера организован в виде стека. Это привело к использованию преимущественно безадресной системы команд, что обеспечило даже более высокую производительность, чем RISC-архитектура. Второй момент, который следует выделить, - это одновременное исполнение группы, в которую входило до 8 команд, что обеспечивало полную загрузку устройств процессора. И все это было реализовано в конце 1980-х годов, задолго до появления EPIC и Itanium.
На момент своего появления транспьютеры были самыми быстродействующими 32-разрядными микропроцессорами. В процессе своего недолго развития их характеристики достигли следующих значений:
производительность: 200 MIPS, 25 MFLOPS (на 64-разрядном процессоре с плавающей точкой);
емкость внутрикристальной памяти: 16 Кбайт;
скорость обмена по линку: 100 Мбит/с.
В середине 1990-х, в эпоху расцвета микропроцессоров этого семейства, фирма INMOS помимо собственно транспьютеров поставляла широкий набор трэмов (TRem - TRansputer Extension Module) - устройств ввода-вывода с линком в качестве интерфейса. В частности, поставлялись трэмы, позволявшие подключить к транспьютеру через линк адаптеры Ethernet или SCSI. В целях увеличения числа физических связей был разработан программируемый коммутатор, осуществляющий передачу сообщения с любого из 32 входов на любой из 32 выходов.
Транспьютеры успешно использовались в различных областях от встроенных систем до суперЭВМ. Однако технология транспьютеров серьезного развития не получила, так как начиная с Pentium Pro в универсальные микропроцессоры введена возможность соединения процессоров в микропроцессорную систему, что обесценило главное преимущество транспьютеров - возможность построения многопроцессорных систем без дополнительных аппаратных затрат. В настоящее время транспьютеры не производятся, они вытеснены похожими разработками конкурентов, особенно Texas INsTRuments (TMS320) и Intel (80860).
Краткие итоги. В лекции представлена классификация Флинна систем многопроцессорной обработки данных, основанная на понятии потока, а также классификация многопроцессорных и многомашинных вычислительных систем на основе степени разделения вычислительных ресурсов системы. Рассмотрены структура и особенности работы SMP-, NUMA-, MPP-систем, а также кластеров. Описан специальный классмикропроцессоров - транспьютеры, созданный для построения мультипроцессорных систем.
Дата: 2019-05-28, просмотров: 584.