Содержание
1. Введение............................................................................................................................................ 3
1.1 Причины появления объектно-ориентированных баз данных.................................................. 3
1.2 Подходы в разработке ООБД.......................................................................................................... 4
1.3 Краткий сравнительный анализ постреляционных и традиционных баз данных................. 5
1.4 Основания дипломной работы...................................................................................................... 5
1.5 Анализ полученного результата................................................................................................... 7
2. Уточнение методов решения задачи.............................................................................. 8
2.1 Наследование................................................................................................................................... 8
2.2 Инкапсуляция................................................................................................................................ 10
2.3 Идентификатор объекта................................................................................................................ 11
2.4 Идентификатор поля агрегата..................................................................................................... 13
2.5 Триггеры. Ограничение доступа.................................................................................................. 13
2.6 Действие (knowhow)...................................................................................................................... 14
2.7 Объекты-поведения....................................................................................................................... 14
2.8 Принципы взаимодействия объектов......................................................................................... 14
2.9 Транзакции и механизм согласованного управления............................................................ 17
3. Разработка структуры СУ...................................................................................................... 18
3.1 Положение дел в области интероперабельности систем.......................................................... 18
3.2 Менеджер памяти........................................................................................................................... 20
3.3 Виртуальная память и каналы.................................................................................................... 20
3.4 Система управления кэшированием объектов......................................................................... 21
3.5 Система управления журнализацией и восстановлением...................................................... 23
3.6 Принципы реализации механизма согласованного управления.......................................... 24
4. Представление данных в ООБД.......................................................................................... 28
4.1 Базовые объекты системы............................................................................................................ 28
4.2 Строение объекта........................................................................................................................... 28
4.3 Контекст транзакции..................................................................................................................... 30
5. Описание операций над объектами в БД................................................................... 31
6. Требования к техническим и программным средствам.................................. 33
7. Реализация прототипа.......................................................................................................... 34
7.1 Построитель.................................................................................................................................... 34
7.2 Заголовочный модуль для каналов............................................................................................ 34
7.3 Менеджер виртуальной памяти................................................................................................... 35
7.4 Система управления хранением объектов................................................................................. 38
7.5 Система управления каналами................................................................................................... 39
7.6 Работа с базовыми объектами..................................................................................................... 40
7.7 Выполнение действий................................................................................................................... 42
7.8 Кэширование объектов................................................................................................................. 42
8. Контрольный пример, демонстрирующий возможности технологии.. 44
9. Оценка трудоемкости разработки ПО с использованием традиционного и предлагаемого подходов........................................................................................................ 45
9.1 Табличные базы данных с низкоуровневыми операциями доступа...................................... 45
9.2 Реляционные базы данных........................................................................................................... 45
9.3 Объектно-ориентированные базы данных................................................................................. 46
9.4 Будущее применения различных баз данных............................................................................ 46
10. Литература................................................................................................................................... 47
Введение
Причины появления
объектно-ориентированных баз данных
Развитие вычислительной техники и увеличение объемов хранимой информации привело к необходимости выделения технологии баз данных в отдельную науку. Как правило, базы данных хранили множество однотипных данных, предоставляя пользователю сервис доступа к нужной ему информации. На смену иерархическим и сетевым базам данных пришли реляционные базы данных. Успех реляционных баз данных обусловлен их более простой архитектурой, наличием ненавигационного языка запросов и, главное, ясностью математики реляционной алгебры.
На этапе зарождения технологии баз данных при построении какой-либо базы данных строилась физическая модель. С накоплением опыта стало понятно, что нужен переход к даталогической модели, которая позволяет абстрагироваться от конкретной СУБД. Появилось понятие схемы базы данных, описывающей организацию данных в СУБД. Программы стали работать с базой данных не напрямую, а через схему БД. Такой подход обеспечил возможность менять структуру БД без необходимости изменять логику программ. Появление и стандартизация SQL предоставила единый интерфейс для работы с данными. Иерархическая и сетевая модели баз данных стали применяться крайне редко. Это было вызвано, прежде всего, трудностью модификации схем иерархических и сетевых баз данных и сильно зависящей от приложений навигацией в этих базах данных.

Далее, развитие объектно-ориентированного анализа и объектно-ориентированного проектирования как эффективных подходов для формализации предметной области, привело к появлению инфологической модели предметной области. Теперь, при разработке базы данных составлялось три модели представления информации предметной области: инфологическая, даталогическая и физическая, не считая локальных пользовательских представлений.
Рис 1: Этапы проектирования БД
Поскольку физическая модель требовала привлечения эксперта в области конкретной СУБД для получения эффективного размещения данных, физическая модель стала строиться самой СУБД из схемы БД, вводимой пользователем на основе даталогической модели предметной области. Затем появились CASE-средства, позволяющие создавать инфологическую модель предметной области и транслирующие ее в даталогическую модель.
Казалось бы, что цель достигнута, – проектировщик работает только с инфологической моделью, но на самом деле, до тех пор, пока работа происходит с реляционной базой данных, существует разрыв между языком программирования (логикой пользователя) и языком описания данных (представлением данных), который преодолевать должен программист. Суть разрыва можно сформулировать так: возможности работы с данными программы и с данными СУБД должны быть одинаковы.
В конце 80-х – начале 90-х годов массовое внедрение персональных компьютеров привело к развитию мультимедиа-технологий и настольных САПР, структуры данных в которых слишком сложны для процедурного программирования или же необычны (например, звук). Это, а также то, что объектно-ориентированное программирование позволяет существенно снизить сложность разработки и обеспечить адекватное представлению моделирование предметной области, привело к тому, что в области языков программирования произошло слияние стилей языков высокого уровня. Доминирующим подходом стало внедрение в них технологий объектно-ориентированного программирования. Не остались в стороне и языки, встроенные в СУБД. В качестве примера вышеизложенного можно привести продукт Visual FoxPro фирмы Microsoft. Эта СУБД обладает объектно-ориентированным языком программирования, но, по сути, является реляционной СУБД, поскольку хранимые данные представлены в виде таблиц, а таблицы представляют собой множество кортежей, которые содержат атомарные значения. Такое несоответствие и привело к буму в области разработки постреляционных баз данных.
Сложившаяся ситуация хотя чем-то и напоминает время перехода к реляционным базам данных, однако во многом и отличается. Прежде всего, отсутствует математическая модель, которая была бы однозначно признана всеми ведущими разработчиками постреляционных СУБД. Нет документа, который однозначно определил бы требования к таким СУБД. И, наконец, нет самой системы, которая считалась бы эталоном для других систем, как это было с СУБД System-R фирмы IBM.
Одним из основных критериев выбора СУБД всегда была производительность. Однако, несмотря на то, что объектно-ориентированные базы данных существуют уже около 10 лет, стандартных тестов на производительность пока нет. Тому есть несколько причин: отсутствие стандартного языка запросов, канонических приложений, разница в архитектуре и т.д.
Что же есть? Имеется многочисленный опыт разработок, например Jasmine, POSTGRES, и других. Три документа, содержащих пожелания относительно возможностей постреляционных СУБД : [3], [12] и [14].
Подходы в разработке ООБД
За время существования баз данных накоплено огромное количество информации. Разработано огромное количество приложений для работы с базами данных. Это привело к появлению двух конкурирующих концепций архитектур постреляционных СУБД:
1. Объектно-реляционные базы данных
2. Объектно-ориентированные базы данных
Объектно-реляционные базы данных представляют собой реляционные базы данных, дополненные надстройкой, представляющей эти данные как объекты. Все по-прежнему хранится в виде таблиц. Этот подход позволяет плавно перейти от технологии хранилища таблиц к технологии хранилища объектов. Остается возможность выборки данных с помощью SQL-запросов. Сам SQL расширен командами работы с объектами. Наиболее известным продуктом, в котором реализован подобный подход является Oracle ver.8. Комитет ANSI X3H2, разработавший стандарт SQL–92, сейчас работает над SQL3. Основными усовершенствованиями в SQL3 должны стать возможность процедурного доступа наравне с декларативным и поддержка объектов. Основным недостатком объектно-реляционных СУБД является необходимость разбирать объекты для размещения их в таблицах и собирать их для передачи пользователю из таблиц [2].
Объектно-ориентированные базы данных хранят объекты целиком. Для выборки объектов с помощью запросов разрабатывается язык OQL (Object Query Language), в который был включен стандарт SQL'92. Единство описания структуры БД достигается применением языка определения объектов ODL (Object Definition Language), предложенного ODMG (Object Database Management Group), являющегося расширением языка IDL. Эти виды баз данных обладают высокой производительностью, часто в несколько раз более высокой, чем реляционные базы данных. Наиболее известными ООСУБД являются Jasmine, ObjectStore и POET.
Из отечественных разработок в области постреляционных баз данных достоверно известно лишь о существовании ООСУБД ODB-Jupiter. Похоже, она была написана специально для создания продукта ODB-Text. По крайней мере, ни о каких других приложениях написанных на ODB-Jupiter ничего не известно. Также в Internet было обнаружено описание некой отечественной объектно-ориентированной базы данных версии 1.2. Точнее, это был модуль, предоставляющий функции объектно-ориентированной СУБД. Документ даже не имел названия. В нем детально рассматривалась организация хранения данных и принцип работы. Похоже, разработка обосновывалась лишь на принципах, которым должна удовлетворять СУООБД. Наиболее интересная идея: назначение строкам уникальных идентификаторов и удаление строк только при упаковке базы. Это дает существенный выигрыш в сравнении строк, так как объекты-строки с одинаковым содержанием имеют одинаковые идентификаторы.
Основания дипломной работы
Наследование
Наследование является мощным средством моделирования (поскольку кратко и точно описывает мир) и помогает программисту разрабатывать новые версии классов и методов, не опасаясь повредить работающую систему. Наследование способствует повторному использованию кода, потому что каждая программа находится на том уровне, на котором ее может использовать наибольшее число объектов.
Совокупности свойств объекта в объектно-ориентированной базе данных уделяется большее внимание, чем во многих объектно-ориентированных языках программирования, поскольку они являются также целью запросов. Объект=состояние+поведение. Чаще всего существует только одна иерархия наследования. Этот подход перешел и в C++. Однако, возможно разделение иерархий наследования данных и наследования поведений. Не всегда желательно иметь точно такую же иерархию наследования поведения, как и иерархию наследования свойств. Разделение этих двух иерархий повышает возможности переиспользования (reuse) поведений.
Определение родства
Остается важный вопрос: как определить, является ли объект потомком другого объекта? Разделение наследований состояния и поведения приводит к тому, что слово «потомок объекта» обретает двойственное значение. С одной стороны, это потомок по данным, с другой стороны, это потомок по поведению.
На самом деле, в чистой объектно-ориентированной системе данные объектов надежно защищены от вмешательства пользователя через механизм инкапсуляции. Доступ к данным производится через методы. Таким образом, родство объектов следует определять исключительно через их интерфейсы. В системе на основе классов обычно строится дерево наследования. В системе на основе прототипов с конкатенацией определение родства достигается за счет операций пересечения интерфейсов. Поведение объекта составляют методы, хранящиеся в объекте-множестве, а значит для определения родства необходимо выполнить операцию пересечения множеств. Если получившийся в результате пересечения интерфейс совпадает с интерфейсом одного из двух сравниваемых объектов, то другой объект – его потомок. Фактически, это алгоритм определения общего предка двух объектов. Использование множеств для хранения интерфейсов позволяет взглянуть на операцию наследования конкатенацией как на операцию слияния множеств.
Инкапсуляция
Идея инкапсуляции в языках программирования происходит от абстрактных типов данных. С этой точки зрения объект делится на интерфейсную часть и реализационную часть. Интерфейсная часть является спецификацией набора допустимых над объектом операций. Только эта часть объекта видима. Реализационная часть состоит из части данных (состояние объекта) и процедурной части (реализация операций).
Интерпретация этого принципа для баз данных состоит в том, что объект инкапсулирует и программу и данные.
Рассмотрим, например, объект Служащий. В реляционной системе служащий представляется кортежем. Запрос к нему осуществляется с помощью реляционного языка, а прикладной программист пишет программы для изменения этой записи, например повышение зарплаты служащего или прием на работу. Такие программы обычно пишутся либо на императивном языке программирования с включением в него операторов языка манипулирования данными или на языке четвертого поколения и хранятся в обычной файловой системе, а не в базе данных. Таким образом, при таком подходе имеются кардинальные различия между программой и данными, а также между языком запросов (для незапланированных запросов) и языком программирования (для прикладных программ).
В объектно-ориентированной системе служащий определяется как объект, который состоит из части данных (очень даже вероятно, что эта часть практически совпадает с записью, определенной для реляционной системы) и части операций (эта часть состоит из операций повышения зарплаты и приема на работу и других операций для доступа к данным сотрудника). При хранении набора сотрудников, как данные, так и операции хранятся в базе данных. Таким образом, имеется единая модель данных и операций, и информация может быть скрыта. Никакие иные операции, кроме указанных в интерфейсе, не выполняются. Это ограничение справедливо как для операций изменения, так и для операций выборки.
Инкапсуляция обеспечивает что-то вроде “логической независимости данных”: мы можем изменить реализацию типа, не меняя каких-либо программ, использующих этот тип. Таким образом, прикладные программы защищены от реализационных изменений на нижних слоях системы.
Здесь уместно вспомнить о “проблеме 2000 года”, возникшей из-за того, что в СУБД отводилось всего два разряда на год даты. Чтобы исправить возникающую ошибку, нужно пересмотреть заново весь код приложения! В ООБД для решения аналогичной проблемы требуется исправление небольшого количества методов, работающих с данными даты.
Идентификатор объекта
Назначение идентификатора
Объекты в БД обладают индивидуальностью. Даже при изменении структуры и поведения объекта, его индивидуальность сохраняется. Два объекта в системе отличаются своими идентификаторами. Идентификатор является характеристикой индивидуальности. Понятие индивидуальности ново для реляционных баз данных. В чисто реляционной БД все кортежи в пределах одной таблицы отличаются между собой. Характеристика различия – первичный ключ. Многие современные реляционные базы данных допускают существование в пределах одной таблицы одинаковых кортежей. И потребность в этом есть, иначе не было бы квалификатора DISTINCT в операторе SQL SELECT.
Идентификатор объекта в БД позволяет различить между собой два одинаковых по значению объекта. Фактически, он играет роль дескриптора адреса объекта. Таким образом, пользователь работает с объектом не через его адрес, а через его идентификатор.
Строение идентификатора
В современных ООБД для ускорения доступа к объектам идентификаторы наделяются составной структурой.
Имеются два основных подхода для идентификации объектов:
· Составной адрес (Structured address)
· Заменитель (Surrogate)
Составной адрес состоит из физической части (сегмента и номера страницы) и логической части (внутристраничный индекс), которые являются масками фиксированной длины и, соединяясь, дают идентификатор. Составные адреса более популярны в современных ООБД как более эффективные: за один дисковый доступ можно получить адрес объекта. Использование составного адреса как идентификаторов приводит к зависимости от организации физического хранения. Это приводит к трудностям при перемещении данных для хранения на другое устройство.
Заменитель – чисто логический идентификатор, генерируемый по некоторому алгоритму, который гарантирует уникальность. В заменителях, индекс (также называется директорией объекта), часто используется для отображения идентификаторов в расположение объектов. Эффективность операций с базой данных во многом определяется скоростью доступа к одиночному объекту. Часто объекты связаны между собой и доступ к одному объекту происходит через доступ к другому. Например, через объект-список происходит доступ к его элементам. Во многих случаях создание объекта (например, глубоким копированием) приводит к каскадному созданию других объектов, составляющих его содержимое. Использование кластеризации помогает организации быстрого доступа к группе связанных объектов. Кроме того, размещение объектов в одной области дискового пространства также увеличивает быстродействие.
В работе [16] описан подход к построению идентификаторов-заменителей. Идентификатор состоит из двух частей: кода кластера и номера в последовательности. Такой подход основывается на следующих трех принципах:
1) Идентификатор объекта должен содержать информацию о кластере, который группирует совместно используемые объекты
2) Должны быть допустимы произвольные размеры кластеров
3) Идентификаторы объектов должны подчиняться достаточно однообразному представлению, чтобы они могли выступать в качестве псевдоключей динамического хеширования.
Есть три признака, по которым СУБД могут принимать решение о месте размещения объектов:
1) Правила, заданные в схеме БД
2) Указание пользователя
3) Статистика доступа
В дипломной работе, несмотря на заманчивость идеи кластеризации, принят тривиальный подход: идентификатор нового объекта – это значение максимального идентификатора, использующийся в системе, плюс один. Объекты также хранятся не в виде кластеров и не вкладываются друг в друга. Хотя система управления памятью позволяет организовать и такой способ хранения.
Идентификатор поля агрегата
Введение идентификатора поля позволяет преодолеть трудность определения размещения данных полей агрегатов. Суть проблемы заключается в том, что если мы наследуем классы B и C от класса A, а затем наследуем множественно класс D от классов B и C, то экземпляр класса D одновременно является экземпляром классов A, B и C. При этом важно, чтобы "старый" класс (например, A) умел работать с объектами класса D. Эта проблема рассматривается в работе [10], в которой авторы вводят следующие ограничения целостности структуры объектов:
1. В БД не могут существовать отдельные собственные части подклассов
2. Каждой части сложного объекта должна соответствовать только одна собственная часть.
В качестве решения они предлагают использование ссылок на классы и каждую собственную часть класса хранить отдельно.
В дипломной работе предлагается вместо хранения ссылок на классы установить для каждого поля свой идентификатор. При наследовании поле сохраняет свой идентификатор. Таким образом, переименование полей не нарушает связь наследования. Переименование может быть автоматическим, например, из-за конфликтов имен полей при множественном наследовании. Аналогично поступает оператор SQL Select, когда в качестве результата запроса ему нужно вернуть несколько столбцов, имеющих одинаковые имена.
Идентификаторы полей уникальны в пределах базы данных, т.е. при объявлении нового поля в классе, идентификатор поля в дальнейшем появляется только в классах-наследниках и только через наследование.
Кроме того, программисты могут использовать для имен полей привычный для них родной язык, другими словами: есть возможность создавать синонимы имен полей.
Действие (knowhow)
Действие представляет собой объект типа “строка”, хранящий текст ДССП-процедуры. Ссылка на действие может хранится в поле OBJKH объекта, через который и происходит вызов действия. Алгоритм выбора выполняемого действия рассматривается ниже. В интерфейсах объектов указаны идентификаторы объектов, которые в поле OBJKH хранят идентификатор действия. Значения этих объектов являются именем действия. Наиболее удобно использовать для этой цели строковые объекты. Использование поля OBJKH позволяет выполнять одно и то же действие для различных методов различных объектов.
При вызове действия с идентификатором OIDKH делается вызов слова с именем kh$<OIDKH>. Например, для объекта с OIDKH=0x00000DFC это будет KH$00000DFC. Если возникает ситуация EXERR, значит слово в словаре отсутствует и подлежит компиляции. Для компиляции текст действия дополняется префиксом “: KH$<oid> ” и суффиксом “ ;”, после чего компилируется командой TEXEC и выполняется. Словарь действий называется $KH_VOC.
При изменении текста метода необходимо полностью очистить словарь ДССП $KH_VOC, хранящий откомпилированные действия, поскольку эти действия содержат в своем коде абсолютные ссылки на прежнюю откомпилированную версию действия. Впрочем, эта процедура очистки словаря выполняется лишь при переопределении текста действия, что бывает достаточно редко.
Объекты-поведения
В отсутствии классов, хранить методы в каждом объекте было бы слишком накладно. Вынесение правил поведения в отдельный объект позволяет уменьшить затраты на хранение объектов-данных. Математическая модель ООБД в [17], также разделяет данные и поведения, что дополнительно дает возможность переиспользовать поведение другого объекта.
Объект-поведение представляет собой множество объектов-методов, которое и называется интерфейсом объекта.
При посылке на вход произвольного объекта OID2 сообщения OID1 (которое тоже является объектом), сначала проверяется, содержится ли OID1 в интерфейсе объекта OID2 (проверка идентичности). Если да, то выполняется действие объекта OID1, иначе сравниваются значения OID1 и объектов интерфейса (проверка эквивалентности). Если соответствие найдено, выполняется действие, указанное в найденном в интерфейсе объекте.
Параметры методов
Набор_параметров (Blackboard) представляет собой множество меток, аргументных пар { (L1, arg1), … , (Ln, argn) }. Li ÎA, argi ÎO для 1 £ i £ n и "i, j Î 1,…,n : i ¹ j Þ Li ¹ Li.
Впрочем, базовые методы также используют передачу параметров через стек, как более эффективный способ программирования.
Синтаксис посылки сообщения
Воздействие(Набор_параметров) ~> Получатель. Объект, называемый Воздействие (Invoker), является сообщением (message) и посылается к другому объекту, названному Получателем (Reciver), используя Набор_параметров, предоставляющий необходимые аргументы. Если параметры в Наборе_параметров отсутствуют, то можно записать короче: Воздействие ~> Получатель. Посланное сообщение всегда возвращает объект, называемый Результат (Result).
Посылка простого сообщения
Пусть B – Набор_параметров и m и r – два объекта в O.
Примитивные взаимодействия
(1) m(B) ~> fail º fail; fail(B) ~> r º fail;
(2) m(B) ~> null º null; null(B) ~> r º null;
(когда m ¹ fail)
(3) m(B) ~> same º same; same(B) ~> r º r;
(когда m ¹ fail и m ¹ null)
При совпадении значения
(5) Если существует метод x в r или его объектах-учителях (объектов, от которых наследуется поведение) такой, что x » m и sig(x) = (A1,c1) ´ …´ (An,cn)® cr и {(A1,a1) ´ …´
´ (An,an)}ÍB и FID каждого поля сi присутствует в ai, тогда
m(B) ~> r º r.kh(x)(A1 : a1, … , An : an )
иначе
(6) Если r является атомарным, то m(B) ~> r º fail.
Иначе m(B) ~> r является комплексным сообщением (complex message sending), обладает сложной структурой.
Комплексные сообщения
Если Воздействие является объектом-агрегатом, то
s(B) ~> o º null, если s=[ ]
s(B) ~> o º [A1 : s1(B) ~> o1, …, An : sn(B) ~> on], если s=[A1 : s1, …, An : sn]
где oj » o, oj неº o) и orf(oi) Ç orf(o) = Æ для j = 1,..,n и для любого i, j Î [1,..,n], если i ¹ j тогда oj неº o и orf(oi) Ç orf(oj) = Æ (т.е. o1,…,on являются глубокими копиями объекта-получателя o).
Если Воздействие является объектом-условием, то
s(B) ~> o º s.then(B) ~> o, если s.if(B) Ï {False, fail}
s(B) ~> o º s.else(B) ~> o, иначе.
Где s.if, s.then, s.else обозначение if-части, then-части и else-части s соответственно.
Если Воздействие является объектом-множеством, то
s(B) ~> o º null, если s={ }
s(B) ~> o º s1(B) ~> o, если s={s1}
s(B) ~> o º s’(B) ~> o, s’= s – {x} после x(B) ~> o
где x – произвольно выбранный элемент из множества s.
Если Воздействие является объектом-списком, то
s(B) ~> o º null, если s=( )
s(B) ~> o º sn(B) ~>(… ~>( s2(B) ~>( s1(B) ~> o))…) где s = (s1, s2, …, sn)
Разработка структуры СУ
Менеджер памяти
Менеджер памяти является ключевым модулем системы.
Его наличие позволяет
· Абстрагироваться от особенностей обращения к различным видам памяти.
· Создавать сколь угодно вложенные друг в друга структуры данных.
· Иметь единый интерфейс на каждом уровне вложенности.
· Организовать кэширование объектов
В состав менеджера памяти входит 3 системы управления:
1. Система управления виртуальной памятью
2. Система управления каналами
3. Система управления кэшированием объектов
Виртуальная память и каналы
Виртуальная память представляет собой непрерывную для пользователя, с ней работающего, область памяти, которая может быть вложена в другую виртуальную память. Виртуальная память состоит из сегментов, связанных между собой в двунаправленную цепь. Каждому сегменту известно его положение относительно нижнего логического уровня. Работа с виртуальной памятью происходит через канал, выделенный для нее. Канал – это набор характеристик описывающих: где расположена виртуальная память, и в каком ее месте мы находимся. Количество каналов ограничено, поэтому канал выделяется той виртуальной памяти, которая нужна в данный момент. Система имеет набор каналов, которые могут иметь ссылку на виртуальную память, либо быть незанятыми. Первые 5 каналов – это базовые каналы, отображенные на физические носители (оперативная память, файл). Вторые 5 каналов – каналы виртуальной памяти, хранящие каталоги объектов. Остальные каналы предназначены для работы с объектами. Все каналы основываются на каких-либо других каналах, образуя, в общем случае, 5 независимых деревьев. Корень – один из базовых каналов (0..4). Одна и та же виртуальная память не может быть загружена в два канала. При переходе от верхнего канала к нижнему выполняется трансляция адреса.
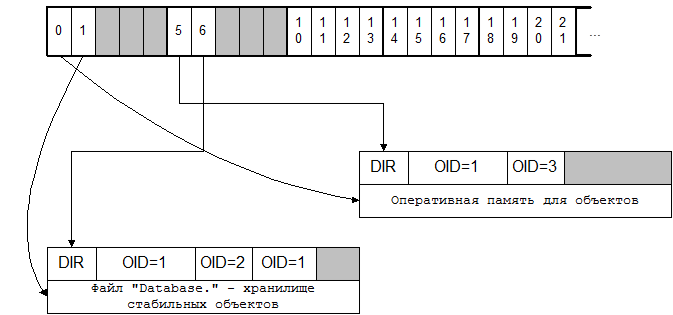
Рис 3: Связь каналов с хранилищами объектов
Таблица 2: Параметры канала
| Параметр канала | Семантика |
| NCHAN | Номер текущего канала |
| LOWCH | Нижний канал; в него вложен этот канал |
| CHGCTX | Признак изменения данных заголовка фрагмента |
| TEKADR | Текущая позиция для чтения/записи |
| SYNCADDR | Адрес начала заголовка текущего сегмента в нижнем канале |
| TEKADR0 | Позиция, соответствующая началу данных фрагмента |
| PREDADDR | Адрес заголовка предыдущего фрагмента (–1, если его нет) |
| NEXTADDR | Адрес заголовка следующего фрагмента (–1, если его нет) |
| BUSYLEN | Занятая длина |
| LEN | Выделенная длина |
Таблица 3: Операции доступа к данным виртуальной памяти
| Операция | Семантика (все операции работают с текущим каналом) |
| IBS | Чтение байта из канала |
| OBS | Запись байта в канал |
| GOTO | Переход по адресу в канале |
| @GOTO | Переход по смещению в канале |
| UPSIZE | Выделить доп. память в конце канала и встать на ее начало |
| DEFRAG | Сделать виртуальную память непрерывной на уровне нижнего канала (т.е. однофрагментной) |
Начало виртуальной памяти соответствует нулевому значению TEKADR. Доступ осуществляется через операции позиционирования (GOTO и @GOTO), чтения байта (IBS) и записи байта (OBS). Остальные функции, реализуются через них (например, чтение длинного слова). К памяти может быть применена функция UPSIZE с аргументом, содержащим необходимое количество байт для выделения. Память может гарантированно выделяться до заполнения всей выделенной длины. При исчерпании выделенной длины, делается запрос к нижестоящему уровню о выделении дополнительной памяти. Если такой запрос применяется к каналу ниже 5-го, соответствующего дисковому файлу, файл увеличивается в размере, если его выделенная длина исчерпана. Если увеличение размера файла невозможно из-за нехватки дискового пространства, то, в случае невозможности выделения памяти за счет упаковки, возбуждается ситуация NOMEMORY. При попытке доступа за пределы определенной виртуальной памяти (например, чтение после расположения данных), возникает ситуация OUTDATA.
Область действия операции
Каждый объект обладает поведением, реализуемым через методы (операции). Если операция работает только с внутренними данными объекта, то она является локальной, если же она посылает сообщения другим объектам, то – глобальной. Посланное к другому объекту сообщение порождает на нем выполнение соответствующей операции. Через транзитивное замыкание можно представить процесс порождения отношением предок – потомок.
Областью действия операции на объекте являются:
Данные состояния объекта, входные параметры операции, системные объекты, а также все объекты, обладающие определенным поведением, если это поведение является объектом, над которым выполняется операция.
Воздействие операции
Все воздействия любой операции на объекте, попадают под одну из четырех категорий: запрос, создание, модификация, удаление. Для каждой операции на объекте определяются соответствующие множества.
Множество запросов QS(opi(O)) определяется рекурсивно как QS(opi(O)) = LocalQS(opi(O)) È GlobalQS(opi(O)), где
· LocalQS = Æ, если нет собственных ivj из O "запрошенных" операцией opi. {O}, иначе.
· GlobalQS =
{Ogq | opi , посылает сообщение к Os для выполнения метода opj, где OsÎ Scope(opi(O)), и OgqÎQS(opj(Os))}.
Аналогично определяются можества создания модификации и удаления операции opi на объекте O.
Множество замен определяется как объединение множеств создания, модификации и удаления. Конфликт операций – выполнение одного из следующих условий:
1. US(opi(O)) Ç US(opj(O')) ¹ Æ
2. QS(opi(O)) Ç US(opj(O')) ¹ Æ
3. US(opi(O)) Ç QS(opj(O')) ¹ Æ
Пользовательские транзакции можно рассматривать как операции над специальным объектом базы данных.
Пользовательские операции могут быть разбиты на ряд шагов, каждый из которых выполняет некоторую логическую единицу работы. Шаги эти также можно считать едиными операциями. Такое разбиение позволяет ввести понятие точки разрыва. Точка разрыва ставится между двумя шагами на одном уровне любой операции.
Эквивалентность расписаний
Для определения эквивалентности расписаний: вводится следующее правило: если результат одной операции получается на основе результата другой операции, то в любом корректном расписании порядок следования конфликтующих операций одинаков. Если конфликта нет, то допустимым является любой порядок следования операций. Если при этом получаются разные результаты, то каждый из них, тем не менее, является правильным. Этот парадокс можно проиллюстрировать на следующем примере:
Положим, имеются две операции: увеличить сумму на счете вдвое и увеличить сумму на счете на 10%. Очевидно, что результат будет разным в зависимости от порядка следования операций. Но, поскольку операции независимы, в любом случае он считается правильным.
Спецификация точки проверки
Идея точки проверки используется для минимизации глубины отката в случае обрыва транзакций. Эти точки могут быть описаны пользователем. Точки проверки связаны с операциями на объектах и могут быть описаны как шаг операции. Нет необходимости иметь спецификацию точки проверки для каждого объекта в системе. Однако пользователь может описать точки проверки в некоторых операциях на некоторых объектах, так, что каждая точка представляет логическую единицу работы. Идея установки точек проверки предоставляет базе данных возможность определять, находится ли она в согласованном состоянии. Точка проверки служит как механизмом синхронизации, так и заботой о связности базы данных. Любая пользовательская транзакция может иметь зависимость от результатов других транзакций. Таким образом, точка проверки в транзакции имеет значение только если все другие активные операции также согласны с тем, что состояние базы данных в этой точке является непротиворечивым состоянием (consistent state). При этом точка проверки действует как точка встречи, в которой все активные транзакции системы фиксируют (commit) свою, возможно, частично сделанную, до этой точки работу.
Приложение базы данных предполагает значительную известность относительно семантики операций в базе данных. Семантика знаний может быть использована для установки точек проверки в транзакциях в точках, которые соответствуют логическому завершению некоторой части работы. В традиционных базах данных с быстро выполняющимися транзакциями сама транзакция является логической единицей работы. Однако в крупных приложениях нельзя трактовать транзакцию целиком как логическую единицу работы. В этом и состоит полезность идеи точек проверки.
Представление данных в ООБД
Базовые объекты системы
Системе известны следующие базовые объекты: ROOT, FAIL, NULL, SAME, ATOMIC, INT, STR, DATIME, BIO, AGG, SET, SEQ.
1. ROOT – корень – предок всех объектов. Данных не имеет.
2. FAIL, копия ROOT – возвращается, если при воздействии произошла ошибка.
3. NULL, копия ROOT – объект-заменитель при отсутствующем значении. Эта проблема возникла недавно, но в теории реляционных баз данных пока не нашла приемлемого решения. Суть проблемы заключается в том, что при вводе данных, некоторые из них могут отсутствовать (например, не известен год рождения), поэтому нельзя сказать, чему они в точности равны. В некоторых случаях нуль может являться значением, для этого и вводится специальное обозначение (NULL).
4. SAME, копия ROOT – объект, позволяющий создавать копии. Он означает, что для взаимодействующего с ним объекта создается копия.
5. ATOMIC – предок всех атомарных объектов. Задает для них основные методы поведения.
6. INT – целое.
7. STR – строка.
8. DATIME – дата и время
9. BIO – условный объект
10. AGG – агрегат
11. SET – множество
12. SEQ – последовательность
Строение объекта
Каждому объекту выделяется персональное виртуальное пространство. Объект предваряется заголовком. За заголовком следуют виртуальные пространства данных и журнала. Каждый объект имеет уникальный идентификатор в пределах системы.
Таблица 5: Заголовок объекта (все поля 32-битные)
| Поле | Семантика |
| OID | Идентификатор объекта (уникальный в пределах системы) |
| OBJBHR | Идентификатор объекта-поведения (методы) |
| OBJKH | Идентификатор объекта-действия |
| TRCOOBJ | Идентификатор транзакционного сообъекта |
| VALUE | Адрес заголовка вложенного канала, хранящего значение |
| HISTORY | Адрес заголовка вложенного канала, хранящего историю изменений |
Блок данных объекта
Атомарный объект хранит внутри блока данных свое значение.
Объект-условие хранит внутри блока данных три идентификатора в следующем порядке: идентификатор метода условия, идентификатор метода, выполняемого, если условие выполнено («истина») и идентификатор метода, выполняемого, если условие не выполнено ( «ложь»).
У объектов агрегат, список и множество первое слово блока данных – размер элемента. Для списка и множества он равен 4. Для агрегата – 12.
Элементом списка и множества является идентификатор объекта. Элементом агрегата является кортеж:
· идентификатор объекта-значения (он обязательно является потомком объекта-образца)
· идентификатор поля (FID)
· идентификатор объекта-образца
Если идентификатор объекта-экземпляра в списке или множестве равен нулю, это означает, что элемент удален. Признаком конца списка, множества, полей объекта служит размер виртуальной памяти, выделенной для размещения данных.
Таблица 6: Строение данных для DATIME
| Длина в байтах | Значение |
| 2 | Год |
| 1 | Месяц |
| 1 | День |
| 1 | Час |
| 1 | Минуты |
| 1 | Секунды |
| 2 | Доли секунд |
Такая структура журнала позволяет фиксировать изменения не только данных, но и поведений, knowhow…
Таблица 7: Структура записи изменений во внутреннем журнале объекта
| Число байт | Значение |
| 4 | Номер транзакции |
| 2 | Адрес размещения в заголовке |
| 4 | Замененное значение |
| 2 | Год |
| 1 | Месяц |
| 1 | День |
| 1 | Час |
| 1 | Минуты |
| 1 | Секунды |
| 2 | Доли секунд |
Контекст транзакции
В системе есть объект DBIO (Database User-Intarface Object), которому известны состояния всех транзакций. Этот объект представляет собой множество, элементами которого являются объекты-агрегаты, описывающие контекст транзакции.
Таблица 9: Контекст транзакции
| Имя поля | Размер в байтах | Значение |
| TR_MESS | 4 | OID сообщения |
| TR_KH | 4 | OID knowhow |
| TR_PARAM | 4 | OID агрегата с параметрами |
| TR_TARGET | 4 | OID целевого объекта сообщения |
| TR_RES | 4 | OID результата |
| TR_STACK | 4 | OID стека |
| TR_N | 4 | Номер транзакции |
| TR_HOSTN | 4 | Номер вызвавшей транзакции |
| TR_STATUS | 1 | Состояние транзакции |
| TR_POINT | 2 | Точка разрыва, в которой находимся |
Для каждой транзакции выделяется свой стек. Механизм сохранения и восстановления стеков описан в [7]. Стеки сохраняются в атомарных объектах.
Требования к техническим и программным средствам
ДССП реализована на множестве компьютерных платформ (VAX, PDP-11, IBM PC, R3000, MC68020, SPARC) и операционных систем (MSDOS, MSDOS-экстендеры, UNIX, RT-11, RSX, OS9, CPM и др.). В данный момент практически закончена разработка ДССП на Си, что обеспечивает перенос этой системы на любую платформу, где есть Си.
Аппаратные средства:
Любая платформа, на которой функционирует ДССП, с объемом оперативной памяти для нужд БД не менее 1 Мб.
Программные средства:
ДССП с диспетчером параллельных процессов (версия 4.42) и Операционная Система.
Разрабатываемая СУООБД может также работать в качестве host-программы на файл-сервере, обрабатывая команды с рабочих станций, поступающие в их персональные ящики на файл-сервере. Ответ рабочие станции получают также через почтовые ящики.
В дальнейшем, могут быть реализованы сетевые протоколы и тогда СУООБД будет являться сервером в клиент-серверных приложениях.
Использование отдельных почтовых ящиков для нескольких параллельно работающих пользователей позволяет возложить на СУООБД функции монитора [6], осуществляющего линеаризацию поступающих запросов к содержимому СУООБД.
Реализация прототипа
Построитель
LOAD TIMEM
LOAD M0
LOAD M2
LOAD Soms
LOAD CHMS
LOAD SYSOBJS
LOAD M3
LOAD LS_CASH
UNDEF
PROGRAM $KH_VOC
Менеджер виртуальной памяти
PROGRAM $M2
B16 [физическая организация памяти]
[вычисление физического адреса и номера базового канала]
:: : POSIX [addr(i)] NCHAN C NBASECH < BR+ LEAVE [addr nchan] D
GOTO DELTA2 S( NCHAN ) TOLOW POSIX [addr(i-1)] ;
:: : TOLOW LOWCH !NCHAN ;
[Пересчет адреса в адрес нижнего уровня: TEKADR(i) -> TEKADR(i-1)]
:: : DELTA2 SYNCADDR HSIZE + TEKADR TEKADR0 - + ;
:: : IBS EON OUTDATA OUTDATA# LAST?
TEKADR POSIX TEKADR++ S( NCHAN ) !NCHAN BSGOTO
NCHAN BR 0 IBS0 1 IBS1 [2 IBS2] ELSE UNKCH ;
:: : OBS EON OUTDATA OUTDATA# LAST?
TEKADR POSIX TEKADR++ S( NCHAN ) !NCHAN BSGOTO
NCHAN BR 0 OBS0 1 OBS1 [2 OBS2] ELSE UNKCH ;
: LAST? TEKADR BUSYLEN TEKADR0 + = IF0 LEAVE NEXTBLK ;
[переход для базового канала ]
: BSGOTO [ADDR] NCHAN BR 0 BSGOTO0 1 BSGOTO1 [2 BSGOTO2] ELSE UNKCH ;
: BSGOTO0 !TEKADR ;
: BSGOTO1 C !TEKADR HSIZE+ SPOS DATACH ;
[ : BSGOTO2 C !TEKADR HSIZE+ SPOS JOURCH ;]
0 %IF
: ADDR [PARAGRAF OFFSET] + [address] ; [Сейчас пгф=1 байту]
[Для файлов можно сделать неск. файлов и распределить по ним пространство]
%FI
: IBS0 TEKADR HSIZE+ MEMORY &0FF TEKADR++ ;
: IBS1 IB DATACH &0FF TEKADR++ ;
[: IBS2 IB JOURCH &0FF TEKADR++ ;]
: OBS0 &0FF TEKADR HSIZE+ ! MEMORY TEKADR++ ;
: OBS1 &0FF OB DATACH TEKADR++ ; [Запись байта]
[: OBS2 &0FF OB JOURCH TEKADR++ ;] [Запись байта]
:: : GOTO NCHAN NBASECH < BR+ BSGOTO VGOTO ;
: VGOTO TEKADR - @GOTO ;
[Переход по смещению]
:: : @GOTO C BRS @GOTO- D @GOTO+ ;
: @GOTO+ DO @GOTO1+ ;
: @GOTO- NEG DO @GOTO1- ;
: @GOTO1+
EON OUTDATA OUTDATA#
TEKADR TEKADR0 BUSYLEN + =
IF+ NEXTBLK TEKADR 1+ !TEKADR ;
: @GOTO1-
EON OUTDATA OUTDATA#
TEKADR TEKADR0 =
IF+ PREDBLK TEKADR 1- !TEKADR ;
: NEXTBLK CHGCTX IF+ SCTX NEXTADDR NOEXIST? !SYNCADDR RELCTX
TEKADR !TEKADR0 ;
: NOEXIST? [ADDR] C -1 = IF+ OUTDATA [ADDR] ;
[Pred, Next, BusyLen, Len]
:: : LCTX' [UPCH] PUSH TEKADR ILS ILS ILS ILS POP
NCHAN E2 !NCHAN !LOWCH !LEN !BUSYLEN !NEXTADDR !PREDADDR !SYNCADDR
0 !CHGCTX ;
[Грузить параметры канала]
:: : LCTX [newch] LCTX' 0 !TEKADR 0 !TEKADR0 ;
: RELCTX TEKADR0 TEKADR NCHAN SYNCADDR TOLOW GOTO LCTX !TEKADR !TEKADR0 ;
: PREDBLK CHGCTX IF+ SCTX PREDADDR NOEXIST? !SYNCADDR RELCTX
TEKADR BUSYLEN - !TEKADR0 ;
: IBSC [CHAN] S( NCHAN ) !NCHAN IBS ;
: ILSC S( NCHAN ) !NCHAN ILS ;
: OBSC [N CHAN] S( NCHAN ) !NCHAN OBS ;
: IOBSCC [SRC DST] C2 IBSC C2 OBSC ;
: DO_IOBSCC [SRC_CH DST_CH N] S( NCHAN )
C3 !NCHAN 0 GOTO DO IOBSCC [SRC DST] ;
: IWS IBS IBS SWB &0 ;
: ILS IWS IWS SETHI ; [SWW &0]
: OWS C OBS SWB OBS ;
: OLS C OWS SWW OWS ;
[Перейти к конечному блоку]
: GOTOENDBK NEXTADDR -1 = EX+ BUSYLEN TEKADR0 +
NEXTADDR !SYNCADDR RELCTX C !TEKADR0 !TEKADR ;
: GOBOTTOM RP GOTOENDBK BUSYLEN TEKADR0 + GOTO ;
: LENVMEM GOBOTTOM TEKADR [LEN] ; [длина виртуальной памяти]
: LASTADDR SYNCADDR LEN + HSIZE+ ;
: OBS-0 NCHAN BR 0 OBS00 1 OBS01 [2 OBS02] ELSE OBS0N ;
: OBS00 0 OBS0 ; : OBS01 0 OBS1 ; [: OBS02 0 OBS2 ;] : OBS0N 0 OBS ;
[Спецификация: Размер увеличивается на N байт. Если это невозможно,
возникает исключительная ситуация NOMEMORY.
После работы мы стоим в том же канале в начале выделенного пространства. ]
: UPSIZE [N] GOBOTTOM TEKADR E2 UPSIZE' GOTO [] ;
: UPSIZE' [N] GOBOTTOM LEN BUSYLEN - CALCOST [HARD SOFT] UPSIZEI
C BR0 D UPSIZEO ;
: CALCOST [N FREE] C2C2 <= BR+ COST1 COST2 [HARD SOFT] ;
: COST1 [N FREE] T0 E2 [0 N] ;
: COST2 [N FREE] C PUSH - POP [N-FREE FREE] ;
: UPSIZEI [N_SOFT] BUSYLEN + !BUSYLEN 1 !CHGCTX SCTX ;
: UPSIZEO [N_HARD] NCHAN BR 0 USO0 1 USO1 2 USO1 ELSE USON ;
: USO1 C GOBOTTOM TEKADR E2 DO OBS-0 [!TEKADR] BSGOTO
C BUSYLEN + !BUSYLEN LEN + !LEN 1 !CHGCTX SCTX ;
: USO0 NOMEMORY [Сюда можно вставить упаковку] ;
[Спецификация: увеличение размера (жестко, т.е. за счет нижнего уровня)]
: USON [N] SYNCADDR LASTADDR USON1 RELCTX [>] UPSIZE' ;
: USON1 S( NCHAN ) TOLOW BUSYLEN = BR+ USON_ADD USON_NEW ;
[Расширение увеличением длины фрагмента]
: USON_ADD C2 [N SYNCADDR N] UPSIZE' C BUSYLEN E2 - HSIZE - E2
[N LEN SYNCADDR] 3 *4 + GOTO OLS [N] [UPSIZEI] ;
[Расширение созданием нового фрагмента]
: USON_NEW C2 [N SYNCADDR N] [GOBOTTOM] C HSIZE+ UPSIZE'
[N SYNCADDR N] C2 -1 0 C4 TEKADR PUSH WRITECTX D 4+ GOTO POP OLS [N] ;
: WRITECTX [PRED NEXT BUSY LEN] C4 OLS C3 OLS C2 OLS C OLS DD DD ;
FIX VAR UPCONST 10 ! UPCONST [Этому числу байт кратно увеличение]
[Увеличение размера нижнего уровня]
[увеличение физического размера этого уровня]
: SCTX CHGCTX IF0 LEAVE 0 !CHGCTX NCHAN BR 0 NOP 1 SCTX1 [2 SCTX2]
3 NOP 4 NOP ELSE SCTXN ;
: SCTXN TEKADR NCHAN LEN BUSYLEN NEXTADDR
PREDADDR SYNCADDR TOLOW GOTO 4 DO OLS !NCHAN GOTO ;
: SAVEALL NOP ; [СОХРАНИТЬ ВЕСЬ КАНАЛ НА ПЕРВИЧНОМ УСТРОЙСТВЕ (ИСТОЧНИКЕ)]
: SCTX1 POS DATACH 8 SPOS DATACH BUSYLEN OL DATACH LEN OL DATACH SPOS DATACH ;
[
: SCTX2 POS JOURCH 8 SPOS JOURCH BUSYLEN OL JOURCH LEN OL JOURCH SPOS JOURCH ;
]
[Новая виртуальная память]
0 %IF
: NEWVM [N] TEKADR C2 HSIZE+ UPSIZE GOTO -1 -1 C3 C WRITECTX D ;
%FI
: NEWVM [N] C HSIZE+ UPSIZE TEKADR PUSH -1 -1 0 C4 WRITECTX DO OBS-0
POP [SYNCADR] ;
: END? NEXTADDR -1 = TEKADR BUSYLEN TEKADR0 + = & ;
: NEWVM1 [N] C HSIZE+ UPSIZE TEKADR PUSH -1 -1 E3 C WRITECTX WRI_DATA
POP [SYNCADR] ;
: LOADCH0 0 !NCHAN 0 !LOWCH 0 !TEKADR 0 !BUSYLEN
TOTMEMLEN !LEN 0 !TEKADR0 0 !SYNCADDR -1 !NEXTADDR -1 !PREDADDR ;
[ДЛЯ БАЗОВЫХ КАНАЛОВ LOWCH=NCHAN]
Система управления каналами
PROGRAM $CHMS
3 VALUE LENGRP [Вместимость уровня приоритетов]
4 VALUE QChannels
LENGRP 3 * 1+ VALUE LenPrioQue [длина очереди приоритетов. Очередь -- с 0]
: N2CH [N] QChannels * 0A + [NCHAN] ;
LenPrioQue 1+ N2CH 10 * LONG VCTR CHDATA [память параметров каналов]
[для каждого канала можно завести 16. различных параметров]
: CHMS.INIT 0 !!! PrioQueOID
0 LenPrioQue DO SETNQ D ;
: SETNQ C C ! PrioQueNUM C N2CH [NUM CHAN1]
[вычислили номер канала для очередного объекта кэша]
C C3 1 ! Channels
1+ C C3 2 ! Channels
1+ C C3 3 ! Channels
1+ C C3 4 ! Channels D 1+ ;
[при обращении к объекту нужно повысить его приоритет]
: HIPRIODD D HIPRIO ;
: HIPRIO [OID] FINDOID C BR- D HIPRIO1 ;
: HIPRIO1 [N] C LENGRP / D C IF+ 1- LENGRP * [N N'] E2 UPOID [] ;
[Новый объект добавляется на последн. поз-ю, а затем к нему примен. HIPRIO]
LenPrioQue LONG VCTR PrioQueOID [список OID]
LenPrioQue WORD VCTR PrioQueNUM [номера записей в массиве каналов]
LenPrioQue QChannels 2 WORD ARR Channels
[обменять в очереди с соседним вышестоящим]
: SWP2OBJ [N] C IF0 LEAVE C PrioQueOID C2 1- PrioQueOID
C3 ! PrioQueOID C2 1- ! PrioQueOID
C PrioQueNUM C2 1- PrioQueNUM C3 ! PrioQueNUM C2 1- ! PrioQueNUM 1- [N-1] ;
: SWP2OBJDD SWP2OBJ DD ;
: FINDOID [OID] 0 LenPrioQue DO CMPOID E2D C LenPrioQue = IF+ T-1 [-1/N] ;
: CMPOID [OID] C PrioQueOID [OID N OID(N)] C3 = EX+ 1+ ;
[Поднять объект от N_DOWN к N_UP в очереди]
: UPOID [N_UP N_DOWN ] C E3 - DO SWP2OBJ D [] ;
[Просмотр очереди (кэш объектов)]
: Q.VIEW 0 LenPrioQue
." M.Hdr D.Hdr M.Dat D.His"
DO QELVIEW D ;
: QELVIEW [n] CR C C 2 TON LENGRP / E2D BR0 #- #) TOB
C PrioQueOID ." OID=" .D C PrioQueNUM ." Num=" .
." Channels= " 1 QChannels DO PriNCH
DD 1+ ;
: PriNCH [NOID NCH] C2C2 Channels 4 TON SP SP 1+ [NOID NCH+1] ;
Работа с базовыми объектами
PROGRAM $SYSOBJS
B16
LONG VAR ADRSTR LONG VAR LENSTR
0 VALUE N_OID 4 VALUE N_BHR 8 VALUE N_KH
0C VALUE N_TRC 10 VALUE N_VAL 14 VALUE N_HIS
13 VALUE JRECLEN
: G_OID N_OID GOTO ; : W_OID G_OID OLS ;
: G_BHR N_BHR GOTO ; : W_BHR G_BHR OLS ;
: G_KH N_KH GOTO ; : W_KH G_KH OLS ;
: G_TRC N_TRC GOTO ; : W_TRC G_TRC OLS ;
: G_VAL N_VAL GOTO ; : W_VAL G_VAL OLS ;
: G_HIS N_HIS GOTO ; : W_HIS G_HIS OLS ;
18 VALUE SZ_HDROBJ
: W_NULLBLK -1 OLS -1 OLS 0 OLS 0 OLS ;
[Описание системных объектов]
ACT VAR DATWR
LONG VAR OIDV
LONG VAR VALINT
[**** ROOT ****]
SZ_HDROBJ HSIZE+ HSIZE+ 4+ VALUE SIZE_ROOT
:: : CLONE_ROOT '' DATWRROOT ! DATWR NEWOBJ1 ;
:: : CLONE_INT ! VALINT '' DATWRINT ! DATWR NEWOBJ1 ;
:: : CLONE_SET 4 CLONE_INT ;
:: : CLONE_SEQ 4 CLONE_INT ;
:: : CLONE_AGG 0C CLONE_INT ;
:: : CLONE_STR [A L] ! LENSTR ! ADRSTR '' DATWRSTR ! DATWR
LENSTR SIZE_ROOT + 4- ! SIZE_X NEWOBJ3 ;
:: : SET_BHR [OID_BHR OID] N_BHR E2 SET_X1 ;
:: : SET_KH [OID_KH OID] N_KH E2 SET_X1 ;
: SET_X1 [ADR OID] C2C2 N_TRSC E2 NEWJREC
C LOADOBJ FINDOID C BR- DD SET_X11 ;
: SET_X11 PrioQueNUM 2 Channels !NCHAN GOTO OLS ;
:: : SET_INT [int oid] C HIPRIO PUSH ! VALINT 4 '' OLSI POP NEWDREC ;
: OLSI VALINT OLS ;
:: : GET_INT [OID] TODATA ILS ;
:: : TODATA [OID] C LOADOBJ C HIPRIO FINDOID PrioQueNUM
3 Channels !NCHAN 0 GOTO ;
:: : SET_STR [A L OID] C HIPRIO
PUSH ! LENSTR ! ADRSTR LENSTR '' OLSS POP NEWDREC ;
: OLSS ADRSTR LENSTR DO DWS1 D ;
ACT VAR BYTE_STR
:: : PRINT_STR '' PRIS ! BYTE_STR ACCESS_STR ;
:: : COPY2BUF_STR '' C2BUF ! BYTE_STR ACCESS_STR ;
:: : ACCESS_STR [OID] TODATA LENVMEM 0 GOTO DO BYTE_STR ;
: PRIS IBS TOB ;
: C2BUF IBS ABUF !TB !1+ ABUF ;
: DD_ROOT
OIDV OLS 0 OLS 0 OLS 0 OLS SZ_HDROBJ HSIZE+ OLS [val]
SZ_HDROBJ OLS [his]
W_NULLBLK [W_NULLBLK] DATWR ;
LONG VAR SIZE_X
: DATWRROOT -1 OLS -1 OLS 0 OLS 4 OLS 0 OLS ;
: DATWRINT -1 OLS -1 OLS 4 OLS 4 OLS VALINT OLS ;
: DATWRSTR -1 OLS -1 OLS LENSTR OLS LENSTR OLS ADRSTR LENSTR DO DWS1 D ;
: DWS1 [A] C @B OBS 1+ ;
: NEWOBJ1 [] SIZE_ROOT ! SIZE_X NEWOBJ3 ;
: NEWOBJ3 '' DD_ROOT ! WRI_DATA
NEWID C ! OIDV SIZE_X C2 D.NEWOBJ [OID] ;
9 VALUE LCH
LCH LONG VCTR CLONEHDR VAR DATCH LONG VAR LENVMEM1
:: : CLONE [OID] C HIPRIO
C LOADOBJ FINDOID PrioQueNUM C PUSH 2 Channels !NCHAN 0 GOTO
CLONE1 []
'' CC_ROOT ! WRI_DATA NEWID C 0 ! CLONEHDR SZ_HDROBJ HSIZE+ C2 D.NEWOBJ
[OID] POP 3 Channels C ! DATCH !NCHAN LENVMEM C ! LENVMEM1
C2 [OID_NEW LEN OID_NEW] CLONE_DATA [OID_NEW] ;
: CLONE1
ILS 1 ! CLONEHDR [BHR] ILS 2 ! CLONEHDR [KH]
ILS 3 ! CLONEHDR [TRC] 0 4 ! CLONEHDR
SZ_HDROBJ 5 ! CLONEHDR -1 6 ! CLONEHDR
-1 7 ! CLONEHDR 0 8 ! CLONEHDR
0 9 ! CLONEHDR ;
: CCR1 [N] C CLONEHDR OLS 1+ ;
: CC_ROOT 0 LCH 1+ DO CCR1 D ;
: CLONE_DATA [LEN OID] '' COPY_DATA E2 NEWDREC [] ;
: COPY_DATA [] DATCH NCHAN LENVMEM1 DO_IOBSCC DD ;
:: 0 VALUE N_TRSC
[Запись новых данных, запись в журнал]
: NEWDREC [SIZED PROC OID] N_VAL N_TRSC C3 NEWJREC FINDOID
PrioQueNUM [SIZE PROC N] C PUSH
2 Channels !NCHAN
[SIZED PROC] ! WRI_DATA NEWVM1 G_VAL C OLS [ADR_DATA]
[перечитать канал данных]
GOTO POP 3 Channels LCTX [] ;
[новая запись в журнал. На вх: номер транз. и адрес из заголовка]
: NEWJREC [addr_hdr TRANS OID] C LOADOBJ FINDOID PrioQueNUM
[. TRANS N] C PUSH 4 Channels
!NCHAN JRECLEN UPSIZE OLS POP NCHAN PUSH 2 Channels !NCHAN
C GOTO ILS POP !NCHAN
E2 OWS OLS W_DATIME [] ;
B10
[Запись текущего времени]
: W_DATIME 1979 OWS 12 OBS 31 OBS TMGET TMS ;
: TMS [num] N2T GBR E2 GBR E2 GBR E2 OBS OBS OBS 100 * OWS ;
B16
[просмотр журнала объекта]
[Переключиться на журнал]
: OBJ.J [OID]
C LOADOBJ FINDOID PrioQueNUM 4 Channels !NCHAN ;
: JVIEW [oid] CR ."Updated data:"
OBJ.J LENVMEM JRECLEN / D 0 GOTO DO JVIEW1 ;
: JVIEW1 CR ."Trans= " ILS .D SP
IWS BR N_BHR ."Behav.=" N_VAL ."AddrVal=" N_KH ."Knowhow="
ELSE ."?????? =" ILS SP .D SP JDATAV1 ;
: JDATAV1 S( BASE@ ) B10 IWS IBS IBS 2 TON #. TOB 2 TON #. TOB 4 TON
SP SP #: POS2 #: POS2 #. POS2 # IWS 4 TON TOB ;
: POS2 [B] IBS 2 TON TOB ;
[Определить размер объекта в памяти = заголовок + данные]
: SIZEMEMOBJ [N] C PrioQueOID BR0 T0 SMEMO1 [0/size] ;
: SMEMO1 3 Channels !NCHAN LENVMEM HSIZE+ HSIZE+ SZ_HDROBJ + [size] ;
Выполнение действий
PROGRAM $M3
[Выполнение действий (knowhow)]
FIX 1000 BYTE VCTR BUFTXT [Буфер для текста действий]
FIX LONG VAR ABUF
: BEGABUF 0 ' BUFTXT ! ABUF ;
: RUNCMD [OID_KH] BEGABUF "KH$" S2BUF N2BUF ABUF BEGABUF ABUF E2 C2 -
TEXEC ;
: MAKECMD [OID_KH] BEGABUF ": KH$" S2BUF C N2BUF # ABUF !TB !1+ ABUF
COPY2BUF_STR " ; " S2BUF
ABUF BEGABUF ABUF E2 C2 - TEXEC ;
: S2BUF [A L] DO S2BUF1 D ;
: S2BUF1 C @B ABUF !TB !1+ ABUF 1+ ;
: N2BUF [N] 8 DO CTN-SB D 8 [C1 .. Cn n] DO CTB ;
: CTN-SB [N] C 0F & #0 + E2 -4 SHT [C N'] ;
: CTB ABUF !TB !1+ ABUF ;
LONG VAR OIDK
: NEW_VOC "PROGRAM $KH_VOC" TEXEC ;
: RUN_KH [OID_KH] NEW_VOC C MAKECMD RUNCMD ;
Кэширование объектов
PROGRAM $LS_CASH
[ Каналы: 1 - Header M.Obj 2 - Header D.Obj 3 - M.Data 4 - D.History ]
[Считаем, что все объекты -- стабильные]
: LOADOBJ [OID] C FINDOID [искали в кэше] C BR- LOADOBJ-1 DD ;
: LOADOBJ-1 D [OID] [Ищем в каталоге БД объект] [C] LOADOBJ1 [LOADOBJ2]
LenPrioQue 1- HIPRIO1 [] ;
: LOADOBJ1 6 LOADOBJ3 ;
[открыть дисковый объект в кэше]
: LOADOBJ3 [OID NDIRCH] EL_FIND [OID 1/0] IF0 O_NOTFND [Нет такого объекта]
C LenPrioQue 1- ! PrioQueOID [Занесли в кэш идентификатор объекта]
ILS [OID ADDR_MEM] [получили адрес размещения в дисковой памяти]
LenPrioQue 1- PrioQueNUM
[получили номер отведенной для работы с объектом группы каналов]
[OID ADDR_MEM NUM]
C 2 Channels [OID ADDR_MEM NUM CHANOBJ]
NCHAN NBASECH - !NCHAN [получили номер базового канала]
C3 GOTO LCTX [OID ADDR_MEM NUM] [загрузили заголовок дискового объекта]
E2D [O N]
C 4 Channels [OID NUM CHANHIST] [получили канал для истории]
G_HIS ILS
[O N C HISTORY] [HISTORY д.б. <>0]
GOTO NCHAN E2 LCTX [Открыли историю в канале] !NCHAN [O N]
C 3 Channels G_VAL ILS GOTO LCTX [временно открыли канал данных
напрямую с жесткого диска]
[LOADDM]
NOP [Здесь нужно установиться на объект в памяти и канал данных перекл. на него]
DD [] ;
VAR NCHANDAT
VAR NCHANOBJ LONG VAR LENDAT
: COPY_DAT1 [] NCHANOBJ 0 GOTOC [NCHANOBJ] NCHAN 0 GOTO 8 DO_IOBSCC D 14 OLS
0 OLS 10 GOTOC NCHAN 4 DO_IOBSCC DD -1 OLS -1 OLS LENDAT OLS LENDAT OLS
COPY_DAT ;
: GOTOC [NCHAN n] C2 S( NCHAN ) !NCHAN GOTO [NCHAN] ;
: COPY_DAT [] NCHANDAT NCHAN [SRC_CH DST_CH]
C2 !NCHAN LENVMEM [SRC_CH DST_CH LEN] 0 GOTO DO_IOBSCC DD ;
8. Контрольный пример, демонстрирующий возможности технологии
DB.NEW
Создадим объект "Поведение клоуна" для клоуна
[] "Поведение клоуна" CLONE_STR
[oid_str] OIDSET GET_BHR CLONE
[oid_str oid] SET_NAMEOBJ [oid]
Создадим объект "Клоун":
[.. ] "Клоун" CLONE_STR
[.. oid_str] CLONE_AGG
[.. oid_str oid] SET_NAMEOBJ [.. oid]
Определим ему поведение
[oid_bhr oid] SET_BHR
Определим в нем поля: X, Y, Цвет
"X" NEWFID SET_NAMEFID [fid] OIDINT "Клоун" NAMEOID AGG+F []
В ДССП можно определить новое слово
: NEWFIELD [ "Имя объекта" "Имя поля"] NEWFID SET_NAMEFID [A L FID]
OIDINT C4C4 NAMEOID AGG+F DD [] ;
"Клоун" "Y" NEWFIELD
"Клоун" "Цвет" NEWFIELD
Создадим методы.
Создать метод "Идти".
"<тело метода "Идти" >" CLONE_STR [oid_kh]
[oid_kh] "Идти" CLONE_STR E2 C2 SET_KH [OID_STRKH]
"Поведение клоуна" NAMEOBJ SET+E
Аналогично создаются другие методы
...
Подготовка для вызова метода по идентификатору:
"Идти" CLONE_STR C "Клоун" NAMEOBJ METHOD? E2 DELOBJ
Подготовка для вызова метода по имени:
"Идти" CLONE_STR
Вызов
[oid] 0 "Клоун" NAMEOBJ [oid_mth 0 oid_obj] SEND
SCAN
SELECT SCHET
REPLACE SUMMA WITH SUMMA*1.1 FOR SCHET.NUM_SCH=CLIENT.NUM_SCH
SELECT CLIENT
REPLACE PREMIA WITH .T.
ENDSCAN
Реляционные базы данных
Реализация языка SQL позволяет работать с базой данных исключительно средствами SQL. Поддерживаются триггеры, отношения между таблицами, хранимые процедуры. Это типичные клиент-серверные СУБД. Управление целостностью данных возлагается на СУБД. Триггеры позволяют вынести практически все проверки из логики программы. Недостатком является необходимость нормализации таблиц, что затрудняет добавление новых таблиц при сопровождении программного средства, а иногда требует перенормализации, что влечет за собой необходимость изменять программный код, а значит, и новые ошибки.
Программный код обработки (MS Visual FoxPro 3.0 и выше):
BEGIN TRANSACTION
UPDATE SCHET SET SUMMA=SUMMA*1.1
WHERE NUM_SCH IN (SELECT NUM_SCH FROM CLIENT)
UPDATE CLIENT SET PREMIA = .T.
END TRANSACTION
Умножение счетов на 1.1
1.1 Операция селекции выбирает множество счетов
1.2 Операция проекции выбирает интересующую часть счета – сумму
1.3 На суммы посылается операция «умножить» с аргументом 1.1
Литература
[1] О.И.Авен Я.А.Коган “Управление вычислительным процессом” М. Энергия 1978
[2] А.М.Андреев Д.В.Березкин, Ю.А.Кантонистов «Среда и хранилище: ООБД»
Мир ПК №4 1998 (стр 74-81)
[3] М. Аткинсон, Ф. Бансилон и др. «Манифест систем объектно-ориентированных баз данных», СУБД № 4 1995
[4] В.Бобров "Объектно-ориентированные базы данных, мультимедийные типы данных и их обработка" Read.Me №4, 1996
[5] Н.П.Брусенцов, В.Б.Захаров и др. «Развиваемый адаптивный язык РАЯ диалоговой системы программирования ДССП» Москва МГУ 1987
[6] Бурцев А.А "Параллельное программирование. Учебное пособие по курсу "Операционные системы" - Обнинск : ИАТЭ, 1994 - 90 с.
[7] Бурцев А.А. «Сопрограммный механизм в ДССП как основа для построения мониторов параллельных процессов»
[8] Г.Буч «Объектно-ориентированное проектирование (с примерами применения)» М.Конкорд 1992
[9] К.Дж.Дейт «Введение в системы баз данных» 1998 Киев Диалектика
[10] Мутушев Д.М. Филиппов В.И. "Объектно-ориентированные базы данных" Программирование. - М., 1995 №6 стр. 59-76
[11] В.Ремеев «FoxPro. Версия 2.5 для MS-DOS. Описание команд и функций» М. «Мистраль» 1994
[12]СУБД № 2 1995 «Системы баз данных третьего поколения: Манифест»
[13]СУБД № 1 1996 «Стандарт систем управления объектными базами данных ODMG-93: краткий обзор и оценка состояния» Л.А.Калиниченко
[14]СУБД № 1 1996 «ТРЕТИЙ МАНИФЕСТ» Х.Дарвин, К.Дэйт
[15]СУБД № 5-6 1996 “Введение в СУБД часть 9” стр. 136-153 С.Д. Кузнецов
[16]Data & Knowledge Engineeging №15 (1995) стр 169-183 “Selection of object surrogates to support clustering” Jukka Teuhola
[17] Data & Knowledge Engineering. Amsterdam 1996 Том 18 №1 стр.29-54 "Unifying data, behaviours, and messages in object-oriented databases" Sylvia L. Osborn, Li Yu
[18] IEEE Transactions On Knowledge And Data Engineering Том 7 №2 Апрель 1995 стр. 274-292 «Security Constraint Processing in a Multilevel Secure Distributed Database Management System» B.Thuraisingham, W.Ford
[19] Journal of systems and software - N.Y., 1996 Том 35 №3 стр. 169-183
Shah P. Wong J. "Concurency control in a object-oriented data base system"
Документы в Internet (http://www.citforum.ru):
[20] В. Индриков, АО ВЕСТЬ “Объектно-ориентированный подход и современные мониторы транзакций”
[21] Л.Калиниченко “Архитектуры и технологии разработки интероперабельных систем”, Институт проблем информатики РАН
[22] С.Д. Кузнецов "Основы современных баз данных"
[23] С. Кузнецов “Безопасность и целостность, или Худший враг себе - это ты сам”
Содержание
1. Введение............................................................................................................................................ 3
1.1 Причины появления объектно-ориентированных баз данных.................................................. 3
1.2 Подходы в разработке ООБД.......................................................................................................... 4
1.3 Краткий сравнительный анализ постреляционных и традиционных баз данных................. 5
1.4 Основания дипломной работы...................................................................................................... 5
1.5 Анализ полученного результата................................................................................................... 7
2. Уточнение методов решения задачи.............................................................................. 8
2.1 Наследование................................................................................................................................... 8
2.2 Инкапсуляция................................................................................................................................ 10
2.3 Идентификатор объекта................................................................................................................ 11
2.4 Идентификатор поля агрегата..................................................................................................... 13
2.5 Триггеры. Ограничение доступа.................................................................................................. 13
2.6 Действие (knowhow)...................................................................................................................... 14
2.7 Объекты-поведения....................................................................................................................... 14
2.8 Принципы взаимодействия объектов......................................................................................... 14
2.9 Транзакции и механизм согласованного управления............................................................ 17
3. Разработка структуры СУ...................................................................................................... 18
3.1 Положение дел в области интероперабельности систем.......................................................... 18
3.2 Менеджер памяти........................................................................................................................... 20
3.3 Виртуальная память и каналы.................................................................................................... 20
3.4 Система управления кэшированием объектов......................................................................... 21
3.5 Система управления журнализацией и восстановлением...................................................... 23
3.6 Принципы реализации механизма согласованного управления.......................................... 24
4. Представление данных в ООБД.......................................................................................... 28
4.1 Базовые объекты системы............................................................................................................ 28
4.2 Строение объекта........................................................................................................................... 28
4.3 Контекст транзакции..................................................................................................................... 30
5. Описание операций над объектами в БД................................................................... 31
6. Требования к техническим и программным средствам.................................. 33
7. Реализация прототипа.......................................................................................................... 34
7.1 Построитель.................................................................................................................................... 34
7.2 Заголовочный модуль для каналов............................................................................................ 34
7.3 Менеджер виртуальной памяти................................................................................................... 35
7.4 Система управления хранением объектов................................................................................. 38
7.5 Система управления каналами................................................................................................... 39
7.6 Работа с базовыми объектами..................................................................................................... 40
7.7 Выполнение действий................................................................................................................... 42
7.8 Кэширование объектов................................................................................................................. 42
8. Контрольный пример, демонстрирующий возможности технологии.. 44
9. Оценка трудоемкости разработки ПО с использованием традиционного и предлагаемого подходов........................................................................................................ 45
9.1 Табличные базы данных с низкоуровневыми операциями доступа...................................... 45
9.2 Реляционные базы данных........................................................................................................... 45
9.3 Объектно-ориентированные базы данных................................................................................. 46
9.4 Будущее применения различных баз данных............................................................................ 46
10. Литература................................................................................................................................... 47
Введение
Причины появления
объектно-ориентированных баз данных
Развитие вычислительной техники и увеличение объемов хранимой информации привело к необходимости выделения технологии баз данных в отдельную науку. Как правило, базы данных хранили множество однотипных данных, предоставляя пользователю сервис доступа к нужной ему информации. На смену иерархическим и сетевым базам данных пришли реляционные базы данных. Успех реляционных баз данных обусловлен их более простой архитектурой, наличием ненавигационного языка запросов и, главное, ясностью математики реляционной алгебры.
На этапе зарождения технологии баз данных при построении какой-либо базы данных строилась физическая модель. С накоплением опыта стало понятно, что нужен переход к даталогической модели, которая позволяет абстрагироваться от конкретной СУБД. Появилось понятие схемы базы данных, описывающей организацию данных в СУБД. Программы стали работать с базой данных не напрямую, а через схему БД. Такой подход обеспечил возможность менять структуру БД без необходимости изменять логику программ. Появление и стандартизация SQL предоставила единый интерфейс для работы с данными. Иерархическая и сетевая модели баз данных стали применяться крайне редко. Это было вызвано, прежде всего, трудностью модификации схем иерархических и сетевых баз данных и сильно зависящей от приложений навигацией в этих базах данных.
Далее, развитие объектно-ориентированного анализа и объектно-ориентированного проектирования как эффективных подходов для формализации предметной области, привело к появлению инфологической модели предметной области. Теперь, при разработке базы данных составлялось три модели представления информации предметной области: инфологическая, даталогическая и физическая, не считая локальных пользовательских представлений.
Рис 1: Этапы проектирования БД
Поскольку физическая модель требовала привлечения эксперта в области конкретной СУБД для получения эффективного размещения данных, физическая модель стала строиться самой СУБД из схемы БД, вводимой пользователем на основе даталогической модели предметной области. Затем появились CASE-средства, позволяющие создавать инфологическую модель предметной области и транслирующие ее в даталогическую модель.
Казалось бы, что цель достигнута, – проектировщик работает только с инфологической моделью, но на самом деле, до тех пор, пока работа происходит с реляционной базой данных, существует разрыв между языком программирования (логикой пользователя) и языком описания данных (представлением данных), который преодолевать должен программист. Суть разрыва можно сформулировать так: возможности работы с данными программы и с данными СУБД должны быть одинаковы.
В конце 80-х – начале 90-х годов массовое внедрение персональных компьютеров привело к развитию мультимедиа-технологий и настольных САПР, структуры данных в которых слишком сложны для процедурного программирования или же необычны (например, звук). Это, а также то, что объектно-ориентированное программирование позволяет существенно снизить сложность разработки и обеспечить адекватное представлению моделирование предметной области, привело к тому, что в области языков программирования произошло слияние стилей языков высокого уровня. Доминирующим подходом стало внедрение в них технологий объектно-ориентированного программирования. Не остались в стороне и языки, встроенные в СУБД. В качестве примера вышеизложенного можно привести продукт Visual FoxPro фирмы Microsoft. Эта СУБД обладает объектно-ориентированным языком программирования, но, по сути, является реляционной СУБД, поскольку хранимые данные представлены в виде таблиц, а таблицы представляют собой множество кортежей, которые содержат атомарные значения. Такое несоответствие и привело к буму в области разработки постреляционных баз данных.
Сложившаяся ситуация хотя чем-то и напоминает время перехода к реляционным базам данных, однако во многом и отличается. Прежде всего, отсутствует математическая модель, которая была бы однозначно признана всеми ведущими разработчиками постреляционных СУБД. Нет документа, который однозначно определил бы требования к таким СУБД. И, наконец, нет самой системы, которая считалась бы эталоном для других систем, как это было с СУБД System-R фирмы IBM.
Одним из основных критериев выбора СУБД всегда была производительность. Однако, несмотря на то, что объектно-ориентированные базы данных существуют уже около 10 лет, стандартных тестов на производительность пока нет. Тому есть несколько причин: отсутствие стандартного языка запросов, канонических приложений, разница в архитектуре и т.д.
Что же есть? Имеется многочисленный опыт разработок, например Jasmine, POSTGRES, и других. Три документа, содержащих пожелания относительно возможностей постреляционных СУБД : [3], [12] и [14].
Подходы в разработке ООБД
За время существования баз данных накоплено огромное количество информации. Разработано огромное количество приложений для работы с базами данных. Это привело к появлению двух конкурирующих концепций архитектур постреляционных СУБД:
1. Объектно-реляционные базы данных
2. Объектно-ориентированные базы данных
Объектно-реляционные базы данных представляют собой реляционные базы данных, дополненные надстройкой, представляющей эти данные как объекты. Все по-прежнему хранится в виде таблиц. Этот подход позволяет плавно перейти от технологии хранилища таблиц к технологии хранилища объектов. Остается возможность выборки данных с помощью SQL-запросов. Сам SQL расширен командами работы с объектами. Наиболее известным продуктом, в котором реализован подобный подход является Oracle ver.8. Комитет ANSI X3H2, разработавший стандарт SQL–92, сейчас работает над SQL3. Основными усовершенствованиями в SQL3 должны стать возможность процедурного доступа наравне с декларативным и поддержка объектов. Основным недостатком объектно-реляционных СУБД является необходимость разбирать объекты для размещения их в таблицах и собирать их для передачи пользователю из таблиц [2].
Объектно-ориентированные базы данных хранят объекты целиком. Для выборки объектов с помощью запросов разрабатывается язык OQL (Object Query Language), в который был включен стандарт SQL'92. Единство описания структуры БД достигается применением языка определения объектов ODL (Object Definition Language), предложенного ODMG (Object Database Management Group), являющегося расширением языка IDL. Эти виды баз данных обладают высокой производительностью, часто в несколько раз более высокой, чем реляционные базы данных. Наиболее известными ООСУБД являются Jasmine, ObjectStore и POET.
Из отечественных разработок в области постреляционных баз данных достоверно известно лишь о существовании ООСУБД ODB-Jupiter. Похоже, она была написана специально для создания продукта ODB-Text. По крайней мере, ни о каких других приложениях написанных на ODB-Jupiter ничего не известно. Также в Internet было обнаружено описание некой отечественной объектно-ориентированной базы данных версии 1.2. Точнее, это был модуль, предоставляющий функции объектно-ориентированной СУБД. Документ даже не имел названия. В нем детально рассматривалась организация хранения данных и принцип работы. Похоже, разработка обосновывалась лишь на принципах, которым должна удовлетворять СУООБД. Наиболее интересная идея: назначение строкам уникальных идентификаторов и удаление строк только при упаковке базы. Это дает существенный выигрыш в сравнении строк, так как объекты-строки с одинаковым содержанием имеют одинаковые идентификаторы.
Краткий сравнительный анализ постреляционных и традиционных баз данных
Постреляционные базы данных вобрали в себя все лучшие черты иерархических, сетевых и реляционных баз данных.
Хотя существуют некоторые сходства, как, например, использование указателей и вложенная структура записей в сетевой модели. Однако надо отметить, что СУООБД используют логические указатели для обеспечения целостности, а также поддерживают иерархию классов, наследование и методы. Таких средств нет в иерархических и сетевых моделях [4].
Реляционные СУБД, идеально соответствующие своему назначению в традиционных областях применения баз данных, — банковское дело, системы резервирования и т.д. — в данном случае оказываются неудобными и неэффективными по многим причинам. Основное требование реляционной модели — нормализация — в случае сложноструктурированных данных с многочисленными взаимосвязями приводит к сложным запросам с соединением таблиц. То есть к тому, к чему реляционные СУБД не приспособлены, поскольку не могут обеспечить высокую производительность, требуемую интерактивным системам.
Производительность реляционных СУБД в таких случаях может уступать СУООБД во много раз. Кроме того, приложения развиваются, и число таблиц увеличивается. Небольшое изменение в организации данных может привести к необходимости изменить исходные тексты программы. При этом вносятся дополнительные ошибки. Объектно-ориентированные языки БД позволяют достичь того же результата локальными изменениями в свойствах и методах интересующих объектов. Кроме того, методы работы с объектами хранятся в базе вместе с объектами.
Основания дипломной работы
Дата: 2019-05-28, просмотров: 405.