| Режим | Описание |
| 0 | Применяется атрибутивная модель сопоставления. Каждый XML-атрибут преобразовывается в столбец таблицы |
| 1 | Аналогично режиму 0, но для необработанных столбцов применяется сопоставление на основе элементов XML-документа |
| 2 | Применяется сопоставление на основе элементов. Каждый элемент преобразовывается в столбец таблицы |
На рис. 14.8 приведен пример использования функции OPENXML для формирования реляционного результирующего набора.

Рис. 14.18. Пример использования функции OPENXML
Обратите внимание (рис. 14.18): 1) из XML-фрагмента с помощью XPATH-выражения выделяется множество тегов с именами аудитория; 2) применяется режим работы 0, подразумевающий атрибутивное сопоставление; 3) имена столбцов в выражении WITH совпадают с именами атрибутов в XML-структуре; 4) после применения функции OPENXML должна быть выполнена системная процедура SP_XML_REMOVEDOCUMENT, освобождающая использованные OPENXML ресурсы.
Для того, чтобы явно указать сопоставление XML-структуры со структурой стоки результирующего набора, можно в выражении WITH каждого столбца результирующего набора указать XPATH-выражение, определяющее содержимое этого столбца (рис. 14.19).
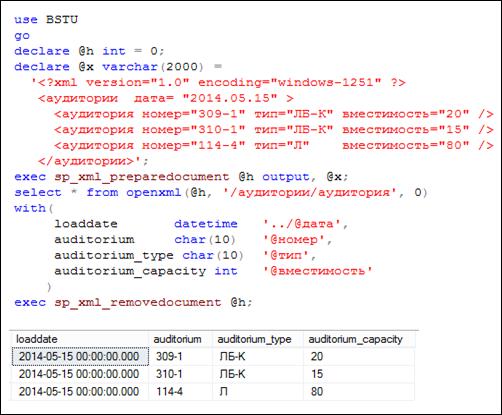
Рис. 14.19. Явное указание XPATH-выражения, определяющего источник данных
На рис. 14.20 приведен пример использования OPENXML в режиме 2, предназначенном для обработки XML-фрагмента в элементном формате XML-данных.
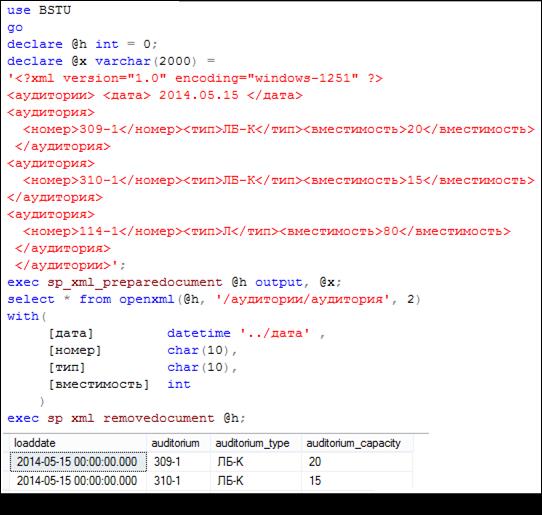
Рис. 14.20. Применение режима 2 функций OPENXML
для обработки XML-фрагмента в элементном формате
Тип данных XML
В большинстве своем данные, хранимые в таблицах БД, имеют фиксированный формат. Например, дата рождения. Очевидно, что для хранения этой информации можно воспользоваться типом DATE. При этом, если потребуется указать, что эта дата не известна, то для столбца можно разрешить значение NULL и интерпретировать при обработке это значение соответствующим образом.
В тех случаях, если данные являются составными (состоящими из нескольких компонент), и при этом не имеют фиксированный формат, удобно использовать XML для их структуризации. Например, если в таблице хранится информация о гражданах разных стран, то структура их почтового адреса может значительно отличаться в зависимости от страны проживания. Или, например, информация об образовании людей (учебные заведения, даты начала и завершения обучения, специальности, квалификации и пр.) будут различными у разных людей.
В таблице БД допускается использование столбцов типа XML. В примере на рис. 14.21 создается таблица STUDENT, содержащая XML-столбец c именем INFO.
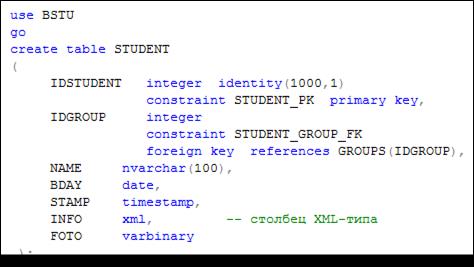
Рис. 14.21. Создание таблицы, содержащей XML-столбец
XML-данные могут быть добавлены в таблицу с помощью оператора INSERT. В простейшем случае сами XML-данные задаются в виде строкового литерала (рис. 14.22), который автоматически будет преобразован в XML-тип при записи
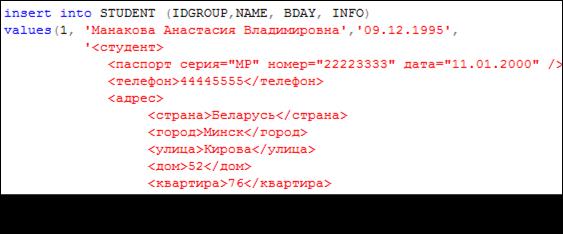
Рис. 14.22. Добавление в таблицу строки, содержащей данные XML-типа
С помощью оператора SELECT данные XML-типа могут быть найдены и извлечены из БД. В простейшем случае извлекается полностью XML-структура (рис. 14.23).
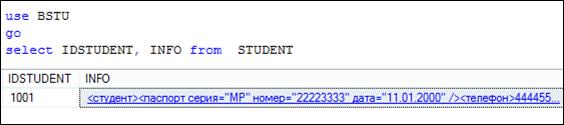
Рис. 14.23. Извлечение данных XML-столбца
Часто требуется извлечь не полностью хранящуюся в БД XML-структуру, а лишь ее подмножество. Для этого можно воспользоваться методами XML-типа (табл. 14.3). В качестве параметра методы принимают строку, содержащую выражение на языках XPATH и XQUERY [7], позволяющие либо выделить, либо изменить фрагменты хранящегося в столбце XML-документа (рис. 14.24–14.26).
Таблица 14.3
Методы типа данных XML
| Метод | Описание |
| query | Исполняет выражения XPATH и XQUERY и возвращает XML-фрагмент |
| value | Исполняет выражения XPATH и XQUERY и возвращает скалярное значение, которое может быть преобразовано в тип SQL |
| exist | Исполняет выражения XPATH и XQUERY и возвращает 1, если узел, заданный выражением, найден |
| modify | Изменение XML-содержимого |
| nodes | Исполняет выражения XPATH и XQUERY и возвращает XML-фрагмент |
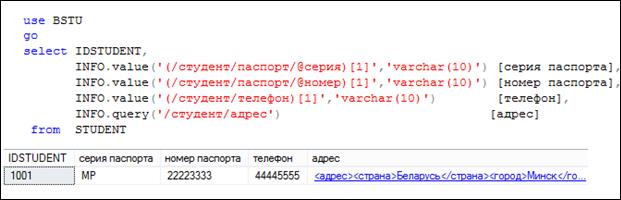
Рис. 14.24. Применение метода value XML-типа для извлечения значений атрибутов и текстовых данных, метода query для извлечения фрагмента XML-документа
Обратите внимание (рис. 14.24): 1) XML-тип является объектным типом (имеет методы и свойства); 2) в первых двух случаях применения метода value извлекаются значения атрибутов серия и номер; 3) в третьем случае применения value извлекается текстовое значение элемента телефон; 4) во всех трех случаях применения метода value в конце заданного выражения стоит число в квадратных скобках, обозначающее номер выбираемого экземпляра; дело в том, что выражения, указанные в качестве параметров, позволяют выбрать более чем одно значение; указанная в квадратных скобках единица позволяет получить только первый экземпляр; 5) второй параметр метода value указывает на тип данных, к которому должно быть преобразовано выбранное значение; 6) метод query, применяемый в четвертом элементе SELECT-списка, позволяет выбрать XML-фрагмент.
В примере на рис. 14.25 метод value используется в выражении секции FROM оператора UPDATE. В секции SET задается новое значение для столбца INFO в выбранных строках таблицы STUDENT.

Рис. 14.25. Поиск и корректировка данных XML-типа в таблице
T-SQL допускает применение переменных XML-типа в сценариях. Работа с такими переменными практически ничем не отличается от работы с переменными традиционных типов.
На рис. 14.26 приведен пример сценария, в котором с помощью оператора DECLARE объявлены две переменные XML-типа.
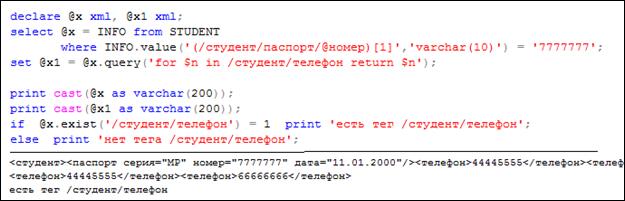
Рис. 14.26. Применение XML-типа в сценарии T-SQL
С помощью операторов SELECT и SET этим переменным присваиваются значения. С помощью оператора PRINT предварительно преобразованные значения XML-переменныx в строки выводятся в выходной поток. В логическом выражении оператора IF применяется метод exists, позволяющий определить наличие заданного XML-узла в значении XML-переменной.
Типизированные XML-данные
Главной особенностью данных XML-типа является их сложность. Значение XML-переменной или XML-столбца таблицы, как правило, является составным и может содержать в себе несколько других значений, которые сами могут представлять собой XML-документы, XML-фрагменты, просто числовые, символьные или другие данные. Сложность усугубляется еще тем, что некоторые элементы, атрибуты XML-документа или значения могут быть не обязательными. Для упрощения работы XML-тип реализован в виде объектного типа. Иными словами, XML-тип имеет методы (табл. 14.3), облегчающие их применение.
Сложность XML-данных требует иного подхода к механизму ограничения целостности для этого типа данных. В семействе XML-технологий существует и активно используется технология, основанная на языке XML-Schema.
XML-Schema – это одна из реализаций языка XML, поддерживаемая консорциумом W3C и предназначенная для описания структуры XML-документа. С помощью языка XML-Schema можно описать правила, которым должен подчиниться XML-документ. Файл, содержащий XML-Schema, обычно имеет расширение XSD (XML Schema definition). Большинство современных систем программирования предусматривают встроенные механизмы, позволяющие с помощью заданного XSD-файла проверять на корректность XML-документы. Для знакомства с языком XML-Schema рекомендуются источники [6, 7].
Для хранения документов XML-Schema в БД MSS предусмотрен специальный объект – XML SCHEMA COLLECTION. Каждый такой объект может содержать один или более XML-SCHEMA-документов.
На рис. 14.27 приведен пример создания объекта XML SCHEMACOLLECTION (далее коллекция схем) с именем Student, содержащего один документ.
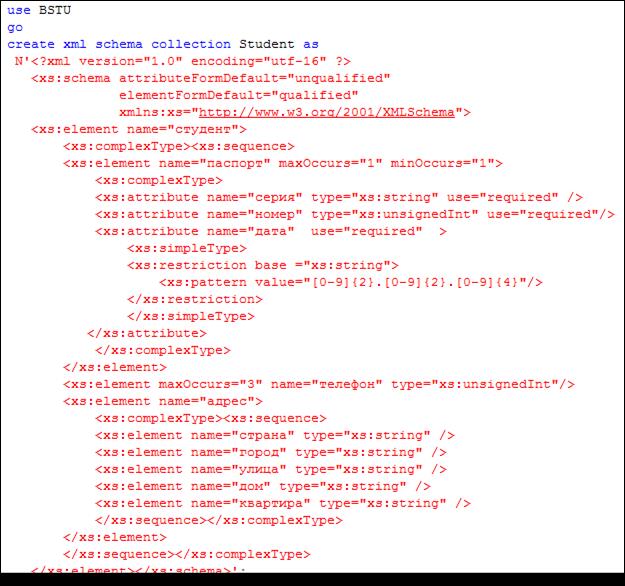
Рис. 14.27. Создание объекта XML SCHEMA COLLECTION, содержащего один документ XML-Schema
Документ XML-Schema, размещенный в коллекции Student, описывает XML-документ с корневым элементом студент (первый тег element).
На втором уровне (внутри тега студент) может быть расположено три тега: паспорт, телефон и адрес (вложенные теги element). Причем тег паспорт должен быть ровно один (атрибуты maxOccurs и minOccurs); тег телефон является обязательным и может быть в количестве не более трех (атрибут maxOccurs ); тег адрес тоже является обязательным, и количество таких тегов не должно быть более одного.
Элементы третьего уровня присутствуют только внутри элемента адрес. Это элементы: страна, город, улица, дом, квартира. Все эти элементы являются обязательными и должны присутствовать ровно один раз.
Данные в документе размещаются как значения атрибутов (теги attribute) или как значения, размещенные в теле элементов (телефон, страна, город, улица, дом, квартира). Тип данных, размещаемых в атрибутах или теле элементов данных, определяется значением атрибута type.
При создании таблицы для XML-столбца можно указать имя коллекции схем (рис. 14.28). Такой столбец называется типизированным столбцом.
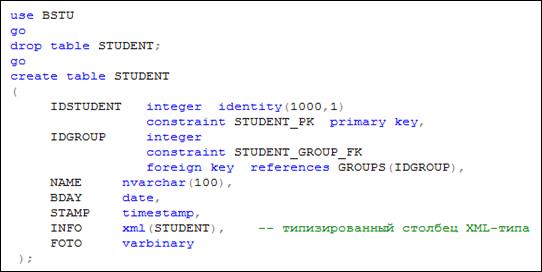
Рис. 14.28. Создание таблицы, содержащей типизированный XML-столбец
Типизированный XML-столбец должен удовлетворять хотя бы одной схеме из связанной с ним коллекции.
На рис. 14.29 приведен пример попытки добавления строки в таблицу STUDENT, содержащую типизированный XML-столбец. При этом возникла ошибка из-за несоответствия вводимого XML-документа схеме (рис. 14.27). Обратите внимание, что в значении атрибута дата элемента паспорт допущена ошибка. В схеме (рис. 14.27) для атрибута дата указано регулярное выражение, задающее правильный формат значения.
В примере на рис. 14.29 возникла ошибка из-за отсутствия обязательного элемента страна, который должен присутствовать внутри элемента адрес.
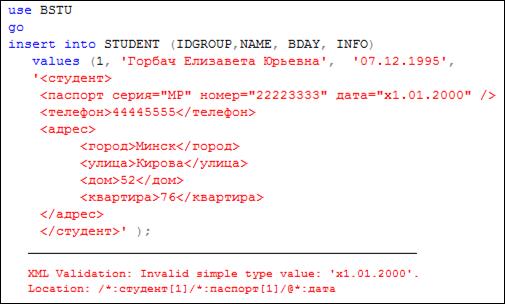
Рис. 14.29. Ошибка при вводе данных в типизированный XML-столбец
(атрибут дата в теге паспорт)
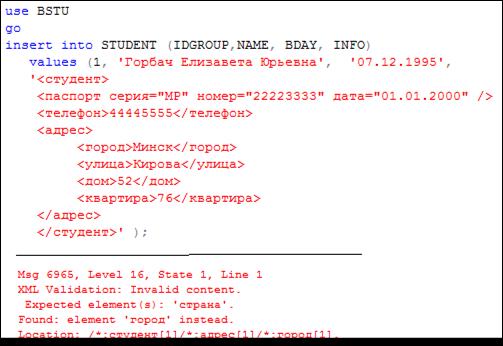
Рис. 14.30. Ошибка при вводе данных в типизированный XML-столбец
(отсутствует обязательный тег страна )
На рис. 14.31 приведен пример добавления в типизированный XML-столбец INFO таблицы STUDENT XML-документа, полностью удовлетворяющего схеме, содержащейся в коллекции схем с именем STUDENT.
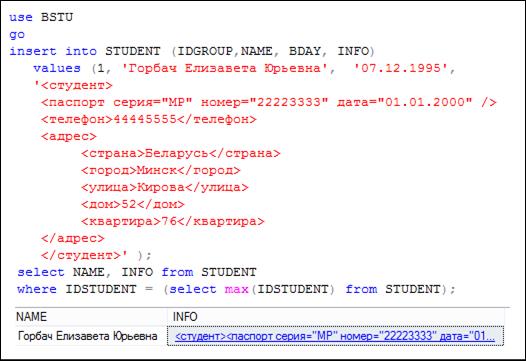
Рис. 14.31. XML-документ, удовлетворяющий схеме (рис. 14.27)
Для более детального знакомства с возможностями применения XML-технологий в MSS рекомендуется воспользоваться изданиями [5, 7].
ЛИТЕРАТУРА
1. Дейт, К. Дж. Введение в системы баз данных / К. Дж. Дейт. – М.: Вильямс, 2005. – 1316 с.
2. Жилинский, А. А. Самоучитель Microsoft SQL Server / А. А. Жилинский. – СПб.: БХВ-Петербург, 2009. – 240 с.
3. Хотек, М. Microsoft SQL Server 2008: Реализация и обслуживание. Учебный курс Microsoft / М. Хотек. – M.: Русская редакция, 2012. – 576 с.
4. Microsoft SQL Server 2008: руководство администратора для профессионалов / Б. Найт [и др]. – M.: Вильямс, 2010. – 944 с.
5. Хабибуллин, И. Ш. Самоучитель XML / И. Ш. Хабибуллин. – СПб.: БХВ-Петербург, 2003. – 336 с.
6. Браст, Э. Дж. Разработка приложений на основе Microsoft SQL Server 2005. Мастер-класс / Э. Дж. Браст, С. Форте. – М.: Русская редакция, 2007. – 880 с.
7. Библиотека MSDN [Электронный ресурс]. – 2012. – Режим доступа: http://msdn.microsoft.com/ru-ru/library / Microsoft – Дата доступа: 12.09.2013.
Приложение. Таблицы базы данных BSTU
Таблица П.1
Таблицы базы данных BSTU
| Имя таблицы | Столбцы таблицы | Наименования столбцов, свойства столбцов |
| FACULTY (Факультеты) | FACULTY | код факультета ,PK, char(10). not null |
| FACULTY_NAME | наименование факультета, varchar(50), default ‘???’ | |
| PROFESSION (Специальности) | PROFESSION | код специальности, PK, char(20). not null |
| FACULTY | код факультета, FK(FACULTY), char(10). not null | |
| PROFESSION_NAME | наименование специальности, varchar(100), null | |
| QUALIFICATION | квалификация, varchar(50), null | |
| PULPIT (Кафедры) | PULPIT | код кафедры, PK, char(20). not null |
| PULPIT_NAME | наименование кафедры, varchar(100), null | |
| FACULTY | код факультета, FK(FACULTY), char(10). not null | |
| TEACHER (Преподаватели) | TEACHER | код преподавателя ,PK, char(10). not null |
| TEACHER_NAME | фамилия, имя, отчество преподавателя, varchar(100), null | |
| GENDER | пол, char(1), GENDER in (‘м’,’ж’) | |
| PULPIT | код кафедры, FK(PULPIT), char(10). not null | |
| SUBJECT (Дисциплины) | SUBJECT | код дисциплины, PK, char(10). not null |
| SUBJECT_NAME | наименование дисциплины, varchar(100), null, unique | |
| PULPIT | код кафеды, FK(PULPIT), char(20). not null | |
| AUDITORIUM_TYPE (Типы учебных аудиторий) | AUDITORIUM_TYPE | код типа аудитории, PK, char(10). not null |
| AUDITORIUM_TYPENAME | наименование типа аудитории, varchar(30), null | |
| AUDITORIUM (Учебные аудитории) | AUDITORIUM | код аудитории, PK, char(20). not null |
| AUDITORIUM_TYPE | код типа аудитории, FK(AUDITORIUM_TYPE), char(10). not null | |
| AUDITORIUM_CAPACITY | вместимость аудитории, int, default 1, check between 1 and 300 | |
| AUDITORIUM_NAME | наименование аудитории, varchar(50), null | |
| GROUPS (Студенческие группы) | IDGROUP | идентификатор группы, PK, int, not null |
| FACULTY | код факультета, FK(FACULTY), char(10). not null | |
| PROFESSION | код специальности, FK(PROFESSION) , char(20). not null | |
| YEAR_FIRST | год поступления, smallint, YEAR_FIRST < текущий год +2 | |
| COURSE | курс, вычисляемое поле, tinyint, вычисляется на основе текущей даты и значения YEAR_FIRST | |
| STUDENT (Студенты) | IDGROUP | идентификатор группы, FK(GROUP), int, not null |
| NAME | фамилия, имя, отчество, nvarchar(100) | |
| BDAY | дата рождения, date | |
| STAMP | штамп времени, timestamp | |
| INFO | дополнительная информация, xml, по умолчанию null | |
| FOTO | фотография, varbinary(max), по умолчанию null | |
| PROGRESS (Успеваемость) | SUBJECT | предмет |
| IDSTUDENT | ||
| PDATE | дата экзамена, date | |
| NOTE | оценка, integer check between 1 and 10 |
Таблица П.2
Содержимое таблицы FACULTY
| FACULTY | FACULTY_NAME |
| ТТЛП | Технология и техника лесной промышленности |
| ТОВ | Технология органических веществ |
| ХТиТ | Химическая технология и техника |
| ИЭФ | Инженерно-экономический факультет |
| ЛесХоз | Лесохозяйственный факультет |
| ИДиП | Издательское дело и полиграфия |
Таблица П.3
Дата: 2019-02-25, просмотров: 413.