| Наименование элемента | Назначение элемента |
| EVENT_INSTANCE | Корневой элемент |
| EventType | Наименование события, вызвавшего триггер |
| PostTime | Штамп времени, соответствующий моменту возникновения события |
| SPID | Значение системного идентификатора процесса |
| ServerName | Имя сервера |
| LoginName | Имя Login от лица которого выполняется триггер |
| DatabaseName | Контекст (имя текущей БД) выполнения триггера |
| TSQLCommand | Корневой элемент описания текущей команды |
| SetOption | Значение текущих опций БД |
| CommandText | Текст оператора, вызвавшего событие, обрабатываемое триггером |
На уровне сервера (ALLSERVER) может быть создан LOGON-триггер, предназначенный для обработки подключения к серверу (рис. 13.99).
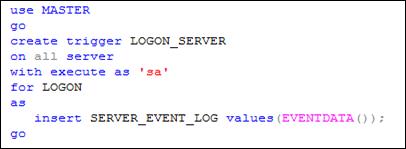
Рис. 13.99. Пример создания Logon-триггера
Если после создания Logon-триггера выполнить подключение к серверу (рис. 13.100), то в результате выполнения триггера (рис. 13.99) содержимое таблицы SERVER_EVENT_LOG пополнится строкой (рис. 13.101), содержащей XML-структуру, представленную на рис. 13.102.
Рис. 13.100. Подключение к серверу с помощью MSMS
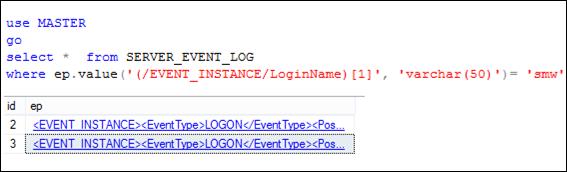
Рис. 13.101. Строки таблицы SERVER_ EVENT_ LOG, добавленные в результате выполнения Logon-триггера (рис. 13.99)
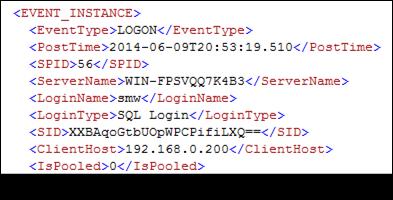
Рис. 13.102. XML-структура, описывающая событие подключения (Logon) к MSS
Обратите внимание, что XML-структура (рис. 13.102) содержит несколько новых элементов: SID – идентификатор сессии, ClientHost – хост клиента.
DDL-триггеры уровня базы данных. На рис. 13.103 представлен пример триггера с именем DDL_DB уровня БД, предназначенного для обработки группы событий с именем DLL_DATABASE_LEVEL_EVENTS (табл. 13.4).
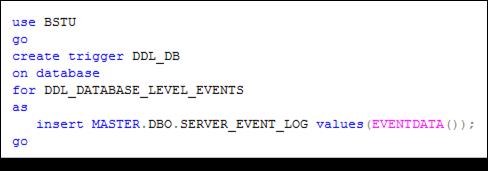
Рис. 13.103. Создание DDL-триггера уровня БД, обрабатывающего группу
событий DLL_ DATABASE_ LEVEL_ EVENTS
После выполнения сценария на рис. 13.104 в таблицу SERVER_EVENT_LOG добавится три строки, соответствующие выполнению трех DDL-операторов CREATE TABLE, ALTER TABLE и DROP TABLE.
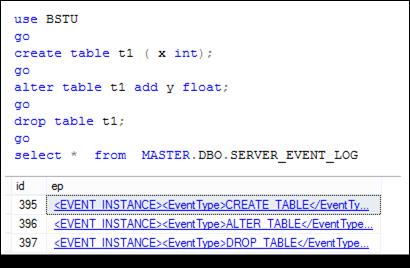
Рис. 13.104. Строки, добавляемые в таблицу SERVER_ EVENT_ LOG в результате выполнения триггера DDL_DB при создании, изменении и удалении таблиц
Как и в случае триггера уровня сервера, в триггере уровня БД функция EVENTDATA формирует XML-структуру, описывающую обрабатываемое триггером событие (рис. 13.105).
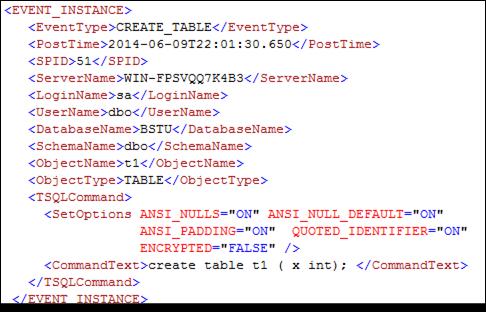
Рис. 13.105. Описание события CREATE_ TABLE в XML-структуре,
формируемой функцией EVENTDATA
Обратите внимание на несколько новых элементов в XML-структуре (рис. 13.105): UserName – имя пользователя БД, SchemaName – имя схемы БД, ObjectName и ObjectType – имя и тип объекта БД.
В примере на рис. 13.106 триггер с именем DLL_DB_DROP_TABLE делает невозможным удаление таблицы с именем TEACHER.
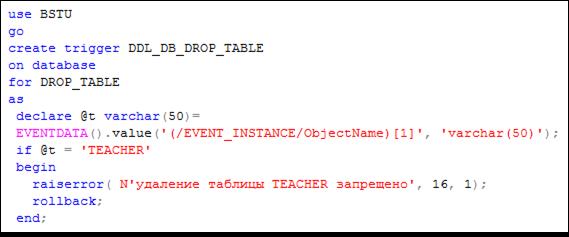
Рис. 13.106. Пример триггера уровня БД, запрещающего удалять таблицу
с именем TEACHER
Обратите внимание на следующее: 1) для выбора значения элемента ObjectName из XML-структуры, сформированной функцией EVENTDATA, применяется метод VALUE, принципы использования которого будут описаны позже; 2) для формирования сообщения об ошибке применяется встроенная функция RAISERROR; 3) для отмены выполнения оператора DROP TABLE осуществляется откат с помощью оператора ROLLBACK; 4) в результате выполнения триггера (рис. 13.106) формируется системное сообщение с номером 50 000 и сообщение, указанное в функции RAISERROR (рис. 13.107).
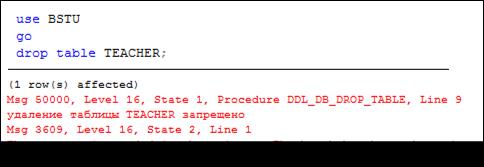
Рис. 13.107. Сообщение, формируемое триггером DDL_ DB_ DROP_ TABLE (рис. 13.106) при попытке удаления таблицы с именем TEACHER
Удаление DDL-триггеров. Удалить DDL-триггеры можно с помощью оператора DROP TRIGGER (рис. 13.108). При этом следует указывать уровень действия удаляемого триггера (ON ALL SERVER или ON DATABASE).
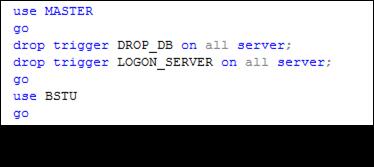
Рис. 13.108. Пример сценария, удаляющего DDL-триггеры
DML-триггеры
Каждый DML-триггер связан с таблицей или представлением и предназначен для обработки одного или нескольких событий, соответствующих трем операторам, изменяющим содержимое таблицы: INSERT, UPDATE и DELETE. MSS поддерживает два типа DML-триггеров: AFTER и INSTEAD OF.
AFTER-триггеры. Триггеры типа AFTER исполняются после выполнения оператора, вызвавшего соответствующее событие. На рис. 13.109 представлен сценарий, создающий три триггера с именами: AUD_AFTER_INSERT, AUD_AFTER_DELETE и AUD_AFTER_UPDATE.
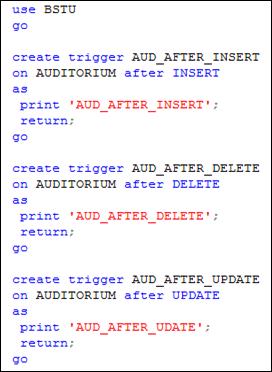
Рис. 13.109. Сценарий, создающий три DML-триггера
Обратите внимание (рис. 13.109) при создании триггера указывается: 1) имя таблицы (после ключевого слова ON), с которой этот триггер связан; 2) событие, обработку которого осуществляет триггер.
На рис. 13.110–13.112 представлены примеры сценариев, выполнение которых приводит к вызову и исполнению триггеров, созданных сценарием на рис. 13.109. Следует обратить внимание на то, что DML-триггеры являются триггерами операторного типа. Триггеры операторного типа вызываются один раз для каждого оператора, генерирующего соответствующее событие, независимо от количества строк таблицы, обработанных этим оператором. Например, оператор INSERT в сценарии на рис. 13.110 добавляет две строки в таблицу AUDITORIUM. При этом триггер с именем AUD_AFTER_INSERT выполняется только один раз. Аналогично при изменении и удалении строк (рис. 13.111, 13.112) осуществляется однократный вызов соответствующих триггеров.

Рис. 13.110. Выполнение триггера с именем AUD_ AFTER_ INSERT
после добавления строк в таблицу AUDITORIM
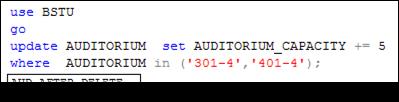
Рис. 13.111. Выполнение триггера с именем AUD_ AFTER_ UPDATE
после изменения строк в таблице AUDITORIM

Рис. 13.112. Выполнение триггера с именем AUD_ AFTER_ DELETE
после удаления строк в таблице AUDITORIM
Один AFTER-триггер может реагировать на несколько событий. В этом случае после ключевого слова AFTER должны быть перечислены все необходимые события.
На рис. 13.113 приведен сценарий, создающий AFTER-триггер с именем AUD_AFTER. Этот триггер будет вызван после выполнения одного из операторов INSERT, UPDATE или DELETE.
В рамках выполнения триггера разработчику доступны две псевдотаблицы с именами INSERTED и DELETED. В зависимости от типа события, активизировавшего триггер, содержимое таблиц разное.
Событие INSERT приводит к тому, что в таблицу INSERTED помещаются строки, добавленные оператором INSERT, вызвавшим это событие. При этом таблица DELETED остается пустой.
При событии DELETE в таблицу DELETED копируются удаленные строки, а таблица INSERTED остается пустой.
При изменении строк таблицы с помощью оператора UPDATE заполняются обе псевдотаблицы. При этом INSERTED содержит обновленные версии строк, а таблица DELETED версию строк до их изменения.
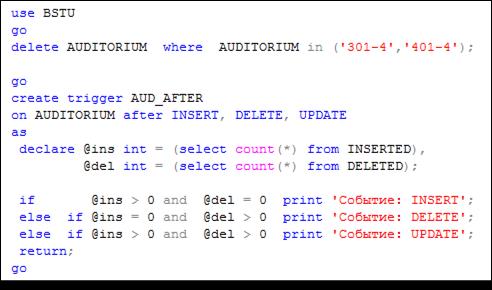
Рис. 13.113. Создание AFTER-триггера, реагирующего
на все DML-события таблицы AUDITORIUM
Триггер, созданный в сценарии на рис. 13.113, с помощью содержимого псевдотаблиц INSERTED и UPDATED определяет тип события, вызвавшего данный триггер, и формирует соответствующее сообщение в стандартный поток вывода.
Сценарий на рис. 13.114 демонстрирует работу триггера AUD_AFTER (рис. 13.113). Обратите внимание: независимо от триггера AUD_AFTER, выполняются триггеры AUD_AFTER_INSERT, AUD_AFTER_DELETE и AUD_AFTER_UPDATE, созданные ранее (рис. 13.109). С одной таблицей или представлением могут быть связаны несколько триггеров.
Как любой объект БД, триггер может быть изменен с помощью DDL-оператора ALTER. На рис. 13.115 представлен сценарий изменяющий триггеры AUD_AFTER_INSERT, AUD_AFTER_DELETE и AUD_AFTER_UPDATE. После изменения каждый триггер будет формировать результирующий набор, содержащий объединение строк таблиц INSERTED и DELETED.
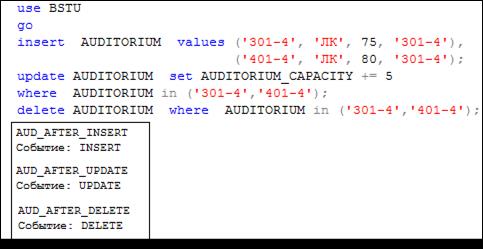
Рис. 13.114. Выполнение триггеров, созданных в сценариях
на рис. 13.109 и 13.113
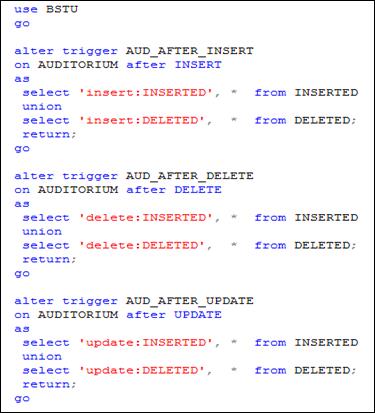
Рис. 13.115. Изменение триггеров AUD_AFTER_INSERT, AUD_AFTER_UPDATE и AUD_AFTER_DELETE
На рис. 13.116 представлен сценарий, активизирующий измененные триггеры (рис. 13.115), а также сформированные ими результирующие наборы.
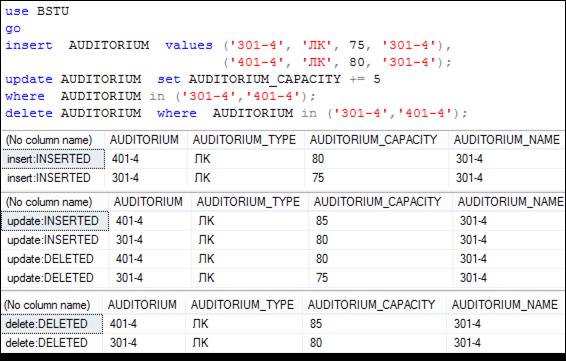
Рис. 13.116. Результаты выполнения триггеров AUD_AFTER_INSERT, AUD_AFTER_UPDATE и AUD_AFTER_DELETE
Важной особенностью AFTER-триггера является то, что он вызывается после выполнения активизирующего его оператора. Поэтому, если оператор нарушает ограничение целостности, то возникшая ошибка не допускает выполнения этого оператора и соответствующих триггеров (рис. 13.117).
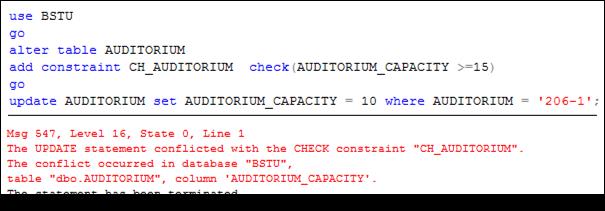
Рис. 13.117. Блокировка вызова соответствующего AFTER-триггера
при нарушении DML-оператором ограничения целостности
В AFTER-триггере допускается применения функции RAISERROR и TCL-операторов COMMIT и ROLLBACK (рис. 13.118, 13.119).
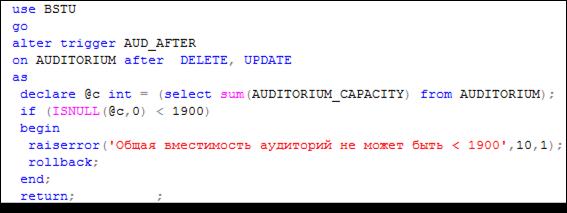
Рис. 13.118.Вызов системной функции RAISERROR и применение TCL-операторов COMMIT и ROLLBACK в AFTER-триггере
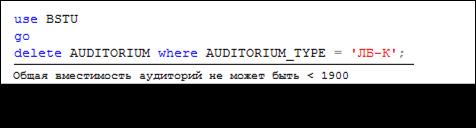
Рис. 13.119. Сообщение об ошибке и аварийном завершении транзакции
в результате выполнения триггера AUD_ AFTER (рис. 13.118)
INSTEAD OF-триггеры. Триггеры типа INSTEAD OF исполняются вместо оператора, вызвавшего соответствующее событие. На рис. 13.120 представлен сценарий, создающий INSTEAD OF-триггер с именем AUDTYPE_INSTEAD.
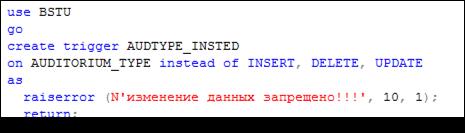
Рис. 13.120. Сценарий, создающий INSTEAD OF-триггер
Сценарий на рис. 13.121 демонстрирует выполнение INSTEAD OF-триггера, созданного с помощью сценария, представленного на рис. 13.120.
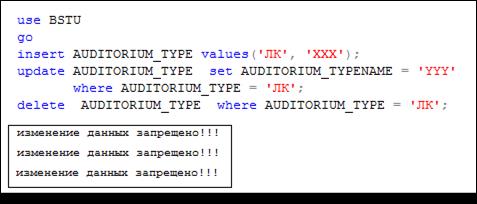
Рис. 13.121. Сценарий, демонстрирующий выполнение INSTEAD OF-триггера AUDTYPE_ INSTEAD (рис. 13.120)
Следует отметить, для таблицы или представления допускается создание только по одному INSTEAD OF-триггеру, реагирующему на каждое событие. Кроме того, выполнение INSTEAD OF-триггера предшествует проверке установленных для таблицы ограничений целостности.
Порядок выполнения DML-триггеров. Если для таблицы или представления созданы INSTEADOF и AFTER-триггеры, реагирующие на одно и то же событие, то выполниться только INSTEAD OF- триггер.
Для нескольких AFTER-триггеров, реагирующих на одно и то же событие, имеется возможность частично упорядочить их выполнение с помощью системной процедуры SP_SETTRIGGERORDER.
Процедура SP_SETTRIGGERORDER принимает три параметра: имя триггера (triggername), позиция в последовательности вызова (order) и тип события (stmttype).
Параметр order может принимать только два значения: First и Last. При этом с помощью значения First обозначается первая позиция триггера, а с помощью Last – последняя. Параметр stmttype может принимать одно из трех следующих значений: INSERT, UPDATE и DELETE.
Таким образом, для заданного с помощью параметра stmttype события с помощью процедуры SP_SETTRIGGERORDER могут быть указаны только первый и последний триггеры таблицы. Порядок выполнения других триггеров, реагирующих на это же событие той же таблицы, не гарантируется.
В сценарии на рис. 13.122 создается три AFTER-триггера, реагирующих на событие UPDATE таблицы AUDITORIUM. Вместе с триггерами, созданными ранее, общее количество AFTER-триггеров таблицы AUDITORIUM составляет пять.
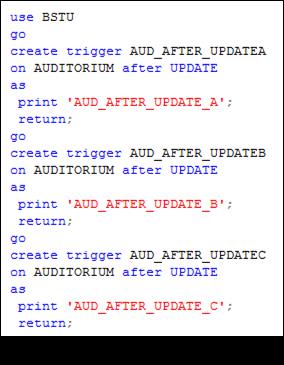
Рис. 13.122. Создание трех AFTER-триггеров, реагирующих на событие UPDATE таблицы AUDITORIUM
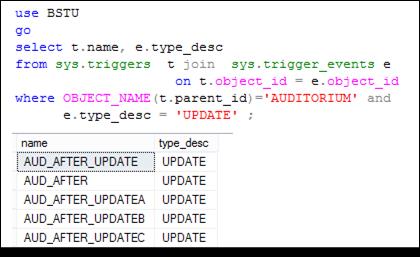
Рис. 13.123. Получение перечня триггеров БД С помощью
системных представлений SYS. TRIGGERS и SYS. TRIGGER_ EVENTS
Сценарий на рис.13.124 дважды вызывает функцию SP_SETTRIGGERORDER. В первом случае триггер AUD_AFTER_UPDATEB устанавливается первым в порядке вызова при событии UPDATE таблицы AUDITORIUM. Второй вызов SP_SETTIRGGERORDER делает триггер AUD_AFTER_UPDATEA замыкающим.

Рис. 13.124. Порядок вызова триггеров AUD_ AFTER_ UPDATEB и AUD_ AFTER_ UPDATEB при событии UPDATE таблицы AUDITORIUM
На рис. 13.125 приведен пример сценария, демонстрирующего порядок выполнения триггеров, реагирующих на событие UPDATE таблицы AUDITORIUM.
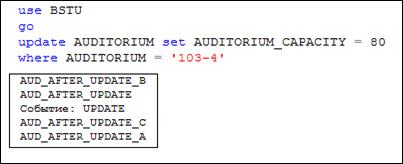
Рис. 13.125. Пример, демонстрирующий порядок вызова AFTER-триггеров,
реагирующих на событие UPDATE таблицы AUDITORIM
Удаление DML-триггеров. Как и DDL-триггеры, DML- триггеры могут быть удалены с помощью оператора DROP TRIGGER (рис.13.126). Обратите внимание: имена DML-триггеров в рамках одной БД уникальны и поэтому в операторе DROP не требуется указания таблицы с которой связан удаляемый триггер.

Рис. 13.126. Удаление DML-триггеров
Глава 14. ПРИМЕНЕНИЕ XML
Стандарт XML
XML (Extensible Markup Language) – расширяемый язык разметки, разработка которого началась в 1996 г. консорциумом W3C [6]. В 1998 г. была выпущена первая спецификация XML 1.0. Эта версия постоянно совершенствуется, на сегодняшний день действует ее третья редакция. Параллельно идет работа над новой версией XML 1.1, но окончательный ее выпуск постоянно откладывается.
Язык XML задает общие правила, по которым создаются теги (элементы языка разметки, предназначенные для разделения данных в текстовых файлах) и оформляются XML-документы. При этом XML-документ представляет собой текстовый файл, содержащий данные, разделенные (часто говорят – размеченные) тегами, составленными по правилам XML и расположенными в правильном (в соответствии с правилами XML) порядке. Совокупность XML-тегов, предназначенных для разметки документов определенного типа называют словарями XML или XML-реализациями. Например, XHTML является XML-реализацией языка гипертекстовой разметки текста, CML – реализация языка записи химических формул, а VoxML – языка записи звуков.
На рис. 14.1 представлен пример XML-документа, содержащего информацию о двух преподавателях кафедры.

Рис.14.1. Пример XML-документа
В XML-документе (рис. 14.1) применяется три тега с именами: Кафедра, Преподаватель и Дисциплина. Тег Кафедра имеет один атрибут с именем код, тег Преподаватель – четыре атрибута (фамилия, имя, отчество и должность), а тег Дисциплина не имеет атрибутов.
Каждый записанный в XML-документе тег представляет элемент этого документа. Например, первый тег Преподаватель задает элемент, описывающий информацию о преподавателе с фамилией Пацей.
Обратите внимание на следующее: 1) XML-документ начинается специальным тегом с именем ? xml (называется – объявление XML), содержащим информацию о версии XML и используемой кодировке; 2) каждый элемент начинается открывающим тегом и завершается закрывающим тегом (имя начинается с наклонной); 3) между открывающим и закрывающим тегами некоторых элементов (например, соответствующим тегам Преподаватель) могут находиться другие теги; 4) XML-документ является содержимым единственного элемента (в примере соответствует тегу Кафедра), называемого корневым; 5) применение XML-формата влечет к значительному увеличению избыточности данных; 6) XML-формат позволяет создавать самодокументированные данные.
Для более подробного знакомства с языком XML рекомендуется изучить пособие [7].
Обмен XML-данными
XML-формат часто используется для обмена данными между компонентами одной информационной системы или на межсистемном уровне. Здесь проявляются главные преимущества XML: 1) все программные платформы «понимают» XML одинаково; 2) практически все программные системы имеют встроенные механизмы, позволяющие эффективно обрабатывать XML-данные.
Для разработчиков программного обеспечения важными являются две задачи: преобразование табличных данных в XML-структуры; преобразование XML-структур в строки реляционной таблицы.
14.2.1. Преобразование реляционных данных в XML-структуры
Для преобразования результата SELECT-запроса в формат XML в операторе SELECT применяется секция FOR XML. При этом можно использовать один из четырех режимов: RAW, AUTO, PATH и EXPLICIT. В рамках этого пособия рассматриваются только первые три режима, для знакомства с принципами применения режима EXPLICIT рекомендуется изучить издание [5].
14.2.1.1. Режим RAW. По умолчанию в режиме RAW в результате SELECT-запроса создается XML-фрагмент, состоящий из последовательности элементов с именем row. Каждый элемент row соответствует строке результирующего набора, имена его атрибутов совпадают с именами столбцов результирующего набора (из списка SELECT), а значения атрибутов равны их значениям.
На рис. 14.2 представлен пример SELECT-запроса, формирующего результирующий набор в реляционном виде. В SELECT-запросе на рис. 14.3 применена инструкция FOR XML RAW, позволяющая получить результирующий набор в виде XML-фрагмента в режиме RAW.
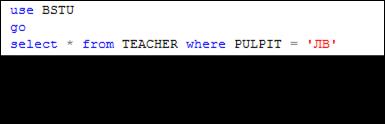
Рис. 14.2. Результат SELECT-запроса в реляционном виде

Рис. 14.3. Применение инструкции FOR XML RAW
Обратите внимание: 1) результатом выполнения SELECT-запроса является XML-фрагмент, а не XML-документ; 2) данные из столбцов таблицы представляются в виде значений атрибутов (такая форма представления данных называется атрибутной).
Если в SELECT-списке запроса указать столбцы, то сформированные элементы имеют только соответствующие им столбцы (рис. 14.4).

Рис. 14.4. XML-элементы, имеющие атрибуты, соответствующие столбцам, указанным в SELECT-списке запроса
Для того чтобы изменить стандартное имя элемента raw на заданное, достаточно его указать в скобках после ключевого слова RAW (рис. 14.5).

Рис. 14.5. Формирование имени элемента, соответствующего строке
результирующего набора, после ключевого слова RAW
Построить корневой элемент для XML-фрагмента можно с помощью ключевого слова ROOT, которое может быть применено в инструкции FOR XML (рис. 14.6).

Рис. 14.6. Создание корневого элемент с помощью ключевого слова ROOT
Если в сформированных XML-элементах требуется, чтобы имена атрибутов отличались от имен столбцов исходных таблиц, следует в SELECT-списке для столбцов указать псевдонимы, которые будут использованы в качестве имен атрибутов (рис. 14.7).

Рис. 14.7. Использование псевдонимов столбцов в качестве имен атрибутов
Обратите внимание, что во всех приведенных выше примерах в результате использования режима RAW (рис. 14.3–14.7) формируется результирующий набор в атрибутном виде (данные – значение атрибута). Для того чтобы сформировать результирующий набор в альтернативном, называемом элементном виде, необходимо в инструкции FOR XML применить ключевое слово ELEMENTS (рис. 14.8).
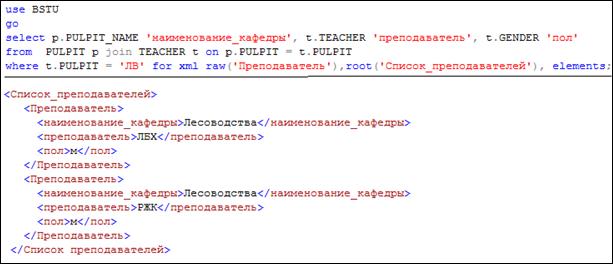
Рис. 14.8. Использование ключевого слова ELEMENTS для формирования
результирующего набора в элементном виде
Обратите внимание (рис. 14.8): 1) имена столбцов (или их псевдонимы) являются именами вложенных элементов; 2) данные представлены как содержимое элементов; 3) применение JOIN в секции FROM оператора SELECT никак не влияет на структуру формируемого XML-фрагмента.
14.2.1.2. Режим AUTO. Результат, полученный в режиме AUTO для простых SELECT-запросов, похож на результат, полученный в режиме RAW. Основное отличие – в качестве имени элемента, соответствующего строке исходной таблицы, используется ее имя (рис. 14.9).
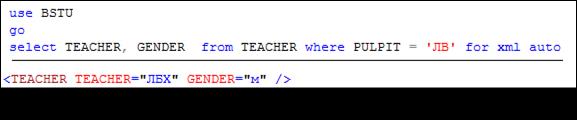
Рис. 14.9. Применение инструкции FOR XML AUTO
Особенность режима AUTO проявляется в многотабличных запросах. В этом случае режим AUTO позволяет построить XML-фрагмент с применением вложенных элементов. Причем порядок вложенности основывается на порядке столбцов (слева направо), указанных в SELECT-списке.
На рис. 14.10 и 14.11 приведены примеры многотабличных SELECT-запросов, формирующих результирующие наборы в режиме AUTO.
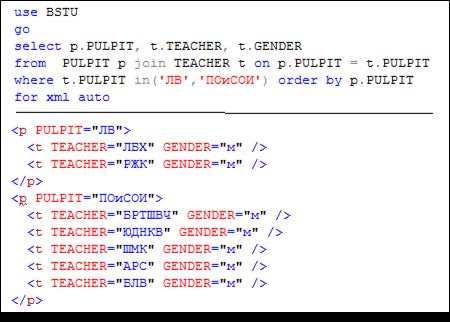
Рис. 14.10. Формирование XML-фрагментов с вложенными элементами
для многотабличных запросов
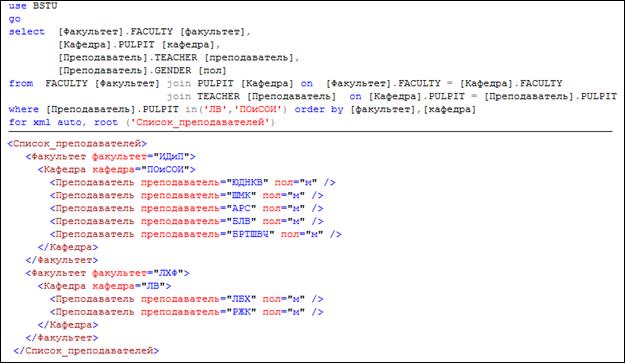
Рис. 14.11. Три уровня вложенности XML-элементов
Как и в режиме RAW, здесь допускается применение ключевых слов ROOT (указывает имя корневого элемента) и ELEMENTS (формирование элементного вида XML-фрагмента). На рис. 14.11 используется ROOT для формирования корневого элемента XML-фрагмента в атрибутной форме. На рис. 14.12 применяется ROOT и ELEMEMTS.
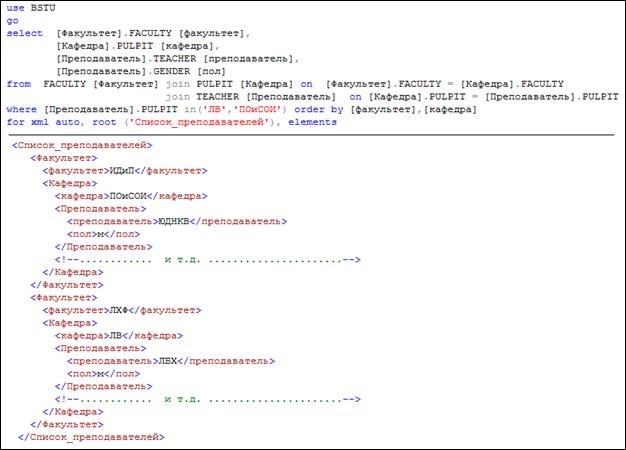
Рис. 14.12. Формирование XML-фрагмента в элементной форме
с помощью ключевого слова ELEMENTS
14.2.1.3. Режим PATH. Режим PATH позволяет разработчику наиболее полным образом управлять процессом формирования XML-структуры. Каждый столбец конфигурируется независимо с помощью заданного в формате XPATH [7] имени псевдонима этого столбца. В таблице 14.1 приведено несколько шаблонов, которые могут быть использованы при записи псевдонимов столбцов в режиме PATH.
Если псевдонимы задавать традиционным способом (это соответствует первому шаблону в таблице 14.1), то сформируется XML-фрагмент, состоящий из элементов с именем row, соответствующих строкам результирующего набора. Каждый row-элемент включает в себя все значения столбцов одной строки в элементной форме. При этом элементы будут иметь имена, совпадающие с заданными в SELECT-списке псевдонимами (рис. 14.13).
Таблица 14.1
Дата: 2019-02-25, просмотров: 431.