Применение параллельных вычислительных систем (ПВС) и суперкомпьютеров является стратегическим направлением развития вычислительной техники [1]. Это вызвано не только принципиальным ограничением максимально возможного быстродействия обычных последовательных ЭВМ, но и практически постоянным наличием вычислительных задач, для решения которых возможностей существующих средств вычислительной техники всегда оказывается недостаточно.
Выход из создавшегося положения напрашивался сам собой. Если один компьютер нс справляется с решением задачи за нужное время, то попробуем взять два, три, десять компьютеров и заставим их одновременно работать над различными частями общей задачи, надеясь получить соответствующее ускорение.
Объединение компьютеров в единую систему повлекло за собой множество следствий. Чтобы обеспечить отдельные компьютеры работой, необходимо исходную задачу разделить на фрагменты, которые можно выполнять независимо друг от друга. Так стали возникать специальные численные методы, допускающие возможность подобного разделения. Чтобы описать способ одновременного выполнения разных фрагментов задачи на разных компьютерах, потребовались специальные языки программирования, специальные операционные системы и т. д. Постепенно такие слова, как «одновременный», «независимый» и похожие на них стали заменяться одним словом «параллельный».Всё это синонимы, если иметь в виду описание каких-то процессов, действий, фактов, состояний, не связанных друг с другом. Ничего другого слова «параллелизм» и «параллельный» в областях, относящихся к компьютерам, не означают.
Существует множество способов организации параллельно работающих вычислительных систем [1, 2]. Параллельность вычислений, когда в один и тот же момент выполняется одновременно несколько операций обработки данных, осуществляется в основном за счет введения избыточности функциональных устройств (многопроцессорности) [3]. В этом случае можно достичь ускорения процесса решения вычислительной задачи, если осуществить разделение применяемого алгоритма на информационно независимые части и организовать выполнение каждой части вычислений на разных функциональных устройствах (процессорах, ядрах, арифметико-логических устройствах и т. д.). Подобный подход позволяет выполнять необходимые вычисления с меньшими затратами времени по сравнению с последовательной организацией вычислений. Возможность получения максимального ускорения ограничивается (по крайней мере, в принципе) только числом имеющихся процессоров и количеством параллельно выполняющихся частей в вычислениях.
Рассматривая проблемы организации параллельных вычислений, следует различать следующие известные режимы выполнения независимых частей программы:
• многозадачный режим (режим разделения времени), при котором для выполнения нескольких процессов используется единственный процессор. Этот режим является псевдопараллельным: активным (исполняемым) может быть один единственный процесс, а все остальные процессы находятся в состоянии ожидания своей очереди. Применение режима разделения времени может повысить эффективность организации вычислений (например, если один из процессов не может выполняться из-за ожидания вводимых данных, то процессор будет задействован для выполнения другого, готового к исполнению процесса). Кроме того, в данном режиме проявляются многие эффекты параллельных вычислений (необходимость взаимоисключения и синхронизации процессов и др.), и как результат этот режим может быть использован при начальной подготовке параллельных программ;
• параллельные вычисления, когда в один и тот же момент может выполняться несколько команд обработки данных. Такой режим вычислений может быть обеспечен не только при использовании нескольких процессоров, но и при помощи конвейерных и векторных обрабатывающих устройств;
• распределенные вычисления - термин, который обычно применяют для указания параллельной обработки данных, когда используется несколько обрабатывающих устройств, достаточно удаленных друг от друга, в которых передача данных по линиям связи приводит к существенным временным задержкам. Как результат эффективная обработка данных при таком способе организации вычислений возможна только для параллельных алгоритмов с низкой интенсивностью потоков межпроцессорных передач данных. Перечисленные условия являются характерными, например, при организации вычислений в многомашинных вычислительных комплексах, образуемых объединением нескольких отдельных ЭВМ с помощью каналов связи локальных или глобальных информационных сетей.
При разработке параллельных алгоритмов решения задач принципиальным моментом является анализ эффективности использования параллелизма [4], состоящий обычно в оценке получаемого ускорения процесса вычисления (сокращения времени решения задачи). Формирование подобных оценок ускорения может осуществляться применительно к выбранному вычислительному алгоритму (оценка эффективности распараллеливания конкретного алгоритма). Другой важный подход может состоять в построении оценок максимально возможного ускорения процесса получения решения задачи конкретного типа (оценка эффективности параллельного способа решения задачи).
Собственно параллелизм предполагает [5] наличие нескольких (п) устройств для обработки данных и алгоритм, позволяющий производить на каждом независимую часть вычислений. В конце обработки частичные данные собираются вместе для получения окончательного результата. В этом случае (пренебрегая накладными расходами на получение и сохранение данных) можно получить ускорение процесса в п раз. Далеко не каждый алгоритм может быть успешно распараллелен таким способом (естественным условием распараллеливания является вычисление независимых частей выходных данных по одинаковым, или сходным, процедурам; итерационность или рекурсивность вызывают наибольшие проблемы при распараллеливании).
Архитектура параллельных компьютеров с самого начала их создания и применения развивалась в самых различных направлениях. Большое разнообразие вычислительных систем породило естественное желание ввести для них какую-то классификацию. Эта классификация должна однозначно относить ту или иную вычислительную систему к некоторому классу, который, в свою очередь, должен достаточно полно се характеризовать. Таких попыток предпринималось множество. Одна из первых классификаций, ссылки на которую наиболее часто встречаются в литературе, была предложена М. Флинном в конце 60-х годов прошлого века. Она базируется на понятиях двух потоков: команд и данных. На основе числа этих потоков выделяется четыре класса архитектур.
1. ОКОД (SISD - Single Instruction Single Data) - единственный поток команд и единственный поток данных. По сути - это классическая машина фон Неймана. К этому классу относятся все однопроцессорные системы.
2. ОКМД (SIMD - Single Instruction Multiple Data) - единственный поток команд и множественный поток данных. Типичными представителями являются матричные компьютеры, в которых все процессорные элементы выполняют одну и ту же программу, применяемую к своим (различным для каждого процессора) локальным данным. Иногда к этому классу относят и векторно-конвейерные компьютеры, если каждый элемент вектора рассматривать как отдельный элемент потока данных. В настоящее время этот класс пополнился графическими процессорами, позволившими существенно увеличить достижимый порог производительности при сравнительно невысокой стоимости.
3. МКОД (MISD - Multiple Instruction Single Date) - множественный поток команд и единственный поток данных. Автор классификации не смог привести ни одного примера реально существующей системы, работающей на этом принципе. Представителями такой архитектуры можно считать высоконадежные вычислительные системы с дублированием процессов обработки одних и тех же данных на нескольких вычислительных устройствах с последующим мажоритарным выбором результатов решения задачи.
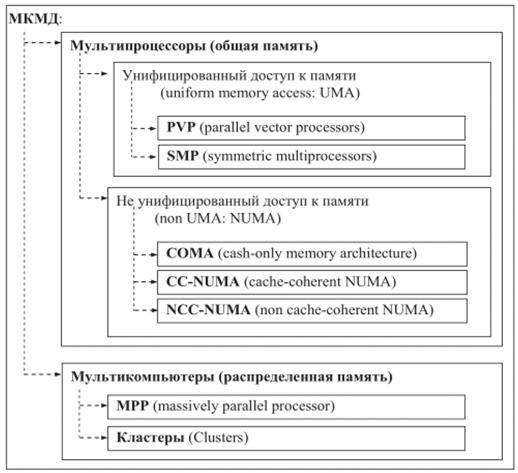
4. МКМД (MIMD - Multiple Instruction Multiple Date) - множественный поток команд и множественный поток данных. Разные вычислительные устройства обрабатывают собственные данные в соответствии с собственной программой каждое. К этому классу относятся практически все современные суперкомпьютеры. Состав и структура этого класса показаны на рисунке.
Компьютеры с общей памятью (или мультипроцессоры) состоят из нескольких (как правило, одинаковых) процессоров, имеющих равно- приоритетный доступ к общей памяти с единым адресным пространством.
К этому классу относится большое количество векторно-конвейерных компьютеров, в свое время находившихся на верхушке списка самых высокопроизводительных систем. Другим типичным примером такой архитектуры являются компьютеры класса SMP (Symmetric Multi Processors), включающие в себя несколько процессоров, но одну память, комплект устройств ввода/вывода и операционную систему (другим классификатором таких систем является термин UMA - uniform memory access). Достоинством компьютеров с общей памятью является (относительная) простота программирования параллельных задач (нет необходимости заниматься организацией пересылок сообщений между процессорами с целью обмена данными), минусом - недостаточная масштабируемость (при увеличении числа процессоров
Структура класса МКМД
резко возрастает конкуренция за доступ к общим ресурсам, в первую очередь к памяти, что ограничивает суммарную производительность системы). Реальные SMP-систсмы содержат обычно не более 32 процессоров, для дальнейшего наращивания вычислительных мощностей подобных систем используется NUMA-тсхнология (non uniform memory access).
При фактическом различии механизмов доступа к собственной памяти и памяти других процессоров в NUMA-системах реализуется виртуальная адресация, позволяющая пользовательским программам рассматривать всю (физически) распределенную между процессорами память как единое адресное пространство. Недостатками NUMA-компыо- теров являются значительная разница времени обращения к собственной (локальной) памяти данного процессора и к памяти сторонних процессоров, а также проблема когерентности кэша (cache coherence problem) - в случае сохранения процессором П1 некоего значения в ячейке N1.
При последующей попытке прочтения данных из той же ячейки N1 процессором П2 последний получит значение, которое может не совпадать с истинным значением переменной, если кэш процессора П1 еще не ‘сброшен' в память (о чем процессор П2 «знать» не обязан). Для решения проблемы когерентности (соответствия, одинаковости) кэша предложена и реализована архитектура ccNUMA (cache coherent NUMA), позволяющая (прозрачными для пользователя средствами) достигать соответствия кэшей процессоров (что требует дополнительных ресурсов и соответственно снижает производительность).
Для всех видов как векторно-конвейерных, так и *иМА-архитектур увеличение количества процессоров связано с непропорционально большим ростом стоимости механизмов обеспечения «прозрачности» доступа к любому участку «общей» памяти. В силу этого ни одна система с общей памятью в настоящее время уже не входит в список 500 суперкомпьютеров (хотя ранее, до 2003-го года, входили и даже составляли до половины всего списка).
Другим стремительно развивающимся направлением развития суперкомпьютеров являются системы с распределенной памятью. Идея построения вычислительных систем данного класса очень проста: берется какое-то количество вычислительных узлов, которые объединяются друг с другом некоторой коммуникационной средой. Каждый вычислительный узел имеет один или несколько процессоров и свою собственную локальную память, разделяемую этими процессорами. Распределенность памяти означает то, что каждый процессор имеет непосредственный доступ только к локальной памяти своего узла. Доступ к данным, расположенным в памяти других узлов, выполняется дольше и другими более сложными способами. В последнее время в качестве узлов все чаще и чаще используют полнофункциональные компьютеры, содержащие, например, и собственные внешние устройства. Коммуникационная среда может специально проектироваться для данной вычислительной системы либо быть стандартной сетью, доступной на рынке.
Преимуществ у такой схемы организации параллельных компьютеров много. В частности, покупатель может достаточно точно подобрать конфигурацию в зависимости от имеющегося бюджета и своих потребностей в вычислительной мощности. Соотношение цена/произ- водитсльность у систем с распределенной памятью ниже, чем у компьютеров других классов. И главное, такая схема дает возможность практически неограниченно наращивать число процессоров в системе и увеличивать ее производительность. Большое число подключаемых
процессоров даже определило специальное название для систем данного класса - компьютеры с массовым параллелизмом, или массивнопараллельные компьютеры.
Основным преимуществом таких систем является масштабируемость (в зависимости от класса решаемых задач и бюджета может быть реализована система с числом узлов от нескольких десятков до нескольких тысяч). Различными производителями было создано большое количество массивно-параллельных суперкомпьютеров, в том числе Cray серии ТЗ, IBM SP, Intel Paragon и другие. Однако сверхвысокая стоимость промышленных массивно-параллельных компьютеров не позволяла применить их в любой области, нуждающейся в системах высокой производительности. Это привело к развитию вычислительных кластеров.
Технологической основой развития кластеризации стали широкодоступные и относительно недорогие микропроцессоры и коммуникационные (сетевые) технологии, появившиеся в свободной продаже в 1990-х годах. Вычислительный кластер представляет собой совокупность вычислительных узлов (от десятков до сотен тысяч), управляющего компьютера и файл-сервера.
Вычислительные узлы и управляющий компьютер обычно объединяют как минимум две, обычно независимые, сети: управляющая сеть (служит целям управления вычислительными узлами) и (часто более производительная) коммуникационная сеть (непосредственный обмен данными между исполняемыми на узлах процессами). Управляющий узел обычно имеет выход в Интернет для доступа удаленных пользователей к ресурсам кластера. Файл-сервер (в небольших кластерах его функции выполняет управляющий компьютер) выполняет функции хранения программ пользователя. Администрирование кластера осуществляется с управляющего узла (или посредством удаленного доступа), пользователи имеют доступ к ресурсам кластера исключительно через управляющий компьютер (в соответствии с присвоенными администратором правами).
Дата: 2019-02-19, просмотров: 417.