Требования к идеальной системе управления распределенными базами данных.
• Прозрачность относительно местоположения. Пользователь не должен беспокоиться о том, где физически располагаются данные. СУБД должна представлять все данные так, как если бы они были локальными, и отвечать за сохранение этой "иллюзии".
• Гетерогенные системы. СУБД должна работать с данными, которые хранятся на различных системах с разной архитектурой и производительностью, включая персональные компьютеры, рабочие станции, серверы ЛВС, мини-компьютеры и мэйнфреймы.
• Прозрачность относительно сети. За исключением различий в производительности, СУБД должна работать одинаково в разнородных сетях, от высокоскоростных ЛВС до низкоскоростных телефонных линий.
• Распределенные запросы. Пользователь должен иметь возможность объединять данные из любых таблиц распределенной базы данных, даже если эти таблицы физически расположены в различных системах.
• Распределенные изменения. Пользователь должен иметь возможность изменять данные в любой таблице, на доступ к которой у него есть необходимые привилегии, независимо от того, находится ли эта таблица в локальной или удаленной системе.
• Распределенные транзакции. СУБД должна выполнять транзакции (используя инструкции COMMIT и ROLLBACK), выходящие за границы одной вычислительной системы, и поддерживать целостность распределенной базы данных даже при возникновении отказов как в отдельных системах, так и в сети в целом. Безопасность, СУБД должна обеспечивать защиту всей распределенной базы данных от несанкционированного доступа.
• Универсальный доступ. СУБД должна обеспечивать единую методику доступа ко всем данным предприятия.
Ни одна из существующих распределенных СУБД по своим возможностям не соответствует этому идеалу. Имеются препятствия, из-за которых с трудом реализуются даже простые формы управления распределенными базами данных. К ним относятся:
• Низкая производительность. В централизованной базе данных время доступа к данным составляет несколько миллисекунд, а скорость их передачи — несколько миллионов символов в секунду. Даже в высокоскоростной локальной сети время доступа увеличивается до десятых долей секунды, а скорость передачи данных падает до 100000 символов в секунду или даже еще ниже. Время доступа к данным по телефонной линии может занимать секунды или минуты, а максимальная пропускная способность уменьшается до нескольких тысяч символов в секунду. Эта огромная разница в быстродействии может резко замедлять доступ к удаленным данным.
• Проблема сохранения целостности данных. Чтобы при выполнении распределенных транзакций соблюдался принцип "все или ничего", необходимо активное взаимодействие двух или более независимых СУБД, работающих в различных вычислительных системах. При этом должны использоваться специальные протоколы двухфазного завершения транзакций, которые приводят к повышению сетевого трафика и длительной блокировке тех частей баз данных, которые участвуют в распределенной транзакции.
• Проблема, связанная с планом выполнения статического SQL. Встроенная статическая инструкция SQL компилируется и сохраняется в базе данных в виде плана выполнения. Когда запрос объединяет данные из двух или более баз данных, в какой из них следует хранить план выполнения? Может, необходимо иметь два или более согласованных плана? А если изменяется структура одной базы данных, то как можно изменить план выполнения в другой базе данных? Применение динамического SQL в сетевой среде для решения этой проблемы практически всегда ведет к неприемлемому снижению производительности приложений из-за повышения сетевого трафика и многочисленных задержек.
• Проблема оптимизации. Когда доступ к данным осуществляется по сети, обычные правила оптимизации инструкций SQL применять нельзя. Например, полное сканирование локальной таблицы может оказаться оптимальнее, чем поиск по индексу в удаленной таблице. Программа оптимизации должна знать параметры сети и, в частности, ее быстродействие. Если говорить в общем, роль оптимизации становится более важной, а ее осуществление более трудным.
• Проблема совместимости данных. В различных вычислительных системах существуют разные типы данных, и даже когда в двух системах присутствуют данные одного и того же типа, они могут иметь разные форматы. Например, в компьютерах VAX и Macintosh 16-разрядные целые числа представляются по-разному.
Для представления символов в мэйнфреймах компании IBM используется кодировка EBCDIC, а в персональных компьютерах — кодировка ASCII. В распределенной СУБД эти различия должны быть незаметны.
• Проблема хранения системных каталогов. Во время работы СУБД часто обращается к своим системным каталогам. Где в распределенной базе данных следует хранить каталог? Если он будет храниться в одной системе, то удаленный доступ к каталогу будет медленным, что может парализовать работу СУБД. Если расположить его в нескольких различных системах, то изменения в каталоге придет распространять по сети и синхронизировать.
• Оборудование от разных поставщиков. Вряд ли управление всеми данными предприятии будет осуществляться с помощью СУБД одного типа; как правило в распределенной базе данных используется несколько СУБД, что требует активной совместной работы СУБД, поставляемых конкурирующими компаниями. Но такое маловероятно.
Распределенные тупиковые ситуации. Когда в двух системах одновременно выполняются транзакции, которые пытаются осуществить доступ к заблокированным данным в другой системе, в распределенной базе данных может возникнуть тупик, хотя в каждой из двух систем тупика не будет. СУБД должна обеспечивать обнаружение глобальных тупиков в распределенной базе данных. Это требует координации усилий сетевых приложений и обычно ведет к резкому снижению производительности.
Проблема восстановления. Если в одной из систем, входящих в распределенную базу данных, произойдет сбой, то администратор этой системы должен иметь возможность запустить процедуру восстановления независимо от других вычислительных систем в сети, и восстановленная система должна быть синхронизирована с другими системами.
Контрольные вопросы
1. Перечислите основные функции ODBC для работы с системными каталогами.
2. Какие расширенные возможности(по сравнению с SQL/CLI) предоставляет ODBC?
3. Какие преимущества обеспечивает механизм управления сеансами ODBC?
4. Каким требованиям должна отвечать идеальная система управления распределенными базами данных.
Лекция 15
Дублирование таблиц
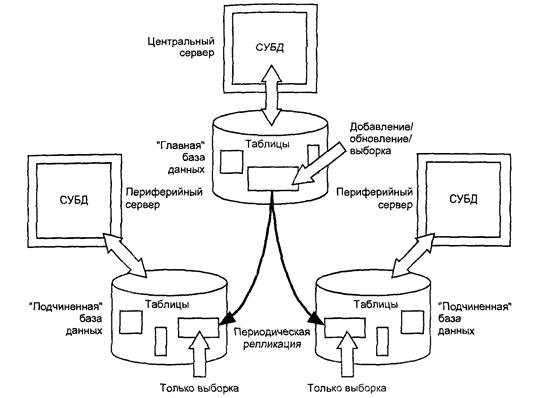
Доступ к удаленным базам данных из локальных СУБД очень удобен при выполнении небольших запросов и нерегулярном доступе к данным. Если же приложению требуется интенсивный и частый доступ к удаленной базе данных, тогда коммуникационные издержки описанной ранее схемы работы могут оказаться неприемлемыми. Когда интенсивность и частота операций удаленного доступа превышает определенный предел, более эффективным оказывается использование локальной копии удаленных данных. Многие производители СУБД предоставляют специальные средства для упрощения процесса извлечения и распространения данных. В простейшем случае содержимое таблицы извлекается из "главной" базы данных, пересылается по сети другой системе и помещается в соответствующую таблицу-реплику в "подчиненной” базе данных (рис. ). Эта процедура обычно выполняется периодически во время наименьшей загрузки системы.
Такой подход очень удобен в тех случаях, когда данные в реплицируемых таблицах изменяются редко или изменения выполняются в пакетном режиме. Предположим, например, что несколько таблиц нашей учебной базы данных, расположенные в главной системе, должны быть реплицированы в локальные базы данных. Содержимое таблицы OFFICES практически никогда не меняется. Поэтому она будет прекрасным кандидатом для репликации в рабочие базы данных дистрибьюторских центров и торговых менеджеров. После того как локальные таблицы-реплики соответствующим образом созданы и заполнены данными из главной таблицы, их можно обновлять раз в месяц или не обновлять вовсе, пока не будет открыт какой-нибудь новый офис.
Описанную стратегию репликации можно реализовать вообще без поддержки со стороны СУБД. Вы можете написать приложение со встроенным SQL, которое будет работать на мэйнфрейме и извлекать данные о ценах на товары из базы данных, помещая их в файл. Еще одна программа может пересылать этот файл в дистрибьюторские центры, где третья программа будет считывать его содержимое и генерировать соответствующие инструкции DROP TABLE, CREATE TABLE и INSERT для заполнения таблиц-реплик.
Первым шагом в направлении автоматизации этой стратегии стала разработка высокоскоростных программ для извлечения и загрузки данных. В этих утилитах, предлагаемых многими производителями современных СУБД, обычно используются специализированные низкоуровневые технологии доступа к базам данных, поэтому выборка и загрузка данных в них выполняется гораздо быстрее, чем при использовании обычных инструкций SELECT и INSERT. Позднее стали появляться аналогичные программные продукты независимых производителей. Определилась новая категория программного обеспечения, получившая название "ПО для интеграции приложений масштаба предприятия" (Enterprise Application Integration — EAI). Задачей программных продуктов этой категории является интеграция различных компьютерных систем, СУБД, других программных комплексов и файлов различных форматов. Связь нескольких СУБД — это лишь малая часть комплексного решения, предлагаемого ты личной EAI-системой, исключительно гибко настраиваемой для нужд конкретного предприятия. Обычно EAI-системы включают графический интерфейс для определения процедуры извлечения данных, набор средств для переформатирования данных в соответствии с требованиями системы-получателя и подсистему для пересылки данных по сети, включающую возможность временного сохранения данных до и после пересылки, а также утилиты для управления всем процессом и его мониторинга.
Двунаправленная репликация
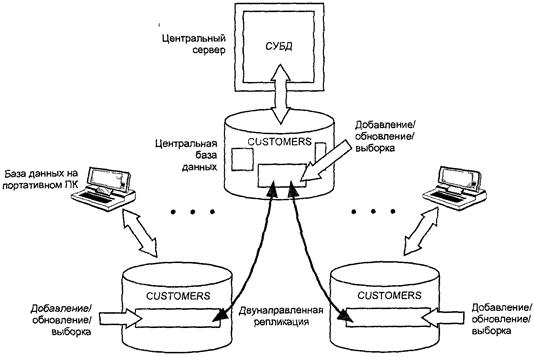
В простейшем случае (см. рис.) таблица связана с каждой своей репликой строгим соотношением "главная/подчиненная". Центральная (главная) таблица содержит "реальные" данные. Это всегда самая последняя информация, и она должна обновляться приложениями только в главной таблице. Копии периодически обновляются в пакетном режиме самой СУБД. В промежутках между обновлениями их информация может оказаться несколько устаревшей, но если база данных сконфигурирована таким образом, значит, это приемлемая плата за преимущество использования локальных копий данных. Приложениям не разрешается обновлять данные, содержащиеся в копиях реплицированной таблицы. В случае подобной попытки СУБД генерирует ошибку.
В схеме репликации Microsoft SQL Server иерархическая связь реплик является неявной. SQL Server определяет главную таблицу как "издателя" данных, а подчиненные таблицы — как их "подписчиков". В создаваемой по умолчанию конфигурации существует один обновляемый издатель и несколько подписчиков, данные в которых доступны только для выборки. Развивая эту аналогию, SQL Server поддерживает два вида обновлений: подписка (когда издатель сам отправляет обновленные данные подписчикам) и запрос (когда вся ответственность за получение обновленных данных лежит на подписчиках).
Однако существуют такие типы приложений, для которых технология табличной репликации очень удобна, но иерархическое отношение между репликами к ним неприменимо. Например, в приложениях, от которых требуется очень высокая степень надежности, часто поддерживаются две идентичные копии данных в двух компьютерных системах. Если одна система выходит из строя, вторая используется для продолжения работы. Другим примером может быть Internet-приложение с большим количество;* пользователей, выполняющее очень интенсивный обмен с базой данных. Для обеспечения приемлемой эффективности работы пользователей такого приложения его рабоч* нагрузка может быть распределена между несколькими компьютерными системами с отдельными синхронизируемыми копиями данных. Или еще один пример. В торговой компании может существовать одна центральная таблица клиентов и сотни ее реплик в портативных компьютерах торговых менеджеров. При этом все менеджеры должны иметь возможность вводить в свои реплики информацию о новых клиентах или изменять данные о старых клиентах. Для всех этих (и многих других) типов приложений наиболее эффективной является схема, при которой все реплики допускают модификацию своего содержимого.
Репликация
Двунаправленная репликация
Схема: Издатель - подписчики
Горизонтальная репликация(по строкам)
Вертикальная репликация (по столбцам)
Зеркальная репликация(таблицы полностью идентичны)
Схема: Издатель - подписчики
|
|
Создание новой публикации (подписки)
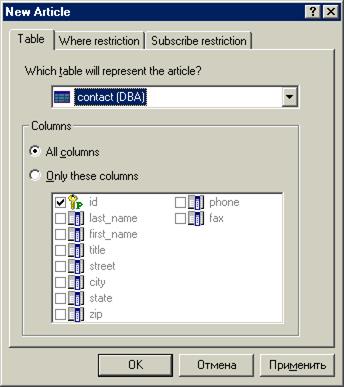
Указываются таблицы, которые необходимо реплицировать.
Для каждой таблицы можно определить набор столбцов включенных в публикацию
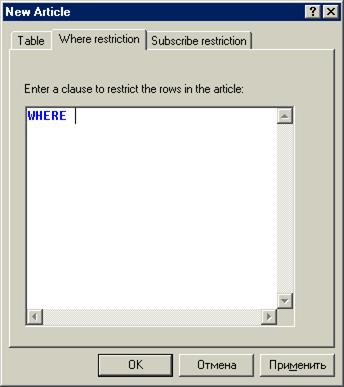
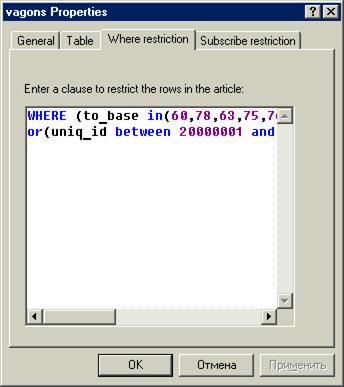
И определить условие where для выборки необходимых строк.
Затем создается новый пользователь(так называемый удаленный пользователь)
Для которого определяется способ передачи информации в центральную(consolidated) базу данных(file, mapi, smtp, vim, ftp) и периодичность обмена (по запросу(send and close), каждые nn:mm часов, ежедневно в указанное время)
Далее удаленный пользователь подписывается на ранее созданную публикацию и для него выгружается его локальная база данных. В ней будут только те данные, которые разрешены публикацией, на которую подписан этот пользователь.
|
|

|
|
|
|
|
|
Контрольные вопросы
1. Опишите механизм репликации БД на основе дублирования таблиц.
2. Опишите механизм двунаправленной репликации БД.
3. Поясните схему репликации “Издатель-Подписчики”.
4. Перечислите шаги необходимые для создания распределенной БД средствами Sybase SQL Anywhere.
Лекция 16
Концепции хранилищ данных
В основе технологии хранилищ данных лежит идея о том, что базы данных ориентированные на оперативную обработку транзакций (Onlinе Transaction Рrocessing – OLTP), и базы данных, предназначенные для делового анализа, используются совершенно по-разному и служат разным целям. Первые – это средство производства, основа каждодневного функционирования предприятия. На производственном предприятии подобные базы данных поддерживают процессы принятия заказов клиентов, учета сырья, складского учета и оплаты продукции, т.е. выполняют главным образом учетные функции. С такими базами данных, как правило, работают клиентские приложения, используемые производственным персоналом, работниками складов т.п. В противоположность этому базы данных второго типа используются для принятия решений на основе сбора и анализа информации. Их главные пользователи – это менеджеры, служащие планового отдела и отдела маркетинга.
Ключевые отличия аналитических и OLTP-приложений, с точки зрения взаимодействия с базами данных, перечислены в табл.
Рабочая нагрузка баз данных, используемых в аналитических и OLTP - приложениях, настолько различна, что очень трудно или даже невозможно подобрать одну СУБД, которая наилучшим образом удовлетворяла бы требованиям приложений обоих типов.
| Характеристика | OLTP | База хранилища данных |
| Типичный размер таблиц | Тысячи строк | Миллионы строк |
| Схема доступа | Предопределена для каждого типа обрабатываемых транзакций | Произвольная; зависит от того, какая именно задача стоит перед пользователем в данный момент и какие средства нужны для ее решения |
| Количество строк, к которым обращается один запрос | Десятки | От тысяч до миллионов |
| С какими данными работает приложение | С отдельными строками | С группами строк (итоговые запросы) |
| Интенсивность Обращений к базе данных | Большое количество транзакций в минуту или в секунду | На выполнение запроса требуется время: минуты или даже часы |
| Тип доступа | Выборка, вставка и обновление | Преимущественно выборка |
| Чем определяется Производительность | Время выполнения Транзакции | Время выполнения запроса |
Компоненты хранилища данных
На рис. изображена архитектура хранилища данных. Выделим три ее основных компонента:
средства наполнения хранилища – это программный комплекс, отвечающий за извлечение данных из корпоративных OLTP-систем (реляционных баз данных, и других систем, их обработку и загрузку в хранилище; этот процесс обычно требует предварительной обработки извлекаемых данных, их фильтрации и переформатирования, причем записи загружаются в хранилище не по одной, а целыми пакетами;
база данных хранилища – обычно это реляционная база данных, оптимизированная для хранения огромных объемов данных, их очень быстрой пакетной загрузки и выполнения сложных аналитических запросов;
средства анализа данных – это программный комплекс, выполняющий статистический и временной анализ, анализ типа "что если" и представление результатов в графической форме.
Современные хранилища преимущественно управляются специализированными реляционными СУБД ведущих производителей рынка корпоративных баз данных.
Архитектура баз данных для хранилищ.
Структура базы данных для хранилища обычно разрабатывается таким образом, чтобы максимально облегчить анализ информации, ведь это основная функция хранилища. Данные должно быть удобно "раскладывать" по разным направлениям (называемым измерениями). Структура базы данных должна обеспечивать проведение всех типов анализа, позволяя выделять данные, соответствующие заданному набору измерений.
Кубы фактов
В большинстве случаев информация в базе данных хранилища может быть представлена в виде N-мерного куба фактов, отражающих деловую активность компании в течение определенного времени: Простейший трехмерный куб данных о продажах изображен на рис.
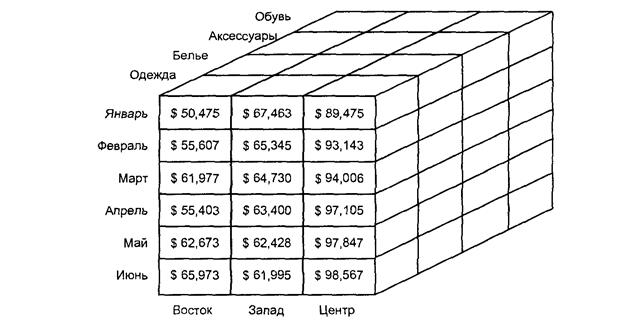
Каждая его ячейка представляет один "факт" - объем продаж в стоимостном или натуральном выражении. Вдоль одной грани куба (одного измерения) располагаются месяцы, в течение которых выполнялись отражаемые кубом продажи. Второе измерение составляют категории товаров, а третье – регионы продаж. В каждой ячейке содержится объем продаж для соответствующей комбинации значений по всем трем измерениям.
В реальных приложениях используются гораздо более сложные кубы с десятью и более измерений.
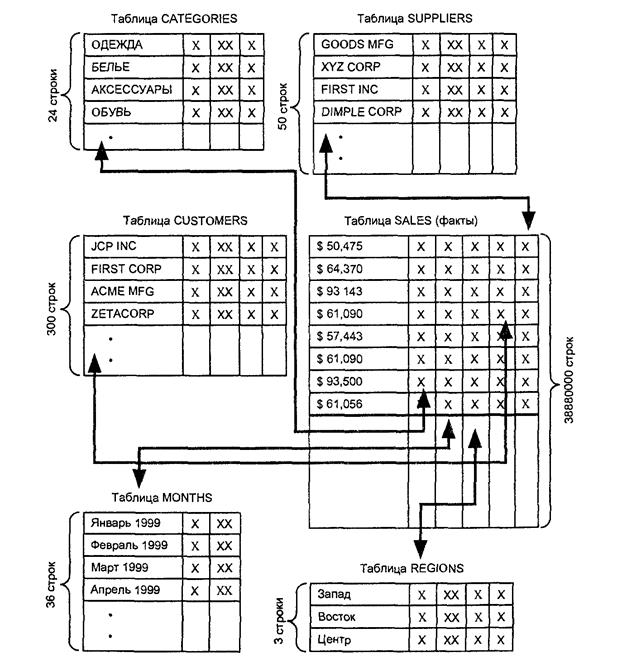
Схема "звезда"
Для большинства хранилищ данных самым эффективным способом моделирования
N-мерного куба фактов является схема "звезда". На рис. изображено, как выглядит такая схема для хранилища данных коммерческой компании, описанного выше.
Для каждого значения измерения, таблице имеется отдельная строка.
Многоуровневые измерения
В схеме "звезда", каждое измерение имеет только один уровень. На практике же довольно распространена более сложная структура базы данных, в которой измерения могу иметь по несколько уровней.
Расширения SQL для хранилищ данных
Теоретически реляционная база данных звездообразной структуры обеспечивает хороший фундамент для выполнения запросов из области делового анализа. Возможность находить не представленную в базе данных в явном виде информацию на основе анализа содержащихся в ней значений как нельзя лучше подходит для произвольных, непрограммируемых запросов, свойственных аналитическим приложениям. Однако между типичными аналитическими запросами и возможностями базового языка SQL имеются серьезные несоответствия. Например:
Сортировка данных. Многие аналитические запросы явно или неявно требуют предварительной сортировки данных. Возможны такие критерии отбора информации, как "первые десять процентов", "первая десятка", и т.п. Однако SQL оперирует неотсортированными наборами записей. Единственным средством сортировки данных в нем является предложение order by в инструкции select, причем сортировка выполняется в самом конце процесса, когда данные уже отобраны и обработаны.
Хронологические последовательности. Многие запросы к хранилищам данных предназначены для анализа изменения некоторых показателей во времени: они сравнивают результаты этого года с результатами прошлого, результаты этого месяца с результатами того же месяца в прошлом году, показывают динамику роста годовых показателей в течение ряда лет и т.п. Однако очень трудно, а иногда и просто невозможно получить сравнительные данные за разные периоды времени в одной строке, возвращаемой стандартной инструкцией SQL. В общем случае это зависит от структуры базы данных.
Сравнениение с итоговыми данными. Многие аналитические запросы сравнивают значения отдельных элементов (например, объемы продаж отдельных офисов) с итоговыми данными (например, объемами продаж по регионам). Такой запрос трудно выразить на стандартном диалекте SQL.
Пытаясь решить все этих проблемы, производители СУБД для хранилищ данных обычно расширяют в своих продуктах возможности языка SQL, добавляя такие расширения:
диапазоны — позволяют формулировать запросы вида "отобрать первые десять записей";
перемещение итогов и средних – используется для хронологического анализа, требующего предварительной обработки исходных данных;
расчет текущих итогов и средних – позволяет получать данные по отдельны месяцам, плюс годовой итог на текущую дату и выполнять другие подобные запросы;
сравнительные коэффициенты – позволяют создавать запросы, выражающие отношение отдельных значений к общим и промежуточным итогам без использования сложных подчиненных запросов;
декодирование – упрощает замену кодов из таблиц измерений понятными именами (например, замену кодов товаров их названиями);
промежуточные итоги – позволяют получать результаты запросов, в которых объединена детализированная и итоговая информация, причем с несколькими уровнями итогов.
Многие разработчики СУБД для хранилищ данных используют аналогичные расширения или встраивают в свои продукты специальные функции для получения нетипичных для SQL. данных. Как и в случае с другими расширениями SQL., их концептуальные возможности, предлагаемые различными разработчиками, сходны, а реализация зачастую совершенно разная.
Контрольные вопросы
1. Концепция хранилищ данных. OLTP системы и OLAP системы.
2. Сравните рабочие нагрузки OLTP и OLAP систем.
3. Перечислите типовые компоненты хранилища данных.
4. Какая архитектура БД используется для организации хранилища данных.
5. Расширения языка SQL используемые в хранилищах данных.
Литература
1) К.Дж. Дейт Введение в системы баз данных, 8-е издание.: Пер. с англ. — Москва: Издательский дом "Вильяме", 2005.
2)М. Ричардс и др. “ORACLE 7.3 Энциклопедия пользователя”.
Киев, изд. Диасофт, 1997г
3)Омельченко Л. Н., Шевякова Д. А. Самоучитель Visual FoxPro 9.0.
СПб: БХВ-Петербург, 2005г.
4)Дж. Грофф, П. Вайнберг. SQL: Полное руководство; Пер. с англ., Киев: Издательская группа BHV, 2001г.
Оглавление
Лекция 1. 2
Лекция 2. 10
Лекция 3. 15
Лекция 4. 24
Лекция 5. 30
Лекция 6. 39
Лекция 7. 44
Лекция 8. 53
Лекция 9. 60
Лекция 10. 69
Лекция 11. 77
Лекция 12. 84
Лекция 13. 93
Лекция 14. 96
Лекция 15. 96
Лекция 16. 96
Литература.. 96
Дата: 2019-02-02, просмотров: 807.