Рассмотрим простейшую модель парной регрессии – линейную регрессию. Линейная регрессия находит широкое применение в эконометрике ввиду четкой экономической интерпретации ее параметров.
Линейная регрессия сводится к нахождению уравнения вида
 или
или  . (1.1)
. (1.1)
Уравнение вида позволяет по заданным значениям фактора  находить теоретические значения результативного признака, подставляя в него фактические значения фактора
находить теоретические значения результативного признака, подставляя в него фактические значения фактора  .
.
Построение линейной регрессии сводится к оценке ее параметров –  и
и  . Классический подход к оцениванию параметров линейной регрессии основан на методе наименьших квадратов (МНК). МНК позволяет получить такие оценки параметров и
. Классический подход к оцениванию параметров линейной регрессии основан на методе наименьших квадратов (МНК). МНК позволяет получить такие оценки параметров и  , при которых сумма квадратов отклонений фактических значений результативного признака
, при которых сумма квадратов отклонений фактических значений результативного признака  от теоретических
от теоретических  минимальна:
минимальна:
 . (1.2)
. (1.2)
Т.е. из всего множества линий линия регрессии на графике выбирается так, чтобы сумма квадратов расстояний по вертикали между точками и этой линией была бы минимальной (рис. 1.2):

Рис. 1.2. Линия регрессии с минимальной дисперсией остатков.
Как известно из курса математического анализа, чтобы найти минимум функции (1.2), надо вычислить частные производные по каждому из параметров и и приравнять их к нулю. Обозначим  через
через  , тогда:
, тогда:
 .
.
 (1.3)
(1.3)
После несложных преобразований, получим следующую систему линейных уравнений для оценки параметров и :
 (1.4)
(1.4)
Решая систему уравнений (1.4), найдем искомые оценки параметров и . Можно воспользоваться следующими готовыми формулами, которые следуют непосредственно из решения системы (1.4):
 ,
,  , (1.5)
, (1.5)
где  – ковариация признаков и
– ковариация признаков и  ,
,  – дисперсия признака и
– дисперсия признака и
 ,
,  ,
,  ,
,  .
.
Ковариация – числовая характеристика совместного распределения двух случайных величин, равная математическому ожиданию произведения отклонений этих случайных величин от их математических ожиданий. Дисперсия – характеристика случайной величины, определяемая как математическое ожидание квадрата отклонения случайной величины от ее математического ожидания. Математическое ожидание – сумма произведений значений случайной величины на соответствующие вероятности[3].
Параметр  называется коэффициентом регрессии. Его величина показывает среднее изменение результата с изменением фактора на одну единицу.
называется коэффициентом регрессии. Его величина показывает среднее изменение результата с изменением фактора на одну единицу.
Возможность четкой экономической интерпретации коэффициента регрессии сделала линейное уравнение регрессии достаточно распространенным в эконометрических исследованиях.
Формально – значение 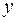 при
при  . Если признак-фактор не может иметь нулевого значения, то вышеуказанная трактовка свободного члена не имеет смысла, т.е. параметр может не иметь экономического содержания.
. Если признак-фактор не может иметь нулевого значения, то вышеуказанная трактовка свободного члена не имеет смысла, т.е. параметр может не иметь экономического содержания.
Уравнение регрессии всегда дополняется показателем тесноты связи. При использовании линейной регрессии в качестве такого показателя выступает линейный коэффициент корреляции  , который можно рассчитать по следующим формулам:
, который можно рассчитать по следующим формулам:
 . (1.6)
. (1.6)
Линейный коэффициент корреляции находится в пределах: 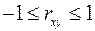 . Чем ближе абсолютное значение к единице, тем сильнее линейная связь между факторами (при
. Чем ближе абсолютное значение к единице, тем сильнее линейная связь между факторами (при  имеем строгую функциональную зависимость). Но следует иметь в виду, что близость абсолютной величины линейного коэффициента корреляции к нулю еще не означает отсутствия связи между признаками. При другой (нелинейной) спецификации модели связь между признаками может оказаться достаточно тесной.
имеем строгую функциональную зависимость). Но следует иметь в виду, что близость абсолютной величины линейного коэффициента корреляции к нулю еще не означает отсутствия связи между признаками. При другой (нелинейной) спецификации модели связь между признаками может оказаться достаточно тесной.
Для оценки качества подбора линейной функции рассчитывается квадрат линейного коэффициента корреляции  , называемый коэффициентом детерминации. Коэффициент детерминации характеризует долю дисперсии результативного признака , объясняемую регрессией, в общей дисперсии результативного признака:
, называемый коэффициентом детерминации. Коэффициент детерминации характеризует долю дисперсии результативного признака , объясняемую регрессией, в общей дисперсии результативного признака:
 , (1.7)
, (1.7)
где  ,
,  .
.
Соответственно величина  характеризует долю дисперсии , вызванную влиянием остальных, не учтенных в модели, факторов.
характеризует долю дисперсии , вызванную влиянием остальных, не учтенных в модели, факторов.
После того как найдено уравнение линейной регрессии, проводится оценка значимости как уравнения в целом, так и отдельных его параметров.
Проверить значимость уравнения регрессии – значит установить, соответствует ли математическая модель, выражающая зависимость между переменными, экспериментальным данным и достаточно ли включенных в уравнение объясняющих переменных (одной или нескольких) для описания зависимой переменной.
Чтобы иметь общее суждение о качестве модели из относительных отклонений по каждому наблюдению, определяют среднюю ошибку аппроксимации:
 . (1.8)
. (1.8)
Средняя ошибка аппроксимации не должна превышать 8–10%.
Оценка значимости уравнения регрессии в целом производится на основе  -критерия Фишера, которому предшествует дисперсионный анализ. В математической статистике дисперсионный анализ рассматривается как самостоятельный инструмент статистического анализа. В эконометрике он применяется как вспомогательное средство для изучения качества регрессионной модели.
-критерия Фишера, которому предшествует дисперсионный анализ. В математической статистике дисперсионный анализ рассматривается как самостоятельный инструмент статистического анализа. В эконометрике он применяется как вспомогательное средство для изучения качества регрессионной модели.
Согласно основной идее дисперсионного анализа, общая сумма квадратов отклонений переменной от среднего значения  раскладывается на две части – «объясненную» и «необъясненную»:
раскладывается на две части – «объясненную» и «необъясненную»:
 ,
,
где  – общая сумма квадратов отклонений;
– общая сумма квадратов отклонений;  – сумма квадратов отклонений, объясненная регрессией (или факторная сумма квадратов отклонений);
– сумма квадратов отклонений, объясненная регрессией (или факторная сумма квадратов отклонений);  – остаточная сумма квадратов отклонений, характеризующая влияние неучтенных в модели факторов.
– остаточная сумма квадратов отклонений, характеризующая влияние неучтенных в модели факторов.
Схема дисперсионного анализа имеет вид, представленный в таблице 1.1 (  – число наблюдений,
– число наблюдений,  – число параметров при переменной ).
– число параметров при переменной ).
Таблица 1.1
| Компоненты дисперсии | Сумма квадратов | Число степеней свободы | Дисперсия на одну степень свободы |
| Общая |
| 
| 
|
| Факторная | 
|
| 
|
| Остаточная | 
| 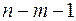
| 
|
Определение дисперсии на одну степень свободы приводит дисперсии к сравнимому виду. Сопоставляя факторную и остаточную дисперсии в расчете на одну степень свободы, получим величину  -критерия Фишера:
-критерия Фишера:
 . (1.9)
. (1.9)
Фактическое значение -критерия Фишера (1.9) сравнивается с табличным значением  при уровне значимости
при уровне значимости  и степенях свободы
и степенях свободы  и
и  . При этом, если фактическое значение -критерия больше табличного, то признается статистическая значимость уравнения в целом.
. При этом, если фактическое значение -критерия больше табличного, то признается статистическая значимость уравнения в целом.
Для парной линейной регрессии  , поэтому
, поэтому
 . (1.10)
. (1.10)
Величина -критерия связана с коэффициентом детерминации  , и ее можно рассчитать по следующей формуле:
, и ее можно рассчитать по следующей формуле:
 . (1.11)
. (1.11)
В парной линейной регрессии оценивается значимость не только уравнения в целом, но и отдельных его параметров. С этой целью по каждому из параметров определяется его стандартная ошибка:  и
и 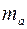 .
.
Стандартная ошибка коэффициента регрессии определяется по формуле:
 , (1.12)
, (1.12)
где  – остаточная дисперсия на одну степень свободы.
– остаточная дисперсия на одну степень свободы.
Величина стандартной ошибки совместно с  -распределением Стьюдента при
-распределением Стьюдента при  степенях свободы применяется для проверки существенности коэффициента регрессии и для расчета его доверительного интервала.
степенях свободы применяется для проверки существенности коэффициента регрессии и для расчета его доверительного интервала.
Для оценки существенности коэффициента регрессии его величина сравнивается с его стандартной ошибкой, т.е. определяется фактическое значение  -критерия Стьюдента:
-критерия Стьюдента:  которое затем сравнивается с табличным значением при определенном уровне значимости
которое затем сравнивается с табличным значением при определенном уровне значимости  и числе степеней свободы
и числе степеней свободы  . Доверительный интервал для коэффициента регрессии определяется как
. Доверительный интервал для коэффициента регрессии определяется как  . Поскольку знак коэффициента регрессии указывает на рост результативного признака при увеличении признака-фактора (
. Поскольку знак коэффициента регрессии указывает на рост результативного признака при увеличении признака-фактора (  ), уменьшение результативного признака при увеличении признака-фактора (
), уменьшение результативного признака при увеличении признака-фактора (  ) или его независимость от независимой переменной (
) или его независимость от независимой переменной (  ) (см. рис. 1.3), то границы доверительного интервала для коэффициента регрессии не должны содержать противоречивых результатов, например,
) (см. рис. 1.3), то границы доверительного интервала для коэффициента регрессии не должны содержать противоречивых результатов, например,  . Такого рода запись указывает, что истинное значение коэффициента регрессии одновременно содержит положительные и отрицательные величины и даже ноль, чего не может быть.
. Такого рода запись указывает, что истинное значение коэффициента регрессии одновременно содержит положительные и отрицательные величины и даже ноль, чего не может быть.

Рис. 1.3. Наклон линии регрессии в зависимости от значения параметра  .
.
Стандартная ошибка параметра  определяется по формуле:
определяется по формуле:
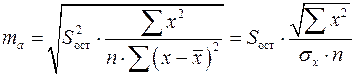 . (1.13)
. (1.13)
Процедура оценивания существенности данного параметра не отличается от рассмотренной выше для коэффициента регрессии. Вычисляется  -критерий:
-критерий:  , его величина сравнивается с табличным значением при
, его величина сравнивается с табличным значением при  степенях свободы.
степенях свободы.
Значимость линейного коэффициента корреляции проверяется на основе величины ошибки коэффициента корреляции  :
:
 . (1.14)
. (1.14)
Фактическое значение -критерия Стьюдента определяется как  .
.
Существует связь между -критерием Стьюдента и  -критерием Фишера:
-критерием Фишера:
 . (1.15)
. (1.15)
В прогнозных расчетах по уравнению регрессии определяется предсказываемое  значение как точечный прогноз
значение как точечный прогноз  при
при 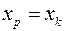 , т.е. путем подстановки в уравнение регрессии
, т.е. путем подстановки в уравнение регрессии  соответствующего значения
соответствующего значения 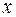 . Однако точечный прогноз явно не реален. Поэтому он дополняется расчетом стандартной ошибки
. Однако точечный прогноз явно не реален. Поэтому он дополняется расчетом стандартной ошибки  , т.е.
, т.е.  , и соответственно интервальной оценкой прогнозного значения :
, и соответственно интервальной оценкой прогнозного значения :
 ,
,
где  , а – средняя ошибка прогнозируемого индивидуального значения:
, а – средняя ошибка прогнозируемого индивидуального значения:
 . (1.16)
. (1.16)
Рассмотрим пример. По данным проведенного опроса восьми групп семей известны данные связи расходов населения на продукты питания с уровнем доходов семьи.
Таблица 1.2
Расходы на продукты питания, 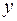 , тыс. руб. , тыс. руб.
| 0,9 | 1,2 | 1,8 | 2,2 | 2,6 | 2,9 | 3,3 | 3,8 |
| Доходы семьи, , тыс. руб.
| 1,2 | 3,1 | 5,3 | 7,4 | 9,6 | 11,8 | 14,5 | 18,7 |
Предположим, что связь между доходами семьи и расходами на продукты питания линейная. Для подтверждения нашего предположения построим поле корреляции.

Рис. 1.4.
По графику видно, что точки выстраиваются в некоторую прямую линию.
Для удобства дальнейших вычислений составим таблицу.
Таблица 1.3
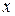
| 
| 
| 
| 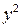
| 
| 
| 
|  , % , %
| |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 1 | 1,2 | 0,9 | 1,08 | 1,44 | 0,81 | 1,038 | –0,138 | 0,0190 | 15,33 |
| 2 | 3,1 | 1,2 | 3,72 | 9,61 | 1,44 | 1,357 | –0,157 | 0,0246 | 13,08 |
| 3 | 5,3 | 1,8 | 9,54 | 28,09 | 3,24 | 1,726 | 0,074 | 0,0055 | 4,11 |
| 4 | 7,4 | 2,2 | 16,28 | 54,76 | 4,84 | 2,079 | 0,121 | 0,0146 | 5,50 |
| 5 | 9,6 | 2,6 | 24,96 | 92,16 | 6,76 | 2,449 | 0,151 | 0,0228 | 5,81 |
| 6 | 11,8 | 2,9 | 34,22 | 139,24 | 8,41 | 2,818 | 0,082 | 0,0067 | 2,83 |
| 7 | 14,5 | 3,3 | 47,85 | 210,25 | 10,89 | 3,272 | 0,028 | 0,0008 | 0,85 |
| 8 | 18,7 | 3,8 | 71,06 | 349,69 | 14,44 | 3,978 | –0,178 | 0,0317 | 4,68 |
| Итого | 71,6 | 18,7 | 208,71 | 885,24 | 50,83 | 18,717 | –0,017 | 0,1257 | 52,19 |
| Среднее значение | 8,95 | 2,34 | 26,09 | 110,66 | 6,35 | 2,34 | – | 0,0157 | 6,52 |
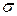
| 5,53 | 0,935 | – | – | – | – | – | – | – |

| 30,56 | 0,874 | – | – | – | – | – | – | – |
Рассчитаем параметры линейного уравнения парной регрессии  . Для этого воспользуемся формулами (1.5):
. Для этого воспользуемся формулами (1.5):
 ;
;
 .
.
Получили уравнение:  . Т.е. с увеличением дохода семьи на 1000 руб. расходы на питание увеличиваются на 168 руб.
. Т.е. с увеличением дохода семьи на 1000 руб. расходы на питание увеличиваются на 168 руб.
Как было указано выше, уравнение линейной регрессии всегда дополняется показателем тесноты связи – линейным коэффициентом корреляции  :
:
 .
.
Близость коэффициента корреляции к 1 указывает на тесную линейную связь между признаками.
Коэффициент детерминации  (примерно тот же результат получим, если воспользуемся формулой (1.7)) показывает, что уравнением регрессии объясняется 98,7% дисперсии результативного признака, а на долю прочих факторов приходится лишь 1,3%.
(примерно тот же результат получим, если воспользуемся формулой (1.7)) показывает, что уравнением регрессии объясняется 98,7% дисперсии результативного признака, а на долю прочих факторов приходится лишь 1,3%.
Оценим качество уравнения регрессии в целом с помощью  -критерия Фишера. Сосчитаем фактическое значение
-критерия Фишера. Сосчитаем фактическое значение  -критерия:
-критерия:
 .
.
Табличное значение (  ,
, 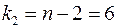 ,
,  ):
):  . Так как
. Так как  , то признается статистическая значимость уравнения в целом.
, то признается статистическая значимость уравнения в целом.
Для оценки статистической значимости коэффициентов регрессии и корреляции рассчитаем  -критерий Стьюдента и доверительные интервалы каждого из показателей. Рассчитаем случайные ошибки параметров линейной регрессии и коэффициента корреляции
-критерий Стьюдента и доверительные интервалы каждого из показателей. Рассчитаем случайные ошибки параметров линейной регрессии и коэффициента корреляции  :
:
 ,
,
 ,
,
 .
.
Фактические значения -статистик:  ,
,  ,
,  . Табличное значение -критерия Стьюдента при
. Табличное значение -критерия Стьюдента при  и числе степеней свободы
и числе степеней свободы  есть
есть  . Так как
. Так как  ,
,  и
и  , то признаем статистическую значимость параметров регрессии и показателя тесноты связи. Рассчитаем доверительные интервалы для параметров регрессии
, то признаем статистическую значимость параметров регрессии и показателя тесноты связи. Рассчитаем доверительные интервалы для параметров регрессии  и :
и :  и
и  . Получим, что
. Получим, что  и
и  .
.
Средняя ошибка аппроксимации (находим с помощью столбца 10 таблицы 1.3;  )
)  говорит о хорошем качестве уравнения регрессии, т.е. свидетельствует о хорошем подборе модели к исходным данным.
говорит о хорошем качестве уравнения регрессии, т.е. свидетельствует о хорошем подборе модели к исходным данным.
И, наконец, найдем прогнозное значение результативного фактора  при значении признака-фактора, составляющем 110% от среднего уровня
при значении признака-фактора, составляющем 110% от среднего уровня  , т.е. найдем расходы на питание, если доходы семьи составят 9,85 тыс. руб.
, т.е. найдем расходы на питание, если доходы семьи составят 9,85 тыс. руб.
 (тыс. руб.)
(тыс. руб.)
Значит, если доходы семьи составят 9,845 тыс. руб., то расходы на питание будут 2,490 тыс. руб.
Найдем доверительный интервал прогноза. Ошибка прогноза
 ,
,
а доверительный интервал (  ):
):
 .
.
Т.е. прогноз является статистически надежным.
Теперь на одном графике изобразим исходные данные и линию регрессии:

Рис. 1.5.
Дата: 2018-11-18, просмотров: 745.