Цель лекции: изучение помехоустойчивых кодов и методов декодирования корректирующих кодов
Содержание:
а) коды Рида- Соломона;
б) сверточные коды;
в) классификация корректирующих кодов;
г) методы декодирования корректирующих кодов.
Коды Рида- Соломона
Коды Рида-Соломона (Reed-Solomon code, R-S code) — это недвоичные циклические коды, символы которых представляют собой m-битовые последовательности, где т — положительное целое число, большее 2. Код (n,к) определен на m-битовых символах при всех n и k, для которых
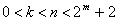 (11.1)
(11.1)
где k - число информационных битов, подлежащих кодированию, а n - число кодовых символов в кодируемом блоке. Для большинства сверточных кодов Рида-Соломона (n, к)
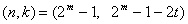 (11.2)
(11.2)
где t - количество ошибочных битов в символе, которые может исправить код, а n-k = 2t- число контрольных символов. Расширенный код Рида-Соломона можно получить при n = 2m или n= 2m+ 1, но не более того.
Код Рида-Соломона обладает наибольшим минимальным расстоянием, возможным для линейного кода с одинаковой длиной входных и выходных блоков кодера. Для недвоичных кодов расстояние между двумя кодовыми словами определяется (по аналогии с расстоянием Хэмминга) как число символов, которыми отличаются последовательности. Для кодов Рила-Соломона минимальное расстояние определяется следующим образом.
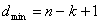 (11.3)
(11.3)
Сверточные коды. Особенностью линейного блочного кода, который описывается двумя целыми числами, n и k, и полиномиальным или матричным генератором является то, что каждый из n-кортежей кодовых слов однозначно определяется k-кортeжeм входного сообщения. Целое число к указывает на число бит данных, которые образуют вход блочного кодера. Целое число п - это суммарное количество разрядов в соответствующем кодовом слове на выходе кодера. Отношение k/n, называемое степенью кодирования кода (code rate), является мерой добавленной избыточности. Сверточный код описывается тремя целыми числами n, k и К, где отношение k/n имеет такое же значение степени кодирования (информация, приходящаяся на закодированный бит), как и для блочного кода; однако п не определяет длину блока или кодового слова, как это было в блочных кодах. Целое число К является параметром, называемым длиной кодового ограничения (constrain! length); оно указывает число разрядов k-кортежа в кодирующем регистре сдвига. Важная особенность сверточных кодов, в отличие от блочных, состоит в том, что кодер имеет память - n-кортежи, получаемые при сверточном кодировании, являются функцией не только одного входного k-кортежа, но и предыдущих К-1 входных k-кортежей. На практике nи к - это небольшие целые числа, а К изменяется с целью контроля мощности и сложности кода.
Методы декодирования корректирующих кодов. Существует несколько вариантов декодирования циклических кодов. Один из них заключается в следующем:
1. Числение остатка (синдрома). Принятую комбинацию делят на образующий многочлен Р(Х). Остаток R(X)=0 означает, что комбинации принята без ошибок;
2. Подсчет веса остатка W. Если вес остатка равен или меньше числа исправляемых ошибок, т.е. W≤s, то принятую комбинацию складывают по модулю 2 с остатком и получают исправленную комбинацию;
3. Циклический сдвиг на один символ влево. Если W>s, то производят циклический сдвиг влево и полученную комбинацию снова делят на образующий многочлен. Если вес остатка W≤s , то циклически сдвинутую комбинацию складывают с остатком и затем циклически сдвигают ее в обратную строну вправо на один символ. В результате получают исправленную комбинацию;
4. Дополнительные циклические сдвиги влево. Если после циклического сдвига на один символ по-прежнему W>s, то производят дополнительные циклические сдвиги влево. При этом после каждого сдвига сдвинутую комбинацию делят на Р(Х) и проверяют вес остатка. При W≤s выполняют действия, указанные в п.3, с той лишь разницей, что обратных циклических сдвигов вправо делают столько, сколько их было сделано влево.
Метод проверки на четность. Если комбинация принята без искажения, то сумма единиц по модулю 2 даст нуль. При искажении какого – либо символа суммирование при проверке может дать единицу. По результату суммирования каждой из проверок составляют двоичное число, указывающее на место искажения.
Мягкое и жесткое декодирование. Для двоичной кодовой системы со степенью кодирования 1/2 демодулятор подает на декодер два кодовых символа за раз. Для жесткого (двухуровневого) декодирования каждую пару принятых кодовых символов можно изобразить на плоскости в виде одного из углов квадрата. Углы помечены двоичными числами (0, 0), (0, 1), (1, 0) и (1, 1), представляющими четыре возможных значения, которые могут принимать два кодовых символа в жесткой схеме принятия решений. Аналогично для 8-уровневого мягкого декодирования каждую пару кодовых символов можно отобразить на плоскости в виде равностороннего прямоугольника размером 8x8, состоящего из 64 точек. В этом случае демодулятор больше не выдает жестких решений; он выдает квантованные сигналы с шумом (мягкая схема принятия решений).
Основное различие между мягким и жестким декодированием по алгоритму Витерби состоит в том, что в мягкой схеме не используется метрика расстояния Хэмминга, поскольку она имеет ограниченное разрешение.
Мажоритарное декодирование. Этот метод заключается в многократной проверке каждого символа принятой кодовой комбинации по специальным таблицам коэффициентов, составленным для каждого варианта (n, k) циклического кода. Значение каждого символа определяется по мажоритарному принципу (слово «мажоритарный» означает большинство), т.е. по принципу голосования. Это означает, что если, например, один из пяти проверок данного символа три показали 1, а две- 0, то символу присваивается значение 1. Если все проверки показали 1 или 0, то символ считается неискаженным и принимается без изменения.
Если при какой-либо проверке окажется равное число 1 и 0, то это означает, что для данного кода произошла неисправимая комбинация ошибок и принятая комбинация должна быть забракована.
Алгоритм Возенкрафта и Фано. Ранее, до того как Витерби открыл оптимальный алгоритм декодирования сверточных кодов, существовали и другие алгоритмы. Самым первым был алгоритм последовательного декодирования, предложенный Уозенкрафтом (Wozencraft) и модифицированный Фано (Fano). В ходе работы последовательного декодера генерируется гипотеза о переданной последовательности кодовых слов и рассчитывается метрика между этой гипотезой и принятым сигналом. Эта процедура продолжается до тех пор, пока метрика показывает, что выбор гипотезы правдоподобен, в противном случае гипотеза последовательно заменяется, пока не будет найдена наиболее правдоподобная. Поиск при этом происходит методом проб и ошибок. Для мягкого или жесткого декодирования можно разработать последовательный декодер, но обычно мягкого декодирования стараются избегать из-за сложных расчетов и большой требовательности к памяти.
Решетчатое (треллис) кодирование. При использовании в системах связи реального времени кодов коррекции ошибок достоверность передачи улучшается за счет расширения полосы частот. Как для блочных, так и для сверточных кодов преобразование каждого k-кортежа входных данных в более длинный n-кортеж кодового слова требует дополнительного расширения полосы пропускания. Вследствие этого в прошлом кодирование не было особенно популярно в узкополосных каналах (таких, как телефонные), в которых расширять полосу частот сигнала было нецелесообразно. Однако приблизительно с 1984 года возникает активный интерес к схемам, где модуляция объединяется с кодированием; такие схемы называются решетчатым кодированием (trellis-coded modulation — ТСМ). Эти схемы позволяют повысить достоверность передачи, не расширяя при этом полосу частот сигнала.
Алгоритм декодирования Витерби. Алгоритм декодирования Витерби был открыт и проанализирован Витерби (Viterbi) в 1967 году. В алгоритме Витерби, по сути, реализуется декодирование, основанное на принципе максимального правдоподобия; однако в нем уменьшается вычислительная нагрузка за счет использования особенностей структуры конкретной решетки кода. Преимущество декодирования Витерби, по сравнению с декодированием по методу "грубой силы", заключается в том, что сложность декодера Витерби не является функцией количества символов в последовательности кодовых слов. Алгоритм включает в себя вычисление меры подобия (или расстояния), между сигналом, полученным в момент времени t1 и всеми путями решетки, входящими в каждое состояние в момент времени t1. В алгоритме Витерби не рассматриваются те пути решетки, которые, согласно принципу максимального правдоподобия, заведомо не могут быть оптимальными. Если в одно и то же состояние входят два пути, выбирается тот, который имеет лучшую метрику; такой путь называется выживающим. Отбор выживающих путей выполняется для каждого состояния. Таким образом, декодер углубляется в решетку, принимая решения путем исключения менее вероятных путей. Предварительный отказ от маловероятных путей упрощает процесс декодирования.
Смысл декодирования Витерби заключается в следующем: если любые два пути сливаются в одном состоянии, то при поиске оптимального пути один из них всегда можно исключить.
Техническая реализация кодирующих и декодирующих устройств . Оценка сложности построения устройств кодирования. Как следует из принципов построения линейных блочных кодов, основными операциями, выполняемыми при кодировании и декодировании, являются суммирование по модулю 2, операции сдвига, запись, считывание и хранение двоичных разрядов. Эти операции могут быть реализованы на стандартных логических элементах. Поэтому сложность схем кодирования и декодирования можно оценить числом таких элементов (например, триггеров).
Рассмотрим принцип построения кодера кода Хемминга. Кодирование сводится к нахождению проверочных разрядов путем сложения по модулю 2 соответствующих информационных элементов. Поскольку на вход кодера символы поступают со скоростью k элементов в единицу времени, а на выходе формируется поток со скоростью n элементов в единицу времени, то для согласования скоростей необходимо буферное устройство памяти, содержащее k ячеек. Информация в буферную память записывается в последовательном коде и на (k+1)-м такте в параллельном коде поступает в кодирующее устройство. Сформированная n-разрядная комбинация в параллельном коде записывается в буферный регистр, откуда с нужной скоростью поступает в канал связи. Поскольку скорость работы кодирующего устройства может быть значительно выше, чем скорость поступления входной информации, то кодер всегда работает в реальном масштабе времени передачи информации.
Дата: 2019-12-22, просмотров: 435.