Язык микроопераций. Ассемблер.
Структура программы на ассемблере:
Model small ;модель программы, или же количество памяти на сегмент
. data ;сегмент данных
;описание переменных
. stack 100 h ;сегмент стека
. code ;сегмент данных
;процедуры, макрокоманды
main :
;основная программа
End main
Директивы резервирования памяти
Для описания простых типов данных в программе используются специальные директивы резервирования и инициализации данных, которые, по сути, являются указаниями транслятору на выделение определенного объема памяти. Если проводить аналогию с языками высокого уровня, то директивы резервирования и инициализации данных являются определениями переменных.
Машинного эквивалента этим директивам нет; просто транслятор, обрабатывая каждую такую директиву, выделяет необходимое количество байт памяти и при необходимости инициализирует эту область некоторым значением .
Директивы резервирования и инициализации данных простых типов имеют формат:
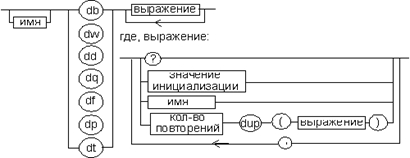
Рис. 5. Директивы описания данных простых типов
На рис. 5 использованы следующие обозначения:
· ? показывает, что содержимое поля не определено, то есть при задании директивы с таким значением выражения содержимое выделенного участка физической памяти изменяться не будет. Фактически, создается неинициализированная переменная;
· значение инициализации — значение элемента данных, которое будет занесено в память после загрузки программы. Фактически, создается инициализированная переменная, в качестве которой могут выступать константы, строки символов, константные и адресные выражения в зависимости от типа данных. Подробная информация приведена в приложении 1;
· выражение — итеративная конструкция с синтаксисом, описанным на рис. 5.17. Эта конструкция позволяет повторить последовательное занесение в физическую память выражения в скобках n раз.
· имя — некоторое символическое имя метки или ячейки памяти в сегменте данных, используемое в программе.
· db — резервирование памяти для данных размером 1 байт. Директивой db можно задавать следующие значения:
o выражение или константу, принимающую значение из диапазона:
§ для чисел со знаком –128...+127;
§ для чисел без знака 0...255;
o символьную строку из одного или более символов. Строка заключается в кавычки. В этом случае определяется столько байт, сколько символов в строке.
· dw — резервирование памяти для данных размером 2 байта. Директивой dw можно задавать следующие значения:
o выражение или константу, принимающую значение из диапазона:
§ для чисел со знаком –32 768...32 767;
§ для чисел без знака 0...65 535;
o выражение, занимающее 16 или менее бит, в качестве которого может выступать смещение в 16-битовом сегменте или адрес сегмента;
o 1- или 2-байтовую строку, заключенная в кавычки.
· dd — резервирование памяти для данных размером 4 байта. Директивой dd можно задавать следующие значения:
o выражение или константу, принимающую значение из диапазона:
§ для i386 и выше:
§ для чисел со знаком –2 147 483 648...+2 147 483 647;
§ для чисел без знака 0...4 294 967 295;
o относительное или адресное выражение, состоящее из 16-битового адреса сегмента и 16-битового смещения;
o строку длиной до 4 символов, заключенную в кавычки.
· df — резервирование памяти для данных размером 6 байт;
· dp — резервирование памяти для данных размером 6 байт. Директивами df и dp можно задавать следующие значения:
o выражение или константу, принимающую значение из диапазона:
§ для чисел со знаком –2 147 483 648...+2 147 483 647;
§ для чисел без знака 0...4 294 967 295;
o относительное или адресное выражение, состоящее из 32 или менее бит (для i80386) или 16 или менее бит (для младших моделей микропроцессоров Intel);
o адресное выражение, состоящее из 16-битового сегмента и 32-битового смещения;
o строку длиной до 6 байт, заключенную в кавычки.
· dq — резервирование памяти для данных размером 8 байт. Директивой dq можно задавать следующие значения:
o относительное или адресное выражение, состоящее из 32 или менее бит
o константу со знаком из диапазона –263...263–1;
o константу без знака из диапазона 0...264–1;
o строку длиной до 8 байт, заключенную в кавычки.
· dt — резервирование памяти для данных размером 10 байт. Директивой dt можно задавать следующие значения:
o относительное или адресное выражение, состоящее из 32 или менее бит
o адресное выражение, состоящее из 16-битового сегмента и 32-битового смещения;
o константу со знаком из диапазона –279...279-1;
o константу без знака из диапазона 0...280-1;
o строку длиной до 10 байт, заключенную в кавычки;
o упакованную десятичную константу в диапазоне 0...99 999 999 999 999 999 999.
Очень важно уяснить себе порядок размещения данных в памяти. Он напрямую связан с логикой работы микропроцессора с данными. Микропроцессоры Intel требуют следования данных в памяти по принципу: младший байт по младшему адресу.
Для иллюстрации данного принципа рассмотрим листинг 1, в котором определим сегмент данных. В этом сегменте данных приведено несколько директив описания простых типов данных.
Листинг 1. Пример использования директив резервирования и инициализации данных. Программа вводит строку с клавиатуры.model small . stack 100 h .datamessage db 'Массив байт, содержащих символьные переменные',10,13 '$'po db 1, 3, 4, 5, 0fh, 0bh, 32, 01011bperem_1 db 0ffh perem_2 dw 3a7fhperem_3 dd 0f54d567ahk1 db 10k2 db ?mas db 10 dup ('?')adr dw k1adr_full dd perem_3 .code start: mov ax,@data mov ds,ax mov ah,0ah mov dx,offset message ; mov dx, adr int 21h mov ax,4c00h int 21hEnd start
Система команд
Логические команды
Любая логическая команда меняет значение следующих флагов of, sf,zf,pf,cf (переполнение, знак, нуля, паритет, перенос)
and операнд_1,операнд_2 — операция логического умножения (И - конъюнкция).
оп1:=оп1 ٧ оп2
and ah, 0a1h; ah:=ah٧0ah
and bx, cx; bx:=bx٧cx
and dx, x1; dx:=dx٧x1
or операнд_1,операнд_2 — операция логического сложения (ИЛИ - дизъюнкцию)
or al, x1; оп1:=оп1 & оп2
or eax,edx
or dx, x1
xor операнд_1,операнд_2 — операция логического исключающего сложения (исключающего ИЛИ ИЛИ-НЕ)
test операнд_1,операнд_2 — операция “проверить” (способом логического умножения).
Команда выполняет поразрядно логическую операцию И над битами операндов операнд_1 и операнд_2. Состояние операндов остается прежним, изменяются только флаги zf, sf, и pf, что дает возможность анализировать состояние отдельных битов операнда без изменения их состояния.
not операнд — операция логического отрицания. Команда выполняет поразрядное инвертирование (замену значения на обратное) каждого бита операнда. Результат записывается на место операнда.
Пример программы логического сложения двух однобайтных чисел.
model small .stack 100h .datax1 db 0c2hx2 db 022hy db ? .code start: mov ax,@data mov ds,ax mov al, x1or al, x2mov y, al mov ax,4c00h int 21 hEnd start
End start
Умножение двоичных чисел
mul множитель_1 - операция умножения двух целых чисел без учета знака
Алгоритм работы:
Команда выполняет умножение двух операндов без учета знаков. Алгоритм зависит от формата операнда команды и требует явного указания местоположения только одного сомножителя, который может быть расположен в памяти или в регистре. Местоположение второго сомножителя фиксировано и зависит от размера первого сомножителя
mul dl; ax:=al*dl, dl- множитель_1 , al- множитель_2
mul x1; dx:ax=ax*0ad91h, x1 word- множитель_1 , ax- множитель_2
mul ecx; edx:eax=eax*ecx, ecx- множитель_1 , eax- множитель_2
imul множитель_1 - операция умножения двух целочисленных двоичных значений со знаком
Деление двоичных чисел
div делитель - выполнение операции деления двух двоичных беззнаковых значений
Алгоритм работы:
Для команды необходимо задание двух операндов — делимого и делителя. Делимое задается неявно и размер его зависит от размера делителя, который указывается в команде
div dl ;ah:al=ax/dl, ax –делимое, dl- делитель , ah-частное, al -остаток
div x1 ;ax:dx=dx:ax/0ad91h, dx:ax –делимое, x1 word- делитель , ax-частное,
;dx -остаток
div ecx ;eax:edx=edx:eax/ecx, edx:eax –делимое, ecx- делитель , eax-частное,
;edx -остаток
idiv делитель - операция деления двух двоичных значений со знаком
Пример программы умножения двух однобайтных чисел.
model small .stack 100h .datax1 db 78yl db ?yh db ? .code start: mov ax,@data mov ds,ax xor ax, ax mov al, 25 mul x1 jnc m1 ;если нет переполнения mov yh,ahm1: mov yl, al mov ax,4c00h int 21hend start
Пример. Вычислите следующее выражение у=(х2-х3)/х1, х1,х2,х3 - однобайтные числа
Model small
Stack 100h
Data
s1 db 'Введите х1',10,13,'$'
s2 db 'Введите х2',10,13,'$'
s3 db 'Введите х3',10,13,'$'
x1 db ?
x2 db ?
yc db ? ;частное
yo db ? ;остаток
Code
start:
mov ax,@data
Mov ds,ax
 |
mov ah,09h
mov dx, offset s1
int 21h ;вывод строки
mov ah,01h вводим х1
int 21h ;вводим число
sub al,30h ;al:=x1
mov x1,al
mov ah,09h
 mov dx, offset s2
mov dx, offset s2
int 21h
mov ah,01h вводим х2
int 21h
sub al,30h ;al:=x2
mov x2,al
mov ah,09h
 mov dx, offset s3
mov dx, offset s3
int 21h
mov ah,01h вводим х3
int 21h
sub al,30h ;al:=x3
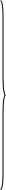 |
mov bl,x2 ;bl:=x2
sub bl,al ;bl:=x2-x3
xchg al,bl ;al:=bl, al:=x2-x3
xor ah,ah ;ax:=x2-x3 вычисляем у
mov dl,x1 ;dl:=x1
div dl ;ax/dl, ax/x1
mov yc,ah
mov yo,al
; можно вывести результат на экран
Mov ax ,4 c 00 h
Int 21h
End start
Команды сдвига
Все команды сдвига обеспечивают манипуляции над отдельными битами операндов, они перемещают биты в поле операнда влево или вправо в зависимости от кода операции.
Все команды сдвига устанавливают флаг переноса cf.
shl операнд,счетчик_сдвигов (Shift Logical Left) - логический сдвиг влево. Содержимое операнда сдвигается влево на количество битов, определяемое значением счетчик_сдвигов. Справа (в позицию младшего бита) вписываются нули;
shr операнд,счетчик_сдвигов — логический сдвиг вправо.
|
Алгоритм работы команд:
· очередной “выдвигаемый” бит устанавливает флаг cf;
· бит, вводимый в операнд с другого конца, имеет значение 0;
· при сдвиге очередного бита он переходит во флаг cf, при этом значение предыдущего сдвинутого бита теряется!
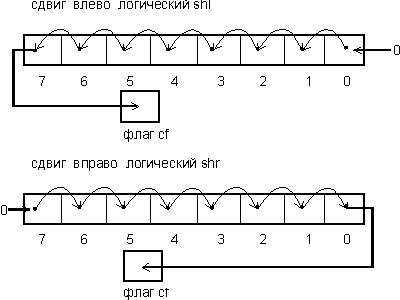
sal операнд,счетчик_сдвигов (Shift Arithmetic Left)
sar операнд,счетчик_сдвигов
арифметический сдвиг влево/вправо. Содержимое операнда сдвигается влево/ вправо на количество битов, определяемое значением счетчик_сдвигов. Справа/ Слева в операнд вписываются нули.
Команда sal не сохраняет знака, но устанавливает флаг cf в случае смены знака очередным выдвигаемым битом. В остальном команда sal полностью аналогична команде shl;
Команда sar сохраняет знак, восстанавливая его после сдвига каждого очередного бита.
Команды циклического сдвига
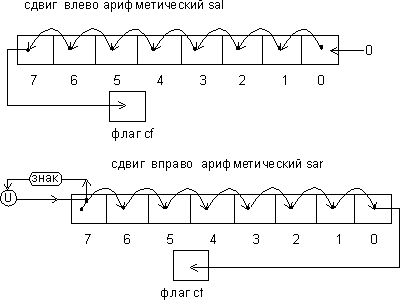
rol операнд , счетчик _ сдвигов (Rotate Left) — циклический сдвиг влево.
Содержимое операнда сдвигается влево на количество бит, определяемое операндом счетчик_сдвигов. Сдвигаемые влево биты записываются в тот же операнд справа.
ror операнд,счетчик_сдвигов (Rotate Right) — циклический сдвиг вправо.
|
Как видно из рис., команды простого циклического сдвига в процессе своей работы осуществляют одно полезное действие, а именно: циклически сдвигаемый бит не только вдвигается в операнд с другого конца, но и одновременно его значение становиться значением флага cf.
Команды циклического сдвига через флаг переноса cf отличаются от команд простого циклического сдвига тем, что сдвигаемый бит не сразу попадает в операнд с другого его конца, а записывается сначала в флаг переноса cf. Лишь следующее исполнение данной команды сдвига (при условии, что она выполняется в цикле) приводит к помещению выдвинутого ранее бита с другого конца операнда (см. рис. 4).
rcl операнд,счетчик_сдвигов (Rotate through Carry Left) — циклический сдвиг влево через перенос.
Содержимое операнда сдвигается влево на количество бит, определяемое операндом счетчик_сдвигов. Сдвигаемые биты поочередно становятся значением флага переноса cf.
rcr операнд,счетчик_сдвигов (Rotate through Carry Right) — циклический сдвиг вправо через перенос.
Содержимое операнда сдвигается вправо на количество бит, определяемое операндом счетчик_сдвигов. Сдвигаемые биты поочередно становятся значением флага переноса cf.
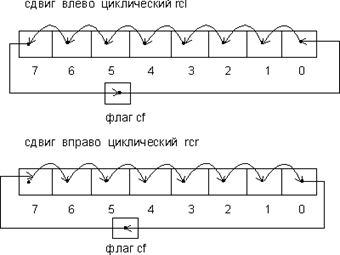
Из рис. 4 видно, что при сдвиге через флаг переноса появляется промежуточный элемент, с помощью которого, в частности, можно производить подмену циклически сдвигаемых битов, в частности, рассогласование битовых последовательностей.
Под рассогласованием битовой последовательности здесь и далее подразумевается действие, которое позволяет некоторым образом локализовать и извлечь нужные участки этой последовательности и записать их в другое место
Пример. Дано отрицательное число. Выведите на экран его значение по модулю деленное на 2.
Любое отрицательное число хранится в дополнительном формате
-1 ffh
-2 feh
…
-10 f6h
получить значение числа по модулю, можно осуществив логическое отрицание над числом и добавив 1.
Model small
Stack 100h
Data
x db -12
Code
start:
mov ax,@data
Mov ds,ax
mov al,x ;в al отрицательное число
not al
inc al ;число по модулю
shr al,1
;выводим результат на экран
aam ;
;преобразование двоичного числа меньшего 63h (9910), которое находится в al в его ;неупакованный BCD-эквивалент
; -разделить значение регистра al на 10;
; -записать частное в регистр ah, остаток — в регистр al.
mov dx,ax ;число в регистр dx
or dx,3030h ;получаю ASCII код числа
xchg dh,dl ;меняю местами старший и младший байт, для вывода символа из dl
mov ah,02h ;
int 21h ;вывожу старшую половинку числа
xchg dh,dl ;меняю местами старший и младший байт,
int 21h ;вывожу младшую половинку числа
Mov ax,4c00h
Int 21h
End start
Команды передачи управления
По принципу действия, команды микропроцессора, обеспечивающие организацию переходов в программе, можно разделить на три группы:
1. Команды безусловной передачи управления:
- команда безусловного перехода; jmp
- вызова процедуры и возврата из процедуры; call, ret
- вызова программных прерываний и возврата из программных прерываний. Int, iret
2. Команды условной передачи управления:
- команды перехода по результату команды сравнения cmp;
- команды перехода по состоянию определенного флага;
- команды перехода по содержимому регистра ecx/cx.
3. Команды управления циклом:
- команда организации цикла со счетчиком ecx/cx;
- команда организации цикла со счетчиком ecx/cx с возможностью досрочного выхода из цикла по дополнительному условию.
jmp адрес_перехода - безусловный переход без сохранения информации о точке возврата. Аналог goto.
jmp m1 m4:
… …
m1: jmp m4
Условные переходы
Команды условного перехода имеют одинаковый синтаксис:
jcc метка_перехода
Мнемокод всех команд начинается с “j” — от слова jump (прыжок), cc — определяет конкретное условие, анализируемое командой. Что касается операнда метка_перехода, то эта метка может находится только в пределах текущего сегмента кода, межсегментная передача управления в условных переходах не допускается.
Для того чтобы принять решение о том, куда будет передано управление командой условного перехода, предварительно должно быть сформировано условие, на основании которого и будет приниматься решение о передаче управления. Источниками такого условия могут быть:
- любая команда, изменяющая состояние арифметических флагов;
- команда сравнения cmp, сравнивающая значения двух операндов;
- состояние регистра ecx/cx.
Условные переходы по содержимому флагов
| Название флага | Номер бита в eflags/flag | Команда условного перехода | Значение флага для осуществления перехода |
| Флаг переноса cf | 1 | jc | cf = 1 |
| Флаг четности pf | 2 | jp | pf = 1 |
| Флаг нуля zf | 6 | jz | zf = 1 |
| Флаг знака sf | 7 | js | sf = 1 |
| Флаг переполнения of | 11 | jo | of = 1 |
| Флаг переноса cf | 1 | jnc | cf = 0 |
| Флаг четности pf | 2 | jnp | pf = 0 |
| Флаг нуля zf | 6 | jnz | zf = 0 |
| Флаг знака sf | 7 | jns | sf = 0 |
| Флаг переполнения of | 11 | jno | of = 0 |
jcxz метка_перехода (Jump if cx is Zero) — переход, если cx ноль;
jecxz метка_перехода (Jump Equal ecx Zero) — переход, если ecx ноль.
Пример программы: определите, равны ли два числа вводимые пользователем с клавиатуры.
Model small
Stack 100h
Data
s1 db 'числа равны$'
s2 db 'числа не равны$'
.code
start:
mov ax,@data
mov ds,ax
mov ah,01h
int 21h ;ввели первое число
mov dl,al
mov ah,01h
int 21h ;ввели второе число
sub al,dl ;сравнили числа
jnz m1
mov dx, offset s1
jmp m2
m1: mov dx, offset s2
m2: mov ah,09h
int 21h ;выводим информационную строку
Mov ax ,4 c 00 h
Int 21h
End start
Команда сравнения cmp
cmp операнд_1,операнд_2 - сравнивает два операнда и по результатам сравнения устанавливает флаги. Команда сравнения cmp имеет интересный принцип работы. Он абсолютно такой же, как и у команды вычитания sub. Единственное, чего она не делает — это запись результата вычитания на место первого операнда.
Алгоритм работы:
-выполнить вычитание (операнд1-операнд2);
-в зависимости от результата установить флаги, операнд1 и операнд2 не изменять (то есть результат не запоминать).
Условные переходы после команд сравнения
| Типы операндов | Мнемокод команды условного перехода | Критерий условного перехода | Значения флагов для осществления перехода |
| Любые | je | операнд_1 = операнд_2 | zf = 1 |
| Любые | jne | операнд_1<>операнд_2 | zf = 0 |
| Со знаком | jl/jnge | операнд_1 < операнд_2 | sf <> of |
| Со знаком | jle/jng | операнд_1 <= операнд_2 | sf <> of or zf = 1 |
| Со знаком | jg/jnle | операнд_1 > операнд_2 | sf = of and zf = 0 |
| Со знаком | jge/jnl | операнд_1 => операнд_2 | sf = of |
| Без знака | jb/jnae | операнд_1 < операнд_2 | cf = 1 |
| Без знака | jbe/jna | операнд_1 <= операнд_2 | cf = 1 or zf=1 |
| Без знака | ja/jnbe | операнд_1 > операнд_2 | cf = 0 and zf = 0 |
| Без знака | jae/jnb | операнд_1 => операнд_2 | cf = 0 |
Пример программы: определите, равны ли два числа вводимые пользователем с клавиатуры.
Model small
Stack 100h
Data
s1 db 'числа равны$'
s2 db 'числа не равны$'
.code
start:
mov ax,@data
mov ds,ax
mov ah,01h
int 21h ;ввели первое число
mov dl,al
mov ah,01h
int 21h ;ввели второе число
cmp al,dl ;сравнили числа
jne m1
mov dx, offset s1
jmp m2
m1: mov dx, offset s2
m2: mov ah,09h
int 21h ;выводим информационную строку
Mov ax ,4 c 00 h
Int 21h
end start
Организация циклов
loop метка_перехода (Loop) — повторить цикл
Работа команды заключается в выполнении следующих действий:
- декремента регистра ecx/cx;
- сравнения регистра ecx/cx с нулем:
- если (ecx/cx) > 0, то управление передается на метку перехода;
- если (ecx/cx) = 0, то управление передается на следующую после loop команду
mov cx, количество циклов
м1: тело цикла
loop m1
loope/loopz метка_перехода (Loop till cx <> 0 or Zero Flag = 0) — повторить цикл, пока cx <> 0 или zf = 0.
loopne/loopnz метка_перехода (Loop till cx <> 0 or Not Zero flag=0) — повторить цикл пока cx <> 0 или zf = 1
Недостаток команд организации цикла loop, loope/loopz и loopne/loopnz в том, что они реализуют только короткие переходы (от –128 до +127 байт).
Организация вложенных циклов
mov cх,n ; в сх заносим количество итераций внешнего цикла
m1:
push cx

 …
…
mov cx,n1; в сх заносим количество итераций внутреннего цикла
m2:
тело внутреннего цикла
loop m2
…
pop cx
loop m1
Пример программы: Напишите программу подсчета у=1+2+3+…+n, n не более 10000.
model small
.stack 100h
.data
yb dd ?
ym dw ?
s1 db 'введите n',10,13,'$'
.code
start:
mov ax,@data
mov ds,ax
mov dx, offset s1
mov ah,09h
int 21h
mov cx,3
 m: shl bx,4
m: shl bx,4
mov ah,01h
int 21h вводим n в регистр bx
sub ax,130h
add bx,ax
loop m
mov cx,bx
xor dx,dx
xor al,al
m1: add dx,cx считаем у
jnc m2
mov al,1
m2: loop m1
cmp al,1
je m3
mov ym,dx
m3: mov yb,edx
mov ax,4c00h
int 21h
end start
Цепочечные команды
(Команды обработки строк символов)
Цепочка – это последовательность элементов, размер которых может быть байт, слово, двойное слово. Содержимое этих элементов может быть любое – символы, числа.
В системе команд микропроцессора имеется семь операций-примитивов обработки цепочек.
Каждая из них реализуется в микропроцессоре тремя командами, в свою очередь, каждая из этих команд работает с соответствующим размером элемента — байтом, словом или двойным словом.
Вместе с цепочечными командами обычно применяют префиксы повторений, которые ставятся перед командой в поле [метки]. Цепочечная команда без префикса выполняется один раз. С префиксом цепочечные команды выполняются циклично.
rep (REPeat) - команда выполняется, пока содержимое в ecx/cx не станет равным 0. При этом цепочечная команда, перед которой стоит префикс, автоматически уменьшает содержимое ecx/cx на единицу. Та же команда, но без префикса, этого не делает.
repe или repz (REPeat while Equal or Zero) - команда выполняется до тех пор, пока содержимое ecx/cx не равно нулю или флаг zf равен 1. Как только одно из этих условий нарушается, управление передается следующей команде программы
repne или repnz (REPeat while Not Equal or Zero) - команда циклически выполняется до тех пор, пока содержимое ecx/cx не равно нулю или флаг zf равен нулю. При невыполнении одного из этих условий работа команды прекращается.
Формирования физического адреса операндов адрес_источника и адрес_приемника происходит следующим образом:
адрес_источника — пара ds:esi/si;
адрес_приемника — пара es:edi/di
Важный момент, касающийся всех цепочечных команд, — это направление обработки цепочки. Есть две возможности:
- от начала цепочки к ее концу, то есть в направлении возрастания адресов;
- от конца цепочки к началу, то есть в направлении убывания адресов.
Цепочечные команды сами выполняют модификацию регистров, адресующих операнды, обеспечивая тем самым автоматическое продвижение по цепочке. Количество байт, на которые эта модификация осуществляется, определяется кодом команды. А вот знак этой модификации определяется значением флага направления df (Direction Flag) в регистре eflags/flags. Состоянием флага df можно управлять с помощью двух команд, не имеющих операндов:
cld (Clear Direction Flag) — очистить флаг направления df = 0, значение индексных регистров esi/si и edi/di будет автоматически увеличиваться (операция инкремента) цепочечными командами, то есть обработка будет осуществляться в направлении возрастания адресов;
std (Set Direction Flag) — установить флаг направления df = 1, то значение индексных регистров esi/si и edi/di будет автоматически уменьшаться (операция декремента) цепочечными командами, то есть обработка будет идти в направлении убывания адресов.
Типовой набор действий для выполнения любой цепочечной команды:
- Установить значение флага df в зависимости от того, в каком направлении будут обрабатываться элементы цепочки — в направлении возрастания или убывания адресов.
- Загрузить указатели на адреса цепочек в памяти в пары регистров ds:(e)si и es: (e)di.
- Загрузить в регистр ecx/cx количество элементов, подлежащих обработке.
- Выдать цепочечную команду с префиксом повторений.
Пересылка цепочек
movs адрес_прием, адрес_источника (MOVe String)- переслать цепочку;
movsb MOVe String Byte) — переслать цепочку байт;
movsw (MOVe String Word) — переслать цепочку слов;
movsd (MOVe String Double word) — переслать цепочку двойных слов.
Команда копирует байт, слово или двойное слово из цепочки источника, в цепочку приемника. Размер пересылаемых элементов ассемблер определяет, исходя из атрибутов идентификаторов. К примеру, если эти идентификаторы были определены директивой db, то пересылаться будут байты, если идентификаторы были определены с помощью директивы dd, то пересылке подлежат двойные слова.
Для цепочечных команд с операндами типа movs адрес_приемника,адрес_источника, не существует машинного аналога. При трансляции в зависимости от типа операндов транслятор преобразует ее в одну из трех машинных команд: movsb, movsw или movsd.
Сама по себе команда movs пересылает только один элемент, исходя из его типа, и модифицирует значения регистров esi/si и edi/di. Если перед командой написать префикс rep, то одной командой можно переслать до 64 Кбайт данных. Число пересылаемых элементов должно быть загружено в счетчик — регистр cx (use16) или ecx (use32).
Пример проги. Пересылка строк командой movs
MODEL small
STACK 256
.data
source db 'Тестируемая строка','$' ;строка-источник
dest db 19 DUP (' ') ;строка-приёмник
.code
main:
mov ax,@data ;загрузка сегментных регистров
mov ds,ax ;настройка регистров DS и ES на адрес сегмента данных
mov es,ax
cld ;сброс флага DF — обработка строки от начала к концу
lea si,source ;загрузка в si смещения строки-источника
lea di,dest ;загрузка в DS смещения строки-приёмника
mov cx,20 ;для префикса rep — счетчик повторений (длина строки)
rep movs dest,source ;пересылка строки
lea dx,dest
mov ah,09h ;вывод на экран строки-приёмника
int 21h
mov ax,4c00h
int 21h
end main
Операция сравнения цепочек
cmps адрес_приемника,адрес_источника(CoMPare String) — сравнить строки;
cmpsb (CoMPare String Byte) — сравнить строку байт;
cmpsw (CoMPare String Word) — сравнить строку слов;
cmpsd (CoMPare String Double word) — сравнить строку двойных слов.
Алгоритм работы команды cmps заключается в последовательном выполнении вычитания (элемент цепочки-источника — элемент цепочки-получателя) над очередными элементами обеих цепочек. Принцип выполнения вычитания командой cmps аналогичен команде сравнения cmp. Она, так же, как и cmp, производит вычитание элементов, не записывая при этом результата, и устанавливает флаги zf, sf и of.
После выполнения вычитания очередных элементов цепочек командой cmps, индексные регистры esi/si и edi/di автоматически изменяются в соответствии со значением флага df на значение, равное размеру элемента сравниваемых цепочек.
Чтобы заставить команду cmps выполняться несколько раз, то есть производить последовательное сравнение элементов цепочек, необходимо перед командой cmps определить префикс повторения. С командой cmps можно использовать префикс повторения repe/repz или repne/repnz:
- repe или repz — если необходимо организовать сравнение до тех пор, пока не будет выполнено одно из двух условий: достигнут конец цепочки (содержимое ecx/cx равно нулю) или в цепочках встретились разные элементы (флаг zf стал равен нулю);
- repne или repnz — если нужно проводить сравнение до тех пор, пока: не будет достигнут конец цепочки (содержимое ecx/cx равно нулю) или в цепочках встретились одинаковые элементы (флаг zf стал равен единице).
Пример программы Сравнение двух строк командой cmps
MODEL small
STACK 256
.data
sov db 0ah,0dh,'Строки совпадают.','$'
nesov db 0ah,0dh,'Строки не совпадают','$'
s1 db '0123456789',0ah,0dh,'$';исследуемые строки
s2 db 10
s3 db 11 dup (0)
.code
main:
mov ax,@data ;загрузка сегментных регистров
mov ds,ax
mov es,ax ;настройка ES на DS
;вводим строку
mov ah, 0аh
mov dx, offset s2
int 21h
;поиск совпадающих элементов, сброс флага DF - сравнение в направлении возрастания адресов
cld
lea si,s1 ;загрузка в si смещения string1
lea di,s3 ;загрузка в di смещения string2
mov cx,10 ;длина строки для префикса repe
repe cmpsb ;сравнение строк (пока сравниваемые элементы строк равны)
;выход при обнаружении не совпавшего элемента
jcxz equal ;cx=0, то есть строки совпадают
lea dx, nesov
jmp exit ;выход
equal: lea dx, sov
exit: mov ah,09h
int 21h ;вывод сообщения
mov ax,4c00h
int 21h
end main ;конец программы
Операция сканирования цепочек
scas адрес_приемника (SCAning String) — сканировать цепочку;
scasb (SCAning String Byte) — сканировать цепочку байт;
scasw (SCAning String Word) — сканировать цепочку слов;
scasd (SCAning String Double Word) — сканировать цепочку двойных слов
Эти команды осуществляют поиск искомого значения, которое находится в регистре al/ax/eax. Принцип поиска тот же, что и в команде сравнения cmps, то есть последовательное выполнение вычитания
(содержимое регистра_аккумулятора – содержимое очередного_элемента_цепочки).
В зависимости от результатов вычитания производится установка флагов, при этом сами операнды не изменяются.
Так же, как и в случае команды cmps, с командой scas удобно использовать префиксы repe/repz или repne/repnz:
- repe или repz — если нужно организовать поиск до тех пор, пока не будет выполнено одно из двух условий: достигнут конец цепочки (содержимое ecx/cx равно 0) или в цепочке встретился элемент, отличный от элемента в регистре al/ax/eax;
- repne или repnz — если нужно организовать поиск до тех пор, пока не будет выполнено одно из двух условий достигнут конец цепочки (содержимое ecx/cx равно 0)или в цепочке встретился элемент, совпадающий с элементом в регистре al/ax/eax.
Пример проги. найти количество * в строке
MODEL small
STACK 256
.data
s1 db 20
s2 db 21 dup ?
s3 db 'количество * в строке',0ah,0dh,'$'
.code
main:
mov ax,@data
mov ds,ax
mov es,ax ;настройка ES на DS
;вводим строку
mov ah,0ah
mov dx, offset s1
int 21h
;поиск *
mov al,'*' ;символ для поиска — `а`(кириллица)
cld ;сброс флага df
lea di, s2 ;загрузка в es:di смещения строки
inc di ;первый элемент в s3 это количество введенных символов, его игнорируем
xor bl ;обнуляем счетчик звездочек
mov cx,20 ;для префикса repne — длина строки
m1: repne scasb ;пока искомый символ и символ в строке не совпадут идет поиск, ;выход при совпадении
je found ;если равны - переход на обработку
;вывод количества звездочек в строке
mov ah,09h
mov dx,offset s3
int 21h ;вывод сообщения nochar
mov al,bl
aam
or ax, 3030h
mov dx,ax
xchg dh,dl
mov ah, 02h
int 21h
xchg dh,dl
int 21h
mov ax,4c00h
int 21h
;суммируем количество звездочек
found: inc bl
jmp m1
end main
Пример .
| Model small .stack 100h .data w db 25 dup (?) .code vvod proc mov ah, 0ah lea dx, w int 21h ret vvod endp main: | … Call schet Call vvod … exit: mov ax,4c00h int 21h schet proc .. ret schet endp end main |
Макрокоманда является одним из многих механизмов замены текста программы. С помощью макрокоманды в текст программы можно вставлять последовательности строк и привязывать их к месту вставки.
Макрокоманда представляет собой строку, содержащую некоторое имя – имя макрокоманды, предназначенное для того, чтобы быть замещенным одной или несколькими другими строками при трансляции.
Для работы с макрокомандой вначале необходимо задать ее шаблон-описание, так называемое макроопределение.
Имя_макрокоманды MACRO [список_формальных_аргументов]
<Тело макроопределения>
ENDM
Существует три варианта расположения макроопределений:
- в начале исходного текста программы до сегмента кода и данных с тем, чтобы не ухудшать читабельность программы. В данном случае макрокоманды будут актуальны только в пределах этой программы;
- в отдельном файле. Для того, чтобы использовать эти макроопределения в других программах, необходимо в начале исходного текста этих программ записать директиву
include имя_файла
- в макробиблиотеке. Макробиблиотека создается в том случае, когда написанные макросы используются практически во всех программах. Подключается библиотека директивой include. Недостаток этого и предыдущего методов в том, что в исходный текст программы включаются абсолютно все макроопределения. Для исправления ситуации можно использовать директиву purge, в качестве операндов которой перечисляются макрокоманды, которые не должны включаться в текст программы.
Include macrobibl.inc ;в исходный текст программы будут вставлены строки из macrobibl.inc
Purge outstr, exit ;за исключением макроопределений outstr, exit
Активизация макроса осуществляется следующим образом:
Имя_макрокоманды список_ фактических_ аргументов
| Model small Vivod macro rg Mov dl, rg Mov ah, 02h Int 21h endm .data .. .code .. vivod al .. | Model small sravnenie macro rg, met cmp rg , ‘a’ ja met add rg, 07h met: add rg, 30h endm .data .. .code .. sravnenie al, m1 .. |
Функционально макроопределения похожи на процедуры. Сходство их в том, что и те, и другие достаточно один раз где-то описать, а затем вызывать их специальным образом. На этом их сходство заканчивается, и начинаются различия, которые в зависимости от целевой установки можно рассматривать и как достоинства и как недостатки:
- в отличие от процедуры, текст которой неизменен, макроопределение в процессе макрогенерации может меняться в соответствии с набором фактических параметров. При этом коррекции могут подвергаться как операнды команд, так и сами команды. Процедуры в этом отношении объекты менее гибки;
- при каждом вызове макрокоманды ее текст в виде макрорасширения вставляется в программу. При вызове процедуры микропроцессор осуществляет передачу управления на начало процедуры, находящейся в некоторой области памяти в одном экземпляре. Код в этом случае получается более компактным, хотя быстродействие несколько снижается за счет необходимости осуществления переходов.
Подключение процедур и макросов во внешнем файле
Внешний файл с расширением inc, а в файле которой использует процедуру или макрос присутствуют следующие строки
Model small
Include [NAME].INC
А вызов макросов и процедур как обычно.
Работа с портами ввода вывода
Адресное пространство памяти в любой микропроцессорной системе семейства х86 делится на пространство адресов памяти и пространство портов ввода/вывода. Это обусловлено архитектурной реализацией и исторической эволюцией процессоров х86.
Для обращения к пространству ввода/вывода используются команды in , out , ins , outs.
In регистр, номер порта – ввод данных из порта в регистр
Out номер порта, регистр – вывод данных из регистра в порт
Ins , Outs - работают с элементами строки памяти.
In ax, 064h ; запись слова в ах из порта 064h
Out 064,al ; запись байта в порт
In ax, dx ; косвенная адресация порта через регистр dx, применяется при использовании 16 разрядного адреса порта
Через порты ввода/вывода осуществляется программирование, контроль и отладка работы периферийных устройств. Зачастую один адрес памяти может служить портом ввода при чтении данных, и портом вывода при записи.
Распределением адресов управляет BIOS через регистры конфигурирования чипсета. Обычно для совместимости аппаратного и программного обеспечения распределение адресов стандартно для любых микропроцессорных систем семейства х86.
ВЫЧИСЛИТЕЛЬНЫЕ СИСТЕМЫ
Состав любой вычислительной системы одинаков: микропроцессор, электронная память подсистема ввода-вывода. Эти устройство объединяет системная шина, состоящая из следующих шин: данных, адреса и управления.
Каждый микропроцессор имеет определенное число элементов памяти, называемых регистрами, арифметико-логическое устройство и устройство управления. Регистры используются для временного хранения выполняемой команды, адресов памяти, обрабатываемых данных и другой внутренней информации МП. В АЛУ производится арифметическая и логическая обработка данных. Устройство управления реализует временную диаграмму и вырабатывает необходимые управляющие сигналы для внутренней работы МП и связи его с другой аппаратурой через внешние шины МП.
Структуры различных типов МП могут существенно различаться, однако наиболее важными параметрами являются архитектура, адресное пространство памяти, разрядность шины данных, быстродействие. Архитектуру МП определяет разрядность слова и внутренней шины данных МП. Первые МП основывались на 4-разрядной архитектуре. Первые ПЭВМ использовали МП с 8-разрядной архитектурой, а современные МП основаны на МП с 64- и 32-разрядной архитектурой.
Микропроцессоры используют последовательный принцип выполнения команд, принцип параллельной работы, или конвейерный метод выполнения команд.
Последовательный принцип, при котором очередная операция начинается только после выполнения предыдущей.
Принцип параллельной работы, при которой одновременно с выполнением текущей команды производятся предварительная выборка и хранение последующих команд.
В МП с 32-разрядной архитектурой используется конвейерный метод выполнения команд, при котором несколько внутренних устройств МП работают параллельно, производя одновременно обработку нескольких последовательных команд программы.
Адресное пространство памяти определяется разрядностью адресных регистров и адресной шины МП. Для выборки команд и обмена данными с памятью МП имеют шину данных, разрядность которой, как правило, совпадает с разрядностью внутренней шины данных, определяемой архитектурой МП.
Одним из важных параметров МП является быстродействие, определяемое тактовой частотой его работы, которая обычно задается внешними синхросигналами. Выполнение простейших команд (например, сложение двух операндов из регистров или пересылка операндов в регистрах МП) требует минимально двух периодов тактовых импульсов (для выборки команды и ее выполнения). Более сложные команды требуют для выполнения до 10—20 периодов тактовых импульсов. Если операнды находятся не в регистрах, а в памяти, дополнительное время расходуется на выборки операндов в регистры и записи результата в память.
Скорость работы МП определяется не только тактовой частотой, но и набором его команд, их гибкостью, развитой системой прерываний.
Электронная память
Содержит операнды и программу, которую выполняет МП. Используются два типа электронной памяти: постоянные запоминающие устройства (ПЗУ) и оперативные запоминающие устройства (ОЗУ).
В ПЗУ хранится информация, которую ЭВМ может использовать сразу же после включения питания. Она включает программы инициализации периферийных микросхем, программы ядра ОС и программы обработки прерываний.
Постоянное запоминающее устройство является энергонезависимой памятью: после выключения питания информация в нем сохраняется. Информация в ОЗУ разрушается при выключении питания.
В ОЗУ хранятся оперативные данные и программы, используемые МП. Поэтому микросхемы ОЗУ по быстродействию должны быть согласованы с МП, а емкость ОЗУ (вместе с ПЗУ) должна приближаться к пределу, определяемому адресным пространством МП.
Схемы ввода-вывода
Связь МП с контроллерами ПУ обычно осуществляется через порты ввода-вывода под непосредственным управлением МП или под управлением специализированных контроллеров. Связь МП с ПУ производится через стандартизованные интерфейсы ПУ.
Организация и быстродействие схемы ввода-вывода влияет на быстродействие всей вычислительной системы.
Микропроцессоры
Архитектура однокристального 16-ти разрядного микропроцессора К1810ВМ86.
Аналог I 8086.
Ориентирован на параллельное выполнение выборки и команд, может быть условно разделен на две части, работающие асинхронно: устройство сопряжения с магистралью (БИ – интерфейсный блок) и блок обработки (БО).
Интерфейсный блок обеспечивает формирование 20-разрядного физического адреса памяти, выборку команд и операндов из памяти, организацию очередности команд и запоминание результатов выполнения команд в памяти.
БИ состоит из очереди команд, сегментных регистров, регистра адреса команд, сумматора адреса (SM) и управления машинными циклами.
Устройство сопряжения готово выполнить цикл выборки слова из памяти всякий раз, когда в очереди освобождаются, по меньшей мере, два байта, БО извлекает из нее коды команд по мере необходимости. Очередь организована по принципу «первым пришел — первого обслужили», а шесть ее уровней позволяют удовлетворять запросы БО в кодах команд достаточно эффективно, сокращая тем самым до минимума затраты времени МП на ожидание выборки команд из памяти. Выполнение команд происходит в логической последовательности, предписанной программой, поскольку в очереди находятся те команды, которые хранились в ячейках памяти, непосредственно следующих за текущей командой. При передаче управления в другую ячейку памяти ход выполнения программы нарушается. Устройство сопряжения очищает регистры очереди, выбирает команду по адресу перехода, передает ее УО и начинает новое заполнение этих регистров. При возврате из подпрограммы или из прерывания происходит восстановление очереди команд, адреса которых автоматически вычисляются в СМА. Если МП необходимо выполнить цикл чтения или записи, то выборка команд приостанавливается на время цикла.
Блок обработки предназначен для выполнения операций по обработке данных и состоит из блока микропрограммного управления (БМУ), АЛУ, восьми регистров общего назначения (РОН) и регистра флагов (F).
Команды, выбранные БИ из памяти и записанные в очередь команд, по запросам от БО поступают в БМУ. Это устройство, содержащее память микрокоманд, декодирует команды и вырабатывает последовательность микрокоманд, управляющую процессом обработки. В АЛУ выполняются арифметические и логические операции над 8- и 16-разрядными числами с фиксированной запятой.
Программно-доступными функциональными частями МП являются регистры общего назначения (для хранения операндов и результатов выполнения команд), сегментные (для хранения базовых адресов текущих сегментов памяти), адреса команд и регистр флагов.
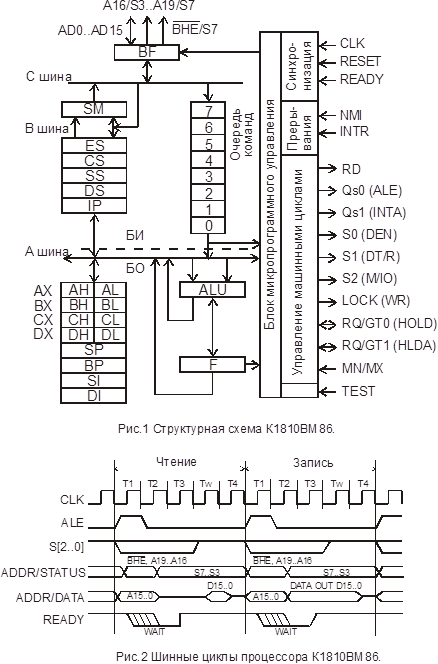
Функциональное назначение выводов микропроцессораК1810ВМ86
Вход MN/MX служит для выбора режима функционирования, который предлагает пользователю выбор состава выходных управляющих сигналов в соответствии со степенью сложности проектируемой МП-системы.
В минимальном режиме (вывод MN/MX подключен к шине питания), ориентированном на малые вычислительные системы, МП выдает сигналы управления обменом с памятью и внешними устройствами, а также обеспечивает доступ к системной магистрали по запросу прямого доступа к памяти, используя сигналы HOLD и HLDA. Если вывод MN/MX подключен к шине «Земля» (общий), то МП находится в максимальном режиме и может работать в сложных одно- и многопроцессорных системах. При работе в этом режиме изменяются функции ряда выводов МП.
| Обозначение выводов | Функциональное назначение выводов |
| AD0 .. AD15 | 16-разрядная двунаправленная мультиплексированная шина адреса/данных |
| A16/S3 .. A19/S6 | 4-х разрядная выходная шина микропроцессора, по которой в такте Т1 передаются 4 старших разряда адреса памяти, а в тактах Т2, Т3, Т4, при выполнении операций обращения к памяти и области ввода/вывода – признаки состояния микропроцессора. S4, S3 – указывают номер одного из 4 сегментных регистров, который в данном цикле участвует в формировании исполнительного адреса. S5 – указывает состояние триггера разрешения прерывания S6 – всегда равен 0. |
| BHE/S7 | Выход, 0 на котором в Т1 указывает, что по шине адреса/данных передаются 8-разрядное слово. Сделано для совместимости со старым ПО. В тактах Т2, Т3, Т4 на этом выходе присутствует S7 – признак состояния МП. Если S7=1 – МП находится в состоянии захвата шин внешним устройством. |
| RD | Чтение, выход, 0 на котором означает, что МП осуществляет чтение из памяти или портов ввода/вывода. |
| RЕАDY | Готовность, вход для подачи сигнала окончания цикла работы устройств памяти или ввода/вывода. Используется для синхронизации более медленных памяти или ВУ. |
| INTR | Вход маскируемых запросов на прерывание. Наличие запроса на этом входе анализируется в конце выполнения каждой команды |
| TEST | Вход, проверяемый по команде WFT |
| NMI | Вход немаскируемых запросов на прерывание |
| RESET | Вход начальной установки микропроцессора |
| CLK | Вход для подачи тактовых импульсов |
| MN/MX | Вход для подачи сигнала переключения минимального/максимального режима. |
| Минимальный режим | |
| INTA | Подтверждение прерывания, выходной сигнал стробирующий ввод информации в МП из источника прерывания, вызвавшего переход в режим прерывания |
| ALE | Строб адреса, выходной сигнал, стробирующий в такте Т1 передачу адресной информации с шин МП AD0 .. AD15 на другие элементы системы |
| DEN | Разрешение обмена данными, выходной сигнал, управляющий выдачей информации из шинных формирователей при выполнении команд чтения/записи. |
| DT/R | Ввод/вывод данных, выходной сигнал, указывающий на направление передачи. 1 – МП выдает информацию, 0 – МП принимает данные. |
| M/IO | Память/внешнее устройство, выходной сигнал отличающий передачу данных для памяти или для внешнего устройства. |
| WR | Запись, выходной сигнал указывающий на то, что МП выдает информацию для записи в память/ВУ. |
| HLDA | Разрешение прямого доступа, подтверждение захвата шин МП внешним устройством. |
| HOLD | Запрос прямого доступа (захвата шины) |
| Максимальный режим | |
| QS0, QS1 | Состояние очереди команд |
| S0 .. S2 | Тип цикла обмена, указывает на одну из возможных ситуаций: 000 – признак INTA 001 – ввод информации с ВУ 010 – вывод данных на ВУ 011 – останов 100 – выборка команды 101 – чтение из памяти 110 – запись в память |
| LOСK | Сигнал блокировки, индицирующий, что другое устройство не может занять системную магистраль (запрет на захват системной шины) |
| RQ/GT0, RQ/GT1 | Запрос/разрешение доступа к шине |
Шинные циклы К1810ВМ86
В максимальном режиме, управляющие сигналы системной шины вырабатываются системным контроллером по сигналам состояния процессора. Все сигналы управления (кроме ALE) активны по низкому уровню, что дает возможность раздельно управлять шиной несколькими устройствами.
Для обращения к устройствам ввода/вывода процессор имеет отдельные инструкции IN и OUT, результатом выполнения которых является формирование шинных сигналов IORD и IOWR. В циклах ввода/вывода используют только младшие 16 бит шины адреса, что позволяет адресовать до 64кбайт регистров ввода/вывода. Адрес устройства задается либо в команде, либо берется из регистра DX.
Циклы обращения к портам отличаются от циклов памяти использованием шины адреса. При обращении к портам линии адреса А16..А19 всегда содержат 0, а линии А8..А15 содержат старший байт адреса, только при косвенной адресации через регистр DX. При обращении по непосредственному адресу линии А8..А15 содержат 0.
Цикл подтверждения прерывания аналогичен циклу чтения порта но вместо сигнала IORD, активен сигнал INTA, а состояние шины адреса процессором в это время не управляется.
САМОСТОЯТЕЛЬНО
Прерывания.
Назначение и типы прерываний.
Механизм обработки программный прерываний.
Механизм обработки аппаратных прерываний.
Контроллер прерываний.
Память.
Сегментная организация памяти.
Виды памяти. ОЗУ. ПЗУ.
Типы ОЗУ: статическая память, динамическая память.
Типы ПЗУ.
Иерархия памяти.
КЭШ память.
Принципы действия КЭШ памяти.
Организация КЭШ памяти.
Распределение адресного пространства.
Новые виды памяти.
FeRAM
Ферроэлектрическая память -- Ferroelectric RAM (FeRAM), это энергонезависимый тип памяти, аналогичный Flash памяти, что означает возможность хранения данных без использования источников энергии. Чипы FeRAM имеют маленькую емкость, на уровне килобит, но производство 1 Мбит чипов FeRAM уже не за горами, этим занимается компания NEC.
DRDRAM
Технология памяти Rambus основной архитектурой для изготовления системной памяти персональных компьютеров, в результате чего с 1999 года начнется вытеснение с этого рынка памяти типа SDRAM. Зная возможности Intel, можно с большой долей уверенности сказать, что так оно и будет. Специалисты корпорация Intel опробовали различные технологии памяти типа DRAM, прежде чем остановить свой выбор на технологии Rambus. Intel лицензировала архитектуру RDRAM у компании Rambus, после чего обе фирмы начали совместные разработки по созданию нового типа памяти, получившего наименование DRDRAM (Direct RDRAM). Кстати, компания Rambus выдала лицензии на свою технологию изготовления памяти семи крупнейшим производителям чипов DRAM и около 15 производителям контроллеров. Результатом выбора корпорацией Intel технологии Rambus может стать появление более быстрой и более совершенной памяти, которая будет применятся повсеместно.
DDR SDRAM
Новый тип памяти DDR SDRAM (Double Data Rate SDRAM), появился в следствии улучшений архитектуры SDRAM, поэтому другое название этого типа памяти - SDRAM II. Лидерство в разработке этого типа памяти принадлежит корпорации Samsung. В настоящее время многие крупные производители чипов памяти заявили о намерении продвигать эту архитектуру. Однако, в свете того, что Intel собирается продвигать другую архитектуру памяти - DRDRAM, будущее DDR SDRAM представляется туманным.
Память типа DDR SDRAM может передавать и принимать данные по восходящему и нисходящему уровню сигнала шины, в отличие от обычной памяти типа SDRAM, которая передает данные только по восходящему уровню сигнала. При этом команды и адреса в DDR SDRAM все равно передаются по верхнему фронту сигнала. Память типа DDR SDRAM имеет большую ширину полосы пропускания, но только в случае передачи длинных пакетов данных. Максимальная величина ширины полосы пропускания DDR SDRAM может достигать 1.6 Гб/сек при частоте шины 100MHz.
Осенью 1998 компания Fujitsu Microelectronics представит первые образцы модулей DIMM, созданных по технологии DDR SDRAM. Работает эта память на частоте 125 Мгц, с пропускной способностью около 200 миллионов операций в секунду, что примерно соответствует DRDRAM. При всех своих достоинствах, эта технология прекрасно работает с нынешними машинами, являясь эволюционным развитием DRAM, в отличие от совершенно новой технологии Rambus, для которой опять понадобятся новые чипсеты системных плат и т.д.
ESDRAM
Enhanced SDRAM (ESDRAM - улучшенная SDRAM) -- более быстрая версия SDRAM, сделанная в соответствии со стандартом JEDEC компанией Enhanced Memory Systems (EMS). С точки зрения времени доступа производительность ESDRAM в два раза выше по сравнению со стандартной SDRAM. В большинстве приложений ESDRAM, благодаря более быстрому времени доступа к массиву SDRAM и наличию кэша, обеспечивает даже большую производительность, чем DDR SDRAM.
Более высокая скорость работы ESDRAM достигается за счет дополнительных функций, которые используются в архитектуре этой памяти. ESDRAM имеет строку кэш-регистров (SRAM), в которых хранятся данные, к которым уже было обращение. Доступ к данным в строке кэша осуществляется быстрее, чем к ячейкам SDRAM, со скоростью 12 ns, т.к. не требуется обращаться к данным в строке через адрес в колонке. При этом скорость работы ячеек ESDRAM составляет 22 ns в отличие от стандартной скорости работы ячеек SDRAM, имеющей значения 50 - 60 ns.
При этом стоит заметить, что память ESDRAM полностью совместима со стандартной памятью JEDEC SDRAM на уровне компонентов и модулей, по количеству контактов и функциональности. Однако, чтобы использовать все преимущества этого типа памяти, необходимо использовать специальный контроллер (чипсет).
Увеличение производительности при использовании ESDRAM достигается за счет применения двухбанковой архитектуры, которая состоит из массива SDRAM и SRAM строчных регистров (кэш). Строчные регистры вместе с быстрым массивом SDRAM обеспечивают более быстрый доступ для чтения и записи данных по сравнению со стандартной SDRAM. ESDRAM может работать в режиме "упреждающего обращения" к массиву SDRAM, в результате следующий цикл записи или чтения может начаться в момент, когда выполнение текущего цикла не завершено. Возможность использовать такой режим напрямую зависит от центрального процессора, управляющего работой конвейера адресации.
С точки зрения применения в качестве системной (оперативной) памяти компьютера чипсет VCS-164 (Polaris) компании VLSI Technology поддерживает ESDRAM, правда, этот чипсет рассчитан для применения в системах на базе процессора Digital Alpha. ESDRAM полностью соответствует спецификации Intel PC-100 SDRAM, и соответственно, совместима с чипсетами Intel 440BX и Via Technologies MVP-3.
FCRAM
Fast Cycle Random Access Memory (FCRAM). Разработчик этого типа памяти - компания Fujitsu. В основу этого типа памяти легла принципиально иная концепция по сравнению с DRAM. Время выполнения цикла соответствует всего 20нс, т.е. в 3-4 раза меньше, чем у нынешних модулей DRAM. Это достигнуто благодаря двум принципиальным моментам. Во-первых, в отличие от современных чипов памяти, где сначала выясняется адрес строки (RAS), а потом, после некоторой задержки, адрес столбца (CAS), где находится нужная ячейка, в FCRAM мгновенно выясняются обе координаты. Во-вторых, существующая память типа DRAM имеет время выполнения цикла 70нс, из-за того, что после выполнения каждой операции над ячейкой должна пройти команда сброса. В FCRAM же встроена цепь автоматического сброса, благодаря чему возможна конвейерная обработка команд, где следующая команда начинает выполняться еще до окончания выполнения предыдущей. Итог - время выполнения цикла - 20нс. В результате мы получаем очень интересный гибрид. По скорости работы FCRAM более напоминает SRAM, а по объему - обычную память DRAM.
MRAM
MRAM - Magnetic random access memory. Разработчик - компания Toshiba. Уже есть пробный образец основной структуры чипа MRAM, воплощающего в себе новую технологию памяти, потенциально способную превзойти существующие типы DRAM и по скорости, и по объему, и по энергопотреблению. Уже этот тестовый образец демонстрирует выдающиеся скоростные качества - цикл чтения занимает всего 6 нс.
Согласно заявлению компании, технология хранения информации в чипе MRAM заключается в создании элемента с мелкими частицами платины и кобальта, находящихся между двумя магнитными слоями. Запись и чтение происходят путем изменения магнитной активности в контуре.
ПРОГРАММНАЯ МОДЕЛЬ ПРОЦЕССОРОВ СЕМЕЙСТВА X 86
Пользовательские регистры
Как следует из названия, пользовательскими регистры называются потому, что программист может использовать их при написании своих программ. К этим регистрам относятся (рис. 1):
· восемь 32-битных регистров, которые могут использоваться программистами для хранения данных и адресов (их еще называют регистрами общего назначения (РОН)):
o eax/ax/ah/al;
o ebx/bx/bh/bl;
o edx/dx/dh/dl;
o ecx/cx/ch/cl;
o ebp/bp;
o esi/si;
o edi/di;
o esp/sp.
· шесть регистров сегментов: cs, ds, ss, es, fs, gs;
· регистры состояния и управления:
o регистр флагов eflags/flags;
o регистр указателя команды eip/ip.
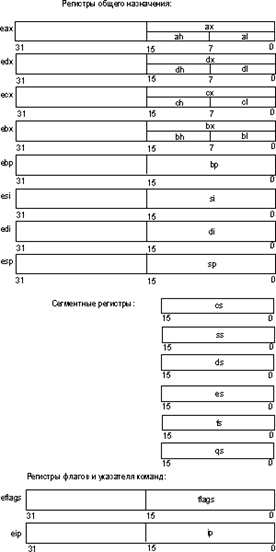
Рис. 1. Пользовательские регистры микропроцессоров i486 и Pentium
Почему многие из этих регистров приведены с наклонной разделительной чертой?
Нет, это не разные регистры — это части одного большого 32-разрядного регистра. Их можно использовать в программе как отдельные объекты.
Так сделано для обеспечения работоспособности программ, написанных для младших 16-разрядных моделей микропроцессоров фирмы Intel, начиная с i8086.
Микропроцессоры i486 и Pentium имеют в основном 32-разрядные регистры. Их количество, за исключением сегментных регистров, такое же, как и у i8086, но размерность больше, что и отражено в их обозначениях — они имеют приставку e (Extended).
Регистры общего назначения
Все регистры этой группы позволяют обращаться к своим “младшим” частям.
Для самостоятельной адресации можно использовать только младшие 16 и 8-битные части этих регистров. Старшие 16 бит этих регистров как самостоятельные объекты недоступны. Это сделано, как мы отметили выше, для совместимости с младшими 16-разрядными моделями микропроцессоров фирмы Intel.
Перечислим регистры, относящиеся к группе регистров общего назначения. Так как эти регистры физически находятся в микропроцессоре внутри арифметико-логического устройства (АЛУ), то их еще называют регистрами АЛУ:
· eax/ax/ah/al (Accumulator register) — аккумулятор.
Применяется для хранения промежуточных данных. В некоторых командах использование этого регистра обязательно;
· ebx/bx/bh/bl (Base register) — базовый регистр.
Применяется для хранения базового адреса некоторого объекта в памяти;
· ecx/cx/ch/cl (Count register) — регистр-счетчик.
Применяется в командах, производящих некоторые повторяющиеся действия. Его использование зачастую неявно и скрыто в алгоритме работы соответствующей команды.
К примеру, команда организации цикла loop кроме передачи управления команде, находящейся по некоторому адресу, анализирует и уменьшает на единицу значение регистра ecx/cx;
· edx/dx/dh/dl (Data register) — регистр данных.
Так же, как и регистр eax/ax/ah/al, он хранит промежуточные данные. В некоторых командах его использование обязательно; для некоторых команд это происходит неявно.
Следующие два регистра используются для поддержки так называемых цепочечных операций, то есть операций, производящих последовательную обработку цепочек элементов, каждый из которых может иметь длину 32, 16 или 8 бит:
· esi/si (Source Index register) — индекс источника.
Этот регистр в цепочечных операциях содержит текущий адрес элемента в цепочке-источнике;
· edi/di (Destination Index register) — индекс приемника (получателя).
Этот регистр в цепочечных операциях содержит текущий адрес в цепочке-приемнике.
В архитектуре микропроцессора на программно-аппаратном уровне поддерживается такая структура данных, как стек. Для работы со стеком в системе команд микропроцессора есть специальные команды, а в программной модели микропроцессора для этого существуют специальные регистры:
· esp/sp (Stack Pointer register) — регистр указателя стека.
Содержит указатель вершины стека в текущем сегменте стека.
· ebp/bp (Base Pointer register) — регистр указателя базы кадра стека.
Предназначен для организации произвольного доступа к данным внутри стека.
Не спешите пугаться столь жесткого функционального назначения регистров АЛУ. На самом деле, большинство из них могут использоваться при программировании для хранения операндов практически в любых сочетаниях. Но, как мы отметили выше, некоторые команды используют фиксированные регистры для выполнения своих действий. Это нужно обязательно учитывать.
Использование жесткого закрепления регистров для некоторых команд позволяет более компактно кодировать их машинное представление. Знание этих особенностей позволит вам при необходимости хотя бы на несколько байт сэкономить память, занимаемую кодом программы.
Сегментные регистры cs, ss, ds, es, gs, fs.
Их существование обусловлено спецификой организации и использования оперативной памяти микропроцессорами Intel. Она заключается в том, что микропроцессор аппаратно поддерживает структурную организацию программы в виде трех частей, называемых сегментами. Соответственно, такая организация памяти называется сегментной.
Для того чтобы указать на сегменты, к которым программа имеет доступ в конкретный момент времени, и предназначены сегментные регистры. Фактически, с небольшой поправкой, как мы увидим далее, в этих регистрах содержатся адреса памяти с которых начинаются соответствующие сегменты. Логика обработки машинной команды построена так, что при выборке команды, доступе к данным программы или к стеку неявно используются адреса во вполне определенных сегментных регистрах. Микропроцессор поддерживает следующие типы сегментов:
1. Сегмент кода. Содержит команды программы.
Для доступа к этому сегменту служит регистр cs (code segment register) — сегментный регистр кода. Он содержит адрес сегмента с машинными командами, к которому имеет доступ микропроцессор (то есть эти команды загружаются в конвейер микропроцессора).
2. Сегмент данных. Содержит обрабатываемые программой данные. Для доступа к этому сегменту служит регистр ds (data segment register) — сегментный регистр данных, который хранит адрес сегмента данных текущей программы.
3. Сегмент стека. Этот сегмент представляет собой область памяти, называемую стеком. Работу со стеком микропроцессор организует по следующему принципу: последний записанный в эту область элемент выбирается первым. Для доступа к этому сегменту служит регистр ss (stack segment register) — сегментный регистр стека, содержащий адрес сегмента стека.
4. Дополнительный сегмент данных.
Неявно алгоритмы выполнения большинства машинных команд предполагают, что обрабатываемые ими данные расположены в сегменте данных, адрес которого находится в сегментном регистре ds.
Если программе недостаточно одного сегмента данных, то она имеет возможность использовать еще три дополнительных сегмента данных. Но в отличие от основного сегмента данных, адрес которого содержится в сегментном регистре ds, при использовании дополнительных сегментов данных их адреса требуется указывать явно с помощью специальных префиксов переопределения сегментов в команде.
Адреса дополнительных сегментов данных должны содержаться в регистрах es, gs, fs (extension data segment registers).
Регистры состояния и управления eflags и ip
Они постоянно содержат информацию о состоянии, как самого микропроцессора, так и программы, команды которой в данный момент загружены на конвейер. Используя эти регистры, можно получать информацию о результатах выполнения команд и влиять на состояние самого микропроцессора.
eflags/flags (flag register) — регистр флагов. Разрядность eflags/flags — 32/16 бит. Отдельные биты данного регистра имеют определенное функциональное назначение и называются флагами. Младшая часть этого регистра полностью аналогична регистру flags для i8086.
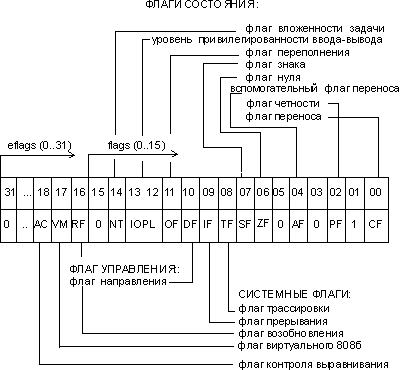

Рис. 2. Содержимое регистра eflags
Исходя из особенностей использования, флаги регистра eflags/flags можно разделить на три группы:
· 8 флагов состояния. Эти флаги могут изменяться после выполнения машинных команд. Флаги состояния регистра eflags отражают особенности результата исполнения арифметических или логических операций. Это дает возможность анализировать состояние вычислительного процесса и реагировать на него с помощью команд условных переходов и вызовов подпрограмм.
· 1 флаг управления - df (Directory Flag). Значение флага df определяет направление поэлементной обработки цепочек данных: от начала строки к концу (df = 0) либо наоборот, от конца строки к ее началу (df = 1).
· 5 системных флагов, управляющих вводом/выводом, маскируемыми прерываниями, отладкой, переключением между задачами и виртуальным режимом 8086. Прикладным программам не рекомендуется модифицировать без необходимости эти флаги, так как в большинстве случаев это приведет к прерыванию работы программы.
eip/ip (Instraction Pointer register) — регистр-указатель команд.
Регистр eip/ip имеет разрядность 32/16 бит и содержит смещение следующей подлежащей выполнению команды относительно содержимого сегментного регистра cs в текущем сегменте команд. Этот регистр непосредственно недоступен программисту, но загрузка и изменение его значения производятся различными командами управления, к которым относятся команды условных и безусловных переходов, вызова процедур и возврата из процедур. Возникновение прерываний также приводит к модификации регистра eip/ip.
Типы данных. Переменные
В программе на ассемблере переменными являются регистры или ячейки памяти, в которых хранятся данные. Существует несколько типов данных-переменных:
1. Непосредственные данные, представляющие собой числовые или символьные значения, являющиеся частью команды. 20d, 0a2h, 10111b
2. Данные простого типа, описываемые с помощью ограниченного набора директив резервирования памяти, позволяющих выполнить самые элементарные операции по размещению и инициализации числовой и символьной информации.
Эти два типа данных являются элементарными, или базовыми; работа с ними поддерживается на уровне системы команд микропроцессора. Используя данные этих типов, можно формализовать и запрограммировать практически любую задачу. Но насколько это будет удобно — вот вопрос.
3. Данные сложного типа, (массивы, структуры, записи и пр.) которые были введены в язык ассемблера с целью облегчения разработки программ. Сложные типы данных строятся на основе базовых типов, которые являются как бы кирпичиками для их построения. Введение сложных типов данных позволяет несколько сгладить различия между языками высокого уровня и ассемблером
Физическая интерпретация данных простого типа основывается на размерности данных:
· байт — восемь последовательно расположенных битов, пронумерованных от 0 до 7, при этом бит 0 является самым младшим значащим битом;
· слово — последовательность из двух байт, имеющих последовательные адреса. Размер слова — 16 бит; биты в слове нумеруются от 0 до 15. Байт, содержащий нулевой бит, называется младшим байтом, а байт, содержащий 15-й бит - старшим байтом. Микропроцессоры Intel имеют важную особенность — младший байт всегда хранится по меньшему адресу. Адресом слова считается адрес его младшего байта. Адрес старшего байта может быть использован для доступа к старшей половине слова.
· двойное слово — последовательность из четырех байт (32 бита), расположенных по последовательным адресам.
· учетверенное слово — последовательность из восьми байт (64 бита), расположенных по последовательным адресам.
· 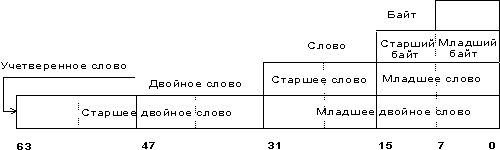
Рис. 3. Основные типы данных микропроцессора
Логическая интерпретация этих типов:
- Целый тип со знаком — двоичное значение со знаком, размером 8, 16 или 32 бита. Знак в этом двоичном числе содержится в 7, 15 или 31-м бите соответственно. Ноль в этих битах в операндах соответствует положительному числу, а единица — отрицательному. Отрицательные числа представляются в дополнительном коде. Числовые диапазоны для этого типа данных следующие:
o 8-разрядное целое — от –128 до +127;
o 16-разрядное целое — от –32 768 до +32 767;
o 32-разрядное целое — от –231 до +231–1.
- Целый тип без знака — двоичное значение без знака, размером 8, 16 или 32 бита. Числовой диапазон для этого типа следующий:
o байт — от 0 до 255;
o слово — от 0 до 65 535;
o двойное слово — от 0 до 232–1.
- Указатель на память двух типов:
o ближнего типа — 32-разрядный логический адрес, представляющий собой относительное смещение в байтах от начала сегмента. Эти указатели могут также использоваться в сплошной (плоской) модели памяти, где сегментные составляющие одинаковы;
o дальнего типа — 48-разрядный логический адрес, состоящий из двух частей: 16-разрядной сегментной части — селектора, и 32-разрядного смещения.
- Цепочка — представляющая собой некоторый непрерывный набор байтов, слов или двойных слов максимальной длины до 4 Гбайт.
- Битовое поле представляет собой непрерывную последовательность бит, в которой каждый бит является независимым и может рассматриваться как отдельная переменная. Битовое поле может начинаться с любого бита любого байта и содержать до 32 бит.
- Неупакованный двоично-десятичный тип — байтовое представление десятичной цифры от 0 до 9. Неупакованные десятичные числа хранятся как байтовые значения без знака по одной цифре в каждом байте. Значение цифры определяется младшим полубайтом.
- Упакованный двоично-десятичный тип представляет собой упакованное представление двух десятичных цифр от 0 до 9 в одном байте. Каждая цифра хранится в своем полубайте. Цифра в старшем полубайте (биты 4–7) является старшей.
-
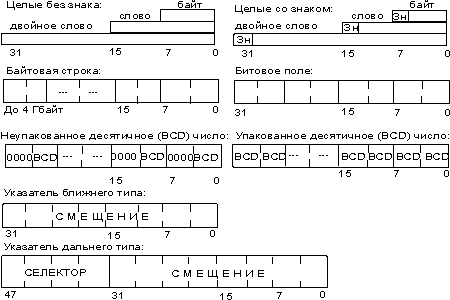
Рис. 4. Основные логические типы данных микропроцессора
Дата: 2019-12-22, просмотров: 394.