Избыточность изображения обусловлена наличием сильных корреляционных связей между значениями яркости смежных пикселов, кроме того, избыточность обусловлена также тем, что неравномерность распределения плотности вероятности их значений мала. Различие в вероятности появления тех или иных уровней яркости невелико. Сказанное поясняется рис.2.1, на котором приведена плотность вероятности значений яркости в исходном изображении 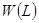 .
.
Рис.2.1.
Первым шагом при сжатии изображений с использованием энтропийного кодирования является декорреляция кодируемой последовательности, при которой устраняются статистические связи между кодируемыми отсчетами и уже затем производится кодирование статистически независимых отсчетов. Простейшим, но не оптимальным способом декорреляции является преобразование последовательности отсчетов кодируемого сигнала, представляющего яркость пикселов изображения 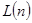 , в последовательность отсчетов приращений этой яркости
, в последовательность отсчетов приращений этой яркости  при переходе с одного пиксела на другой, т.е.
при переходе с одного пиксела на другой, т.е.
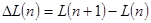 ,
,
где 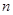 - номер отсчета. В результате такого преобразования статистические связи между кодируемыми отсчетами сильно ослабляются, а распределение плотности вероятности их значений становится резко неравномерным. Отмеченное поясняется рис. 2.2, на котором приведена плотность вероятности приращения яркости
- номер отсчета. В результате такого преобразования статистические связи между кодируемыми отсчетами сильно ослабляются, а распределение плотности вероятности их значений становится резко неравномерным. Отмеченное поясняется рис. 2.2, на котором приведена плотность вероятности приращения яркости  . Из сопоставления рис. 2.1 и рис. 2.2 видно, что во втором случае плотность вероятности распределения приращений резко неравномерна, благодаря чему сигнал последовательности приращений обладает большой избыточностью, а следовательно, может быть в большей степени сжат.
. Из сопоставления рис. 2.1 и рис. 2.2 видно, что во втором случае плотность вероятности распределения приращений резко неравномерна, благодаря чему сигнал последовательности приращений обладает большой избыточностью, а следовательно, может быть в большей степени сжат.
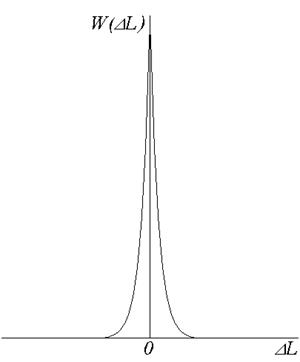
Рис.2.2
Рис.2.3
Кодирование длин серий
Кодирование длин серий или как его еще называют RLE (Run-Length Encoding) в настоящее время широко применяется при записи графических изображений в файлы либо как самостоятельный метод, либо в составе более сложных алгоритмов кодирования, применяемых в различных форматах графических файлов, например в JPEG. Этот метод применяется также в таких распространенных форматах, как PCX, TIFF и TARGA.
Многие графические изображения, например, чертежи, плакаты и т.п. включают в себя значительные однородные области, имеющие одинаковые яркость и цвет. При разложении таких изображений в растр наличие однородных областей приводит к появлению в строках последовательностей отсчетов, имеющих одни и те же значения, как показано на рис. 2.4. Эта особенность позволяет при их сжатии расходовать меньше двоичных единиц, чем при традиционном методе кодирования, записывая лишь длину серии (число повторений одинаковых отсчетов) и значение яркости, с которого начинается
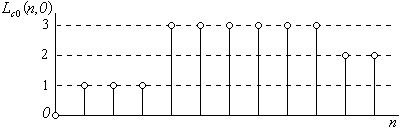
Рис.2.4.
серия. Так при использовании метода кодирования длин серий для кодирования отсчетов яркости, показанных на рис. 2.4, получим следующую кодовую последовательность: 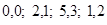 . Из изложенного следует, что при использовании этого метода в кодируемом сигнале устраняются (строго говоря, ослабляются) корреляционные связи.
. Из изложенного следует, что при использовании этого метода в кодируемом сигнале устраняются (строго говоря, ослабляются) корреляционные связи.
Определим величину коэффициента сжатия, которое обеспечивается при использовании этого метода. Учитывая, что для записи числа повторений одинаковых отсчетов в последовательности, максимальная протяженность которой равна 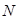 , необходимо затратить
, необходимо затратить 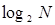 двоичных единиц, а также необходимо затратить
двоичных единиц, а также необходимо затратить 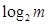 двоичных единиц для записи значения самой величины, где
двоичных единиц для записи значения самой величины, где 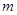 - число уровней квантования яркости в кодируемом изображении, найдем, что затрата двоичных единиц для записи последовательности составит
- число уровней квантования яркости в кодируемом изображении, найдем, что затрата двоичных единиц для записи последовательности составит
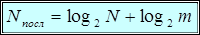 .
.
Обозначая вероятность нового значения, т.е. вероятность появления последовательности, через 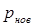 , а число строк в изображении и число отсчетов в строке, соответственно через
, а число строк в изображении и число отсчетов в строке, соответственно через  и
и 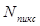 , найдем, что полная затрата двоичных единиц кода для записи изображения будет равна
, найдем, что полная затрата двоичных единиц кода для записи изображения будет равна 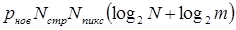 . Принимая во внимание, что при традиционном кодировании для записи такого изображения потребуется
. Принимая во внимание, что при традиционном кодировании для записи такого изображения потребуется  двоичных единиц, находим, что коэффициент сжатия
двоичных единиц, находим, что коэффициент сжатия 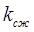 , обеспечиваемое от применения метода кодирования длин серий составит
, обеспечиваемое от применения метода кодирования длин серий составит
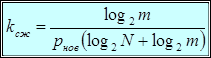 .
.
Из этой формулы видно, что коэффициент сжатия сильно зависит от вероятности появления новых значений  . При малых значениях вероятности новых значений коэффициент сжатия оказывается большим, но быстро убывает при ее увеличении. К сожалению, статистика полутоновых изображений такова, что при 256 уровнях квантования практически каждый новый отсчет (пиксел) представляет новое значение, т.е.
. При малых значениях вероятности новых значений коэффициент сжатия оказывается большим, но быстро убывает при ее увеличении. К сожалению, статистика полутоновых изображений такова, что при 256 уровнях квантования практически каждый новый отсчет (пиксел) представляет новое значение, т.е.  . Обращаясь к формуле, видим, что при
. Обращаясь к формуле, видим, что при 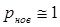 коэффициент сжатия оказывается меньше единицы, т.е. применение описанного метода приводит не к сокращению числа двоичных единиц, а к увеличению. Объясняется это тем, что в этом случае дополнительная затрата двоичных единиц идет на представление длительности последовательностей, хотя их протяженность почти всегда равна единице.
коэффициент сжатия оказывается меньше единицы, т.е. применение описанного метода приводит не к сокращению числа двоичных единиц, а к увеличению. Объясняется это тем, что в этом случае дополнительная затрата двоичных единиц идет на представление длительности последовательностей, хотя их протяженность почти всегда равна единице.
Недостатком этого метода является также его низкая помехоустойчивость. Даже редкие помехи приводят либо к появлению на изображениях протяженных штрихов, поскольку помеха изменяет значение яркости всей последовательности, либо, что еще хуже, к “раздергиванию” строк, если помеха искажает данные о числе повторения отсчета в последовательности. Достоинством же этого метода является простота его реализации. Отмеченные особенности определили и область его применения, а именно при записи графических изображений, в том числе цветных, содержащих большие однородные поля.
Кодирование методом LZW
В настоящее время метод LZW (Алгоритм сжатия, с адаптивностью и использованием кодов переменной длины с максимальной длиной 12 двоичных единиц.), используется в форматах записи как графической, так и гипертекстовой информации: GIF, TIFF, PDF.
6.1 ПРИНЦИПЫ МЕТОДА СЖАТИЯ LZW
Принципы метода сжатия LZW. Пусть сжатию подлежит черно-белое полутоновое изображение, проквантованное по яркости на 256 уровней. Сжатие начинается с того, что строится (инициализируется) первоначальная таблица кодов, в которой каждому уровню квантования сопоставляется код, представляющий собой двоичную запись номера уровня квантования. Так, например, нулевому уровню квантования приписывается значение кода - 0, первому уровню квантования значение - 1, и т.д., 255-му уровню квантования значение -255. Такая таблица содержит 256 значений кода. Далее в таблицу записываются еще два кода: код очистки, которому присваивается значение 256 и код конца записи -257. Код очистки используют для того, чтобы не произошло переполнение таблицы, которая по принятому соглашению может включать коды протяженностью не более 12 двоичных единиц (числа до 4096). Он необходим, так как по мере заполнения таблицы и соответствующего увеличения кода имеет место переход к кодам протяженностью в 10, 11 и 12 двоичных единиц, Код очистки инициализирует таблицу заново, стирая в ней все коды, начиная с 258 и выше и освобождая тем самым место для кодового представления встречающихся в изображении комбинаций символов. Код конца записи, как это видно из его названия, сигнализирует о том, что кодируемая последовательность окончилась. После завершения подготовительных операций алгоритм готов к началу сжатия данных (изображения).
Алгоритм сжатия данных:
· Инициализировать, т.е. ввести первоначальную таблицу кодов;
· Очистить таблицу кодов, начиная с кода 258 и до конца;
· Очистить буфер строки ( String ), буфер строки ( Test ) и буфер строки ( Byte ).
· Далее в цикле:
а) Прочитать очередной байт кодируемых данных в буфер ( Byte ).
б) Сцепить (конкатенировать) String + Byte и поместить результат в буфер Test .
в) Проверить, имеется ли в таблице кодов код, соответствующий комбинации, помещенной в буфер Test ?
- если имеется, то содержимое буфера Test переписать в буфер String и перейти в начало цикла;
- если нет, то добавить в таблицу код, соответствующий содержимому буфера Test , присвоив ему значение, совпадающее со следующим свободным порядковым номером, вывести в выходной поток код, соответствующий содержимому буфера String , переписать содержимое буфера Byte в String и перейти в начало цикла.
· Работа программы заканчивается тем, что делаются записи в выходной поток кода содержимого String и кода конца записи.
В результате применения такого алгоритма получаем коды переменной длины, причем для сочетаний из двух-трех символов, каждый из которых в отдельности описывается в таблице 8-разрядным кодом, длина полученных кодов будет составлять не 16 и не 24 бита, а существенно меньшей.
Декодированию (декомпрессии) сжатых данных.
Декодирующий алгоритм, получая коды комбинаций исходных отсчетов, составляет по ним кодовую таблицу идентичную той, которую составляет кодирующий алгоритм.
Декодирующий алгоритм:
· Прочитать новый код сжатых данных ( Newcode ).
· Если Newcode представляет собой код конца записи, то завершить работу.
· Если Newcode представляет собой код очистки, то необходимо:
а) проинициализировать таблицу кодов;
б) прочитать следующий код сжатых данных (если это будет код конца записи, то завершить работу);
в) найти Newcode в кодовой таблице и вывести соответствующую ему декомпрессированную последовательность отсчетов;
г) скопировать Newcode в буфер, где был записан предыдущий код ( Prevcode ).
· Если же Newcode находится в таблице, но не является ни кодом очистки, ни кодом конца записи, то необходимо:
а) вывести соответствующую ему декомпрессированную последовательность отсчетов;
б) взять первый байт декомпрессированного кода Newcode и декомпрессированного кода Prevcode, конкатенировать их и добавить в кодовую таблицу;
г) скопировать Newcode в буфер, где хранится Prevcode .
Если Newcode в таблице отсутствует, а, кроме того, он не является кодом очистки и кодом конца записи, то необходимо:
а) конкатенировать и вывести значение декомпрессированного кода Prevcode+ первый байт того же значения;
б) добавить в таблицу элемент для вышеприведенного значения;
в) скопировать Newcode в буфер Prevcode .
Метод сжатия LZW может быть применен не только для сжатия данных, каждая единица которых имеет размер в один байт, например, отсчетов яркости черно-белого полутонового изображения, но также и для сжатия данных, имеющих произвольный размер. В этом случае кодовые последовательности этих данных объединяются в группы по 8 двоичных единиц. Так если каждый отсчет содержит 4 двоичных единицы, то объединение в группы происходит по два отсчета, а если один отсчет представлен 16 двоичными единицами кода, то такая кодовая последовательность делится пополам. Величина сжатия, обеспечиваемая при использовании этого метода, невелика и лежит обычно в пределах 2 – 3 раза.
Метод кодирования Хаффмена
Этот метод позволяет получить код с минимальной средней длиной при заданном распределении вероятностей значений некоррелированных отсчетов сигналов. Особенностью этого метода кодирования является использование кодов переменной длины, при этом наиболее вероятным символам присваиваются наиболее короткие кодовые слова, а менее вероятным – длинные.
На рис. 2.5 показано кодовое дерево применительно к случаю кодирования шести символов A1, A2,
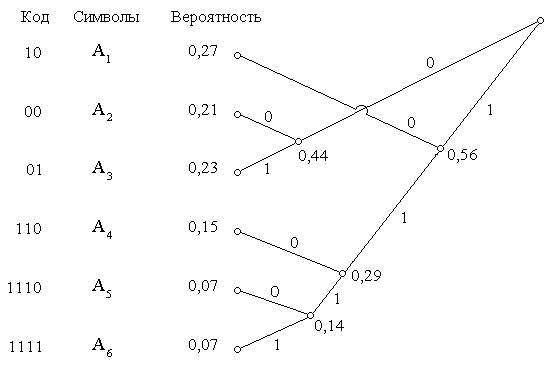
Рис.2.5.
A3, A4, A5, A6 и приведены вероятности, с которыми они появляются. Построение кодовой таблицы начинается с того, что два символа с наименьшими вероятностями объединяются в узел кодового дерева, которому приписывается их суммарная вероятность. Речь идет о символах A5 и A6, суммарная вероятность которых равна 0,14. Далее объединяются следующие символы или узлы с наименьшей вероятностью, как это показано на рисунке. Этот процесс продолжается до тех пор, пока ветви кодового дерева не сойдутся к одному узлу, расположенному в вершине. После этого ветви дерева в зависимости от того, в какую сторону они расходятся от узла, обозначаются нулями или единицами (на рис. 2.5 правые ветви обозначены нулями, а левые единицами). Для того, чтобы найти значение кодового слова, которое следует приписать каждому символу, необходимо идти от вершины кодового дерева к данному символу, записывая нули или единицы, которыми обозначены пройденные ветви.
В случае применения кода Хаффмена для сжатия изображений необходимо вначале осуществить декорреляцию сигнала, которым представлено изображение, например, используя для этой цели метод кодирования длин серий, а уже затем применять кодирование по Хаффмену.
Дата: 2019-12-10, просмотров: 369.