Проблема сжатия изображений
Для записи изображений требуются достаточно большие объемы памяти, часто в единицы и даже десятки Мегабайт – а, это может оказаться недостижимым, если изображение необходимо записать на дискету или передать по Интернет. Существуют специально разработанные форматы записи графических файлов, практически каждый из которых базируется на том или ином, а иногда и на нескольких алгоритмах сжатия изображений – это является решением проблемы. Посредством сжатия (компрессии) изображений удается в несколько раз и даже в ряде случаев в десятки раз сократить цифровой поток, представляющий изображение. Например: есть отсканированная фотография – цветное изображение 1732*1165 пикселов при 24 битах на пиксел (режим True Color) требует 5,8 Мбайт. Для такого изображения при записи его в формате TIFF требуется приблизительно 4,9 Мбайт, а если использовать формат JPEG, то можно получить разные степени сжатия в зависимости от жесткости требований предъявляемых к качеству изображения. В данном случае максимально высокого качества изображение будет занимать всего 2,4 Мбайт, среднего (вполне приемлего для большинства задач) качества 0,2 Мбайт, а применение максимального сжатия позволит довести эту цифру до 0,07 Мбайта.
При записи изображений – существует еще одна существенная деталь - сохранение качества изображения. Как правило, проблема эффективного сжатия изображений решается либо без потери качества, либо с минимальными потерями, практически незаметными для зрителя. Это оказалось возможным благодаря свойственным изображениям статистической и психофизической избыточности, что позволяет произвести такое кодирование изображения, при котором для его записи потребуется существенно меньше двоичных единиц кода.
1.1 Оценка качества изображения
"Качество изображения" – это понятие, которое можно рассматривать как меру подобия сформированного изображения его входному оптическому изображению. Для определения критерия качества на практике пользуются методом экспертных оценок, а также рядом измеряемых параметров, набор которых может быть разным для информационных систем различного назначения, в которых то или иное изображение используется.
Наиболее часто оцениваемыми являются следующие
параметры:
Ø четкость, определяемая числом элементов разложения изображения по горизонтали и вертикали;
Ø воспроизведение градаций яркости внутри яркостного динамического диапазона;
Ø контраст, под которым понимают отношение максимальной яркости изображения к минимальной;
Ø отношение сигнала к шуму, определяемое как отношение размаха сигнала от черного до белого к эффективному значению шума;
Ø геометрические искажения, характеризующие точность воспроизведения координат отдельных элементов исходного изображения;
Ø цветовоспроизведение, характеризующее степень отличия цветов в полученном изображении от цветов в исходном изображении, а также ряд других параметров.
При оценке качества существует ряд дополнительных факторов
- если производится оценивание отношения сигнала к шуму для системы, конечным звеном которой является человек, то следует обращать внимание на степень видности помехи для зрителя, которая в сильной степени зависит от спектрального состава помехи. Делают оценку сигнала к взвешенному шуму (Среднеквадратичное значение шума, предварительно пропущенного через фильтр, имитирующий частотные преобразования, протекающие в зрительной системе):
- для предотвращения возникновения шума пространственной дискретизации частота пространственной дискретизации, т.е. плотность отсчетов на изображении, в соответствии с теоремой Котельникова должна по крайней мере вдвое превышать верхнюю частоту пространственного спектра дискретизируемого изображения, а во избежание появления ложных контуров на изображении число уровней квантования должно быть выбрано достаточно большим (стандартным требованием является 256 уровней квантования), что потребует достаточно большого числа бит на каждый пиксел изображения. Этим как раз и обусловливаются то большое количество двоичных единиц, которым описывается изображение, а, следовательно, и необходимость его сжатия.
Кодирование длин серий
Кодирование длин серий или как его еще называют RLE (Run-Length Encoding) в настоящее время широко применяется при записи графических изображений в файлы либо как самостоятельный метод, либо в составе более сложных алгоритмов кодирования, применяемых в различных форматах графических файлов, например в JPEG. Этот метод применяется также в таких распространенных форматах, как PCX, TIFF и TARGA.
Многие графические изображения, например, чертежи, плакаты и т.п. включают в себя значительные однородные области, имеющие одинаковые яркость и цвет. При разложении таких изображений в растр наличие однородных областей приводит к появлению в строках последовательностей отсчетов, имеющих одни и те же значения, как показано на рис. 2.4. Эта особенность позволяет при их сжатии расходовать меньше двоичных единиц, чем при традиционном методе кодирования, записывая лишь длину серии (число повторений одинаковых отсчетов) и значение яркости, с которого начинается
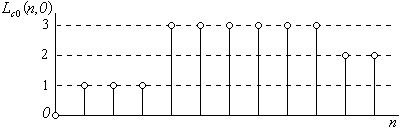
Рис.2.4.
серия. Так при использовании метода кодирования длин серий для кодирования отсчетов яркости, показанных на рис. 2.4, получим следующую кодовую последовательность: 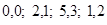 . Из изложенного следует, что при использовании этого метода в кодируемом сигнале устраняются (строго говоря, ослабляются) корреляционные связи.
. Из изложенного следует, что при использовании этого метода в кодируемом сигнале устраняются (строго говоря, ослабляются) корреляционные связи.
Определим величину коэффициента сжатия, которое обеспечивается при использовании этого метода. Учитывая, что для записи числа повторений одинаковых отсчетов в последовательности, максимальная протяженность которой равна 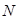 , необходимо затратить
, необходимо затратить 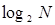 двоичных единиц, а также необходимо затратить
двоичных единиц, а также необходимо затратить 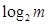 двоичных единиц для записи значения самой величины, где
двоичных единиц для записи значения самой величины, где 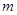 - число уровней квантования яркости в кодируемом изображении, найдем, что затрата двоичных единиц для записи последовательности составит
- число уровней квантования яркости в кодируемом изображении, найдем, что затрата двоичных единиц для записи последовательности составит
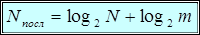 .
.
Обозначая вероятность нового значения, т.е. вероятность появления последовательности, через 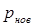 , а число строк в изображении и число отсчетов в строке, соответственно через
, а число строк в изображении и число отсчетов в строке, соответственно через  и
и 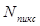 , найдем, что полная затрата двоичных единиц кода для записи изображения будет равна
, найдем, что полная затрата двоичных единиц кода для записи изображения будет равна 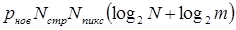 . Принимая во внимание, что при традиционном кодировании для записи такого изображения потребуется
. Принимая во внимание, что при традиционном кодировании для записи такого изображения потребуется  двоичных единиц, находим, что коэффициент сжатия
двоичных единиц, находим, что коэффициент сжатия 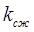 , обеспечиваемое от применения метода кодирования длин серий составит
, обеспечиваемое от применения метода кодирования длин серий составит
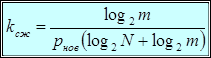 .
.
Из этой формулы видно, что коэффициент сжатия сильно зависит от вероятности появления новых значений  . При малых значениях вероятности новых значений коэффициент сжатия оказывается большим, но быстро убывает при ее увеличении. К сожалению, статистика полутоновых изображений такова, что при 256 уровнях квантования практически каждый новый отсчет (пиксел) представляет новое значение, т.е.
. При малых значениях вероятности новых значений коэффициент сжатия оказывается большим, но быстро убывает при ее увеличении. К сожалению, статистика полутоновых изображений такова, что при 256 уровнях квантования практически каждый новый отсчет (пиксел) представляет новое значение, т.е.  . Обращаясь к формуле, видим, что при
. Обращаясь к формуле, видим, что при 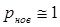 коэффициент сжатия оказывается меньше единицы, т.е. применение описанного метода приводит не к сокращению числа двоичных единиц, а к увеличению. Объясняется это тем, что в этом случае дополнительная затрата двоичных единиц идет на представление длительности последовательностей, хотя их протяженность почти всегда равна единице.
коэффициент сжатия оказывается меньше единицы, т.е. применение описанного метода приводит не к сокращению числа двоичных единиц, а к увеличению. Объясняется это тем, что в этом случае дополнительная затрата двоичных единиц идет на представление длительности последовательностей, хотя их протяженность почти всегда равна единице.
Недостатком этого метода является также его низкая помехоустойчивость. Даже редкие помехи приводят либо к появлению на изображениях протяженных штрихов, поскольку помеха изменяет значение яркости всей последовательности, либо, что еще хуже, к “раздергиванию” строк, если помеха искажает данные о числе повторения отсчета в последовательности. Достоинством же этого метода является простота его реализации. Отмеченные особенности определили и область его применения, а именно при записи графических изображений, в том числе цветных, содержащих большие однородные поля.
Кодирование методом LZW
В настоящее время метод LZW (Алгоритм сжатия, с адаптивностью и использованием кодов переменной длины с максимальной длиной 12 двоичных единиц.), используется в форматах записи как графической, так и гипертекстовой информации: GIF, TIFF, PDF.
6.1 ПРИНЦИПЫ МЕТОДА СЖАТИЯ LZW
Принципы метода сжатия LZW. Пусть сжатию подлежит черно-белое полутоновое изображение, проквантованное по яркости на 256 уровней. Сжатие начинается с того, что строится (инициализируется) первоначальная таблица кодов, в которой каждому уровню квантования сопоставляется код, представляющий собой двоичную запись номера уровня квантования. Так, например, нулевому уровню квантования приписывается значение кода - 0, первому уровню квантования значение - 1, и т.д., 255-му уровню квантования значение -255. Такая таблица содержит 256 значений кода. Далее в таблицу записываются еще два кода: код очистки, которому присваивается значение 256 и код конца записи -257. Код очистки используют для того, чтобы не произошло переполнение таблицы, которая по принятому соглашению может включать коды протяженностью не более 12 двоичных единиц (числа до 4096). Он необходим, так как по мере заполнения таблицы и соответствующего увеличения кода имеет место переход к кодам протяженностью в 10, 11 и 12 двоичных единиц, Код очистки инициализирует таблицу заново, стирая в ней все коды, начиная с 258 и выше и освобождая тем самым место для кодового представления встречающихся в изображении комбинаций символов. Код конца записи, как это видно из его названия, сигнализирует о том, что кодируемая последовательность окончилась. После завершения подготовительных операций алгоритм готов к началу сжатия данных (изображения).
Алгоритм сжатия данных:
· Инициализировать, т.е. ввести первоначальную таблицу кодов;
· Очистить таблицу кодов, начиная с кода 258 и до конца;
· Очистить буфер строки ( String ), буфер строки ( Test ) и буфер строки ( Byte ).
· Далее в цикле:
а) Прочитать очередной байт кодируемых данных в буфер ( Byte ).
б) Сцепить (конкатенировать) String + Byte и поместить результат в буфер Test .
в) Проверить, имеется ли в таблице кодов код, соответствующий комбинации, помещенной в буфер Test ?
- если имеется, то содержимое буфера Test переписать в буфер String и перейти в начало цикла;
- если нет, то добавить в таблицу код, соответствующий содержимому буфера Test , присвоив ему значение, совпадающее со следующим свободным порядковым номером, вывести в выходной поток код, соответствующий содержимому буфера String , переписать содержимое буфера Byte в String и перейти в начало цикла.
· Работа программы заканчивается тем, что делаются записи в выходной поток кода содержимого String и кода конца записи.
В результате применения такого алгоритма получаем коды переменной длины, причем для сочетаний из двух-трех символов, каждый из которых в отдельности описывается в таблице 8-разрядным кодом, длина полученных кодов будет составлять не 16 и не 24 бита, а существенно меньшей.
Декодированию (декомпрессии) сжатых данных.
Декодирующий алгоритм, получая коды комбинаций исходных отсчетов, составляет по ним кодовую таблицу идентичную той, которую составляет кодирующий алгоритм.
Декодирующий алгоритм:
· Прочитать новый код сжатых данных ( Newcode ).
· Если Newcode представляет собой код конца записи, то завершить работу.
· Если Newcode представляет собой код очистки, то необходимо:
а) проинициализировать таблицу кодов;
б) прочитать следующий код сжатых данных (если это будет код конца записи, то завершить работу);
в) найти Newcode в кодовой таблице и вывести соответствующую ему декомпрессированную последовательность отсчетов;
г) скопировать Newcode в буфер, где был записан предыдущий код ( Prevcode ).
· Если же Newcode находится в таблице, но не является ни кодом очистки, ни кодом конца записи, то необходимо:
а) вывести соответствующую ему декомпрессированную последовательность отсчетов;
б) взять первый байт декомпрессированного кода Newcode и декомпрессированного кода Prevcode, конкатенировать их и добавить в кодовую таблицу;
г) скопировать Newcode в буфер, где хранится Prevcode .
Если Newcode в таблице отсутствует, а, кроме того, он не является кодом очистки и кодом конца записи, то необходимо:
а) конкатенировать и вывести значение декомпрессированного кода Prevcode+ первый байт того же значения;
б) добавить в таблицу элемент для вышеприведенного значения;
в) скопировать Newcode в буфер Prevcode .
Метод сжатия LZW может быть применен не только для сжатия данных, каждая единица которых имеет размер в один байт, например, отсчетов яркости черно-белого полутонового изображения, но также и для сжатия данных, имеющих произвольный размер. В этом случае кодовые последовательности этих данных объединяются в группы по 8 двоичных единиц. Так если каждый отсчет содержит 4 двоичных единицы, то объединение в группы происходит по два отсчета, а если один отсчет представлен 16 двоичными единицами кода, то такая кодовая последовательность делится пополам. Величина сжатия, обеспечиваемая при использовании этого метода, невелика и лежит обычно в пределах 2 – 3 раза.
Метод кодирования Хаффмена
Этот метод позволяет получить код с минимальной средней длиной при заданном распределении вероятностей значений некоррелированных отсчетов сигналов. Особенностью этого метода кодирования является использование кодов переменной длины, при этом наиболее вероятным символам присваиваются наиболее короткие кодовые слова, а менее вероятным – длинные.
На рис. 2.5 показано кодовое дерево применительно к случаю кодирования шести символов A1, A2,
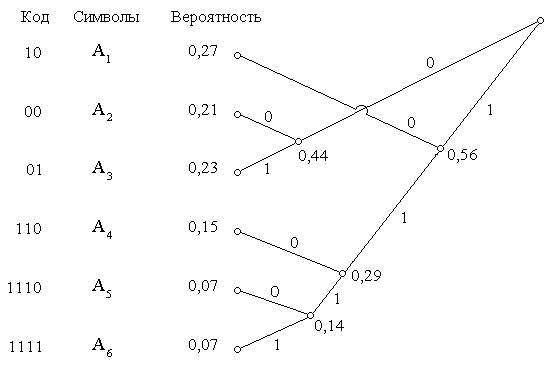
Рис.2.5.
A3, A4, A5, A6 и приведены вероятности, с которыми они появляются. Построение кодовой таблицы начинается с того, что два символа с наименьшими вероятностями объединяются в узел кодового дерева, которому приписывается их суммарная вероятность. Речь идет о символах A5 и A6, суммарная вероятность которых равна 0,14. Далее объединяются следующие символы или узлы с наименьшей вероятностью, как это показано на рисунке. Этот процесс продолжается до тех пор, пока ветви кодового дерева не сойдутся к одному узлу, расположенному в вершине. После этого ветви дерева в зависимости от того, в какую сторону они расходятся от узла, обозначаются нулями или единицами (на рис. 2.5 правые ветви обозначены нулями, а левые единицами). Для того, чтобы найти значение кодового слова, которое следует приписать каждому символу, необходимо идти от вершины кодового дерева к данному символу, записывая нули или единицы, которыми обозначены пройденные ветви.
В случае применения кода Хаффмена для сжатия изображений необходимо вначале осуществить декорреляцию сигнала, которым представлено изображение, например, используя для этой цели метод кодирования длин серий, а уже затем применять кодирование по Хаффмену.
ОРТОГОНАЛЬНЫХ ПРЕОБРАЗОВАНИЙ
Особенностью данного метода сжатия изображений является то, что при этом методе кодируется не само изображение, а значения спектральных коэффициентов, получающихся при ортогональном преобразовании изображения. В результате ортогональных преобразований изображения  , имеющего сильные корреляционные связи между смежными отсчетами (пикселами), имеет место декорреляция, в результате которой значения спектральных коэффициентов
, имеющего сильные корреляционные связи между смежными отсчетами (пикселами), имеет место декорреляция, в результате которой значения спектральных коэффициентов  оказываются практически некоррелироваными. В отличие от исходного изображения, для которого характерно в среднем равномерное распределение энергии между его отсчетами (пикселами), распределение энергии между спектральными коэффициентами резко неравномерно. При этом основная доля энергии приходится на спектральные коэффициенты с малыми индексами
оказываются практически некоррелироваными. В отличие от исходного изображения, для которого характерно в среднем равномерное распределение энергии между его отсчетами (пикселами), распределение энергии между спектральными коэффициентами резко неравномерно. При этом основная доля энергии приходится на спектральные коэффициенты с малыми индексами  ,
,  , представляющие амплитуды низких пространственных частот и лишь небольшая ее часть – на прочие. В целях сжатия изображений спектральные коэффициенты, имеющие малую амплитуду, либо квантуются на малое число уровней, либо вообще отбрасываются, что позволяет для их представления использовать коды с малым числом двоичных единиц. Так как средний квадрат шума квантования пропорционален среднему квадрату квантуемого сигнала, то возникающие при этом искажения изображения невелики. При декомпрессии (восстановлении) изображения вначале по имеющемуся коду восстанавливаются спектральные коэффициенты, а затем путем обратного ортогонального преобразования восстанавливается само изображение. Поскольку при записи или при передаче спектральных коэффициентов, в отличие от записи или передачи значений отсчетов исходного изображения, только небольшая их часть представлена кодом с большим количеством двоичных единиц, в то время как для представления остальных расходуется значительно меньше двоичных единиц, если они вообще не отбрасываются, достигается высокая степень сжатия. Поскольку, как это следует из приведенного описания метода, восстановленное изображение отличается от исходного вследствие квантования спектральных коэффициентов с большими индексами на малое число уровней, данный метод сжатия относится к группе методов сжатия с потерей информации.
, представляющие амплитуды низких пространственных частот и лишь небольшая ее часть – на прочие. В целях сжатия изображений спектральные коэффициенты, имеющие малую амплитуду, либо квантуются на малое число уровней, либо вообще отбрасываются, что позволяет для их представления использовать коды с малым числом двоичных единиц. Так как средний квадрат шума квантования пропорционален среднему квадрату квантуемого сигнала, то возникающие при этом искажения изображения невелики. При декомпрессии (восстановлении) изображения вначале по имеющемуся коду восстанавливаются спектральные коэффициенты, а затем путем обратного ортогонального преобразования восстанавливается само изображение. Поскольку при записи или при передаче спектральных коэффициентов, в отличие от записи или передачи значений отсчетов исходного изображения, только небольшая их часть представлена кодом с большим количеством двоичных единиц, в то время как для представления остальных расходуется значительно меньше двоичных единиц, если они вообще не отбрасываются, достигается высокая степень сжатия. Поскольку, как это следует из приведенного описания метода, восстановленное изображение отличается от исходного вследствие квантования спектральных коэффициентов с большими индексами на малое число уровней, данный метод сжатия относится к группе методов сжатия с потерей информации.
Существуют два метода отбора спектральных коэффициентов: зональный и пороговый. Первый метод заключается в том, что заранее, исходя из статистики изображений, в матрице спектральных коэффициентов выделяются зоны и все спектральные коэффициенты, входящие в одну зону, квантуются на одно и то же число уровней, как это показано на рис. 3.1.
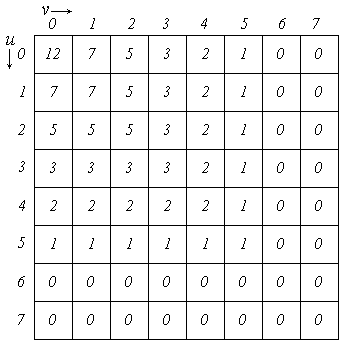
Рис. 3.1.
Второй метод состоит в том, что сохраняются только те спектральные коэффициенты, амплитуда которых превышает заранее установленный порог. Этот метод отбора сложнее зонального, поскольку кроме передачи (записи) значений спектральных коэффициентов необходимо также передавать (записывать) их индексы.
Перед тем как переходить к более детальному рассмотрению метода сжатия данных, основанного на применении ортогональных преобразований, сравним его с ДКИМ. Общим для этих двух методов является двухэтапная обработка изображений, включающая в себя декорреляцию и последующее оптимальное кодирование сигнала. Важное различие между ДКИМ и методом сжатия с использованием ортогональных преобразований состоит в том, что в первом случае имеет место декорреляция за счет предсказания, при которой используется “локальная” статистика изображения, в то время как во втором случае имеет место декорреляция за счет укрупнения и, следовательно, используется “средняя” статистика изображения. При передаче стационарных изображений эта особенность не играет роли, и оба метода сжатия дают близкие результаты. Если же изображение не стационарно, как например, при передаче мелкомасштабного объекта на фоне поля с медленно изменяющейся яркостью, это различие в способе декорреляции весьма существенно. На той части изображения, где расположен мелкомасштабный объект, “текущее” значение коэффициента автокорреляции между сигналами от соседних отсчетов невелико (  ), поэтому его сжатие посредством ДКИМ оказывается неэффективным. В то же время значение коэффициента автокорреляции
), поэтому его сжатие посредством ДКИМ оказывается неэффективным. В то же время значение коэффициента автокорреляции 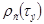 , усредненное по всему изображению, может быть близким к единице, благодаря чему будет обеспечиваться высокая эффективность сжатия методом, использующим ортогональные преобразования.Рассмотрим более подробно ортогональные преобразования предварительно дискретизированных изображений, представляемых в виде массива (матрицы) чисел
, усредненное по всему изображению, может быть близким к единице, благодаря чему будет обеспечиваться высокая эффективность сжатия методом, использующим ортогональные преобразования.Рассмотрим более подробно ортогональные преобразования предварительно дискретизированных изображений, представляемых в виде массива (матрицы) чисел 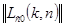 размером
размером 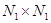 , где
, где  – номер строки,
– номер строки, 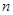 - номер столбца (номер отсчета в строке). Следует обратить внимание на то, что в этой записи порядок указания координат точки отсчета яркости на изображении изменен на обратный, т.е. вместо обозначения
- номер столбца (номер отсчета в строке). Следует обратить внимание на то, что в этой записи порядок указания координат точки отсчета яркости на изображении изменен на обратный, т.е. вместо обозначения 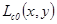 мы пишем
мы пишем 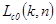 . Это делается для согласования с формой записи, принятой в матричном анализе, где первая координата обозначает номер строки, а вторая – номер столбца. Спектральные коэффициенты находятся путем прямого ортогонального преобразования изображения следующим образом
. Это делается для согласования с формой записи, принятой в матричном анализе, где первая координата обозначает номер строки, а вторая – номер столбца. Спектральные коэффициенты находятся путем прямого ортогонального преобразования изображения следующим образом
 ,
,
где 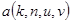 - ядро прямого преобразования (базисные функции, по которым происходит разложение);
- ядро прямого преобразования (базисные функции, по которым происходит разложение); 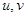 - индексы спектральных коэффициентов, определяющие их принадлежность в соответствующей базисной функции, а также положение в матрице спектральных коэффициентов, которая имеет тот же размер, что и преобразуемое изображение. Исходное изображение (массив чисел
- индексы спектральных коэффициентов, определяющие их принадлежность в соответствующей базисной функции, а также положение в матрице спектральных коэффициентов, которая имеет тот же размер, что и преобразуемое изображение. Исходное изображение (массив чисел 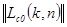 ) находится путем обратного ортогонального преобразования
) находится путем обратного ортогонального преобразования
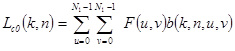 ,
,
где  - ядро обратного преобразования. Если преобразование разделимо, т.е. если
- ядро обратного преобразования. Если преобразование разделимо, т.е. если
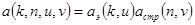 ,
, 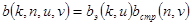 ,
,
а нас будут интересовать разделимые преобразования, то оно может быть выполнено в два этапа, вначале по всем столбцам, а затем по всем строкам
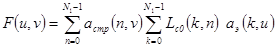 , (3.5)
, (3.5)
и соответственно
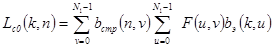 . (3.6)
. (3.6)
Для удобства записи и вычислений используют матричный аппарат. В матричной форме разделимые ортогональные преобразования записываются следующим образом
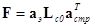 ,
, 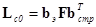 , (3.7)
, (3.7)
где 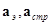 - ортогональные матрицы прямого преобразования по столбцам и строкам,
- ортогональные матрицы прямого преобразования по столбцам и строкам, 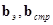 - ортогональные матрицы обратного преобразования по столбцам и строкам,
- ортогональные матрицы обратного преобразования по столбцам и строкам, 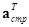 и
и 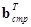 - матрицы, полученные в результате транспонирования матриц
- матрицы, полученные в результате транспонирования матриц 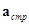 и
и 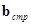 ;
;
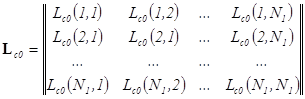 ,
,
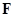 - матрица спектральных коэффициентов, получаемая в результате двумерного ортогонального преобразования,
- матрица спектральных коэффициентов, получаемая в результате двумерного ортогонального преобразования,
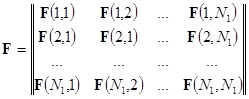 .
.
Учитывая, что 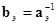 ,
, 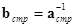 , а также соотношения
, а также соотношения 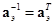 и
и 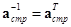 , справедливые для ортогональных матриц, имеем
, справедливые для ортогональных матриц, имеем
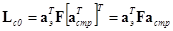 , (3.8)
, (3.8)
где  ,
, 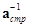 - матрицы, полученные в результате обращения матриц
- матрицы, полученные в результате обращения матриц 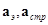 .
.
Базисные функции  ,
, 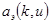 ,
, 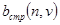 ,
,  в формулах (3.5) и (3.6) (или, что - то же самое, ортогональные матрицы в формулах (3.7) и (3.8)) определяются применяемым ортогональным преобразованием. Так, например, в случае двумерного дискретного преобразования Фурье (ДПФ) базисные функции представляют собой комплексные экспоненты, а сами ортогональные преобразования имеют вид
в формулах (3.5) и (3.6) (или, что - то же самое, ортогональные матрицы в формулах (3.7) и (3.8)) определяются применяемым ортогональным преобразованием. Так, например, в случае двумерного дискретного преобразования Фурье (ДПФ) базисные функции представляют собой комплексные экспоненты, а сами ортогональные преобразования имеют вид
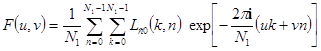 ,
,
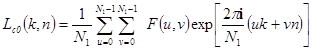 ,
,
в этих формулах множитель 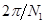 имеет смысл пространственной частоты,
имеет смысл пространственной частоты,  .
.
Известно, что (ДПФ) не является лучшим преобразованием для применения в целях сжатия данных, т.к. значения спектральных коэффициентов в области высоких пространственных частот при этом преобразовании имеют сравнительно высокие значения. В настоящее время при сжатии изображений широкое распространение получило дискретное косинусное преобразование (ДКП). Среди других ранее применявшихся ортогональных преобразования при сжатии изображений следует назвать: преобразование Адамара (ПА), преобразование Хаара (ПХ), наклонное преобразование ( slant transform ).
Ортогональные преобразования изображений допускают ряд следующих интерпретаций.
Во-первых, двумерное преобразование изображения можно рассматривать как его разложение в обобщенный двумерный спектр, а спектральные коэффициенты – как амплитуды соответствующих спектральных составляющих. В том случае, если применяются негармонические базисные функции, как, например, в случае преобразования Адамара, понятие частоты необходимо обобщить и пользоваться понятием секвенты. Напомним, что секвентой (ненормированной) называется величина, равная половине среднего числа пересечения нуля в единицу времени (на единицу длины).
Другая возможная интерпретация обусловлена тем, что матрица преобразуемого изображения и матрицы базисных изображений имеют одинаковые размеры, т.е. состоят из одного и того же числа строк и столбцов. Это дает возможность спектральные коэффициенты рассматривать как весовые коэффициенты, с которыми необходимо просуммировать базисные изображения, чтобы получить исходное изображение.
Спектральные коэффициенты можно также рассматривать и как функции взаимной корреляции между преобразуемым изображением и соответствующими базисными изображениями.
И, наконец, ортогональные преобразования можно рассматривать как такой поворот N – мерной системы координат ( 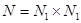 ), в которой преобразуемое изображение, состоящее из N отсчетов, представляется N – мерным вектором, при котором корреляция между его компонентами сводится к минимуму.
), в которой преобразуемое изображение, состоящее из N отсчетов, представляется N – мерным вектором, при котором корреляция между его компонентами сводится к минимуму.
Важным свойством ортогональных преобразований является сохранение метрики, благодаря этому свойству евклидово расстояние между изображениями равно евклидову расстоянию между их образами (спектральными отображениями).
ДИСКРЕТНОЕ КОСИНУСНОЕ ПРЕОБРАЗОВАНИЕ
Двумерное дискретное косинусное преобразование является разделимым и может быть выполнено по формулам
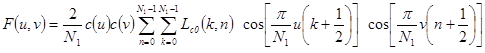 , (3.9)
, (3.9)
 , (3.10)
, (3.10)
где функции 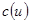 и
и  определены следующим образом:
определены следующим образом: 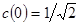 ,
, 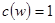 при
при 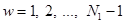 . Как известно, вычисление двумерного дискретного косинусного преобразования по приведенным формулам требует для его выполнения
. Как известно, вычисление двумерного дискретного косинусного преобразования по приведенным формулам требует для его выполнения 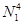 операций умножения и сложения, что создает серьезную проблему, поскольку значения
операций умножения и сложения, что создает серьезную проблему, поскольку значения 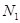 для реальных изображений составляют несколько сотен. В связи с этим были предприняты исследования, направленные на сокращение требуемого объема вычислений. В результате этих исследований были разработаны два, дополняющих друг друга метода.
для реальных изображений составляют несколько сотен. В связи с этим были предприняты исследования, направленные на сокращение требуемого объема вычислений. В результате этих исследований были разработаны два, дополняющих друг друга метода.
Первый метод заключается в том, что кодируемое изображение размером 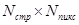 отсчетов предварительно разбивается на отдельные блоки размером
отсчетов предварительно разбивается на отдельные блоки размером 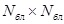 отсчетов, а затем независимо каждый из блоков подвергается дискретному косинусному преобразованию. Поскольку каждый блок содержит в
отсчетов, а затем независимо каждый из блоков подвергается дискретному косинусному преобразованию. Поскольку каждый блок содержит в 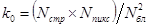 раз меньше отсчетов, чем исходное изображение, то на его преобразование в соответствии с формулами (3.9, 3.10), потребуется уже не
раз меньше отсчетов, чем исходное изображение, то на его преобразование в соответствии с формулами (3.9, 3.10), потребуется уже не 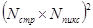 операций (в случае, когда
операций (в случае, когда  потребовалось бы соответственно
потребовалось бы соответственно 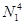 операций), а только
операций), а только 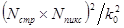 вычислительных операций.
вычислительных операций.

Рис. 3.2.
Учитывая, что все изображение содержит 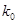 блоков, находим количество вычислительных операций, которые необходимо выполнить, чтобы осуществить преобразование всего изображения
блоков, находим количество вычислительных операций, которые необходимо выполнить, чтобы осуществить преобразование всего изображения 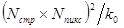 , т.е. в раз меньше, чем без разбиения на блоки. Поясним изложенное примером. Предположим, что исходное изображение имеет размер
, т.е. в раз меньше, чем без разбиения на блоки. Поясним изложенное примером. Предположим, что исходное изображение имеет размер  отсчетов, а размер блока составляет
отсчетов, а размер блока составляет 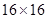 отсчетов. Тогда в соответствии с приведенными выше рассуждениями без разбиения изображения на блоки потребовалось бы 171992678400 вычислительных операций, при разбиении же изображения на блоки потребуется всего лишь 106168320, т.е. в 1620 раз меньше, чем в первом случае. Из этого следует, что чем более мелкими будут блоки, тем большим будет их число
отсчетов. Тогда в соответствии с приведенными выше рассуждениями без разбиения изображения на блоки потребовалось бы 171992678400 вычислительных операций, при разбиении же изображения на блоки потребуется всего лишь 106168320, т.е. в 1620 раз меньше, чем в первом случае. Из этого следует, что чем более мелкими будут блоки, тем большим будет их число 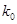 и тем большим будет сокращение числа операций, необходимых для выполнения ортогонального преобразования, в данном случае ДКП. Однако, как показывает детальный анализ этой проблемы, делать блоки меньшими, чем , или в крайнем случае
и тем большим будет сокращение числа операций, необходимых для выполнения ортогонального преобразования, в данном случае ДКП. Однако, как показывает детальный анализ этой проблемы, делать блоки меньшими, чем , или в крайнем случае 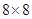 отсчетов, не следует, так как корреляционные связи в изображении распространяются примерно на этот интервал и дальнейшее уменьшение размеров блоков повлечет за собой увеличение амплитуд спектральных коэффициентов
отсчетов, не следует, так как корреляционные связи в изображении распространяются примерно на этот интервал и дальнейшее уменьшение размеров блоков повлечет за собой увеличение амплитуд спектральных коэффициентов 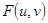 с большими индексами
с большими индексами 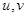 , и, как следствие, уменьшение сжатия данных.
, и, как следствие, уменьшение сжатия данных.
Второй метод сокращения требуемого объема вычислений при выполнении дискретного косинусного преобразования состоит в применении быстрого алгоритма вычисления ДКП, при котором требуемый объем вычислений (умножений и сложений) сокращается с  до
до 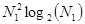 .
.
Поясним эффективность этого метода на примере, полагая, что размер блока составляет 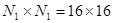 отсчетов изображения. При непосредственном вычислении спектральных коэффициентов по формулам (3.9, 3.10) потребовалось бы выполнить 65536 операций умножения и сложения. Используя же быстрый алгоритм, потребуется выполнить всего лишь 2048 операций, т.е. в 32 раза меньше, чем в первом случае.
отсчетов изображения. При непосредственном вычислении спектральных коэффициентов по формулам (3.9, 3.10) потребовалось бы выполнить 65536 операций умножения и сложения. Используя же быстрый алгоритм, потребуется выполнить всего лишь 2048 операций, т.е. в 32 раза меньше, чем в первом случае.
В настоящее время при выполнении ДКП используют оба описанные метода сокращения количества вычислительных операций, поскольку они, дополняя друг друга, позволяют существенно ускорить вычисления.
Вывод
Мультимедиа технологии – это совокупность программно-аппаратных средств, реализующих обработку информации в звуковом и зрительном виде. Каждый из нас не раз слышал, что "компьютер может все". Однако, в реальной жизни мы не имели убедительных подтверждений подобных высказываний прежде всего потому, что имелись в виду потенциальные возможности компьютера, известные, в основном, узкому кругу специалистов. Ситуация существенно изменилась с появлением мультимедиа технологий, позволяющих раскрыть этот потенциал в привычной информационной среде.
Графика, анимация, фото, видео, звук, текст в интерактивном режиме работы создают интегрированную информационную среду, в которой пользователь обретает качественно новые возможности. Самое широкое применение мультимедиа технологии нашли в образовании - от детского до пожилого возраста и от вузовских аудиторий до домашних условий. Мультимедиа продукты успешно используются в различных информационных, демонстрационных и рекламных целях, внедрение мультимедиа в телекоммуникации стимулировало бурный рост новых применений. В данной работе, на основе методическо - информационных материалов были рассмотрены возможности ММТ в области обработки изображений, по средствам которых можно, к примеру, обработать фотографии, «качественно» передать информацию от пользователя к пользователю, компактно хранить информацию на жестких дисках ПК, создавать постеры или работать с иллюстрациями – любые преобразования с изображениями хоть в профессиональной сфере, хоть на бытовом уровне.
СПИСОК ЛИТЕРАТУРЫ
1. Красильников Н.Н. Цифровая обработка изображений. - М.: Вузовская книга, 2001.- 319 с.
2. Красильников Н.Н., Красильникова О.И. Мультимедиатехнологии в информационных сетях. Методы сжатия и форматы записи графической информации: Учеб. Пособие. СПбГУАП. СПб., 2004.- 68 с
3. Информационный ресурс: http://www.dialektika/com/books/5-8459-0888-4/html.
Проблема сжатия изображений
Для записи изображений требуются достаточно большие объемы памяти, часто в единицы и даже десятки Мегабайт – а, это может оказаться недостижимым, если изображение необходимо записать на дискету или передать по Интернет. Существуют специально разработанные форматы записи графических файлов, практически каждый из которых базируется на том или ином, а иногда и на нескольких алгоритмах сжатия изображений – это является решением проблемы. Посредством сжатия (компрессии) изображений удается в несколько раз и даже в ряде случаев в десятки раз сократить цифровой поток, представляющий изображение. Например: есть отсканированная фотография – цветное изображение 1732*1165 пикселов при 24 битах на пиксел (режим True Color) требует 5,8 Мбайт. Для такого изображения при записи его в формате TIFF требуется приблизительно 4,9 Мбайт, а если использовать формат JPEG, то можно получить разные степени сжатия в зависимости от жесткости требований предъявляемых к качеству изображения. В данном случае максимально высокого качества изображение будет занимать всего 2,4 Мбайт, среднего (вполне приемлего для большинства задач) качества 0,2 Мбайт, а применение максимального сжатия позволит довести эту цифру до 0,07 Мбайта.
При записи изображений – существует еще одна существенная деталь - сохранение качества изображения. Как правило, проблема эффективного сжатия изображений решается либо без потери качества, либо с минимальными потерями, практически незаметными для зрителя. Это оказалось возможным благодаря свойственным изображениям статистической и психофизической избыточности, что позволяет произвести такое кодирование изображения, при котором для его записи потребуется существенно меньше двоичных единиц кода.
1.1 Оценка качества изображения
"Качество изображения" – это понятие, которое можно рассматривать как меру подобия сформированного изображения его входному оптическому изображению. Для определения критерия качества на практике пользуются методом экспертных оценок, а также рядом измеряемых параметров, набор которых может быть разным для информационных систем различного назначения, в которых то или иное изображение используется.
Наиболее часто оцениваемыми являются следующие
параметры:
Ø четкость, определяемая числом элементов разложения изображения по горизонтали и вертикали;
Ø воспроизведение градаций яркости внутри яркостного динамического диапазона;
Ø контраст, под которым понимают отношение максимальной яркости изображения к минимальной;
Ø отношение сигнала к шуму, определяемое как отношение размаха сигнала от черного до белого к эффективному значению шума;
Ø геометрические искажения, характеризующие точность воспроизведения координат отдельных элементов исходного изображения;
Ø цветовоспроизведение, характеризующее степень отличия цветов в полученном изображении от цветов в исходном изображении, а также ряд других параметров.
При оценке качества существует ряд дополнительных факторов
- если производится оценивание отношения сигнала к шуму для системы, конечным звеном которой является человек, то следует обращать внимание на степень видности помехи для зрителя, которая в сильной степени зависит от спектрального состава помехи. Делают оценку сигнала к взвешенному шуму (Среднеквадратичное значение шума, предварительно пропущенного через фильтр, имитирующий частотные преобразования, протекающие в зрительной системе):
- для предотвращения возникновения шума пространственной дискретизации частота пространственной дискретизации, т.е. плотность отсчетов на изображении, в соответствии с теоремой Котельникова должна по крайней мере вдвое превышать верхнюю частоту пространственного спектра дискретизируемого изображения, а во избежание появления ложных контуров на изображении число уровней квантования должно быть выбрано достаточно большим (стандартным требованием является 256 уровней квантования), что потребует достаточно большого числа бит на каждый пиксел изображения. Этим как раз и обусловливаются то большое количество двоичных единиц, которым описывается изображение, а, следовательно, и необходимость его сжатия.
Статистическая избыточность изображений
Статистическая избыточность сигнала неподвижного изображения обусловлена наличием сильных статистических связей между его смежными пикселами, а также тем, что различные уровни их яркости имеют различную вероятность.
Статистическая избыточность сигнала, которым представлено изображение, как неподвижное, так и движущееся, может быть устранена или сильно уменьшена, а, следовательно, уменьшен цифровой поток, путем его соответствующей перекодировки (сжатия).
Эта перекодировка включает в себя два этапа - вначале декорреляцию сигнала, а затем представление часто встречающихся значений сигнала более короткими кодовыми комбинациями, а редко встречающихся значений - более длинными кодовыми комбинациями.
При этом не происходит потери информации, поскольку исходное изображение может быть точно восстановлено. Вследствие этого методы, реализующие этот принцип сжатия изображений, называются методами сжатия без потери информации, или энтропийными методами (от слова "энтропия" - одного из основных понятий теории информации).
Энтропия - (согласно Шеннону) является мерой, устанавливающей среднее количество информации на символ сообщения (на растровый элемент изображения). Для последовательности из m статистически независимых символов, появляющихся с вероятностями 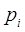 , энтропия выражается в следующем виде
, энтропия выражается в следующем виде
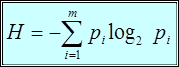 , (1.1)
, (1.1)
где 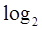 - двоичный логарифм, i - номер символа.
- двоичный логарифм, i - номер символа.
Если вероятность появления некоторого символа сообщения равна единице, а остальных нулю, т.е. неопределенность появления данного символа отсутствует, и энтропия будет равна нулю. В случае же, когда вероятности появления всех символов одинаковы
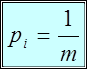 ,
,
энтропия достигает своего максимального значения равного

Сопоставляя найденное значение энтропии с ее максимальным значением, определяют величину избыточности сигнала следующим образом
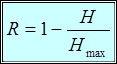 . (1.2)
. (1.2)
В том случае, когда вероятности появления всех символов одинаковы
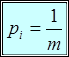 ,
,
избыточность, как это ясно из изложенного, отсутствует.
Коэффициент, показывающий, во сколько раз можно уменьшить число двоичных единиц кода, требующихся для представления сообщений источника с энтропией H (в рассматриваемом случае изображения), по сравнению со случаем, когда при том же наборе символов все символы источника сообщения кодируются кодовыми словами одинаковой длины, называется коэффициентом сжатия
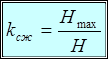 . (1.3)
. (1.3)
До сих пор мы рассматривали случай, когда смежные растровые элементы изображения были статистически независимы, т.е. в качестве изображения был выбран белый шум. Однако в реальных изображениях значения яркостей смежных пикселов взаимно коррелированы. В этом случае, располагая значением сигнала, представляющего яркость некоторого пиксела, можно с некоторой вероятностью предсказать значения сигналов от соседних пикселов. Следовательно, информация, привносимая последующим пикселом в случае знания предшествующего, будет меньше, чем в случае, когда сигналы, представляющие значения яркости пикселов, были бы статистически независимы. Величина энтропии 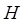 в этом случае должна рассчитываться уже по другой формуле
в этом случае должна рассчитываться уже по другой формуле
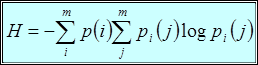 , (1.4)
, (1.4)
где 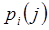 - условная вероятность появления j-го символа, если предыдущим был i-ый символ. Формула (1.4) является более общей и в частном случае, когда статистическая связь между пикселами отсутствует, она переходит в формулу (1.1). Действительно, в этом случае, поскольку
- условная вероятность появления j-го символа, если предыдущим был i-ый символ. Формула (1.4) является более общей и в частном случае, когда статистическая связь между пикселами отсутствует, она переходит в формулу (1.1). Действительно, в этом случае, поскольку  от i не зависит, мы можем его заменить на
от i не зависит, мы можем его заменить на 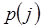 и записать
и записать
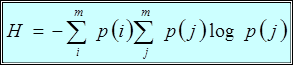 ,
,
а так как внутренняя сумма не зависит от i, то суммы можно поменять местами
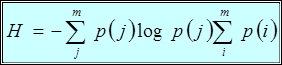 . (5)
. (5)
Но поскольку 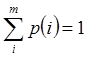 , так как суммируются все вероятности
, так как суммируются все вероятности 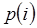 , формула (1.4) переходит в формулу (1.1), что и требовалось показать.
, формула (1.4) переходит в формулу (1.1), что и требовалось показать.
В рассматриваемом случае, когда элементы изображения взаимно коррелированы, энтропия  будет меньше, чем в случае, если бы значения сигнала были бы статистически независимы. Вследствие этого достижимый коэффициент сжатия возрастает. Поэтому первым шагом при сжатии данных обычно является декорреляция кодируемой последовательности, при которой, устраняются статистические связи между кодируемыми отсчетами, и уже затем производится энтропийное кодирование статистически независимых отсчетов.
будет меньше, чем в случае, если бы значения сигнала были бы статистически независимы. Вследствие этого достижимый коэффициент сжатия возрастает. Поэтому первым шагом при сжатии данных обычно является декорреляция кодируемой последовательности, при которой, устраняются статистические связи между кодируемыми отсчетами, и уже затем производится энтропийное кодирование статистически независимых отсчетов.
Дата: 2019-12-10, просмотров: 439.