ТИПЫ ДАННЫХ
Типы данных, абстрактные типы и структуры данных
В языках программирования тип данных переменной обозначает множество значений, которые может принимать эта переменная.
Типы данных включают:
-натуральные и целые числа,
-вещественные числа,
-литеры,
-строки и др.
В некоторых языках программирования тип каждой константы или переменной определяется компилятором по записи присваиваемого значения.
В зависимости от назначения языка программирования защита типов, осуществляемая на этапе компиляции, может быть более или менее жесткой.
Отсутствие жесткой защиты типов дает системному программисту дополнительные возможности, но при этом человек сам отвечает за правильность своих действий.
Абстрактный тип данных (АТД) – это математическая модель и набор операторов, определенных в рамках данной модели.
Базовым строительным блоком структуры данных является ячейка, которая предназначена для хранения значения определенного базового или составного типа данных.
ХЕШИРОВАНИЕ ДАННЫХ
Открытое хеширование
Закрытое хеширование
При использовании хеш-таблиц необходимо стараться избегать очень плотного ее заполнения. Обычно длину таблицы выбирают из расчета двукратного превышения предполагаемого максимального числа записей. В случае большой заполненности таблицы может понадобиться рехеширование. В этом случае увеличивают длину таблицы, изменяют хеш-функцию и переупорядочивают данные.
СТРУКТУРЫ ДАННЫХ
Полустатические и динамические структуры данных
Понятие динамических структур данных. Возможности, предоставляемые использованием динамических структур данных.
Полустатические структуры данных характеризуются следующими признаками:
- они имеют переменную длину и простые процедуры ее изменения;
- изменение длины структуры происходит в определенных пределах, не превышая какого-то максимального (предельного) значения.
Если полустатическую структуру рассматривать на логическом уровне, то о ней можно сказать, что это последовательность данных, связанная отношениями линейного списка.
Физическое представление полустатических структур данных в памяти – это обычно последовательность слотов в памяти, где каждый следующий элемент расположен в следующем слоте. Физическое представление может иметь вид однонаправленного списка, где каждый следующий элемент адресуется указателем, находящимся в текущем элементе.
В противовес статическим величинам, память под которые выделяется во время компиляции и сохраняется в течение всей работы программы, существуют динамические величины. Под них память выделяется динамически во время выполнения программы.
Использование динамических величин предоставляет программисту ряд дополнительных возможностей.
· Во-первых, подключение динамической памяти позволяет увеличить объем обрабатываемых данных.
· Во-вторых, если потребность в каких-то данных отпала до окончания программы, то занятую ими память можно освободить для другой информации.
· В-третьих, использование динамической памяти позволяет создавать структуры данных переменного размера.
При этом следует понимать, что работа с динамическими данными замедляет выполнение программы, поскольку доступ к величине происходит в два этапа: сначала ищется указатель, а затем по нему – величина. Работа с динамическими величинами связана с использованием ссылочного типа данных. Указатель содержит адрес поля в динамической памяти, хранящего величину определенного типа. Сам указатель располагается в статической памяти.
Тип «Запись»
Запись – это структурированный тип данных, состоящий из фиксированного числа компонентов одного или нескольких типов. Определение типа записи начинается идентификатором record и заканчивается зарезервированным словом end . Между ними располагается список компонентов, называемых полями, с указанием идентификаторов полей и типа каждого поля.
Значения полей записи могут использоваться в выражениях. Имена отдельных полей не применяются по аналогии с идентификаторами переменных, поскольку может быть несколько записей одинакового типа. Обращение к значению поля осуществляется с помощью идентификатора переменной и идентификатора поля, разделенных точкой. Такая комбинация называется составным именем. Для получения доступа к полям записи Car можно записать: M . Number , M . Marka , M . FIO , M . Address.
Составное имя можно использовать везде, где допустимо применение типа поля. Для присваивания полям значений используется оператор присваивания.
(Важно!) Указатели могут использоваться с типом «запись» таким же образом, как и с данными других типов.
Дважды связные списки
Иногда возникает необходимость организовать эффективное перемещение по списку, как в прямом, так и в обратном направлениях; или по заданному элементу нужно быстро найти предшествующий ему и последующий элементы. В этих ситуациях можно дать каждой ячейке указатели и на следующие, и на предыдущие ячейки списка, т.е. организовать дважды связный список. На рис. 3 приведен такой список.

Рис. 3 – Дважды связный список
Важным преимуществом является то, что можно использовать указатель ячейки, содержащей i-й элемент, для определения i-й позиции вместо использования указателя предшествующей ячейки. Однако при этом появляются дополнительные указатели и, следовательно, удлиняются некоторые процедуры. Ниже приведен код объявления дважды связного списка.
Ниже показаны процедуры построения двусвязного списка, а также удаления элемента из него.
Здесь предполагается, что удаляемая ячейка не является ни первой, ни последней в списке. Сплошными линиями показаны указатели до удаления, а пунктирными – после удаления элемента. Сначала с помощью указателя поля previous определяется положение предыдущей ячейки. Затем в поле next этой ячейки устанавливается указатель на ячейку, предшествующую позиции р. Таким образом, ячейка в позиции р исключается из цепочек указателей и при необходимости может быть использована повторно.
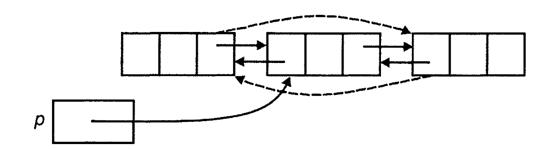
Рис. 3 – Удаление элемента из дважды связного списка
ОЧЕРЕДИ И СТЕКИ
Разновидности очередей
Интересной разновидностью очередей являются многопоточные очереди (multi headed queues). Элементы в нее, как обычно, добавляются в конец очереди, но очередь имеет несколько потоков ( front end ) или голов ( heads ).
Примером многопоточной очереди в обычной жизни является очередь клиентов в банке. Все клиенты находятся в одной очереди, но их обслуживает несколько служащих. Освободившийся банковский работник обслуживает клиента, который находится в очереди первым. Такой порядок обслуживания кажется справедливым, поскольку клиенты обслуживаются в порядке прибытия. Он также эффективен, так как все служащие остаются занятыми до тех пор, пока клиенты ждут в очереди.
В общем случае многопоточные очереди более эффективны, чем несколько однопоточных очередей.
Циклическая очередь. Некоторые программы можно улучшить, используя циклические очереди. При организации очереди на основе массива при достижении предела массива можно вернуть указатели вставки в очередь и удаления из нее на начало массива. В этом случае в очередь можно добавлять и удалять из нее любое число элементов. Такая очередь называется циклической, поскольку массив используется не как линейный список, а как циклический.
В действительности очередь становится заполненной только в том случае, когда указатель свободного места совпадает с указателем выборки следующего элемента. В противном случае очередь будет иметь свободное место для нового элемента. В начале программы индекс выборки должен устанавливаться не в нулевое значение, а на значение максимального числа событий. В противном случае первое обращение к процедуре постановки в очередь приведет к появлению сообщения о заполнении структуры. Следует помнить, что очередь может содержать только на один элемент меньше, чем значение максимального числа событий, поскольку указатели выборки и постановки в очередь всегда должны отличаться хотя бы на единицу (в противном случае нельзя будет понять заполнена ли очередь или она пустая).
Наиболее широко циклические очереди применяются в операционных системах при буферизации информации, которая считывается или записывается на дисковые файлы или консоль. Другое широкое применение эти очереди нашли в решении задач реального времени, когда, например, пользователь может продолжать делать ввод с клавиатуры во время выполнения другой задачи. Так работают многие текстовые процессоры, когда изменяется формат параграфа или выравнивается строка. Имеется короткий промежуток времени, когда набранная на клавиатуре информация не выводится на экран до окончания другого процесса. Для достижения такого эффекта в программе должна предусматриваться постоянная проверка ввода с клавиатуры в ходе выполнения другого процесса. При вводе некоторого символа его значение должно быстро ставиться в очередь, и процесс должен продолжаться. После завершения процесса набранные символы выбираются из очереди и обрабатываются обычным образом.
Приоритетные очереди . Каждый элемент в приоритетной очереди (priority queue) имеет связанный с ним приоритет. Если программе нужно удалить элемент из очереди, она выбирает элемент с наивысшим приоритетом. Как хранятся элементы в приоритетной очереди, не имеет значения, если программа всегда может найти элемент с наивысшим приоритетом.
Некоторые операционные системы использую приоритетные очереди для планирования заданий. В операционной системе UNIX все процессы имеют разные приоритеты. Когда процессор освобождается, выбирается готовый к исполнению процесс с наивысшим приоритетом. Процессы с более низким приоритетом должны ждать завершения или блокировки (например, при ожидании внешнего события, такого как чтение данных с диска) процессов с более высокими приоритетами.
Простой способ организации приоритетной очереди — поместить все элементы в список. Если требуется удалить элемент из очереди, можно найти в списке элемент с наивысшим приоритетом. Чтобы добавить элемент в очередь, он помещается в начало списка. При использовании этого метода, для добавления нового элемента в очередь требуется только один шаг. Чтобы найти и удалить элемент с наивысшим приоритетом, требуется O(N) шагов, если очередь содержит N элементов.
Немного лучше была бы схема с использованием связного списка, в котором элементы были бы упорядочены в прямом или обратном порядке. Чтобы добавить элемент в очередь, нужно найти его правильное положение в списке и поместить его туда. Чтобы упростить поиск положения элемента, можно использовать сигнальные метки в начале и конце списка, присвоив им соответствующие приоритеты.
Интуитивными моделями стека могут служить колода карт, лежащая на столе; книги, сложенные в стопку и т.д. В таких моделях можно взять только верхний предмет, а добавить новый объект можно, только положив его на верхний.
Рис. 1 – Реализация стека на основе массива
Еще одним удобным вариантом представления стека является способ на основе списка, в котором добавление новых элементов и извлечение имеющихся происходит с одного конца списка. Значением указателя, представляющего стек, является ссылка на вершину стека. Каждый элемент стека содержит поле ссылки на следующий элемент. В этом случае описать стек можно следующим образом.
Если стек пуст, то значение указателя st равно nil .
Необходимое и достаточное средство для рекурсивного представления программ – это описание процедур или функций, т.к. оно позволяет присваивать какому-либо оператору имя, с помощью которого можно вызывать этот оператор.
Если процедура Р содержит явное обращение к самой себе, то она называется прямо рекурсивной; если Р содержит обращение к процедуре Q , которая содержит (прямо или косвенно) обращение к Р, то Р называется косвенно рекурсивной.
С процедурой связывают некоторое множество локальных объектов (переменных, констант и т.д.), которые определены локально в этой процедуре, а вне ее не существуют или не имеют смысла. Каждый раз, когда такая процедура рекурсивно вызывается, для нее создается новое множество локальных переменных. Хотя они имеют те же имена, что и соответствующие элементы множества локальных переменных, созданного при предыдущем обращении к этой же процедуре, их значения различны. Следующие правила области действия идентификаторов позволяют исключить какой-либо конфликт при использовании имен: идентификаторы всегда ссылаются на множество переменных, созданное последним. То же правило относится к параметрам процедуры.
Подобно операторам цикла, рекурсивные процедуры могут привести к бесконечным вычислениям. Поэтому необходимо рассмотреть проблему окончания работы процедур.
Для того, чтобы работа когда-либо завершилась, необходимо, чтобы рекурсивное обращение к процедуре Р подчинялось условию В, которое в какой-то момент перестает выполняться.
На практике необходимо убедиться в том, что наибольшая глубина рекурсии не только конечна, но и достаточно мала. Поскольку при каждом рекурсивном вызове процедуры Р выделяется некоторая память для размещения ее переменных. Кроме этих локальных переменных, нужно еще сохранять текущее состояние вычислений, чтобы вернуться к нему, когда закончится выполнение новой активации Р, и нужно будет вернуться к старой.
Сравнивая рекурсию с итерационными методами, следует отметить, что рекурсивные алгоритмы наиболее пригодны в случаях, когда поставленная задача или используемые данные определены рекурсивно. В тех случаях, когда вычисляемые значения определяются с помощью простых рекуррентных соотношений, гораздо эффективнее применять итеративные методы.
Рекурсивные алгоритмы особенно подходят для задач, где обрабатываемые данные определяются в терминах рекурсии.
Постфиксная, префиксная, инфиксная записи представления выражений и их особенности.
Примеры различных форм записи выражений.
Если текущий элемент – знак операции, то выполняется эта операция над операндами, записанными левее знака операции. Результат операции записывается вместо первого (самого левого) операнда, участвовавшего в операции. Остальные элементы (операнды и знак операции), участвовавшие в операции, вычеркиваются из записи. Просмотр продолжается. В результате последовательного выполнения этого правила будут выполнены все операции в выражении, и запись сократится до одного элемента – результата вычисления выражения.
Для управления порядком выполнения операций над операндами используется скобочная запись выражений. При вычислении сначала вычисляется та часть выражения, скобочный уровень вложенности которой самый высокий. При наличии нескольких операторов с наивысшим скобочным уровнем, они вычисляются слева направо. При вычислении выражений с операциями, которым присвоен приоритет, или частично скобочных выражениях инфиксной формы записи, необходимо повторное сканирование слева направо.
Выполнить операцию.
Постфиксное и префиксное выражения корректны тогда и только тогда, когда ранг выражения равен 1, а ранг любой правой головы польской формулы больше (меньше) или равен 1. Ранг корректного выражения равен 1.
Алгебраическое преобразование инфиксного выражения в обратное польское основано на приоритетах операторов и предлагает использование стека. Обратное польское выражение хранится в виде выходной строки, используемой в дальнейшем при генерации объектного кода.
В ходе преобразования инфиксного выражения в обратное польское порядок всех переменных и констант не меняется, а порядок операторов выходной строки соответствует их приоритетам.
| Символ | Приоритет | Ранг |
| +,– | 1 | –1 |
| *, / | 2 | –1 |
| A,b,…,z | 3 | 1 |
| Дно стека | 0 | – |
Рассмотрим пример преобразования инфиксного выражения a+b*c–d/e*h в обратное польское
| Сканируемый символ | Содержание стека | Обратная польская запись | Ранг |
| |– | |||
| А | |– a | ||
| + | |– + | a | 1 |
| B | |– +b | a | 1 |
| * | |– +* | ab | 2 |
| С | |– +*c | ab | 2 |
| – | |– – | abc*+ | 1 |
| D | |– –d | abc*+ | 1 |
| / | |– – / | abc*+d | 2 |
| E | |– – / e | abc*+d | 2 |
| * | |– – * | abc*+de/ | 2 |
| H | |– – * h | abc*+de/ | 2 |
| |– | |– | abc*+de/h*– | 1 |
Алгоритм преобразования.
Если приоритет входного символа меньше или равен приоритету верхнего элемента стека, то этот элемент удаляется из стека и помещается в формируемую строку, после чего сравнивается приоритеты очередного символа и нового верхнего символа.
ТИПЫ ДАННЫХ
Типы данных, абстрактные типы и структуры данных
В языках программирования тип данных переменной обозначает множество значений, которые может принимать эта переменная.
Типы данных включают:
-натуральные и целые числа,
-вещественные числа,
-литеры,
-строки и др.
В некоторых языках программирования тип каждой константы или переменной определяется компилятором по записи присваиваемого значения.
В зависимости от назначения языка программирования защита типов, осуществляемая на этапе компиляции, может быть более или менее жесткой.
Дата: 2019-07-24, просмотров: 307.