МЕТОДИЧЕСКИЕ УКАЗАНИЯ И ЗАДАНИЯ
к лабораторным работам по курсу
«Информационная безопасность»
(для студентов специальности 7.080403 “Программное обеспечение АС”)
(Часть 1 – Криптографические и стеганографические методы защиты информации)
Донецк-ДонНТУ-2013
МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ УКРАИНЫ
ДОНЕЦКИЙ НАЦИОНАЛЬНЫЙ ТЕХНИЧЕСКИЙ УНИВЕРСИТЕТ
МЕТОДИЧЕСКИЕ УКАЗАНИЯ И ЗАДАНИЯ
к лабораторным работам по курсу
«Информационная безопасность»
(для студентов специальности 7.080403 “Программное обеспечение АС”)
(Часть 1 – Криптографические и стеганографические методы защиты информации)
Рассмотрено на заседании кафедры
КСМ
Протокол № от
Утверждено на заседании
учебно-издательского Совета ДонНТУ
протокол № от
Донецк –2013
УДК 681.3
Методические указания и задания к лабораторным работам по курсу «Информационная безопасность» для студентов специальности «Программное обеспечение АС», часть 1 - «Криптографические и стеганографические методы защиты информации»/ Сост.: Губенко Н.Е., Чернышова А.В. - Донецк, ДонНТУ, 2013 - 89 стр.
Приведены методические указания и задания к выполнению лабораторных работ по курсу «Информационная безопасность» для студентов специальности «Программное обеспечение АС». Излагаются вопросы, связанные с криптографическими и стеганографическими методами защиты информации. Рассматриваются простейшие базовые криптоалгоритмы, симметричные и ассиметричные криптосистемы, проверка подлинности информации средствами электронно-цифровой подписи, использование однонаправленных хэш-функций в криптографии, простейшие стеганографические алгоритмы защиты информации.
Методические указания предназначены для усвоения теоретических основ и формирования практических навыков по курсу «информационная безопасность» по разделу «Криптографические и стеганографические методы защиты информации».
Составители: доцент каф. КСМ, к.т.н. Губенко Н.Е.
Ст.преп. каф. ПМиИ Чернышова А.В.
Рецензент:
Лабораторная работа №1
Тема: Базовые алгоритмы шифрования.
Цель: Изучить базовые алгоритмы шифрования и написать программу, выполняющую шифрование текста с помощью одного из базовых алгоритмов, выполнив предварительно модификацию базового алгоритма шифрования.
Методические указания к лабораторной работе
Рассматриваемые простейшие методы кодирования заключаются в видоизменении информации таким образом, чтобы при попытке ее прочитать, злоумышленник не увидел ничего, кроме бессмысленной последовательности символов, а при попытке подделать или переделать документ, читатель, увидев ту же бессмыслицу, сразу понял бы это. Это и называется шифрованием или криптографией.
Зашифровав текст, его можно переправлять любым доступным способом, но никто не сможет узнать содержимое послания. Хотя, последнее не совсем верно, так как злоумышленник может попытаться раскрыть код.
Наука о раскрытии шифров – криптоанализ – всегда развивалась параллельно шифрованию. В последнее время, обе науки начали опираться на серьезный математический анализ, что только усилило их противоборство.
Не всегда криптоанализ используется злоумышленником. Дело в том, что преступная организация также может зашифровать послание. Тогда, дешифрация сообщения может оказаться жизненно важной. Поэтому, употреблять слово злоумышленник, говоря о шифровании, не совсем корректно, тем более, что в военном конфликте понятия прав и виноват весьма и весьма относительны. Но если сообщение шифруется, всегда есть опасность попытки его дешифрации.
Именно поэтому появился термин криптостойкость, то есть устойчивость алгоритма к криптоанализу.
Прежде чем говорить о более сложных алгоритмах шифрования, рассмотрим базовые алгоритмы, которые частично используются в современных алгоритмах шифрования. К простейшим алгоритмам шифрования относятся:
- шифр Полибия;
- шифр Цезаря;
- шифр Ришелье;
- перестановочный шифр;
- шифр Виженера;
- шифр Плейфера;
- шифрование с ключом;
- шифр Вернама;
- шифр «Люцифер»;
Многие криптосистемы, как простые, так и сложные основываются на принципах подставки, перестановки и гаммировании. Прежде чем рассматривать простейшие алгоритмы шифрования опишем в чем суть подстановок, перестановок и гаммирования, так как эти принципы являются базовыми.
Перестановки.
Перестановкой s набора целых чисел (0,1,...,N-1) называется его переупорядочение. Для того чтобы показать, что целое i перемещено из позиции i в позицию s(i), где 0 £ (i) < n, будем использовать запись
s=(s(0), s(1),..., s(N-1)).
Число перестановок из (0,1,...,N-1) равно n!=1*2*...*(N-1)*N. Введем обозначение s для взаимно-однозначного отображения (гомоморфизма) набора S={s0,s1, ...,sN-1}, состоящего из n элементов, на себя.
s: S ® S
s: si ® ss(i), 0 £ i < n
Будем говорить, что в этом смысле s является перестановкой элементов S. И, наоборот, автоморфизм S соответствует перестановке целых чисел (0,1,2,.., n-1).
Криптографическим преобразованием T для алфавита Zm называется последовательность автоморфизмов: T={T(n):1£n<¥}
T(n): Zm,n®Zm,n, 1£n<¥
Каждое T(n) является, таким образом, перестановкой n-грамм из Zm,n.
Поскольку T(i) и T(j) могут быть определены независимо при i¹j, число криптографических преобразований исходного текста размерности n равно (mn)! (Здесь и далее m - объем используемого алфавита.). Оно возрастает непропорционально при увеличении m и n: так, при m=33 и n=2 число различных криптографических преобразований равно 1089!. Отсюда следует, что потенциально существует большое число отображений исходного текста в шифрованный.
Практическая реализация криптографических систем требует, чтобы преобразования {Tk: kÎK} были определены алгоритмами, зависящими от относительно небольшого числа параметров (ключей).
Системы подстановок.
Определение Подстановкой p на алфавите Zm называется автоморфизм Zm, при котором буквы исходного текста t замещены буквами шифрованного текста p(t):
Zm à Zm; p: t à p(t).
Набор всех подстановок называется симметрической группой Zm è будет в дальнейшем обозначаться как SYM(Zm).
Утверждение SYM(Zm) c операцией произведения является группой, т.е. операцией, обладающей следующими свойствами:
Замкнутость: произведение подстановок p1p2 является подстановкой:
p: tàp1(p2(t)).
Ассоциативность: результат произведения p1p2p3 не зависит от порядка расстановки скобок:
(p1p2)p3=p1(p2p3)
Существование нейтрального элемента: постановка i, определяемая как i(t)=t, 0£t<m, является нейтральным элементом SYM(Zm) по операции умножения: ip=pi для "pÎSYM(Zm).
Существование обратного: для любой подстановки p существует единственная обратная подстановка p-1, удовлетворяющая условию
pp‑1=p‑1p=i.
Число возможных подстановок в симметрической группе Zm называется порядком SYM(Zm) и равно m! .
Определение. Ключом подстановки k для Zm называется последовательность элементов симметрической группы Zm:
k=(p0,p1,...,pn-1,...), pnÎSYM(Zm), 0£n<¥
Подстановка, определяемая ключом k, является криптографическим преобразованием Tk, при помощи которого осуществляется преобразование n-граммы исходного текста (x0 ,x1 ,..,xn-1) в n-грамму шифрованного текста (y0 ,y1 ,...,yn-1):
yi=p(xi), 0£i<n
где n – произвольное (n=1,2,..). Tk называется моноалфавитной подстановкой, если p неизменно при любом i, i=0,1,..., в противном случае Tk называется многоалфавитной подстановкой.
Примечание. К наиболее существенным особенностям подстановки Tk относятся следующие:
1. Исходный текст шифруется посимвольно. Шифрования n-граммы (x0 ,x1 ,..,xn-1) и ее префикса (x0 ,x1 ,..,xs-1) связаны соотношениями
Tk(x0 ,x1 ,..,xn-1)=(y0 ,y1 ,...,yn-1)
Tk(x0 ,x1 ,..,xs-1)=(y0 ,y1 ,...,ys-1)
2. Буква шифрованного текста yi является функцией только i-й компоненты ключа pi и i-й буквы исходного текста xi.
В потоковых шифрах, т. е. при шифровании потока данных, каждый бит исходной информации шифруется независимо от других с помощью гаммирования.
Гаммирование - наложение на открытые данные гаммы шифра (случайной или псевдослучайной последовательности единиц и нулей) по определенному правилу. Обычно используется "исключающее ИЛИ", называемое также сложением по модулю 2 и реализуемое в ассемблерных программах командой XOR. Для расшифровывания та же гамма накладывается на зашифрованные данные.
При однократном использовании случайной гаммы одинакового размера с зашифровываемыми данными взлом кода невозможен (так называемые криптосистемы с одноразовым или бесконечным ключом). В данном случае "бесконечный" означает, что гамма не повторяется.
В некоторых потоковых шифрах ключ короче сообщения. Так, в системе Вернама для телеграфа используется бумажное кольцо, содержащее гамму. Конечно, стойкость такого шифра не идеальна.
Понятно, что обмен ключами размером с шифруемую информацию не всегда уместен. Поэтому чаще используют гамму, получаемую с помощью генератора псевдослучайных чисел (ПСЧ). В этом случае ключ - порождающее число (начальное значение, вектор инициализации, initializing value, IV) для запуска генератора ПСЧ. Каждый генератор ПСЧ имеет период, после которого генерируемая последовательность повторяется. Очевидно, что период псевдослучайной гаммы должен превышать длину шифруемой информации.
Генератор ПСЧ считается корректным, если наблюдение фрагментов его выхода не позволяет восстановить пропущенные части или всю последовательность при известном алгоритме, но неизвестном начальном значении.
При использовании генератора ПСЧ возможно несколько вариантов:
1. Побитовое шифрование потока данных. Цифровой ключ используется в качестве начального значения генератора ПСЧ, а выходной поток битов суммируется по модулю 2 с исходной информацией. В таких системах отсутствует свойство распространения ошибок.
2. Побитовое шифрование потока данных с обратной связью (ОС) по шифртексту. Такая система аналогична предыдущей, за исключением того, что шифртекст возвращается в качестве параметра в генератор ПСЧ. Характерно свойство распространения ошибок. Область распространения ошибки зависит от структуры генератора ПСЧ.
3. Побитовое шифрование потока данных с ОС по исходному тексту. Базой генератора ПСЧ является исходная информация. Характерно свойство неограниченного распространения ошибки.
4. Побитовое шифрование потока данных с ОС по шифртексту и по исходному тексту.
Чтобы получить линейные последовательности элементов гаммы, длина которых превышает размер шифруемых данных, используются датчики ПСЧ. На основе теории групп было разработано несколько типов таких датчиков.
Конгруэнтные датчики
В настоящее время наиболее доступными и эффективными являются конгруэнтные генераторы ПСП. Для этого класса генераторов можно сделать математически строгое заключение о том, какими свойствами обладают выходные сигналы этих генераторов с точки зрения периодичности и случайности.
Одним из хороших конгруэнтных генераторов является линейный конгруэнтный датчик ПСЧ. Он вырабатывает последовательности псевдослучайных чисел T(i), описываемые соотношением
T(i+1) = (A*T(i)+C) mod m,
где А и С - константы, Т(0) - исходная величина, выбранная в качестве порождающего числа. Очевидно, что эти три величины и образуют ключ.
Такой датчик ПСЧ генерирует псевдослучайные числа с определенным периодом повторения, зависящим от выбранных значений А и С. Значение m обычно устанавливается равным 2n , где n - длина машинного слова в битах. Датчик имеет максимальный период М до того, как генерируемая последовательность начнет повторяться. По причине, отмеченной ранее, необходимо выбирать числа А и С такие, чтобы период М был максимальным. Как показано Д. Кнутом, линейный конгруэнтный датчик ПСЧ имеет максимальную длину М тогда и только тогда, когда С - нечетное, и А mod 4 = 1.
Для шифрования данных с помощью датчика ПСЧ может быть выбран ключ любого размера. Например, пусть ключ состоит из набора чисел x(j) размерностью b, где j=1, 2, ..., n. Тогда создаваемую гамму шифра G можно представить как объединение непересекающихся множеств H(j).
Шифрование с помощью датчика ПСЧ является довольно распространенным криптографическим методом. Во многом качество шифра, построенного на основе датчика ПСЧ, определяется не только и не столько характеристиками датчика, сколько алгоритмом получения гаммы. Один из фундаментальных принципов криптологической практики гласит, даже сложные шифры могут быть очень чувствительны к простым воздействиям.
Рассмотрим базовые алгоритмы подробнее.
Шифр Полибия.
Самый, пожалуй, древний из всех известных, хотя и не такой распространенный, как шифр Цезаря. Полибий, греческий историк, умер за тридцать лет до появления Цезаря. Суть его метода в том, что составляется прямоугольник (Доска Полибия), например такой, как представлен на рисунке 1.1.
| А | Б | В | Г | Д | Е | |
| А | А | Б | В | Г | Д | Е |
| Б | Ж | З | И | Й | К | Л |
| В | М | Н | О | П | Р | С |
| Г | Т | У | Ф | Х | Ц | Ч |
| Д | Ш | Щ | Ъ | Ы | Ь | Э |
| Е | Ю | Я | . | , | - |
Рисунок 1.1 – Доска Полибия
Каждая буква может быть представлена парой букв, указывающих строку и столбец, в которых расположена данная буква. Так, представлением букв П, О будут ВГ, ВВ соответственно, а сообщение ШИФР ПОЛИБИЯ зашифруется как ДАБВГВВДЕЕВГВВБЕБВАББВЕБ. Хоть эта система и является более древней, но устойчивость к раскрытию у нее гораздо выше, несмотря на то, что наблюдается увеличение количества символов зашифрованного текста.
Шифр Цезаря.
Первый документально подтвержденный шифр: Гай Юлий Цезарь, желая защитить свои записи, заменял каждую букву следующей по алфавиту. Можно расширить этот алгоритм, поставив в соответствие каждой букве, какую либо другую букву, разумеется, без повторений. Можно даже заменять буквы совершенно сторонними символами, это не повлияет на криптостойкость.
Во времена Цезаря, когда мало кто умел читать, да и статистика не была особенно развитой, такой шифр было почти невозможно взломать. Но теперь этот способ шифрования используют только в качестве головоломок.
Объяснить это легко. Посчитав вхождение каждого символа в тексте, и зная статистические особенности языка, то есть частоту появления каждого символа в текстах, можно смело заменить часть символов на настоящие. Остальной текст можно получить исходя из избыточности текстов на естественных языках. Очевидно также, что шифр Цезаря можно использовать только для текстов.
 Это один из самых старых шифров, имеющий ряд серьезных недостатков. Огромное семейство подстановок Цезаря названо по имени римского императора Гая Юлия Цезаря, который поручал Марку Туллию Цицерону составлять послания с использованием 50-буквенного греческого алфавита со сдвигом в 3 знака и дальнейшей подстановкой. Информация об этом дошла к нам от Светония. Попробуем воспроизвести этот метод шифрования для русского алфавита. Для этого создадим таблицу соответствия (рис. 1.2):
Это один из самых старых шифров, имеющий ряд серьезных недостатков. Огромное семейство подстановок Цезаря названо по имени римского императора Гая Юлия Цезаря, который поручал Марку Туллию Цицерону составлять послания с использованием 50-буквенного греческого алфавита со сдвигом в 3 знака и дальнейшей подстановкой. Информация об этом дошла к нам от Светония. Попробуем воспроизвести этот метод шифрования для русского алфавита. Для этого создадим таблицу соответствия (рис. 1.2):
Рисунок 1.2 – Пример таблицы соответствия букв русского алфавита
Шифр Ришелье.
Совершенно “естественно” выглядит криптотекст, полученный с помощью криптосистемы Ришелье. Соответственно, защищенность этого алгоритма гораздо выше предыдущих. В основе лежит “замешивание” по определенным законам исходного текста в “мусоре”, или посторонних символах. Зашифрованный текст получается гораздо длиннее исходного, причем эта разница и определяет реальную криптостойкость системы. Суть метода Ришелье в следующем. Создается подобная решетка с прорезями вместо крестов (рис. 1.3):
| Х | Х | Х | Х | ||||||
| Х | Х | Х | Х | ||||||
| Х | |||||||||
| Х | Х | Х | Х | Х | |||||
| Х | Х | ||||||||
| Х | Х | Х | Х | Х |
Рисунок 1.3 – Пример решетки Ришелье
Далее в прорезях отверстий пишется текст, решетка снимается и все оставшееся пространство заполняется “мусором”, затем для усложнения расшифровки криптотекст можно выписать в ряд. Для длинных сообщений этот метод применяется несколько раз. Кстати говоря, выходной криптотекст можно оформить с помощью “мусора” и в виде смыслового послания. Выполнить обратное преобразование в исходный текст можно, зная размер блока и имея аналогичную решетку.
Перестановочные шифры.
Этот шифр тоже является одним из первых, он предполагает разбиение текста на блоки, а затем перемешивание символов внутри блока. Это можно сделать разными методами. В первых вариантах этого шифра использовалась таблица, которую заполняли по строкам исходными данными, а зашифрованные данные читали по столбцам.
Криптостойкость этого шифра также оставляет желать лучшего. Дело в том, что филологи уже давно установили, что для прочтения текста не важен порядок букв в слове, достаточно чтобы на месте были первая и последняя буквы слова. Конечно, размер блока не может совпадать с размерами всех слов текста, то есть перемешивание будет более серьезным, но научится читать такой текст не очень сложно.
Рассмотрим этот метод на несложном алгоритме простой столбцевой перестановки. Предварительно условимся, что число столбцов равно пяти. Допустим, имеется текст, который требуется зашифровать: “ПРОСТЫЕ ПЕРЕСТАНОВКИ ВНОСЯТ СУМЯТИЦУ”. Запишем этот текст слева направо, сверху вниз, заполняя последовательно пять столбцов (рис 1.4):
| 1 | 2 | 3 | 4 | 5 |
| П | Р | О | С | Т |
| Ы | Е | П | Е | |
| Р | Е | С | Т | А |
| Н | О | В | К | И |
| В | Н | О | С | |
| Я | Т | С | У | |
| М | Я | Т | И | Ц |
| У | ||||
Рисунок 1.4 – Пример простой столбцевой перестановки
Теперь зададимся ключом, например 35142, и выпишем в ряд столбцы, начиная с третьего, в соответствии с ключом: “О СВН Т ТЕАИСУЦ ПЫРН ЯМУСПТКОСИ РЕЕОВТЯ”. Получилось довольно неплохо. Для расшифровки требуется количество символов зашифрованного текста разделить на 5 и сформировать столбцы в соответствии с ключом.
В итоге получится исходная таблица, из которой можно прочитать текст построчно. Криптостойкость увеличится, если к полученному зашифрованному тексту применить повторное шифрование с другим размером таблицы и ключом или с перестановками не столбцов, а рядов. Перестановочные шифры очень хорошо сочетать с другими, таким образом повышая криптостойкость.
Шифр Виженера.
Наиболее известной и по праву одной из старейших многоалфавитных (одному шифруемому символу соответствует более одного символа) криптосистем является система известного французского криптографа графа Блейза Виженера (1523-1596).
Для преобразования строится алфавитный квадрат с построчным сдвигом символов в каждом последующем ряду (рисунок 1.5)

Рисунок 1.5 – Квадрат Виженера
Далее выбирается ключ. Затем пишется шифруемая фраза, а под ней циклически записывается ключ. Преобразование производится так: шифруемому символу соответствует символ, находящийся на пересечении буквы ключа (столбец) и буквы исходного текста (строка).
Одним и тем же буквам исходного текста соответствуют не всегда одинаковые символы, то есть символы могут принимать различные значения, что является несомненным плюсом в плане криптостойкости зашифрованного текста.
Далее выбирается ключ, например “ГРАФДРАКУЛА”. Затем пишется шифруемая фраза, а под ней циклически записывается ключ. Для примера возьмем фразу “ОТРЯД ЖДЕТ УКАЗАНИЙ” и исключим из нее пробелы:
“ОТРЯДЖДЕТУКАЗАНИЙ” – исходный текст, “ГРАФДРАКУЛАГРАФДР” – циклический ключ. Преобразование производится так: шифруемому символу соответствует символ, находящийся на пересечении буквы ключа (столбец) и буквы исходного текста (строка).
Получим: “СВРУИЦДПЕЮКГЧАБМЩ”. Как видно, одним и тем же буквам исходного текста соответствуют не всегда одинаковые символы, то есть символы могут принимать различные значения, что является несомненным плюсом в плане криптостойкости зашифрованного текста.
Квадрат может быть каким угодно, главное, чтобы он был легко воспроизводимым и левый столбец, так же как и верхний ряд, соответствовали всему алфавиту. В качестве альтернативного варианта это может быть известный квадрат Френсиса Бьюфорта, где строки – зеркальное отражение строк квадрата Виженера. Для усложнения строки могут быть переставлены местами в определенном порядке и т. д. Усложненной разновидностью этого метода является метод шифрования с автоключом, предложенный математиком Дж. Кардано (XVI в.). Суть его в том, что, кроме циклического ключа, есть еще один, записываемый однократно перед циклическим ключом – первичный ключ. Этот нехитрый прием придает дополнительную стойкость алгоритму.
Шифр Плейфейра.
Назван так в честь своего разработчика. Алгоритм заключается в следующем: сначала составляется равносторонний алфавитный квадрат. Для русского алфавита подойдет квадрат 5х6. Задается ключевая фраза без повторов букв, например “БАРОН ЛИС”. Фраза вписывается в квадрат без пробелов, далее последовательно вписываются недостающие буквы алфавита в правильной последовательности. Одну букву придется исключить для выполнения условия равносторонности. Пусть это будет Ъ. Примем допущение, что Ъ=Ь. Итак, получился квадрат, который легко восстановить по памяти:
Теперь условия для преобразования:
1) Текст должен иметь четное количество букв и делиться на биграммы (сочетания по две буквы), недостающую часть текста дополняем самостоятельно одним (любым) символом. Например, текст “ОСЕНЬ” преобразуется в “ОСЕНЬА”.
2) Биграмма не должна содержать одинаковых букв – “СОСНА” – “СО СН АБ”.
| Б | А | Р | О | Н |
| Л | И | С | В | Г |
| Д | Е | Ж | З | К |
| М | П | Т | У | Ф |
| Х | Ц | Ч | Ш | Щ |
| Ь | Ы | Э | Ю | Я |
Рисунок 1.6 – Пример алфавитного квадрата для шифрования методом Плейфера
Правила преобразования:
Если биграмма не попадает в одну строку или столбец, то мы смотрим на буквы в углах прямоугольника, образованного рассматриваемыми буквами. Например: “ДИ” = “ЛЕ”, “ЬУ” = “МЮ” и т. д.
Если биграмма попадает в одну строку (столбец), мы циклично смещаемся на одну букву вправо (вниз). Например, “ЛС”=“ИВ”, “ТЭ”=“ЧР”.
Итак, мы готовы преобразовать текст. Приступим к шифрованию:
“СОВЕЩАНИЕ СОСТОИТСЯ В ПЯТНИЦУ” – первоначально преобразуется в биграммы: “СО ВЕ ЩА НИ ЕС ОС ТО ИТ СЯ ВП ЯТ НИ ЦУ”. Выполнив преобразование по вышеизложенным правилам, получим биграммы: “РВ ЗИ НЦ ГА ИЖ ВР РУ ПС ЭГ УИ ФЭ ГА ПШ”.
Обратите внимание на то, что одинаковые буквы на входе дали разные буквы на выходе криптосистемы, а одинаковые буквы на выходе совсем не соответствуют одинаковым на входе. Таким образом, криптотекст “РВЗИНЦГАИЖВРРУПСЭГУИ” выглядит гораздо более “симпатично”, чем после прямой замены моноалфавитной криптосистемы.
Правила преобразования могут значительно варьироваться. Алфавит может быть упрощен до логического минимума с целью сокращения квадрата. Например, можно переводить текст в транслитерацию и писать латинскими буквами, тогда квадрат будет размером 5х5.
Шифрование с ключом.
Этот метод относится к современному периоду.
Текст представляется в двоичном формате, создается двоичный код некоторого размера (ключ), двоичный текст разбивается на блоки того же размера и каждый блок суммируется по модулю два с ключом. Обратное преобразование выполняется тем же методом.
Фактически, это «современный шифр Цезаря», просто подстановка выполняется не посимвольно, а словами. Правда, понятие слова здесь несколько иное – это блок заданной длины.
Криптостойкость этого метода намного выше, чем у предыдущих шифров. Без использования специальных методов криптоанализа его будет очень сложно взломать. Но в настоящее время этот метод используют только для не очень важных документов, так как криптоанализ, в совокупности с современными вычислительными средствами, позволяет не только прочесть текст сообщения, но и во многих случаях получить ключ, что губительно для системы безопасности.
Система Вернама.
В 1949 году, Шеннон сформулировал и доказал свою «пессимистическую теорему»: шифр является абсолютно криптостойким тогда и только тогда, когда энтропия ключа больше либо равна энтропии исходного текста. Из теоремы следует, что длина ключа должна быть соразмерна с длиной текста. Если быть более точным, длина ключа должна равняться длине текста.
На основе этой теоремы построена система Вернама. Каждый бит ключа этой системы равновероятно равен 0 либо 1. Длина ключа равна длине текста. Ключ используется только один раз. Доказано, что этот шифр абсолютно не вскрываем. Не будем этого доказывать, но обоснуем.
Для вскрытия шифрованного сообщения необходимо перебрать все возможные комбинации ключей (это единственный способ, так как ключ используется лишь единожды), и среди полученных значений текста выбрать исходный, пусть это будет текст на русском языке. Допустим, что злоумышленник может это сделать мгновенно, то есть опустим временную сложность такой задачи. Для текста любой длины, будет много бессмысленных результатов и их можно отбросить, но злоумышленник получит все возможные тексты заданной длины, в том числе наш текст. Но ничто и никогда не укажет на то, какой из текстов является исходным.
Рассмотрим это на примере четырех буквенных имен. Пусть зашифровано имя «Даша», а ключ «АБВГ». Если используется кодировка ASCII, то зашифрованный текст выглядит следующим образом: ♦!j#. Как говорилось ранее, единственный способ дешифровать текст, полный перебор всех возможных ключей. Но очевидно, что существует такой ключ, суммирование с которым зашифрованного текста даст в результате «Маша», или даже «Миша». Но действительно, невозможно ответить на вопрос, какое из имен является исходным.
Возможно, что аналитик знает часть текста, например, он знает что это договор на продажу недвижимости, но не знает цену. В результате перебора, если на это хватит времени, он получит все возможные цены «заданной длины». То есть если цена трехзначная, аналитиком будет получена девятьсот одна различная цена. Таким образом, взлом системы Вернама не приведет к получению новой информации и является абсолютно невскрываемым.
Недостаток этой системы – длина ключа. Сам Вернам предлагал пересылать ключ курьером. При этом если курьер не довез ключ, можно сгенерировать новый ключ и снова его отправить. Однако такой механизм чрезвычайно неудобен, поэтому эта система не используется в настоящее время.
Этот шифр при его идеальности лишен помехоустойчивости, потому как изменение одного бита, практически невозможно отследить.
Шифры, основанные на системе Вернама.
Если мы не можем использовать очень длинный ключ, следует использовать короткий, удлиняя его по некоторому правилу. Было предпринято много попыток создать шифр, как можно более приближенный к системе Вернама.
Первой попыткой было использование ключа в качестве параметров генератора псевдослучайных последовательностей. На деле все системы сводились именно к этому. Но в некоторых случаях ключ получали за счет его преобразований, например, с помощью нелинейной функции.
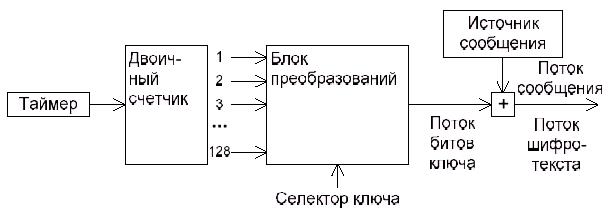
Рисунок 1.7 - Генерация ключа, для имитации системы Вернама
Наиболее удачной была схема, в которой ключ подавался на вход блоку преобразований (рисунок 1.7) одновременно с выходом двоичного счетчика, подключенного к таймеру. Для передачи сообщения правда требовалась большая синхронизация, нежели для системы Вернама, но вполне приемлемая.
Шифр «Люцифера».
Этот шифр изначально разрабатывался для аппаратной реализации. Именно при его создании одновременно использовались новейшие достижения в математике и теории кодирования и опыт веков.
«Люцифер» был создан фирмой IBM и долго использовался для внутренних нужд, так как аппаратная реализация системы шифрования имеет некоторые недостатки.
Авторы шифра предложили совместить два основных подхода к шифрованию: подстановки и перестановки.
Сначала, текст разбивается на блоки по n бит. Затем они поступают на вход мультиплексора, который раскладывает блок по модулю 2^n. Биты перемешиваются, и обрабатываются демультиплексором, который собирает биты в блок длиной n бит.
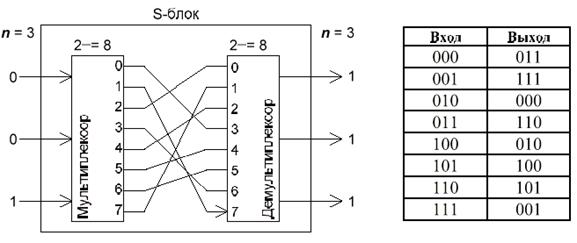
Рисунок 1.8 - Подстановки «Люцифера»
Преимущество таких постановок (Рисунок 1.8) заключается в нелинейности преобразований. По большому счету, можно любой входной поток превратить в любой выходной, но, разумеется, это производится на этапе разработки.
Выполнив подстановку, следует выполнить перестановки. Это делается соответствующей схемой, в которой просто перемешиваются биты (рисунок 1.9).
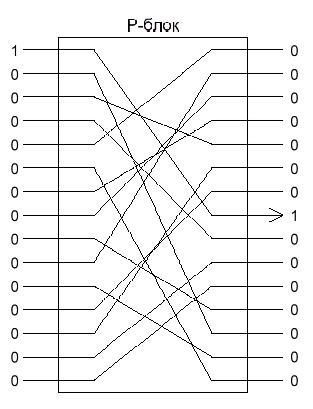
Рисунок 1.9 - Подстановки «Люцифера»
Узнать коммутацию такого блока довольно легко, достаточно подавать ровно одну единицу на вход, и получать ровно одну единицу на выходе. Однако, совместив оба подхода, и создавая как бы несколько итераций, можно очень сильно запутать аналитика (рисунок 1.10).
Легко увидеть, что если на вход подать одну единицу, на выходе получается больше единиц, чем нулей. Криптоаналитик, получивший текст, зашифрованный «Люцифером» будет поставлен в тупик.
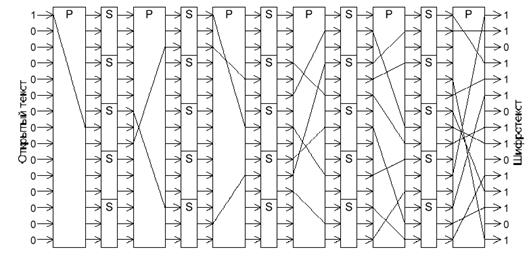
Рисунок 1.10 - «Люцифер»
Для этого шифра очень важно правильно подобрать параметры преобразований обоих типов. Дело в том, что при неудачном выборе параметров преобразований, они могут свестись к простой перестановке, которую легко раскрыть. Поэтому в аппаратную реализацию шифра встроили «сильные параметры.
Однако, аппаратная реализация шифра не позволяет его широкого применения, так как блок подстановок выполняет преобразование, схожее с суммированием с ключом, а суммирование с одним и тем же ключом ставит шифр под удар. С одной стороны, все, кто имеет доступ к системе, знают ключ, поэтому может произойти утечка, с другой стороны, аналитик, получивший достаточно много шифровок сможет таки дешифровать сообщение.
Было несколько попыток избавиться от этого недостатка, но наиболее удачная из них заключалась в том, чтобы каждый блок подстановок заменить двумя, при этом для шифрования, пользователь указывает первый или второй вид подстановок выполнять, создавая двоичный ключ (рисунок 1.11).
Такая реализация шифра была гораздо более криптостойкой и использовалась некоторое время.
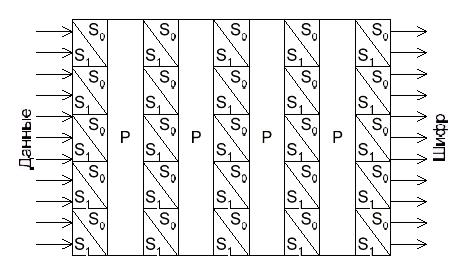
Рисунок 1.11 - «Люцифер» с ключом
Действительно криптостойкий шифр на основе «Люцифера» был предложен в 1973 году Хорстом Фейстелем. Этот алгоритм на самом деле является общим случаем «Люцифера».
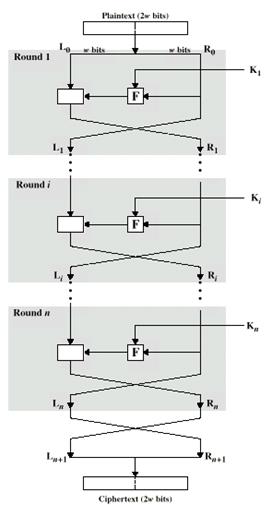
Рисунок 1.12 - Классическая сеть Фейстеля
Классическая (или простая) сеть Фейстеля (рисунок 1.12) разбивает исходный текст на блок длиной 2n бит, каждый блок разбивается на два потока L (левый) и R(правый). Далее выполняется преобразование по формуле:
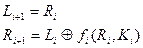
где Ki – ключ, Fi – функция преобразования.
Каждое такое действие называется раундом. Обычно используется 8-16 раундов. При этом, ключ в каждом раунде может быть как частью общего ключа, так и ее модификацией по некоторому правилу: следует отметить, что это в значительной мере влияет на криптостойкость. Также важным является правило, по которому текст разбивается на потоки.
Основное достоинство алгоритма заключается в том, что функция f не обязана быть обратимой, более того, для повышения криптостойкости обычно используют нелинейные именно необратимые функции.
Ключ, с которым суммируется текст не повторяется из блока в блок, а изменяется в зависимости от самого текста, это значительно увеличивает его энтропию, и, следовательно, увеличивает криптостойкость метода.
Процедура расшифровки очевидна, следует применить те же формулы, но в обратном порядке. Некоторые исследователи нашли способ применять один и тот же алгоритм и для шифровки, и для расшифровки, для этого необходимо удвоить число раундов, и во второй половине расположить функции и ключи в обратном порядке. Но как показали эксперименты, криптотойкость при таком подходе значительно ниже.
В последствии были построены сети Фейстеля с большим числом потоков. Это позволило также усложнить подход к функциям преобразования. На рисунке 1.13 представлены примеры таких сетей.
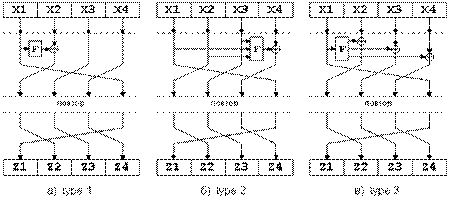
Рисунок 1.13 - Примеры сетей Фейстеля с большим числов потоков
Также существует несколько способов перемешивания: без него, симметричный, асимметричный, - представленные на рисунке 1.14.
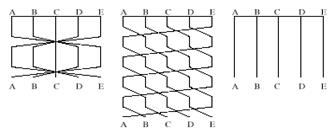
Рисунок 1.14 - Способы перемешивания потоков
Сравнивая сети Фейстеля с системой Вернама, становится очевидной высокая помехоустойчивость сетей Фейстеля: если система Вернама при искажении одного бита в зашифрованном тексте, искажала один бит в расшифрованном, то в сети Фейстеля этот бит повлияет на довольно большую часть текста и станет заметным, что позволит выявить случайные или преднамеренные искажения, и переслать шифрованный текст еще раз по другому каналу связи.
В последнее время появились упоминания так называемых Микро Декоррелированных Сетей Фейстеля. Суммируя текст с ключом, криптограф автоматически помещает информацию о ключе в зашифрованный текст, а получение ключа есть конечная цель любого криптоаналитика. Дэвид Вагнер, в своем труде «Атака бумерангом» описал способ уменьшить количество информации в тексте, зашифрованным сетью Фейстеля. Он предложил рассмотреть функции Fi как функции от текста, так, как если бы ключ был частью функции.
Рассмотрим для примера функцию f(x)=ax+b по одной паре х и f(x) нельзя ничего сказать об а и b. Чем больше пар необходимо, тем лучше такая функция. Но в сетях Фейстеля, криптоаналитик в худшем случае знает исходный текст и зашифрованный тексты, то есть исходные данные и результат последней функции, что делает задачу криптоанализа в случае микро декоррелирующих сетей почти невыполнимой.
Существуют также динамические сети Фейстеля, причем существует несколько их вариантов.
Первый вариант, более простой, предполагает изменение величины блока от раунда к раунду. С одной стороны, это значительно увеличивает время шифрования, так как уже нельзя выбрав блок, сразу полностью произвести все преобразования. С другой стороны, это в значительной мере изменяет статистические характеристики текста. Это легко объяснить тем, что происходит более глубокое перемешивание битов текста. Подстановки в этом случае также несколько отличаются: так как на разных раундах производится подстановка слов различной длины, символы, попадающие в разные блоки, в зависимости от раунда, изменяются по-другому.
Второй вид динамических сетей фейстеля несколько сложнее. Он использует множества отображающих функций – определенное количество функций, по числу блоков, каждая из которых применяется в своем блоке. При этом множество функций изменяется от раунда к раунду. Это изменение также может быть простым перемешиванием, но в идеале, функции не должны повторяться вообще.
Рассматривают также и объединение двух видов динамических сетей Фейстеля. Когда каждый блок суммируется с результатом своей собственной функции, и количество блоков изменяется в зависимости от раунда.
Задание к лабораторной работе
В соответствии с вариантом задания написать программу, реализующую один из базовых алгоритмов шифрования, при этом произвести некоторую модификацию выбранного алгоритма. Программа должна выполнять чтение файла, просмотр, его шифрование, расшифровывание, просмотр зашифрованного расшифрованного документа.
Отчет по лабораторной работе должен включать в себя: Краткое словесное описание базового алгоритма с его частичной модификацией, пример работы алгоритма, листинг программы, результаты работы программы.
Варианты заданий:
№ по журналу Базовый алгоритм
- 1-3 Шифр Полибия;
- 4-6 Шифр Цезаря;
- 7-9 Шифр Ришелье;
- 10-12 Перестановочный шифр;
- 13-15 Шифр Виженера
- 16-18 Шифрование с ключем
- 19-21 Шифр Вернама
21 – 25 Шифр Плейфейра.
-
Контрольные вопросы к лабораторной работе:
1) Что такое криптоанализ?
2) Что такое криптоскойкость алгоритма?
3) В чем суть перестановочных шифров?
4) В чем суть подстановочных шифров?
5) Назначение гаммирования.
6) Какой из рассмотренных базовых алгоритмов является по Вашему мнению наиболее криптостойким? Объяснить, почему.
7) Как, по Вашему мнению, можно увеличить криптостойкость алгоритма с использованием перестановок?
Лабораторная работа №2
Тема: Симметричные криптосистемы.
Цель работы: Изучение принципов шифрования в симметричных криптосистемах. Изучение классов преобразований в симметричных криптосистемах.
Методические указания к выполнению лабораторной работы
Криптографическая система это семейство преобразований шифра и совокупность ключей (т.е. алгоритм + ключи). Само по себе описание алгоритма не является криптосистемой. Только дополненное схемами распределения и управления ключами оно становится системой. Примеры алгоритмов – описания DES, ГОСТ28147-89. Дополненные алгоритмами выработки ключей, они превращаются в криптосистемы. Современные криптосистемы классифицируют следующим образом (рис. 2.1):
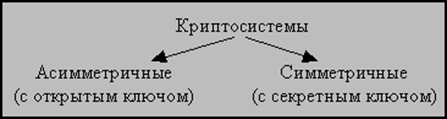
Рисунок 2.1 – Классификация криптосистем
Криптосистемы могут обеспечивать не только секретность передаваемых сообщений, но и их аутентичность (подлинность), а также подтверждение подлинности пользователя.
Симметричные криптосистемы (с секретным ключом - secret key systems) данные криптосистемы построены на основе сохранения в тайне ключа шифрования. Процессы зашифрования и расшифрования используют один и тот же ключ. Секретность ключа является постулатом. Основная проблема при применении симметричных криптосистем для связи заключается в сложности передачи обоим сторонам секретного ключа. Симметричные криптосистемы принято подразделять на блочные и поточные.
Блочные криптосистемы разбивают текст сообщения (файла, документа и т.д.) на отдельные блоки и затем осуществляют преобразование этих блоков с использованием ключа.
Поточные криптосистемы работают иначе. На основе ключа системы вырабатывается некая последовательность– так называемая выходная гамма, которая затем накладывается на текст сообщения. Таким образом, преобразование текста осуществляется как бы потоком по мере выработки гаммы.
Устройство блочных шифров.
Само преобразование шифра должно использовать следующие принципы (по К. Шеннону):
Рассеивание (diffusion) - т.е. изменение любого знака открытого текста или ключа влияет на большое число знаков шифротекста, что скрывает статистические свойства открытого текста;
Перемешивание (confusion) - использование преобразований, затрудняющих получение статистических зависимостей между шифротектстом и открытым текстом.
Практически все современные блочные шифры являются композиционными - т.е. состоят из композиции простых преобразований или F=F1oF2oF3oF4o..oFn, где F - преобразование шифра, Fi - простое преобразование, называемое также i-ым циклом шифрования. Само по себе преобразование может и не обеспечивать нужных свойств, но их цепочка позволяет получить необходимый результат. Например, стандарт DES состоит из 16 циклов. Если же используется одно и то же преобразование, т.е. Fi постоянно для i, то такой композиционный шифр называют итерационным шифром.
Наибольшую популярность имеют шифры, устроенные по принципу шифра Фейстеля (Файстеля - Feistel), в которых:
1. Входной блок для каждого преобразования разбивается на две половины: p=(l,r), где l - левая, a r - правая;
2. Используется преобразование вида Fi (l,r)=(r,l Ä fi(r)), где fi– зависящая от ключа Ki функция, а Ä - операция XOR или некая другая.
Функция fi называется цикловой функцией, а ключ Ki, используемый для получения функции fi называется цикловым ключом. Как можно заметить, с цикловой функцией складывается только левая половина, а правая остается неизменной. Затем обе половины меняются местами. Это преобразование прокручивается несколько раз (несколько циклов) и выходом шифра является получившаяся в конце пара (l,r) Графически все выглядит следующим образом (рис. 2.2):
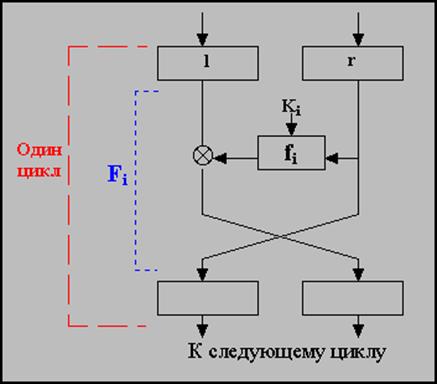
Рисунок 2.2 – Пример одного цикла преобразований
В качестве функции fi выступает некая комбинация перестановок, подстановок, сдвигов, добавлений ключа и прочих преобразований. Так, при использовании подстановок информация проходит через специальные блоки, называемые S-блоками (S-боксами, S-boxes), в которых значение группы битов заменяется на другое значение. По такому принципу (с небольшими отличиями) построены многие алгоритмы: DES, ит.п. В других алгоритмах используются несколько иные принципы. Так, например, алгоритмы, построенные по SP-принципу (SP-сети) осуществляют преобразование, пропуская блок через последовательность подстановок (Substitutions) и перестановок (Permutations). Отсюда и название– SP-сети, т.е. сети "подстановок-перестановок". Примером такого алгоритма является очень перспективная разработка Rijndael. Саму идею построения криптографически стойкой системы путем последовательного применения относительно простых криптографических преобразований была высказана Шенноном (идея многократного шифрования).
Размеры блоков в каждом алгоритме свои. DES использует блоки по 64 бита (две половинки по 32 бита), LOKI97 - 128 бит.
Получение цикловых ключей.
Ключ имеет фиксированную длину. Однако при прокрутке хотя бы 8 циклов шифрования с размером блока, скажем, 128 бит даже при простом прибавлении посредством XOR потребуется 8*128=1024 бита ключа, поскольку нельзя добавлять в каждом цикле одно и то же значение ,так как это ослабляет шифр. Поэтому для получения последовательности ключевых бит придумывают специальный алгоритм выработки цикловых ключей (ключевое расписание - key schedule). В результате работы этого алгоритма из исходных бит ключа шифрования получается массив бит определенной длины, из которого по определенным правилам составляются цикловые ключи. Каждый шифр имеет свой алгоритм выработки цикловых ключей.
Режимы работы блочных шифров.
Чтобы использовать алгоритмы блочного шифрования для различных криптографических задач существует несколько режимов их работы. Наиболее часто встречающимися в практике являются следующие режимы:
электронная кодовая книга - ECB (Electronic Code Book);
сцепление блоков шифротекста - CBC (Cipher Block Chaining);
обратная связь по шифротектсту - CFB (Cipher Feed Back);
обратная связь по выходу - OFB (Output Feed Back).
Обозначим применение шифра к блоку открытого текста как Ek(M)=C, где k - ключ, M - блок открытого текста, а C - получающийся шифротекст.
Электронная Кодовая Книга (ECB)
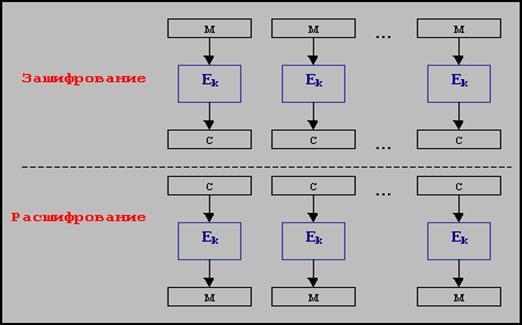
Рисунок 2.3 - Схема электронной кодовой книги
Исходный текст разбивается на блоки, равные размеру блока шифра. Затем каждый блок шифруют независимо от других с использованием одного ключа шифрования (рис.2.3).
Непосредственно этот режим применяется для шифрования небольших объемов информации, размером не более одного блока или для шифрования ключей. Это связано с тем, что одинаковые блоки открытого текста преобразуются в одинаковые блоки шифротекста, что может дать взломщику (криптоаналитику) определенную информацию о содержании сообщения. К тому же, если он предполагает наличие определенных слов в сообщении (например, слово "Здравствуйте" в начале сообщения или "До свидания" в конце), то получается, что он обладает как фрагментом открытого текста, так и соответствующего шифротекста, что может сильно облегчить задачу нахождения ключа.
Основным достоинством этого режима является простота реализации.
Сцепление блоков шифротекста (CBC)
Один из наиболее часто применимых режимов шифрования для обработки больших количеств информации. Исходный текст разбивается на блоки, а затем обрабатывается по следующей схеме (рис.2):
1. Первый блок складывается побитно по модулю 2 (XOR) с неким значением IV – вектором инициализации (Init Vector), который выбирается независимо перед началом шифрования.
2. Полученное значение шифруется.
3. Полученный в результате блок шифротекста отправляется получателю и одновременно служит начальным вектором IV для следующего блока открытого текста.
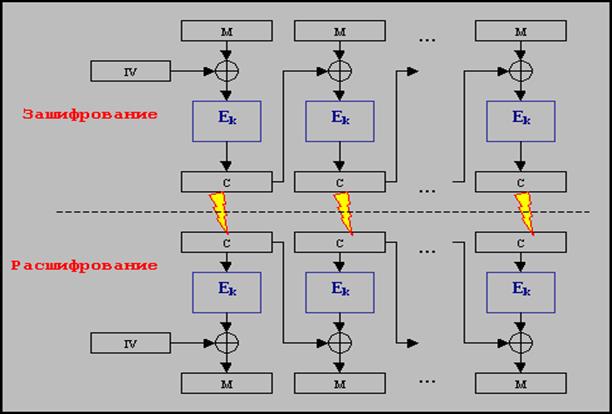
Рисунок 2.4 - Схема сцепления блоков шифротекста
Расшифрование осуществляется в обратном порядке.
В виде формулы, преобразование в режиме CBC можно представить как Ci=Ek(Mi Å Ci-1), где i - номер соответствующего блока. Из-за использования такого сцепления блоков шифротекста с открытым текстом пропадают указанные выше недостатки режима ECB, поскольку каждый последующий блок зависит от всех предыдущих. Если во время передачи один из блоков шифротекста исказится (передастся с ошибкой), то получатель сможет корректно расшифровать предыдущие блоки сообщения. Проблемы возникнут только с этим "бракованным" и следующим блоками. Одним из важных свойств этого режима является "распространение ошибки"– изменение блока открытого текста меняет все последующие блоки шифротекста. Поскольку последний блок шифротекста зависит от всех блоков открытого текста, то его можно использовать для контроля целостности и аутентичности (проверки подлинности) сообщения. Его называют кодом аутентификации сообщения (MAC - Message Authentication Code). Он может защитить как от случайных, так и преднамеренных изменений в сообщениях.
Обратная связь по шифротексту (CFB)
Режим может использоваться для получения поточного шифра из блочного. Размер блока в данном режиме меньше либо равен размеру блока шифра.
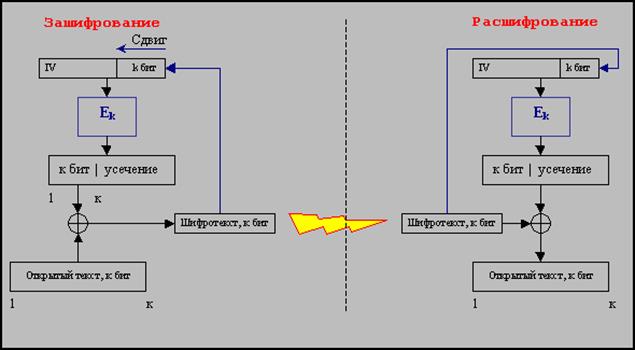
Рисунок 2.5 - Схема обратной связи по шифротексту
Описание работы схемы:
1. IV представляет собой сдвиговый регистр. Вначале IV заполняется неким значением, которое называется синхропосылкой, не является секретным и передается перед сеансом связи получателю.
2. Значение IV шифруется.
3. Берутся первые k бит зашифрованного значения IV и складываются (XOR) с k битами открытого текста. Получается блок шифротекста из k бит.
4. Значение IV сдвигается на k битов влево, а вместо него становится значение ш.т.
5. Затем опять 2 пункт и т.д до конца цикла шифрования.
Расшифрование происходит аналогично.
Особенностью данного режима является распространение ошибки на весь последующий текст. Рекомендованные значения k: 1 <= k <= 8.
Применяется, как правило, для шифрования потоков информации типа оцифрованной речи, видео.
Обратная связь по выходу (OFB)
Данный режим примечателен тем, что позволяет получать поточный шифр в его классическом виде, в отличии от режима CFB, в котором присутствует связь с шифротекстом. Принцип работы схож с принципом работы режима CFB, но сдвиговый регистр IV заполняется не битами шифротекста, а битами, выходящими из-под усечения.
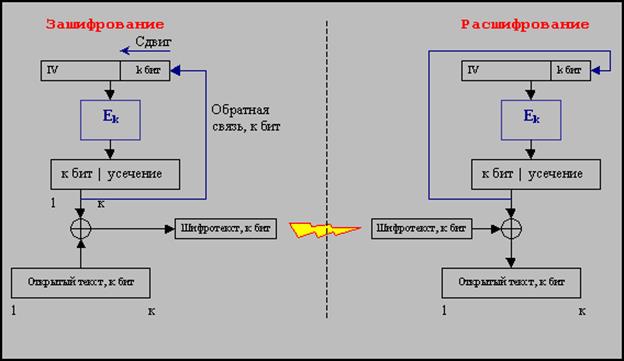
Рисунок 2.6 - Схема обратной связи по выходу
Расшифрование осуществляется аналогично. То есть, для любого блока длины k операция зашифрования выглядит следующим образом: Ci=Mi Å Gi, где Gi - результат зашифрования некоторого вектора, являющегося заполнением сдвигового регистра. Главное свойство шифра – единичные ошибки не распространяются, т.к. заполнение сдвигового регистра осуществляется независимо от шифротекста.
Область применения: потоки видео, аудио или данных, для которых необходимо обеспечить оперативную доставку. Широко используется у военных наряду с поточными шифрами.
Описание MD 5
После некоторой первоначальной обработки MD5 обрабатывает входной текст 512-битовыми блоками, разбитыми на 16 32-битовых подблоков. Выходом алгоритма является набор из четырех 32-битовых блоков, которые объединяются в единое 128-битовое хэш-значение.
Во-первых, сообщение дополняется так, чтобы его длина была на 64 бита короче числа, кратного 512. Этим дополнением является 1, за которой вплоть до конца сообщения следует столько нулей, сколько нужно. Затем, к результату добавляется 64-битовое представление длины сообщения (истинной, до дополнения). Эти два действия служат для того, чтобы длина сообщения была кратна 512 битам (что требуется для оставшейся части алгоритма), и чтобы гарантировать, что разные сообщения не будут выглядеть одинаково после дополнения. Инициализируются четыре переменных:
А = 0x01234567
В = 0x89abcdef
С = 0xfedcba98
D = 0x76543210
Они называются переменными сцепления.
Теперь перейдем к основному циклу алгоритма. Этот цикл продолжается, пока не исчерпаются 512-битовые блоки сообщения.
Четыре переменных копируются в другие переменные: А в а, В в b , С в с и D в d .
Главный цикл состоит из четырех очень похожих этапов. На каждом этапе 16 раз используются различные операции. Каждая операция представляет собой нелинейную функцию над тремя переменными из набора а, b , с и d . Затем она добавляет этот результат к четвертой переменной, подблоку текста и константе. Далее результат циклически сдвигается вправо на переменное число битов и добавляет результат к одной из переменных а, b , с и d . Наконец результат заменяет одну из переменных а, b , с и d . Существуют четыре нелинейных функции, используемые по одной в каждой операции (для каждого этапа - другая функция).
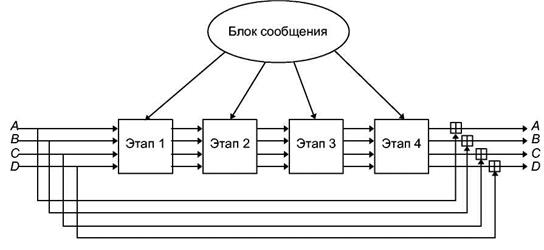
Рисунок 3.2 - Главный цикл MD5
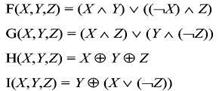
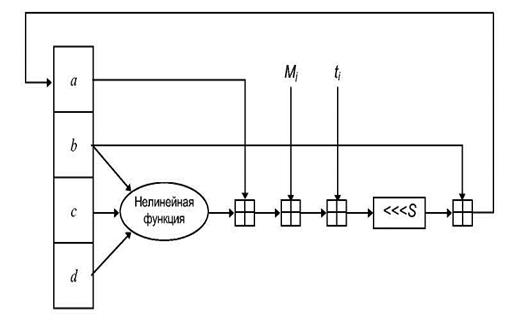
Рисунок 3.3 - Схема одной операции алгоритма MD5
Эти функции спроектированы так, чтобы, если соответствующие биты X , Y и Z независимы и несмещены, каждый бит результата также был бы независимым и несмещенным . Функция F - это побитовое условие: если X , то Y , иначе Z. Функция Н - побитовая операция четности.
Если Mj обозначает j-ый подблок сообщения (от 0 до 15), a <« s обозначает циклический сдвиг влево на s битов, то используются следующие четыре операции:
FF(a,b,c,d,Mj,s,ti) означает a = b + ((a + ¥(b,c,d) + М,- + tt) <«s)
GG(a,b,c,dMj,s,ti) означает a = b + ((a + G(b,c,d) + Mj + tt) <«s)
H H(a,b,c,d,Mj,s,ti) означает a = b + ((a + H(b,c,d) + M,- + tt) <«s)
II{a,b,c,dMj,s,ti) означает a = b + ((a + I(b,c,d) + Mj + tt) <«s)
Четыре этапа алгоритма.
Шаг 1: Добавление байтов заполнителей
Сообщение расширяется, так чтобы его длина (в битах) была 448 по модулю 512 – т.е. сообщению не хватает ровно 64 бит для кратности 512 битам. Добавление битов происходит в любом случае, даже если длина исходного сообщения изначально обладает этим свойством. Добавление происходит следующим образом:
- первый добавленный бит – «1», остальные «0». Минимум 1 бит, максимум 512.
Шаг 2: Добавление длины:
64 битное значение b (длины исходного сообщения) добавляется к сообщению. Если же длина более 2^64 (это маловероятно), то лишь младшие 64 бита длины используются.
Теперь сообщение имеет длину, кратную 512 битам (16 32 битных слова), его можно представить как слова:
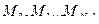 , где N- кратно 16
, где N- кратно 16
Шаг 3: Инициализация буфера MD
Буфер из четырех слов (A,B,C,D), используется для расчета MD. Инициализируется:
word A: 01 23 45 67word B: 89 ab cd efword C: fe dc ba 98word D: 76 54 32 10Шаг 4: Обработка сообщения блоками по 16 слов
Сначала определим четыре вспомогательных функции, на вход получают 3 слова, результат – слово.
F(X,Y,Z) = XY v not(X) Z
G(X,Y,Z) = XZ v Y not(Z)
H(X,Y,Z) = X xor Y xor Z
I(X,Y,Z) = Y xor (X v not(Z))
Каждый бит F – Если X то Y, иначе Z
Каждый бит G – Преобладающее значение X,Y,Z
Каждый бит H – xor, или контроль четности
Этот шаг использует специальную таблицу T[1..64], заполненную из значений синуса. T[i]=Целая часть 4294967296 * abs(sin(i)), где i в радианах.
Делаем следующее: Обрабатываем каждый блок в 16 слов. */ For i = 0 to N/16-1 do /* Копируем блок i в X. */ For j = 0 to 15 do X[j] = M[i*16+j]. end /* цикла j */ /* Сохраняем значения A как AA, B как BB, C как CC, и D как DD. */ AA = A BB = B CC = C DD = D /* Раунд 1. *//* Пусть [abcd k s i] определяют операцию
a = b + ((a + F(b,c,d) + X[k] + T[i]) <<< s). */
/* Делаем следующие 16 операций. */
[ABCD 0 7 1] [DABC 1 12 2] [CDAB 2 17 3] [BCDA 3 22 4]
[ABCD 4 7 5] [DABC 5 12 6] [CDAB 6 17 7] [BCDA 7 22 8]
[ABCD 8 7 9] [DABC 9 12 10] [CDAB 10 17 11] [BCDA 11 22 12]
[ABCD 12 7 13] [DABC 13 12 14] [CDAB 14 17 15] [BCDA 15 22 16]
/* Раунд 2. */
/* Пусть [abcd k s i] определяют операцию
a = b + ((a + G(b,c,d) + X[k] + T[i]) <<< s). */
/* Делаем следующие 16 операций. */
[ABCD 1 5 17] [DABC 6 9 18] [CDAB 11 14 19] [BCDA 0 20 20]
[ABCD 5 5 21] [DABC 10 9 22] [CDAB 15 14 23] [BCDA 4 20 24]
[ABCD 9 5 25] [DABC 14 9 26] [CDAB 3 14 27] [BCDA 8 20 28]
[ABCD 13 5 29] [DABC 2 9 30] [CDAB 7 14 31] [BCDA 12 20 32]
/* Раунд 3. */
/* Пусть [abcd k s t] определяют операцию
a = b + ((a + H(b,c,d) + X[k] + T[i]) <<< s). */
/* Делаем следующие 16 операций. */
[ABCD 5 4 33] [DABC 8 11 34] [CDAB 11 16 35] [BCDA 14 23 36]
[ABCD 1 4 37] [DABC 4 11 38] [CDAB 7 16 39] [BCDA 10 23 40]
[ABCD 13 4 41] [DABC 0 11 42] [CDAB 3 16 43] [BCDA 6 23 44]
[ABCD 9 4 45] [DABC 12 11 46] [CDAB 15 16 47] [BCDA 2 23 48]
/* Раунд 4. */
/* Пусть [abcd k s t] определяют операцию
a = b + ((a + I(b,c,d) + X[k] + T[i]) <<< s). */
/* Делаем следующие 16 операций. */
[ABCD 0 6 49] [DABC 7 10 50] [CDAB 14 15 51] [BCDA 5 21 52]
[ABCD 12 6 53] [DABC 3 10 54] [CDAB 10 15 55] [BCDA 1 21 56]
[ABCD 8 6 57] [DABC 15 10 58] [CDAB 6 15 59] [BCDA 13 21 60]
[ABCD 4 6 61] [DABC 11 10 62] [CDAB 2 15 63] [BCDA 9 21 64]
/* Изменяем ABCD – регистры для следующего блока */ A = A + AA B = B + BB C = C + CC D = D + DD end /* цикла по i */Шаг 5: Вывод
MD – это A,B,C,D – начиная с младшего байта A и заканчивая старшим байтом D (128 бит).
Безопасность MD 5
Рон Ривест привел следующие улучшения MD5 в сравнении с MD4 :
1. Добавился еще один этап.
2. Теперь в каждом действии используется уникальная прибавляемая константа .
3. Функция G на этапе 2 была изменена, чтобы сделать G менее симметричной.
4. Теперь каждое действие добавляется к результату предыдущего этапа. Это обеспечивает более быстрый лавинный эффект.
5. Изменился порядок, в котором использовались подблоки сообщения на этапах 2 и 3, чтобы сделать шаблоны менее похожими.
6. Значения циклического сдвига влево на каждом этапе были приближенно оптимизированы для ускорения лавинного эффекта. Четыре сдвига, используемые на каждом этапе, отличаются от значений, используемых на других этапах.
MD 2
MD2 - это другая 128-битовая однонаправленная хэш-функция, разработанная Роном Ривестом. Она вместе с MD5 используется для цифровой подписи в протоколах РЕМ. Безопасность MD2 опирается на случайную перестановку байтов. Эта перестановка фиксирована и зависит от цифр числа pi. Идентификаторы So , S 1, S 2, , S 255 являются перестановкой.
Чтобы выполнить хэширование сообщения М необходимо:
1. Дополнить сообщение i байтами, значение i должно быть таким, чтобы длина полученного сообщения была кратна 16 байтам.
2. Добавить к сообщению 16 байтов контрольной суммы.
3. Проинициализировать 48-байтовый блок: Хо, Х\, Х2, . . ., ХА1. Заполнить первые 16 байтов X нулями, во вторые 16 байтов X скопировать первые 16 байтов сообщения, а третьи 16 байтов X должны быть равны XOR первых и вторых 16 байтов X .
4. Вот как выглядит функция сжатия:
t = 0
For j = 0 to 17
For к = 0 to 47
t = Xk XOR St,
Xk=t
t = (t +j) mod 256
5. Скопировать во вторые 16 байтов Xвторые 16 байтов сообщения, а третьи 16 байтов X должны быть равны XOR первых и вторых 16 байтов X . Выполнить этап (4). Повторять этапы (3) и (4) по очереди для каждых 16 байтов сообщения.
6. Выходом являются первые 16 байтов X .
Хотя в MD2 пока не было найдено слабых мест, она работает медленнее большинства других предлагаемых хэш-функций.
Алгоритм безопасного хэширования ( Secure Hash Algorithm , SHA )
Алгоритм безопасного хэширования ( Secure Hash Algorithm, SHA), необходимый для обеспечения безопасности Алгоритма цифровой подписи (Digital Signature Algorithm, DSA). Для любого входного сообщения длиной меньше 264 битов SHA выдает 160-битовый результат, называемый кратким содержанием сообщения. Далее, краткое содержание сообщения становится входом DSA, который вычисляет подпись для сообщения. Подписывание краткого содержания вместо всего сообщения часто повышает эффективность процесса, так как краткое содержание сообщения намного меньше, чем само сообщение. То же краткое содержание сообщения должно быть получено тем, кто проверяет подпись, если принятая им версия сообщения используется в качестве входа SHA. SHA называется безопасным, так как он разработан так, чтобы было вычислительно невозможно найти сообщение, соответствующее данному краткому содержанию сообщения или найти два различных сообщения с одинаковым кратким содержанием сообщения . Любые изменения, произошедшие при п ередаче сообщения, с очень высокой вероятностью приведут к изменению краткого содержания сообщения, и подпись не пройдет проверку. Принципы, лежащие в основе SHA, аналогичны использованным профессором Рональдом Л. Ривестом при проектировании алгоритма краткого содержания сообщения MD4. SHA разработан по образцу упомянутого алгоритма.
SHA выдает 160-битовое хэш-значение, более длинное, чем у MD5
Описание SHA
Во-первых, сообщение дополняется, чтобы его длина была кратной 512 битам. Используется то же дополнение, что и в MD5: сначала добавляется 1, а затем нули так, чтобы длина полученного сообщения была на 64 бита меньше числа, кратного 512, а затем добавляется 64-битовое представление длины оригинального сообщения.
Инициализируются пять 32-битовых переменных (в MD5 используется четыре переменных, но рассматриваемый алгоритм должен выдавать 160-битовое хэш-значение):
А = 0x67452301
В = 0xefcdab89
С = 0x10325476
D = 0x10325476
E = 0xc3d2elf0
Затем начинается главный цикл алгоритма. Он обрабатывает сообщение 512-битовыми блоками и продолжается, пока не исчерпаются все блоки сообщения.
Сначала пять переменных копируются в другие переменные: А в а, В в b , С в с, D в d и Е в е.
Главный цикл состоит из четырех этапов по 20 операций в каждом (в MD5 четыре этапа по 16 операций в каждом). Каждая операция представляет собой нелинейную функцию над тремя из а, b , с, d и е, а затем выполняет сдвиг и сложение аналогично MD5. В SHA используется следующий набор нелинейных функций:
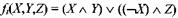 , для t=0 до 19
, для t=0 до 19 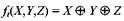 , для t=20 до 39
, для t=20 до 39
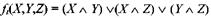 , для t=40 до 59
, для t=40 до 59  , для t=60 до 79 в алгоритме используются следующие четыре константы:
, для t=60 до 79 в алгоритме используются следующие четыре константы:
К t = 0х5а827999, для t=0 до 19
К t = 0x6ed9ebal , для t=20 до 39
К t = 0x8flbbcdc, для t=40 до 59
К t = 0xca62cld6, для t=60 до 79
(Если интересно, как получены эти числа, то :0х5а827999 = 21/2/4, 0x6ed9ebal = 31/2/4, 0x8flbbcdc = 51/2/4, 0xca62cld6 = 101/2/4; все умножено на 232)
Блок сообщения превращается из 16 32-битовых слов (Мо по М15) в 80 32-битовых слов ( W 0 no W 79 ) с помощью следующего алгоритма:
Wt = Mt , для t = 0 по 15
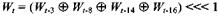 , для t=16 по 79
, для t=16 по 79
Если t - это номер операции (от 1 до 80), W , представляет собой t -ый подблок расширенного сообщения, а <<< - это циклический сдвиг влево на s битов, то главный цикл выглядит следующим образом:
FOR t = 0 to 79
TEMP = (а <<<5) +ft(b,c,d) + e+Wt + Kt
e = d
d = c
c = b <<< 30
b = a
a = TEMP
Ha рисунке 3.4 показана одна операция. Сдвиг переменных выполняет ту же функцию, которую в MD5 выполняет использование в различных местах различных переменных.
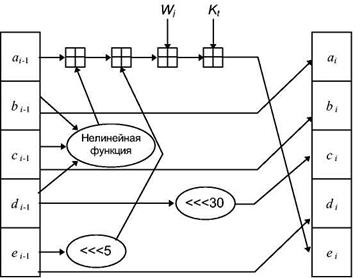
Рисунок 3.4 - Одна операция SHA.
После всего этого а, b , с, d и е добавляются к А, В, С D и Е, соответственно, и алгоритм продолжается для следующего блока данных. Окончательным результатом служит объединение А, В, С D и Е.
Безопасность SHA
SHA очень похожа на MD4, но выдает 160-битовое хэш-значение. Главным изменением является введение расширяющего преобразования и добавление выхода предыдущего шага в следующий с целью получения более быстрого лавинного эффекта.
Задание к лабораторной работе
1. Изучить алгоритм и разработать программу реализации алгоритма хеш-функции в соответствии с вариантом:
- алгоритм MD 2 - <номер по журналу > MOD 4 =0;
- алгоритм MD 4 - <номер по журналу > MOD 4 =1;
- алгоритм MD 5 - <номер по журналу > MOD 4 =2;
- алгоритм SHA - <номер по журналу > MOD 4 =0;
2. Проанализировать алгоритм с точки зрения его безопасности.
Контрольные вопросы к лабораторной работе:
1. Какова кратность длины исходного сообщения?
2. Какова разрядность вычисленного хеш-значения?
3. Какие логические операции используются в алгоритме?
4. Для чего используется метод МД-усиления?
5. Для чего используются однонаправленные хеш-функции?
Лабораторная работа №4
Тема: Ассиметричные алгоритмы шифрования. Шифрование данных алгоритмом RSA. Понятия электронно-цифровой подписи. ЭЦП RSA.
Цель работы: Изучение принципов шифрования в ассиметричных криптосистемах. Изучение и программная реализация алгоритма RSA, ЭЦП RSA.
Методические указания к выполнению лабораторной работы
Процесс криптографического закрытия данных может осуществляться как программно, так и аппаратно. Аппаратная реализация отличается существенно большей стоимостью, однако ей присущи и преимущества: высокая производительность, простота, защищенность и т.д. Программная реализация более практична, допускает известную гибкость в использовании.
Для современных криптографических систем защиты информации сформулированы следующие общепринятые требования:
зашифрованное сообщение должно поддаваться чтению только при наличии ключа;
число операций, необходимых для определения использованного ключа шифрования по фрагменту шифрованного сообщения и соответствующего ему открытого текста, должно быть не меньше общего числа возможных ключей;
число операций, необходимых для расшифровывания информации путем перебора всевозможных ключей должно иметь строгую нижнюю оценку и выходить за пределы возможностей современных компьютеров (с учетом возможности использования сетевых вычислений);
знание алгоритма шифрования не должно влиять на надежность защиты;
незначительное изменение ключа должно приводить к существенному изменению вида зашифрованного сообщения даже при использовании одного и того же ключа;
структурные элементы алгоритма шифрования должны быть неизменными;
дополнительные биты, вводимые в сообщение в процессе шифрования, должен быть полностью и надежно скрыты в шифрованном тексте;
длина шифрованного текста должна быть равной длине исходного текста;
не должно быть простых и легко устанавливаемых зависимостью между ключами, последовательно используемыми в процессе шифрования;
любой ключ из множества возможных должен обеспечивать надежную защиту информации;
алгоритм должен допускать как программную, так и аппаратную реализацию, при этом изменение длины ключа не должно вести к качественному ухудшению алгоритма шифрования.
Как бы ни были сложны и надежны симметричные криптографические системы - их слабое место при практической реализации - проблема распределения ключей. Для того, чтобы был возможен обмен конфиденциальной информацией между двумя субъектами информационной системы, ключ должен быть сгенерирован одним из них, а затем каким-то образом опять же в конфиденциальном порядке передан другому. Т.е. в общем случае для передачи ключа опять же требуется использование какой-то криптосистемы.
Для решения этой проблемы на основе результатов, полученных классической и современной алгеброй, были предложены системы с открытым ключом.
Суть их состоит в том, что каждым адресатом ИС генерируются два ключа, связанные между собой по определенному правилу. Один ключ объявляется открытым, а другой закрытым. Открытый ключ публикуется и доступен любому, кто желает послать сообщение адресату. Секретный ключ сохраняется в тайне.
Исходный текст шифруется открытым ключом адресата и передается ему. Зашифрованный текст в принципе не может быть расшифрован тем же открытым ключом. Дешифрование сообщение возможно только с использованием закрытого ключа, который известен только самому адресату.
Криптографические системы с открытым ключом используют так называемые необратимые или односторонние функции, которые обладают следующим свойством: при заданном значении x относительно просто вычислить значение f(x), однако если y=f(x), то нет простого пути для вычисления значения x.
Множество классов необратимых функций и порождает все разнообразие систем с открытым ключом. Однако не всякая необратимая функция годится для использования в реальных ИС.
В самом определении необратимости присутствует неопределенность. Под необратимостью понимается не теоретическая необратимость, а практическая невозможность вычислить обратное значение, используя современные вычислительные средства за обозримый интервал времени.
Обобщенная схема асимметричной криптосистемы с открытым ключом показана на рисунке 1. В этой криптосистеме применяют два различных ключа:
КВ – открытый ключ получателя В, используемый отправителем А:
kВ – секретный ключ получателя В.
Генератор ключей целесообразно располагать на стороне получателя В (чтобы не пересылать секретный ключ kВ по незащищенному каналу).

Рисунок 4.1 - Обобщенная схема асимметричной криптосистемы с открытым ключом
Процесс передачи зашифрованной информации в асимметричной криптосистеме осуществляется следующим образом:
1) Подготовительный этап:
- абонент В генерирует пару ключей: секретный ключ kВ и открытый ключ КВ ;
- открытый ключ КВ посылает абоненту А и остальным абонентам (или делается доступным, например, на разделяемом ресурсе).
2) Использование – обмен информацией между абонентами А и В:
- абонент А зашифровывает сообщение с помощью открытого ключа КВ абонента В и отправляет шифртекст абоненту В;
- абонент В расшифровывает сообщение с помощью своего секретного ключа kВ , Никто другой (в том числе абонент А) не может расшифровать данное сообщение, так как не имеет секретного ключа абонента В. Защита информации в асимметричной криптосистеме основана на секретности ключа kВ получателя сообщения.
Характерные особенности асимметричных криптосистем: открытый ключ и криптограмма могут быть отправлены по незащищенным каналам, то есть они известны противнику; алгоритмы шифрования и расшифрования являются открытыми.
Поэтому чтобы гарантировать надежную защиту информации, к системам с открытым ключом предъявляются два важных и очевидных требования:
1. Преобразование исходного текста должно быть необратимым и исключать его восстановление на основе открытого ключа.
2. Определение закрытого ключа на основе открытого также должно быть невозможным на современном технологическом уровне. При этом желательна точная нижняя оценка сложности (количества операций) раскрытия шифра.
Алгоритмы шифрования с открытым ключом получили широкое распространение в современных информационных системах. Так, алгоритм RSA стал мировым стандартом де-факто для открытых систем и рекомендован МККТТ.
Вообще же все предлагаемые сегодня криптосистемы с открытым ключом опираются на один из следующих типов необратимых преобразований:
1. Разложение больших чисел на простые множители.
2. Вычисление логарифма в конечном поле.
3. Вычисление корней алгебраических уравнений.
Здесь же следует отметить, что алгоритмы криптосистемы с открытым ключом можно использовать в трех назначениях.
1. Как самостоятельные средства защиты передаваемых и хранимых данных.
2. Как средства для распределения ключей. Алгоритмы рассматриваемой группы более трудоемки, чем традиционные криптосистемы. Поэтому часто на практике рационально с помощью систем с открытым ключом распределять ключи, объем которых как информации незначителен. А потом с помощью обычных алгоритмов осуществлять обмен большими информационными потоками.
3. Средства аутентификации пользователей (электронно-цифровая подпись).
Рассмотрим асимметричный алгоритм шифрования RSA.
Несмотря на довольно большое число различных систем с открытым ключом, наиболее популярна - криптосистема RSA, разработанная в 1977 году и получившая название в честь ее создателей: Рона Ривеста, Ади Шамира и Леонарда Эйдельмана.
Они воспользовались тем фактом, что нахождение больших простых чисел в вычислительном отношении осуществляется легко, но разложение на множители произведения двух таких чисел практически невыполнимо. Доказано (теорема Рабина), что раскрытие шифра RSA эквивалентно такому разложению. Поэтому для любой длины ключа можно дать нижнюю оценку числа операций для раскрытия шифра, а с учетом производительности современных компьютеров оценить и необходимое на это время.
Общее описание алгоритма RSA:
1. Отправитель выбирает два очень больших простых числа Р и Q и вычисляет два произведения N=PQ и M=(P-1)(Q-1).
2. Затем он выбирает случайное целое число D, взаимно простое с М, и вычисляет Е, удовлетворяющее условию DE = 1 MOD М.
3. После этого он публикует D и N как свой открытый ключ шифрования, сохраняя Е как закрытый ключ.
4. Если S - сообщение, длина которого, определяемая по значению выражаемого им целого числа, должна быть в интервале (1, N), то оно превращается в шифровку возведением в степень D по модулю N и отправляется получателю S'=(S**D) MOD N.
5. Получатель сообщения расшифровывает его, возводя в степень Е по модулю N, так как S =(S'**E) MOD N = (S**(D*E)) MOD N.
Таким образом, открытым ключом служит пара чисел N и D, а секретным ключом число Е.
Возможность гарантированно оценить защищенность алгоритма RSA стала одной из причин популярности этой системы с открытым ключом на фоне десятков других схем. Поэтому алгоритм RSA используется в банковских компьютерных сетях, особенно для работы с удаленными клиентами (обслуживание кредитных карточек).
В настоящее время алгоритм RSA используется во многих стандартах, среди которых SSL, S-HHTP, S-MIME, SWAN, STT и PCT.
Рассмотрим математические результаты, положенные в основу этого алгоритма.
Теорема 1. (Малая теорема Ферма.)
Если р - простое число, то
xp-1 = 1 (mod p) (1)
для любого х, простого относительно р, и
xp = х (mod p) (2)
для любого х.
Доказательство. Достаточно доказать справедливость уравнений (1) и (2) для хÎZp. Проведем доказательство методом индукции.
Далее
xp=(x-1+1)p= å C(p,j)(x-1)j=(x-1)p+1 (mod p),
0£j£p
так как C(p,j)=0(mod p) при 0<j<p. С учетом этого неравенства и предложений метода доказательства по индукции теорема доказана.
Определение. Функцией Эйлера j(n) называется число положительных целых, меньших n и простых относительно n.
| n | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| j(n) | 1 | 2 | 2 | 3 | 2 | 6 | 4 | 6 | 4 | 10 | 4 |
Теорема 2. Если n=pq, (p и q - отличные друг от друга простые числа), то
j(n)=(p-1)(q-1).
Теорема 3. Если n=pq, (p и q - отличные друг от друга простые числа) и х - простое относительно р и q, то
xj(n) = 1 (mod n).
Следствие . Если n=pq, (p и q - отличные друг от друга простые числа) и е простое относительно j(n), то отображение
Еe,n: x®xe (mod n)
является взаимно однозначным на Zn.
Очевиден и тот факт, что если е - простое относительно j(n), то существует целое d, такое, что
ed = 1 (mod j(n)) (3)
На этих математических фактах и основан популярный алгоритм RSA.
Пусть n=pq, где p и q - различные простые числа. Если e и d удовлетворяют уравнению (8.2.3), то отображения Еe,n и Еd,n являются инверсиями на Zn. Как Еe,n, так и Еd,n легко рассчитываются, когда известны e, d, p, q. Если известны e и n, но p и q неизвестны, то Еe,n представляет собой одностороннюю функцию; нахождение Еd,n по заданному n равносильно разложению n. Если p и q - достаточно большие простые, то разложение n практически не осуществимо. Это и заложено в основу системы шифрования RSA.
Пользователь i выбирает пару различных простых pi и qi и рассчитывает пару целых (ei, di), которые являются простыми относительно j(ni), где ni=pi qi . Справочная таблица содержит публичные ключи {(ei ,ni)}.
Предположим, что исходный текст
x =(x0, x1, ..., xn-1), xÎZn , 0 £ i < n,
сначала представлен по основанию ni :
N = c0+ci ni+....
Пользователь i зашифровывает текст при передаче его пользователю j, применяя к n отображение Edi,ni :
N ® Edi,ni n = n’.
Пользователь j производит дешифрование n’, применяя Eei,ni :
N’ ® Eei,ni n’= Eei,ni Edi,ni n = n .
Очевидно, для того чтобы найти инверсию Edi,ni по отношению к Eei,ni, требуется знание множителей n=pi qi. Время выполнения наилучших из известных алгоритмов разложения при n=10100 на сегодняшний день выходит за пределы современных технологических возможностей.
Рассмотрим небольшой пример, иллюстрирующий применение алгоритма RSA.
Пример: Зашифруем сообщение “САВ”. Для простоты будем использовать маленькие числа (на практике применяются гораздо большие).
1. Выберем p=3 и q=11.
2. Определим n=3*11=33.
3. Найдем (p-1)(q-1)=20. Следовательно, в качестве d, взаимно простое с 20, например, d=3.
4. Выберем число е. В качестве такого числа может быть взято любое число, для которого удовлетворяется соотношение (е*3) (mod 20) = 1, например 7.
5. Представим шифруемое сообщение как последовательность целых чисел с помощью отображения: А®1, В®2, С®3. Тогда сообщение принимает вид (3,1,2). Зашифруем сообщение с помощью ключа {7,33}.
ШТ1 = (37) (mod 33) = 2187 (mod 33) = 9,
ШТ2 = (17) (mod 33) = 1 (mod 33) = 1,
ШТ3 = (27) (mod 33) = 128 (mod 33) = 29.
6. Расшифруем полученное зашифрованное сообщение (9,1,29) на основе закрытого ключа {3,33}:
ИТ1 = (93) (mod 33) = 729 (mod 33) = 3,
ИТ2= (13) (mod 33) = 1 (mod 33) = 1,
ИТ3 = (293) (mod 33) = 24389 (mod 33) = 2.
Практическая реализация RSA
В настоящее время алгоритм RSA активно реализуется как в виде самостоятельных криптографических продуктов, так и в качестве встроенных средств в популярных приложениях.
Важная проблема практической реализации - генерация больших простых чисел. Решение задачи «в лоб» - генерация случайного большого числа n (нечетного) и проверка его делимости на множители от 3 вплоть до n 0.5. В случае неуспеха следует взять n+2 и так далее.
В принципе в качестве p и q можно использовать «почти» простые числа, то есть числа для которых вероятность того, что они простые, стремится к 1. Но в случае, если использовано составное число, а не простое, криптостойкость RSA падает. Имеются неплохие алгоритмы, которые позволяют генерировать «почти» простые числа с уровнем доверия 2-100.
Другая проблема - ключи какой длины следует использовать?
Для практической реализации алгоритмов RSA полезно знать оценки трудоемкости разложения простых чисел различной длины, сделанные Шроппелем.
| log10 n | Число операций | Примечания |
| 50 | 1.4*1010 | Раскрываем на суперкомпьютерах |
| 100 | 2.3*1015 | На пределе современных технологий |
| 200 | 1.2*1023 | За пределами современных технологий |
| 400 | 2.7*1034 | Требует существенных изменений в технологии |
| 800 | 1.3*1051 | Не раскрываем |
Сами авторы RSA рекомендуют использовать следующие размеры модуля n:
768 бит - для частных лиц;
1024 бит - для коммерческой информации;
2048 бит - для особо секретной информации.
Третий немаловажный аспект реализации RSA - вычислительный. Ведь приходится использовать аппарат длинной арифметики. Если используется ключ длиной k бит, то для операций по открытому ключу требуется О( k 2 ) операций, по закрытому ключу - О( k 3 ) операций, а для генерации новых ключей требуется О( k 4 ) операций.
Криптографический пакет BSAFE 3.0 (RSA D.S.) на компьютере Pentium-90 осуществляет шифрование со скоростью 21.6 Кбит/c для 512-битного ключа и со скоростью 7.4 Кбит/c для 1024 битного. Самая «быстрая» аппаратная реализация обеспечивает скорости в 60 раз больше.
Где H - хеш сообщения,
S - его сигнатура,
D - секретный ключ,
E - открытый ключ.
Проверке подлинности посвящены стандарты:
- проверка подлинности (аутентификация, authentication) - ISO 8730-90, ISO/IES 9594-90 и ITU X.509;
- целостность - ГОСТ 28147-89, ISO 8731-90;
- цифровая подпись - ISO 7498, P 34.10-94 (Россия), DSS (Digital Signature Standard, США).
Цифровая сигнатура
Часто возникают ситуации, когда получатель должен уметь доказать подлинность сообщения внешнему лицу. Чтобы иметь такую возможность, к передаваемым сообщениям должны быть приписаны так называемые цифровые сигнатуры.
Цифровая сигнатура - это строка символов, зависящая как от идентификатора отправителя, так и содержания сообщения.
 | |||
 | |||
Рисунок 4.1 - Цифровая сигнатура
Никто при этом кроме пользователя А не может вычислить цифровую сигнатуру А для конкретного сообщения. Никто, даже сам пользователь не может изменить посланного сообщения так, чтобы сигнатура осталась неизменной. Хотя получатель должен иметь возможность проверить является ли цифровая сигнатура сообщения подлинной. Чтобы проверить цифровую сигнатуру, пользователь В должен представить посреднику С информацию, которую он сам использовал для верификации сигнатуры.
Если помеченное сигнатурой сообщение передается непосредственно от отправителя к получателю, минуя промежуточное звено, то в этом случае идет речь об истинной цифровой сигнатуре.
Рассмотрим типичную схему цифровой сигнатуры.
Пусть Е - функция симметричного шифрования и f - функция отображения некоторого множества сообщений на подмножество мощности р из последовательности {1, ..., n}.
Например р=3 и n=9. Если m - сообщение, то в качестве f можно взять функцию f(m) = {2, 5, 7}.
Для каждого сообщения пользователь А выбирает некоторое множество ключей K=[K1, ..., Kn} и параметров V={v1, ...,vn} для использования в качестве пометок сообщения, которое будет послано В. Множества V и V’={E(v1,K1) ..., E(vn,Kn)} посылаются пользователю В и заранее выбранному посреднику С.
Пусть m - сообщение и idm - объединение идентификационных номеров отправителя, получателя и номера сообщения. Если f({idm, m}), то цифровая сигнатура m есть множество K’=[Ki, ..., Kj}. Сообщение m, идентификационный номер idm и цифровая сигнатура К’ посылаются В.

Рисунок 4.2 – Использование посредника
Получатель В проверяет сигнатуру следующим образом. Он вычисляет функцию f({idm, m}) и проверяет ее равенство К’. Затем он проверяет, что подмножество {vi, ...,vj} правильно зашифровано в виде подмножества {E(vi,Ki) ..., E(vj,Kj)} множества V’.
В конфликтной ситуации В посылает С сообщение m, идентификационный номер idm и множество ключей K’, которое В объявляет сигнатурой m. Тогда посредник С так же, как и В, будет способен проверить сигнатуру. Вероятность раскрытия двух сообщений с одним и тем же значением функции f должна быть очень мала. Чтобы гарантировать это, число n должно быть достаточно большим, а число р должно быть больше 1, но меньше n.
Ряд недостатков этой модели очевиден:
должно быть третье лицо - посредник, которому доверяют как получатель, так и отправитель;
получатель, отправитель и посредник должны обменяться существенным объемом информации, прежде чем будет передано реальное сообщение;
передача этой информации должна осуществляться в закрытом виде;
эта информация используется крайне неэффективно, поскольку множества K, V, V’ используются только один раз.
Тем не менее, даже такая схема цифровой сигнатуры может использоваться в информационных системах, в которых необходимо обеспечить аутентификацию и защиту передаваемых сообщений.
Использование цифровой сигнатуры предполагает использование некоторых функций шифрования:
S = H( k, T),
где S - сигнатура, k - ключ, T - исходный текст.
Функция H( k, T) - является хэш-функцией, если она удовлетворяет следующим условиям:
1) исходный текст может быть произвольной длины;
2) само значение H( k, T) имеет фиксированную длину;
3) значение функции H( k, T) легко вычисляется для любого аргумента;
4) восстановить аргумент по значению с вычислительной точки зрения - практически невозможно;
функция H( k, T) – однозначна
При этом разделяют слабую и сильную однозначность. При слабой однозначности для заданного значения T практически невозможно отыскать другой текст Т’, для которого H( k, T) = H( k, T’). При сильной однозначности для любого текста T невозможно найти другой подходящий текст, имеющий то же значение хэш-функции
Из определения следует, что для любой хэш-функции есть тексты-близнецы - имеющие одинаковое значение хэш-функции, так как мощность множества аргументов неограниченно больше мощности множества значений. Такой факт получил название «эффект дня рождения». (Факт теории вероятностей: в группе из 23 человек с вероятностью больше 0.5 два и более человека родились в одно и то же число)
Наиболее известные из хэш-функций - MD2, MD4, MD5 и SHA.
Три алгоритма серии MD разработаны Ривестом в 1989-м, 90-м и 91-м году соответственно. Все они преобразуют текст произвольной длины в 128-битную сигнатуру.
Алгоритм MD2 предполагает:
дополнение текста до длины, кратной 128 битам;
вычисление 16-битной контрольной суммы (старшие разряды отбрасываются);
добавление контрольной суммы к тексту;
повторное вычисление контрольной суммы.
Алгоритм MD4 предусматривает:
дополнение текста до длины, равной 448 бит по модулю 512;
добавляется длина текста в 64-битном представлении;
512-битные блоки подвергаются процедуре Damgard-Merkle, причем каждый блок участвует в трех разных циклах. (В отличие от хэш-функции - этот класс преобразований предполагает вычисление для аргументов фиксированной длины также фиксированных по длине значений)
Задание к лабораторной работе
Студенты, имеющие четный вариант по журналу, реализуют шифрование файлов с помощью алгоритма RSA.
Студенты, имеющие нечетный вариант по журналу, реализуют ЭЦП на базе RSA.
Контрольные вопросы к лабораторной работе:
1. Какие асимметричные алгоритмы шифрования Вы знаете?
2. Какие системы асимметричные или симметричные являются более криптостойкими, почему?
3. В чем отличие арбитражной электронной цифровой подписи от обычной.
4. Назначение сигнатуры? Использование сигнатурного подхода при реализации ЭЦП.
Лабораторная работа №5
Тема: Стеганографические методы защиты информации.
Цель работы: Изучение стеганографических методов защиты информации. Реализация программы с использованием стеганографических принципов защиты информации.
Аддитивные алгоритмы
Алгоритмы аддитивного внедрения информации заключаются в линейной модификации исходного изображения.
В аддитивных методах внедрения ЦВЗ представляет собой последовательность чисел wi, которая внедряется в выбранное подмножество пикселей исходного изображения f. Основное и наиболее часто используемое выражение для встраивания информации в этом случае
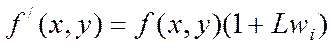 (1)
(1)
Другой способ встраивания был предложен И.Коксом:
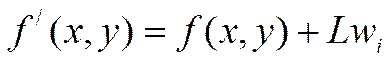 (2)
(2)
Тут:
-  - цвет пикселя с координатами x,y после преобразования
- цвет пикселя с координатами x,y после преобразования
-  - цвет пикселя с координатами x,y до преобразования
- цвет пикселя с координатами x,y до преобразования
-L - весовой коэффициент(целое положительное число)
-w(i)-встраиваемое в пиксель x,y число (символ)
Цвет пикселя должен представляться в виде одного целого числа.
Нужно отметить, что не все пиксели изображения модифицируются. Модифицируемые пиксели должны быть равномерно распределены по растру изображения. Например, на рисунке показано, как равномерно распределены модифицируемые пиксели по растру размером 5*5. В данном случае в растр «вшивается» информация размером 9 блоков (размер блока рекомендуется брать равным 1-му байту).
| * | * | * | ||
| * | * | * | ||
| * | * | * |
Естественно, размер растра зависит от размеров изображения-контейнера, а количество блоков - от количества «вшиваемой» в изображение информации.
Коэффициент L, рекомендуется изменять по определенному правилу при «вшивании» каждого блока информации. Это повышает устойчивость скрытой информации к дешифрованию.
Имеется массив возможный вариантов коэффициента L.
Правило выборки следующего L определяется правилом выборки следующего элемента массива. Примеры возможных алгоритмов выборки L:
1) прямой порядок;
2) поочередно прямой и обратный порядок выборки;
3) поочередно: L(i), i-четное
L(i), i-нечетное
4) L-константа
Нестандартный проход выбранных нами для модификации пикселей изображения также увеличивает стойкость алгоритма к дешифрованию. Примеры возможных проходов (в скобках указан порядковый номер пикселя при его модификации («вшивании» информации)):
1) построчный
| *(1) | *(2) | *(3) | ||
| *(4) | *(5) | *(6) | ||
| *(7) | *(8) | *(9) |
2) зигзагообразный
| *(1) | *(2) | *(3) | ||
| *(6) | *(5) | *(4) | ||
| *(7) | *(8) | *(9) |
3) по столбцам
| *(1) | *(4) | *(7) | ||
| *(2) | *(5) | *(8) | ||
| *(3) | *(6) | *(9) |
Примечание:
Рекомендуется в качестве базового формата брать формат, реализующий алгоритм сжатия информации без потерь (например, bmp или pcx). Формат Jpeg не подходит для выполнения работы, т.к. при восстановлении информации из изображения - часть информации теряется или искажается!
Для извлечения скрытой информации необходимо иметь 2 изображения - исходное и то, в которое была записана секретная информация.
Перебираем координаты и сравниваем цвета соответствующих пикселей в изображениях, в случае их несовпадения, мы выявляем пиксели, несущие в себе секретную информацию. Для каждой пары таких пикселей необходимо определить их цвета и выполнить операцию обратную операции преобразования цвета пикселя изображения. Например, для формулы (2) обратная операция будет выглядеть следующим образом:
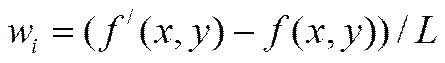
Примечание: способ перебора координат пикселей при сопоставлении цветов зависит от способа прохода пикселей при «вшивании» информации в изображение.
2)LSB-алгоритм
Цифровые изображения представляют собой матрицу пикселей. Пиксель – это единичный элемент изображения. Он имеет фиксированную разрядность двоичного представления. Например, пиксели полутонового изображения кодируются 8 битами (значения яркости изменяются от 0 до 255).
Младший значащий бит (LSB) изображения несет в себе меньше всего информации. Известно, что человек обычно не способен заметить изменение в этом бите. Фактически, он является шумом. Поэтому его можно использовать для встраивания информации. Таким образом, для полутонового изображения объем встраиваемых данных может составлять 1/8 объема контейнера. Например, в изображение размером 512х512 можно встроить 32 килобайта информации. Если модифицировать два младших бита (что также почти незаметно), то можно скрытно передать вдвое больший объем данных.
Достоинства рассматриваемого метода заключаются в его простоте и сравнительно большом объеме встраиваемых данных. Однако, он имеет серьезные недостатки. Во-первых, скрытое сообщение легко разрушить. Во-вторых, не обеспечена секретность встраивания информации. Нарушителю точно известно местоположение всего секретного сообщения.
Задание к лабораторной работе:
1) Реализовать аддитивный алгоритм (по варианту). Обеспечить возможность как «вшивания» информации (текста) в изображение, так и извлечение секретной информации. Также возможность сохранения и загрузки изображений с жесткого диска.
2) Реализовать алгоритм LSB(по варианту). Требования аналогичные по сравнению с аддитивным алгоритмом.
Таблица 5.2 – Варианты заданий к лабораторной работе
| Вариант | Аддитивный алгоритм | Алгоритм LSB | ||
| Вид аддитивной функции | Способ сканирования изображения | Правило получения следующего L | Число используемых младших бит | |
| 1 | 1 | 1 | 1 | 1 |
| 2 | 2 | 2 | 2 | 1 |
| 3 | 1 | 3 | 3 | 2 |
| 4 | 2 | 1 | 4 | 2 |
| 5 | 1 | 2 | 1 | 1 |
| 6 | 2 | 3 | 2 | 2 |
| 7 | 1 | 1 | 3 | 1 |
| 8 | 2 | 2 | 4 | 1 |
| 9 | 1 | 3 | 1 | 2 |
| 10 | 2 | 1 | 2 | 1 |
| 11 | 1 | 2 | 3 | 2 |
| 12 | 2 | 3 | 4 | 2 |
| 13 | 1 | 1 | 1 | 1 |
| 14 | 2 | 2 | 2 | 2 |
| 15 | 1 | 3 | 3 | 1 |
| 16 | 2 | 1 | 4 | 1 |
| 17 | 1 | 2 | 1 | 2 |
| 18 | 2 | 3 | 2 | 1 |
| 19 | 1 | 1 | 3 | 2 |
| 20 | 2 | 2 | 4 | 2 |
| 21 | 1 | 3 | 1 | 1 |
| 22 | 2 | 1 | 2 | 1 |
| 23 | 1 | 2 | 3 | 2 |
| 24 | 2 | 3 | 4 | 1 |
| 25 | 1 | 1 | 1 | 1 |
| 26 | 2 | 2 | 2 | 2 |
| 27 | 1 | 3 | 3 | 2 |
| 28 | 2 | 1 | 4 | 1 |
| 29 | 1 | 2 | 1 | 2 |
Вид аддитивной функции:
1- 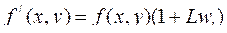
2- 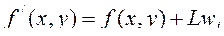
Способ сканирования изображения:
1) построчный
2) зигзагообразный
3) по столбцам
Правило получения следующего L:
1) прямой порядок;
2) поочередно прямой и обратный порядок выборки;
3) поочередно: L(i), i-четное
L(i), i-нечетное
4) L-константа
Контрольные вопросы к лабораторной работе:
1) Что собой представляет стеганография?
2) Перечислите области применения стеганографических алгоритмов шифрования?
3) Какие способы сканирования изображения Вы знаете?
4) В чем суть LSB-алгоритма?
5) От чего зависит криптостойкость стегасистем?
Литература
1. В.Столлингс, «Криптография и защита сетей. Принципы и практика», Издательский дом «Вильямс», Москва, С-Петербург, Киев, 2001 г., 669 стр.
2. Соколов А.В., Шаньгин В.Ф., «Защита информации в распределенных корпоративных сетях и системах», ДМК, Москва, 2002 г.
3. Саломаа А. «Криптография с открытым ключем», М.:Мир, 1995 г., 320 стр.
4. Шнайдер Б., «Прикладная криптография. Протоколы, алгоритмы и исходные тексты на языке С»
5. Баричев С., «Криптография без секретов»
6. Дж. Брассард «Современная криптология», 1988 г.
7. Шеннон К. «Теория связи в секретных системах. Примеры секретных систем»
8. Исагулиев К. П., «Справочник по криптологии», 2004 г, 238 стр.
9. Грибунин В.Г., Цифровая стеганография, СОЛОН-Пресс, 2002 можно скачать (http://www.autex.spb.ru/wavelet/books/dstego.htm)
10. Материалы сайта http://www.autex.spb.ru (http://www.autex.spb.ru/wavelet/stego.htm)
11. Генне О.В., Основные положения стеганографии // Защита информации. Конфидент, N3, 2000
Содержание
Лабораторная работа №1 «Базовые алгоритмы шифрования»………………...4
Лабораторная работа №2 «Симметричные криптосистемы»……………........29
Лабораторная работа №3 «Однонаправленные хеш-функции в криптографии» ………………………………………………………………..…40
Лабораторная работа №4 «Ассиметричные алгоритмы шифрования. Шифрование данных алгоритмом RSA. Понятия электронно-цифровой подписи. ЭЦП RSA» …………………………………………………………….59
Лабораторная работа №5 «Стеганографические методы защиты информации» …………………………………………………………………….77
Литература ………………………………………………………………………87
МЕТОДИЧЕСКИЕ УКАЗАНИЯ И ЗАДАНИЯ
к лабораторным работам по курсу
«Информационная безопасность»
(для студентов специальности 7.080403 “Программное обеспечение АС”)
(Часть 1 – Криптографические и стеганографические методы защиты информации)
Составители: Наталия Евгеньевна Губенко
Алла Викторовна Чернышова
МЕТОДИЧЕСКИЕ УКАЗАНИЯ И ЗАДАНИЯ
к лабораторным работам по курсу
«Информационная безопасность»
(для студентов специальности 7.080403 “Программное обеспечение АС”)
(Часть 1 – Криптографические и стеганографические методы защиты информации)
Донецк-ДонНТУ-2013
МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ УКРАИНЫ
ДОНЕЦКИЙ НАЦИОНАЛЬНЫЙ ТЕХНИЧЕСКИЙ УНИВЕРСИТЕТ
МЕТОДИЧЕСКИЕ УКАЗАНИЯ И ЗАДАНИЯ
к лабораторным работам по курсу
«Информационная безопасность»
(для студентов специальности 7.080403 “Программное обеспечение АС”)
(Часть 1 – Криптографические и стеганографические методы защиты информации)
Рассмотрено на заседании кафедры
КСМ
Протокол № от
Утверждено на заседании
учебно-издательского Совета ДонНТУ
протокол № от
Донецк –2013
УДК 681.3
Методические указания и задания к лабораторным работам по курсу «Информационная безопасность» для студентов специальности «Программное обеспечение АС», часть 1 - «Криптографические и стеганографические методы защиты информации»/ Сост.: Губенко Н.Е., Чернышова А.В. - Донецк, ДонНТУ, 2013 - 89 стр.
Приведены методические указания и задания к выполнению лабораторных работ по курсу «Информационная безопасность» для студентов специальности «Программное обеспечение АС». Излагаются вопросы, связанные с криптографическими и стеганографическими методами защиты информации. Рассматриваются простейшие базовые криптоалгоритмы, симметричные и ассиметричные криптосистемы, проверка подлинности информации средствами электронно-цифровой подписи, использование однонаправленных хэш-функций в криптографии, простейшие стеганографические алгоритмы защиты информации.
Методические указания предназначены для усвоения теоретических основ и формирования практических навыков по курсу «информационная безопасность» по разделу «Криптографические и стеганографические методы защиты информации».
Составители: доцент каф. КСМ, к.т.н. Губенко Н.Е.
Ст.преп. каф. ПМиИ Чернышова А.В.
Рецензент:
Лабораторная работа №1
Тема: Базовые алгоритмы шифрования.
Цель: Изучить базовые алгоритмы шифрования и написать программу, выполняющую шифрование текста с помощью одного из базовых алгоритмов, выполнив предварительно модификацию базового алгоритма шифрования.
Методические указания к лабораторной работе
Рассматриваемые простейшие методы кодирования заключаются в видоизменении информации таким образом, чтобы при попытке ее прочитать, злоумышленник не увидел ничего, кроме бессмысленной последовательности символов, а при попытке подделать или переделать документ, читатель, увидев ту же бессмыслицу, сразу понял бы это. Это и называется шифрованием или криптографией.
Зашифровав текст, его можно переправлять любым доступным способом, но никто не сможет узнать содержимое послания. Хотя, последнее не совсем верно, так как злоумышленник может попытаться раскрыть код.
Наука о раскрытии шифров – криптоанализ – всегда развивалась параллельно шифрованию. В последнее время, обе науки начали опираться на серьезный математический анализ, что только усилило их противоборство.
Не всегда криптоанализ используется злоумышленником. Дело в том, что преступная организация также может зашифровать послание. Тогда, дешифрация сообщения может оказаться жизненно важной. Поэтому, употреблять слово злоумышленник, говоря о шифровании, не совсем корректно, тем более, что в военном конфликте понятия прав и виноват весьма и весьма относительны. Но если сообщение шифруется, всегда есть опасность попытки его дешифрации.
Именно поэтому появился термин криптостойкость, то есть устойчивость алгоритма к криптоанализу.
Прежде чем говорить о более сложных алгоритмах шифрования, рассмотрим базовые алгоритмы, которые частично используются в современных алгоритмах шифрования. К простейшим алгоритмам шифрования относятся:
- шифр Полибия;
- шифр Цезаря;
- шифр Ришелье;
- перестановочный шифр;
- шифр Виженера;
- шифр Плейфера;
- шифрование с ключом;
- шифр Вернама;
- шифр «Люцифер»;
Многие криптосистемы, как простые, так и сложные основываются на принципах подставки, перестановки и гаммировании. Прежде чем рассматривать простейшие алгоритмы шифрования опишем в чем суть подстановок, перестановок и гаммирования, так как эти принципы являются базовыми.
Перестановки.
Перестановкой s набора целых чисел (0,1,...,N-1) называется его переупорядочение. Для того чтобы показать, что целое i перемещено из позиции i в позицию s(i), где 0 £ (i) < n, будем использовать запись
s=(s(0), s(1),..., s(N-1)).
Число перестановок из (0,1,...,N-1) равно n!=1*2*...*(N-1)*N. Введем обозначение s для взаимно-однозначного отображения (гомоморфизма) набора S={s0,s1, ...,sN-1}, состоящего из n элементов, на себя.
s: S ® S
s: si ® ss(i), 0 £ i < n
Будем говорить, что в этом смысле s является перестановкой элементов S. И, наоборот, автоморфизм S соответствует перестановке целых чисел (0,1,2,.., n-1).
Криптографическим преобразованием T для алфавита Zm называется последовательность автоморфизмов: T={T(n):1£n<¥}
T(n): Zm,n®Zm,n, 1£n<¥
Каждое T(n) является, таким образом, перестановкой n-грамм из Zm,n.
Поскольку T(i) и T(j) могут быть определены независимо при i¹j, число криптографических преобразований исходного текста размерности n равно (mn)! (Здесь и далее m - объем используемого алфавита.). Оно возрастает непропорционально при увеличении m и n: так, при m=33 и n=2 число различных криптографических преобразований равно 1089!. Отсюда следует, что потенциально существует большое число отображений исходного текста в шифрованный.
Практическая реализация криптографических систем требует, чтобы преобразования {Tk: kÎK} были определены алгоритмами, зависящими от относительно небольшого числа параметров (ключей).
Системы подстановок.
Определение Подстановкой p на алфавите Zm называется автоморфизм Zm, при котором буквы исходного текста t замещены буквами шифрованного текста p(t):
Zm à Zm; p: t à p(t).
Набор всех подстановок называется симметрической группой Zm è будет в дальнейшем обозначаться как SYM(Zm).
Утверждение SYM(Zm) c операцией произведения является группой, т.е. операцией, обладающей следующими свойствами:
Замкнутость: произведение подстановок p1p2 является подстановкой:
p: tàp1(p2(t)).
Ассоциативность: результат произведения p1p2p3 не зависит от порядка расстановки скобок:
(p1p2)p3=p1(p2p3)
Существование нейтрального элемента: постановка i, определяемая как i(t)=t, 0£t<m, является нейтральным элементом SYM(Zm) по операции умножения: ip=pi для "pÎSYM(Zm).
Существование обратного: для любой подстановки p существует единственная обратная подстановка p-1, удовлетворяющая условию
pp‑1=p‑1p=i.
Число возможных подстановок в симметрической группе Zm называется порядком SYM(Zm) и равно m! .
Определение. Ключом подстановки k для Zm называется последовательность элементов симметрической группы Zm:
k=(p0,p1,...,pn-1,...), pnÎSYM(Zm), 0£n<¥
Подстановка, определяемая ключом k, является криптографическим преобразованием Tk, при помощи которого осуществляется преобразование n-граммы исходного текста (x0 ,x1 ,..,xn-1) в n-грамму шифрованного текста (y0 ,y1 ,...,yn-1):
yi=p(xi), 0£i<n
где n – произвольное (n=1,2,..). Tk называется моноалфавитной подстановкой, если p неизменно при любом i, i=0,1,..., в противном случае Tk называется многоалфавитной подстановкой.
Примечание. К наиболее существенным особенностям подстановки Tk относятся следующие:
1. Исходный текст шифруется посимвольно. Шифрования n-граммы (x0 ,x1 ,..,xn-1) и ее префикса (x0 ,x1 ,..,xs-1) связаны соотношениями
Tk(x0 ,x1 ,..,xn-1)=(y0 ,y1 ,...,yn-1)
Tk(x0 ,x1 ,..,xs-1)=(y0 ,y1 ,...,ys-1)
2. Буква шифрованного текста yi является функцией только i-й компоненты ключа pi и i-й буквы исходного текста xi.
В потоковых шифрах, т. е. при шифровании потока данных, каждый бит исходной информации шифруется независимо от других с помощью гаммирования.
Гаммирование - наложение на открытые данные гаммы шифра (случайной или псевдослучайной последовательности единиц и нулей) по определенному правилу. Обычно используется "исключающее ИЛИ", называемое также сложением по модулю 2 и реализуемое в ассемблерных программах командой XOR. Для расшифровывания та же гамма накладывается на зашифрованные данные.
При однократном использовании случайной гаммы одинакового размера с зашифровываемыми данными взлом кода невозможен (так называемые криптосистемы с одноразовым или бесконечным ключом). В данном случае "бесконечный" означает, что гамма не повторяется.
В некоторых потоковых шифрах ключ короче сообщения. Так, в системе Вернама для телеграфа используется бумажное кольцо, содержащее гамму. Конечно, стойкость такого шифра не идеальна.
Понятно, что обмен ключами размером с шифруемую информацию не всегда уместен. Поэтому чаще используют гамму, получаемую с помощью генератора псевдослучайных чисел (ПСЧ). В этом случае ключ - порождающее число (начальное значение, вектор инициализации, initializing value, IV) для запуска генератора ПСЧ. Каждый генератор ПСЧ имеет период, после которого генерируемая последовательность повторяется. Очевидно, что период псевдослучайной гаммы должен превышать длину шифруемой информации.
Генератор ПСЧ считается корректным, если наблюдение фрагментов его выхода не позволяет восстановить пропущенные части или всю последовательность при известном алгоритме, но неизвестном начальном значении.
При использовании генератора ПСЧ возможно несколько вариантов:
1. Побитовое шифрование потока данных. Цифровой ключ используется в качестве начального значения генератора ПСЧ, а выходной поток битов суммируется по модулю 2 с исходной информацией. В таких системах отсутствует свойство распространения ошибок.
2. Побитовое шифрование потока данных с обратной связью (ОС) по шифртексту. Такая система аналогична предыдущей, за исключением того, что шифртекст возвращается в качестве параметра в генератор ПСЧ. Характерно свойство распространения ошибок. Область распространения ошибки зависит от структуры генератора ПСЧ.
3. Побитовое шифрование потока данных с ОС по исходному тексту. Базой генератора ПСЧ является исходная информация. Характерно свойство неограниченного распространения ошибки.
4. Побитовое шифрование потока данных с ОС по шифртексту и по исходному тексту.
Чтобы получить линейные последовательности элементов гаммы, длина которых превышает размер шифруемых данных, используются датчики ПСЧ. На основе теории групп было разработано несколько типов таких датчиков.
Конгруэнтные датчики
В настоящее время наиболее доступными и эффективными являются конгруэнтные генераторы ПСП. Для этого класса генераторов можно сделать математически строгое заключение о том, какими свойствами обладают выходные сигналы этих генераторов с точки зрения периодичности и случайности.
Одним из хороших конгруэнтных генераторов является линейный конгруэнтный датчик ПСЧ. Он вырабатывает последовательности псевдослучайных чисел T(i), описываемые соотношением
T(i+1) = (A*T(i)+C) mod m,
где А и С - константы, Т(0) - исходная величина, выбранная в качестве порождающего числа. Очевидно, что эти три величины и образуют ключ.
Такой датчик ПСЧ генерирует псевдослучайные числа с определенным периодом повторения, зависящим от выбранных значений А и С. Значение m обычно устанавливается равным 2n , где n - длина машинного слова в битах. Датчик имеет максимальный период М до того, как генерируемая последовательность начнет повторяться. По причине, отмеченной ранее, необходимо выбирать числа А и С такие, чтобы период М был максимальным. Как показано Д. Кнутом, линейный конгруэнтный датчик ПСЧ имеет максимальную длину М тогда и только тогда, когда С - нечетное, и А mod 4 = 1.
Для шифрования данных с помощью датчика ПСЧ может быть выбран ключ любого размера. Например, пусть ключ состоит из набора чисел x(j) размерностью b, где j=1, 2, ..., n. Тогда создаваемую гамму шифра G можно представить как объединение непересекающихся множеств H(j).
Шифрование с помощью датчика ПСЧ является довольно распространенным криптографическим методом. Во многом качество шифра, построенного на основе датчика ПСЧ, определяется не только и не столько характеристиками датчика, сколько алгоритмом получения гаммы. Один из фундаментальных принципов криптологической практики гласит, даже сложные шифры могут быть очень чувствительны к простым воздействиям.
Рассмотрим базовые алгоритмы подробнее.
Шифр Полибия.
Самый, пожалуй, древний из всех известных, хотя и не такой распространенный, как шифр Цезаря. Полибий, греческий историк, умер за тридцать лет до появления Цезаря. Суть его метода в том, что составляется прямоугольник (Доска Полибия), например такой, как представлен на рисунке 1.1.
| А | Б | В | Г | Д | Е | |
| А | А | Б | В | Г | Д | Е |
| Б | Ж | З | И | Й | К | Л |
| В | М | Н | О | П | Р | С |
| Г | Т | У | Ф | Х | Ц | Ч |
| Д | Ш | Щ | Ъ | Ы | Ь | Э |
| Е | Ю | Я | . | , | - |
Рисунок 1.1 – Доска Полибия
Каждая буква может быть представлена парой букв, указывающих строку и столбец, в которых расположена данная буква. Так, представлением букв П, О будут ВГ, ВВ соответственно, а сообщение ШИФР ПОЛИБИЯ зашифруется как ДАБВГВВДЕЕВГВВБЕБВАББВЕБ. Хоть эта система и является более древней, но устойчивость к раскрытию у нее гораздо выше, несмотря на то, что наблюдается увеличение количества символов зашифрованного текста.
Шифр Цезаря.
Первый документально подтвержденный шифр: Гай Юлий Цезарь, желая защитить свои записи, заменял каждую букву следующей по алфавиту. Можно расширить этот алгоритм, поставив в соответствие каждой букве, какую либо другую букву, разумеется, без повторений. Можно даже заменять буквы совершенно сторонними символами, это не повлияет на криптостойкость.
Во времена Цезаря, когда мало кто умел читать, да и статистика не была особенно развитой, такой шифр было почти невозможно взломать. Но теперь этот способ шифрования используют только в качестве головоломок.
Объяснить это легко. Посчитав вхождение каждого символа в тексте, и зная статистические особенности языка, то есть частоту появления каждого символа в текстах, можно смело заменить часть символов на настоящие. Остальной текст можно получить исходя из избыточности текстов на естественных языках. Очевидно также, что шифр Цезаря можно использовать только для текстов.
Это один из самых старых шифров, имеющий ряд серьезных недостатков. Огромное семейство подстановок Цезаря названо по имени римского императора Гая Юлия Цезаря, который поручал Марку Туллию Цицерону составлять послания с использованием 50-буквенного греческого алфавита со сдвигом в 3 знака и дальнейшей подстановкой. Информация об этом дошла к нам от Светония. Попробуем воспроизвести этот метод шифрования для русского алфавита. Для этого создадим таблицу соответствия (рис. 1.2):
Рисунок 1.2 – Пример таблицы соответствия букв русского алфавита
Шифр Ришелье.
Совершенно “естественно” выглядит криптотекст, полученный с помощью криптосистемы Ришелье. Соответственно, защищенность этого алгоритма гораздо выше предыдущих. В основе лежит “замешивание” по определенным законам исходного текста в “мусоре”, или посторонних символах. Зашифрованный текст получается гораздо длиннее исходного, причем эта разница и определяет реальную криптостойкость системы. Суть метода Ришелье в следующем. Создается подобная решетка с прорезями вместо крестов (рис. 1.3):
| Х | Х | Х | Х | ||||||
| Х | Х | Х | Х | ||||||
| Х | |||||||||
| Х | Х | Х | Х | Х | |||||
| Х | Х | ||||||||
| Х | Х | Х | Х | Х |
Рисунок 1.3 – Пример решетки Ришелье
Далее в прорезях отверстий пишется текст, решетка снимается и все оставшееся пространство заполняется “мусором”, затем для усложнения расшифровки криптотекст можно выписать в ряд. Для длинных сообщений этот метод применяется несколько раз. Кстати говоря, выходной криптотекст можно оформить с помощью “мусора” и в виде смыслового послания. Выполнить обратное преобразование в исходный текст можно, зная размер блока и имея аналогичную решетку.
Перестановочные шифры.
Этот шифр тоже является одним из первых, он предполагает разбиение текста на блоки, а затем перемешивание символов внутри блока. Это можно сделать разными методами. В первых вариантах этого шифра использовалась таблица, которую заполняли по строкам исходными данными, а зашифрованные данные читали по столбцам.
Криптостойкость этого шифра также оставляет желать лучшего. Дело в том, что филологи уже давно установили, что для прочтения текста не важен порядок букв в слове, достаточно чтобы на месте были первая и последняя буквы слова. Конечно, размер блока не может совпадать с размерами всех слов текста, то есть перемешивание будет более серьезным, но научится читать такой текст не очень сложно.
Рассмотрим этот метод на несложном алгоритме простой столбцевой перестановки. Предварительно условимся, что число столбцов равно пяти. Допустим, имеется текст, который требуется зашифровать: “ПРОСТЫЕ ПЕРЕСТАНОВКИ ВНОСЯТ СУМЯТИЦУ”. Запишем этот текст слева направо, сверху вниз, заполняя последовательно пять столбцов (рис 1.4):
| 1 | 2 | 3 | 4 | 5 |
| П | Р | О | С | Т |
| Ы | Е | П | Е | |
| Р | Е | С | Т | А |
| Н | О | В | К | И |
| В | Н | О | С | |
| Я | Т | С | У | |
| М | Я | Т | И | Ц |
| У | ||||
Рисунок 1.4 – Пример простой столбцевой перестановки
Теперь зададимся ключом, например 35142, и выпишем в ряд столбцы, начиная с третьего, в соответствии с ключом: “О СВН Т ТЕАИСУЦ ПЫРН ЯМУСПТКОСИ РЕЕОВТЯ”. Получилось довольно неплохо. Для расшифровки требуется количество символов зашифрованного текста разделить на 5 и сформировать столбцы в соответствии с ключом.
В итоге получится исходная таблица, из которой можно прочитать текст построчно. Криптостойкость увеличится, если к полученному зашифрованному тексту применить повторное шифрование с другим размером таблицы и ключом или с перестановками не столбцов, а рядов. Перестановочные шифры очень хорошо сочетать с другими, таким образом повышая криптостойкость.
Шифр Виженера.
Наиболее известной и по праву одной из старейших многоалфавитных (одному шифруемому символу соответствует более одного символа) криптосистем является система известного французского криптографа графа Блейза Виженера (1523-1596).
Для преобразования строится алфавитный квадрат с построчным сдвигом символов в каждом последующем ряду (рисунок 1.5)
Рисунок 1.5 – Квадрат Виженера
Далее выбирается ключ. Затем пишется шифруемая фраза, а под ней циклически записывается ключ. Преобразование производится так: шифруемому символу соответствует символ, находящийся на пересечении буквы ключа (столбец) и буквы исходного текста (строка).
Одним и тем же буквам исходного текста соответствуют не всегда одинаковые символы, то есть символы могут принимать различные значения, что является несомненным плюсом в плане криптостойкости зашифрованного текста.
Далее выбирается ключ, например “ГРАФДРАКУЛА”. Затем пишется шифруемая фраза, а под ней циклически записывается ключ. Для примера возьмем фразу “ОТРЯД ЖДЕТ УКАЗАНИЙ” и исключим из нее пробелы:
“ОТРЯДЖДЕТУКАЗАНИЙ” – исходный текст, “ГРАФДРАКУЛАГРАФДР” – циклический ключ. Преобразование производится так: шифруемому символу соответствует символ, находящийся на пересечении буквы ключа (столбец) и буквы исходного текста (строка).
Получим: “СВРУИЦДПЕЮКГЧАБМЩ”. Как видно, одним и тем же буквам исходного текста соответствуют не всегда одинаковые символы, то есть символы могут принимать различные значения, что является несомненным плюсом в плане криптостойкости зашифрованного текста.
Квадрат может быть каким угодно, главное, чтобы он был легко воспроизводимым и левый столбец, так же как и верхний ряд, соответствовали всему алфавиту. В качестве альтернативного варианта это может быть известный квадрат Френсиса Бьюфорта, где строки – зеркальное отражение строк квадрата Виженера. Для усложнения строки могут быть переставлены местами в определенном порядке и т. д. Усложненной разновидностью этого метода является метод шифрования с автоключом, предложенный математиком Дж. Кардано (XVI в.). Суть его в том, что, кроме циклического ключа, есть еще один, записываемый однократно перед циклическим ключом – первичный ключ. Этот нехитрый прием придает дополнительную стойкость алгоритму.
Шифр Плейфейра.
Назван так в честь своего разработчика. Алгоритм заключается в следующем: сначала составляется равносторонний алфавитный квадрат. Для русского алфавита подойдет квадрат 5х6. Задается ключевая фраза без повторов букв, например “БАРОН ЛИС”. Фраза вписывается в квадрат без пробелов, далее последовательно вписываются недостающие буквы алфавита в правильной последовательности. Одну букву придется исключить для выполнения условия равносторонности. Пусть это будет Ъ. Примем допущение, что Ъ=Ь. Итак, получился квадрат, который легко восстановить по памяти:
Теперь условия для преобразования:
1) Текст должен иметь четное количество букв и делиться на биграммы (сочетания по две буквы), недостающую часть текста дополняем самостоятельно одним (любым) символом. Например, текст “ОСЕНЬ” преобразуется в “ОСЕНЬА”.
2) Биграмма не должна содержать одинаковых букв – “СОСНА” – “СО СН АБ”.
| Б | А | Р | О | Н |
| Л | И | С | В | Г |
| Д | Е | Ж | З | К |
| М | П | Т | У | Ф |
| Х | Ц | Ч | Ш | Щ |
| Ь | Ы | Э | Ю | Я |
Рисунок 1.6 – Пример алфавитного квадрата для шифрования методом Плейфера
Правила преобразования:
Если биграмма не попадает в одну строку или столбец, то мы смотрим на буквы в углах прямоугольника, образованного рассматриваемыми буквами. Например: “ДИ” = “ЛЕ”, “ЬУ” = “МЮ” и т. д.
Если биграмма попадает в одну строку (столбец), мы циклично смещаемся на одну букву вправо (вниз). Например, “ЛС”=“ИВ”, “ТЭ”=“ЧР”.
Итак, мы готовы преобразовать текст. Приступим к шифрованию:
“СОВЕЩАНИЕ СОСТОИТСЯ В ПЯТНИЦУ” – первоначально преобразуется в биграммы: “СО ВЕ ЩА НИ ЕС ОС ТО ИТ СЯ ВП ЯТ НИ ЦУ”. Выполнив преобразование по вышеизложенным правилам, получим биграммы: “РВ ЗИ НЦ ГА ИЖ ВР РУ ПС ЭГ УИ ФЭ ГА ПШ”.
Обратите внимание на то, что одинаковые буквы на входе дали разные буквы на выходе криптосистемы, а одинаковые буквы на выходе совсем не соответствуют одинаковым на входе. Таким образом, криптотекст “РВЗИНЦГАИЖВРРУПСЭГУИ” выглядит гораздо более “симпатично”, чем после прямой замены моноалфавитной криптосистемы.
Правила преобразования могут значительно варьироваться. Алфавит может быть упрощен до логического минимума с целью сокращения квадрата. Например, можно переводить текст в транслитерацию и писать латинскими буквами, тогда квадрат будет размером 5х5.
Шифрование с ключом.
Этот метод относится к современному периоду.
Текст представляется в двоичном формате, создается двоичный код некоторого размера (ключ), двоичный текст разбивается на блоки того же размера и каждый блок суммируется по модулю два с ключом. Обратное преобразование выполняется тем же методом.
Фактически, это «современный шифр Цезаря», просто подстановка выполняется не посимвольно, а словами. Правда, понятие слова здесь несколько иное – это блок заданной длины.
Криптостойкость этого метода намного выше, чем у предыдущих шифров. Без использования специальных методов криптоанализа его будет очень сложно взломать. Но в настоящее время этот метод используют только для не очень важных документов, так как криптоанализ, в совокупности с современными вычислительными средствами, позволяет не только прочесть текст сообщения, но и во многих случаях получить ключ, что губительно для системы безопасности.
Система Вернама.
В 1949 году, Шеннон сформулировал и доказал свою «пессимистическую теорему»: шифр является абсолютно криптостойким тогда и только тогда, когда энтропия ключа больше либо равна энтропии исходного текста. Из теоремы следует, что длина ключа должна быть соразмерна с длиной текста. Если быть более точным, длина ключа должна равняться длине текста.
На основе этой теоремы построена система Вернама. Каждый бит ключа этой системы равновероятно равен 0 либо 1. Длина ключа равна длине текста. Ключ используется только один раз. Доказано, что этот шифр абсолютно не вскрываем. Не будем этого доказывать, но обоснуем.
Для вскрытия шифрованного сообщения необходимо перебрать все возможные комбинации ключей (это единственный способ, так как ключ используется лишь единожды), и среди полученных значений текста выбрать исходный, пусть это будет текст на русском языке. Допустим, что злоумышленник может это сделать мгновенно, то есть опустим временную сложность такой задачи. Для текста любой длины, будет много бессмысленных результатов и их можно отбросить, но злоумышленник получит все возможные тексты заданной длины, в том числе наш текст. Но ничто и никогда не укажет на то, какой из текстов является исходным.
Рассмотрим это на примере четырех буквенных имен. Пусть зашифровано имя «Даша», а ключ «АБВГ». Если используется кодировка ASCII, то зашифрованный текст выглядит следующим образом: ♦!j#. Как говорилось ранее, единственный способ дешифровать текст, полный перебор всех возможных ключей. Но очевидно, что существует такой ключ, суммирование с которым зашифрованного текста даст в результате «Маша», или даже «Миша». Но действительно, невозможно ответить на вопрос, какое из имен является исходным.
Возможно, что аналитик знает часть текста, например, он знает что это договор на продажу недвижимости, но не знает цену. В результате перебора, если на это хватит времени, он получит все возможные цены «заданной длины». То есть если цена трехзначная, аналитиком будет получена девятьсот одна различная цена. Таким образом, взлом системы Вернама не приведет к получению новой информации и является абсолютно невскрываемым.
Недостаток этой системы – длина ключа. Сам Вернам предлагал пересылать ключ курьером. При этом если курьер не довез ключ, можно сгенерировать новый ключ и снова его отправить. Однако такой механизм чрезвычайно неудобен, поэтому эта система не используется в настоящее время.
Этот шифр при его идеальности лишен помехоустойчивости, потому как изменение одного бита, практически невозможно отследить.
Шифры, основанные на системе Вернама.
Если мы не можем использовать очень длинный ключ, следует использовать короткий, удлиняя его по некоторому правилу. Было предпринято много попыток создать шифр, как можно более приближенный к системе Вернама.
Первой попыткой было использование ключа в качестве параметров генератора псевдослучайных последовательностей. На деле все системы сводились именно к этому. Но в некоторых случаях ключ получали за счет его преобразований, например, с помощью нелинейной функции.
Рисунок 1.7 - Генерация ключа, для имитации системы Вернама
Наиболее удачной была схема, в которой ключ подавался на вход блоку преобразований (рисунок 1.7) одновременно с выходом двоичного счетчика, подключенного к таймеру. Для передачи сообщения правда требовалась большая синхронизация, нежели для системы Вернама, но вполне приемлемая.
Шифр «Люцифера».
Этот шифр изначально разрабатывался для аппаратной реализации. Именно при его создании одновременно использовались новейшие достижения в математике и теории кодирования и опыт веков.
«Люцифер» был создан фирмой IBM и долго использовался для внутренних нужд, так как аппаратная реализация системы шифрования имеет некоторые недостатки.
Авторы шифра предложили совместить два основных подхода к шифрованию: подстановки и перестановки.
Сначала, текст разбивается на блоки по n бит. Затем они поступают на вход мультиплексора, который раскладывает блок по модулю 2^n. Биты перемешиваются, и обрабатываются демультиплексором, который собирает биты в блок длиной n бит.
Рисунок 1.8 - Подстановки «Люцифера»
Преимущество таких постановок (Рисунок 1.8) заключается в нелинейности преобразований. По большому счету, можно любой входной поток превратить в любой выходной, но, разумеется, это производится на этапе разработки.
Выполнив подстановку, следует выполнить перестановки. Это делается соответствующей схемой, в которой просто перемешиваются биты (рисунок 1.9).
Рисунок 1.9 - Подстановки «Люцифера»
Узнать коммутацию такого блока довольно легко, достаточно подавать ровно одну единицу на вход, и получать ровно одну единицу на выходе. Однако, совместив оба подхода, и создавая как бы несколько итераций, можно очень сильно запутать аналитика (рисунок 1.10).
Легко увидеть, что если на вход подать одну единицу, на выходе получается больше единиц, чем нулей. Криптоаналитик, получивший текст, зашифрованный «Люцифером» будет поставлен в тупик.
Рисунок 1.10 - «Люцифер»
Для этого шифра очень важно правильно подобрать параметры преобразований обоих типов. Дело в том, что при неудачном выборе параметров преобразований, они могут свестись к простой перестановке, которую легко раскрыть. Поэтому в аппаратную реализацию шифра встроили «сильные параметры.
Однако, аппаратная реализация шифра не позволяет его широкого применения, так как блок подстановок выполняет преобразование, схожее с суммированием с ключом, а суммирование с одним и тем же ключом ставит шифр под удар. С одной стороны, все, кто имеет доступ к системе, знают ключ, поэтому может произойти утечка, с другой стороны, аналитик, получивший достаточно много шифровок сможет таки дешифровать сообщение.
Было несколько попыток избавиться от этого недостатка, но наиболее удачная из них заключалась в том, чтобы каждый блок подстановок заменить двумя, при этом для шифрования, пользователь указывает первый или второй вид подстановок выполнять, создавая двоичный ключ (рисунок 1.11).
Такая реализация шифра была гораздо более криптостойкой и использовалась некоторое время.
Рисунок 1.11 - «Люцифер» с ключом
Действительно криптостойкий шифр на основе «Люцифера» был предложен в 1973 году Хорстом Фейстелем. Этот алгоритм на самом деле является общим случаем «Люцифера».
Рисунок 1.12 - Классическая сеть Фейстеля
Классическая (или простая) сеть Фейстеля (рисунок 1.12) разбивает исходный текст на блок длиной 2n бит, каждый блок разбивается на два потока L (левый) и R(правый). Далее выполняется преобразование по формуле:
где Ki – ключ, Fi – функция преобразования.
Каждое такое действие называется раундом. Обычно используется 8-16 раундов. При этом, ключ в каждом раунде может быть как частью общего ключа, так и ее модификацией по некоторому правилу: следует отметить, что это в значительной мере влияет на криптостойкость. Также важным является правило, по которому текст разбивается на потоки.
Основное достоинство алгоритма заключается в том, что функция f не обязана быть обратимой, более того, для повышения криптостойкости обычно используют нелинейные именно необратимые функции.
Ключ, с которым суммируется текст не повторяется из блока в блок, а изменяется в зависимости от самого текста, это значительно увеличивает его энтропию, и, следовательно, увеличивает криптостойкость метода.
Процедура расшифровки очевидна, следует применить те же формулы, но в обратном порядке. Некоторые исследователи нашли способ применять один и тот же алгоритм и для шифровки, и для расшифровки, для этого необходимо удвоить число раундов, и во второй половине расположить функции и ключи в обратном порядке. Но как показали эксперименты, криптотойкость при таком подходе значительно ниже.
В последствии были построены сети Фейстеля с большим числом потоков. Это позволило также усложнить подход к функциям преобразования. На рисунке 1.13 представлены примеры таких сетей.
Рисунок 1.13 - Примеры сетей Фейстеля с большим числов потоков
Также существует несколько способов перемешивания: без него, симметричный, асимметричный, - представленные на рисунке 1.14.
Рисунок 1.14 - Способы перемешивания потоков
Сравнивая сети Фейстеля с системой Вернама, становится очевидной высокая помехоустойчивость сетей Фейстеля: если система Вернама при искажении одного бита в зашифрованном тексте, искажала один бит в расшифрованном, то в сети Фейстеля этот бит повлияет на довольно большую часть текста и станет заметным, что позволит выявить случайные или преднамеренные искажения, и переслать шифрованный текст еще раз по другому каналу связи.
В последнее время появились упоминания так называемых Микро Декоррелированных Сетей Фейстеля. Суммируя текст с ключом, криптограф автоматически помещает информацию о ключе в зашифрованный текст, а получение ключа есть конечная цель любого криптоаналитика. Дэвид Вагнер, в своем труде «Атака бумерангом» описал способ уменьшить количество информации в тексте, зашифрованным сетью Фейстеля. Он предложил рассмотреть функции Fi как функции от текста, так, как если бы ключ был частью функции.
Рассмотрим для примера функцию f(x)=ax+b по одной паре х и f(x) нельзя ничего сказать об а и b. Чем больше пар необходимо, тем лучше такая функция. Но в сетях Фейстеля, криптоаналитик в худшем случае знает исходный текст и зашифрованный тексты, то есть исходные данные и результат последней функции, что делает задачу криптоанализа в случае микро декоррелирующих сетей почти невыполнимой.
Существуют также динамические сети Фейстеля, причем существует несколько их вариантов.
Первый вариант, более простой, предполагает изменение величины блока от раунда к раунду. С одной стороны, это значительно увеличивает время шифрования, так как уже нельзя выбрав блок, сразу полностью произвести все преобразования. С другой стороны, это в значительной мере изменяет статистические характеристики текста. Это легко объяснить тем, что происходит более глубокое перемешивание битов текста. Подстановки в этом случае также несколько отличаются: так как на разных раундах производится подстановка слов различной длины, символы, попадающие в разные блоки, в зависимости от раунда, изменяются по-другому.
Второй вид динамических сетей фейстеля несколько сложнее. Он использует множества отображающих функций – определенное количество функций, по числу блоков, каждая из которых применяется в своем блоке. При этом множество функций изменяется от раунда к раунду. Это изменение также может быть простым перемешиванием, но в идеале, функции не должны повторяться вообще.
Рассматривают также и объединение двух видов динамических сетей Фейстеля. Когда каждый блок суммируется с результатом своей собственной функции, и количество блоков изменяется в зависимости от раунда.
Задание к лабораторной работе
В соответствии с вариантом задания написать программу, реализующую один из базовых алгоритмов шифрования, при этом произвести некоторую модификацию выбранного алгоритма. Программа должна выполнять чтение файла, просмотр, его шифрование, расшифровывание, просмотр зашифрованного расшифрованного документа.
Отчет по лабораторной работе должен включать в себя: Краткое словесное описание базового алгоритма с его частичной модификацией, пример работы алгоритма, листинг программы, результаты работы программы.
Варианты заданий:
№ по журналу Базовый алгоритм
- 1-3 Шифр Полибия;
- 4-6 Шифр Цезаря;
- 7-9 Шифр Ришелье;
- 10-12 Перестановочный шифр;
- 13-15 Шифр Виженера
- 16-18 Шифрование с ключем
- 19-21 Шифр Вернама
21 – 25 Шифр Плейфейра.
-
Контрольные вопросы к лабораторной работе:
1) Что такое криптоанализ?
2) Что такое криптоскойкость алгоритма?
3) В чем суть перестановочных шифров?
4) В чем суть подстановочных шифров?
5) Назначение гаммирования.
6) Какой из рассмотренных базовых алгоритмов является по Вашему мнению наиболее криптостойким? Объяснить, почему.
7) Как, по Вашему мнению, можно увеличить криптостойкость алгоритма с использованием перестановок?
Лабораторная работа №2
Тема: Симметричные криптосистемы.
Цель работы: Изучение принципов шифрования в симметричных криптосистемах. Изучение классов преобразований в симметричных криптосистемах.
Методические указания к выполнению лабораторной работы
Криптографическая система это семейство преобразований шифра и совокупность ключей (т.е. алгоритм + ключи). Само по себе описание алгоритма не является криптосистемой. Только дополненное схемами распределения и управления ключами оно становится системой. Примеры алгоритмов – описания DES, ГОСТ28147-89. Дополненные алгоритмами выработки ключей, они превращаются в криптосистемы. Современные криптосистемы классифицируют следующим образом (рис. 2.1):
Рисунок 2.1 – Классификация криптосистем
Криптосистемы могут обеспечивать не только секретность передаваемых сообщений, но и их аутентичность (подлинность), а также подтверждение подлинности пользователя.
Симметричные криптосистемы (с секретным ключом - secret key systems) данные криптосистемы построены на основе сохранения в тайне ключа шифрования. Процессы зашифрования и расшифрования используют один и тот же ключ. Секретность ключа является постулатом. Основная проблема при применении симметричных криптосистем для связи заключается в сложности передачи обоим сторонам секретного ключа. Симметричные криптосистемы принято подразделять на блочные и поточные.
Блочные криптосистемы разбивают текст сообщения (файла, документа и т.д.) на отдельные блоки и затем осуществляют преобразование этих блоков с использованием ключа.
Поточные криптосистемы работают иначе. На основе ключа системы вырабатывается некая последовательность– так называемая выходная гамма, которая затем накладывается на текст сообщения. Таким образом, преобразование текста осуществляется как бы потоком по мере выработки гаммы.
Устройство блочных шифров.
Само преобразование шифра должно использовать следующие принципы (по К. Шеннону):
Рассеивание (diffusion) - т.е. изменение любого знака открытого текста или ключа влияет на большое число знаков шифротекста, что скрывает статистические свойства открытого текста;
Перемешивание (confusion) - использование преобразований, затрудняющих получение статистических зависимостей между шифротектстом и открытым текстом.
Практически все современные блочные шифры являются композиционными - т.е. состоят из композиции простых преобразований или F=F1oF2oF3oF4o..oFn, где F - преобразование шифра, Fi - простое преобразование, называемое также i-ым циклом шифрования. Само по себе преобразование может и не обеспечивать нужных свойств, но их цепочка позволяет получить необходимый результат. Например, стандарт DES состоит из 16 циклов. Если же используется одно и то же преобразование, т.е. Fi постоянно для i, то такой композиционный шифр называют итерационным шифром.
Наибольшую популярность имеют шифры, устроенные по принципу шифра Фейстеля (Файстеля - Feistel), в которых:
1. Входной блок для каждого преобразования разбивается на две половины: p=(l,r), где l - левая, a r - правая;
2. Используется преобразование вида Fi (l,r)=(r,l Ä fi(r)), где fi– зависящая от ключа Ki функция, а Ä - операция XOR или некая другая.
Функция fi называется цикловой функцией, а ключ Ki, используемый для получения функции fi называется цикловым ключом. Как можно заметить, с цикловой функцией складывается только левая половина, а правая остается неизменной. Затем обе половины меняются местами. Это преобразование прокручивается несколько раз (несколько циклов) и выходом шифра является получившаяся в конце пара (l,r) Графически все выглядит следующим образом (рис. 2.2):
Рисунок 2.2 – Пример одного цикла преобразований
В качестве функции fi выступает некая комбинация перестановок, подстановок, сдвигов, добавлений ключа и прочих преобразований. Так, при использовании подстановок информация проходит через специальные блоки, называемые S-блоками (S-боксами, S-boxes), в которых значение группы битов заменяется на другое значение. По такому принципу (с небольшими отличиями) построены многие алгоритмы: DES, ит.п. В других алгоритмах используются несколько иные принципы. Так, например, алгоритмы, построенные по SP-принципу (SP-сети) осуществляют преобразование, пропуская блок через последовательность подстановок (Substitutions) и перестановок (Permutations). Отсюда и название– SP-сети, т.е. сети "подстановок-перестановок". Примером такого алгоритма является очень перспективная разработка Rijndael. Саму идею построения криптографически стойкой системы путем последовательного применения относительно простых криптографических преобразований была высказана Шенноном (идея многократного шифрования).
Размеры блоков в каждом алгоритме свои. DES использует блоки по 64 бита (две половинки по 32 бита), LOKI97 - 128 бит.
Получение цикловых ключей.
Ключ имеет фиксированную длину. Однако при прокрутке хотя бы 8 циклов шифрования с размером блока, скажем, 128 бит даже при простом прибавлении посредством XOR потребуется 8*128=1024 бита ключа, поскольку нельзя добавлять в каждом цикле одно и то же значение ,так как это ослабляет шифр. Поэтому для получения последовательности ключевых бит придумывают специальный алгоритм выработки цикловых ключей (ключевое расписание - key schedule). В результате работы этого алгоритма из исходных бит ключа шифрования получается массив бит определенной длины, из которого по определенным правилам составляются цикловые ключи. Каждый шифр имеет свой алгоритм выработки цикловых ключей.
Режимы работы блочных шифров.
Чтобы использовать алгоритмы блочного шифрования для различных криптографических задач существует несколько режимов их работы. Наиболее часто встречающимися в практике являются следующие режимы:
электронная кодовая книга - ECB (Electronic Code Book);
сцепление блоков шифротекста - CBC (Cipher Block Chaining);
обратная связь по шифротектсту - CFB (Cipher Feed Back);
обратная связь по выходу - OFB (Output Feed Back).
Обозначим применение шифра к блоку открытого текста как Ek(M)=C, где k - ключ, M - блок открытого текста, а C - получающийся шифротекст.
Электронная Кодовая Книга (ECB)
Рисунок 2.3 - Схема электронной кодовой книги
Исходный текст разбивается на блоки, равные размеру блока шифра. Затем каждый блок шифруют независимо от других с использованием одного ключа шифрования (рис.2.3).
Непосредственно этот режим применяется для шифрования небольших объемов информации, размером не более одного блока или для шифрования ключей. Это связано с тем, что одинаковые блоки открытого текста преобразуются в одинаковые блоки шифротекста, что может дать взломщику (криптоаналитику) определенную информацию о содержании сообщения. К тому же, если он предполагает наличие определенных слов в сообщении (например, слово "Здравствуйте" в начале сообщения или "До свидания" в конце), то получается, что он обладает как фрагментом открытого текста, так и соответствующего шифротекста, что может сильно облегчить задачу нахождения ключа.
Основным достоинством этого режима является простота реализации.
Сцепление блоков шифротекста (CBC)
Один из наиболее часто применимых режимов шифрования для обработки больших количеств информации. Исходный текст разбивается на блоки, а затем обрабатывается по следующей схеме (рис.2):
1. Первый блок складывается побитно по модулю 2 (XOR) с неким значением IV – вектором инициализации (Init Vector), который выбирается независимо перед началом шифрования.
2. Полученное значение шифруется.
3. Полученный в результате блок шифротекста отправляется получателю и одновременно служит начальным вектором IV для следующего блока открытого текста.
Рисунок 2.4 - Схема сцепления блоков шифротекста
Расшифрование осуществляется в обратном порядке.
В виде формулы, преобразование в режиме CBC можно представить как Ci=Ek(Mi Å Ci-1), где i - номер соответствующего блока. Из-за использования такого сцепления блоков шифротекста с открытым текстом пропадают указанные выше недостатки режима ECB, поскольку каждый последующий блок зависит от всех предыдущих. Если во время передачи один из блоков шифротекста исказится (передастся с ошибкой), то получатель сможет корректно расшифровать предыдущие блоки сообщения. Проблемы возникнут только с этим "бракованным" и следующим блоками. Одним из важных свойств этого режима является "распространение ошибки"– изменение блока открытого текста меняет все последующие блоки шифротекста. Поскольку последний блок шифротекста зависит от всех блоков открытого текста, то его можно использовать для контроля целостности и аутентичности (проверки подлинности) сообщения. Его называют кодом аутентификации сообщения (MAC - Message Authentication Code). Он может защитить как от случайных, так и преднамеренных изменений в сообщениях.
Обратная связь по шифротексту (CFB)
Режим может использоваться для получения поточного шифра из блочного. Размер блока в данном режиме меньше либо равен размеру блока шифра.
Рисунок 2.5 - Схема обратной связи по шифротексту
Описание работы схемы:
1. IV представляет собой сдвиговый регистр. Вначале IV заполняется неким значением, которое называется синхропосылкой, не является секретным и передается перед сеансом связи получателю.
2. Значение IV шифруется.
3. Берутся первые k бит зашифрованного значения IV и складываются (XOR) с k битами открытого текста. Получается блок шифротекста из k бит.
4. Значение IV сдвигается на k битов влево, а вместо него становится значение ш.т.
5. Затем опять 2 пункт и т.д до конца цикла шифрования.
Расшифрование происходит аналогично.
Особенностью данного режима является распространение ошибки на весь последующий текст. Рекомендованные значения k: 1 <= k <= 8.
Применяется, как правило, для шифрования потоков информации типа оцифрованной речи, видео.
Обратная связь по выходу (OFB)
Данный режим примечателен тем, что позволяет получать поточный шифр в его классическом виде, в отличии от режима CFB, в котором присутствует связь с шифротекстом. Принцип работы схож с принципом работы режима CFB, но сдвиговый регистр IV заполняется не битами шифротекста, а битами, выходящими из-под усечения.
Рисунок 2.6 - Схема обратной связи по выходу
Расшифрование осуществляется аналогично. То есть, для любого блока длины k операция зашифрования выглядит следующим образом: Ci=Mi Å Gi, где Gi - результат зашифрования некоторого вектора, являющегося заполнением сдвигового регистра. Главное свойство шифра – единичные ошибки не распространяются, т.к. заполнение сдвигового регистра осуществляется независимо от шифротекста.
Область применения: потоки видео, аудио или данных, для которых необходимо обеспечить оперативную доставку. Широко используется у военных наряду с поточными шифрами.
Аутентификация сообщений с помощью блочных шифров.
Аутентификация (authentication – проверка подлинности чего (или кого-)-либо. Может быть аутентификация пользователя, сообщения и т.д. Необходимо отличать ее от следующего понятия:
Идентификация (identification)– некое описательное представление какого-то субъекта. Так, если кто-то заявляет, что он – Вася Иванов, то он идентифицирует себя как "Вася Иванов". Но проверить, так ли это на самом деле (провести аутентификацию) мы можем только при помощи его паспорта.
Итак, как же можно проверить подлинность сообщения с помощью блочного шифра?
Отправитель А хочет отправить некое сообщение (a1,..,at). Он зашифровывает на секретном ключе, который знает только он и получатель, в режиме CBC или CFB это сообщение, а затем, из получившегося шифротекста, берет последний блок bt из к бит (при этом к должно быть достаточно большим).
1. Отправитель А посылает сообщение (a1, .. , at , bt ) получателю в открытом виде или зашифровав его на другом ключе.
2. Получатель В, получив сообщение, (a1, .. , at , bt ), зашифровывает (a1,..,at ) в том же режиме, что и А (должна быть договоренность) на том же секретном ключе (который знает только он и А).
3. Сравнивая полученный результат с bt он удостоверяется, что сообщение отправил А, что оно не было подделано на узле связи (в случае передачи в открытом виде).
В данной схеме bt является кодом аутентификации сообщения (МАС). Для российского стандарта шифрования процесс получения кода аутентификации называется работой в режиме имитовставки.
Некоторые комментарии:
Режим шифрования должен быть обязательно с распространением ошибок (т.е. CBC или CFB). Необходимо использовать шифр с достаточной длиной блока, а то может появиться ситуация, когда из-за небольшого числа используемых бит для аутентификации возможно подменить исходное сообщение и при знании ключа получить тот же самый результат. Также очевидно, что схема опирается на то, что оба абонента имеют один и тот же секретный ключ, который получили заранее.
Задание к лабораторной работе:
1. Изучить алгоритм и разработать программу реализации алгоритма хеш-функции в соответствии с вариантом:
- алгоритм Электронная Кодовая Книга -
<номер по журналу > MOD 4 = 0;
- алгоритм Сцепление блоков шифротекста -
<номер по журналу > MOD 4 = 1;
- алгоритм Обратная связь по шифротексту -
<номер по журналу > MOD 4 = 2;
- алгоритм Обратная связь по выходу -
<номер по журналу > MOD 4 = 3
2. Проанализировать алгоритм с точки зрения его безопасности.
Контрольные вопросы к лабораторной работе:
1. В чем отличие принципов симметричного и асимметричного шифрования;
2. Каковы основные принципы построения блочных и поточных алгоритмов;
3. В чем принцип рассеивания и перемешивания;
4. Для чего используется вектор инициализации.
Лабораторная работа №3
Тема: Однонаправленные хеш-функции в криптографии.
Цель: Изучение алгоритмов построения и использования однонаправленных хеш-функций.
Методические указания к выполнению лабораторной работы
Согласно Шнайдеру Б. однонаправленная функция Н(М) применяется к сообщению произвольной длины М и возвращает значение фиксированной длины h , то есть
h = Н(М), где h имеет длину т.
Многие функции позволяют вычислять значение фиксированной длины по входным данным произвольной длины, но у рассматриваемых хэш-функций есть дополнительные свойства, делающие их однонаправленными:
Зная М, легко вычислить h .
Зная Н, трудно определить М, для которого H ( M )= h .
Зная М, трудно определить другое сообщение М’ , для которого Н(М) = Н(М').
То есть смысл однонаправленных хэш-функций и состоит в обеспечении для М уникального идентификатора ("отпечатка пальца"). Если Алиса подписала М с помощью алгоритма цифровой подписи на базе Н(М) , а Боб может создать М', другое сообщение, отличное от М, для которого Н(М) = Н(М'), то Боб сможет утверждать, что Алиса подписала М'.
В ряде приложений однонаправленности недостаточно, необходимо выполнение другого требования, называемого устойчивостью к коллизиям. Его можно сформулировать так: трудно найти два случайных сообщения М и М', для которых Н(М) = Н(М').
Проанализируем протокол, впервые описанный Гидеоном Ювалом, который показывает, как, если предыдущее требование не выполняется, Алиса может использовать вскрытие методом дня рождения для обмана Боба. Он основан не на поиске другого сообщения М, для которого Н(М) = Н(М'), а на поиске двух случайных сообщений, М и М', для которых Н(М) = Н(М') (метод «дней рождений» смотри в Шнайдере раздел7.4).
1. Алиса готовит две версии контракта: одну, выгодную для Боба, и другую, приводящую его к банкротству
2. Алиса вносит несколько незначительных изменений в каждый документ и вычисляет хэш-функции.
(Этими изменениями могут быть действия, подобные следующим : замена ПРОБЕЛА комбинацией ПР О-БЕЛ-ЗАБОЙ-ПРОБЕЛ, вставка одного-двух пробелов перед возвратом каретки, и т.д. Делая или не делая по одному изменению в каждой из 32 строк, Алиса может легко получить 2 32 различных документов.)
3. Алиса сравнивает хэш-значения для каждого изменения в каждом из двух документов, разыскивая пару, для которой эти значения совпадают. (Если выходом хэш-функции является всего лишь 64-разрядное значение, Алиса, как правило, сможет найти совпадающую пару сравнив 232 версий каждого документа.) Она
восстанавливает два документа, дающих одинаковое хэш-значение.
4. Алиса получает подписанную Бобом выгодную для него версию контракта, используя протокол, в котором он подписывает только хэш-значение.
5. Спустя некоторое время Алиса подменяет контракт, подписанный Бобом, другим, который он не подписывал. Теперь она может убедить арбитра в том, что Боб подписал другой контракт.
Это серьезная проблема. Одним из советов по ее избежанию является обязательное внесение мелких изменений в подписываемый документ.
При возможности успешного вскрытия этим методом, могут применяться и другие способы вскрытия. Например, противник может посылать системе автоматического контроля (может быть спутниковой) случайные строки сообщений со случайными строками подписей. На каком-то этапе подпись под одним из этих случайных сообщений окажется правильной. Враг не сможет узнать, к чему приведет эта команда, но, если его единственной целью является вмешательство в работу спутника, он своего добьется.
Дата: 2019-07-24, просмотров: 400.