Технические характеристики современных серверов
Симметричные мультипроцессорные системы компании Bull
Группа компаний, объединенных под общим названием Bull, является одним из крупнейших производителей информационных систем на мировом компьютерном рынке и имеет свои отделения в Европе и США. Большая часть акций компании принадлежит французскому правительству. В связи с происходившей в последнем пятилетии перестройкой структуры компьютерного рынка компания объявила о своей приверженности к направлению построения открытых систем. В настоящее время компания продолжает выпускать компьютеры класса мейнфрейм (серии DPS9000/900, DPS9000/800, DPS9000/500) и среднего класса (серии DPS7000 и DPS6000), работающие под управлением фирменной операционной системы GCOS8, UNIX-системы (серии DPX/20, Escala), а также широкий ряд персональных компьютеров компании Zenith Data Systems (ZDS), входящей в группу Bull.
Активность Bull в области открытых систем сосредоточена главным образом на построении UNIX-систем. В результате технологического соглашения с компанией IBM, в 1992 году Bull анонсировала ряд компьютеров DPX/20, базирующихся на архитектуре POWER, а позднее в 1993 году на архитектуре PowerPC и работающих под управлением операционной системы AIX (версия системы UNIX компании IBM). Версия ОС AIX 4.1, разработанная совместно специалистами IBM и Bull, поддерживает симметричную многопроцесоорную обработку.
Архитектура PowerScale, представляет собой первую реализацию симметричной мультипроцессорной архитектуры (SMP), разработанной Bull специально для процессоров
PowerPC. В начале она была реализована на процессоре PowerPC 601, но легко модернизируется для процессоров 604 и 620. Эта новая SMP-архитектура используется в семействе систем Escala.
Описание архитектуры PowerScale
В архитектуре PowerScale (рис. 4.1) основным средством оптимизации доступа к разделяемой основной памяти является использование достаточно сложной системной шины. В действительности эта "шина" представляет собой комбинацию шины адреса/управления, реализованной классическим способом, и набора магистралей данных, которые соединяются между собой посредством высокоскоростного матричного коммутатора. Эта система межсоединений получила название MPB_SysBus. Шина памяти используется только для пересылки простых адресных тегов, а неблокируемый матричный коммутатор - для обеспечения более интенсивного трафика данных. К матричному коммутатору могут быть подсоединены до 4 двухпроцессорных портов, порт ввода/вывода и подсистема памяти.
Главным преимуществом такого подхода является то, что он позволяет каждому процессору иметь прямой доступ к подсистеме памяти. Другим важным свойством реализации является использование расслоения памяти, что позволяет многим процессорам обращаться к памяти одновременно.
Ниже приведена схема, иллюстрирующая общую организацию доступа к памяти (рис. 4.2) Каждый процессорный модуль имеет свой собственный выделенный порт памяти для пересылки данных. При этом общая шина адреса и управления гарантирует, что на уровне системы все адреса являются когерентными.
Вопросы балансировки нагрузки
В процессе разработки системы был сделан выбор в направлении использования больших кэшей второго уровня (L2), дополняющих кэши первого уровня (L1), интегрированные в процессорах PowerPC. Это решение породило необходимость более глубокого рассмотрения работы системы в целом. Чтобы получить полное преимущество от использования пространственной локальности данных, присутствующих в кэшах L2, необходимо иметь возможность снова назначить ранее отложенный процесс на процессор, на котором он ранее выполнялся, даже если этот процессор не является следующим свободным процессором. Подобная "настройка" системы является основой для балансировки нагрузки и аналогична процессу планирования.
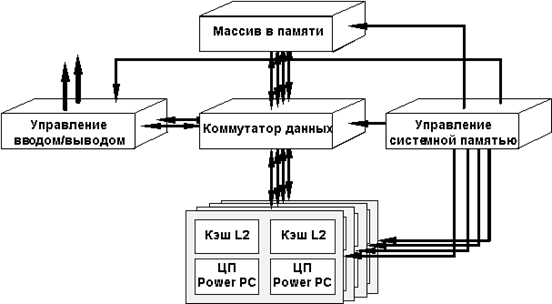
Рис. 4.1. Архитектура PowerScale
Очевидно, что всегда полезно выполнять процесс на одном и том же процессоре и иметь более высокий коэффициент попаданий в кэш, чем при выполнении процесса на следующем доступном процессоре. Используя алгоритмы, базирующиеся на средствах ядра системы, можно определить наиболее подходящее использование пула процессоров с учетом текущего коэффициента попаданий в кэш. Это позволяет оптимизировать уровень миграции процессов между процессорами и увеличивает общую пропускную способность системы.
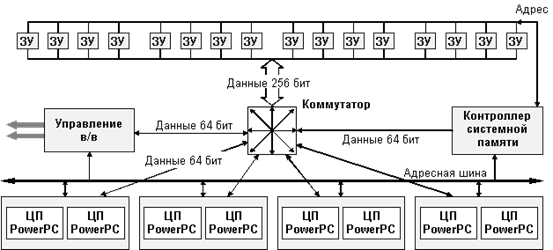
Рис. 4.2. Схема организации доступа к памяти
Модель памяти
Процессор PowerPC определяет слабо упорядоченную модель памяти, которая позволяет оптимизировать использование пропускной способности памяти системы. Это достигается за счет того, что аппаратуре разрешается переупорядочивать операции загрузки и записи так, что требующие длительного времени операции загрузки могут выполняться ранее определенных операций записи. Такой подход позволяет уменьшить действительную задержку операций загрузки. Архитектура PowerScale полностью поддерживает эту модель памяти как на уровне процессора за счет набора команд PowerPC, так и глобально путем реализации следующих ограничений:
· Обращения к глобальным переменным синхронизации выполняются строго последовательно.
· Никакое обращение к переменной синхронизации не выдается процессором до завершения выполнения всех обращений к глобальным данным.
· Никакие обращения к глобальным данным не выдаются процессором до завершения выполнения предыдущих обращений к переменной синхронизации.
Для обеспечения подобной модели упорядоченных обращений к памяти на уровне каждого процессора системы используются определенная аппаратная поддержка и явные команды синхронизации. Кроме того, на системном уровне соблюдение необходимых протоколов для обеспечения упорядочивания обращений между процессорами или между процессорами и подсистемой ввода/вывода возложено на программное обеспечение.
Подсистема памяти
С реализацией архитектуры глобальной памяти в мультипроцессорной системе обычно связан очень важный вопрос. Как объединить преимущества "логически" локальной для каждого процессора памяти, имеющей малую задержку доступа, с требованиями реализации разделяемой глобальной памяти?
Компания Bull разработала патентованную архитектуру, в которой массив памяти полностью расслоен до уровня длины строки системного кэша (32 байта). Такая организация обеспечивает минимум конфликтов между процессорами при работе подсистемы памяти и гарантирует минимальную задержку. Требование реализации глобальной памяти обеспечивается тем, что массив памяти для программных средств всегда представляется непрерывным.
Предложенная конструкция решает также проблему, часто возникающую в других системах, в которых использование методов расслоения для организации последовательного доступа к различным областям памяти возможно только, если платы памяти устанавливаются сбалансировано. Этот, кажущийся тривиальным, вопрос может приводить к излишним закупкам дополнительных ресурсов и связан исключительно с возможностями конструкции системы. PowerScale позволяет обойти эту проблему.
Архитектура PowerScale автоматически оптимизирует степень расслоения памяти в зависимости от того, какие платы памяти инсталлированы в системе. В зависимости от конкретной конфигурации она будет использовать низкую или высокую степень расслоения или их комбинацию. Все это полностью прозрачно для программного обеспечения и, что более важно, для пользователя.
Когерентность кэш-памяти
Известно, что требования, предъявляемые современными процессорами к полосе пропускания памяти, можно существенно сократить путем применения больших многоуровневых кэшей. Проблема когерентности памяти в мультипроцессорной системе возникает из-за того, что значение элемента данных, хранящееся в кэш-памяти разных процессоров, доступно этим процессорам только через их индивидуальные кэши. При этом определенные операции одного из процессоров могут влиять на достоверность данных, хранящихся в кэшах других процессоров. Поэтому в подобных системах жизненно необходим механизм обеспечения когерентного (согласованного) состояния кэшей. С этой целью в архитектуре PowerScale используется стратегия обратной записи, реализованная следующим образом.
Заключение
При разработке PowerScale Bull удалось создать архитектуру с достаточно высокими характеристиками производительности в расчете на удовлетворение нужд приложений пользователей сегодня и завтра. И обеспечивается это не только увеличением числа процессоров в системе, но и возможностью модернизации поколений процессоров PowerPC. Разработанная архитектура привлекательна как для разработчиков систем, так и пользователей, поскольку в ее основе лежит одна из главных процессорных архитектур в компьютерной промышленности - PowerPC.
Технические характеристики современных серверов
Дата: 2019-05-29, просмотров: 312.