Коммутационная матрица - основной и самый быстрый способ взаимодействия процессоров портов, именно он был реализован в первом промышленном коммутаторе локальных сетей. Однако, реализация матрицы возможна только для определенного числа портов, причем сложность схемы возрастает пропорционально квадрату количества портов коммутатора (рисунок 4.2).
Рис. 4.2. Коммутационная матрица
Более детальное представление одного из возможных вариантов реализации коммутационной матрицы для 8 портов дано на рисунке 4.3. Входные блоки процессоров портов на основании просмотра адресной таблицы коммутатора определяют по адресу назначения номер выходного порта. Эту информацию они добавляют к байтам исходного кадра в виде специального ярлыка - тэга (tag). Для данного примера тэг представляет просто 3-х разрядное двоичное число, соответствующее номеру выходного порта.
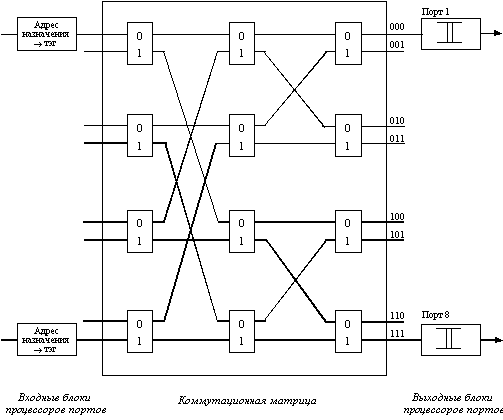
Рис. 4.3. Реализация коммутационной матрицы 4х4 с помощью двоичных переключателей
Матрица состоит из трех уровней двоичных переключателей, которые соединяют свой вход с одним из двух выходов в зависимости от значения бита тэга. Переключатели первого уровня управляются первым битом тэга, второго - вторым, а третьего - третьим.
Матрица может быть реализована и по-другому, на основании комбинационных схем другого типа, но ее особенностью все равно остается технология коммутации физических каналов. Известным недостатком этой технологии является отсутствие буферизации данных внутри коммутационной матрицы - если составной канал невозможно построить из-за занятости выходного порта или промежуточного коммутационного элемента, то данные должны накапливаться в их источнике, в данном случае - во входном блоке порта, принявшего кадр.
Коммутаторы с общей шиной
Коммутаторы с общей шиной используют для связи процессоров портов высокоскоростную шину, используемую в режиме разделения времени. Эта архитектура похожа на изображенную на рисунке 4.1 архитектуру коммутаторов на основе универсального процессора, но отличается тем, что шина здесь пассивна, а активную роль выполняют специализированные процессоры портов.
Пример такой архитектуры приведен на рисунке 4.4. Для того, чтобы шина не была узким местом коммутатора, ее производительность должна быть по крайней мере в N/2 раз выше скорости поступления данных во входные блоки процессоров портов. Кроме этого, кадр должен передаваться по шине небольшими частями, по несколько байт, чтобы передача кадров между несколькими портами происходила в псевдопараллельном режиме, не внося задержек в передачу кадра в целом. Размер такой ячейки данных определяется производителем коммутатора. Некоторые производители, например, LANNET (сейчас подразделение компании Madge Networks), выбрали в качестве порции данных, переносимых за одну операцию по шине, ячейку АТМ с ее полем данных в 48 байт. Такой подход облегчает трансляцию протоколов локальных сетей в протокол АТМ, если коммутатор поддерживает эти технологии.
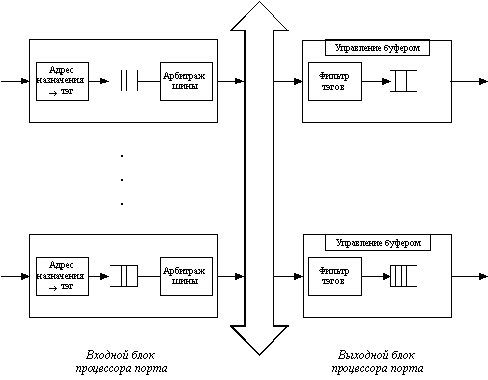
Рис. 4.4. Архитектура общей шины
Входной блок процессора помещает в ячейку, переносимую по шине, тэг, в котором указывает номер порта назначения. Каждый выходной блок процессора порта содержит фильтр тэгов, который выбирает тэги, предназначенные данному порту.
Шина, так же как и коммутационная матрица, не может осуществлять промежуточную буферизацию, но так как данные кадра разбиваются на небольшие ячейки, то задержек с начальным ожиданием доступности выходного порта в такой схеме нет.
Дата: 2019-05-29, просмотров: 362.