Динамические структуры данных могут создаваться, изменять свой размер и уничтожаться в процессе выполнения программы. Мы рассмотрим наиболее часто используемые динамические структуры:
- списки,
- очереди,
- стеки,
- бинарные деревья.
а) Списки
Простейшая форма списка – это группа объектов. Она содержит некоторые объекты и позволяет программе работать с ними. Если это все, что вам необходимо, то вы можете в качестве списка использовать массив, отслеживая при помощи некоторой переменной число элементов в нем.
Если вы в программе можете обойтись именно таким построением списка, то используйте такую организацию данных. Этот метод эффективен, прост в отладке и эксплуатации. Однако для решения ряда задач требуется построение более сложных и функциональных связанных списков, которые располагаются в куче. Рассмотрим такие списки.
Список – это структура данных, каждый элемент которой (звено списка) содержит данные одного формата, связанные друг с другом при помощи указателей, расположенных всамих элементах. Звенья списка могут располагаться в произвольных местах кучи, связывают их указатели. Указатель на начало списка (на первый элемент списка) содержится в переменной, которая называется указателем списка. Если в списке нет элементов, то есть список пуст, то указатель списка имеет значение NULL. Под каждый элемент списка отводится несколько соседних байтов памяти, в первых из которых размещена собственно информация, а в остальных – указатели (в простейшем случае один указатель) на другие элементы списка. Информация может иметь простой или структурированный тип данных. Размер звена списка зависит от размеров полей звена.
Достоинством списков является то, что их длина (число звеньев) заранее не фиксируется, удаление и вставка звена реализуется быстро и просто путем замены указателей в одном – двух звеньях. К недостаткам использования списков относят: лишний расход памяти для размещения указателей и отсутствие прямого доступа к любому элементу списка. (Для реализации доступа к i-тому элементу списка надо просмотреть i-1 предшествующий элемент).
Простейший вариант списка – линейный однонаправленный список.

 U
U
Поле указателя последнего элемента однонаправленного списка содержит значение NULL.
Элемент списка естественно представить структурой. Тогда базовым типом для указателя будет являться тип структуры.
struct sp
{int info;
struct sp *next;
}
Структура объявленного типа имеет информационное поле целого типа и указатель на такую же структуру, с помощью которого структуры объединяются в списки. Указатель указывает на структуру (иногда называемую узлом или звеном) целиком, а не на отдельные компоненты, находящиеся внутри ее.
После этого надо объявить указатель на объявленный структурный шаблон:
typedef sp *SP_ptr; // указатель на тип sp
Затем объявляют указатель на начало списка. Назовем его head:
SP_ptr head = NULL;
Создание списка.
Построение списка сводится к последовательному добавлению элементов в первоначально пустой список. На пустой список указывает пустой указатель, имеющий значение NULL.
Рассмотрим создание списка на примере. Сформировать список, содержащий целые числа 3, 5, 1, 9.
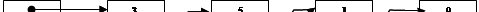
U
Введем необходимые объявления.
struct sp
{int info;
struct sp *next;
}
sp * head = NULL;
Список будем организовывать путем добавления элементов “в хвост списка”.
Нулевой указатель на начало списка является признаком того, что список пустой. Для начала формирования списка, то есть для размещения первого элемента в списке, следует выделить память под этот элемент, предварительно убедившись, что список пустой. Это достигается выполнением следующих операторов:
if (head == NULL)
{ head = new sp;
head -> info = 3;
head -> next = NULL;
}
Оператор head -> info = 3; эквивалентен оператору (* head ). info = 1; Первый из них называется оператором косвенного выбора и объединяет в себе действия, связанные с разыменованием и выбором поля структуры. Второй оператор осуществляет прямой выбор.
Список из одного элемента будет иметь вид:

U
Список редко состоит из одного элемента, поэтому следующим шагом является добавление нового элемента в список. Для этого необходимо объявить указатель на текущий элемент p и выполнить следующие действия:
sp *p; // указатель на текущий элемент
sp *tail; // указатель на “хвост” списка
if (head == NULL)
{ head = new sp;
head -> info = 3;
head -> next = NULL;
}
p = new sp;
p -> info = 5;
p -> next = head -> next; // в данном случае NULL
head -> next = p;
tail = p;
После вставки элемента список приобретет такой вид:
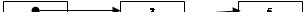 head
head
p
tail
Так будем формировать список, пока не закончатся все числа, которые в этот список нужно поместить. Если мы знаем, сколько элементов нам надо поместить в список, то можем написать цикл, который будет решать поставленную задачу.
sp * p; // указатель на текущий элемент
sp * tail; // указатель на “хвост” списка
int N = 10; // количество элементов в списке
int cnt = 1; // счетчик элементов
head = NULL;
…
if (head == NULL)
{ head = new sp;
head -> info = cnt++; // или какому-то другому значению
head -> next = NULL;
tail = head;
}
for (int i = 2; i < N; i++)
{ p = new sp;
p ->info = cnt++;
tail -> next = p;
p -> next = NULL;
tail = p;
}
В результате сформируется заданный список, head будет указывать на голову списка, tail – на хвост списка.
Вывод списка на экран можно записать очень просто:
p = head;
for (int i = 1; i < N; i++)
{ cout << p-> info << ‘ ‘;
p = p -> next; // перекидывание указателя на следующий элемент списка
}
cout << endl;
При выводе списка на экран мы последовательно просматриваем его с самого начала.
Каждое звено линейного списка семантически можно рассматривать как запертый ящик, содержащий ключ от другого ящика. Существует только один ключ, лежащий вне списка. Это указатель списка. Последний ящик содержит ключ NULL. Предположим, что необходимо открыть третий запертый ящик. Ключ от третьего ящика находится во втором. Корректный способ доступа к третьему ящику заключается в открытии сначала первого. После извлечения ключа из него мы можем открыть второй ящик, а после извлечения ключа уже из второго – сможем открыть третий ящик и тогда будут доступны данные, лежащие там. Рассмотренный алгоритм открытия ящиков часто используется для работы со списками и называется алгоритмом обхода. Обход всего списка начинается с посещения первого узла и завершается посещением последнего.
Дата: 2019-05-28, просмотров: 441.