Потерянное время (Lost time) - сумма его составляющих – потерь из-за недостаточного параллелизма (User insufficient _ par), системных потерь из-за недостаточного параллелизма (Sys insufficient _ par), коммуникаций (Communication) и простоев (Idle time).
Простои на данном процессоре (Idle time) - разность между максимальным временем выполнения интервала (на каком-то процессоре) и временем его выполнения на данном процессоре.
Общее время коммуникаций (Communication).
Реальные потери из-за рассинхронизации (Real synchronization).
Потенциальные потери из-за разброса времен (Variation).
Разбалансировка (Load _ imbalance) вычисляется как разность между максимальным процессорным временем (CPU + MPI) и соответствующим временем на данном процессоре.
Время выполнения интервала (Execution _ time).
Полезное процессорное время (User CPU_time).
Полезное системное время (MPI time).
Число используемых процессоров для данного интервала (Processors).
Времена коммуникаций для всех типов коллективных операций
Реальные потери из-за рассинхронизации для всех типов коллективных операций.
Потенциальные потери из-за рассинхронизации для всех типов коллективных операций.
Потенциальные потери из-за разброса времен для всех типов коллективных операций.
Этап 2
Подготовка текстового представления вычисленных характеристик. Такое представление упрощает первоначальный анализ характеристик при запуске параллельной программы на удаленной ЭВМ.
Этап 3
Визуализация результатов анализа эффективности.
Подсистема визуализации должна обеспечить графическое представление вычисленных характеристик эффективности и помочь пользователю их исследовать - позволить с разной степенью подробности просматривать историю выполнения программы и объяснять, как были вычислены те или иные характеристики.
Устройство анализатора
Итак, анализатор состоит из трех основных компонент.
Первая – сбор информации по трассе. Вторая – анализ собранных данных. Третья – визуализация.
Сбор трассы
При каждом запуске параллельной программы в режиме трассировки, создается группа файлов с информацией обо всех ключевых событиях в трассе. Тут есть времена и параметры всех событий, которые имели место при выполнении программы. К этим данным есть возможность доступа через специальные функции интерфейса. Также можно получить информацию для разного рода вспомогательных таблиц (имена используемых функций, исходных файлов и т.п.).
Далее полученные данные поступают на вход модулям анализа и сбора характеристик.
Анализ
В соответствии с описанной в пункте 4.2 методикой, вся программа будет разбита на систему интервалов, точнее дерево интервалов. Корнем дерева будет вся программа, она считается интервалом нулевого уровня.
Далее в соответствии с вложенностью интервалы первого уровня и т.д.
Как указать границы интервалов?
Для этого используются пара функций MPI_Send() и MPI_Recv() для указания начала интервала, и такая же пара для указания его окончания. При этом посылка и прием сообщения происходят самому себе и от самого себя (имеется ввиду, что в качестве номера отправителя/получателя используется номер самого процесса). Кроме того, тэг сообщения имеет следующий вид:
TAG = 0x(aa)(id)(aa/bb).
Тэг является четырехбайтным целым числом. Первый байт у «нашего» тэга – это 0xaa. Это позволяет отличить его от обычных посылок/приемов сообщений. Последний байт может быть 0xaa – символизирует начало интервала, 0xbb – конец интервала. Внутри специальный идентификатор интервала (2 байта), его можно использовать, например, для того, чтобы отдельно выделить итерации цикла.
Такой способ выделения был выбран потому, что:
· он всегда попадает в трассировку (некоторые специальные функции вроде MPI_Pcontrol() в текущей версии трассировщика не попадают).
· занимает относительно немного времени (порядка 100 тиков процессора).
· прост в использовании и не требует дополнительных средств, помимо стандартных MPI-функций.
Таким образом, программист может добавить в свой код границы интересующих его областей программы (в нашей терминологии интервалы).
Далее по этим тэгам среди всех событий будут найдены те, которые являются границами интервалов и будут определены их идентификаторы.
Для этого вводится специальный класс:
class Margin
{
public:
Margin(bool ,unsigned long ,int ,unsigned int ,int);
friend bool operator <( const Margin& s1, const Margin& s2)
bool enter_leave;
unsigned long time;
int identity;
unsigned int proc;
unsigned int scl;
};
И функция:
vector < Margin >* createMargins ( void );
которая и вычисляет=> определяет необходимые границы вместе со всеми параметрами.
После определения границ, создается структура дерево, в которой хранятся все данные обо всех интервалах.
Кратко об используемых структурах данных.
Создан специальный класс tree:
class tree
{
public:
static int Intervallevel; // current interval level
static int IntervalID; // current interval ID
long index;
int level; // Interval level
int EXE_count;
int source_line;
string source_file;
int ID;
//Characteristics for every interval
unsigned long Exec_time;
unsigned long Productive_time;
double Efficiency;
unsigned long CPU_time;
unsigned long MPI_time;
unsigned long Lost_time;
unsigned long Comm_time;
unsigned long SendRecv_time;
unsigned long CollectiveAll_time;
unsigned long Idle_time;
unsigned long AllToAll_time;
unsigned long Time_variation;
unsigned long Potent_sync;
unsigned long T_start;
vector < pair<unsigned long,unsigned int> >* cmp_pairs;
//for intelval's tree
tree* parent_interval;
int count;
vector<tree *> nested_intervals;
vector<Processors> Procs;
};
Этот класс содержит информацию обо всех характеристиках данного интервала, описанных в 5.2. Кроме того, в нем есть информация о родительском узле дерева, а также обо всех «листьях-потомках».
В этом классе в качестве вспомогательного используется класс Processors.
class Processors
{
public:
unsigned long enter_time;
unsigned long leave_time;
unsigned int number;
unsigned long MPI_time;
unsigned long SendRecv_time;
unsigned long CollectiveAll_time;
unsigned long Idle_time;
unsigned long AllToAll_time;
unsigned long CPU_time;
unsigned long Comm_time;
unsigned long Time_variation;
unsigned long Potent_sync;
unsigned long T_start;
};
В этом классе содержатся элементарные составляющие всех компонентов, собранные на каждом интервале каждого процессора.
Далее, после определения границ интервалов, происходит создание дерева интервалов. В этом дереве и будет храниться информация обо всех интервалах.
Класс tree включает методы, которые и собирают информацию из структур, собранных на трассе.
Первая группа характеристик собирается в функции
Leave(int line, char* file, long index,unsigned int proc,unsigned long time).
· MPI_time Используем – getMPITimebyProc ( );
· SendRecv_time - getSendRecvCommunicationTimebyProc();
· CollectiveAll_time – getCollectiveAllByProc ( );
· AllToAll_time - getAllToAllByProc();
· Potent_sync - getPotentSyncByProc();
· Time_variation - getTimeVariationByProc();
· T_start - getNonBlockedTimebyProc();
Вычисление характеристик.
getMPITimebyProc () – Происходит суммирование интервалов времени, занятых под MPI-функции (интервалы получаются как разность между временем выхода и входа в MPI-функцию).
getSendRecvCommunicationTimebyProc ( )- Происходит суммирование интервалов времени, вычисляемых как разность времени выхода из функции приема сообщения и времени входа в функцию посылки сообщения.
getPotentSyncByProc () – Вычисляется по-разному для операций одиночных посылок/приемов сообщений и коллективных операций. Сюда входят все случаи, когда Recv был выдан раньше Send’а. Эти «задержки» как раз и суммируются. Для коллективных же операций суммируется время «задержки» старта операции на некоторых процессорах.
getTimeVariationByProc () – Вычисляется время, рассинхронизации окончания коллективной операции.
getNonBlockedTimebyProc () – Вычисляется аналогично getMPITimebyProc (), только суммируются времена работы только не блокирующих операций.
Все эти характеристики собираются на каждом процессоре для данного интервала. Прототип всех функций одинаков:
getFunction(unsigned long enter_time, unsigned long leave_time, unsigned int proc).
Собранные «элементарные» характеристики, затем собираются в более общие по всему интервалу.
Первая используемая для этого функция – это функция Integrate().
В этой функции собираются следующие характеристики:
· CPU_time
· MPI_time
· SendRecv_time
· CollectiveAll_time
· AllToAll_time
· Comm_time(Общее время коммуникаций)
· Idle_time(время бездействия)
· Potent_sync
· Time_variation
· T_start
Все они уже являются характеристиками всего интервала.
Далее происходит вычисление уже не общих, а сравнительных характеристик. Зная все эти компоненты на каждом процессоре для интервала, мы находим процессоры с максимальным, минимальным значением по времени, а также среднее значения всех характеристик.
После функции Integrate() вычисляется полезное время calculateProductive(), потом время запуска - calculateExecution(),
эффективность распараллеливания - efficiency(), и, наконец, потерянное время – calculateLost().
На этом сбор и анализ информации оканчиваются. Следующий этап, это генерация соответствующих текстовых выдач. Эти выдачи представляют собой текстовый файл и имеют следующий вид (Пример).
Пример. Текстовый файл с итоговыми характеристиками.
Interval (LineNumber = 153 SourceFile = exch.c) Level=0 EXE_Count=1
---Main Characteristics---
Parallelization Efficiency 0.978833
Execution Time 2.079975
Processors 4
Total Time 8.319900
Productive Time 8.143794 (CPU MPI)
MPI время на одном процессоре считается полезным, а на остальных - потерянным
Lost Time 0.176106
---MPI Time 0.173490
---Idle Time 0.002616
Communication Time 0.076563
*****SendRecv Time 0.013295
*****CollectiveAll Time 0.063268
*****AllToAll Time 0.000000
Potential Sync. 0.068763
Time Variation 0.001790
Time of Start 0.000000
---Comparative Characteristics---
Tmin Nproc Tmax Nproc Tmid
Lost Time 0.033087 3 0.060057 0 0.044026
Idle Time 0.000000 1 0.000898 0 0.000654
Comm. Time 0.006597 3 0.034854 0 0.019140
MPI Time 0.032259 3 0.059159 0 0.043372
Potential Sync. 0.001800 0 0.029369 3 0.017190
Time variation 0.000161 1 0.000607 3 0.000447
Time of Start 0.000000 0 0.000000 0 0.000000
Для каждого интервала выдается следующая информация:
· имя файла с исходным текстом MPI-программы и номер первого оператора интервала в нем (SourceFile, LineNumber);
· номер уровня вложенности (Level);
· количество входов (и выходов) в интервал (EXE_Count);
· основные характеристики выполнения и их компоненты (Main characteristics);
· минимальные, максимальные и средние значения характеристик выполнения программы на каждом процессоре (Comparative characteristics);
При выдаче характеристик их компоненты располагаются в той же строке (справа в скобках), либо в следующей строке (справа от символов “*” или “-“).
Информация о минимальных, максимальных и средних значениях характеристик оформлена в таблицу. Также есть информация обо всех характеристиках на каждом процессоре.
Визуализация
Следующим этапом после того, как все необходимые характеристики собраны, является этап визуализации.
Этот этап необходим, так как хотя текстовый файл содержит всю необходимую информацию, при большом числе интервалов пользоваться им не очень удобно. Кажется целесообразным, что, так как интервалы “отображались” логически в виде дерева, то и визуализировать их нужно в виде дерева. Было выбрана форма отображения, аналогичная древовидной организации файловой структуры данных на дисках. Соответственно, каждый интервал доступен из своего родителя, интервалы нижних уровней отображаются правее. Также при нажатии на интервал, в текстовое поле
выводится информация обо всех характеристиках именно этого интервала.
Это значительно облегчает поиск необходимой для анализа области.
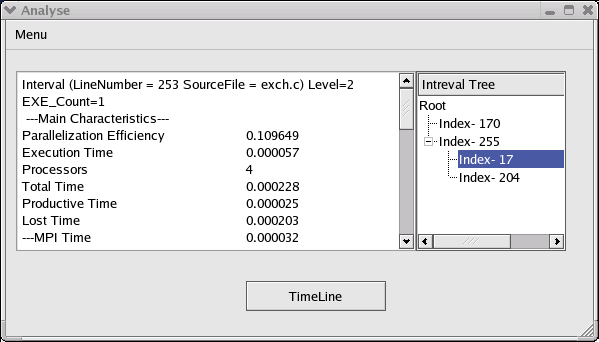
Рис.6. Окно программы анализа.
Также полезным для представления общей картины запуска является упорядоченный по времени список событий. При этом используется так называемый (TimeLine), все события отображаются на линии определенным цветом в соответствии со временем, когда они произошли. Это позволяет отслеживать не просто нужную область, а точно интересующее событие.
Используя механизм Tooltip’ов, пользователь получает возможность узнать тип события (пользовательский (UserCode) или MPI) и название функции (для MPI - функций).
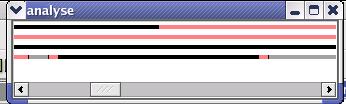
Рис.7. TimeLine
Узнать это можно по цвету линии с событием. Список цветов описан в Приложении 2.
Заключение
В данной работе исследовались возможности анализа эффективности MPI-программ. Было разработано собственное программное средство, использующее подходы, применяемые в DVM-системе.
Приблизительный объем программы на С++ в строках кода = 6500 строк.
Программа оттестирована на тестах, поставляемых с MPI – реализациями, а также с тестами NAS (NPB2.3), с добавлением описанных выше директив для границ интервала.
В процессе дипломной работы были:
ü Проанализированы современные средства анализа параллельных программ.
ü Изучены алгоритмы анализа и сбора характеристик.
ü Реализовано программное средство со следующими возможностями:
1. Отображение выполнения программы в виде дерева интервалов
2. Сбор и отображение характеристик выбранного интервала.
3. Выдача общей информации обо всех интервалах в текстовый файл.
4. Показ time-line.
Выводы:
· Отладка эффективности параллельных программ – процесс очень сложный и трудоемкий
· Развитые средства анализа эффективности могут существенно ускорить этот процесс.
· Необходима грамотная - наглядная визуализация результатов.
· Для достижения эффективности параллельной программы приходится многократно изменять программу, иногда кардинально меняя схему ее распараллеливания. Поэтому важно использовать высокоуровневые средства разработки параллельных программ
· Необходимо учитывать различные эффекты, связанные с нестабильностью поведения параллельных программ.
В дальнейшем планируется вести работу в направлении интеллектуализации системы. Желательно получение автоматических советов пользователю-программисту по улучшению эффективности программы. Это поможет упростить решение традиционных сложностей, возникающих на пути отладки параллельной программы.
Приложение 1
Структура программы.

Модуль main – вызов процедур сбора информации, анализа и генерации результата. Compute – вычисление все необходимых характеристик трассы. Для этого используется модуль tree, который отвечает за формирование дерева с данными об искомых характеристиках. Модуль determine позволяет находить и выделять интервалы в исходном коде и в трассе программы. Модуль visual занимается графическим отображением полученных данных и состоит и timeline – события в трассе, и characteristics – дерево интервалов с отображаемыми характеристиками.
Приложение 2
Используемые цвета на TimeLine :
1. Коллективные операции:
MPI_Barrier, MPI_Bcast, MPI_Gather, MPI_Gatherv, MPI_Scatter, MPI_Scatterv, MPI_Allgather, MPI_Allgatherv, MPI_Alltoall, MPI_Alltoallv, MPI_Reduce, MPI_Allreduce, MPI_Reduce_scatter, MPI_Scan
черный
2. Операции посылки
MPI_Send, MPI_Bsend, MPI_Ssend, MPI_Rsend
тёмно-зелёный
3. Неблокирующие операции посылки
MPI_Isend, MPI_Ibsend, MPI_Issend, MPI_Irsend
светло-зелёный
4. Операции получения/ожидания/посылки-получения с блокировкой MPI_Recv, MPI_Wait, MPI_Waitany, MPI_Waitall, MPI_Waitsome, MPI_Probe, MPI_Sendrecv, MPI_Sendrecv_replace
темно-синий
5. Операции получения/проверки без блокировки
MPI_Irecv, MPI_Test, MPI_Testany, MPI_Testall, MPI_Testsome, MPI_Iprobe голубой
6. Другие (малоиспользуемые) операции
MPI_Request_free, MPI_Cancel, MPI_Test_cancelled, MPI_Send_init, MPI_Bsend_init, MPI_Ssend_init, MPI_Rsend_init, MPI_Recv_init, MPI_Start, MPI_Startall
светло-серый
7. Пользовательский код
светло-розовый
Дата: 2019-04-22, просмотров: 373.