Открытие файла при помощи fopen
Функция Fopen возвращает информацию потока ввода-вывода, прикреплённого к указанному файлу или другому устройству, с которого идет чтение (или в который идет запись).
FILE *fopen(const char *path, const char *mode);
В случае неудачи функция возвращает нулевой указатель.
Закрытие потока при помощи fclose
Функция fclose принимает один аргумент: указатель на структуру FILE потока для закрытия.
int fclose(FILE *fp);
и возвращает нуль в случае успеха или EOF в случае неудачи. При нормальном завершении программы функция вызывается автоматически для каждого открытого файла.
Чтение из потока:
При помощи fgetc
Функция fgetc применяется для чтения символа из потока.
int fgetc(FILE *fp);
В случае успеха, fgetc возвращает следующий байт или символ из потока (зависит от того, файл «двоичный» или «текстовый»). В противном случае, fgetc возвращает EOF.
2. при помощи fgets
Функция fgets применяется для чтения строки из потока. Считывание происходит до тех пор пока не будет достигнут конец строки (\n) или длина строки, в которую происходит считывание.
Запись в поток:
При помощи fwrite
Функция fwrite записывает блок данных в поток.
int fwrite ( const char * array, size_t size, size_t count, FILE * stream );
Так запишется массив элементов array в текущую позицию в потоке. Для каждого элемента запишется size байт. Индикатор позиции в потоке изменится на число байт, записанных успешно. Возвращаемое значение будет равно count в случае успешного завершения записи. В случае ошибки возвращаемое значение будет меньше count.
При помощи fputс
Функция fputc применяется для записи символа в поток.
int fputc(int c, FILE *fp);
Если прошло успешно, то fputc возвращает записанный символ. Если ошибка, то fputc возвращает EOF.
9. Ввод/вывод в Си++ и работа с объектами cin и cout.
Функция scanf() заменена на объект cin.
Функция printf() заменена на объект cout,
cerr (не буферизируется),
clog (буферизируется).
Для работы с объектами используются операции “>>” и “<<”, взять из потока и поместить в поток соответственно.
Например:
cout << "Hello world!" << endl;
cin >> i; // ввод данных
cout << " Вы ввели : " << i << endl;
Объекты могут вызывать методы для выполнения некоторых действий.
Например вставка заполнителя:
cout.fill('*'); // задание символа заполнителя
cout << "price: ";
cout.width(5); // количество символов
cout << price << endl;
Установка точности вывода:
cout.precision(2);
10. Файловый ввод/вывод в Си++.
#include <имя_файла>
#include "имя_файла"
Для использования нового ввода/вывода, в языке Си++ используется файл iostream.
Следует опускать расширение файла *.h.
Необходимо подключить файл fstream.
#include <fstream>
Необходимо создать объект типа fstream, после чего необходимо открыть файловый поток, ассоциировав его с конкретным файлом.
ofstream file; // создание потока на чтение
file.open("file.txt"); // ассоциация с file.txt
или
ofstream file("file.txt");
ifstream file("file.txt"); // поток на запись
Режимы файлов
Параллельно можно установить режим направления потока (запись/чтение).
fstream file("file.txt", ios_base::in); // чтение
fstream file("file.txt", ios_base::out);// запись
Для работы с бинарными файлами можно добавить режим ios_base::binary.
fstream file("file.txt",
ios_base::out |
ios_base::binary
);
Проверка открытия файла выглядит так
if (!file.is_open())
cerr << "file.txt не открыт !" << endl;
Произвести чтение/запись нужных данных в поток.
file << "Текст на запись" << endl;
while (file.get(ch)) // читать и выводить
cout << ch; // на экран посимвольно
getline(file, str); // читать всю строку целиком
cout << str; // вывести её на экран
Закрыть поток
file.close();
11. Тип данных string. Основные операции над строками типа string в Си++.
Содержит последовательности 16-битовых (2-байтовых) кодовых точек без знака со значениями в диапазоне от 0 до 65535. Каждая кодовая точка, или код знака, представляет один символ Юникода. Строка может содержать от нуля до приблизительно двух миллиардов (2^31) знаков Юникода.
Заметки
Используйте тип данных String для хранения нескольких символов без предоставления в виде массива Char() элементов Char.
Значением String по умолчанию является Nothing (пустая ссылка). Обратите внимание, что это не то же самое, что пустая строка (значение "").
Требования формата
Необходимо заключить литерал String в кавычки (" "). Если необходимо, чтобы такая строка содержала кавычки, используются два последовательных знака кавычек (""). Это показано в приведенном ниже примере.
Dim j As String = "Joe said ""Hello"" to me."
Dim h As String = "Hello"
' The following messages all display the same thing:
' "Joe said "Hello" to me."
MsgBox(j)
MsgBox("Joe said " & """" & h & """" & " to me.")
MsgBox("Joe said """ & h & """ to me.")
Следует отметить, что парные кавычки, которые представляют кавычки в строке, могут выставляться как в середине строки String, так и в ее начале или конце.
Работа со строками
После присвоения строки переменной типа String эта строка остается неизменной, то есть нельзя изменить её длину или содержимое. При изменении строки каким-либо образом Visual Basic создает новую строку и закрывает предыдущую. После этого переменная String указывает на новую строку.

12. Тип данных bool. Тип данных void.
В языке С++ используется двоичная логика (истина, ложь). Лжи соответствует нулевое значение, истине – единица. Величины данного типа могут также принимать значения true и false.
Внутренняя форма представления значения false соответствует 0, любое другое значение интерпретируется как true. В некоторых компиляторах языка С++ нет данного типа, в этом случае используют тип int, который при истинных значениях выдает 1, а при ложных – 0. Под данные логического типа отводится 1 байт.
Тип void
Множество значений этого типа пусто. Тип void имеет три назначения:
1. указание о невозвращении функцией значения;
2. указание о неполучении параметров функцией;
3. создание нетипизированных указателей.
Тип void в основном используется для определения функций, которые не возвращают значения, для указания пустого списка аргументов функции, как базовый тип для указателей и в операции приведения типов.
| Основные типы данных | |||||||
| Тип | Обозначение | Название | Размер памяти, байт (бит) | Диапазон значений | |||
| Имя типа | Другие имена | ||||||
| целый | int | signed | целый | 4 (32) | -2 147 483 648 до 2 147 483 647 | ||
| signed int | |||||||
| unsigned int | unsigned | беззнаковый целый | 4 (32) | 0 до 4 294 967 295 | |||
| short | short int | короткий целый | 2 (16) | -32 768 до 32 767 | |||
| signed shortint | |||||||
| unsignedshort | unsignedshort int | беззнаковый короткий целый | 2 (16) | 0 до 65 535 | |||
| long | long int | длинный целый | 4 (32) | -2 147 483 648 до 2 147 483 647 | |||
| signed long int | |||||||
| unsignedlong | unsignedlong int | беззнаковый длинный целый | 4 (32) | 0 до 4 294 967 295 | |||
| long long | long long int | длинный-предлинный целый | 8 (64) | -9 223 372 036 854 775 808 до 9 223 372 036 854 775 807 | |||
| signed long long int | |||||||
| unsignedlong long | unsignedlong | беззнаковый длинный-предлинный целый | 8 (64) | 0 до 18 446 744 073 709 551 615 | |||
| long int | |||||||
| символьный | char | signed char | байт (целый длиной не менее 8 бит) | 1 (8) | -128 до 127 | ||
| unsignedchar | - | беззнаковый байт | 1 (8) | 0 до 255 | |||
| wchar_t | - | расширенный символьный | 2 (16) | 0 до 65 535 | |||
| вещественный | float | - | вещественный одинарной точности | 4 (32) | 3.4Е-38 до 3.4Е+38 (7 значащих цифр) | ||
| double | - | вещественный двойной точности | 8 (64) | 1.7Е-308 до 1.7Е+308 (15 значащих цифр) | |||
| long double | - | вещественный максимальной точности | 8 (64) | 1.7Е-308 до 1.7Е+308 (15 значащих цифр) | |||
| bool | - | логический | 1 (8) | true (1) или false (0) | |||
| enum | - | перечисляемый | 4 (32) | -2 147 483 648 до 2 147 483 647 | |||
13. Понятие пространства имён (namespace) и директивы/объявления using
Ключевое слово namespace (пространство имён) используется для объявления области, которая содержит набор связанных объектов. Можно использовать пространство имён для организации элементов кода, а также для создания глобально уникальных типов.
пространство имен определяет область объявлений, в которой допускается хранить одно множество имен отдельно от другого. По существу, имена, объявленные в одном пространстве имен, не будут вступать в конфликт с аналогичными именами, объявленными в другой области.
В пространстве имен можно объявить один или несколько из следующих типов:
другое пространство имен;
class
interface
struct
enum
delegate
директивы/объявления using
Директива using позволяет использовать имена из пространства-имен без явного указания квалификатора имя-пространства-имен. Разумеется, для повышения удобочитаемости можно по-прежнему использовать полные квалифицированные имена.
using namespace [::] [ nested-name-specifier ] namespace-name
Директива using используется в двух случаях:
разрешает использование типов в пространстве имен, поэтому уточнение использования типа в этом пространстве имен не требуется;
using System.Text;
позволяет создавать псевдонимы пространства имен или типа. Это называется директива using alias.
using Project = PC.MyCompany.Project;
Объявление using включает имя в ту область объявления, в которой находится это объявление using.
using [typename][::] nested-name-specifier unqualified-id
using :: unqualified-id
14. Работа препроцессора и его директивы (#include, #define, #ifdef/#ifndef, #endif).
Директивы процессора
#include
Указывает препроцессору, что содержимое заданного файла необходимо обработать так, как если бы оно находилось в исходной программе в той точке, в которой располагается эта директива.
#define
Директива #define создает макрос, представляющий собой ассоциацию обычного или параметризованного идентификатора со строкой токена. После определения макроса, компилятор может заменить строку токена для каждого вхождения идентификаторов в файле источника.
#ifdef
Указывает, что на этапе компиляции следует включить заданную группу команд, если была определена константа этапа компиляции с именем ConstantName.
#ifndef Указывает, что на этапе компиляции следует включить заданную группу команд, если константа этапа компиляции с именем ConstantName не определена
Директивой (командной строкой[1]) препроцессора называется строка в исходном коде, имеющая следующий формат: #ключевое_слово параметры:
· ноль или более символов пробелов и/или табуляции;
· символ #;
· ноль или более символов пробелов и/или табуляции;
· одно из предопределённых ключевых слов;
· параметры, зависимые от ключевого слова.
Список ключевых слов:
· define — создание константы или макроса;
· undef — удаление константы или макроса;
· include — вставка содержимого указанного файла;
· if — проверка истинности выражения;
· ifdef — проверка существования константы или макроса;
· ifndef — проверка не существования константы или макроса;
· else — ветка условной компиляции при ложности выражения if;
· elif — проверка истинности другого выражения; краткая форма записи для комбинации else и if;
· endif — конец ветки условной компиляции;
· line — указание имени файла и номера текущей строки для компилятора;
· error — вывод сообщения и остановка компиляции;
· warning — вывод сообщения без остановки компиляции;
· pragma — указание действия, зависящего от реализации, для препроцессора или компилятора;
· если ключевое слово не указано, директива, игнорируется;
· если указано несуществующее ключевое слово, выводится сообщение о ошибке и компиляция прерывается.
15. Объявление и инициализация указателей. Опасность при работе с указателем.
После объявления нестатического локального указателя до первого присвоения он содержит неопределенное значение. (Глобальные и статические локальные указатели при объявлении неявно инициализируются нулем.) Если попытаться использовать указатель перед присвоением ему нужного значения, то скорее всего он мгновенно разрушит программу или всю операционную систему. Это очень досадная ошибка.
При работе с указателями большинство программистов придерживаются следующего важного соглашения: указатель, не ссылающийся в текущий момент времени должным образом на конкретный объект, должен содержать нулевое значение. Нуль используется потому, что С гарантирует отсутствие чего-либо по нулевому адресу. Следовательно, если указатель равен нулю, то это значит, во-первых, что он ни на что не ссылается, а во-вторых — что его сейчас нельзя использовать.
Указателю можно задать нулевое значение, присвоив ему 0. Например, следующий оператор инициализирует р нулем:
char *p = 0;Дополнительно к этому во многих заголовочных файлах языка С, например, в <stdio.h> определен макрос NULL, являющийся нулевой указательной константой. Поэтому в программах на С часто можно увидеть следующее присваивание:
p = NULL;Однако равенство указателя нулю не делает его абсолютно "безопасным". Использование нуля в качестве признака неподготовленности указателя — это только соглашение программистов, но не правило языка С. В следующем примере компиляция пройдет без ошибки, а результат, тем не менее, будет неправильным:
int *p = 0;*p = 10; /* ошибка! */В этом случае присваивание посредством p будет присваиванием по нулевому адресу, что обычно вызывает разрушение программы.
Во многих процедурах для повышения эффективности программы можно использовать то, что нулевой указатель заведомо считается неподготовленным для использования. Например, можно использовать нулевой указатель как признак конца массива указателей (по аналогии с нулевым терминатором строки). Процедура, использующая массив указателей, таким образом узнает о конце массива. Такой подход иллюстрируется в таком примере. Просматривая список имен, функция search() определяет, есть ли в этом списке заданное имя.
#include <stdio.h>#include <string.h> int search(char *p[], char *name); char *names[] = { "Сергей", "Юрий", "Ольга", "Игорь", NULL}; /* Нулевая константа кончает список */ int main(void){ if(search(names, "Ольга") != -1) printf("Ольга есть в списке.\n"); if(search(names, "Павел") == -1) printf("Павел в списке не найден.\n"); return 0;} /* Просмотр имен. */int search(char *p[], char *name){ register int t; for(t=0; p[t]; ++t) if(!strcmp(p[t], name)) return t; return -1; /* имя не найдено */}В функцию search() передаются два параметра. Первый из них, p — массив указателей на строки, представляющие собой имена из списка. Второй параметр name является указателем на строку с заданным именем. Функция search() просматривает массив указателей, пока не найдет строку, совпадающую со строкой, на которую указывает name. Итерации цикла for повторяются до тех пор, пока не произойдет совпадение имен, или не встретится нулевой указатель. Конец массива отмечен нулевым указателем, поэтому при достижении конца массива управляющее условие цикла примет значение ЛОЖЬ. Иными словами, p[t] имеет значение ЛОЖЬ, когда p[t] является нулевым указателем. В рассмотренном примере именно это и происходит, когда идет поиск имени "Павел", которого в списке нет.
В программах на С указатель типа char * часто инициализируют строковой константой (как в предыдущем примере). Рассмотрим следующий пример:
char *p = "тестовая строка";Переменная р является указателем, а не массивом. Поэтому возникает логичный вопрос: где хранится строковая константа "тестовая строка"? Так как p не является массивом, она не может храниться в p, тем не менее, она где-то записана. Чтобы ответить на этот вопрос, нужно знать, что происходит, когда компилятор встречает строковую константу. Компилятор создает так называемую таблицу строк, в ней он сохраняет строковые константы, которые встречаются ему по ходу чтения текста программы. Следовательно, когда встречается объявление с инициализацией, компилятор сохраняет строку "тестовая строка" в таблице строк, а в указатель p записывает ее адрес. Дальше в программе указатель p может быть использован как любая другая строка. Это иллюстрируется следующим примером:
#include <stdio.h>#include <string.h> char *p = "тестовая строка"; int main(void){ register int t; /* печать строки слева направо и справа налево */ printf(p); for(t=strlen(p)-1; t>-1; t--) printf("%c", p[t]); return 0;}16. Указатель на указатель. Указатель на статическую переменную. Указатель на динамическую переменную. Связь массива и указателя.
Указатель на указатель
Указатели могут ссылаться на другие указатели. При этом в ячейках памяти, на которые будут ссылаться первые указатели, будут содержаться не значения, а адреса вторых указателей. Число символов * при объявлении указателя показывает порядок указателя. Чтобы получить доступ к значению, на которое ссылается указатель его необходимо разыменовывать соответствующее количество раз. Разработаем программу, которая будет выполнять некоторые операции с указателями порядка выше первого.
- MVS
- Code::Blocks
- Dev-C++
- QtCreator
| // pointer.cpp: определяет точку входа для консольного приложения. #include "stdafx.h" #include <iostream> using namespace std; int _tmain(int argc, _TCHAR* argv[]) { int var = 123; // инициализация переменной var числом 123 int *ptrvar = &var; // указатель на переменную var int **ptr_ptrvar = &ptrvar; // указатель на указатель на переменную var int ***ptr_ptr_ptrvar = &ptr_ptrvar; cout << " var\t\t= " << var << endl; cout << " *ptrvar\t= " << *ptrvar << endl; cout << " **ptr_ptrvar = " << **ptr_ptrvar << endl; // два раза разименовываем указатель, так как он второго порядка cout << " ***ptr_ptrvar = " << ***ptr_ptr_ptrvar << endl; // указатель третьего порядка cout << "\n ***ptr_ptr_ptrvar -> **ptr_ptrvar -> *ptrvar -> var -> "<< var << endl; cout << "\t " << &ptr_ptr_ptrvar<< " -> " << " " << &ptr_ptrvar << " ->" << &ptrvar << " -> " << &var << " -> " << var << endl; system("pause"); return 0; } |
Указатели на функции
Указатели могут ссылаться на функции. Имя функции, как и имя массива само по себе является указателем, то есть содержит адрес входа.
| 1 2 | // объявление указателя на функцию /*тип данных*/ (* /*имя указателя*/)(/*список аргументов функции*/); |
Тип данных определяем такой, который будет возвращать функция, на которую будет ссылаться указатель. Символ указателя и его имя берутся в круглые скобочки, чтобы показать, что это указатель, а не функция, возвращающая указатель на определённый тип данных. После имени указателя идут круглые скобки, в этих скобках перечисляются все аргументы через запятую как в объявлении прототипа функции. Аргументы наследуются от той функции, на которую будет ссылаться указатель. Разработаем программу, которая использует указатель на функцию. Программа должна находить НОД – наибольший общий делитель. НОД – это наибольшее целое число, на которое без остатка делятся два числа, введенных пользователем. Входные числа также должны быть целыми.
- MVS
- Code::Blocks
- Dev-C++
- QtCreator
| // pointer_onfunc.cpp: определяет точку входа для консольного приложения. #include "stdafx.h" #include <iostream> using namespace std; int nod(int, int ); // прототип указываемой функции int main(int argc, char* argv[]) { int (*ptrnod)(int, int); // объявление указателя на функцию ptrnod=nod; // присваиваем адрес функции указателю ptrnod int a, b; cout << "Enter first number: "; cin >> a; cout << "Enter second number: "; cin >> b; cout << "NOD = " << ptrnod(a, b) << endl; // обращаемся к функции через указатель system("pause"); return 0; } int nod(int number1, int number2) // рекурсивная функция нахождения наибольшего общего делителя НОД { if ( number2 == 0 ) //базовое решение return number1; return nod(number2, number1 % number2); // рекурсивное решение НОД } |
Указатели и массивы
В Си существует связь между указателями и массивами, и связь эта настолько тесная, что эти средства лучше рассматривать вместе. Любой доступ к элементу массива, осуществляемый операцией индексирования, может быть выполнен с помощью указателя. Вариант с указателями в общем случае работает быстрее, но разобраться в нем, особенно непосвященному, довольно трудно.
Объявление
int a[10];определяет массив a, состоящий из десяти последовательных объектов с именами a[0], a[1], ..., a[9].
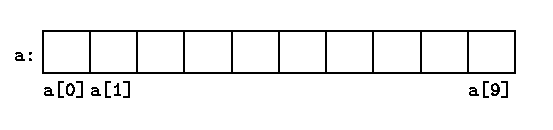
Запись a[i] отсылает нас к i-му элементу массива. Если pa есть указатель на int, т.е. объявлен как
int *pa;то в результате присваивания
pa = &a[0];pa будет указывать на нулевой элемент a, иначе говоря, pa будет содержать адрес элемента a[0].
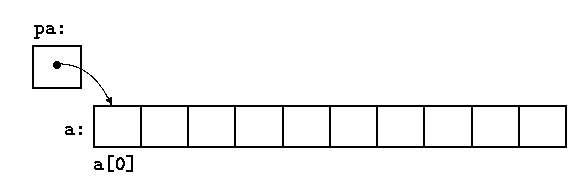
Теперь присваивание
x = *pa;будет копировать содержимое a[0] в x.
Если pa указывает на некоторый элемент массива, то pa+1 по определению указывает на следующий элемент, pa+i — на i-й элемент после pa, а pa-i — на i-й элемент перед pa. Таким образом, если pa указывает на a[0], то
*(pa+1)есть содержимое a[1], pa+i — адрес a[i], а *(pa+i) — содержимое a[i].
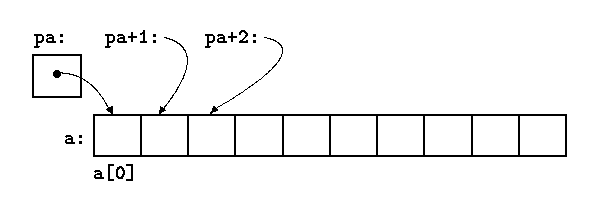
Сделанные замечания верны независимо от типа и размера элементов массива a. Смысл слов «добавить 1 к указателю», как и смысл любой арифметики с указателями, состоит в том, чтобыpa+1 указывал на следующий объект, а pa+i — на i-й после pa.
Между индексированием и арифметикой с указателями существует очень тесная связь. По определению значение переменной или выражения типа массив есть адрес нулевого элемента массива. После присваивания
pa = &a[0];pa и a имеют одно и то же значение. Поскольку имя массива является синонимом адреса его начального элемента, присваивание pa = &a[0] можно также записать в следующем виде:
pa = a;Еще более удивительно (по крайней мере на первый взгляд) то, что a[i] можно записать как *(a+i). Вычисляя a[i], Си сразу преобразует его в *(a+i); указанные две формы записи эквивалентны. Из этого следует,что записи &a[i] и a+i также будут эквивалентными, т.е. и в том и в другом случае это адрес i-го элемента массива a. С другой стороны, если pa — указатель, то его можно использовать с индексом, т.е. запись pa[i] эквивалентна записи *(pa+i). Короче говоря, элемент массива можно изображать как в виде указателя со смещением, так и в виде имени массива с индексом.
Между именем массива и указателем, выступающим в роли имени массива, существует одно различие. Указатель — это переменная, поэтому можно написать pa = a или pa++. Но имя массива не является переменной, и записи вроде a = pa или a++ не допускаются.
Если имя массива передается функции, то последняя получает в качестве аргумента адрес его начального элемента. Внутри вызываемой функции этот аргумент является локальной переменной, содержащей адрес. Мы можем воспользоваться отмеченным фактом и написать еще одну версию функции strlen, вычисляющей длину строки.
/* strlen: возвращает длину строки */ int strlen(char *s) { int n; for (n = 0; *s != '\0'; s++) n ++; return n ; }Так как переменная s — указатель, к ней применима операция ++; s++ не оказывает никакого влияния на строку символов в функции, которая обратилась к strlen. Просто увеличивается на 1 некоторая копия указателя,находящаяся в личном пользовании функции strlen. Это значит,что все вызовы, такие как:
strlen("Здравствуй, мир"); /* строковая константа */ strlen(array); /* char array[100]; */ strlen(ptr); /* char *ptr; */правомерны.
Формальные параметры
char s[];и
char *s;в определении функции эквивалентны. Мы отдаем предпочтение последнему варианту, поскольку он более явно сообщает,что s есть указатель. Если функции в качестве аргумента передается имя массива, то она может рассматривать его так, как ей удобно — либо как имя массива,либо как указатель, и поступать с ним соответственно. Она может даже использовать оба вида записи, если это покажется уместным и понятным.
17. Объявление и инициализация ссылок. Особенности работы ссылок.
Инициализация ссылка
Переменные ссылочного типа должны быть инициализированы с объектом типа, из которого ссылочный тип является производным или с объектом типа, который может быть преобразован в тип является производным от которого является ссылочным типом. Например:
Единственный способ инициализации ссылки с временным объектом инициализации константы временный объект. После инициализации переменной ссылочного типа всегда указывает на один и тот же объект. его нельзя изменить, чтобы она указывала на другой объект.
Хотя синтаксис может быть таким же, инициализация переменных ссылочного типа и присвоение переменных ссылочного типа семантически различными. В предыдущем примере назначения, которые изменяют iVar и lVar просмотрите похожи на инициализациям, но имеющих различные эффекты. Инициализация указывающее объект, на который указывает переменные ссылочного типа; присвоити назначения в ссылать-к объекту через ссылку.
Поскольку и передачи аргумента ссылочного типа функции и возвращая значение ссылочного типа из функций инициализации, формальных аргументов функции, как правильно инициализированы, возвращаемых ссылок.
Переменные ссылочного типа можно объявлять без инициализаторов только в следующем:
· Объявления функции (заполнителей). Например:
· int func( int& );· Объявления типа Функция-возвращения. Например:
· int& func( int& );· Объявление члена класса ссылочного типа. Например:
· class c {· public:· int& i;· };· Объявление переменной явно указанной как extern. Например:
· extern int& iVal;При инициализации переменной ссылочного типа, компилятор использует граф решений, приведенные в следующей диаграмме выбрал между создать ссылку на объект или создать временный объект, к которому контрольные точки.
Ссылки
Ссылка вводит для доступа к переменной второе имя и является константным указателем на объект. Значение переменной-ссылки изменить нельзя. При объявлении ссылки перед именем переменной ставится символ &. Ссылка при объявлении всегда должна быть проинициализирована.
Например:
18. Динамическое выделение и освобождение памяти (Си и Си++).
Память, которую использует программа делится на три вида:
- Статическая память (static memory)
- хранит глобальные переменные и константы;
- размер определяется при компиляции.
- Стек (stack)
- хранит локальные переменные, аргументы функций и промежуточные значения вычислений;
- размер определяется при запуске программы (обычно выделяется 4 Мб).
- Куча (heap)
- динамически распределяемая память;
- ОС выделяет память по частям (по мере необходимости).
Динамически распределяемую память следует использовать в случае если мы заранее (на момент написания программы) не знаем сколько памяти нам понадобится (например, размер массива зависит от того, что введет пользователь во время работы программы) и при работе с большими объемами данных (например, массив из 1 000 000 int`ов не поместится на стеке).
Работа с динамической памятью в С
Для работы с динамической памятью в языке С используются следующие функции: malloc, calloc, free, realloc.
Рассмотрим их подробнее.
void *malloc(size_t size);
В качестве входного параметра функция принимает размер памяти, которую требуется выделить. Возвращаемым значением является указатель на выделенный в куче участок памяти.
Для выделения памяти под 1 000 000 int`ов необходимо выполнить следующий код:
int * p = malloc(1000000*sizeof(int));
В языке С++ потребуется небольшая модификация данной кода (из-за того, что в С++ нет неявного приведения указателей):
int * p = (int *) malloc(1000000*sizeof(int));
Если ОС не смогла выделить память (например, памяти не хватило), то malloc возвращает 0.
После окончания работы с выделенной динамически памятью нужно освободить ее. Для этой цели используется функция free, которая возвращает память под управление ОС.
void free(void *ptr);
В качестве входного параметра в free нужно передать указатель, значение которого полученно из функции malloc. Вызов free на указателях полученных не из malloc (например, free(p+10)) приведет к неопределенному поведению. Это связанно с тем, что при выделении памяти при помощи malloc в ячейки перед той, на которую указывает возвращаемый функцией указатель операционная система записывает служебную информацию (см. рис.). При вызове free(p+10) информация находящаяся перед ячейкой (p+10) будет трактоваться как служебная.
void *calloc(size_t nmemb, size_t size);
Функция работает аналогично malloc, но отличается синтаксисом (вместо размера выделяемой памяти нужно задать количество элементов и размер одного элемента) и тем, что выделенная память будет обнулена. Например, после выполнения
int * q = (int *) calloc(1000000, sizeof(int))
q будет указывать на начало массива из миллиона int`ов инициализированных нулями.
void *realloc(void *ptr, size_t size);
Функция изменяет размер выделенной памяти (на которую указывает ptr, полученный из вызова malloc, calloc или realloc). Если размер указанный в параметре size больше, чем тот, который был выделен под указатель ptr, то проверяется, есть ли возможность выделить недостающие ячейки памяти подряд с уже выделенными. Если места недостаточно, то выделяется новый участок памяти размером size и данные по указателю ptr копируются в начало нового участка.
Работа с динамической памятью в С++
В С++ есть свой механизм выделения и освобождения памяти — это функции new и delete.
Пример использования new:
int * p = new int[1000000]; // выделение памяти под 1000000 int`ов
Т.е. при использовании функции new не нужно приводить указатель и не нужно использовать sizeof().
Освобождение выделенной при помощи new памяти осуществляется посредством следующего вызова:
delete [] p;
Если требуется выделить память под один элемент, то можно использовать
int * q = new int;
или
int * q = new int(10); // выделенный int проинциализируется значением 10
в этом случае удаление будет выглядеть следующим образом:
delete q;
Замечание:
Выделять динамически небольшие кусочки памяти (например, под один элемент простого типа данных) не целесообразно по двум причинам:
- При динамическом выделении памяти в ней помимо значения указанного типа будет храниться служебная информация ОС и С/С++. Таким образом потребуется гораздо больше памяти, чем при хранении необходимых данных на стеке.
- Если в памяти хранить большое количество маленьких кусочков, то она будет сильно фрагментирована и большой массив данных может не поместиться.
Многомерные массивы.
new позволяет выделять только одномерные массивы, поэтому для работы с многомерными массивами необходимо воспринимать их как массив указателей на другие массивы.
Для примера рассмотрим задачу выделения динамической памяти под массив чисел размера n на m.
Ый способ
На первом шаге выделяется указатель на массив указателей, а на втором шаге, в цикле каждому указателю из массива выделяется массив чисел в памяти:
int ** a = new int*[n];
for (int i = 0; i != n; ++i)
a[i] = new int[m];
Однако, этот способ плох тем, что в нём требуется n+1 выделение памяти, а это достаточно дорогая по времени операция.
Ой способ
На первом шаге выделение массива указателей и массива чисел размером n на m. На втором шаге каждому указателю из массива ставится в соответствие строка в массиве чисел.
int ** a = new int*[n];
a[0] = new int[n*m];
for (int i = 1; i != n; ++i)
a[i] = a[0] + i*m;
В данном случае требуется всего 2 выделения памяти.
Для освобождения памяти требуется выполнить:
1ый способ:
for (int i = 0; i != n; ++i)
delete [] a[i];
delete [] a;
2ой способ:
delete [] a[0];
delete [] a;
Таким образом, второй способ опять же требует гораздо меньше вызовов функции delete [], чем первый.
19. Операторы членства “.” и “->” используемые при работе с составными типами
данных.
a->b Обращение к члену структуры («член b объекта, на который указывает a»), выбор элемента по указателю, перегружаемый.
Пример R T::operator ->();
Тип возвращаемого значения оператора «operator->()» должен быть типом, к которому применим оператор «->», например, указателем. Если «x» имеет тип «C», и класс «C» перегружает оператор «operator->()», выражение «x->y» раскрывается как «x.operator->()->y».
a.b Обращение к члену структуры («член b объекта a»), выбор элемента по ссылке, неперегружаемый.
Операторы .* и —>* называются операторами-указателями на член. Они позволяют указывать на член класса, а не на конкретный экземпляр члена в каком-то объекте. Эти два оператора нужны постольку, поскольку указатель на член класса не определяет полностью адрес. Вместо этого он обеспечивает смещение до члена в классе. Поскольку указатели на член не являются истинными указателями в полном смысле этого слова, то обычные операторы . и —> не могут использоваться. Вместо этого применяются операторы .* и — >*.
Начнем с примера. Следующая программа осуществляет суммирование семи целых чисел. В ней доступ к функции surn_it() и переменной sum осуществляется с использованием указателей на член.
#include <iostream.h>
class myclass {
public:
int sum;
void myclass::sum_it(int x);
};
void myclass::sum_it(int x) {
int i;
sum = 0;
for(i=x; i; i--) sum += i;
}
int main()
{
int myclass::*dp; // указатель на целочисленный член
void (myclass::*fp) (int x); // указатель на функцию-член
myclass с;
dp = &myclass::sum; // получение адреса данных
fp = &myclass::sum_it; // получение адреса функции
(c.*fp)(7); // вычисление суммы с 7
cout << "summation of 7 is " << c.*dp;
return 0;
}
Внутри функции main() программа создает два указателя на член: dp, указывающий на переменную sum, и fp, указывающий на функцию sum_it(). Обратим внимание на синтаксис каждого объявления. Для указания класса используется оператор области видимости. В программе также создается объект с класса myclass.
Далее программа получает адреса sum и sum_it(). Как указывалось ранее, эти адреса являются на самом деле смещениями в объекте myclass до членов sum и sum_it(). Далее программа использует функцию, на которую указывает fp, для вызова функции sum_it() объекта с. Дополнительные скобки необходимы для того, чтобы корректно ассоциировать оператор .*. Наконец, суммарная величина выводится на экран, для чего осуществляется доступ к члену sum объекта с с использованием dp.
При осуществлении доступа к члену объекта с использованием самого объекта или ссылки на него необходимо применять оператор .*. Однако, т. к. используется указатель на объект, то потребуется оператор —>*, как иллюстрирует следующая версия предыдущей программы:
#include <iostream.h>
class myclass {
public:
int sum;
void myclass::sum_it(int x);
};
void myclass::sum_it(int x) {
int i;
sum = 0;
for(i=x; i; i--) sum += i;
}
int main()
{
int myclass::*dp; // указатель на целочисленный член
void (myclass::*fp) (int x); // указатель на функцию-член
myclass *c, d; // с теперь указатель на объект
с = &d; // с получает адрес объекта
dp = &myclass::sum; // получение адреса данных
fp = &myclass::sum_it; // получение адреса функции
(c->*fp) (7); // использование ->* для вызова функции
cout << "summation of 7 is " << c->*dp; // использование ->*
return 0;
}
В той версии с является указателем на объект типа myclass, а оператор ->* используется для доступа к членам sum и sum_it().
20. Встраиваемые функции. Возвращаемое значение.
Операторы .* и —>* называются операторами-указателями на член. Они позволяют указывать на член класса, а не на конкретный экземпляр члена в каком-то объекте. Эти два оператора нужны постольку, поскольку указатель на член класса не определяет полностью адрес. Вместо этого он обеспечивает смещение до члена в классе. Поскольку указатели на член не являются истинными указателями в полном смысле этого слова, то обычные операторы . и —> не могут использоваться. Вместо этого применяются операторы .* и — >*.
Начнем с примера. Следующая программа осуществляет суммирование семи целых чисел. В ней доступ к функции surn_it() и переменной sum осуществляется с использованием указателей на член.
#include <iostream.h>
class myclass {
public:
int sum;
void myclass::sum_it(int x);
};
void myclass::sum_it(int x) {
int i;
sum = 0;
for(i=x; i; i--) sum += i;
}
int main()
{
int myclass::*dp; // указатель на целочисленный член
void (myclass::*fp) (int x); // указатель на функцию-член
myclass с;
dp = &myclass::sum; // получение адреса данных
fp = &myclass::sum_it; // получение адреса функции
(c.*fp)(7); // вычисление суммы с 7
cout << "summation of 7 is " << c.*dp;
return 0;
}
Внутри функции main() программа создает два указателя на член: dp, указывающий на переменную sum, и fp, указывающий на функцию sum_it(). Обратим внимание на синтаксис каждого объявления. Для указания класса используется оператор области видимости. В программе также создается объект с класса myclass.
Далее программа получает адреса sum и sum_it(). Как указывалось ранее, эти адреса являются на самом деле смещениями в объекте myclass до членов sum и sum_it(). Далее программа использует функцию, на которую указывает fp, для вызова функции sum_it() объекта с. Дополнительные скобки необходимы для того, чтобы корректно ассоциировать оператор .*. Наконец, суммарная величина выводится на экран, для чего осуществляется доступ к члену sum объекта с с использованием dp.
При осуществлении доступа к члену объекта с использованием самого объекта или ссылки на него необходимо применять оператор .*. Однако, т. к. используется указатель на объект, то потребуется оператор —>*, как иллюстрирует следующая версия предыдущей программы:
#include <iostream.h>
class myclass {
public:
int sum;
void myclass::sum_it(int x);
};
void myclass::sum_it(int x) {
int i;
sum = 0;
for(i=x; i; i--) sum += i;
}
int main()
{
int myclass::*dp; // указатель на целочисленный член
void (myclass::*fp) (int x); // указатель на функцию-член
myclass *c, d; // с теперь указатель на объект
с = &d; // с получает адрес объекта
dp = &myclass::sum; // получение адреса данных
fp = &myclass::sum_it; // получение адреса функции
(c->*fp) (7); // использование ->* для вызова функции
cout << "summation of 7 is " << c->*dp; // использование ->*
return 0;
}
В той версии с является указателем на объект типа myclass, а оператор ->* используется для доступа к членам sum и sum_it().
21. Спецификаторы и квалификаторы памяти.
Квалификатор (также классификатор, спецификатор, модификатор, описатель) константа — это переменная, которую обязательно инициализировать, и которая после этого не меняет своего значения.
Константа служит для защиты переменных от попытки изменить их значение. Константой переменную делает, использование перед типом данных, квалификатор const при инициализации этой переменной.
Общая форма объявления:
const тип имя_переменной = значение_константы;
Пример:
const int MONTHS = 12;
Например, переменная MONTHS, это количество месяцев в году. Оно, по определению, всегда будет 12. если в программе просто поставить число 12, то спустя какое то время, велика вероятность, что программист уже не вспомнит, что означает данное число в конкретном месте программы. По этому, константы позволяют также повысить удобочитаемость и информативность текста программы. Константы пришли в дополнение к макросу #define. По негласному соглашению имена макросов и констант пишутся в верхнем регистре.
Константы обязательно инициализировать, например:
const int foo = 10; /* можно */
const int bar; /* нельзя */
Это логично, поскольку, если мы не инициализируем ее сразу, то вообще никогда не сможем ничего ей присвоить, поэтому, в таком случае, она окажется бесполезной.
Преимущество констант перед #define заключается в следующем:
•позволяют явным образом определить тип данных;
•к ним можно применять правила обзора данных, чтобы ограничить описание для определённых функций или файлов;
•константами могут быть более сложные типы данных (составные), например массивы и структуры;
•константы могут использоваться для указания размера массива;
•имена констант можно использовать при отладке программы;
•использование #define ведёт к трудно уловимым ошибкам, связанными с не ожидаемым поведением макроподстановки.
Простой пример использования const:
int main()
{
const int Size = 10;
int array[Size] = {0};
for (int i = 0; i < Size; i++)
array[i] = i;
for (int i = 0; i < Size; i++)
cout << array[i] << " ";
return 0;
}
Также существует ещё ряд спецификаторов, подробности использования, которых хорошо описаны здесь[1]. Здесь они только коротко описаны.
Например спецификаторы классов хранения (памяти):
1.auto — используется всегда не явно компилятором (если не определено другое).
2.register — указывает, что переменная будет храниться в регистрах процессора.
3.static — определяет связывание переменной в файле.
4.extern — определяет, что переменная определена в другом файле.
5.mutable — применяется в контексте const. В некоторых случаях, если структура или класс объявлен как const, но требуется снять это ограничение с какой-то конкретной переменной.
cv-спецификаторы:
1.const — создаёт константу;
2.volatile — указывает на возможность изменения переменной из внешней среды.
Спецификаторы классов хранения и cv-спецификаторы являются носителями дополнительной информации о хранении переменной.
22. Автоматическая, статическая и динамическая продолжительность хранения переменных.
Статическая память Статическая память выделяется переменным на всё время выполнения программы. Метод прост и не требует никакой поддержки в ходе выполнения программы, так как адреса переменных в этом случае могут быть определены ещё на этапе компиляции программы. В языке Turbo Pascal нет явного упоминания о статической памяти, но фактически к ней можно отнести память, в которой размещаются константы и переменные, которые описаны на уровне главной программы. Пример программы с использованием статической памяти. program Static; var i: Integer; procedure Sub; var Cnt:integer; begin inc(Cnt); WriteLn('Cnt = ',Cnt) end; begin for i:=1 to 3 do Sub; end. В этой программе константа Cnt, а фактически инициализируемая переменная, не смотря на то, что является локальной в процедуре Sub, существует во время выполнения программы. При запуске программы её значение не теряется после выхода из процедуры Sub вплоть до следующего входа в неё.
Автоматическая память Автоматическая память характерна для языков с блочной структурой. В отличие от статической она позволяет использовать одни и те же участки основной памяти для размещения разных переменных из разных программных блоков. Дело в том, что память для локальных переменных блока, выделяется только на время его выполнения. Это повышает эффективность использования памяти, но требует некоторой поддержки управления памятью в ходе выполнения программы, что несколько снижает производительность. Оказалось, что снижение производительности можно свести к минимуму, если использовать для управления памятью принцип стека, но это приводит к вложенной организации блоков программы. Для примера рассмотрим два варианта построения программы решения одной и той же задачи: Найти произведение сумм элементов массива. program Prgm1; const m = 10000; var a: array[1..m] of Integer; b: array[1..m] of Real; i,Sa: Integer; Sb: Real; begin { Ввод массивов a и b } Sa:=0; Sb:=0; for i:=1 to m do Sa:=Sa+a[i]; for i:=1 to m do Sb:=Sb+b[i]; WriteLn(Sb*Sa); end. program Prgm2; const m = 10000; var Sa: Integer; Sb: Real; procedure SumA; var a: array[1..m] of Integer; i: Integer; begin { Ввод массива a } for i:=1 to m do Sa:=Sa+a[i]; end; procedure SumB; var b: array[1..m] of Real; i: Integer; begin { Ввод массива b } for i:=1 to m do Sb:=Sb+b[i]; end; begin Sa:=0; Sb:=0; SumA; SumB; WriteLn(Sb*Sa); end. Не смотря на то, что это абстрактные программы, они обе формально правильные и можно попытаться их выполнить. При попытке выполнить первую программу мы получим сообщение об ошибке компиляции "Error 96". Причина ошибки заключается в том, что общий объём памяти, который выделяется переменным уровня главной программы не должен превышать 64 KB. Учитывая, что переменная типа Integer занимает 2 байта, а типа Real - 6 байтов, то для нашей программы мы получим оценку 10000*(6+2) B = 80000 B = (80000 / 1024) KB = 78.2 KB, что превышает имеющиеся возможности. Попытка выполнить вторую программу тоже приводит к сообщению об ошибке компиляции - "Error 202" (переполнение стека). Так как массивы находятся в разных процедурных блоках программы, а они вызываются последовательно, то это означает, что массивы последовательно используют одну и ту же память в стеке. Оценка необходимого объёма памяти в этом случае составляет 6*10000 B = 58.6 KB - размер большего массива. Причина ошибки состоит в том, что по умолчанию размер стека составляет всего 16 KB, но, к счастью, его можно увеличить до значения 65 520 B, что составляет почти 64 KB. Для этого в интегрированной среде надо выбрать Options | Memory sizes и установить желаемый размер стека. После этого вторая программа будет выполняться без ошибок.
Динамическая память Динамической называется переменная, память для которой выделяется во время работы программы. У динамической переменной нет имени, - к ней можно обратиться только при помощи специальной переменной, - переменной-указателя. Переменная-указатель – переменная целого типа – это адрес байта памяти, содержащей другое данное (переменную, константу, адрес другой переменной и т.п.). Любой ссылочный (адресный) тип данных определяет множество значений, которые являются указателями (ссылками) на значения какого-либо другого типа данных. Указатели и динамические переменные позволяют создавать сложные динамические структуры данных, такие как связанные списки и деревья. Указателю можно присваивать значение указателя того же типа, константу NIL (пустой указатель) или адрес объекта, определенный с помощью стандартных функций модуля System - Addr (ИмяПеременной) (оператора @ИмяПереиенной) и Ptr(СегментнаяЧастьАдреса, Смещение). Сегмент данных — это непрерывная область оперативной памяти с объемом в 65 536 байт (64 Кбайт). Динамические переменные могут размещаться в памяти компьютера и убираться из нее в процессе работы программы. Так, например, если введенные динамические переменные уже обработаны и до конца программы использоваться не будут, то их можно убрать из памяти компьютера, а на освободившемся месте разместить другие динамические переменные, необходимые по ходу выполнения решаемой задачи. Указанное свойство таких переменных весьма полезно при обработке крупных массивов данных. Область памяти, в которой размещаются динамические переменные, называется кучей (heap), максимальный ее объем более чем в 6 раз превышает объем сегмента данных и составляет около 400 Кбайт. Это не означает, что отдельные переменные (запись или массив) могут иметь такой большой размер. Конечно же, нет: ни одна переменная в Turbo Pascal не может превышать объем 65 520 байт. Однако распределить составляющие записи или массива по различным сегментам памяти оказывается вполне возможным. При этом общий объем «распределенной» переменной может существенно превысить объем отдельного сегмента. Распределение переменной по разным сегментам кучи особенно полезно, когда ее объем заранее предсказать нельзя. Рекомендуется применять динамические переменные если: 1. Необходимы переменные, имеющие большой объем и освобождающие память после их использования. 2. Размер переменной трудно предсказуем. 3. Размер переменной превышает 64 Кбайт.
23. Внутренние и внешние связывание. Область видимости переменных.
Связывание описывает экстент (протяжение, пространство), в пределах которого переменная, определенная в одной части программы, может быть привязана к любой другой части программы. Переменная с областью видимости в пределах блока, будучи локальной, не имеет связывания. Переменная с областью видимости в пределах файла имеет внутреннее или внешнее связывание. Внутреннее связывание означает, что переменная может быть использована в файле, содержащем ееопределение. Внешнее связывание означает, что переменная может быть использована в других файлах.
Память, использованная для хранения данных, которыми манипулирует программа, может быть охарактеризована продолжительностью хранения, областью видимости и связыванием. Продолжительность хранения может быть статической, автоматической или распределенной. Если продолжительность хранения статическая, память распределяется в начале выполнения программы и остается занятой на протяжении всего выполнения. Если продолжительность хранения автоматическая, то память под переменную выделяется в момент, когда выполнение программы входит в блок, в котором эта переменная определена, и освобождается, когда выполнение программы покидает этот блок. Область видимости определяет, какая часть программы может получить доступ к данным. Переменные, определенные вне пределов функции, имеют область видимости в пределах файла и видимы в любой функции, определенной после объявления этой переменной. Переменная, определенная в блоке или как параметр функции, видима только в этом блоке и в любом из блоков, вложенных в этот блок.
24. Перегрузка функции.
(полиморфизм функций, совмещение имён) — позволяет программисту определять несколько функций с одним и тем же именем (интерфейсом). Перегрузка в языке Си++ является практической реализацией принципа полиморфизма времени компиляции. Перегрузка функций подразумевает использование одного и того же имени функции при разных аргументах. То есть, главным способом различия функций с одинаковыми именами является задание аргументов разного типа и количества. Имена переменных (аргументов функции) не имеют значения. Общий вид перегрузки функций:

Пример перегрузки функции sqr() 4-и раза:


2 Классы, объекты и инкапсуляция
Понятие класса и объекта.
Базовым в объектно-ориентированном программировании является понятие класса. Класс имеет заранее заданные свойства. Состояние класса задается значениями его полей. Класс решает определенные задачи, т.е. располагает методами решения. Но сам класс непосредственно не используется в программах. Образно говоря, класс — это шаблон, на основе которого создаются экземпляры класса, или объекты. Программа, написанная с использованием ООП, состоит из объектов, которые могут взаимодействовать между собой. Например, как только вы создаете новое приложение типа Application в среде Delphi, в редакторе кодов автоматически появляется объявление класса Tform1, которое выглядит так. type Tform1 = class(TForm) private { Private declarations } public { Public declarations } end ; Это можно рассматривать как заготовку для разработки класса. Затем создается объект (переменная или экземпляр класса) типа Tform1. var Form1: Tform1;
Данные и методы.
Методы Методы представляют собой процедуры и функции, принадлежащие классу. Методы определяют поведение класса. В классе всегда должны присутствовать два важнейших метода: конструктор и деструктор. При проектировании класса можно создать произвольное количество любых других методов, необходимых для решения конкретных задач. Создание метола — процесс, состоящий из двух этапов. Сначала следует объявить метод в объявлении класса, а затем создать код его реализации. Например, выполните следующее. 1. Создайте новый проект типа Application. 2. Откройте инспектор объектов и щелкните на вкладке Events (События). 3. Два раза щелкните на поле обработчика OnСlick. В редакторе кодов получите следующую программу (см. листинг ниже), где в классе Tform1 появится процедура FormClick, а в разделе реализации — описание этой процедуры. unit Unit1; interface uses Windows, Messages, SysUtils, Variants, Classes, Graphics, Controls, Forms, Dialogs; type Tform1 = class(TForm) procedure FormClick(Sender: TObject); private { Private declarations } public { Public declarations } end; var Form1: Tform1; implementation {$R *.dfm} procedure Tform1.FormClick(Sender: TObject); begin { Здесь код обработки щелчка мыши. } end; end. Таким образом вы создали пустую процедуру обработки щелчка мыши. Можете ее заполнить соответствующими кодами и получить нужный эффект. Например, можете изменить цвет фона окна на черный, для чего поместите в описание процедуры Tform1.FormClick (между ключевыми словами begin . . . end) следующую строку: Form1.Color := clBlack; и запустите программу (клавиша ). После того как появится окно, щелкните на нем мышью и наблюдайте результат. Свойства В основе свойств лежат промежуточные методы, обеспечивающие доступ к данным и коду, содержащемуся в классе, таким образом избавляя конечного пользователя от деталей реализации класса. По отношению к компонентам свойства являются теми элементами, сведения о которых отображаются в инспекторе объектов.
Объекты Объекты (экземпляры класса) представляют собой сущности, которые могут содержать данные и код. Объекты Delphi предоставляют программисту все основные возможности объектно-ориентированного программирования, такие как наследование, инкапсуляция и полиморфизм. Перед тем как создать объект, следует объявить класс, на основе которого этот объект будет создан, В Delphi это делается с помощью ключевого слова class. Объявления классов помещаются в раздел объявления типов модуля или программы. type TFooObject = class; Только после объявления класса можно делать объявление переменных этого типа в разделе var. var FooObject: TFooObject; Полностью объект создается с помощью вызова одного из конструкторов соответствующего класса. Конструктор отвечает за создание объекта, а также за выделение памяти и необходимую инициализацию полей. Конструктор не только создает объект, но и приводит этот объект в состояние, необходимое для его дальнейшего использования. Каждый класс содержит по крайней мере один конструктор Create, который может иметь различное количество параметров разного типа — в зависимости от типа объекта. Создание каждого объекта с помощью вызова его конструктора входит в обязанности программиста. Синтаксис вызова конструктора следующий. FooObjееt := TFooObjееt.Create; Обратите внимание на особенность вызова конструктора — он вызывается с помощью ссылки на класс, а не на экземпляр класса (в отличие от других методов, которые вызываются с помощью ссылки на объект). Иначе просто нельзя — ведь экземпляр объекта FooObject в момент вызова конструктора еще не создан. Но код конструктора класса TFooObject статичен и находится в памяти. Он относится к классу, а не к его экземпляру, поэтому такой вызов вполне корректен. Вызов конструктора для создания экземпляра класса часто называют созданием объекта. При создании объекта с помощью конструктора компилятор гарантирует, что все поля объекта будут инициализированы. Все числовые поля будут обнулены, указатели примут значение nil, а строки будут пусты. По окончании использования экземпляра объекта следует освободить выделенную для него память с помощью метода Free. Этот метод сначала проверяет, не равен ли экземпляр объекта значению nil, и затем вызывает деструктор объекта — метод Destroy. Действие деструктора обратно действию конструктора, т.е. он освобождает всю выделенную память и выполняет другие действия по освобождению захваченных конструктором объекта ресурсов. Синтаксис вызова метода Free прост. FooObject.Free; Обратите внимание, что, в отличие от вызова конструктора, вызов деструктора выполняется с помощью ссылки на экземпляр, а не на тип. Также заметьте, что нет необходимости всегда объявлять и описывать конструкторы и деструкторы. Ведь все классы языка Delphi неявно наследуют функциональные возможности базового класса TObject, причем независимо от того, указано ли это наследование явно или нет. Например, объявление type TFoo = class; полностью эквивалентно объявлению класса type TFoo = class(TObject); Интерфейсы Интерфейс определяет набор функций и процедур, которые могут быть использованы для взаимодействия программы с объектом. Определение конкретного интерфейса известно не только разработчику, но и пользователю, оно воспринимается как соглашение о правилах объявления и использования этого интерфейса. В классе может быть реализовано несколько интерфейсов. В результате объект становится "многоликим", являя клиенту каждого интерфейса свое особое лицо. Интерфейсы определяют, каким образом могут общаться между собой объект и его клиент. Класс, поддерживающий некоторый интерфейс, также обязан обеспечить реализацию всех его функций и процедур.
Связь классов и структур.
Классы и структуры являются двумя основными конструкциями системы общих типов CTS в платформе .NET Framework. Каждая по сути является структурой данных, инкапсулирующей набор данных и поведение, связанные как логическая единица. Данные и поведение являются членами класса или структуры, и в них включены методы, свойства, события и т.д., как описано далее в этом разделе.
Объявление класса или структуры подобно чертежу, который используется для создания экземпляров или объектов во время выполнения. При определении класса или структуры с именем Person, Person является именем типа. При объявлении или инициализации переменной p типа Person, p считается объектом или экземпляромPerson. Возможно создание нескольких экземпляров одного типа Person, и каждый экземпляр может иметь разные значения в своих свойствах и полях.
Класс является ссылочным типом. При создании объекта класса переменная, к которой назначается объект, сохраняет только ссылку на память. При назначении ссылки на объект к новой переменной новая переменная ссылается на исходный объект. Изменения, внесенные через одну переменную, отображаются в другой переменной, поскольку обе они ссылаются на одни данные.
Структура является типом значения. При создании структуры переменная, к которой она назначается, сохраняет фактические данные структуры. При назначении структуры новой переменной выполняется ее копирование. Поэтому новая переменная и исходная переменная содержат две отдельных копии одних данных.Изменения, внесенные в одну копию, не влияют на другую копию.
Как правило, классы используются для моделирования более сложного поведения или данных, которые, как предполагается, будут изменены после создания объекта класса. Структуры лучше всего подходят для небольших структур данных, которые содержат преимущественно те данные, которые не предназначены для изменения после создания структуры.
Меню, процедурный код
Например, пусть у нас есть HTML-элемент, представляющий собой «меню», вот такой:
| 1 | <div id="food-menu" class="menu"> |
| 2 | <span class="menu-title">Продуктовое меню</span> |
| 3 | <ul class="menu-items"> |
| 4 | <li>Сыр</li> |
| 5 | <li>Колбаса</li> |
| 6 | <li>Торт</li> |
| 7 | </ul> |
| 8 | </div> |
Оживим его в процедурном стиле — через создание функций:
| 01 | var foodMenu = $("#food-menu"); |
| 02 |
| 03 | function open() { |
| 04 | foodMenu.addClass('menu-open'); |
| 05 | } |
| 06 |
| 07 | function close() { |
| 08 | foodMenu.removeClass('menu-open'); |
| 09 | } |
| 10 |
| 11 | foodMenu.on('click', '.menu-title', function() { |
| 12 | if (foodMenu.hasClass('menu-open')) { |
| 13 | close(); |
| 14 | } else { |
| 15 | open(); |
| 16 | } |
| 17 | }); |
Это ещё называют «простыня кода». Потому что чем больше такого кода — тем сложнее его поддерживать. Особенно это заметно при создании сложных интерфейсов.
Меню, объектный подход
При объектном подходе меню описывается в виде объекта, например:
| 01 | /** |
| 02 | * options -- объект с параметрами меню. |
| 03 | * elem -- элемент меню |
| 04 | */ |
| 05 | function Menu(options) { |
| 06 | var elem = options.elem; |
| 07 |
| 08 | this.open = function() { |
| 09 | elem.addClass('menu-open'); |
| 10 | }; |
| 11 |
| 12 | this.close = function() { |
| 13 | elem.removeClass('menu-open'); |
| 14 | }; |
| 15 |
| 16 | elem.on('click', '.menu-title', function() { |
| 17 | if (elem.hasClass('menu-open')) { |
| 18 | close(); |
| 19 | } else { |
| 20 | open(); |
| 21 | } |
| 22 | }); |
| 23 |
| 24 | } |
Теперь мы можем использовать его в любом месте кода:
| 1 | var foodMenu = new Menu({ |
| 2 | elem: $('#food-menu') |
| 3 | }); |
| 4 | // ... |
| 5 | foodMenu.open(); |
Механизм включения.
class имя_класса : список_базовых_классов
{список_компонентов_класса};
class имя_базового_класса
{ данные_базового_класса;};
class имя_класса_потомка: спецификатор_доступа имя_базового_класса
{данные_класса_потомка;};
4 Полиморфизм
1. Перегрузка операций.
Кратко смысл полиморфизма можно выразить фразой: «Один интерфейс, множество методов». В Си++ полиморфизм реализован ввиде перегрузки функций, перегрузки операций и полиморфного наследования.
Перегрузка операций
Для повышения возможностей моделирования объектов реального мира в классе добавлена возможность перегрузки операций. Перегрузка операций позволяет определить (переопределить) операции, что даёт возможность их использовать с объектом класса.
На самом деле в Си++ некоторые операции уже перегружены. Например, операция (*) при использовании с двумя операндами перемножает их, а при применении её к адресу даёт доступ к значению, расположенному по этому адресу.
Чтобы понять, зачем нужна перегрузка операций сравните два следующих оператора присваивания:
strcpy(string_1, string_2);
и
string_1 = string_2;
Сама перегрузка операций синтаксически выглядит, как функция.
Общий вид прототипа перегрузки операции:
operatorop(список_аргументов);
где, op — это символ, перегружаемой операции. Например: operator+().
Допускается перегружать только определённые в Си++ операции. Допустим нельзя перегрузить $ или @, так как в языке их нет(то есть нельзя создавать новые операции). Также Си++ налагает дополнительные ограничения на перегрузку, перечисленные далее.
●Перегружаемые операции должны иметь, как минимум один операнд пользовательского типа.
●Нельзя перегружать операцию с нарушением её исходного синтаксиса. Например, если операция определена для работы с двумя операндами, то и перегруженную операцию нужно использовать с двумя операндами, а не со одним.
●Нельзя перегружать следующие операции:
sizeof() - операция получения размера;
. - операция принадлежности(членства);
.*- операция принадлежности к указателю;
:: - операция разрешения контекста;
:? - условная операция.
●Для следующих операций допустимо использовать только функции-члены:
= - операция присваивания;
() - операция вызова функции;
[] - операция индексации;
-> - операция доступа к членам класса через указатель.
При перегрузке операций, допустим, если требуется сложить два объекта, то это можно записать так:
n = k + t;
Компилятор, в свою очередь, определив операцию класса, объектами которого являются операнды, заменит эту запись на следующую:
n = k.operator+(t);
Пример класса с использованием функции sum() для сложения объектов за место перегрузки операций:
class A
{
int x;
Public:
A() : x(0) {} // тоже самое x = 0;
A(int n) : x(n){} // тоже самое x = n;
~A(){}
void Set_A(int const n){x = n;}
int Get_A() const {return x;}
void Show() const {cout << x << endl;}
A sum(const A & a){return x + a.x;}
};
int main()
{
A n = 3, m = 4, k; // создание и инициализация переменных класса A
cout << n << " " << m << endl; // вывод их содержимого
k = n.sum(m); // сложение переменных n и m
cout << k; // печать результата
return 0;
}
Пример класса с реализованной перегрузкой операции сложения:
class A
{
int x;
Public:
A() : x(0) {} // тоже самое x = 0;
A(int n) : x(n){} // тоже самое x = n;
~A(){}
void Set_A(int const n){x = n;}
int Get_A() const {return x;}
void Show() const {cout << x << endl;}
A operator+(const A &a){return x + a.x;}
};
int main()
{
A n = 3, m = 4, k; // создание и инициализация переменных класса A
cout << n << " " << m << endl; // вывод их содержимого
k = n + m; // сложение переменных n и m
cout << k; // печать результата
return 0;
}
Существует ещё одна особенность перегрузки. Предыдущий пример показал, как перегрузить операцию, если левый операнд является объектом, а что делать, если он будет цифровой константой? Например:
k = 4 + m;
С логической точки зрения это абсолютно нормальная операция, но если вспомнить, что компилятор преобразует её к следующему виду:
k = 4.operator+(m);
то появляется проблема, налагающая некоторые особенности по работе с перегрузкой операций. Решить её помогут функции друзья. Подробнее про друзей читайте в теме 6.5.1.
Вывод данных из класса на экран можно организовать за счёт перегрузки операции << ― поместить в поток. Если добавить эту операцию и операцию присвоения, то наш пример станет выглядеть так:
class A
{
int x;
Public:
A() : x(0) {} // тоже самое x = 0;
A(int n) : x(n){} // тоже самое x = n;
~A(){}
void Set_A(int const n){x = n;}
int Get_A() const {return x;}
void Show() const {cout << x << endl;}
A operator+(const A &a){return x + a.x;}
A& operator=(const A& rhs); // перегрузка операции присвоения
A operator<<(ostream & os) {os << x << endl;} // перегрузка операции поместить в поток
};
Однако, возникает проблема связанная с тем, что воспользоваться перегруженной операцией поместить в поток, необходимо использовать следующий код:
k << cout;
который является довольно запутанным. По этому, в данном случае, также придётся воспользоваться функциями друзьями.
Перегрузка операции присваивания почти ничем не отличается от перегрузки других операций, за исключением того, что требуется вставить проверку: не присваивает ли объект сам себя. Пример такого присваивания:
k = k;
Код этой проверки вместе с кодом перегруженной операции присваивания выглядит так:
A& A::operator=(const A& rhs)
if (this == &rhs) return *this; // проверка — текущий объект и объект rhs
// не являются ли, одним и тем же объектом
x = rhs.x; // присваиваем данные из объекта rhs в текущий
return *this;
}
2.Полиморфное наследование. (динамический полиморфизм)
При использовании механизма наследования мы можем использовать методы из базового класса в классах потомках. То есть, если в базовом классе определена функция, то мы можем её использовать в классе наследнике. Но иногда возникают ситуации, в которых требуется использовать унаследованный метод, который вёл бы себя иначе, чем метод определённый в базовом классе. Такой способ поведения называется полиморфным. При этом ценность полиморфного наследования заключается в том, что можно использовать один метод для разных объектов. При этом модель поведения метода будет выбираться в зависимости от контекста.
Бывают следующие виды полиморфного наследования:
●переопределение методов базового класса в производном классе;
●использование виртуальных функций.
3.Виртуальные функции понятия и реализация.
Виртуальная функция — это функция, которая может быть переопределена классом-наследником, для того чтобы тот имел свою, отличающуюся, реализацию. В языке C++ используется такой механизм, как таблица виртуальных функций
(кратко vtable) для того, чтобы поддерживать связывание на этапе выполнения программы. Виртуальная таблица — статический массив, который хранит для каждой виртуальной функции указатель на ближайшую в иерархии наследования реализацию этой функции. Ближайшая в иерархии реализация определяется во время выполнения посредством извлечения адреса функции из таблицы методов объекта.
Теперь давайте подумаем, как реализовать концепцию виртуальных функций на C. Зная, что виртуальные функции представлены в виде указателей и хранятся в vtable, а vtable — статический массив, мы должны создать структуру, имитирующую сам класс ClassA, таблицу виртуальных функций для ClassA, а также реализацию методов ClassA.
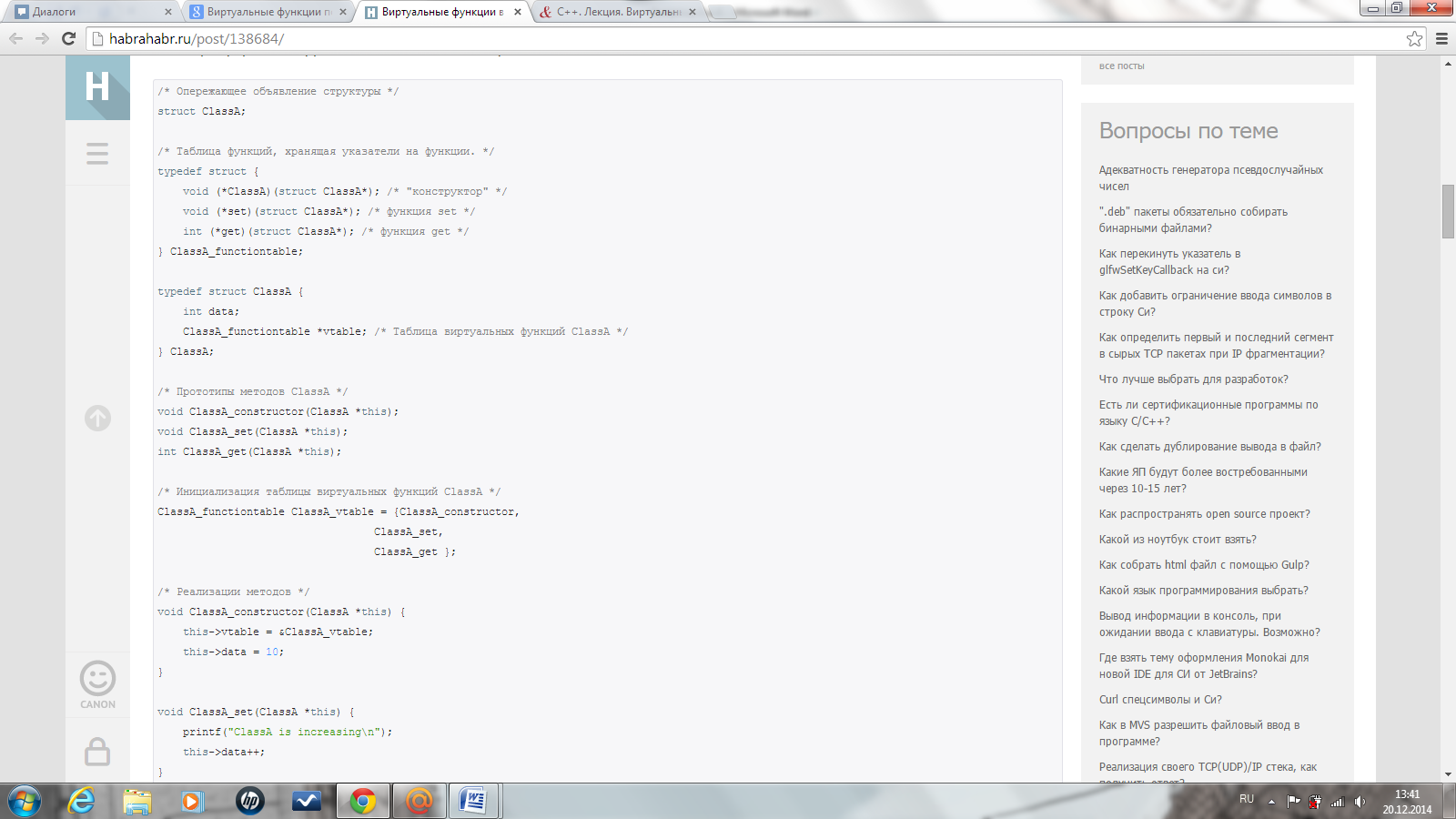
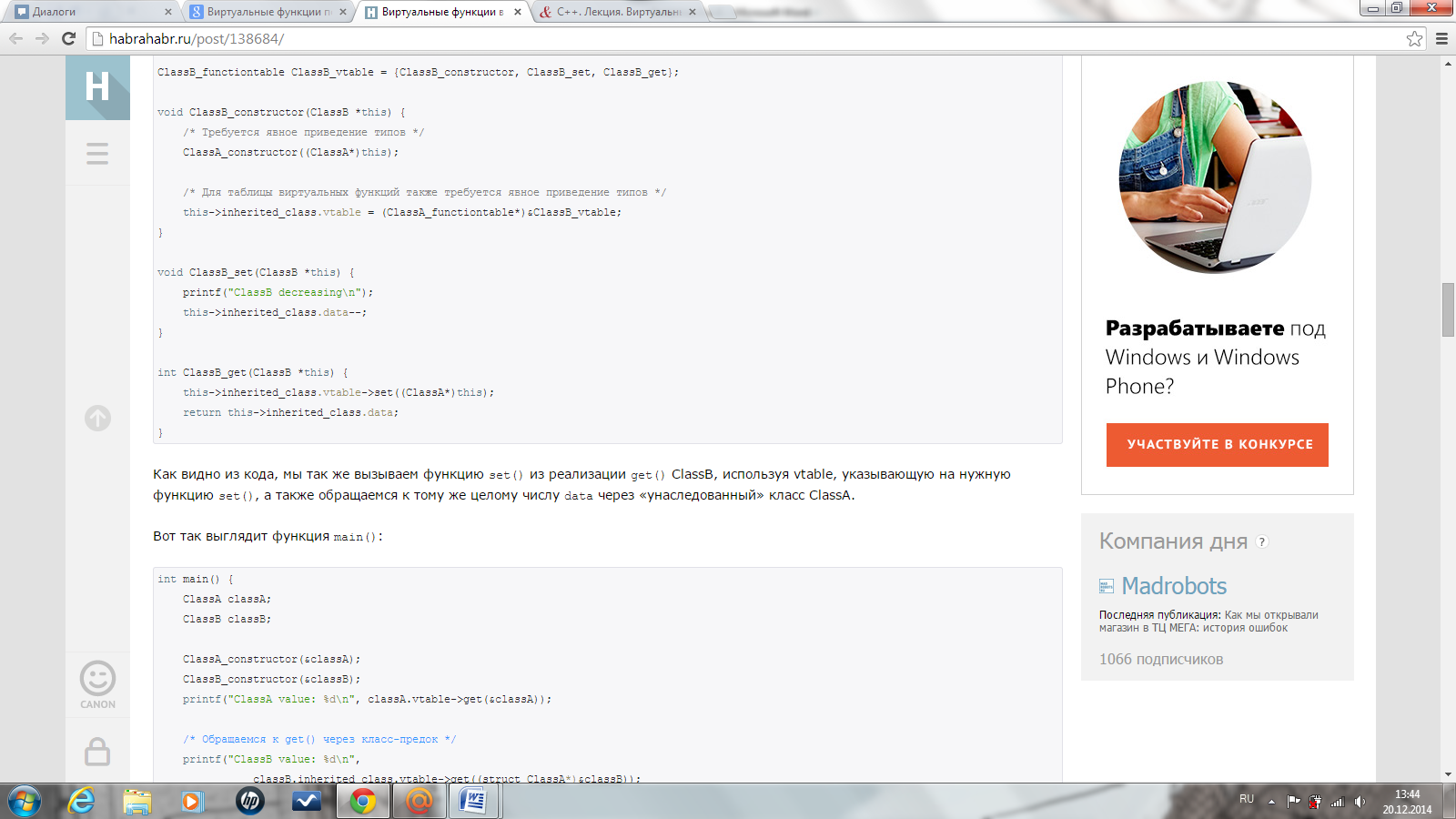
Открытие файла при помощи fopen
Функция Fopen возвращает информацию потока ввода-вывода, прикреплённого к указанному файлу или другому устройству, с которого идет чтение (или в который идет запись).
FILE *fopen(const char *path, const char *mode);
В случае неудачи функция возвращает нулевой указатель.
Закрытие потока при помощи fclose
Функция fclose принимает один аргумент: указатель на структуру FILE потока для закрытия.
int fclose(FILE *fp);
и возвращает нуль в случае успеха или EOF в случае неудачи. При нормальном завершении программы функция вызывается автоматически для каждого открытого файла.
Чтение из потока:
При помощи fgetc
Функция fgetc применяется для чтения символа из потока.
int fgetc(FILE *fp);
В случае успеха, fgetc возвращает следующий байт или символ из потока (зависит от того, файл «двоичный» или «текстовый»). В противном случае, fgetc возвращает EOF.
2. при помощи fgets
Функция fgets применяется для чтения строки из потока. Считывание происходит до тех пор пока не будет достигнут конец строки (\n) или длина строки, в которую происходит считывание.
Запись в поток:
При помощи fwrite
Функция fwrite записывает блок данных в поток.
int fwrite ( const char * array, size_t size, size_t count, FILE * stream );
Так запишется массив элементов array в текущую позицию в потоке. Для каждого элемента запишется size байт. Индикатор позиции в потоке изменится на число байт, записанных успешно. Возвращаемое значение будет равно count в случае успешного завершения записи. В случае ошибки возвращаемое значение будет меньше count.
При помощи fputс
Функция fputc применяется для записи символа в поток.
int fputc(int c, FILE *fp);
Если прошло успешно, то fputc возвращает записанный символ. Если ошибка, то fputc возвращает EOF.
9. Ввод/вывод в Си++ и работа с объектами cin и cout.
Функция scanf() заменена на объект cin.
Функция printf() заменена на объект cout,
cerr (не буферизируется),
clog (буферизируется).
Для работы с объектами используются операции “>>” и “<<”, взять из потока и поместить в поток соответственно.
Например:
cout << "Hello world!" << endl;
cin >> i; // ввод данных
cout << " Вы ввели : " << i << endl;
Объекты могут вызывать методы для выполнения некоторых действий.
Например вставка заполнителя:
cout.fill('*'); // задание символа заполнителя
cout << "price: ";
cout.width(5); // количество символов
cout << price << endl;
Установка точности вывода:
cout.precision(2);
10. Файловый ввод/вывод в Си++.
#include <имя_файла>
#include "имя_файла"
Для использования нового ввода/вывода, в языке Си++ используется файл iostream.
Следует опускать расширение файла *.h.
Необходимо подключить файл fstream.
#include <fstream>
Необходимо создать объект типа fstream, после чего необходимо открыть файловый поток, ассоциировав его с конкретным файлом.
ofstream file; // создание потока на чтение
file.open("file.txt"); // ассоциация с file.txt
или
ofstream file("file.txt");
ifstream file("file.txt"); // поток на запись
Режимы файлов
Параллельно можно установить режим направления потока (запись/чтение).
fstream file("file.txt", ios_base::in); // чтение
fstream file("file.txt", ios_base::out);// запись
Для работы с бинарными файлами можно добавить режим ios_base::binary.
fstream file("file.txt",
ios_base::out |
ios_base::binary
);
Проверка открытия файла выглядит так
if (!file.is_open())
cerr << "file.txt не открыт !" << endl;
Произвести чтение/запись нужных данных в поток.
file << "Текст на запись" << endl;
while (file.get(ch)) // читать и выводить
cout << ch; // на экран посимвольно
getline(file, str); // читать всю строку целиком
cout << str; // вывести её на экран
Закрыть поток
file.close();
11. Тип данных string. Основные операции над строками типа string в Си++.
Содержит последовательности 16-битовых (2-байтовых) кодовых точек без знака со значениями в диапазоне от 0 до 65535. Каждая кодовая точка, или код знака, представляет один символ Юникода. Строка может содержать от нуля до приблизительно двух миллиардов (2^31) знаков Юникода.
Заметки
Используйте тип данных String для хранения нескольких символов без предоставления в виде массива Char() элементов Char.
Значением String по умолчанию является Nothing (пустая ссылка). Обратите внимание, что это не то же самое, что пустая строка (значение "").
Требования формата
Необходимо заключить литерал String в кавычки (" "). Если необходимо, чтобы такая строка содержала кавычки, используются два последовательных знака кавычек (""). Это показано в приведенном ниже примере.
Dim j As String = "Joe said ""Hello"" to me."
Dim h As String = "Hello"
' The following messages all display the same thing:
' "Joe said "Hello" to me."
MsgBox(j)
MsgBox("Joe said " & """" & h & """" & " to me.")
MsgBox("Joe said """ & h & """ to me.")
Следует отметить, что парные кавычки, которые представляют кавычки в строке, могут выставляться как в середине строки String, так и в ее начале или конце.
Работа со строками
После присвоения строки переменной типа String эта строка остается неизменной, то есть нельзя изменить её длину или содержимое. При изменении строки каким-либо образом Visual Basic создает новую строку и закрывает предыдущую. После этого переменная String указывает на новую строку.
12. Тип данных bool. Тип данных void.
В языке С++ используется двоичная логика (истина, ложь). Лжи соответствует нулевое значение, истине – единица. Величины данного типа могут также принимать значения true и false.
Внутренняя форма представления значения false соответствует 0, любое другое значение интерпретируется как true. В некоторых компиляторах языка С++ нет данного типа, в этом случае используют тип int, который при истинных значениях выдает 1, а при ложных – 0. Под данные логического типа отводится 1 байт.
Тип void
Множество значений этого типа пусто. Тип void имеет три назначения:
1. указание о невозвращении функцией значения;
2. указание о неполучении параметров функцией;
3. создание нетипизированных указателей.
Тип void в основном используется для определения функций, которые не возвращают значения, для указания пустого списка аргументов функции, как базовый тип для указателей и в операции приведения типов.
| Основные типы данных | |||||||
| Тип | Обозначение | Название | Размер памяти, байт (бит) | Диапазон значений | |||
| Имя типа | Другие имена | ||||||
| целый | int | signed | целый | 4 (32) | -2 147 483 648 до 2 147 483 647 | ||
| signed int | |||||||
| unsigned int | unsigned | беззнаковый целый | 4 (32) | 0 до 4 294 967 295 | |||
| short | short int | короткий целый | 2 (16) | -32 768 до 32 767 | |||
| signed shortint | |||||||
| unsignedshort | unsignedshort int | беззнаковый короткий целый | 2 (16) | 0 до 65 535 | |||
| long | long int | длинный целый | 4 (32) | -2 147 483 648 до 2 147 483 647 | |||
| signed long int | |||||||
| unsignedlong | unsignedlong int | беззнаковый длинный целый | 4 (32) | 0 до 4 294 967 295 | |||
| long long | long long int | длинный-предлинный целый | 8 (64) | -9 223 372 036 854 775 808 до 9 223 372 036 854 775 807 | |||
| signed long long int | |||||||
| unsignedlong long | unsignedlong | беззнаковый длинный-предлинный целый | 8 (64) | 0 до 18 446 744 073 709 551 615 | |||
| long int | |||||||
| символьный | char | signed char | байт (целый длиной не менее 8 бит) | 1 (8) | -128 до 127 | ||
| unsignedchar | - | беззнаковый байт | 1 (8) | 0 до 255 | |||
| wchar_t | - | расширенный символьный | 2 (16) | 0 до 65 535 | |||
| вещественный | float | - | вещественный одинарной точности | 4 (32) | 3.4Е-38 до 3.4Е+38 (7 значащих цифр) | ||
| double | - | вещественный двойной точности | 8 (64) | 1.7Е-308 до 1.7Е+308 (15 значащих цифр) | |||
| long double | - | вещественный максимальной точности | 8 (64) | 1.7Е-308 до 1.7Е+308 (15 значащих цифр) | |||
| bool | - | логический | 1 (8) | true (1) или false (0) | |||
| enum | - | перечисляемый | 4 (32) | -2 147 483 648 до 2 147 483 647 | |||
13. Понятие пространства имён (namespace) и директивы/объявления using
Ключевое слово namespace (пространство имён) используется для объявления области, которая содержит набор связанных объектов. Можно использовать пространство имён для организации элементов кода, а также для создания глобально уникальных типов.
пространство имен определяет область объявлений, в которой допускается хранить одно множество имен отдельно от другого. По существу, имена, объявленные в одном пространстве имен, не будут вступать в конфликт с аналогичными именами, объявленными в другой области.
В пространстве имен можно объявить один или несколько из следующих типов:
другое пространство имен;
class
interface
struct
enum
delegate
директивы/объявления using
Директива using позволяет использовать имена из пространства-имен без явного указания квалификатора имя-пространства-имен. Разумеется, для повышения удобочитаемости можно по-прежнему использовать полные квалифицированные имена.
using namespace [::] [ nested-name-specifier ] namespace-name
Директива using используется в двух случаях:
разрешает использование типов в пространстве имен, поэтому уточнение использования типа в этом пространстве имен не требуется;
using System.Text;
позволяет создавать псевдонимы пространства имен или типа. Это называется директива using alias.
using Project = PC.MyCompany.Project;
Объявление using включает имя в ту область объявления, в которой находится это объявление using.
using [typename][::] nested-name-specifier unqualified-id
using :: unqualified-id
14. Работа препроцессора и его директивы (#include, #define, #ifdef/#ifndef, #endif).
Директивы процессора
#include
Указывает препроцессору, что содержимое заданного файла необходимо обработать так, как если бы оно находилось в исходной программе в той точке, в которой располагается эта директива.
#define
Директива #define создает макрос, представляющий собой ассоциацию обычного или параметризованного идентификатора со строкой токена. После определения макроса, компилятор может заменить строку токена для каждого вхождения идентификаторов в файле источника.
#ifdef
Указывает, что на этапе компиляции следует включить заданную группу команд, если была определена константа этапа компиляции с именем ConstantName.
#ifndef Указывает, что на этапе компиляции следует включить заданную группу команд, если константа этапа компиляции с именем ConstantName не определена
Директивой (командной строкой[1]) препроцессора называется строка в исходном коде, имеющая следующий формат: #ключевое_слово параметры:
· ноль или более символов пробелов и/или табуляции;
· символ #;
· ноль или более символов пробелов и/или табуляции;
· одно из предопределённых ключевых слов;
· параметры, зависимые от ключевого слова.
Список ключевых слов:
· define — создание константы или макроса;
· undef — удаление константы или макроса;
· include — вставка содержимого указанного файла;
· if — проверка истинности выражения;
· ifdef — проверка существования константы или макроса;
· ifndef — проверка не существования константы или макроса;
· else — ветка условной компиляции при ложности выражения if;
· elif — проверка истинности другого выражения; краткая форма записи для комбинации else и if;
· endif — конец ветки условной компиляции;
· line — указание имени файла и номера текущей строки для компилятора;
· error — вывод сообщения и остановка компиляции;
· warning — вывод сообщения без остановки компиляции;
· pragma — указание действия, зависящего от реализации, для препроцессора или компилятора;
· если ключевое слово не указано, директива, игнорируется;
· если указано несуществующее ключевое слово, выводится сообщение о ошибке и компиляция прерывается.
15. Объявление и инициализация указателей. Опасность при работе с указателем.
После объявления нестатического локального указателя до первого присвоения он содержит неопределенное значение. (Глобальные и статические локальные указатели при объявлении неявно инициализируются нулем.) Если попытаться использовать указатель перед присвоением ему нужного значения, то скорее всего он мгновенно разрушит программу или всю операционную систему. Это очень досадная ошибка.
При работе с указателями большинство программистов придерживаются следующего важного соглашения: указатель, не ссылающийся в текущий момент времени должным образом на конкретный объект, должен содержать нулевое значение. Нуль используется потому, что С гарантирует отсутствие чего-либо по нулевому адресу. Следовательно, если указатель равен нулю, то это значит, во-первых, что он ни на что не ссылается, а во-вторых — что его сейчас нельзя использовать.
Указателю можно задать нулевое значение, присвоив ему 0. Например, следующий оператор инициализирует р нулем:
char *p = 0;Дополнительно к этому во многих заголовочных файлах языка С, например, в <stdio.h> определен макрос NULL, являющийся нулевой указательной константой. Поэтому в программах на С часто можно увидеть следующее присваивание:
p = NULL;Однако равенство указателя нулю не делает его абсолютно "безопасным". Использование нуля в качестве признака неподготовленности указателя — это только соглашение программистов, но не правило языка С. В следующем примере компиляция пройдет без ошибки, а результат, тем не менее, будет неправильным:
int *p = 0;*p = 10; /* ошибка! */В этом случае присваивание посредством p будет присваиванием по нулевому адресу, что обычно вызывает разрушение программы.
Во многих процедурах для повышения эффективности программы можно использовать то, что нулевой указатель заведомо считается неподготовленным для использования. Например, можно использовать нулевой указатель как признак конца массива указателей (по аналогии с нулевым терминатором строки). Процедура, использующая массив указателей, таким образом узнает о конце массива. Такой подход иллюстрируется в таком примере. Просматривая список имен, функция search() определяет, есть ли в этом списке заданное имя.
#include <stdio.h>#include <string.h> int search(char *p[], char *name); char *names[] = { "Сергей", "Юрий", "Ольга", "Игорь", NULL}; /* Нулевая константа кончает список */ int main(void){ if(search(names, "Ольга") != -1) printf("Ольга есть в списке.\n"); if(search(names, "Павел") == -1) printf("Павел в списке не найден.\n"); return 0;} /* Просмотр имен. */int search(char *p[], char *name){ register int t; for(t=0; p[t]; ++t) if(!strcmp(p[t], name)) return t; return -1; /* имя не найдено */}В функцию search() передаются два параметра. Первый из них, p — массив указателей на строки, представляющие собой имена из списка. Второй параметр name является указателем на строку с заданным именем. Функция search() просматривает массив указателей, пока не найдет строку, совпадающую со строкой, на которую указывает name. Итерации цикла for повторяются до тех пор, пока не произойдет совпадение имен, или не встретится нулевой указатель. Конец массива отмечен нулевым указателем, поэтому при достижении конца массива управляющее условие цикла примет значение ЛОЖЬ. Иными словами, p[t] имеет значение ЛОЖЬ, когда p[t] является нулевым указателем. В рассмотренном примере именно это и происходит, когда идет поиск имени "Павел", которого в списке нет.
В программах на С указатель типа char * часто инициализируют строковой константой (как в предыдущем примере). Рассмотрим следующий пример:
char *p = "тестовая строка";Переменная р является указателем, а не массивом. Поэтому возникает логичный вопрос: где хранится строковая константа "тестовая строка"? Так как p не является массивом, она не может храниться в p, тем не менее, она где-то записана. Чтобы ответить на этот вопрос, нужно знать, что происходит, когда компилятор встречает строковую константу. Компилятор создает так называемую таблицу строк, в ней он сохраняет строковые константы, которые встречаются ему по ходу чтения текста программы. Следовательно, когда встречается объявление с инициализацией, компилятор сохраняет строку "тестовая строка" в таблице строк, а в указатель p записывает ее адрес. Дальше в программе указатель p может быть использован как любая другая строка. Это иллюстрируется следующим примером:
#include <stdio.h>#include <string.h> char *p = "тестовая строка"; int main(void){ register int t; /* печать строки слева направо и справа налево */ printf(p); for(t=strlen(p)-1; t>-1; t--) printf("%c", p[t]); return 0;}16. Указатель на указатель. Указатель на статическую переменную. Указатель на динамическую переменную. Связь массива и указателя.
Указатель на указатель
Указатели могут ссылаться на другие указатели. При этом в ячейках памяти, на которые будут ссылаться первые указатели, будут содержаться не значения, а адреса вторых указателей. Число символов * при объявлении указателя показывает порядок указателя. Чтобы получить доступ к значению, на которое ссылается указатель его необходимо разыменовывать соответствующее количество раз. Разработаем программу, которая будет выполнять некоторые операции с указателями порядка выше первого.
- MVS
- Code::Blocks
- Dev-C++
- QtCreator
| // pointer.cpp: определяет точку входа для консольного приложения. #include "stdafx.h" #include <iostream> using namespace std; int _tmain(int argc, _TCHAR* argv[]) { int var = 123; // инициализация переменной var числом 123 int *ptrvar = &var; // указатель на переменную var int **ptr_ptrvar = &ptrvar; // указатель на указатель на переменную var int ***ptr_ptr_ptrvar = &ptr_ptrvar; cout << " var\t\t= " << var << endl; cout << " *ptrvar\t= " << *ptrvar << endl; cout << " **ptr_ptrvar = " << **ptr_ptrvar << endl; // два раза разименовываем указатель, так как он второго порядка cout << " ***ptr_ptrvar = " << ***ptr_ptr_ptrvar << endl; // указатель третьего порядка cout << "\n ***ptr_ptr_ptrvar -> **ptr_ptrvar -> *ptrvar -> var -> "<< var << endl; cout << "\t " << &ptr_ptr_ptrvar<< " -> " << " " << &ptr_ptrvar << " ->" << &ptrvar << " -> " << &var << " -> " << var << endl; system("pause"); return 0; } |
Указатели на функции
Указатели могут ссылаться на функции. Имя функции, как и имя массива само по себе является указателем, то есть содержит адрес входа.
| 1 2 | // объявление указателя на функцию /*тип данных*/ (* /*имя указателя*/)(/*список аргументов функции*/); |
Тип данных определяем такой, который будет возвращать функция, на которую будет ссылаться указатель. Символ указателя и его имя берутся в круглые скобочки, чтобы показать, что это указатель, а не функция, возвращающая указатель на определённый тип данных. После имени указателя идут круглые скобки, в этих скобках перечисляются все аргументы через запятую как в объявлении прототипа функции. Аргументы наследуются от той функции, на которую будет ссылаться указатель. Разработаем программу, которая использует указатель на функцию. Программа должна находить НОД – наибольший общий делитель. НОД – это наибольшее целое число, на которое без остатка делятся два числа, введенных пользователем. Входные числа также должны быть целыми.
- MVS
- Code::Blocks
- Dev-C++
- QtCreator
| // pointer_onfunc.cpp: определяет точку входа для консольного приложения. #include "stdafx.h" #include <iostream> using namespace std; int nod(int, int ); // прототип указываемой функции int main(int argc, char* argv[]) { int (*ptrnod)(int, int); // объявление указателя на функцию ptrnod=nod; // присваиваем адрес функции указателю ptrnod int a, b; cout << "Enter first number: "; cin >> a; cout << "Enter second number: "; cin >> b; cout << "NOD = " << ptrnod(a, b) << endl; // обращаемся к функции через указатель system("pause"); return 0; } int nod(int number1, int number2) // рекурсивная функция нахождения наибольшего общего делителя НОД { if ( number2 == 0 ) //базовое решение return number1; return nod(number2, number1 % number2); // рекурсивное решение НОД } |
Указатели и массивы
В Си существует связь между указателями и массивами, и связь эта настолько тесная, что эти средства лучше рассматривать вместе. Любой доступ к элементу массива, осуществляемый операцией индексирования, может быть выполнен с помощью указателя. Вариант с указателями в общем случае работает быстрее, но разобраться в нем, особенно непосвященному, довольно трудно.
Объявление
int a[10];определяет массив a, состоящий из десяти последовательных объектов с именами a[0], a[1], ..., a[9].
Запись a[i] отсылает нас к i-му элементу массива. Если pa есть указатель на int, т.е. объявлен как
int *pa;то в результате присваивания
pa = &a[0];pa будет указывать на нулевой элемент a, иначе говоря, pa будет содержать адрес элемента a[0].
Теперь присваивание
x = *pa;будет копировать содержимое a[0] в x.
Если pa указывает на некоторый элемент массива, то pa+1 по определению указывает на следующий элемент, pa+i — на i-й элемент после pa, а pa-i — на i-й элемент перед pa. Таким образом, если pa указывает на a[0], то
*(pa+1)есть содержимое a[1], pa+i — адрес a[i], а *(pa+i) — содержимое a[i].
Сделанные замечания верны независимо от типа и размера элементов массива a. Смысл слов «добавить 1 к указателю», как и смысл любой арифметики с указателями, состоит в том, чтобыpa+1 указывал на следующий объект, а pa+i — на i-й после pa.
Между индексированием и арифметикой с указателями существует очень тесная связь. По определению значение переменной или выражения типа массив есть адрес нулевого элемента массива. После присваивания
pa = &a[0];pa и a имеют одно и то же значение. Поскольку имя массива является синонимом адреса его начального элемента, присваивание pa = &a[0] можно также записать в следующем виде:
pa = a;Еще более удивительно (по крайней мере на первый взгляд) то, что a[i] можно записать как *(a+i). Вычисляя a[i], Си сразу преобразует его в *(a+i); указанные две формы записи эквивалентны. Из этого следует,что записи &a[i] и a+i также будут эквивалентными, т.е. и в том и в другом случае это адрес i-го элемента массива a. С другой стороны, если pa — указатель, то его можно использовать с индексом, т.е. запись pa[i] эквивалентна записи *(pa+i). Короче говоря, элемент массива можно изображать как в виде указателя со смещением, так и в виде имени массива с индексом.
Между именем массива и указателем, выступающим в роли имени массива, существует одно различие. Указатель — это переменная, поэтому можно написать pa = a или pa++. Но имя массива не является переменной, и записи вроде a = pa или a++ не допускаются.
Если имя массива передается функции, то последняя получает в качестве аргумента адрес его начального элемента. Внутри вызываемой функции этот аргумент является локальной переменной, содержащей адрес. Мы можем воспользоваться отмеченным фактом и написать еще одну версию функции strlen, вычисляющей длину строки.
/* strlen: возвращает длину строки */ int strlen(char *s) { int n; for (n = 0; *s != '\0'; s++) n ++; return n ; }Так как переменная s — указатель, к ней применима операция ++; s++ не оказывает никакого влияния на строку символов в функции, которая обратилась к strlen. Просто увеличивается на 1 некоторая копия указателя,находящаяся в личном пользовании функции strlen. Это значит,что все вызовы, такие как:
strlen("Здравствуй, мир"); /* строковая константа */ strlen(array); /* char array[100]; */ strlen(ptr); /* char *ptr; */правомерны.
Формальные параметры
char s[];и
char *s;в определении функции эквивалентны. Мы отдаем предпочтение последнему варианту, поскольку он более явно сообщает,что s есть указатель. Если функции в качестве аргумента передается имя массива, то она может рассматривать его так, как ей удобно — либо как имя массива,либо как указатель, и поступать с ним соответственно. Она может даже использовать оба вида записи, если это покажется уместным и понятным.
17. Объявление и инициализация ссылок. Особенности работы ссылок.
Инициализация ссылка
Переменные ссылочного типа должны быть инициализированы с объектом типа, из которого ссылочный тип является производным или с объектом типа, который может быть преобразован в тип является производным от которого является ссылочным типом. Например:
Единственный способ инициализации ссылки с временным объектом инициализации константы временный объект. После инициализации переменной ссылочного типа всегда указывает на один и тот же объект. его нельзя изменить, чтобы она указывала на другой объект.
Хотя синтаксис может быть таким же, инициализация переменных ссылочного типа и присвоение переменных ссылочного типа семантически различными. В предыдущем примере назначения, которые изменяют iVar и lVar просмотрите похожи на инициализациям, но имеющих различные эффекты. Инициализация указывающее объект, на который указывает переменные ссылочного типа; присвоити назначения в ссылать-к объекту через ссылку.
Поскольку и передачи аргумента ссылочного типа функции и возвращая значение ссылочного типа из функций инициализации, формальных аргументов функции, как правильно инициализированы, возвращаемых ссылок.
Переменные ссылочного типа можно объявлять без инициализаторов только в следующем:
· Объявления функции (заполнителей). Например:
· int func( int& );· Объявления типа Функция-возвращения. Например:
· int& func( int& );· Объявление члена класса ссылочного типа. Например:
· class c {· public:· int& i;· };· Объявление переменной явно указанной как extern. Например:
· extern int& iVal;При инициализации переменной ссылочного типа, компилятор использует граф решений, приведенные в следующей диаграмме выбрал между создать ссылку на объект или создать временный объект, к которому контрольные точки.
Ссылки
Ссылка вводит для доступа к переменной второе имя и является константным указателем на объект. Значение переменной-ссылки изменить нельзя. При объявлении ссылки перед именем переменной ставится символ &. Ссылка при объявлении всегда должна быть проинициализирована.
Например:
18. Динамическое выделение и освобождение памяти (Си и Си++).
Память, которую использует программа делится на три вида:
- Статическая память (static memory)
- хранит глобальные переменные и константы;
- размер определяется при компиляции.
- Стек (stack)
- хранит локальные переменные, аргументы функций и промежуточные значения вычислений;
- размер определяется при запуске программы (обычно выделяется 4 Мб).
- Куча (heap)
- динамически распределяемая память;
- ОС выделяет память по частям (по мере необходимости).
Динамически распределяемую память следует использовать в случае если мы заранее (на момент написания программы) не знаем сколько памяти нам понадобится (например, размер массива зависит от того, что введет пользователь во время работы программы) и при работе с большими объемами данных (например, массив из 1 000 000 int`ов не поместится на стеке).
Работа с динамической памятью в С
Для работы с динамической памятью в языке С используются следующие функции: malloc, calloc, free, realloc.
Рассмотрим их подробнее.
void *malloc(size_t size);
В качестве входного параметра функция принимает размер памяти, которую требуется выделить. Возвращаемым значением является указатель на выделенный в куче участок памяти.
Для выделения памяти под 1 000 000 int`ов необходимо выполнить следующий код:
int * p = malloc(1000000*sizeof(int));
В языке С++ потребуется небольшая модификация данной кода (из-за того, что в С++ нет неявного приведения указателей):
int * p = (int *) malloc(1000000*sizeof(int));
Если ОС не смогла выделить память (например, памяти не хватило), то malloc возвращает 0.
После окончания работы с выделенной динамически памятью нужно освободить ее. Для этой цели используется функция free, которая возвращает память под управление ОС.
void free(void *ptr);
В качестве входного параметра в free нужно передать указатель, значение которого полученно из функции malloc. Вызов free на указателях полученных не из malloc (например, free(p+10)) приведет к неопределенному поведению. Это связанно с тем, что при выделении памяти при помощи malloc в ячейки перед той, на которую указывает возвращаемый функцией указатель операционная система записывает служебную информацию (см. рис.). При вызове free(p+10) информация находящаяся перед ячейкой (p+10) будет трактоваться как служебная.
void *calloc(size_t nmemb, size_t size);
Функция работает аналогично malloc, но отличается синтаксисом (вместо размера выделяемой памяти нужно задать количество элементов и размер одного элемента) и тем, что выделенная память будет обнулена. Например, после выполнения
int * q = (int *) calloc(1000000, sizeof(int))
q будет указывать на начало массива из миллиона int`ов инициализированных нулями.
void *realloc(void *ptr, size_t size);
Функция изменяет размер выделенной памяти (на которую указывает ptr, полученный из вызова malloc, calloc или realloc). Если размер указанный в параметре size больше, чем тот, который был выделен под указатель ptr, то проверяется, есть ли возможность выделить недостающие ячейки памяти подряд с уже выделенными. Если места недостаточно, то выделяется новый участок памяти размером size и данные по указателю ptr копируются в начало нового участка.
Работа с динамической памятью в С++
В С++ есть свой механизм выделения и освобождения памяти — это функции new и delete.
Пример использования new:
int * p = new int[1000000]; // выделение памяти под 1000000 int`ов
Т.е. при использовании функции new не нужно приводить указатель и не нужно использовать sizeof().
Освобождение выделенной при помощи new памяти осуществляется посредством следующего вызова:
delete [] p;
Если требуется выделить память под один элемент, то можно использовать
int * q = new int;
или
int * q = new int(10); // выделенный int проинциализируется значением 10
в этом случае удаление будет выглядеть следующим образом:
delete q;
Замечание:
Выделять динамически небольшие кусочки памяти (например, под один элемент простого типа данных) не целесообразно по двум причинам:
- При динамическом выделении памяти в ней помимо значения указанного типа будет храниться служебная информация ОС и С/С++. Таким образом потребуется гораздо больше памяти, чем при хранении необходимых данных на стеке.
- Если в памяти хранить большое количество маленьких кусочков, то она будет сильно фрагментирована и большой массив данных может не поместиться.
Многомерные массивы.
new позволяет выделять только одномерные массивы, поэтому для работы с многомерными массивами необходимо воспринимать их как массив указателей на другие массивы.
Для примера рассмотрим задачу выделения динамической памяти под массив чисел размера n на m.
Ый способ
На первом шаге выделяется указатель на массив указателей, а на втором шаге, в цикле каждому указателю из массива выделяется массив чисел в памяти:
int ** a = new int*[n];
for (int i = 0; i != n; ++i)
a[i] = new int[m];
Однако, этот способ плох тем, что в нём требуется n+1 выделение памяти, а это достаточно дорогая по времени операция.
Ой способ
На первом шаге выделение массива указателей и массива чисел размером n на m. На втором шаге каждому указателю из массива ставится в соответствие строка в массиве чисел.
int ** a = new int*[n];
a[0] = new int[n*m];
for (int i = 1; i != n; ++i)
a[i] = a[0] + i*m;
В данном случае требуется всего 2 выделения памяти.
Для освобождения памяти требуется выполнить:
1ый способ:
for (int i = 0; i != n; ++i)
delete [] a[i];
delete [] a;
2ой способ:
delete [] a[0];
delete [] a;
Таким образом, второй способ опять же требует гораздо меньше вызовов функции delete [], чем первый.
19. Операторы членства “.” и “->” используемые при работе с составными типами
данных.
a->b Обращение к члену структуры («член b объекта, на который указывает a»), выбор элемента по указателю, перегружаемый.
Пример R T::operator ->();
Тип возвращаемого значения оператора «operator->()» должен быть типом, к которому применим оператор «->», например, указателем. Если «x» имеет тип «C», и класс «C» перегружает оператор «operator->()», выражение «x->y» раскрывается как «x.operator->()->y».
a.b Обращение к члену структуры («член b объекта a»), выбор элемента по ссылке, неперегружаемый.
Операторы .* и —>* называются операторами-указателями на член. Они позволяют указывать на член класса, а не на конкретный экземпляр члена в каком-то объекте. Эти два оператора нужны постольку, поскольку указатель на член класса не определяет полностью адрес. Вместо этого он обеспечивает смещение до члена в классе. Поскольку указатели на член не являются истинными указателями в полном смысле этого слова, то обычные операторы . и —> не могут использоваться. Вместо этого применяются операторы .* и — >*.
Начнем с примера. Следующая программа осуществляет суммирование семи целых чисел. В ней доступ к функции surn_it() и переменной sum осуществляется с использованием указателей на член.
#include <iostream.h>
class myclass {
public:
int sum;
void myclass::sum_it(int x);
};
void myclass::sum_it(int x) {
int i;
sum = 0;
for(i=x; i; i--) sum += i;
}
int main()
{
int myclass::*dp; // указатель на целочисленный член
void (myclass::*fp) (int x); // указатель на функцию-член
myclass с;
dp = &myclass::sum; // получение адреса данных
fp = &myclass::sum_it; // получение адреса функции
(c.*fp)(7); // вычисление суммы с 7
cout << "summation of 7 is " << c.*dp;
return 0;
}
Внутри функции main() программа создает два указателя на член: dp, указывающий на переменную sum, и fp, указывающий на функцию sum_it(). Обратим внимание на синтаксис каждого объявления. Для указания класса используется оператор области видимости. В программе также создается объект с класса myclass.
Далее программа получает адреса sum и sum_it(). Как указывалось ранее, эти адреса являются на самом деле смещениями в объекте myclass до членов sum и sum_it(). Далее программа использует функцию, на которую указывает fp, для вызова функции sum_it() объекта с. Дополнительные скобки необходимы для того, чтобы корректно ассоциировать оператор .*. Наконец, суммарная величина выводится на экран, для чего осуществляется доступ к члену sum объекта с с использованием dp.
При осуществлении доступа к члену объекта с использованием самого объекта или ссылки на него необходимо применять оператор .*. Однако, т. к. используется указатель на объект, то потребуется оператор —>*, как иллюстрирует следующая версия предыдущей программы:
#include <iostream.h>
class myclass {
public:
int sum;
void myclass::sum_it(int x);
};
void myclass::sum_it(int x) {
int i;
sum = 0;
for(i=x; i; i--) sum += i;
}
int main()
{
int myclass::*dp; // указатель на целочисленный член
void (myclass::*fp) (int x); // указатель на функцию-член
myclass *c, d; // с теперь указатель на объект
с = &d; // с получает адрес объекта
dp = &myclass::sum; // получение адреса данных
fp = &myclass::sum_it; // получение адреса функции
(c->*fp) (7); // использование ->* для вызова функции
cout << "summation of 7 is " << c->*dp; // использование ->*
return 0;
}
В той версии с является указателем на объект типа myclass, а оператор ->* используется для доступа к членам sum и sum_it().
20. Встраиваемые функции. Возвращаемое значение.
Операторы .* и —>* называются операторами-указателями на член. Они позволяют указывать на член класса, а не на конкретный экземпляр члена в каком-то объекте. Эти два оператора нужны постольку, поскольку указатель на член класса не определяет полностью адрес. Вместо этого он обеспечивает смещение до члена в классе. Поскольку указатели на член не являются истинными указателями в полном смысле этого слова, то обычные операторы . и —> не могут использоваться. Вместо этого применяются операторы .* и — >*.
Начнем с примера. Следующая программа осуществляет суммирование семи целых чисел. В ней доступ к функции surn_it() и переменной sum осуществляется с использованием указателей на член.
#include <iostream.h>
class myclass {
public:
int sum;
void myclass::sum_it(int x);
};
void myclass::sum_it(int x) {
int i;
sum = 0;
for(i=x; i; i--) sum += i;
}
int main()
{
int myclass::*dp; // указатель на целочисленный член
void (myclass::*fp) (int x); // указатель на функцию-член
myclass с;
dp = &myclass::sum; // получение адреса данных
fp = &myclass::sum_it; // получение адреса функции
(c.*fp)(7); // вычисление суммы с 7
cout << "summation of 7 is " << c.*dp;
return 0;
}
Внутри функции main() программа создает два указателя на член: dp, указывающий на переменную sum, и fp, указывающий на функцию sum_it(). Обратим внимание на синтаксис каждого объявления. Для указания класса используется оператор области видимости. В программе также создается объект с класса myclass.
Далее программа получает адреса sum и sum_it(). Как указывалось ранее, эти адреса являются на самом деле смещениями в объекте myclass до членов sum и sum_it(). Далее программа использует функцию, на которую указывает fp, для вызова функции sum_it() объекта с. Дополнительные скобки необходимы для того, чтобы корректно ассоциировать оператор .*. Наконец, суммарная величина выводится на экран, для чего осуществляется доступ к члену sum объекта с с использованием dp.
При осуществлении доступа к члену объекта с использованием самого объекта или ссылки на него необходимо применять оператор .*. Однако, т. к. используется указатель на объект, то потребуется оператор —>*, как иллюстрирует следующая версия предыдущей программы:
#include <iostream.h>
class myclass {
public:
int sum;
void myclass::sum_it(int x);
};
void myclass::sum_it(int x) {
int i;
sum = 0;
for(i=x; i; i--) sum += i;
}
int main()
{
int myclass::*dp; // указатель на целочисленный член
void (myclass::*fp) (int x); // указатель на функцию-член
myclass *c, d; // с теперь указатель на объект
с = &d; // с получает адрес объекта
dp = &myclass::sum; // получение адреса данных
fp = &myclass::sum_it; // получение адреса функции
(c->*fp) (7); // использование ->* для вызова функции
cout << "summation of 7 is " << c->*dp; // использование ->*
return 0;
}
В той версии с является указателем на объект типа myclass, а оператор ->* используется для доступа к членам sum и sum_it().
21. Спецификаторы и квалификаторы памяти.
Квалификатор (также классификатор, спецификатор, модификатор, описатель) константа — это переменная, которую обязательно инициализировать, и которая после этого не меняет своего значения.
Константа служит для защиты переменных от попытки изменить их значение. Константой переменную делает, использование перед типом данных, квалификатор const при инициализации этой переменной.
Общая форма объявления:
const тип имя_переменной = значение_константы;
Пример:
const int MONTHS = 12;
Например, переменная MONTHS, это количество месяцев в году. Оно, по определению, всегда будет 12. если в программе просто поставить число 12, то спустя какое то время, велика вероятность, что программист уже не вспомнит, что означает данное число в конкретном месте программы. По этому, константы позволяют также повысить удобочитаемость и информативность текста программы. Константы пришли в дополнение к макросу #define. По негласному соглашению имена макросов и констант пишутся в верхнем регистре.
Константы обязательно инициализировать, например:
const int foo = 10; /* можно */
const int bar; /* нельзя */
Это логично, поскольку, если мы не инициализируем ее сразу, то вообще никогда не сможем ничего ей присвоить, поэтому, в таком случае, она окажется бесполезной.
Преимущество констант перед #define заключается в следующем:
•позволяют явным образом определить тип данных;
•к ним можно применять правила обзора данных, чтобы ограничить описание для определённых функций или файлов;
•константами могут быть более сложные типы данных (составные), например массивы и структуры;
•константы могут использоваться для указания размера массива;
•имена констант можно использовать при отладке программы;
•использование #define ведёт к трудно уловимым ошибкам, связанными с не ожидаемым поведением макроподстановки.
Простой пример использования const:
int main()
{
const int Size = 10;
int array[Size] = {0};
for (int i = 0; i < Size; i++)
array[i] = i;
for (int i = 0; i < Size; i++)
cout << array[i] << " ";
return 0;
}
Также существует ещё ряд спецификаторов, подробности использования, которых хорошо описаны здесь[1]. Здесь они только коротко описаны.
Например спецификаторы классов хранения (памяти):
1.auto — используется всегда не явно компилятором (если не определено другое).
2.register — указывает, что переменная будет храниться в регистрах процессора.
3.static — определяет связывание переменной в файле.
4.extern — определяет, что переменная определена в другом файле.
5.mutable — применяется в контексте const. В некоторых случаях, если структура или класс объявлен как const, но требуется снять это ограничение с какой-то конкретной переменной.
cv-спецификаторы:
1.const — создаёт константу;
2.volatile — указывает на возможность изменения переменной из внешней среды.
Спецификаторы классов хранения и cv-спецификаторы являются носителями дополнительной информации о хранении переменной.
22. Автоматическая, статическая и динамическая продолжительность хранения переменных.
Статическая память Статическая память выделяется переменным на всё время выполнения программы. Метод прост и не требует никакой поддержки в ходе выполнения программы, так как адреса переменных в этом случае могут быть определены ещё на этапе компиляции программы. В языке Turbo Pascal нет явного упоминания о статической памяти, но фактически к ней можно отнести память, в которой размещаются константы и переменные, которые описаны на уровне главной программы. Пример программы с использованием статической памяти. program Static; var i: Integer; procedure Sub; var Cnt:integer; begin inc(Cnt); WriteLn('Cnt = ',Cnt) end; begin for i:=1 to 3 do Sub; end. В этой программе константа Cnt, а фактически инициализируемая переменная, не смотря на то, что является локальной в процедуре Sub, существует во время выполнения программы. При запуске программы её значение не теряется после выхода из процедуры Sub вплоть до следующего входа в неё.
Автоматическая память Автоматическая память характерна для языков с блочной структурой. В отличие от статической она позволяет использовать одни и те же участки основной памяти для размещения разных переменных из разных программных блоков. Дело в том, что память для локальных переменных блока, выделяется только на время его выполнения. Это повышает эффективность использования памяти, но требует некоторой поддержки управления памятью в ходе выполнения программы, что несколько снижает производительность. Оказалось, что снижение производительности можно свести к минимуму, если использовать для управления памятью принцип стека, но это приводит к вложенной организации блоков программы. Для примера рассмотрим два варианта построения программы решения одной и той же задачи: Найти произведение сумм элементов массива. program Prgm1; const m = 10000; var a: array[1..m] of Integer; b: array[1..m] of Real; i,Sa: Integer; Sb: Real; begin { Ввод массивов a и b } Sa:=0; Sb:=0; for i:=1 to m do Sa:=Sa+a[i]; for i:=1 to m do Sb:=Sb+b[i]; WriteLn(Sb*Sa); end. program Prgm2; const m = 10000; var Sa: Integer; Sb: Real; procedure SumA; var a: array[1..m] of Integer; i: Integer; begin { Ввод массива a } for i:=1 to m do Sa:=Sa+a[i]; end; procedure SumB; var b: array[1..m] of Real; i: Integer; begin { Ввод массива b } for i:=1 to m do Sb:=Sb+b[i]; end; begin Sa:=0; Sb:=0; SumA; SumB; WriteLn(Sb*Sa); end. Не смотря на то, что это абстрактные программы, они обе формально правильные и можно попытаться их выполнить. При попытке выполнить первую программу мы получим сообщение об ошибке компиляции "Error 96". Причина ошибки заключается в том, что общий объём памяти, который выделяется переменным уровня главной программы не должен превышать 64 KB. Учитывая, что переменная типа Integer занимает 2 байта, а типа Real - 6 байтов, то для нашей программы мы получим оценку 10000*(6+2) B = 80000 B = (80000 / 1024) KB = 78.2 KB, что превышает имеющиеся возможности. Попытка выполнить вторую программу тоже приводит к сообщению об ошибке компиляции - "Error 202" (переполнение стека). Так как массивы находятся в разных процедурных блоках программы, а они вызываются последовательно, то это означает, что массивы последовательно используют одну и ту же память в стеке. Оценка необходимого объёма памяти в этом случае составляет 6*10000 B = 58.6 KB - размер большего массива. Причина ошибки состоит в том, что по умолчанию размер стека составляет всего 16 KB, но, к счастью, его можно увеличить до значения 65 520 B, что составляет почти 64 KB. Для этого в интегрированной среде надо выбрать Options | Memory sizes и установить желаемый размер стека. После этого вторая программа будет выполняться без ошибок.
Динамическая память Динамической называется переменная, память для которой выделяется во время работы программы. У динамической переменной нет имени, - к ней можно обратиться только при помощи специальной переменной, - переменной-указателя. Переменная-указатель – переменная целого типа – это адрес байта памяти, содержащей другое данное (переменную, константу, адрес другой переменной и т.п.). Любой ссылочный (адресный) тип данных определяет множество значений, которые являются указателями (ссылками) на значения какого-либо другого типа данных. Указатели и динамические переменные позволяют создавать сложные динамические структуры данных, такие как связанные списки и деревья. Указателю можно присваивать значение указателя того же типа, константу NIL (пустой указатель) или адрес объекта, определенный с помощью стандартных функций модуля System - Addr (ИмяПеременной) (оператора @ИмяПереиенной) и Ptr(СегментнаяЧастьАдреса, Смещение). Сегмент данных — это непрерывная область оперативной памяти с объемом в 65 536 байт (64 Кбайт). Динамические переменные могут размещаться в памяти компьютера и убираться из нее в процессе работы программы. Так, например, если введенные динамические переменные уже обработаны и до конца программы использоваться не будут, то их можно убрать из памяти компьютера, а на освободившемся месте разместить другие динамические переменные, необходимые по ходу выполнения решаемой задачи. Указанное свойство таких переменных весьма полезно при обработке крупных массивов данных. Область памяти, в которой размещаются динамические переменные, называется кучей (heap), максимальный ее объем более чем в 6 раз превышает объем сегмента данных и составляет около 400 Кбайт. Это не означает, что отдельные переменные (запись или массив) могут иметь такой большой размер. Конечно же, нет: ни одна переменная в Turbo Pascal не может превышать объем 65 520 байт. Однако распределить составляющие записи или массива по различным сегментам памяти оказывается вполне возможным. При этом общий объем «распределенной» переменной может существенно превысить объем отдельного сегмента. Распределение переменной по разным сегментам кучи особенно полезно, когда ее объем заранее предсказать нельзя. Рекомендуется применять динамические переменные если: 1. Необходимы переменные, имеющие большой объем и освобождающие память после их использования. 2. Размер переменной трудно предсказуем. 3. Размер переменной превышает 64 Кбайт.
23. Внутренние и внешние связывание. Область видимости переменных.
Связывание описывает экстент (протяжение, пространство), в пределах которого переменная, определенная в одной части программы, может быть привязана к любой другой части программы. Переменная с областью видимости в пределах блока, будучи локальной, не имеет связывания. Переменная с областью видимости в пределах файла имеет внутреннее или внешнее связывание. Внутреннее связывание означает, что переменная может быть использована в файле, содержащем ееопределение. Внешнее связывание означает, что переменная может быть использована в других файлах.
Память, использованная для хранения данных, которыми манипулирует программа, может быть охарактеризована продолжительностью хранения, областью видимости и связыванием. Продолжительность хранения может быть статической, автоматической или распределенной. Если продолжительность хранения статическая, память распределяется в начале выполнения программы и остается занятой на протяжении всего выполнения. Если продолжительность хранения автоматическая, то память под переменную выделяется в момент, когда выполнение программы входит в блок, в котором эта переменная определена, и освобождается, когда выполнение программы покидает этот блок. Область видимости определяет, какая часть программы может получить доступ к данным. Переменные, определенные вне пределов функции, имеют область видимости в пределах файла и видимы в любой функции, определенной после объявления этой переменной. Переменная, определенная в блоке или как параметр функции, видима только в этом блоке и в любом из блоков, вложенных в этот блок.
24. Перегрузка функции.
(полиморфизм функций, совмещение имён) — позволяет программисту определять несколько функций с одним и тем же именем (интерфейсом). Перегрузка в языке Си++ является практической реализацией принципа полиморфизма времени компиляции. Перегрузка функций подразумевает использование одного и того же имени функции при разных аргументах. То есть, главным способом различия функций с одинаковыми именами является задание аргументов разного типа и количества. Имена переменных (аргументов функции) не имеют значения. Общий вид перегрузки функций:
Пример перегрузки функции sqr() 4-и раза:
2 Классы, объекты и инкапсуляция
Дата: 2019-03-05, просмотров: 340.