Структурированный тип данных
Это данные, определяющие упорядоченную совокупность скалярных переменных (char, int, float, double, …) и характеризуемые типом своих компонент.
К ним относят: массивы, структуры, объединения, указатели, динамические структуры (стеки, очереди, списки), классы.
Остановимся на массивах.
Массивы
Массив — это составной, структурированный тип данных одного заранее определенного типа, который имеет следующие характеристики:
* элементы массива имеют одинаковый тип (в отличие от структур), поэтому каждый элемент массива занимает одинаковый объём памяти;
* массив располагается в оперативной памяти (в отличие от файлов);
* элементы массива упорядочены и занимают подряд идущие ячейки (в отличие от динамических структур: стеков, очередей, списков).
По своей структуре массивы данных могут быть одномерными (векторами размера 1*n или n*1), двухмерными (матрицами размера n*m) или многомерными (размера n*m*p...).
С точки зрения времени распределения памяти под массив они делятся на статические и динамические.
Если память под массив выделяется на этапе компиляции текста программы, то такие массивы называются статическими. Статические массивы всегда имеют фиксированный размер. Память для динамического массива выделяется во время выполнения программы, и если массив не нужен, память для него можно освободить.
Для имени массива может быть использована переменная, состоящая из символов (буквы) латинского алфавита с цифрами и знаком подчеркивания и т.д. в соответствии с правилами написания имен идентификаторов, принятых в языке С/С++.
Доступ к элементам массива в языке С/С++ осуществляется двумя способами.
1) С помощью порядкового номера элемента массива, который называется индексом. В качестве индекса можно использовать выражение целого или совместимого с ним типа, в том числе константу или переменную.
Замечание. В качестве индекса нельзя использовать выражение вещественного типа.
2) С помощью указателя (адреса) на первый элемент массива, т. к. в С/С++ существует связь между массивами и указателями.
Основные действия с массивами
I . Инициализация массива.
1) Ввод элементов массива с клавиатуры (см. выше) или с заранее подготовленного файла.
2) Задание значения элементов массива можно (проинициализировать) на этапе его описания:
<тип> <имя_массива> [размер]={список значений};
где в фигурных скобках записываются значения элементов массива соответствующего типа, разделённые запятыми. Например:
const N=5;
float A[N]={-1.1, 22, 3, -4.4, 50};
Замечание. Если в списке меньше N значений, то недостающие элементы массива примут нулевое значение. Наоборот, если указать больше N значений, “компилятору это не понравится”.
в) Ввод массива символов (или строку) можно выполнить по-разному.
* Можно указать размерность, достаточную для размещения текста и символа конца строки (‘\0’). Этот символ надо явно записать в конце списка, например:
char T[11]={‘м’,’а’,’т’,’е’,’м’,’а’,’т’,’и’,’к’,’а’,’\0’};
* Второй способ проще и удобнее: char T[11]=“математика”;
В этом случае нулевой символ добавляется к концу строки автоматически. Кроме того, как для числовых, так и для символьных массивов необязательно указывать размерность. Она будет определена в зависимости от количества записанных элементов или длины строки. Например,
int V[]={11, 2, -3, 44, -5}; //объявляет и инициализирует целочисленный массив из пяти элементов,
сhar S[]=”ВМФ”; // строку из четырёх символов, так как добавлен символ конца строки.
Указанный способ определения массива удобен для отладки программы, так как не надо тратить время на многократный ввод его элементов. При тестировании достаточно изменить несколько элементов массива.
г) Задание значения элементов массива с помощью генератора случайных чисел:
const n=5;
int Y[n];
randomize(); //srand(time(0));
for (int i=0; i<n; i++)
{ Y[i]=random(100); //Y[i]=rand()%100;
cout <<Y[i]<<" ";
}
Функция randomize () ( или srand( time (0)) ) – генерирует новую последовательность случайных чисел, которая может использоваться для функции random () ( rand () ). (рекомендуют использовать, чтобы массив был «более случайным», в противном случае массив может быть таким же, каким был при предыдущем выполнении программы).
Параметр функции random (в нашем примере 100) ( или rand()%100 ) означает, что числа массива будут целыми на промежутке от 0 до 99 включительно. Если надо, чтобы числа были не только положительными, можно записать, например, так: Y[j]=random(100)-50; или Y [ i ]= -50+ rand ()%100; Тогда числа будут на промежутке от –50 до 49.
Если надо получить вещественные числа, можно в цикле записать, например, так: A[i]=random(5)/10.-0.25; При этом массив A объявляется как float , а константу 10 надо записать обязательно с символом «.», то есть как вещественное число. Иначе получатся все одинаковые числа (-0.25), так как при делении любого целого числа, меньшего 5, на целое число 10 получится целая часть результата, то есть нуль.
д) Задание массива по некоторому правилу (закону), например:
for ( int j=0; j<n; j++)
if (j%2) A[j]= j*10;
else A [ j ]= j /100.;
II . Вывод матриц.
а) Простой вывод в виде таблицы можно выполнить, используя два цикла for для вывода элементов первой строки, затем второй и т.д.
Кроме этого можно предложить следующий вариант вывода:
cout <<”\n”;
for ( i=0; i<n; i++)
{ printf("\n"); // Переход на новую строку экрана.
for ( j =0; j < m ; j ++)
printf ("%5 d ", A [ i ][ j ]);
}
При таком выводе числа столбцов будут выровнены благодаря наличию формата %5d, т. е. независимо от размерности чисел они будут выводиться друг под другом. Напомним, что для вещественных чисел необходимо указать, например, формат %7.2f. В этом фрагменте важно место оператора printf ("\n"). Если символ “\n” записать во внутреннем цикле (printf ("\n%5d", A[i][j])), то в каждой строке экрана будет выводиться по одному числу. Необходимо также обратить внимание на расстановку фигурных скобок.
Иногда для наглядности целесообразно элементы матрицы в зависимости от условия выводить разным цветом. Например, положительные числа вывести цветом C1 на фоне C2, а отрицательные и нулевые — наоборот, цветом С2 на фоне С1, где С1 и С2 — целые числа, определяющие цвет. Это реализуется, например, следующим образом:
void MyColors ( int C 1, int C 2)//пользовательская функция для задания цвета
{ textcolor(C1);
textbackground (C2); }
void main()
{ textbackground(3); clrscr(); // Очищает и закрашивает экран
const n=4,m=6; float A[n][m];
// Пример формирования вещественной матрицы
// случайным образом
randomize();
for ( int i=0; i<n; i++)
for ( int j=0; j<m; j++)
A[i][j]=(random(50)-40)/100. + random(5);
for ( int i=0; i<n; i++)
{ cout<<endl; // Переход на новую строку экрана.
for ( int j=0; j<m; j++)
{ if (A[i][j]>0) MyColors(2,15); // Изменение цветов
else MyColors(15,2);
cprintf ("%7.2f", A[i][j]);
}
} getch();
}
Типы алгоритмов на обработку матриц (двухмерных массивов)
Ввиду многообразия задач по рассматриваемой теме сделана попытка классификации некоторых простых матричных задач.
Построчная обработка
К такому типу относятся задачи, в которых для каждой строки матрицы требуется найти её некоторый параметр. Таким параметром может быть, например, сумма, количество всех элементов строки или элементов с некоторым условием, наименьший (наибольший) элемент среди всех или части элементов строки и т. д. К этому классу можно отнести и задачи типа “есть ли нуль в строке матрицы?”. Их особенность в том, что не обязательно надо анализировать все элементы строки.
В таких программах внешний цикл строится по номеру строки, а в одном или нескольких внутренних циклах обрабатывается строка как одномерный массив. При этом полученные характеристики строк можно запоминать в одномерном массиве размерности n или выводить сразу по мере получения.
Обработка всей матрицы
Это задачи, в которых выполняется анализ матрицы не отдельно для каждой строки или столбца, а для всей матрицы в целом. В таких алгоритмах можно обрабатывать её как по строкам, так и по столбцам. Внешний цикл отвечает за перебор строк, а внутренний —столбцов.
Найдём наибольший элемент во всей матрице и номер строки и столбца, на пересечении которых он находится:
int MyMax, Imax, Jmax;
MyMax =A[0][0]; Imax=Jmax=0;
for (int i=0; i<n; i++)
for (int j=0; j<m; j++)
if ( A[i][j]>MyMax)
{ MyMax= A[i][j];
Imax=i;
Jmax =j; }
printf (" \n Максимум = %d в %d строке , %d столбце ", MyMax,Imax, Jmax);
Обратим внимание, что операторы MyMax=A [0][0];Imax=Jmax=0; располагаются вне всех циклов, так как мы находим общий наибольший элемент, т. е. одно число, а не для каждой строки или столбца отдельно.
Обработка части матрицы
Выделим некоторые подтипы таких задач.
Обработка элементов главной или побочной диагонали квадратной матрицы, объявленной, например, так: const n=5; int A[n][n]; Структура циклов останется такой же, как при решении аналогичной задачи для одномерного массива. Например, найти среднее арифметическое элементов главной диагонали, т.к. для элементов главной диагонали оба индекса одинаковы, то это можно обойтись одним циклом:
float Sum=0;
for (int i=0; i<n; i++)
Sum+=A[i][i];
Sum/=n;
Для обработки побочной диагонали, как и при решении некоторых других типов задач, необходимо найти зависимость второго индекса от первого. Легко видеть, что сумма индексов равна n-1, поэтому второй индекс для элемента побочной диагонали будет равен n-1-i, и соответствующая часть программы будет такой:
float Sum=0;
for (int i=0; i<n; i++)
Sum+=A[i][ n-1-i];
Sum/=n;
Обработка верхнего треугольника квадратной матрицы относительно главной диагонали — это те элементы, у которых i <j, если главная диагональ не включается, или i <=j, если включается. Аналогично определяется нижний треугольник относительно главной диагонали и треугольники относительно побочной диагонали.
Для обработки таких треугольников необходимо определить, как изменяются индексы. Анализируя, например, верхний треугольник, можно видеть, что в нулевой строке j изменяется от 0 до n-1, в первой строке — от 1 до n-1, во второй строке — от 2 до n-1 и так далее. Значит, в произвольной i-й строке индекс j изменяется от i до n-1. Поэтому, например, подсчёт количества нулевых элементов верхнего треугольника, включая и главную диагональ, будет выглядеть следующим образом:
int K=0;//количество нулей в верхнем треугольнике
for (int i=0; i<n; i++)
for (int j=i; j< n; j++)
if (A[i][j] ==0) K++;
5. Преобразование матрицы
Выделим некоторые подтипы таких задач.
Перестановка двух строк, номера n1 и n2 которых заданы, выполняется следующим образом. Составим функцию для перестановки двух целых чисел:
void RR( int &x, int &y)
{ int t; t=x; x=y; y=t;}
В другой функции или в main выполняем поэлементную перестановку каждой пары элементов:
for (int j=0; j<m; j++)
RR( A[n1][ j] , A[n2][j]);
В качестве упражнения с помощью той же функции выполните перестановку m1–го и m2–го столбцов, если m1 и m2 заданы.
Удаление k–й строки, где k известно, выполняется так:
for (int i=k; i<n-1; i++)
for (int j=0; j<m; j++)
A[i][j]=A[i+1][j];
Здесь на место k–й строки помещаем каждый элемент (k+1)–й строки, на место (k+1)–й — (к+2)–ю строку и так далее. Наконец, на место (n-2)–й копируем (n-1)–ю строку. Таким образом, все строки, начиная с (к+1)–й, “поднимаем на одну вверх”. При этом объём зарезервированной памяти для матрицы не изменяется. По-прежнему в памяти находится n строк, то есть физически ни одну строку из памяти мы не удаляли. Но после удаления одной строки количество обрабатываемых строк на одну уменьшается. Последняя строка в обработке уже не должна участвовать.
Для вставки одной строки после к-й на первом этапе необходимо все строки с (n-1)–й до (к+1) в обратном порядке “опустить вниз”:
for (int i=n-2; i>=k+1; i - -)
for (int j=0; j<m; j++)
A[i+1][j]=A[i][j];
Затем на место освободившейся (k+1)–й строки надо поместить вставляемую строку, например, одномерный массив B такой же размерности m, что и строка матрицы:
for (int j=0; j<m; j++)
A[k+1][j]=B[j];
При объявлении матрицы необходимо учесть, что после вставки количество строк увеличится. Поэтому если по условию вставляется одна строка, то объявляем так: int A[n+1][m]. Если после каждой строки с некоторым условием (например, в строке больше половины нулей) надо вставить новую строку, то матрицу надо объявить так: int A[2*n][m]. В этом случае резервируется максимальный объём памяти в предположении, что после каждой строки надо вставлять новую. Реально такой вариант будет маловероятным и память будет использоваться неэффективно.
Похожая проблема с памятью имеет место и при удалении строк. Более того, если перестановку, удаление или вставку строк надо выполнять несколько раз, то для больших матриц может возникнуть проблема и с временем выполнения программы. Поэтому
на практике такое преобразование эффективнее выполнять с помощью динамических матриц или списков (2–й семестр).
Построение матриц
Выделим некоторые подтипы таких задач.
Элементы новой матрицы зависят от своих же индексов.
Элементы матрицы используют одно число.
Построение матрицы на одном или нескольких одномерных или двухмерных массивах.
Передача параметров
Формальные параметры, которые используются при описании заголовка функции, могут быть двух видов: параметры-значения и параметры-переменные. Использование параметров-значений или параметров-переменных влияет на тип передачи данных из программы в функцию и наоборот.
1) Параметры-значения используются в тех случаях, когда функция получает некоторые параметры, но после действия функции, их не возвращает. Такие параметры имеют след. особенности:
* для фактического и формального параметров компилятор отводит разные ячейки памяти;
* при выполнении программы содержимое фактического параметра копируется в формальный параметр, то есть при первом вызове LINE 2 ( 20 , 5 , '*'); Len=20, y=5 и ch= ’*’ , хотя это явно нигде не записывается;
* из первой особенности следует, что если в функции изменить формальный параметр, то это не повлияет на значение переменной, используемой при вызове, то есть фактического параметра. Если бы в функции изменили y (например, там было бы записано y++ ), то значение соответствующей переменной Y в головной функции после второго вызова осталось бы без изменения, т. е. тем, что ввели;
* в качестве фактического параметра, соответствующего параметру-значению может быть выражение соответствующего или совместимого типа. Например, функцию можно вызвать так: LINE2 ( LEN*2, Y+1, ‘*’). Как частный случай можно передавать константу: LINE 2 ( 20 , 5 , '*'); или переменную LINE 2( LEN , Y , C ); При этом её имя, используемое при вызове, не обязательно должно отличаться, как в нашем примере, от имени формального параметра. В головной программе переменную для фактической длины символов можно было бы тоже назвать Len. Но и в этом случае это разные ячейки памяти.
2) Формальные параметры-переменные используются в тех случаях, когда функция получает некоторые параметры, но после действия функции, эти параметры необходимо вернуть в вызывающую функцию, например main ().
Передачу данных из пользовательской функции в программу можно двумя способами: через ссылочный тип или через указатели.
Рассмотрим ссылочный тип. Ссылочный тип используется следующим образом:
* в заголовке функции параметры записываются как параметры-переменные ссылочного типа, то есть с символом &, например, void SINCOS(float x, float eps, float &y, float &z);
* в теле функции никакие дополнительные символы для этих переменных не используются, то есть работают, как с обычными переменными;
* при вызове функции в качестве фактических параметров, указывают простые переменные соответствующего типа объявленные обычным образом, например, SINCOS(Х, Е, Y , Z );
* входные параметры как параметры-значения (х, eps ) используются по тем же правилам;
Замечание. С помощью ссылочного типа для формального (y) и фактического (Y) параметров отводится одна и та же ячейка памяти, которая в пользовательской функции называется y, а при вызове в вызывающей функции main () - Y. Поэтому все изменения параметра y сказываются на изменении параметра Y. Таким образом, происходит передача значения параметра из пользовательской функции в основную (вызывающую) функцию.
Например. Для x=-0.8, -0.6, -0.4, … , 0.8 найти и вывести на экран значения функций:
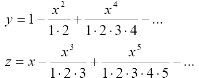
в виде следующих пяти столбцов: x , y, cos(x), z, sin(x), в которых показать значения указанных тригонометрических функций, вычисленные как сумма бесконечного ряда с заданной точностью, так и с помощью встроенных функций.
Для решения задачи составим функцию SINCOS, которая вычисляет обе бесконечные суммы с произвольной одинаковой точностью. Поэтому она имеет два входных параметра: аргумент функций (x) и одинаковую точность вычисления бесконечных сумм (eps) и два выходных (y и z), которые в заголовке функции объявляются с помощью ссылочного типа.
void SINCOS(float x, float eps, float &y, float &z);
void main()
{
float x, sn, cs;
cout <<" x y=cos(x) Cos(Standart) z=sin(x) Sin(Standart)";
cout <<”\n\n”;
for (x=-0.8; x<0.805; x+=0.2)
{ SINCOS(x,1E-10, cs, sn);
printf ("%5.1f %10.6f %12.6f %10.6f %12.6f\n", x, cs, cos(x), sn, sin(x)) ;
}
getch ();
}
// пользовательская функция
void SINCOS(float x, float eps, float &y, float &z)
{ float k=1, s1=1; y=1;
do
{s1=s1*(-1)*x*x/(k*(k+1));
y+=s1;
k+=2;
}
while (fabs(v1)>eps);
k=2; s1=x; z=x;
do
{ s1=s1*(-1)*x*x/(k*(k+1));
z+=s1;
k+=2;
}
while (fabs(v1)>eps);
}
Структуры
Все переменные, которые мы использовали до настоящего времени, относились к одному определенному типу, они были или символьными (char), или строковыми (char St[15]), или целочисленными (int), или с плавающей точкой (float). Даже массивы независимо от их размерности содержали переменные только одного типа. Все встречавшиеся нам переменные были простыми, то есть такими переменными, значения которым присваиваются путем простого использования имени переменной в инструкциях ввода данных или присваи-
вания.
Сейчас рассмотрим еще один структурированный тип данных: структуры.
Структурой называется переменная, представляющая собой множество других, логически связанных, переменных, относящихся к различным типам.
В структуре могут быть собраны различные объекты – переменные, массивы, указатели, другие структуры и т.д., которые для удобства работы с ними сгруппированы под одним именем.
Формат описания структуры имеет вид:
struct [ имя_типа_структуры ]
{
//Описание_элементов
<тип_1> < элемент_1 >;
<тип_2> < элемент_2 > ;
…………………….
<тип_п> <элемент_п>;
} [список переменных];
где
struct – служебное слово;
[имя_типа_структуры] – имя нового пользовательского типа;
<тип_1>…<тип_п> - известные типы данных;
<элемент_1> …<элемент_п> - идентификаторы, называемые полями структуры;
[список переменных] – список переменных имеющих тип данной структуры.
Например:
1) создать новый тип данных с именем CD, который содержит пять элементов информации: три строки, одно значение типа float и одно целочисленное значение.
struct CD
{
char name[20]; // имя диска
char description[40]; // описание
char category[12]; // категория
float cost; // цена
int number; // номер
};
……………
CD disc[10]; // массив из 10-ти дисков
……………
Размер области памяти для структуры равен 78 байт (это можно определить при помощи функции sizeof(CD) ), а для disk [10] равен 780 байт.
Данную структуру можно использовать для создания картотеки CD дисков.
2) создать новый тип данных для работы с комплексными числами:
struct complex
{
float x, y;
} z1,z2,z3;
3) создать новый тип данных для создания базы данных по автомобилям и массив из 100 автомобилей:
struct TAuto
{
char FIO [20]; //фам., имя, отч. владельца
char Adres [40]; //адрес владельца
char Marka [25]; //марка авто
char Number [10]; //номер авто
float V ; //объем двигателя
};
……………
TAuto auto[100];
……………
4) создать новый тип данных для использования в динамических структурах: стеках, очередях и списках:
struct pointer
{
int Data ; //поле данных динамической структуры
pointer *next; //поле указателя
};
…….
pointer ph , pk ; //указатели на вершину, конец дин. структуры
…….
5) создать новый тип данных для хранения данных о человеке:
struct { char Name [20]; // Имя char Surname [20]; // Фамилия int age ; // возраст char adres ; // адрес char passport [11]; //данные паспорта } Man, Female ;
Работа со структурами
1) Инициализация полей структуры. Если начальные значения полей структуры известны, то их можно задать при описании структуры:
struct
{
char fio[30];
int date, code;
double salary;
}worker = {" Страусенко " , 31 , 215 , 34.55};
struct complex
{
float x , y ;
} Z [2][3] = {
{{1, 1}, {1, 1}, {1, 1}}, // строка 1. TO есть массив Z [0]
{{2, 2}, {2, 2}, {2, 2}} // строка 2. то есть массив Z [1]
} ;
2) Доступ к полям структуры. Доступ к элементам (компонентам, полям) структуры осуществляется двумя способами:
* с помощью оператора связывающей точки (оператора точки) "." при непосредственной работе со структурой;
* при использовании указателей на структуры с помощью стрелки "–>".
Общий формат доступа к элементам структуры имеет следующий вид:
<имя_переменной_структуры>.<имя_поля>; <имя_указателя_на_структуру>–><имя_поля>;
<*имя_указателя_на_структуру>.<имя_поля>;
Например:
* printf(“Введите данные первого диска:);
printf(“Наименование-->”);
scanf(“%s”,&disk[0].name);
printf(“Описание-->”);
scanf(“%s”,&disk[0].description);
…………
printf(“Стоимость-->”);
scanf(“%f”,&disk[0].coast);
………..
* printf();
scanf();
Структурированный тип данных
Это данные, определяющие упорядоченную совокупность скалярных переменных (char, int, float, double, …) и характеризуемые типом своих компонент.
К ним относят: массивы, структуры, объединения, указатели, динамические структуры (стеки, очереди, списки), классы.
Остановимся на массивах.
Массивы
Массив — это составной, структурированный тип данных одного заранее определенного типа, который имеет следующие характеристики:
* элементы массива имеют одинаковый тип (в отличие от структур), поэтому каждый элемент массива занимает одинаковый объём памяти;
* массив располагается в оперативной памяти (в отличие от файлов);
* элементы массива упорядочены и занимают подряд идущие ячейки (в отличие от динамических структур: стеков, очередей, списков).
По своей структуре массивы данных могут быть одномерными (векторами размера 1*n или n*1), двухмерными (матрицами размера n*m) или многомерными (размера n*m*p...).
С точки зрения времени распределения памяти под массив они делятся на статические и динамические.
Если память под массив выделяется на этапе компиляции текста программы, то такие массивы называются статическими. Статические массивы всегда имеют фиксированный размер. Память для динамического массива выделяется во время выполнения программы, и если массив не нужен, память для него можно освободить.
Для имени массива может быть использована переменная, состоящая из символов (буквы) латинского алфавита с цифрами и знаком подчеркивания и т.д. в соответствии с правилами написания имен идентификаторов, принятых в языке С/С++.
Доступ к элементам массива в языке С/С++ осуществляется двумя способами.
1) С помощью порядкового номера элемента массива, который называется индексом. В качестве индекса можно использовать выражение целого или совместимого с ним типа, в том числе константу или переменную.
Замечание. В качестве индекса нельзя использовать выражение вещественного типа.
2) С помощью указателя (адреса) на первый элемент массива, т. к. в С/С++ существует связь между массивами и указателями.
Дата: 2018-12-28, просмотров: 413.