Немного истории
Язык программирования С был разработал вначале 70-х годов Денисом Ритчи, сотрудником компании Bell Laboratories, который занимался разработкой операционной системы (ОС) UNIX. Для выполнения данной работы ему необходим был язык программирования, который отличался краткостью и эффективностью по управлению аппаратными средствами компьютера. Язык программирования ассемблер для этих целей не подходил, так как он привязан к конкретному типу процессора и перенос программы с одного компьютера на другой сопровождается дополнительной работой.
Язык программирования С++ был разработан в начале 80-х годов сотрудником компании Bell Laboratories Бьярни Страуструпом. Его основная цель заключалась в том, чтобы программистам было легче и приятнее писать хорошие программы, и при этом не приходилось программировать на ассемблере [ Bjarne Stroustrup. The C++ Programming Language. Third Edition. Reading, MA: Addision-Wesley Publishing Company. 1997 ].
Состав алгоритмического языка С/С++
В тексте на любом естественном языке можно выделить четыре основных элемента:
символы, слова, словосочетания и предложения.
Подобные элементы содержит и алгоритмический язык С/C++, только здесь:
* слова – это лексемы (элементарные конструкции),
* словосочетания – это выражения,
* предложения – это операторы.
Причем лексемы образуются из символов, выражения – из лексем и символов, а операторы – из символов, выражений и лексем (рис. 1.1):
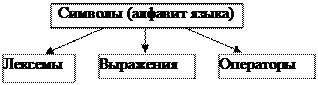 |
Рис. 1.1. Состав алгоритмического языка.
На рисунке 1.1:
* Алфавит языка, или его символы – это основные неделимые знаки, с помощью которых пишутся все тексты на языке.
* Лексема (элементарная конструкция) – это неделимая последовательность знаков алфавита (символов), имеющая самостоятельный смысл.
* Выражение – это совокупность символов и лексем, которая задает правило вычисления некоторого значения.
* Оператор – это совокупность символов, лексем и выражений, которая задает законченное описание некоторого действия.
Для описания сложного действия требуется последовательность операторов. Операторы могут быть объединены в составной оператор, или блок (последовательность операторов заключенная в фигурные скобки: {} ). В этом случае они рассматриваются как один оператор. Операторы бывают исполняемые и неисполняемые. Исполняемые операторы задают действия над данными. Неисполняемые операторы служат для описания данных, поэтому их часто называют операторами описания или просто описаниями.
Объединенная единым алгоритмом совокупность описаний и операторов образует программу на алгоритмическом языке. Для того чтобы выполнить программу, требуется перевести ее на язык, понятный процессору — в машинные коды. Этот процесс, как правило, состоит из нескольких этапов и называется компиляцией.
Алфавит языка
Алфавит C++ включает:
• прописные и строчные латинские буквы и знак подчеркивания;
• арабские цифры от 0 до 9;
• специальные знаки: " { } , i [ ] ( ) + - / % * . \ ? < = > ! & # - ; ' '
• пробельные символы: пробел, символы табуляции, символы перехода на новую строку.
Из символов алфавита формируются лексемы языка, к которым относят:
• идентификаторы;
• ключевые (зарезервированные) слова;
• знаки операций;
• константы;
• разделители (скобки, точка, запятая, пробельные символы).
Границы лексем определяются другими лексемами, такими, как разделители или знаки операций.
Идентификаторы
Идентификатор — это имя программного объекта. В идентификаторе могут использоваться латинские буквы, цифры и знак подчеркивания. Прописные и строчные буквы различаются, например, sysop, SySoP и SYSOP — три различных имени.
СОВЕТ
Для улучшения читаемости программы следует давать объектам осмысленные имена. Существует соглашение о правилах создания имен, называемое венгерской нотацией (поскольку предложил ее сотрудник компании Microsoft венгр по национальности), по которому каждое слово, составляющее идентификатор, начинается с прописной буквы, а вначале ставится префикс, соответствующий типу величины, например, iMaxLength, IpfnSetFirstDialog. Другая традиция — разделять слова, составляющие имя, знаками подчеркивания: maxjength, number_of_galosh.
При выборе идентификатора необходимо иметь в виду следующее:
* длина идентификатора по стандарту не ограничена, но некоторые компиляторы и компоновщики налагают на нее ограничения;
* идентификатор создается на этапе объявления переменной, функции, типа и т. п., после этого его можно использовать в последующих операторах программы;
* идентификатор не должен совпадать с ключевыми словами (см. следующий раздел) и именами используемых стандартных объектов языка;
* не рекомендуется начинать идентификаторы с символа подчеркивания, поскольку они могут совпасть с именами системных функций или переменных, и, кроме того, это снижает мобильность программы;
* на идентификаторы, используемые для определения внешних переменных, налагаются ограничения компоновщика (использование различных компоновщиков или версий компоновщика накладывает разные требования на имена внешних переменных).
* между двумя идентификаторами должен быть хотя бы один разделительный символ (пробел, знак операции и т.п.);
* первым символом идентификатора может быть буква или знак подчеркивания, но не цифра. Пробелы внутри имен не допускаются.
Ключевые слова
Ключевые слова — это зарезервированные идентификаторы, которые имеют специальное значение для компилятора. Их можно использовать только в том смысле, в котором они определены разработчиками языка программирования.
Список ключевых слов C++ приведен ниже.
asm auto bool break case catch char class const const_cast continue default delete do double dynamic_cast else enum explicit export extern false float for friend goto if inline int long mutable namespace new operator private protected public register reinterpret_cast return short signed sizeof static static__cast struct switch template this throw true try typedef typeid typename union unsigned using virtual void volatile wchar_t while.
Знаки операций
Знак операции — это один или более символов, определяющих действие над операндами.
Внутри знака операции пробелы не допускаются. Операции делятся на унарные, бинарные и тернарную по количеству участвующих в них операндов.
Один и тот же знак может интерпретироваться по-разному в зависимости от контекста. Все знаки операций за исключением [ ], ( ) и ? : представляют собой отдельные лексемы.
Константы
Константами называют элементы данных, значения которых установлены в описательной части программы и в процессе выполнения программы не изменяются. Различаются целые, вещественные, символьные и строковые константы. Компилятор, выделив константу в качестве лексемы, относит ее к одному из типов по ее внешнему виду.
Форматы констант, соответствующие каждому типу, приведены в табл. 1.2.
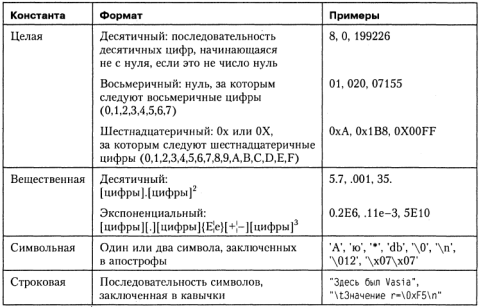 Таблица 1.2. Константы в языке C++
Таблица 1.2. Константы в языке C++
Если требуется сформировать отрицательную целую или вещественную константу, то перед константой ставится знак унарной операции изменения знака (-), например: -218, -022, -ОхЗС, -4.8, -0.1е4.
Вещественная константа в экспоненциальном формате представляется в виде мантиссы и порядка. Мантисса записывается слева от знака экспоненты (Е или е), порядок— справа от знака.
Символьные константы, состоящие из одного символа, занимают в памяти один байт и имеют стандартный тип char. Двухсимвольные константы занимают два байта и имеют тип int, при этом первый символ размещается в байте с меньшим адресом (о типах данных рассказывается в следующем разделе).
Символ обратной косой черты используется для представления:
• кодов, не имеющих графического изображения (например, \а — звуковой сигнал, \n — перевод курсора в начало следующей строки);
• символов апострофа ( ' ) , обратной косой черты ( \ ), знака вопроса ( ? ) и кавычки
( " );
• любого символа с помощью его шестнадцатеричного или восьмеричного кода, например, \073, 0xF5.
Числовое значение должно находиться в диапазоне от 0 до 255.
Последовательности символов, начинающиеся с обратной косой черты, называют управляющими, или escape-Последовательностями. В таблице 1.3 приведены их допустимые значения. Управляющая последовательность интерпретируется как одиночный символ.
Если в последовательности цифр встречается недопустимая, она считается концом цифрового кода.
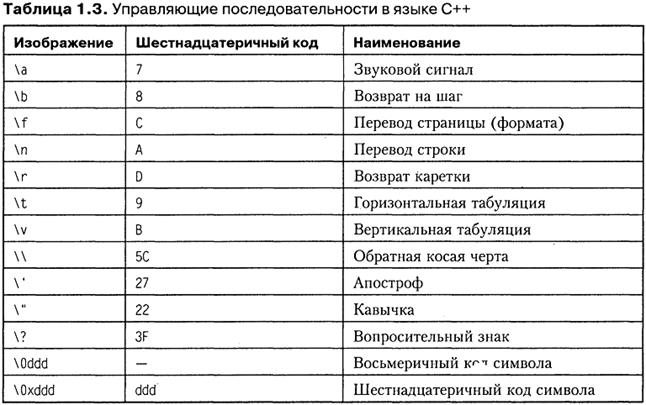
Управляющие последовательности могут использоваться и в строковых константах,
называемых иначе строковыми литералами. Например, если внутри строки требуется записать кавычку, ее предваряют косой чертой, по которой компилятор отличает ее от кавычки, ограничивающей строку:
"Издательский дом \"Питер\""
В конец каждого строкового литерала компилятором добавляется нулевой символ, представляемый управляющей последовательностью \0. Поэтому длина строки всегда на единицу больше количества символов в ее записи. Таким образом, пустая строка "" имеет длину 1 байт. Обратите внимание на разницу между строкой из одного символа, например, "А", и символьной константой 'А'. Пустая символьная константа недопустима.
Комментарии
Комментарий либо начинается с двух символов «прямая косая черта» (//) и заканчивается символом перехода на новую строку, либо заключается между символами-скобками /* и */. Внутри комментария можно использовать любые допустимые на данном компьютере символы, а не только символы из алфавита языка C++, поскольку компилятор комментарии игнорирует. Вложенные комментарии-скобки стандартом не допускаются, хотя в некоторых компиляторах разрешены.
Типы данных С++
Концепция типа данных
Основная цель любой программы состоит в обработке данных. Данные различного типа хранятся и обрабатываются по-разному. В любом алгоритмическом языке каждая константа, переменная, результат вычисления выражения или функции должны иметь определенный тип.
Тип данных определяет:
• внутреннее представление данных в памяти компьютер
• множество значений, которые могут принимать величины этого типа;
• операции и функции, которые можно применять к величинам этого типа.
Исходя из этих характеристик, программист выбирает тип каждой величины, используемой в программе для представления реальных объектов. Обязательное описание типа позволяет компилятору производить проверку допустимости различных конструкций программы. От типа величины зависят машинные команды, которые будут использоваться для обработки данных.
Все типы языка C++ можно разделить на основные и составные. В языке C++ определено шесть основных типов данных для представления целых, вещественных, символьных и логических величин. На основе этих типов программист может вводить описание составных типов. К ним относятся массивы, перечисления, функции, структуры, ссылки, указатели, объединения и классы.
Основные типы данных
Основные (стандартные) типы данных часто называют арифметическими, поскольку их можно использовать в арифметических операциях. Для описания основных типов определены следующие ключевые слова:
• int (целый);
• char (символьный);
• wchar_t (расширенный символьный);
• bool (логический);
• float (вещественный);
• double (вещественный с двойной точностью).
Первые четыре типа называют целочисленными (целыми), последние два — типами с плавающей точкой. Код, который формирует компилятор для обработки целых величин, отличается от кода для величин с плавающей точкой.
Существует четыре спецификатора типа, уточняющих внутреннее представление
и диапазон значений стандартных типов:
• short (короткий);
• long (длинный);
• signed (знаковый);
• unsigned (беззнаковый).
Целый тип (int)
Размер типа int не определяется стандартом, а зависит от компьютера и компилятора. Для 16-разрядного процессора под величины этого типа отводится 2 байта, для 32-разрядного - 4 байта.
Спецификатор short перед именем типа указывает компилятору, что под число требуется отвести 2 байта независимо от разрядности процессора. Спецификатор long означает, что целая величина будет занимать 4 байта. Таким образом, на 16-разрядном компьютере эквиваленты int и short int, а на 32-разрядном — int и long int.
Внутреннее представление величины целого типа — целое число в двоичном коде. При использовании спецификатора signed старший бит числа интерпретируется как знаковый (0 — положительное число, 1 — отрицательное). Спецификатор unsigned позволяет представлять только положительные числа, поскольку старший разряд рассматривается как часть кода числа. Таким образом, диапазон значений типа 1nt зависит от спецификаторов. Диапазоны значений величин целого типа с различными спецификаторами для IBM PC-совместимых компьютеров приведены в табл. 1.4.
По умолчанию все целочисленные типы считаются знаковыми, то есть спецификатор signed можно опускать.
Константам, встречающимся в программе, приписывается тот или иной тип в соответствии с их видом. Если этот тип по каким-либо причинам не устраивает программиста, он может явно указать требуемый тип с помощью суффиксов L, 1 (long) и u, U (unsigned). Например, константа 32L будет иметь тип long и занимать 4 байта. Можно использовать суффиксы L и U одновременно, например, 0x22UL или 05LU.
ПРИМЕЧАНИЕ . Типы short int, long int, signed int и unsigned int можно сокращать до short, long, signed и unsigned соответственно .
Символьный тип (char)
Под величину символьного типа отводится количество байт, достаточное для размещения любого символа из набора символов для данного компьютера таблица ASCII, что и обусловило название типа. Как правило, это 1 байт.
Тип char, как и другие целые типы, может быть со знаком или без знака. В величинах со знаком можно хранить значения в диапазоне от -128 до 127. При использовании спецификатора unsigned значения могут находиться в пределах от 0 до 255. Этого достаточно для хранения любого символа из 256-символьного набора ASCII. Величины типа char применяются также для хранения целых чисел, не превышающих границы указанных диапазонов.
Расширенный символьный тип (wchar_t)
Тип wchar_t предназначен для работы с набором символов, для кодировки которых недостаточно 1 байта, например, Unicode. Размер этого типа зависит от реализации; как правило, он соответствует типу short. Строковые константы типа wchar_t записываются с префиксом L, например, L"Gates".
Логический тип (bool)
Величины логического типа могут принимать только значения true и false, являющиеся зарезервированными словами. Внутренняя форма представления значения false — 0 (нуль). Любое другое значение интерпретируется как true. При преобразовании к целому типу true имеет значение 1.
ПРИМЕЧАНИЕ
Минимальные и максимальные допустимые значения для целых типов зависят от реализации и приведены в заголовочном файле <limits.h> (<c1imits>), характеристики вещественных типов — в файле <float.h> (<cfloat>).
Тип void
Кроме перечисленных, к основным типам языка относится тип void, но множество значений этого типа пусто. Он используется для определения функций, которые не возвращают значения, для указания пустого списка аргументов функции (о функциях мы поговорим позже), как базовый тип для указателей и в операции приведения типов.
Структура программы
Программа на языке C++ состоит из функций, описаний и директив препроцессора. Одна из функций должна иметь имя main – это главная фунукция. Выполнение программы начинается с первого оператора этой функции. Простейшее определение функции имеет следующий формат:
тип_возвращаемого_значения имя_функции ([ параметры функции ] )
{
тело функции
}
Как правило, функция используется для вычисления какого-либо значения, поэтому перед именем функции указывается его тип. О функциях детальнее мы поговорим чуть позже, а ниже приведены лишь самые необходимые сведения:
• если функция не должна возвращать значение, указывается тип void:
• тело функции является блоком и, следовательно, заключается в фигурные скобки;
• функции не могут быть вложенными;
• каждый оператор заканчивается точкой с запятой (кроме составного оператора).
Пример структуры программы, содержащей функции main, fl и f2:
Директивы препроцессора
Прототипы функций f 1 и f 2
Int ma i n()
{
Операторы главной функции
С вызовом функций f 1 и f 2
}
int f 1 ()
{
операторы функции f1
}
int f2 ()
{
операторы функции f2
}
Ввод/вывод в алгоритмическом языке С/С++
В языке C++ нет встроенных средств ввода/вывода — он осуществляется с помощью специальных функций, типов и объектов, содержащихся в стандартных библиотечных файлах (модулях).
Используется два способа ввода/вывода:
1. Функции, унаследованные из языка С;
2. Объекты C++.
Основные функции ввода/вывода в стиле С:
int scanf (<форматная строка>,<адрес>,<адрес>,...); // ввод
int printf(<форматная строка>,<аргумент>,<аргумент>,...) // вывод
Они выполняют форматированный ввод и вывод произвольного количества величин (<адрес> и <аргумент>) в соответствии со строкой формата <форматная строка>.
Форматная строка - это строка, которая начинается и заканчивается двойными кавычками ("вот так") и содержит спецификаторы формата (спецификаторы преобразования), начинающиеся со знака %, которые при вводе или выводе заменяются конкретными величинами.
Целью функции scanf является ввод значения переменных, указанных после <форматной строки>. Однако необходимо помнить, что после <форматной строки> указываются не имена переменных, а их адреса. Для взятия адреса переменной перед ее именем обязательно должен стоять символ &. Напиример:
scanf("%d%d",&a,&b);
Целью функции printf является вывод <форматной строки> на экран. До вывода <аргументы>, указанные в строке, преобразуются в соответствии со спецификаторами формата, указанными в <форматной строке>.
Список наиболее употребительных спецификаций преобразования приведен в таблице.
Модификаторы формата
Совместно с спецификатором формата может использоваться модификатор формата. Модификаторы формата применяются для управления шириной поля вывода, отводимого для размещения значения переменной. Модификаторы — это одно или два числа, первое из которых задает минимальное количество позиций, отводимых под число (ширина поля вывода), а второе — сколько из этих позиций отводится под дробную часть числа (точность). Если указанного количества позиций для размещения значения недостаточно, автоматически выделяется большее количество позиций:
• %-minC или %minC;
• %min.precisionC или %min.precisionC.
Здесь С — спецификация формата из приведенной выше таблицы, min — число, задающее минимальную ширину поля. Смысл модификатора precision, также задаваемого десятичным числом, зависит от спецификации формата, с которой он используется:
• при выводе строки (спецификация %s) precision указывает максимальное число символов для вывода;
• при выводе вещественного числа (спецификации %f или %е) precision указывает количество цифр после десятичной точки;
• при выводе целого числа (спецификации %d или %i), precision указывает минимальное количество выводимых цифр. Если число представляется меньшим числом цифр, чем указано в precision, выводятся ведущие (начальные) нули.
• при выводе вещественного числа (спецификации %d или %G) precision указывает максимальное количество значащих цифр, которые будут выводится.
Символ минус (-) указывает на то, что значение выравнивается по левому краю и, если нужно, дополняется пробелами справа. При отсутствии минуса значение выравнивается по правому краю и дополняется пробелами слева.
Перед спецификацией могут использоваться префиксы l и h, например, %lf, %hu.
Префикс h с типами d, i, о, х и X указывает на то, что тип аргумента short int, а с типом u - short unsigned int .
Префикс l с типами d, i, о, х и X указывает на то, что тип аргумента long int, с типом u - long unsigned int, а с типами е, Е, f, g и G - что тип аргумента double, а не float.
Пример:
#include <stdio.h>
#include <conio.h>
int main()
{
clrscr();
int int1 = 45, int2 = 13;
float f = 3.621;
double dbl = 2.23;
char ch = 'z', *str = "ramambahari";
printf(“int1 = %d| int2 = %3d| int2 = %-4d|\n”,int1,int2,int2);
printf ("int1 = %X| int2 = %3x| int2 = %4o|\n”,int1,int2,int2);
printf(“f = %f| f = %4.2f| f = %6.1f|\n”, f, f,f);
printf(“f = %g| f = %e| f = %+E|\n”, f, f, f);
printf(“dbl = %5.2lf | bdl = %e| dbl = %4.1G|\n”,dbl,dbl,dbl);
printf("ch = %c| ch = %3c| \n”,ch,ch);
printf(“str = %14s| \nstr = %-14s|\nstr = %s|\n”,str,str,str);
getch();return 0;
}
Результат работы программы:
int1 = 45| int2 = 13| int2 = 13 |
int1 = 2D| int2 = d| int2 = 15 |
f = 3.621000| f = 3.62 | f = 3.6 |
f = 3.621 I f = 3.621000e+000 | f = +3.621000E+000 |
dbl = 2.23 I dbl = 2.230000e+000 | dbl = 2 |
ch = z| ch = z I
str = ramambahari|
str = ramambahari |
str = ramambahari |
Замечание.
Функции ввода gets и getch.
Функция gets воспринимает любую информацию до тех пор, пока вы не нажмете клавишу Enter. Код, соответствующий этой клавише, в строку не вводится, но в конце строки добавляется нулевой символ \0.
Функция getch считывает с клавиатуры один символ, не отображая его на экране (в отличие от функции scanf и gets). Эта функция не передает символ в качестве параметра; она сама имеет тип char, и ее значение может быть непосредственно присвоено переменной типа char, например: ch = getch ();
3. Заголовочный файл <iostream.h> содержит описание набора классов для управления вводом/выводом. В нем определены стандартные объекты-потоки cin для ввода с клавиатуры и cout для вывода на экран, а также операции помещения в поток « и чтения из потока ». Чуть позднее, мы рассмотрим ввод и вывод данных через потоки cin / cout.
Пример программы с использованием потоков cin / cout из библиотеки классов C++:
#include <iostream.h>
#include <conio.h>
void main()
{
int a;
cout << "Введите целое число\n";
cin >> a;
cout << "Вы ввели число " << a << " спасибо!";
getch();
}
Переменные и выражения
В любой программе требуется производить вычисления. Для вычисления значений используются выражения, которые состоят из операндов, знаков операций и скобок. Операнды задают данные для вычислений. Операции задают действия, которые необходимо выполнить. Каждый операнд является, в свою очередь, выражением или одним из его частных случаев, например, константой или переменной. Операции выполняются в соответствии с приоритетами. Для изменения порядка выполнения операций используются круглые скобки. Рассмотрим составные части выражений и правила их вычисления.
Переменные
Переменная — это именованная область памяти, в которой хранятся данные определенного типа. У переменной есть имя и значение. Имя служит для обращения к области памяти, в которой хранится значение. Во время выполнения программы значение переменной можно изменять. Перед использованием любая переменная должна быть описана.
Пример описания целой переменной с именем а и вещественной переменной х:
int a ; float x ;
Общий вид оператора описания переменных:
[класс памяти] [const] тип имя [инициализатор];
Рассмотрим правила задания составных частей этого оператора.
• Необязательный класс памяти может принимать одно из значений auto, extern, static и register. О них рассказывается чуть ниже.
• Модификатор const показывает, что значение переменной изменять нельзя. Такую переменную называют именованной константой, или просто константой.
• При описании можно присвоить переменной начальное значение, это называется инициализацией. Инициализатор можно записывать - со знаком равенства:
= значение
Константа должна быть инициализирована при объявлении. В одном операторе можно описать несколько переменных одного типа, разделяя их запятыми.
Например:
short int а = 1; // целая переменная а
const char С = ‘С’ ; // символьная константа С
char s, sf = ‘f’ ; // инициализация относится только к sf;
float с = 0.22, x =3, su ;
Если тип инициализирующего значения не совпадает с типом переменной, выполняются преобразования типа по определенным правилам.
Описание переменной, кроме типа и класса памяти, явно или по умолчанию задает ее область действия. Класс памяти и область действия зависят не только от собственно описания, но и от места его размещения в тексте программы.
Область действия идентификатора — это часть программы, в которой его можно использовать для доступа к связанной с ним области памяти. В зависимости от области действия переменная может быть локальной или глобальной.
Если переменная определена внутри блока (напомню, что блок ограничен фигурными скобками), она называется локальной, область ее действия — от точки описания до конца блока, включая все вложенные блоки. Если переменная определена вне любого блока, она называется глобальной и областью ее действия считается файл, в котором она определена, от точки описания до его конца.
Класс памяти определяет время жизни и область видимости программного объекта (в частности, переменной). Если класс памяти не указан явным образом, он определяется компилятором исходя из контекста объявления.
Время жизни может быть постоянным (в течение выполнения программы) и переменным (в течение выполнения блока).
Областью видимости идентификатора называется часть текста программы, из которой допустим обычный доступ к связанной с идентификатором областью памяти. Чаще всего область видимости совпадает с областью действия. Исключением является ситуация, когда во вложенном блоке описана переменная с таким же именем. В этом случае внешняя переменная во вложенном блоке невидима, хотя он и входит в ее область действия. Тем не менее, к этой переменной, если она глобальная, можно обратиться, используя операцию доступа к области видимости - :: .
Для задания класса памяти используются следующие спецификаторы:
* auto — автоматическая переменная. Память под нее выделяется в стеке и при необходимости инициализируется каждый раз при выполнении оператора, содержащего ее определение. Освобождение памяти происходит при выходе из блока, в котором описана переменная. Время ее жизни — с момента описания до конца блока. Для глобальных переменных этот спецификатор не используется, а для локальных он принимается по умолчанию, поэтому задавать его явным образом большого смысла не имеет.
* extern — означает, что переменная определяется в другом месте программы (в другом файле или дальше по тексту). Используется для создания переменных, доступных во всех модулях программы, в которых они объявлены.
* static — статическая переменная. Время жизни — постоянное. Инициализируется один раз при первом выполнении оператора, содержащего определение переменной. В зависимости от расположения оператора описания статические переменные могут быть глобальными и локальными. Глобальные статические переменные видны только в том модуле, в котором они описаны.
* register — аналогично auto, но память выделяется по возможности в регистрах процессора. Если такой возможности у компилятора нет, переменные обрабатываются как auto.
Например:
int а; // 1 глобальная переменная а
int main()
{
int b; // 2 локальная переменная b
extern int x ; // 3 переменная x определена в другом месте
static int с; // 4 локальная статическая переменная с
а = 1 ; // 5 присваивание глобальной переменной
int а; // 6 локальная переменная а
а = 2; // 7 присваивание локальной переменной
::а = 3; // 8 присваивание глобальной переменной
return 0;
}
int x = 4; // 9 определение и инициализация х
В этом примере глобальная переменная а определена вне всех блоков. Память под нее выделяется в сегменте данных в начале работы программы, областью действия является вся программа. Область видимости — вся программа, кроме строк 8-6, так как в первой из них определяется локальная переменная с тем же именем, область действия которой начинается с точки ее описания и заканчивается при выходе из блока. Переменные b и с — локальные, область их видимости — блок, но время жизни различно: память под b выделяется в стеке при входе в блок и освобождается при выходе из него, а переменная с располагается в сегменте данных и существует все время, пока работает программа.
Если при определении начальное значение переменных явным образом не задается, компилятор присваивает глобальным и статическим переменным нулевое значение соответствующего типа. Автоматические переменные не инициализируются.
Имя переменной должно быть уникальным в своей области действия (например, в одном блоке не может быть двух переменных с одинаковыми именами).
СОВЕТ
Не жалейте времени на придумывание подходящих имен идентификаторов. Имя должно отражать смысл хранимой величины, быть легко распознаваемым и, желательно, не содержать символов, которые можно перепутать друг с другом, например, 1 (строчная L) или I (прописная i).
Для разделения частей имени можно использовать знак подчеркивания. Не давайте переменным имена, демонстрирующие знание иностранного слэнга. Как правило, переменным с большой областью видимости даются более длинные имена (желательно с префиксом типа), а для переменных, вся жизнь которых проходит на протяжении нескольких строк исходного текста, хватит и одной буквы с комментарием при объявлении.
Описание переменной может выполняться в форме объявления или определения.
Объявление информирует компилятор о типе переменной и классе памяти, а определение содержит, кроме этого, указание компилятору выделить память в соответствии с типом переменной. В C++ большинство объявлений являются одновременно и определениями. В приведенном выше примере только описание 3 является объявлением, но не определением.
Переменная может быть объявлена многократно, но определена только в одном месте программы, поскольку объявление просто описывает свойства переменной, а определение связывает ее с конкретной областью памяти.
Операции
В таблице ниже приведен список основных операций, определенных в языке C++, в соответствии с их приоритетами (по убыванию приоритетов, операции с разными приоритетами разделены чертой). Остальные операции будут вводиться по мере изложения.
В соответствии с количеством операндов, которые используются в операциях, они делятся на унарные (один операнд), бинарные (два операнда) и тернарную (три операнда).
Все приведенные в таблице операции, кроме условной и sizeof, могут быть перегружены. О перегрузке операций рассказывается на с. 189.
 Таблица 1.5. Основные операции языка C++
Таблица 1.5. Основные операции языка C++
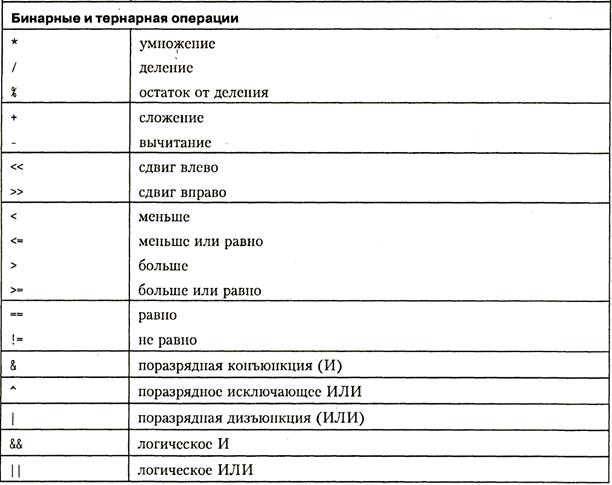

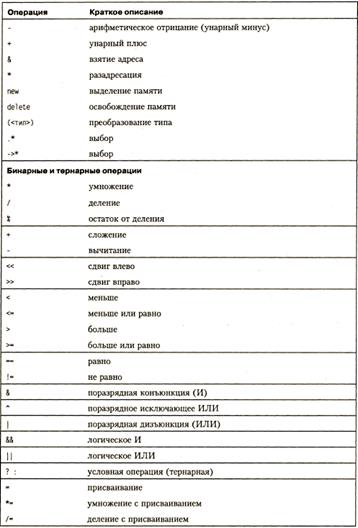
Полный перечень операций языка С++
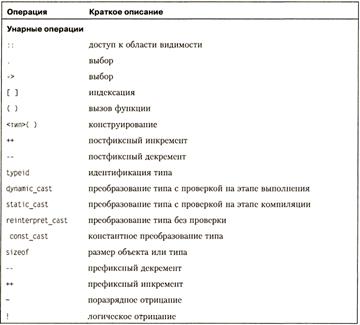

Операции увеличения и уменьшения на 1 (++ и --). Эти операции, называемые также инкрементом и декрементом, имеют две формы записи — префиксную, когда операция записывается перед операндом (++i), и постфиксную (i++). В префиксной форме сначала изменяется операнд, а затем его значение становится результирующим значением выражения, а в постфиксной форме значением выражения является исходное значение операнда, после чего он изменяется.
#include <stdio.h>
#include <conio.h>
void main()
{
int х = 3, у = 3;
printf("Значение префиксного выражения: %d\n", ++х):
printf("Значение постфиксного выражения: %d\n", у++);
printf("Значение х после приращения: %d\n", х);
printf("Значение у после приращения: %d\n", у);
getch();
}
Результат работы программы:
Значение префиксного выражения: 4
Значение постфиксного выражения: 3
Значение х после приращения: 4
Значение у после приращения: 4
Операция определения размера sizeof предназначена для вычисления размера объекта или типа в байтах, и имеет две формы:
Sizeof выражение
sizeof ( тип )
Пример:
#include <iostream.h>
#include <conio.h>
void main()
{
float x = 1;
cout << "sizeof (float) =" << sizeof (float);
cout « "\nsizeof x ="<< sizeof x;
cout « "\nsizeof (x + 1.0) =" << sizeof (x +1.0);
getch();
}
Результат работы программы:
sizeof (float) = 4
sizeof x = 4
sizeof (x + 1.0) = 8
В последнем случае имеем 8, так как к переменной х типа float прибавляется вещественная константа 0.1, которая по умолчанию имеет тип doublе, поэтому происходит преобразование типов данных к более длинному, т.е. double. Для переменных типа double в оперативной памяти отводится 8 байт.
Операции отрицания (- , ! , ~).
Арифметическое отрицание (унарный минус -) изменяет знак операнда целого или вещественного типа на противоположный.
Логическое отрицание (!) дает в результате значение 0, если операнд есть истина (не нуль), и значение 1, если операнд равен нулю. Операнд должен быть целого или вещественного типа, а может иметь также тип указатель.
Поразрядное отрицание (~), часто называемое побитовым, инвертирует каждый разряд в двоичном представлении целочисленного операнда.
Деление (/) и остаток от деления (%).
Операция деления (/)применима к операндам арифметического типа. Если оба операнда целочисленные, результат операции округляется до целого числа, в противном случае тип результата определяется правилами преобразования (см. раздел «Выражения», с. 38, и приложение 3).
Операция остатка от деления (%) применяется только к целочисленным операндам. Знак результата зависит от реализации.
#include <stdio.h>
#include <conio.h>
void main()
{
int x = 11, у = 4;
float z = 4;
printf("Результаты деления: x/y=%d x/z=%f\n", x/y, x/z):
printf("Остаток = %d\n", x%y);
getch();
}
Результат работы программы:
Результаты деления: x/y=2 x/z=2.750000
Остаток= 3
Операции сдвига ( << и >> ) применяются к целочисленным операндам. Они сдвигают двоичное представление первого операнда влево или вправо на количество двоичных разрядов, заданное вторым операндом. При сдвиге влево ( << ) освободившиеся разряды обнуляются. При сдвиге вправо (>>) освободившиеся биты заполняются нулями, если первый операнд беззнакового типа, и знаковым разрядом в противном случае. Операции сдвига не учитывают переполнение и потерю значимости.
Операции отношения (<, <=, >, >=, == , !=) сравнивают первый операнд со вторым. Операнды могут быть арифметического типа или указателями. Результатом операции является значение true или false (любое значение, не равное нулю, интерпретируется как true). Операции сравнения на равенство и неравенство имеют меньший приоритет, чем остальные операции сравнения.
Поразрядные операции (&, | , ^) применяются только к целочисленным операндам и работают с их двоичными представлениями. При выполнении операций операнды сопоставляются побитово (первый бит первого операнда с первым битом второго, второй бит первого операнда со вторым битом второго, и т д.).
При поразрядной конъюнкции, или поразрядном И (операщия обозначается &) бит результата равен 1 только тогда, когда соответствующие биты обоих операндов равны 1.
При поразрядной дизъюнкции, или поразрядном ИЛИ (операция обозначается |) бит результата равен 1 тогда, когда соответствующий бит хотя бы одного из операндов равен 1.
При поразрядном исключающем ИЛИ (операция обозначается ^) бит результата равен 1 только тогда, когда соответствующий бит только одного из операндов равен 1.
#include <iostream.h>
#include <conio.h>
void main()
{
cout << "\n 6 & 5 = " << (6 & 5);
cout << "\n 6 | 5 = " << (6 | 5);
cout << "\n 6 ^ 5 = " << (6 ^ 5;)
getch();
}
Результат работы программы:
6 & 5 = 4
6 | 5 = 7
6 ^ 5 = 3
Логические операции (&& и ||). Операнды логических операций И (&&) и ИЛИ (||) могут иметь арифметический тип или быть указателями, при этом операнды в каждой операции могут быть различных типов. Преобразования типов не производятся, каждый операнд оценивается с точки зрения его равенства нулю (операнд, равный нулю, рассматривается как false, не равный нулю — как true). Результатом логической операции является true (не ноль) или false (ноль).
Результат операции логическое И имеет значение true только если оба операнда имеют значение true.
Результат операции логическое ИЛИ имеет значение true, если хотя бы один из операндов имеет значение true.
Логические операции выполняются слева направо.
Если значения первого операнда достаточно, чтобы определить результат операции, второй операнд не вычисляется: if ( (q = = 0) && (cos(q) = =0) ) printf(“True”);
else printf(“False”);
Операции присваивания (=, +=, -=, *= и т. д.). Операции присваивания могут использоваться в программе как законченные операторы.
Формат операции простого присваивания (=):
<Идентификатор> = <выражение>;
Сначала вычисляется <выражение>, стоящее в правой части операции, а потом его результат записывается в область памяти, указанную в левой части.
Замечание.
При присваивании производится преобразование типа выражения к типу <идентификатора>, что может привести к потере информации.
Условная операция ( ?:). Эта операция тернарная, то есть имеет три операнда. Ее формат:
операнд_1 ? операнд_2 : операнд_3;
Здесь операнд_1 операнд может иметь арифметический тип или быть указателем. Он оценивается с точки зрения его эквивалентности нулю (операнд, равный нулю, рассматривается как false, не равный пулю — как true). Если результат вычисления операнда_1 равен true, то результатом условной операции будет значение операнда_2, иначе — операнд3. Вычисляется всегда либо операнд_2, либооперанд_3. Их тип может различаться.
Например: определить максимум из двух целых чисел.
#inc1ude <stdio.h>
void main()
{ int a = 11, b = 4, max;
max = (b > a) ? b : a;
printf("Наибольшее число: %d", max);
}
Преобразование типов данных
Стр.38, 231, приложение 3
При вычислении различных типов выражений в языке С/С++ может происходить неявное и явное преобразование типов данных. Преобразование типов происходит, если в выражении участвуют операнды различного типа (более короткие типы преобразуются в более длинные для сохранения значимости и точности, что используется как тип результата), а это повлияет на результат операции.
В основе всех преобразований лежит изменение внутреннего представления величин (с потерей точности или без потери точности).
Преобразования типов всегда происходит по определенным правилам:
1) Любые операнды типа char, unsigned char или short преобразуются к типу int по правилам:
* char расширяется нулем или знаком в зависимости от умолчания для char;
* unsigned char расширяется нулем;
* signed char расширяется знаком;
* short, unsigned short и enum при преобразовании не изменяются.
* Затем любые два операнда становятся либо int, либо float, double или long double.
2) Если один из операндов имеет тип long double, то другой преобразуется к типу long double.
3) Если один из операндов имеет тип double, то другой преобразуется к типу double.
4) Если один из операндов имеет тип float, то другой преобразуется к типу float.
5) Если один из операндов имеет тип unsigned long, то другой преобразуется к типу unsigned long.
6) Если один из операндов имеет тип long, то другой преобразуется к типу long.
7) Если один из операндов имеет тип unsigned, то другой преобразуется к типу unsigned.
Для выполнения явных преобразований типа в C++ существует целая группа операций: const_cast, dynamic_cast, reinterpret_cast и static_cast, а также операция приведения типа, унаследованная из языка С (эта операция использовалась нами в лабораторных работах). Рассмотрим эти операции.
1) Операция приведения типов. Формат использования:
<тип> (<переменная>)
(<тип>) <переменная>
Результатом операции является значение заданного <типа>.
int а = 2;
float b = 6.8;
printf(“a = %f b = %d”, double (a), (int) b);
Величина a преобразуется к типу double, a переменная b — к типу int с отсечением дробной части.
2) Операция const_cast. Операция служит для удаления модификатора const. Как правило, она используется при передаче в функцию константного указателя на место обычного (изменяемого) формального параметра, не имеющего модификатора const, а это запрещено. Операция const_cast снимает это ограничение. Естественно, функция не должна пытаться изменить значение, на которое ссылается передаваемый указатель, иначе результат выполнения программы не определен.
Формат операции:
const_cast <тип> (<выражение>);
Обозначенный <тип> должен быть таким же, как и тип <выражения>, за исключением модификатора const. Обычно это указатель. Операция формирует результат указанного <типа>.
Пример пользовательской функции:
void print ( int *р) // Функция не изменяет значение указателя *р
{
cout « *р;
}
……………..
const int *р;
print ( p ); // Ошибка, поскольку р объявлен как указатель на константу
Операция const_cast используется в том случае, когда программист уверен, что в теле функции значение, на которое ссылается указатель, не изменяется. Естественно, если есть возможность добавить к описанию формального параметра модификатор const, это предпочтительнее использования преобразования типа при вызове функции.
3) Операция dynamic _ cast. Операция применяется для преобразования указателей родственных классов иерархии, в основном — указателя базового класса в указатель на производный класс, при этом во время выполнения программы производится проверка допус тимости преобразования. Формат операции: dynamic_cast <тип *> (выражение) Выражение должно быть указателем или ссылкой на класс, тип — базовым или производным для этого класса. После проверки допустимости преобразования в случае успешного выполнения операция формирует результат заданного типа, в противном случае для указателя результат равен нyлю, а для ссылки порождается исключение bad_cast. Если заданный тип и тип выражения не относятся к одной иерархии, преобразование не допускается. Преобразование из базового класса в производный, называют понижающим (downcast), так как графически в иерархии наследования принято изображать производные классы ниже базовых. Приведение из производного класса в базовый называют повышающим (upcast), а приведение между производными класса ми одного базового или, наоборот, между базовыми классами одного производ ного — перекрестным (crosscas
Повышающее преобразование
Выполнение с помощью операции dynamic_cast повышающего преобразования равносильно простому присваиванию:
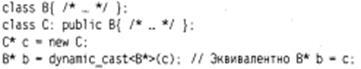
Понижающее преобразование
Чаще всего операция dynamic_cast применяется при понижающем преобразовании — когда компилятор не имеет возможности проверить правильность приведения. Производные классы могут содержать функции, которых нет в базовых классах. Для их вызова через указатель базового класса нужно иметь уверенность, что этот указатель в действительности ссылается на объект производного класса. Та кая проверка производится в момент выполнения приведения типа с использова нием RTTI (run-time type information) — «информации о типе во время выполне ния программы». Для того чтобы проверка допустимости могла быть выполнена, аргумент операции dynamic_cast должен быть полиморфного типа, то есть иметь хотя бы один виртуальный метод (см. с. 205).
Для полиморфного объекта реализация операции clynam1c_cast весьма эффектив на, поскольку ссылка на информацию о типе объекта заносится в таблицу вирту альных методов, и доступ к ней осуществляется легко. С точки зрения логики требование, чтобы объект был полиморфным, также оп равдано: ведь если класс не имеет виртуальных методов, его нельзя безопасным образом использовать, не зная точный тип указателя. А если тип известен, ис пользовать операцию dynam1c_cast нет необходимости. Результат примепения операции dynamic^cast к указателю всегда требуется про верять явным образом. В приведенном ниже примере описан полиморфный базо вый класс В и производный от него класс С, в котором определена функция f2. Для того чтобы вызывать ее из функции demo только в случае, когда последней передается указатель на объект производного класса, используется операция dynamic_cast с проверкой результата преобразования:

При использовании в этом примере вместо dynamic_cast приведения типов в сти ле С, например: С* с = (С*) р: проконтролировать допустимость операции невозможно, PI если указатель р на самом деле не ссылается на объект класса С, это приведет к ошибке. Другим недостатком приведения в стиле С является невозможность преобра зования в производный виртуального базового класса, это запрещено синтакси-чески. С помощью операции dynamic_cast такое преобразование возможно при условии, что класс является полиморфным и преобразование недвусмыслерню. Рассмотрим пример, в котором выполняется понижающее преобразование виртуального базового класса

Преобразование ссылок Для аргумента-ссылки смысл операции преобразования несколько иной, чем для указателя. Поскольку ссылка всегда указывает на конкретный объект, операция dynamic_cast должна выполнять преобразование именно к типу этого объекта. Корректность приведения проверяется автоматически, в случае несовпадения порождается исключение bad_cast:


Перекрестное преобразование Операция dynamic_cast позволяет выполнять безопасное преобразование типа между производными классами одного базового класса, например:

Классы С и D являются производными от класса В. Функции demo передается ука затель на класс D, являющийся на самом деле указателем на «братский» для него класс С, поэтому динамическое преобразование типа из D в С в функции demo завершается успешно.
При необходимости можно осуществить преобразование между базовыми клас сами одного производного класса, например:


Класс D является потомком В и С, поэтому содержит методы обоих классов. Если в функцию demo передается на самом деле указатель не на В, а на D, его можно пре образовать к его второму базовому классу С.
4) Операция static_cast . Операция stat1c__cast используется для преобразования типа на этапе компиля ции между:
целыми типами;
целыми и вещественными типами;
целыми и перечисляемыми типами;
указателями и ссылками на объекты одной иерархии, при условии, что оно однозначно и не связано с понижающим преобразованием виртуального базо вого класса.
Формат операции:
static_cast <тип> (выражение)
Результат операции имеет указанный тип, который может быть ссылкой, указа телем, арифметическим или перечисляемым типом. При выполнении операции внутреннее представление данных может быть моди фицировано, хотя численное значение остается неизменным. Например:

Такого рода преобразования применяются обычно для подавления сообщений компилятора о возможной потере данных в том случае, когда есть уверенность, что требуется выполнить именно это действие. Результат преобразования остает ся на совести программиста. Операция static_cast позволяет выполнять преобразования из производного класса в базовый и наоборот без ограничений:

Преобразование выполняется при компиляции, при этом объекты могут не быть полиморфными. Программист должен сам отслеживать допустимость дальней ших действий с преобразованными величинами. В общем случае использование для преобразования указателей родственных классов иерархии предпочтительнее использовать операцию dynamic_cast. В этом случае если преобразование возможно на этапе компиляции, генерируется тот же код, что и для static_cast. Кроме того, dynam1c_cast допускает перекрестное пре образование, нисходящее приведение виртуального базового класса и произво дит проверку допустимости приведения во время выполнения.
5) Операция reinterpret_cast Операция reinterpret_cast применяется для преобразования не связанных между собой типов, например, указателей в целые или наоборот, а также указателей типа void* в конкретный тип. При этом внутреннее представление данных оста ется неизменным, а изменяется только точка зрения компилятора на данные. Формат операции:
reinterpret_cast <тип> (выражение)
Результат операции имеет указанный тип, который может быть ссылкой, указа телем, целым или вещественным типом.

Различие между static^cast и re1nterpret_cast позволяет компилятору произво дить минимальную проверку при использовании stat1c_cast, а программисту — обозначать опасные преобразования с помощью re1nterpret_cast. Результат пре образования остается на совести программиста.
Динамическое определение типа
Механизм идентификации типа во время выполнения программы (RTTI) позво ляет определять, на какой тип в текущий момент времени ссылается указатель, а также сравнивать типы объектов. Для доступа к RTTI в стандарт языка введена операция typeid и класс type_1nfoi. Формат операции typeid:
typeid (тип) typeid (выражение)
Базовые конструкции алгоритмического языка С/С++
Оператор «выражение».
Любое выражение, завершающееся точкой с запятой, рассматривается как оператор, выполнение которого заключается в вычислении выражения. Частным случаем выражения является пустой оператор ; (он используется, когда по синтаксису оператор требуется, а по смыслу — нет). Примеры:
i++; //
а* = b + с;
funс(i, к);
Операторы ветвления
1) Условный оператор if Условный оператор if используется для разветвления процесса вычислений на два направления. Структурная схема оператора приведена на рис. 1.5. Формат оператора:
if ( выражение ) оператор_1; [else оператор_2;]
Сначала вычисляется выражение, которое может иметь арифметический тип или тип указателя. Если оно не равно нулю (имеет значение true), выполняется оператор_1, иначе — оператор_2. После этого управление передается на оператор, следующий за if. Одна из ветвей может отсутствовать, логичнее опускать вторую ветвь вместе с ключевым словом еlse. Если в какой-либо ветви требуется выполнить несколько операторов, их необходимо заключить в блок, иначе компилятор не сможет понять, где заканчивается оператор if. Блок может содержать любые операторы, в том числе описания и другие условные операторы (но не может состоять из одних описаний). Необходимо учитывать, что переменная, описанная в блоке, вне блока не существует.
Пример 1.
if (а<0) b = 1; //1
if (a<b && (a>d || a = =0 )) b++; else {b *= a; a = 0;} //2
if (a<b) { if (a<c) m = a; else m = c;} else { if (b<c) m = b; else m = c;} //3
if (a++) b++; //4
if (b>a) max = b; else max = a; //5
Здесь:
1) Пропущен else – краткая форма записи оператора if.
2) Запись условия состоящего из нескольких простых условий.
3) Запись вложенных операторов if, причем фигурные скобки необязательны.
4) Показано, что условием может быть не только логическое выражение, а любое арифметическое выражение.
5) Полная форма записи оператора if.
 Пример2. Производится выстрел по мишени, изображенной на рис. 1.6. Опреде лить количество очков.
Пример2. Производится выстрел по мишени, изображенной на рис. 1.6. Опреде лить количество очков.
#include <iostream.h>
#include <conio.h>
void main()
{
float x, у;
int kol;
cout << "Введите координаты выстрела \n";
cin >> x >> у;
if ( x*x + y*y < 1 ) kol = 2;
else if( x*x + y*y < 4 ) kol = 1;
else коl = 0;
cout << “\n Очков: “ << kol;
getch();
}
Замечание.
1) Необходимо внимательно следить за записью условий использующих проверку на равенство (= =), так как возможно использование простого присваивания (=), например,
if (a=l)b=0;
Синтаксической ошибки нет, так как операция присваивания формирует результат, кото рый и оценивается на равенство/неравенство нулю. В данном примере присваивание переменной b будет выполнено независимо от значения переменной а. Поэтому в выражениях проверки переменной на равенство константе константу рекомендуется записывать слева от операции сравнения: if (1= =а) b=0;
2) Вторая ошибка — неверная запись проверки на принадлежность диапазону. Например, чтобы проверить условие 0<х<1, нельзя записать его в условном операторе непосредственно, так как будет выполнено сначала сравнение 0<х, а его результат (true или false, преобразованное в int) будет сравниваться с 1. Правильный способ записи: шf(0<x && х<1)...
2) Оператор switch. Оператор switch (переключатель) предназначен для разветвления процесса вычислений по нескольким направлениям. Структурная схема оператора приведена на рис. 1.7.
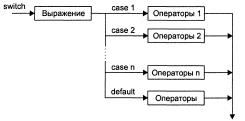
Формат оператора:
switch ( <выражение> )
{
case <значение_1> : [<список_операторов_1>]
case < значение_2> : [<список_операторов_2>]
………………………..
case < значение_N> : [<список_операторов_N>]
[default: <список операторов N+1>]
}
Выполнение оператора начинается с вычисления <выражения> (оно должно быть целочисленным), а затем управление передается первому оператору из списка, значение которого совпало с вычисленным. После этого, если выход из переключателя явно не указан, последовательно выполняются все остальные ветви. Выход из переключателя обычно выполняется с помощью операторов break или return. Оператор break выполняет выход из самого внутреннего из объемлющих его операторов switch, for, while и do. и do. Оператор return выполняет выход из функции, в теле которой он записан.
Все перечисленные <значения> должны быть разными, но быть одного целочисленного типа. Несколько меток могут следовать подряд. Если совпадения не произошло, выполняются операторы, расположенные после слова default (а при его отсутствии управление передается следующему за switch оператору).
Пример: Написать программу, которая дописывает слово рубль в правильном падеже.
Операторы цикла
Операторы цикла используются для организации многократно повторяющихся вычислений. Любой цикл состоит из тела цикла, то есть тех операторов, которые выполняются несколько раз, начальных установок, модификации параметра цикла и проверки условия продолжения выполнения цикла.
Один проход цикла называется итерацией. Проверка условия выполняется на каждой итерации либо до тела цикла (тогда говорят о цикле с предусловием), либо после тела цикла (цикл с постусловием).
Переменные, изменяющиеся в теле цикла и используемые при проверке условия продолжения, называются параметрами цикла. Целочисленные параметры цикла, изменяющиеся с постоянным шагом на каждой итерации, называются счетчиками цикла.
Начальные установки могут явно не присутствовать в программе, их смысл состоит в том, чтобы до входа в цикл задать значения переменным, которые в нем используются.
Цикл завершается, если условие его продолжения не выполняется. Возможно принудительное завершение как текущей итерации, так и цикла в целом. Для этого служат операторы break, continue, return и goto.
Передавать управление извне внутрь цикла не рекомендуется. Для удобства, а не по необходимости, в C++ есть три разных оператора цикла —while, do while и for.
Цикл с параметром ( for )
Цикл с параметром имеет следующий формат:
for (<инициализация>; <выражение>; <модификации>) <оператор>;
<Инициализация> используется для объявления и присвоения начальных значений величинам, используемым в цикле. В этой части можно записать несколько операторов, разделенных запятой (операцией «последовательное выполнение»), например, так:
for (int 1 = 0, j = 2, ...
int к, m;
for (k = 1, m = 0; ...
Областью действия переменных, объявленных в части инициализации цикла, является цикл. Инициализация выполняется один раз в начале исполнения цикла.
<Выражение> определяет условие выполнения цикла: если его результат, приведенный к типу bool, равен true, цикл выполняется. Цикл с параметром реализован как цикл с предусловием.
<Модификации> выполняются после каждой итерации цикла и служат обычно для изменения параметров цикла. В части модификаций можно записать несколько операторов через запятую. Простой или составной оператор представляет собой тело цикла. Любая из частей оператора for может быть опущена (но точки с запятой надо оставить на своих местах).
Пример. Оператор, вычисляющий сумму чисел от 1 до 100:
for (int i = 1, s = 0; i<=100; i++) s += 1;
Пример. Программа печатает таблицу значений функции y=x^2+1 во введенном диапазоне (задача на табулирование функции):
#include <stdio.h>
void main()
{clrscr();
float Xn, Xk, Dx, X;
printf("Введите диапазон и шаг изменения аргумента: " ):
scanf(“%f%f%f", &Хn, &Хк, &Dx):
printf(“I X I Y I\n"):
for (X = Xn; X<=Xk; X += Dx)
printf(“I %5.2f I %5.2f I\ n” , X, X*X + 1):
getch();
}
Пример (программа находит все делители целого положительного числа):
#include <iostream.h>
#include <conio.h>
void main()
{
int num, i, div:
cout << "\nВведите число --> ";
cin >> num;
for (i = num / 2, div = 2; div <= i ; div++)
if (!(num % div)) cout << div <<"\n"; //выделение остатка от деления
getch();
}
Пример. Программа вычисляет значение гиперболического синуса 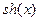 от вещественного аргумента х с заданной точностью eps с помощью разложения в бесконечный ряд.
от вещественного аргумента х с заданной точностью eps с помощью разложения в бесконечный ряд.
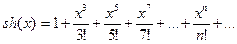
Вычисление заканчивается, когда абсолютная величина очередного члена ряда, прибавляемого к сумме, станет меньше заданной точности.
#include <iestream.h>
#include <math.h>
#include <conio.h>
void main()
{
const int Maxiter = 500; // ограничитель количества итераций
double x, eps;
cout << "\nВведите аргумент и точность: ";
сin >> x >> eps;
int flag = 1; // признак успешного вычисления true
double у = x, ch = х; // сумма и первый член ряда
for (int n = 0; fabs(ch) > eps; n++)
{
ch *= x * x /(2 * n + 2)/(2 * n + 3); // очередной член ряда
у += ch;
if (n > Maxiter)
{
cout « "\nРяд расходится!";
flag = 0; //false
break;
}
}
if (flag) cout << "\nЗначение функции: " << у;
getch();
}
Замечание.
1) Любой цикл for может быть приведен к эквивалентному ему циклу while и наоборот по следующей схеме:
| for (<действие_1>; < действие_2>; < действие_3>) | < действие_1>; while (<действие_2>) { < действие_3> } |
Замечание.
2) При записи тела циклов проверить, всем ли переменным, встречающимся в правой части операторов присваивания, присвоены до этого начальные значения.
3) Проверить, изменяется ли в цикле хотя бы одна переменная, входящая в условие выхода из цикла;
4) Предусмотреть аварийный выход из цикла по достижению некоторого количества итераций.
5) Если тело цикла состоит более чем из одного оператора (действия), то эти операторы взять в операторные скобки (фигурные скобки).
Операторы цикла взаимозаменяемы, но можно привести некоторые рекомендации по выбору наилучшего в каждом конкретном случае.
Оператор do while обычно используют, когда цикл требуется обязательно выполнить хотя бы раз (например, если в цикле производится ввод данных).
Оператором while удобнее пользоваться в случаях, когда число итераций заранее не известно, очевидных параметров цикла нет или модификацию параметров удобнее записывать не в конце тела цикла.
Оператор for предпочтительнее в большинстве остальных случаев (однозначно — для организации циклов со счетчиками).
Немного истории
Язык программирования С был разработал вначале 70-х годов Денисом Ритчи, сотрудником компании Bell Laboratories, который занимался разработкой операционной системы (ОС) UNIX. Для выполнения данной работы ему необходим был язык программирования, который отличался краткостью и эффективностью по управлению аппаратными средствами компьютера. Язык программирования ассемблер для этих целей не подходил, так как он привязан к конкретному типу процессора и перенос программы с одного компьютера на другой сопровождается дополнительной работой.
Язык программирования С++ был разработан в начале 80-х годов сотрудником компании Bell Laboratories Бьярни Страуструпом. Его основная цель заключалась в том, чтобы программистам было легче и приятнее писать хорошие программы, и при этом не приходилось программировать на ассемблере [ Bjarne Stroustrup. The C++ Programming Language. Third Edition. Reading, MA: Addision-Wesley Publishing Company. 1997 ].
Состав алгоритмического языка С/С++
В тексте на любом естественном языке можно выделить четыре основных элемента:
символы, слова, словосочетания и предложения.
Подобные элементы содержит и алгоритмический язык С/C++, только здесь:
* слова – это лексемы (элементарные конструкции),
* словосочетания – это выражения,
* предложения – это операторы.
Причем лексемы образуются из символов, выражения – из лексем и символов, а операторы – из символов, выражений и лексем (рис. 1.1):
| |
Рис. 1.1. Состав алгоритмического языка.
На рисунке 1.1:
* Алфавит языка, или его символы – это основные неделимые знаки, с помощью которых пишутся все тексты на языке.
* Лексема (элементарная конструкция) – это неделимая последовательность знаков алфавита (символов), имеющая самостоятельный смысл.
* Выражение – это совокупность символов и лексем, которая задает правило вычисления некоторого значения.
* Оператор – это совокупность символов, лексем и выражений, которая задает законченное описание некоторого действия.
Для описания сложного действия требуется последовательность операторов. Операторы могут быть объединены в составной оператор, или блок (последовательность операторов заключенная в фигурные скобки: {} ). В этом случае они рассматриваются как один оператор. Операторы бывают исполняемые и неисполняемые. Исполняемые операторы задают действия над данными. Неисполняемые операторы служат для описания данных, поэтому их часто называют операторами описания или просто описаниями.
Объединенная единым алгоритмом совокупность описаний и операторов образует программу на алгоритмическом языке. Для того чтобы выполнить программу, требуется перевести ее на язык, понятный процессору — в машинные коды. Этот процесс, как правило, состоит из нескольких этапов и называется компиляцией.
Алфавит языка
Алфавит C++ включает:
• прописные и строчные латинские буквы и знак подчеркивания;
• арабские цифры от 0 до 9;
• специальные знаки: " { } , i [ ] ( ) + - / % * . \ ? < = > ! & # - ; ' '
• пробельные символы: пробел, символы табуляции, символы перехода на новую строку.
Из символов алфавита формируются лексемы языка, к которым относят:
• идентификаторы;
• ключевые (зарезервированные) слова;
• знаки операций;
• константы;
• разделители (скобки, точка, запятая, пробельные символы).
Границы лексем определяются другими лексемами, такими, как разделители или знаки операций.
Идентификаторы
Идентификатор — это имя программного объекта. В идентификаторе могут использоваться латинские буквы, цифры и знак подчеркивания. Прописные и строчные буквы различаются, например, sysop, SySoP и SYSOP — три различных имени.
СОВЕТ
Для улучшения читаемости программы следует давать объектам осмысленные имена. Существует соглашение о правилах создания имен, называемое венгерской нотацией (поскольку предложил ее сотрудник компании Microsoft венгр по национальности), по которому каждое слово, составляющее идентификатор, начинается с прописной буквы, а вначале ставится префикс, соответствующий типу величины, например, iMaxLength, IpfnSetFirstDialog. Другая традиция — разделять слова, составляющие имя, знаками подчеркивания: maxjength, number_of_galosh.
При выборе идентификатора необходимо иметь в виду следующее:
* длина идентификатора по стандарту не ограничена, но некоторые компиляторы и компоновщики налагают на нее ограничения;
* идентификатор создается на этапе объявления переменной, функции, типа и т. п., после этого его можно использовать в последующих операторах программы;
* идентификатор не должен совпадать с ключевыми словами (см. следующий раздел) и именами используемых стандартных объектов языка;
* не рекомендуется начинать идентификаторы с символа подчеркивания, поскольку они могут совпасть с именами системных функций или переменных, и, кроме того, это снижает мобильность программы;
* на идентификаторы, используемые для определения внешних переменных, налагаются ограничения компоновщика (использование различных компоновщиков или версий компоновщика накладывает разные требования на имена внешних переменных).
* между двумя идентификаторами должен быть хотя бы один разделительный символ (пробел, знак операции и т.п.);
* первым символом идентификатора может быть буква или знак подчеркивания, но не цифра. Пробелы внутри имен не допускаются.
Ключевые слова
Ключевые слова — это зарезервированные идентификаторы, которые имеют специальное значение для компилятора. Их можно использовать только в том смысле, в котором они определены разработчиками языка программирования.
Список ключевых слов C++ приведен ниже.
asm auto bool break case catch char class const const_cast continue default delete do double dynamic_cast else enum explicit export extern false float for friend goto if inline int long mutable namespace new operator private protected public register reinterpret_cast return short signed sizeof static static__cast struct switch template this throw true try typedef typeid typename union unsigned using virtual void volatile wchar_t while.
Знаки операций
Знак операции — это один или более символов, определяющих действие над операндами.
Внутри знака операции пробелы не допускаются. Операции делятся на унарные, бинарные и тернарную по количеству участвующих в них операндов.
Один и тот же знак может интерпретироваться по-разному в зависимости от контекста. Все знаки операций за исключением [ ], ( ) и ? : представляют собой отдельные лексемы.
Константы
Константами называют элементы данных, значения которых установлены в описательной части программы и в процессе выполнения программы не изменяются. Различаются целые, вещественные, символьные и строковые константы. Компилятор, выделив константу в качестве лексемы, относит ее к одному из типов по ее внешнему виду.
Форматы констант, соответствующие каждому типу, приведены в табл. 1.2.
Таблица 1.2. Константы в языке C++
Если требуется сформировать отрицательную целую или вещественную константу, то перед константой ставится знак унарной операции изменения знака (-), например: -218, -022, -ОхЗС, -4.8, -0.1е4.
Вещественная константа в экспоненциальном формате представляется в виде мантиссы и порядка. Мантисса записывается слева от знака экспоненты (Е или е), порядок— справа от знака.
Символьные константы, состоящие из одного символа, занимают в памяти один байт и имеют стандартный тип char. Двухсимвольные константы занимают два байта и имеют тип int, при этом первый символ размещается в байте с меньшим адресом (о типах данных рассказывается в следующем разделе).
Символ обратной косой черты используется для представления:
• кодов, не имеющих графического изображения (например, \а — звуковой сигнал, \n — перевод курсора в начало следующей строки);
• символов апострофа ( ' ) , обратной косой черты ( \ ), знака вопроса ( ? ) и кавычки
( " );
• любого символа с помощью его шестнадцатеричного или восьмеричного кода, например, \073, 0xF5.
Числовое значение должно находиться в диапазоне от 0 до 255.
Последовательности символов, начинающиеся с обратной косой черты, называют управляющими, или escape-Последовательностями. В таблице 1.3 приведены их допустимые значения. Управляющая последовательность интерпретируется как одиночный символ.
Если в последовательности цифр встречается недопустимая, она считается концом цифрового кода.
Управляющие последовательности могут использоваться и в строковых константах,
называемых иначе строковыми литералами. Например, если внутри строки требуется записать кавычку, ее предваряют косой чертой, по которой компилятор отличает ее от кавычки, ограничивающей строку:
"Издательский дом \"Питер\""
В конец каждого строкового литерала компилятором добавляется нулевой символ, представляемый управляющей последовательностью \0. Поэтому длина строки всегда на единицу больше количества символов в ее записи. Таким образом, пустая строка "" имеет длину 1 байт. Обратите внимание на разницу между строкой из одного символа, например, "А", и символьной константой 'А'. Пустая символьная константа недопустима.
Комментарии
Комментарий либо начинается с двух символов «прямая косая черта» (//) и заканчивается символом перехода на новую строку, либо заключается между символами-скобками /* и */. Внутри комментария можно использовать любые допустимые на данном компьютере символы, а не только символы из алфавита языка C++, поскольку компилятор комментарии игнорирует. Вложенные комментарии-скобки стандартом не допускаются, хотя в некоторых компиляторах разрешены.
Типы данных С++
Концепция типа данных
Основная цель любой программы состоит в обработке данных. Данные различного типа хранятся и обрабатываются по-разному. В любом алгоритмическом языке каждая константа, переменная, результат вычисления выражения или функции должны иметь определенный тип.
Тип данных определяет:
• внутреннее представление данных в памяти компьютер
• множество значений, которые могут принимать величины этого типа;
• операции и функции, которые можно применять к величинам этого типа.
Исходя из этих характеристик, программист выбирает тип каждой величины, используемой в программе для представления реальных объектов. Обязательное описание типа позволяет компилятору производить проверку допустимости различных конструкций программы. От типа величины зависят машинные команды, которые будут использоваться для обработки данных.
Все типы языка C++ можно разделить на основные и составные. В языке C++ определено шесть основных типов данных для представления целых, вещественных, символьных и логических величин. На основе этих типов программист может вводить описание составных типов. К ним относятся массивы, перечисления, функции, структуры, ссылки, указатели, объединения и классы.
Основные типы данных
Основные (стандартные) типы данных часто называют арифметическими, поскольку их можно использовать в арифметических операциях. Для описания основных типов определены следующие ключевые слова:
• int (целый);
• char (символьный);
• wchar_t (расширенный символьный);
• bool (логический);
• float (вещественный);
• double (вещественный с двойной точностью).
Первые четыре типа называют целочисленными (целыми), последние два — типами с плавающей точкой. Код, который формирует компилятор для обработки целых величин, отличается от кода для величин с плавающей точкой.
Существует четыре спецификатора типа, уточняющих внутреннее представление
и диапазон значений стандартных типов:
• short (короткий);
• long (длинный);
• signed (знаковый);
• unsigned (беззнаковый).
Целый тип (int)
Размер типа int не определяется стандартом, а зависит от компьютера и компилятора. Для 16-разрядного процессора под величины этого типа отводится 2 байта, для 32-разрядного - 4 байта.
Спецификатор short перед именем типа указывает компилятору, что под число требуется отвести 2 байта независимо от разрядности процессора. Спецификатор long означает, что целая величина будет занимать 4 байта. Таким образом, на 16-разрядном компьютере эквиваленты int и short int, а на 32-разрядном — int и long int.
Внутреннее представление величины целого типа — целое число в двоичном коде. При использовании спецификатора signed старший бит числа интерпретируется как знаковый (0 — положительное число, 1 — отрицательное). Спецификатор unsigned позволяет представлять только положительные числа, поскольку старший разряд рассматривается как часть кода числа. Таким образом, диапазон значений типа 1nt зависит от спецификаторов. Диапазоны значений величин целого типа с различными спецификаторами для IBM PC-совместимых компьютеров приведены в табл. 1.4.
По умолчанию все целочисленные типы считаются знаковыми, то есть спецификатор signed можно опускать.
Константам, встречающимся в программе, приписывается тот или иной тип в соответствии с их видом. Если этот тип по каким-либо причинам не устраивает программиста, он может явно указать требуемый тип с помощью суффиксов L, 1 (long) и u, U (unsigned). Например, константа 32L будет иметь тип long и занимать 4 байта. Можно использовать суффиксы L и U одновременно, например, 0x22UL или 05LU.
ПРИМЕЧАНИЕ . Типы short int, long int, signed int и unsigned int можно сокращать до short, long, signed и unsigned соответственно .
Символьный тип (char)
Под величину символьного типа отводится количество байт, достаточное для размещения любого символа из набора символов для данного компьютера таблица ASCII, что и обусловило название типа. Как правило, это 1 байт.
Тип char, как и другие целые типы, может быть со знаком или без знака. В величинах со знаком можно хранить значения в диапазоне от -128 до 127. При использовании спецификатора unsigned значения могут находиться в пределах от 0 до 255. Этого достаточно для хранения любого символа из 256-символьного набора ASCII. Величины типа char применяются также для хранения целых чисел, не превышающих границы указанных диапазонов.
Расширенный символьный тип (wchar_t)
Тип wchar_t предназначен для работы с набором символов, для кодировки которых недостаточно 1 байта, например, Unicode. Размер этого типа зависит от реализации; как правило, он соответствует типу short. Строковые константы типа wchar_t записываются с префиксом L, например, L"Gates".
Логический тип (bool)
Величины логического типа могут принимать только значения true и false, являющиеся зарезервированными словами. Внутренняя форма представления значения false — 0 (нуль). Любое другое значение интерпретируется как true. При преобразовании к целому типу true имеет значение 1.
Типы с плавающей точкой (float, double и long double)
Стандарт C++ определяет три типа данных для хранения вещественных значений: float, double и long double.
Типы данных с плавающей точкой хранятся в памяти компьютера иначе, чем целочисленные. Внутреннее представление вещественного числа состоит из двух частей — мантиссы и порядка. В IBM PC-совместимых компьютерах величины типа float занимают 4 байта, из которых один двоичный разряд отводится под знак мантиссы, 8 разрядов под порядок и 23 под мантиссу. Мантисса — это число, большее 1.0, но меньшее 2.0. Поскольку старшая цифра мантиссы всегда равна 1, она не xранится.
Для величин типа double, занимающих 8 байт, под порядок и мантиссу отводится 11 и 52 разряда соответственно. Длина мантиссы определяет точность числа, а длина порядка — его диапазон. Как можно видеть из табл. 1.4, при одинаковом количестве байт, отводимом под величины типа float и long int, диапазоны их допустимых значений сильно различаются из-за внутренней формы представления.
Спецификатор long перед именем типа double указывает, что под величину отводится 10 байт.
Константы с плавающей точкой имеют по умолчанию тип double. Можно явно указать тип константы с помощью суффиксов F, f (float) и L, 1 (long). Например, константа 2E+6L будет иметь тип long double, а константа 1.82f — тип float.

Для вещественных типов в таблице приведены абсолютные величины минимальных и максимальных значений.
Для написания переносимых на различные платформы программ нельзя делать предположений о размере типа int. Для его получения необходимо пользоваться операцией sizeof, результатом которой является размер типа в байтах. Например, для операционной системы MS-DOS sizeof (int) даст в результате 2, а для Windows 9Х или OS/2 результатом будет 4.
В стандарте ANSI диапазоны значений для основных типов не задаются, определяются только соотношения между их размерами, например:
sizeof(float) < sizeof(double) < sizeof(long double)
sizeof(char) < slzeof(short) < sizeof(int) < sizeof(long)
ПРИМЕЧАНИЕ
Минимальные и максимальные допустимые значения для целых типов зависят от реализации и приведены в заголовочном файле <limits.h> (<c1imits>), характеристики вещественных типов — в файле <float.h> (<cfloat>).
Тип void
Кроме перечисленных, к основным типам языка относится тип void, но множество значений этого типа пусто. Он используется для определения функций, которые не возвращают значения, для указания пустого списка аргументов функции (о функциях мы поговорим позже), как базовый тип для указателей и в операции приведения типов.
Структура программы
Программа на языке C++ состоит из функций, описаний и директив препроцессора. Одна из функций должна иметь имя main – это главная фунукция. Выполнение программы начинается с первого оператора этой функции. Простейшее определение функции имеет следующий формат:
тип_возвращаемого_значения имя_функции ([ параметры функции ] )
{
тело функции
}
Как правило, функция используется для вычисления какого-либо значения, поэтому перед именем функции указывается его тип. О функциях детальнее мы поговорим чуть позже, а ниже приведены лишь самые необходимые сведения:
• если функция не должна возвращать значение, указывается тип void:
• тело функции является блоком и, следовательно, заключается в фигурные скобки;
• функции не могут быть вложенными;
• каждый оператор заканчивается точкой с запятой (кроме составного оператора).
Пример структуры программы, содержащей функции main, fl и f2:
Директивы препроцессора
Прототипы функций f 1 и f 2
Int ma i n()
{
Операторы главной функции
С вызовом функций f 1 и f 2
}
int f 1 ()
{
операторы функции f1
}
int f2 ()
{
операторы функции f2
}
Ввод/вывод в алгоритмическом языке С/С++
В языке C++ нет встроенных средств ввода/вывода — он осуществляется с помощью специальных функций, типов и объектов, содержащихся в стандартных библиотечных файлах (модулях).
Используется два способа ввода/вывода:
1. Функции, унаследованные из языка С;
2. Объекты C++.
Основные функции ввода/вывода в стиле С:
int scanf (<форматная строка>,<адрес>,<адрес>,...); // ввод
int printf(<форматная строка>,<аргумент>,<аргумент>,...) // вывод
Они выполняют форматированный ввод и вывод произвольного количества величин (<адрес> и <аргумент>) в соответствии со строкой формата <форматная строка>.
Форматная строка - это строка, которая начинается и заканчивается двойными кавычками ("вот так") и содержит спецификаторы формата (спецификаторы преобразования), начинающиеся со знака %, которые при вводе или выводе заменяются конкретными величинами.
Целью функции scanf является ввод значения переменных, указанных после <форматной строки>. Однако необходимо помнить, что после <форматной строки> указываются не имена переменных, а их адреса. Для взятия адреса переменной перед ее именем обязательно должен стоять символ &. Напиример:
scanf("%d%d",&a,&b);
Целью функции printf является вывод <форматной строки> на экран. До вывода <аргументы>, указанные в строке, преобразуются в соответствии со спецификаторами формата, указанными в <форматной строке>.
Список наиболее употребительных спецификаций преобразования приведен в таблице.
Дата: 2019-02-02, просмотров: 903.