 |
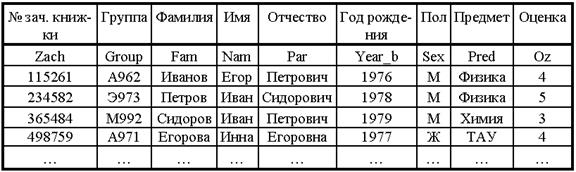
Когда возникает потребность хранить, периодически обновлять и анализировать большие объёмы структурированных данных, то можно использовать картотеку, хранящую записи для каждого студента, таблицу с перечнем всех студентов и предметов и т. д. Однако на практике для таких целей чаще всего используются базы данных (БД). Информация в БД хранится в табличном виде. БД – это, прежде всего, набор таблиц, хотя, в базу данных могут входить так же процедуры и ряд других объектов. Таблица БД представляет собой обычную двумерную таблицу с характеристиками (атрибутами) какого-то множества объектов. Таблица имеет имя – идентификатор, по которому на неё можно сослаться. Например, таблица для хранения информации о студентах может быть представлена в следующем виде (рисунок 16.1).
Рисунок 16.1 – Данные о студентах
Столбцы таблицы соответствуют тем или иным характеристикам объектов – полям.
Каждое поле характеризуется именем и типом хранящихся данных. Имя поля – это идентификатор, который используется в программах для манипуляции данными. Он строится по тем же правилам, как любой идентификатор, т. е. пишется латинскими буквами, состоит из одного слова и т. д. Таким образом, имя – это не то, что отображается на экране или в отчёте заголовка столбца (это отображение можно писать по-русски), а идентификатор, соответствующий этому заголовку. Например, для таблицы введём для последующих ссылок имена полей Zach, Group, Fam, Nam, Par, Year_b, Sex, Pred, Oz, соответствующие указанным в ней заголовкам полей.
Тип поля характеризует тип хранящихся в поле данных. Это могут быть строки, числа, булевы значения, большие тексты, изображения и т. п.
Каждая строка таблицы соответствует одному из объектов. Она называется записью и содержит значения всех полей, характеризующих данный объект.
При построении таблиц БД важно обеспечить непротиворечивость информации. Это делается введением ключевых полей, обеспечивающих уникальность каждой записи. Ключевым может быть одно или несколько полей. В приведённом примере можно было бы сделать ключевыми совокупность полей Fam, Nam и Par. Но в этом случае нельзя было бы заносить в таблицу сведения о полных однофамильцах, у которых совпадают фамилия, имя и отчество. Поэтому целесообразнее использовать поле Zach – номер зачетной книжки, которое можно сделать ключевым, поскольку номер зачетной книжки не может быть одинаковым у двух студентов.
В каждый момент времени есть некоторая текущая запись, с которой ведется работа. Записи в таблице базы данных физически могут располагаться без какого-либо порядка, просто в последовательности их ввода (появления новых студентов). Но когда данные таблицы предъявляются пользователю, они должны быть упорядочены. Для упорядочения данных в БД, так же, как и для упорядочения данных в массивах, используется понятие индекса.
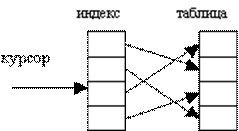
Индекс показывает, в какой последовательности будет просматриваться таблица. Часто индексы хранятся отдельно от файла с данными. Для быстрой сортировки обычно индексы выносят в отдельный индексный файл с тем же названием, но с другим расширением. В таком файле содержатся только первичные ключи и описание очередности записей. Основной же файл при этом остается неупорядоченным. Так как индексный файл намного меньше файла объектов, сортировка по индексу происходит гораздо быстрее, чем сортировка основного файла (рисунок 16.2).
Индексы могут быть первичными и вторичными. Например, первичным индексом могут служить поля, отмеченные при создании таблицы как ключевые. А вторичные индексы могут создаваться для других полей как при создании таблицы, так и впослед
 |
ствии. Вторичным индексам присваиваются идентификаторы, по которым их можно использовать.
Рисунок 16.2 – Перемещение курсора по индексу
Если индекс включает в себя несколько полей, то упорядочение БД сначала осуществляется по первому полю, а для записей, имеющих одинаковое значение первого поля, по второму полю. Например, таблицу о студентах можно проиндексировать по группам, а внутри каждой группы по алфавиту.
Дата: 2019-02-02, просмотров: 404.