Элементы списка называются узлами. Узел представляет собой объект, содержащий в себе указатель на другой объект того же типа и данные. Очевидным способом реализации узла является структура:
 struct TelNum {
struct TelNum {
TelNum * next; //указатель на следующий элемент
long telephon; // данные
char name[30]; // данные
};
TelNum *temp = new TelNum; - создается новый узел.
Список представляет собой последовательность узлов, связанных указателями, содержащимися внутри узла. Узлы списка создаются динамически в программе по мере необходимости с помощью соответсвующих функций и располагаются в различных местах динамической памити. При уничтожении узла память обязательно освобождается.
Простейшим списком является линейный или однонаправленный список. Признаком конца списка является значение указателя на следующий элемент равное NULL. Для работы со списком должен существовать указатель на первый элемент - заголовок списка. Иногда удобно иметь и указатель на конец списка.
Указатель
заголовок
Основными операциями, производимыми со списками, являются обход, вставка и удаление узлов. Можно производить эти операции в начале списка, в середине и в конце.
Вставка узла
 a) в начало списка
a) в начало списка
start
temp
temp->next = start;
start = temp;
 b) в середину списка
b) в середину списка
start current
temp
temp->next = current->next;
current->next = temp;
a)  в конец списка
в конец списка
end temp
end->next = temp;
end = temp;
end->next = NULL;
Удаление узла из списка
a) первого узла
start

TelNum *del = start;
start = start->next;
delete del;
b) В середине писка

current del
TelNum *del = current->next;
current->next = del->next;
delete del;
c) в конце списка
 current end
current end
TelNum *del = end;
current->next=NULL;
delete del;
end = current;
Алгоритмы, приведенные выше, обладают существенным недостатком - если необходимо произвести вставку или удаление ПЕРЕД заданным узлом, то так как неизвестен адрес предыдущего узла, невозможно получить доступ к указателю на удаляемый (вставляемый) узел и для его поиска надо произвести обход списка, что для больших списков неэффективно. Избежать этого позволяет двунаправленный список, который имеет два указателя: один - на последующий узел, другой - на предыдущий.
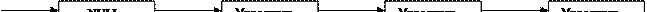
start
NULL
// Пример программы работы с односвязным списком
#include <stdio.h>
#include <conio.h>
struct TelNum;
int printAllData(TelNum * start);
int inputData(TelNum * n);
struct TelNum
{
TelNum * next;
long number;
char name[30];
};
// Описание: печать списка
int printAllData(TelNum * start){
int c=0;
for(TelNum * t=start;t; t= t->next)
printf("#%3.3i %7li %s\n",++c,t->number,t->name);
return 0;
}
// Описание: ввод данных в структуру n конец ввода - ввод нуля
// в первое поле. Возвращает 1 если конец ввода
int inputData(TelNum * n){
printf("Номер?"); scanf("%7li",&n->number);
if(!n->number) return 1;
printf("Имя? "); scanf("%30s",&n->name);
return 0;
}
void main(void){
TelNum * start = NULL; //сторож
TelNum * end = start;
do{ //блок добавления записей
TelNum * temp = new TelNum;
if(inputData(temp)) {
delete temp;
break;
}
else {
if(start==NULL) {
temp->next = start;
start = temp;
end = temp;
}
else {
end->next=temp;
end=temp;
end->next=NULL;
}
}
}while(1);
printf("\nЗаписи после добавления новых:\n");
printAllData(start);
getch();
do{ //блок удаления записей
TelNum * deleted = start;
start = start->next;
delete deleted;
printAllData(start);
getch();
}while(start!=NULL);
}
Бинарные деревья
В бинарном дереве каждый узел содержит 2 указателя. Начальная точка бинарного дерева называется корневым узлом.

Корневой узел Е указывает на В и Н. Узел В является корневым узлом для левого поддерева Е, узел Н – для правого поддерева Е. За исключением самого нижнего яруса каждый узел бинарного дерева имеет одно или два поддерева.
Обычно левое поддерево содержит меньшие данные, правое большие, что ускоряет поиск информации. Дерево такого типа называется деревом бинарного поиска.
Поиск обычно начинается с корня. В зависимости от результата сравнения двигаются либо влево (если данные узла больше образца поиска), либо вправо (если меньше). Новые узлы всегда присоединяются к нижним вершинам, так что дерево всегда растет вниз.
Чтобы распечатать бинарное дерево можно использовать алгоритм, называемый обратным ходом. Простейший алгоритм - рекурсивный. При заданном корне, программа совершает 3 шага:
а) выполняет обход левого поддерева;
б) печать корня;
в) выполняет обход правого поддерева.
Если обнаружен указатель NULL, то продвижение в направлении обхода в данном поддереве прекращается.
При прямом обходе содержимое корня печатается до обхода поддеревьев.
При концевом обходе содержимое корня печатается после совершения обхода двух поддеревьев.
// Пример программы работы с бинарным деревом
#include <stdio.h>
#include <conio.h>
#include <string.h>
struct TelNum;
void printtreepre(TelNum * ); //обход с корня дерева, левое поддерево, правое поддерево
void printtreein(TelNum * ); //обход с вершины правое поддерево,корень, левое поддерево
void printtreepost(TelNum * ); //обход с вершины левое поддерево, правое поддерево,корень
int inputData(TelNum * );
TelNum * addtree(TelNum *, TelNum *);
struct TelNum
{
TelNum * left, *right;
long number;
char name[30];
};
// Описание: печать списка
void printtreepre(TelNum * root)
{
if(!root) return;
if(root->number)
printf("номер %7li фамилия %s\n",root->number,root->name);
printtreepre(root->left);
printtreepre(root->right);
}
void printtreein(TelNum * root)
{
if(!root) return;
if(root->number)
printtreein(root->left);
printf("номер %7li фамилия %s\n",root->number,root->name);
printtreein(root->right);
}
void printtreepost(TelNum * root)
{
if(!root) return;
if(root->number)
printtreepost(root->left);
printtreepost(root->right);
printf("номер %7li фамилия %s\n",root->number,root->name);
}
// Описание: ввод данных
int inputData(TelNum * n)
{
printf("Номер?"); scanf("%7li",&n->number);
if(!n->number) return 1;
printf("Имя? "); scanf("%30s",&n->name);
return 0;
}
// Добавление узла к дереву
TelNum * addtree(TelNum *root, TelNum *temp) {
if(root==NULL) { //добавление узла в вершину дерева
TelNum * root = new TelNum;
root->number=temp->number;
strcpy(root->name,temp->name);
root->left=NULL;
root->right=NULL;
return root;
}
else {
if(root->number>temp->number)
root->left=addtree(root->left,temp);
else root->right=addtree(root->right,temp);
}
return root;
}
// Поиск значения в бинарном дереве
//по номеру телефона
void searchtree(TelNum *root, int num) {
while (root!=NULL) {
if(root->number==num) {
printf("номер %7li фамилия %s\n",root->number,root->name);
return ;
}
else{
if(root->number>num)
root=root->left;
else root=root->right;
}
}
puts("Телефон не найден");
return ;
}
void main(void)
{
TelNum * start = NULL; //сторож
TelNum * temp = new TelNum;
do{ //блок добавления записей
if(inputData(temp))
{delete temp;
break;
}
else
start=addtree(start,temp);
}while(1);
printtreepre(start); //ebcahgi
getch();
printtreein(start); //ighebca
getch();
printtreepost(start); //acbighe
getch();
int num;
puts("Введите номер телефона");
scanf("%d",&num);
searchtree(begin,num);
}
РАЗМЕЩЕНИЕ ДАННЫХ В ПАМЯТИ
Данные могут храниться в регистрах процессора, в области статической памяти, в области организованной как стек и в динамической памяти.
Статическая память - данные размещаются в ней после компиляции и хранятся до конца. В стеке - временно.
Динамическая память "куча" используется в зависимости от выбранной модели памяти. Различают "ближнюю кучу" - неиспользованную часть сегмента стека и "дальнюю кучу" - оставшаяся свободная память машины. В начале блока выделяемой памяти записывается его размер. Он затем используется при удалении.
Вся оперативная память логически разбита на сегменты. Для обращения к сегментам используются 4 специальных регистра микропроцессора для хранения адресов сегментов:
CS – сегмент кода программы,
DS – сегмент статических данных программы,
SS – сегмент стека для временных переменных,
ES - дополнительный сегмент статических данных.
Для оптимизации управления памятью имеется 7 моделей памяти. Размещением данных в памяти управляет программист. Адрес любого участка памяти состоит из смещения и сегмента. Полный (физический) адрес для чтения и записи данных в память получается: адрес сегмента * 16 + смещение.
Организация процессора I8086 накладывает ограничения на размер статистической памяти программы - размер кодов функций и размер статических данных. Размер данных не более 64 Кб в одном сегменте, т.к. размер адресуемой памяти ПЭВМ равен 1 Мб.
Существует 2 варианта построения программы:
А) весь исходный текст компилируется сразу;
Б) программа собирается из нескольких фрагментов (модулей), которые компилируются отдельно. В любом таком модуле свой сегмент данных и сегмент кода. Объединение сегментов может происходить по-разному – в зависимости от используемого метода настройки сегментных регистров CS и DS. Может быть так, что независимо от количества модулей настройка CS, DS выполняется только однажды - тогда размер кода должен быть меньше 64 Кбайт.
Распределение данных по сегментам и управление перехода от сегмента к сегменту берет на себя компилятор. Для каждого модуля можно выделить более одного сегмента статических данных и кода.
Для "малых" моделей все указатели типа near, для больших - far. Указатели на функции для моделей tiny, small,compact - near, в остальных - far. Если все функции в одном файле, то все указатели типа near. Если несколько модулей, но они не обращаются друг к другу, тоже самое. Но если есть обращения функций одного модуля к функциям другого, они должны быть описаны как far функции.
void near fn (int arg);
fn (1);
При вызове функции из другого сегмента адрес возврата состоит из адреса сегмента и смещения
void far ff(int arg);
ff(2);
МОДЕЛИ ПАМЯТИ
C++ поддерживает 7 моделей памяти: tiny, small, medium, compact, large, huge, flat. Для каждой модели различается количество сегментов отведенных под код программы и данных. Рассмотрим эти модели.
1. Крошечная модель T iny - 64 Кбайта код программы и данные
 CS,DS,SS
CS,DS,SS
SP
2. Малая модель S mall – 64Кбайта код программы и 64 Кбайта данные
CS
DS,SS
SP
3. Средняя модель M edium – 1 Мбайт код программы и 64 Кбайта данные
 CS
CS
DS,SS
SP
4. Компактная модель Compact - 64Кбайта код программы и 1 Мбайт данные
 CS
CS
DS
SS
SP
5.Большая модель Large – 1 Мбайт код программы и 1 Мбайт данные

CS
DS
SS
SP
6. Гигантская модель Huge - 1 Мбайт код программы и 1 Мбайт данные
 CS
CS
DS
SS
SP
7.Плоская модель Flat.
Модель Flat соответствует варианту модели Small, но используется 32 разрядные смещения (суммарная длина адреса 6 байт). Эта модель используется только для МП 386 и выше. В этом случае с помощью одного регистра обеспечивается доступ ко всей физической памяти. Хотя регистры DS, SS, ES отличаются, они фактически указывают на один физический адрес начала сегмента (дескрипторы имеют одинаковый адрес и длину сегмента, но разные права доступа к элементам памяти внутри сегмента). Эта модель используется для программ для Windows.
Размер кода или данных ограничен адресной памятью (1 Мбайт).
tiny 64 Кб всего
small 64 Кб кода и 64 Кб данные
medium 1Мб код, 64 Кб данные
compact 64 Кб код, 1Мб данные
large 1Мб код, 1Мб данные
huge тоже что large, но размер статических данных может превышать 64 Кб.
В huge для статистических данных выделяют более 1 сегмента.
int far array [30000]; //массив создается в новом сегменте данных
char far a [70000]; // ошибка более 64кб.
char huge b[70000]; // верно.
Для совместной компляции нескольких модулей создается файл-проект. Проект создается через пункт меню Project - проект, где указываются все компилируемые файлы. Для этого используется подпункт меню:
Open Project -> Insert - добавить модуль
Delete - удалить модуль
СПИСОК ЛИТЕРАТУРЫ
1. М. Уэйт, С. Прайт, Д. Мартин. Язык СИ. - М.: "Мир", 1988 г.
2. Кеpниган Б., Ритчи Д. Язык пpогpаммиpования Си. - М.: Финансы и статистика, 1992г.
3. Кузнецов С.Д. Турбо Си. - М.: Малип, 1992г.
4. П. Киммел Borland C++ 5.0. – C-П.: «BHV-Cанкт Питербург», 1997 год.
5. Цимбал А.А.,Майоров А.Г., Козодаев М.А. Turbo C++: язык и его применение. – М.: «Джен Ай Лтд», 1993 г.
Дата: 2018-12-21, просмотров: 669.