ОСНОВЫ АЛГОРИТМИЗАЦИИ И ПРОГРАММИРОВАНИЯ.
ЯЗЫК С /С++. СТРУКТУРНЫЙ ПОДХОД
Краткий курс лекций
Тирасполь 2000
СОДЕРЖАНИЕ
1. ОБЗОР ЯЗЫКа ПРОГРАММИРОВАНИЯ С. 5
2. ЭТАПЫ СОЗДАНИЯ ПРОГРАММЫ.. 5
3. СТРУКТУРА ПРОГРАММЫ НА ЯЗЫКЕ СИ. 6
3.1. Внутренняя структура программы. 6
3.2. Пример программы на СИ. 6
4. БАЗОВЫЕ ЭЛЕМЕНТЫ ЯЗЫКА СИ. 7
5. ДАННЫЕ В ПРОГРАММЕ НА СИ. 8
5.1. Константы. 8
5.2. Базовые стандартные типы переменных. 9
6. ОПЕРАЦИИ ЯЗЫКА СИ. 11
6.1. Арифметические операции. 11
6.2. Операции отношения. 12
6.3. Логические операции. 12
6.4. Операции с разрядами. 13
6.5. Операции сдвига. 13
6.6. Операция условия ?: 14
6.7. Преобразование типов. 14
6.8. Операции приведения. 14
6.9. Дополнительные операции присваивания. 15
7. ОПЕРАТОРЫ ЯЗЫКА СИ. 15
8. СТАНДАРТНЫЕ ФУНКЦИИ ВВОДА И ВЫВОДА. 22
8.1. Функция вывода данных на экран printf () 22
8.2. Модификаторы спецификаций преобразования. 23
8.3. Функция ввода данных с клавиатуры sсanf() 23
8.4. Функции ввода/вывода одного символа getchar(), putchar() 24
8.5. Функции небуфиризированного ввода с клавиатуры. 24
8.6. Ввод/вывод в поток в С++. 24
8.7. Форматирование вывода. 25
9. МАССИВЫ.. 26
9.1. Одномерные массивы. 26
9.2 Многомерные массивы. 28
10 ФУНКЦИИ. 30
10.1 Cоздание и использование пользовательских функций. 31
10.2 Параметры функции. 32
10.3 Возвращение значения функцией. 33
10.4 Inline-функции. 33
10.5 Значение формальных параметров функции по умолчанию.. 33
10.6 Перегрузка функций. 34
11 КЛАССЫ ПАМЯТИ И ОБЛАСТЬ ДЕЙСТВИЯ. 35
11.1 Глобальные переменные. 35
11.2 Локальные переменные. 36
11.3 Доступ к функциям в многомодульной программе. 37
12 ПРЕПРОЦЕССОР ЯЗЫКА СИ. 39
12.1 Подстановка имен. 39
12.2 Включение файлов. 40
12.3 Условная компиляция. 40
13 УКАЗАТЕЛИ. 41
13.1 Операция косвенной адресации * 41
13.2 Описание указателей. 41
13.3 Использование указателей для связи функций. 42
13.4 Указатели на одномерные массивы. 42
13.5 Указатели на многомерные массивы. 43
13.6 Операции над указателями. 43
13.7 Передача массива в качестве параметра в функцию.. 44
13.8 Указатель на void * 45
14 СИМВОЛЬНЫЕ СТРОКИ И ФУНКЦИИ НАД СТРОКАМИ. 46
14.1 Массивы символьных строк. 46
14.2 Массивы указателей. 47
14.3 Указатель как возвращаемое значение функции. 47
Передача указателя как параметра функции. 47
14.4 Функции, работающие со строками. 48
14.5 Стандартные библиотечные функции. 48
14.6 Преобразование символьных строк. 49
15 ССЫЛКИ. 50
16 Параметры КОМАНДНОЙ СТРОКИ. 51
17 ПРОИЗВОДНЫЕ ТИПЫ ДАННЫХ. 52
17.1 Структуры. 52
17.2 Объединения. 56
17.3 Синоним имени типа. 56
17.4 Определение именнованных констант. 57
17.5 Перечисления. 57
17.6 Битовые поля. 58
18 ДИНАМИЧЕСКОЕ ВЫДЕЛЕНИЕ ПАМЯТИ. 59
18.1 Операция new и delete в С++. 60
18.2 Операция new с массивами. 61
18.3 Инициализаторы с операцией new. 61
18.4 Ошибки при использовании динамичской памяти. 62
19 ФАЙЛ. 64
19.1 Открытие файла fopen() 64
19.2 Закрытие файла fclose() 64
19.3 Функции ввода/вывода одного символа fgetc(), fputc() 64
19.4 Функции форматированного ввода/вывода в файл. 65
19.5 Функции ввода/вывода строки символов в файл. 65
19.6 Функции управления указателем в файле. 66
19.7 Ввод/вывод записей фиксированной длины. 66
20 ДИНАМИЧЕСКИЕ СТРУКТУРЫ ДАННЫХ. 68
20.1 Однонаправленные связные списки. 68
20.2 Бинарные деревья. 71
21 РАЗМЕЩЕНИЕ ДАННЫХ В ПАМЯТИ. 74
22 МОДЕЛИ ПАМЯТИ. 75
ЭТАПЫ СОЗДАНИЯ ПРОГРАММЫ
1) Программа готовится с помощью любого текстового редактора и запоминается в исходном файле с расширением *.С, *.СРР.
2) Преобразуется компилятором в объектный файл *.obj.
3) Вместе с другими объектными файлами преобразуется в исполняемый файл программой, называемой загрузчиком или редактором связей *.EXE.
Этот файл уже может быть исполнен компьютером.
СТРУКТУРА ПРОГРАММЫ НА ЯЗЫКЕ СИ
Программа на языке Си определяется как совокупность одного или нескольких модулей. Модулем является самостоятельно компилируемый файл. Модуль содержит один или несколько функций. Функция состоит из операторов языка Си. Рис.1.
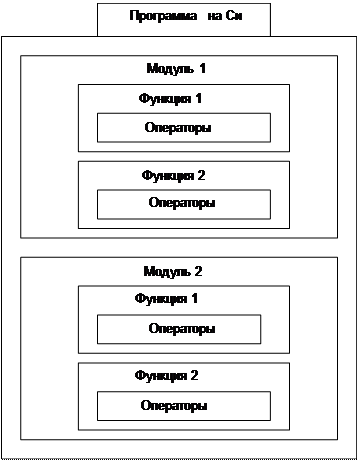 |
Рис.1 Структура программы на языке Си.
Пример программы на СИ
 заголовок
заголовок
# include < stdio.h > //включение файла
void main (void) /*пример*/- имя функции и комментарии
{
тело функции
 int num;
int num;
num = 1;
printf("пример программы"); // вывод на экран
printf("на Си");
} // конец тела функции
Программа Си всегда имеет функцию main(). С нее начинается выполнение программы.
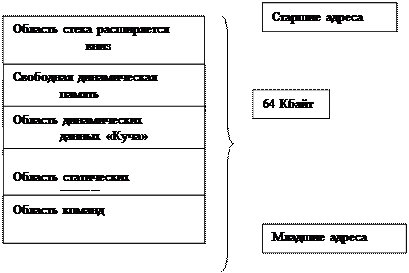 |
Рис.2. Внутренняя структура программы на Си.
БАЗОВЫЕ ЭЛЕМЕНТЫ ЯЗЫКА СИ
1. Комментарии – используются для документирования программы.
§ // - далее все игнорируется до конца строки.
§ /* Текст */ - в любом месте программы
§ /* Строка 1 - для комментария любой длины
строка 2
строка 3
*/
2. Идентификатор - это имя, которое присваивается какому-либо объекту (переменной). Используются строчные и прописные английские буквы, цифры и знак подчёркивания. Строчные и прописные буквы различаются. Начинаются с буквы или знака подчеркивания. Длина не ограничена.
В современном программировании часто используется для создания идентификаторов Венгерская нотация. Например: WordParametrFormat или Word_Parametr_Format.
3. Служебные слова – это слова, с которыми в языке жестко сопоставлены определённые смысловые значения и которые не могут быть использованы для других целей. Это имена операторов, команды препроцессора и так далее.
ДАННЫЕ В ПРОГРАММЕ НА СИ
Каждая программа оперирует в программе с данными. Они присутствуют в программе в виде переменных и констант.
Данные, которые могут изменяться или которым может присваиваться значения во время выполнения программы, называются переменными.
Данные, которым устанавливаются определенные значения и они сохраняют свои значения на всем протяжении работы программы, называются константами.
Константы
Константы - это фиксированные значения. Значение, будучи установлено, больше не меняется.
Типы констант:
a) Целые и длинные целые. Записываются в десятичной, восьмеричной и шестнадцатеричной системе счисления.
Десятичная система:
Размер: Диапазон чисел:
16 битов ± 32768 знаковое
0 – 65535u беззнаковое - (unsigned)
32 бита ± 2147483648l знаковое длинное – (long)
0 – 4294967295ul беззнаковое длинное - (unsigned long )
Пример: 12, 12567, 24u, 135l, 4567ul
Восьмеричная система:
Если число начинается с цифры 0, оно интерпретируется как восьмиричное число
16 битов 0 ¸ 077777
0100000 ¸ 0177777u
32 бита 0200000 ¸ 01777777777l
020000000000 ¸ 037777777777ul
Пример: 0674
Шестнадцатеричная система:
Если число начинается с символа 0х, то оно интерпретируется как шестнадцатиричное
16 битов 0x0000 ¸ 0x7FFF
0x8000 ¸ 0xEFFFu
32 бита 0x10000 ¸ 0x7FFFFFFFl
0x80000000 ¸ 0xFFFFFFFFul
Пример: 0х3D4
b ) Вещественные константы. Это числа с плавающей точкой. Значение имеет дробную часть. По умолчанию все вещественные константы имеют тип двойной точности double. Занимают в памяти 8 байт. Диапазон значений ± 1 e ±308.
Принудительно можно задать формат одинарной точности. Число будет занимать 4 байта. (5.75 f)
А также расширенной точности – 10 байт. (3.14L)
Знак + можно не писать. Разрешается опускать либо десятичную точку, либо экспоненциальную часть, но не одновременно (.2; 4е16). Можно не писать дробную либо целую часть, но не одновременно (100.; .8е-5)
c) Символьные константы. Это набор символов, используемых в ЭВМ.
Делятся на 2 группы: печатные и непечатные (управляющие коды). Символьная константа включает в себя только 1 символ, который необходимо заключить в апострофы и занимает 1 байт памяти.
Любой символ имеет своё двойное представление в таблице ASCII
Символ 'А' 'a' ' ' '\n'
Его код 65 97 32 10
Как целый тип данных 'A'=01018, 010000012, 4116, 6510.
Управляющие коды начинаются с символа \ и тоже заключаются в апострофы. Наиболее распространенные управляющие коды:
\n – переход на новую строку
\t – табуляция (сдвиг курсора на некоторое фиксированное значение)
\b – шаг назад (сдвиг на одну позицию назад)
\r – возврат каретки (возврат к началу строки)
\f – подача бланка (протяжка бумаги на 1 страницу)
\\ - слеш
\’ - апостроф
\” - кавычки
Последние три знака могут выступать символьными константами, а также применяться в функции вывода на экран printf() , поэтому применение их в качестве символов может привести к ошибке. Например, если мы хотим вывести строку «Символ \ называется слеш», то оператор должен выглядеть так:
рrintf( «Символ \\ называется слеш»
d) Строковые константы - содержат последовательность из 1 и более символов,
заключённых в " ". Расходуется по 1 байту на любой символ + 1байт на так называемый ноль-символ - признак конца строки. Ноль-символ – не цифра ноль, он означает, что количество символов в строке (N) должно быть на 1 байт больше (N+1), чтобы обозначать конец строки.
ОПЕРАЦИИ ЯЗЫКА СИ
Операции в языке Си применяются для представления арифметических выражений. Насчитывается около 40 операций и 16 приоритетов. Величина, над которой выполняется операция, называется операндом. Операции могут быть унарные (один операнд), бинарные (два операнда) и тернарные.
Арифметические операции
Можно выполнять действия над переменными, переменными и константами, константами.
Самый высокий приоритет у скобок ()
1) Изменение знака - r = -12; -r (2)
2) Умножения * сm = 2,54 *in; (3)
3) Деления / var = 12.0 / 3.0; (3)
Операции отношения
Меньше <, (7) Больше или равно > =, (7)
Меньше или равно <=, (7) Не равно != (8)
Больше > (7) Равно = = . (8)
Используются для сравнения в условных выражениях. Вырабатывают значения «истина» и «ложь».
Не следует путать знаки = и = =. С помощью операции присваивания (=) некоторой переменной слева от этого знака присваивается значение. А с помощью операции отношений (= =) проверяется равенство выражений, стоящих слева и справа от этого знака.
Все операции отношений возвращают результат «истина» или «ложь» (0 или 1). Значение переменных при этом не изменяется.
При сравнении float лучше пользоваться только операциями < и >, т.к. ошибки округления могут привести к тому, что числа окажутся неравными, хотя по логике они должны быть равны. (например 3*1/3 равно 1,0, но 1/3 в вещественном формате будет представлена как 0,999999…, и произведение не будет равно 1)
Приоритет больше чем у операции присваивания, но меньше чем у +, -.
y > x+2; - сначала сложение, затем сравнение.
Логические операции
Используются для проверки условия, вырабатывая значение истина или ложь.
1) && "И" (операция логического умножения.)
Выражение истинно только в том случае, если истинны выражения, стоящие до и после &&. Если первое – ложь, то дальше не проверяется. (12)
2) || "ИЛИ" (логическое сложение.)
Выражение истинно, если одно из выражений истинно. Если первое – истина, дальше не проверяется (13)
3) ! "НЕ" (отрицание) (2)
Булева логика:
| x | y | && | || | ! |
| 0 | 0 | 0 | 0 | 0 11 |
| 0 | 1 | 0 | 1 | |
| 1 | 0 | 0 | 1 | 0 |
| 1 | 1 | 1 | 1 |
Примеры:
if(x>0 && x<10) действие
5>2 && 4>7 - ложь
5>2 || 4>7 - истина
!(4>7) – истина
У операции ! (НЕ) очень высокий приоритет (выше только у скобок). && и || выше присваивания, но ниже чем отношения.
a>b && b>c || b>d
((a>b) && (b>c) || (b>d))
Операции с разрядами
Поразрядные логические операции. Приводят к изменению значения переменной. Действия производятся над данными класса целых и char. Они называются поразрядными, потому что они выполняются отдельно над каждым разрядом независимо от разряда, находящегося слева или справа.
1) ~ Дополнение до 1 или поразрядное отрицание. Это унарная операция изменяет каждую 1 на 0, а 0 на 1.
~(11010) получим (00101)
2) & Поразрядное И служит для сбрасывания битов. Эта бинарная операция сравнивает последовательно разряд за разрядом два операнда. Результат равен 1, если оба соответствующих разряда операндов равны 1
(10010011) & (00111101) => (00010001)
3) | Поразрядное ИЛИ служит для установки битов. Эта бинарная операция сравнивает последовательно разряд за разрядом два операнда. Результат равен 1, если один (или оба) из соответствующих разряда операндов равен 1.
(10010011) | (00111101) => (10111111)
4) ^ Исключающее ИЛИ. Результат равен 1, если один из разрядов равен 1 (но не оба)
(10010011) ^ (00111101) => (10101110)
Операции сдвига
Операции сдвига осуществляют поразрядный сдвиг операнда. Величина сдвига определяется значением правого операнда. Сдвигаемые разряды теряются. При сдвиге вправо знаковый разряд размножается.
1) << сдвиг влево Разряды левого операнда сдвигаются влево на число позиций, указанное правым операндом. Освобождающиеся позиции заполняются нулями, а разряды, сдвигаемые за левый предел левого операнда, теряются.
(10001010)<<2 = = 00101000
2) >> сдвиг вправо Разряды левого операнда сдвигаются вправо на число позиций, указанное правым операндом. Разряды, сдвигаемые за правый предел левого операнда, теряются. Для беззнаковых чисел освобожденные слева разряды заполняются нулями. Для чисел со знаком левый разряд принимает значение знака.
(10001010)>>2 = = 00100010
Эти операции выполняют эффективное умножение и деление на степени 2:
number<<n – умножает number на 2 в n-й степени
number>>n – делит number на 2 в n-й степени
6.6. Операция условия ?:
Операция состоит из двух частей (? и :) и содержит три операнда (операнд1 ? операнд2 : операнд 3). Это более короткий способ записи оператора if else и называется «условным выражением».
Например: условное выражение x = (y<0)? –y : y; означает, что если у меньше 0, то х = -у, в противном случае х = у. В терминах оператора if else это выглядело бы так:
if(y<0)
x = -y;
else
x = y;
Условные выражения более компактны и приводят к получению более компактного машинного кода.
Т.о. если условие операнда 1 истинно, то значением условного выражения является величина операнда 2, если условие операнда 1 ложно – величина операнда 2.
Условное выражение удобно использовать, когда имеется некоторая переменная, которой можно присвоить одно из двух возможных значений.
max = (а>b) ? a : b;
6.7. Преобразование типов
В операторах и выражениях должны быть данные одного и того же типа. Но на Си возможно это нарушить (в отличии от Паскаля). Си компилятор автоматически преобразует типы, но следует соблюдать определенные правила:
1.Если производится операция над данными 2-х разных типов, то обе величины приводятся к высшему типу (происходит "повышение" типа).
2. Типы от высшего к низшему: double, float, long, int, short, char. Применение слова unsigned повышает ранг соответствующего типа со знаком.
3. В операторе присваивания конечный результат вычисления выражения в правой части приводится к типу переменной, которой должно быть присвоено это значение ( при этом может быть как повышение так и понижение типа). "Понижение" типа приводит к отбрасыванию разрядов.
4. При вычислениях величин типа float они автоматически преобразуются в тип double (для сохранения точности вычислений, это уменьшает ошибку округления). Конечный результат преобразуется обратно в float, если это диктуется оператором описания.
Операции приведения
Хотя в СИ и возможно преобразование типов, лучше избегать этого и указывать точно тип данных. Это называется привидением типов.
int num;
num = 1,6+1,7; 3,3 => 3. Сначала числа складываются, затем результат приводится к указанному типу.
num = (int)1,6+(int)1,7; 1+1 = 2. В это случае, числа сначала приведены к данному типу, а затем складываются.
ОПЕРАТОРЫ ЯЗЫКА СИ
Основу программы на Си составляют выражения, а не операторы. Большинство операторов в программе являются выражениями с ‘;’. Это позволяет создавать эффективные программы.
Оператор является законченной конструкцией языка Си. Операторы служат основными конструкциями при построении программы. Выражение состоит из операций и операндов (операнд – то, над чем выполняется операция, простейшее выражение может состоять из одного операнда). Оператор служит командой компьютеру. Операторы бывают простые и составные. Простые операторы оканчиваются ‘;’ .
Простые операторы:
1. Пустой оператор ‘;’
2. Оператор описания int x, y;
3. Оператор присвоения count = 0.0;
4. Оператор выражение (управляющий оператор)
sum = sum+count;
var = (var + 10)/4;
5. Оператор вызова функции
printf("Привет \n");
6. Оператор следоаания ‘,’
x=7, y=10;
Составные операторы или блоки:
Это группа операторов, заключенных в фигурные скобки {...}.
7. Оператор ветвления if ... else .
If (условное выражение1)
оператор1;
If (условное выражение2)
оператор1;
}
else оператор2;
// Пример задачи на использование оператора
#include <stdio.h>
#define LIMIT 12600
#define MAX 25200
#define NORMA 60
#define PEOPLE 20
void main(void)
{
float kwh; //количество киловат
float bill; // плата
int p,house;
printf("Укажите количество израсходованных кВт/ч.\n);
scanf("%f",&kwh);
printf("Укажите количество человек в семье.\n);
scanf("%d",&p);
house=NORMA+PEOPLE*p;
if(kwh<=house)
bill=kwh*LIMIT;
else
bill= house*LIMIT + (kwh-house)*MAX;
printf("Плата за %f составляет %f.\n",kwh,bill);
}
Операторы цикла while
Цикл – это многократно повторяющиеся действия или группа действий.
Операторы цикла могут быть трех видов: с предусловием, с постусловием, со счетчиком.
а) с предусловием:
Оператор while состоит из трех частей: это ключевое слово while, затем в круглых скобках указывается проверяемое условие, и тело цикла - оператор, который выполняется, если условие истинно (таких операторов может быть несколько, тогда они заключаются в {} и получается составной оператор). Если оператор один, то действие оператора while распространяется от ключевого слова while до ‘;’.
while (условное выражение) или while (условное выражение){
оператор; операторы;
}
Схема выполнения цикла
 |
while Истина
Ложь (переход к следующей операции)
Тело цикла может состоять из нескольких операторов. В этом случае оно заключается
в фигурные скобки.
Пример 1: Пример 2:
index = 0; index = 0;
while (index++ < 10) while (index++ < 10) {
sum = 10*index + 2; sum = 10*index + 2;
printf ("sum = % d \n", sum); printf ("sum = % d \n", sum);
}
В примере 1 в цикл включен только один оператор присваивания. Печать данных будет производиться только 1 раз – после завершения цикла (будет выведено – sum=102). В примере 2 в цикл включено два оператора, поэтому печать результатов будет выводиться на каждом шаге работы цикла.
В операторе цикла с предусловием, решение о прохождении цикла принимается до прохождения цикла. Поэтому возможно, что цикл никогда не будет пройден.
Последовательность действий, состоящая из проверки выражения и выполнения оператора, периодически повторяется до тех пор, пока выражение не станет ложным. Каждый такой шаг называется «итерацией».
//Пример программы с циклом while
#include <stdio.h>
void main(void)
{
int guess=1;
char res;
printf("Задумайте число от 1 до 100. Я попробую его угадать");
printf("\n Отвечайте д, если моя догадка верна и”);
printf( «\n н, если я ошибаюсь.\n»);
printf("Итак ваше число %d?\n", guess);
while((res=getchar()) != 'д')
if(res!='\n')
printf("Тогда оно равно %d?\n", ++guess);
printf("Ура, я угадала!!!");
}
б) Оператор цикла с постусловием (истинность условия проверяется после выполнения каждой итерации цикла. Решение, выполнять или нет очередной раз тело цикла, принимается после выполнения всех итераций). Этот цикл всегда выполняется хотя бы 1 раз.
do или do {
оператор; операторы;
while (условное выражение); } while (условное выражение);
Проверка истинности осуществляется после выполнения оператора или блока операторов. Хотя бы один раз этот цикл будет выполнен.
Схема выполнения цикла
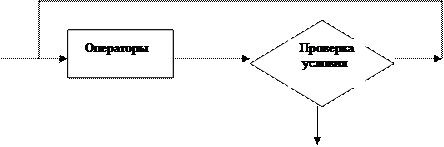 |
Do while Истина
Ложь
Рассмотрим два примера:
Пример 1 Пример 2
do { while((ch = getchar()) ! = '\n')
ch = getchar(); putchar (ch);
putchar (ch);
} while(ch ! = '\n')
Функция getchar() получает один символ, поступающий с клавиатуры и передает его программе, аргументов она не имеет. Функция putchar получает один символ, поступающий из программы, и пересылает его для вывода на экран, эта функция имеет один аргумент, т.е. в скобках необходимо указывать символ, который будет выведен на печать. Можно использовать эту функцию в следующем виде: putchar(getchar()) – эта запись компактна и не требует введения вспомогательных переменных.)
Во втором примере на экран будут выводиться все символы до появления символа «новая строка». А в первом примере будут выводиться все символы, включительно и символ «новая строка» (только после печати этого символа, если он введен, в цикле производится проверка символа «новая строка» и действие цикла завершается).
Цикл выполняется хотя бы один раз, так как проверка осуществляется только после его завершения.
в) Оператор цикла со счетчиком
for (выр1; выр2; выр3) или for (выр1; выр2; выр3) {
оператор; операторы;
}
Выр1 – инициализация, проводится только 1 раз в начале цикла.
Выр2 - проверка условия окончания цикла (производится перед каждым возможным выполнением тела цикла. Когда выражение становится ложным, цикл завершается).
Выр3 – наращивание счетчика цикла (выражение вычисляется в конце каждого выполнения тела цикла).
Схема выполнения цикла
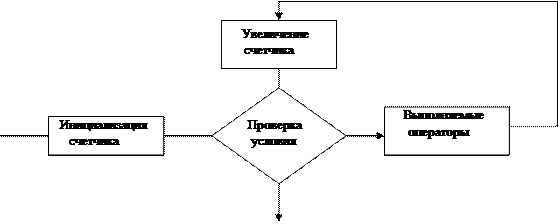 |
for Истина
Ложь
Если какое-либо из выражений отсутствует, то ‘;’ все равно ставится. Могут отсутствовать все выражения, и тогда цикл бесконечен. Цикл for очень многообразен.
Примеры:
1). for (n = 1; n < 1000; n++) ; счет в порядке возрастания
2). for ( i = 10; i > 0; i--) ; счет в порядке убывания
3). for (n = 2; n < 60; n = n + 12) ; значение переменной n будет увеличиваться на 12 при каждом выполнении тела цикла (после этой команды можно ввести printf(“%d\n”,n) и тогда на экран будут выводиться числа 2,14,26,38,50,62)
4). Можно вести подсчет с помощью символов:
for (ch = 'a'; ch <= 'z'; ch++) ;
printf(«Величина кода ASCII для %c равна %d.\n», ch, ch);
на печать будут выведены все буквы от a до z вместе с их кодами ASCII.
5). Наращивание может происходить и после выполнения действий в выражениях (значение переменных будет меняться при каждой итерации):
for (x = 1; y <= 75; y = 5*(x++)+10) ;
for (i = 1, cost = 20; i <= 16; i++, cost+= 17) ;
6). Можно опустить одно или более выражений (но нельзя опустить символы ;). Необходимо только включить в тело цикла несколько операторов, которые приведут к завершению его работы.
ans = 2;
for (n = 3; ans <=25;)
ans=*n;
Значение переменной asn сначала будет равно2, затем на первой итерации цикла примет значение 6, затем 18 и 54.
7). Бесконечный цикл
for (;;) ;
пустое условие всегда считается истинным.
8). Первое выражение не обязательно должно инициализировать переменную. Там может стоять оператор некоторого специального вида, например printf. Необходимо только помнить, что первое выражение выполняется только один раз, до начала выполнения остальных частей цикла.
for (printf ("Запомните введение числа!\n"); num = =6;)
scanf (" % d, &num);
г) Вложенные циклы
Если внутри одного цикла находится другой цикл, то эта конструкция называется вложенный цикл. Внутренний цикл выполняется столько раз, сколько задано во внешнем цикле.
// Пример программы на вложенные циклы
// Вывести на экран числа от 0 до 99 по 10 в каждой строке
#include <stdio.h>
void main(void)
{
int num=0;
int i, j;
for(i=0; i<10; i++) {
for(j=0; j<10; j++)
printf("%4d",num++);
printf("\n");
}
}
Форматирование вывода
Для форматирования вывода можно установить несколько флагов, для этого используются функции-члены setf, unsetf.
unsigned v =12345;
cout << "Before: " << v << endl;
cout.setf(cout.hex); //Модификация потока
cout << "After: " << v << endl;
Для форматирования можно подключить заголовочный файл Iomanip.h, тогда используем манипуляторы
cout << "In hexadecimal v == " << hex << v << endl;
cout << "In decimal v == " << dec << v << endl;
ends вставить нулевой завершающий символ в строку
endl начать новую строку
oct 8-ричная система счисления
Для выравнивания по правому краю целочисленных переменных можно задать: cout.width(8); но он не оказывает влияние на следующее выводимое значение.
Заключительная программа
Задача. Три бригады собирают в саду яблоки. Написать программу учета сбора яблок каждой бригадой. Определить, сколько яблок было собрано за день и средний заработок в каждой бригаде.
# include <stdio.h>
# include <conio.h>
void main (void) {
int worker1, worker2, worker3; //Кол-во человек в бригадах
int weight1, weight2, weight3; //Вес яблок
char ch;
float cost; //Стоимость яблок
int num, w; //Номер бригады и вес яблок
clrscr();
weight1 = weight2 = weight3 = 0;
printf("Введите количество студентов в каждой бригаде\n");
scanf ("%d %d %d",&worker1,&worker2,&worker3);
printf("Введите стоимость 1 кг. яблок \n");
scantf("%f",&cost);
for(;;) {
printf("В. номер бригады и количество собранных яблок\n");
scanf("%d %d",&num,&w);
switch (num) {
case 1:
weight1 += w;
break;
case 2:
weight2 += w;
break;
case 3:
weight3 += w;
break;
default:
printf("Вы неверно ввели номер бригады\n");
}
printf("Для окончания нажмите клавишу q\n");
ch = getche();
if (ch == 'q')
break;
}
printf("Собрано яблок \n");
printf("1 б-й = %d, 2 б-й = %d, 3 б-й = %d\n”, weight1,weight2,weight3);
printf("Всего за день собрано %d яблок\n ",weight1+weight2+ weight3);
printf("Заработок в 1-й бригаде=%f\n", (float)weight1*cost/worker1);
printf("Заработок в 2-й бригаде=%f\n", (float)weight2*cost/worker2);
printf("Заработок в 3-й бригаде=%f\n", (float)weight3*cost/worker3);
}
МАССИВЫ
Одномерные массивы
Массив - это набор переменных, расположенных последовательно в памяти, имеющих одно имя и отличающихся друг от друга числовым признаком.
float mas [20]; - объявляет массив mas, состоящий из 20 членов или элементов. 1 элемент mas [0], последний mas [19].
mas [5] = 32.54; присваивание значения элементу массива
float y = mas[5];
Массивы могут быть образованы из данных любого типа. Одномерные массивы называются вектором, двумерные – матрицей.
 |
4б 4б 4б
Обращение к элементу массива осуществляется с помощью индекса. Индекс изменяются от 0 до n-1, где n размерность массива.
Для работы с массивами часто используются циклы.
#include <stdio.h>
void main (void) {
int i, a[10];
for (i=0; i<10; i++)
scanf (" %d",&a[i]); //ввод с клавиатуры
printf ("Вывести следующие результаты \n");
for (i=0; i<10; i++)
printf (" %5d", a[i]); // вывод на экран.
}
Многомерные массивы
Определяются в программе также как и одномерные с указанием размерности каждого индекса в квадратных скобках.
float rain[5][12];
Количество выделяемой памяти рассчитывается как 4*5*12 байт.
Каждый индекс изменяется от 0 до n-1. В памяти все элементы располагаются последовательно, но индексы меняются следующим образом:
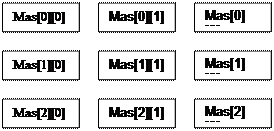 |
//Пример программы ввода кол-ва осадков помесячно за 5 лет и расчета среднего за каждый год и за 5 лет
void main(void){
int i,j;
float mas[5][12], sumyear, sum=0;
for (i=0; i<5; i++){
printf("Ввести кол-во осадков за %d год помесячно\n", i+1);
sumyear=0;
for (j=0; j<12; j++){
scanf ("%f",&mas[i][j]);
sumyear+=mas[i][j];
}
sum+=sumyear/12;
printf(Ср. за %d год = %.2f\n”,sumyear/12);
}
printf(Ср. за 5 лет = %.2f\n”,sum/5);
}
ФУНКЦИИ
Функция – это фрагмент программы со своим именем, к которому можно обратиться для выполнения необходимых действий.
Функция содержит как данные, так и операции над этими данными. Если для объекта имя ссылается на область памяти, где он хранится, то и имя функции ссылается на начало кода этой функции. Функции в Си играют ту же роль что и функции, программы, процедуры в других языках.
- они освобождают от повторного программирования, если конкретную задачу нужно решать в программе несколько раз.
- повышают уровень модульности программы, облегчают её чтение, внесение изменений, коррекцию ошибок. Например:
void main (void){
float list[50];
read list (list); // ввод набора чисел
sort list (list); // сортировка
average (list); // поиск среднего
bargaph (list); // печать графика
}
- cозданные функции можно использовать и в других программах.
Функции бывают библиотечные и пользовательские. Для использования библиотечных функций нужно указать заголовочный файл, в которых они объявлены (директива #include).
Параметры функции
Вернёмся к рассмотренной задаче. Пусть функция starbar() печатает любой символ, указанный в вызывающей программе. Он передается в функцию как аргумент.
#inсlude <stdio.h>
void starbar (char); // объявление функции
void main (void) {
starbar ('_'); // вызов функции
printf ("ПГУ");
printf ("им.Т.Г.Шевченко");
printf ("25 октября, 200");
starbar('#'); // вызов функции
}
void starbar (char x) { // определение функции
int count;
for (count=1; count<=65; count++)
putchar (x);
putchar ('\n');
}
Определение функции начинается с заголовка void starbar (char x) {
Переменная x - является формальным параметром. Это новая переменная и под нее должна быть выделена отдельная ячейка памяти. При вызове функции мы присваиваем формальному аргументу значение фактического аргумента.
starbar (‘-‘); x = '-';
Фактический аргумент может быть константой, переменной или сложным выражением.
Можно передавать в функцию несколько фактических аргументов, разделенных запятыми.
printnum (int i, int j) {
printf ("Первый аргумент %d, вторй аргумент %d\n", i, j);
}
Inline-функции
Перед определением функции может быть использован спецификатор inline для того, чтобы компилятор помещал код функции непосредственно в место вызова функции.
#include <stdio.h>
#include <conio.h>
#include <dos.h>
inline float Circle(float r) {
return 2*3.14*r;
};
void main(void)
{
float y;
y = Circle(2);
printf(“%.2f\n”,y);
}
Это увеличивает код программы, но ведет к увеличению быстродействия работы программы. Inline-функции не должны содержать сложные программные конструкции.
Перегрузка функций
Имена функций могут быть перегружены в пределах одной области видимости. Компилятор отличает одну функцию от другой по сигнатуре. Сигнатура задается числом, порядком следования и типами ее параметров.
#include <stdio.h>
#include <string.h>
int Name (int first) {
return first*first;
}
int Name (unsigned first) {
return first*first;
}
char Name (char first) {
return first*first;
}
int Name (int first,char *second) {
return first*strlen(second);
}
float Name (float r) {
return r*r;
}
double Name (double r) {
return r*r;
}
void main(void) {
printf("%d\n", noName(4));
printf("%d\n", noName((unsigned)4));
printf("%c\n", noName('c'));
printf("%d\n", noName(4,"cлово"));
printf("%0.2f\n", noName((float)1.2));
printf("%0.2lf\n", noName((double)1.2));
}
Глобальные переменные
1. Extern - внешние переменные
Хранятся в области данных программы. Определяются до main() и доступны в любой функции программы. Время жизни - программа. При определении инициализируются по умолчанию 0 на стадии компиляции. Область видимости вся программа.
int count;
void main (void){
count ++;
.........
}
fun (){
printf ("%d\n", count);
}
Переменная count является внешней и доступна в обеих функциях.
Если в программе есть одноименная локальная переменная, она закрывает глобальную переменную. Для расширения видимости операция расширения доступа ::
int count;
void main (void){
int count; //автоматическая переменная
::count++;
..........
printf(“%d”,::count);
}
void fun (void){
count ++;
printf ("%d\n",count);
}
Если переменная определяется в одном модуле, но к ней есть обращение в другом, то нужно обязательно это указать, объявив ее как внешнюю, иначе будет создана новая переменная с этим именем.
I модуль. II модуль.
int cost; void func (void){
void main (void){ extern int cost;
............ ................
} }
Локальные переменные
3. Внутренняя статическая переменная
Ключевое слово static . Объявляется и определяется внутри одной функции, блока. Инициализируют 0 на стадии компиляции. Создаётся в области данных. Время жизни - работа всей программы, но область видимости только эта функция. При многократном вызове сохраняет своё значение. Инициализирует только 1 раз.
void main (void){
int count;
for (count=1; count<5; count ++){
printf ("%d\n", count);
fun ();
}
}
void fun (void){
static int num;
int i=1;
printf ("%d %d\n", i, num++);
}
4. Регистровая переменная
Ключевое слово register int i . Помещаются в регистры микропроцессора для увеличения скорости вычисления. Если нет свободного регистра, рассматриваются как автоматические. Область видимости блок, в котором были определены. По умолчанию не инициализируются.
5. Автоматические переменные
Ключевое слово auto . Определяются внутри любого блока. Время жизни работа блока. Создаются в области стека. Область видимости блок, в котором были определены. По умолчанию не инициализируются.
Пример 1.
if (i==1){
int j=0;
int k=1;
i++;
}
printf(“%d %d”,j,k); //сообщение об ошибке
Пример 2.
int i;
......
{
int i; Внешнее i не видимо
......
}
...... Здесь опять ее видно
Существуют понятия: область видимости и область существования. Область видимости не может выходить за область существования, но область существования может превышать область видимости.
ПРЕПРОЦЕССОР ЯЗЫКА СИ
Компиляция выполняет еще один шаг перед собственно компиляцией исходного файла, называемый предварительно обработкой. Препроцессор просматривает программу и заменяет символьные аббревиатуры в программе на соответствующие директивы. Он расширяет возможности языка 3 функциями.
1. Подстановкой имен;
2. Включением файлов;
3. Условной компиляцией.
Это позволяет создавать мобильные, более удобочитаемые и более удобные для сопровождения программы.
# - первый символ в левой позиции, в любом месте исходного файла сообщает препроцессору, что далее следует директива. Она имеет действие до конца файла.
Подстановка имен
Директивы:
#define – создать макроопределение
# undef - удалить макроопределение
Директива #define служит для:
а) определения символических констант
#define TWO 2
#define MSG “Приднестровский Университет”
#define PX printf(“X равен %d\n”,x)
#define FMT “X равен %d”
void main (void) {
int x=TWO;
PX;
Printf(FMT,x);
Printf(“%s\n”,MSG);
Printf(“TWO:MSG\n”);
}
Макроопределение не должно содержать пробелы. Процесс прохождения от макроопределения до заключительной строки называется макрорасширением. Препроцессор делает подстановки.
б) Макроопределение с аргументом
Очень похоже на функцию (макро-функция).
#define SQUARE(x) x*x
#define PR(x) printf(“X равен %d\n”,x)
void main(void) {
int x=4; int z;
z=SQUARE(x); //16
PR(z);
Z=SQUARE(2); //4
PR(z);
PR(SQUARE(X));
PR(100/SQUARE(2));//100
PR(SQUARE(X+2)); //14
PR(SQUARE(++X)); //30
}
Макрофункция ведет к увеличению программы. Функция к увеличению времени работы программы. Макроопределение создает строчный код, не нужно заботится о типах переменных.
Включение файлов
Директива # include позволяет включить в текст содержимое файла, имя которого является параметром директивы.
1. #include <stdio.h> - ищет в системном каталоге
2. #include “stdio.h” – ищет в текущем рабочем каталоге.
3. Можно создавать свои файлы с функциями и подключать.
#include “my_file.cpp”
4. Можно подключать макроопределение. Макрорасширение макроса должно приводить к одной из первых двух форм директивы.
#define MY_FILE “d:\\bc\work\\my_file.h”
#include MY_FILE
Условная компиляция
Позволяет компилировать не все части программы. Директивы условной компиляции исползуются в больших программах.
# if константное_выражение
[фрагмент текста]
[# elif константное_выражение
фрагмент текста]
...
[# else фрагмент текста]
# endif
Результатом вычисления константного_выражения является целое число. Если оно не 0, то выполняется фрагмент текста программы от директивы #if до одной из директив #else, #elif или #endif.
1. #ifdef CI
#include <stdio.h>
#define MAX 80
#else
#include <iostream.h>
#define MAX 132
#endif
2. #ifndef – если макроопределение не определено
#ifndef MY_FILE // файл будет компилироваться только один раз
#define MY_FILE //когда макрос не определен
#include “my_fyle”
#endif
3. #if SYS == ”IBM”
//похоже на оператор, за ним следует константное выражение
//которое считается истинным, если оно не равно 0
#endif
4. Можно исключить блок программы
#ifdef любое имя
*****
#endif
#if defined(__LARGE__)||defined(__HUGE__)
typedef INT long
#else
typedef INT int
#endif
УКАЗАТЕЛИ
Память состоит из байтов, каждый из которых пронумерован, начиная с 0, 1, 2 ... Номер – это адрес. В Си есть переменные, которые могут содержать этот адрес – указатели и операция взятия адреса - &.
int var=1; - определение и инициализация переменной. var – её имя.
printf ("%d %d\n",var, &var); 1 12136
Машинный код команды можно выразить словами. "Выделить 2 байта памяти, присвоить им имя var. Поместить в ячейку с адресом 12136 число". Фактический адрес этой переменной 12136, а его символическое представление &var.
Значением переменной типа указатель служит адрес некоторой величины. Дадим имя этой переменной ptr; тогда можно написать ptr=&var;
В этом случае говорим "ptr указывает на var", где ptr-переменная, &var-константа.
ptr=# - теперь указывает на num.
13.1 Операция косвенной адресации *
Для доступа к переменной, адрес которой помещен в ptr, используется операция косвенной адресации.
val=*ptr; //val==num
*ptr = 10; //num==10
Описание указателей
Мы уже знаем как описываются переменные, массивы. Как же описать указатель! Сложность в том, что переменные разных типов содержат разное число ячеек, но операции с указателями требуют знания отведенной им памяти. Поэтому, при определении указателя, мы описываем, на какой тип переменной она будет указывать, и что это указатель символ *.
int* ptr;
float* pmas;
char* pc;
Операции над указателями
1. Присвоить ему значение адреса
int*px, x=2; px=&x;
2. Можно присвоить константу - адрес ячейки с описанием состояния аппаратных средств - абсолютный адрес.
3. После присвоения адреса можно применять операцию взятия косвенного адреса.
px=&x; y=*px; //y==x; Приоритет выше, чем y операции «присвоение»
*px=10; x=10;
4. *px+2 //к значению переменной, адрес которой в px, прибавить 2.
рх++; // рх+1 увеличение адреса на длину типа.
++рх;
4. сравнение указателей ==, !=, >=, <=, >, <
//Пример программы копирования двух массивов
void main(void) {
char ar1[100], ar2[100];
char *pa1, *pa2;
pa1=&ar1;
pa2=&ar2;
while(pa2<(ar2+sizeof(ar2)))
*pa1++=*pa2++;
}
Внутренние арифметические операции с указателями зависят от действующей модели памяти и наличия переопределяющих модификаторов указателя. Разность между двумя значениями указателей имеет смысл только в том случае, если оба они указывают на один массив.
Арифметические операции с указателями ограничены сложением, вычитанием и сравнением. Арифметические операции с указателями объектов типа "указатель на тип type" автоматически учитывают размер этого типа, то есть число байт, необходимое для хранения в памяти объекта данного типа.
При выполнении арифметических операций с указателями предполагается, что указатель указывает на массив объектов. Таким образом, если указатель объявлен как указатель на type, то прибавление к нему целочисленного значения перемещает указатель на соответствующее количество объектов type. Если type имеет размер 10 байтов, то прибавление целого числа 5 к указателю этого типа перемещает указатель в памяти на 50 байт. Разность представляет собой число элементов массива, разделяющих два значения указателей. Например, если ptr1 указывает на третий элемент массива, а ptr2 на десятый, то результатом выполнения вычитания ptr2 - ptr1 будет 7.
Когда с "указателем на тип type" выполняется операция сложения или вычитания целого числа, то результат также будет "указателем на тип type". Если type не является массивом, то операнд указателя будет рассматриваться как указатель на первый элемент "массива типа type" длиной sizeof(type).
Конечно, такого элемента, как "указатель на следующий за последним элементом" не существут, однако указатель может принимать это значение. Если P указывает на последний элемент массива, то значение P+1 допустимо, но неопределено. Использование указателя на элемент вне массива ведет к непредсказуемым результатам работы программы. Контроль за допустимыми значениями указателей возлагается на программиста.
Массивы символьных строк
1. Строки в символьный массив можно вводить с клавиатуры.
char mas[80];
scanf("%S",mas);
2. Если требуется несколько строк, то организуем цикл ввода
char mas[4][81];
for (i=0; i<4; i++)
sсanf("%S", mas[i]); // &mas[i][0]
3. Можно сразу инициализировать в программе.
char m1[] = "Только одна строка"; // автоматически определяется
// длина строки + 1 байт на '\0'.
4. Размер массива можно задать явно.
char m2[50] = "Только одна строка"; //18+1
5. char m3[]={'c', 'm', 'p', 'o', 'k', 'a', '\o'};
6. Инициализация массива строк:
char masstr[3][16]={"Первая строка",
"Вторая строка",
"Третья строка" };
*masstr[0]=='П';
*masstr[1]=='B';
*masstr[2]=='Т';
printf(“\n %c”, *masstr[i]); //печать одной буквы
printf(“\n %s”, *(masstr+i)); //печать строки
printf(“\n %u”, masstr[i]); //печать адреса строки
7. «Рваный массив» – это массив указателей на строки.
static char *masstr[3]= {"Первая строка",
"Вторая строка",
"Третья строка" };
В случае «рваного массива» длина строк разная и зря не расходуется память.
Массивы указателей
Можно определять массивы указателей
int* parray[5]; //5 указателей на целые значения.
*parray[3] - //3-й элемент массива.
char *keywords[5]={"ADD", "CHANGE", "DELETE", "LIST", "QUIT"};
В памяти:
keyword[0] – адрес 10000 строка ADD\0 4б
keyword[1] - 10004 CHANGE\0 7б
keyword[2] - 10011 DELETE\0 7б
for (i=0; i<5; i++)
printf("%s", keywords[i]); //печать строки
char *key[3],**pt; //определение указателя на указатель
pt=key;
printf(“%s %d\n”,*pt,**pt); //печатается первая строка и код первой буквы
for (i=0; i<5; i++)
printf(“%c ”,**(pt+i)); //все первые буквы строк
for (i=0; i<3; i++)
printf(“%c ”,*(*pt+i)); //все слово по буквам
ССЫЛКИ
Ссылка - это псевдоним для другой переменной. Они объявляются при помощи символа &. Ссылки должны быть проинициализированы при объявлении, причем только один раз.
Тип "ссылка на type" определяется следующим образом:
type& имя_перем = иниц.
Ссылка при определении сразу же инициализируется. Инициализация ссылки производится следующим образом:
int i = 0;
int& iref = i;
Физически iref представляет собой постоянный указатель на int - переменную типа int* const. Ее значение не может быть изменено после ее инициализации. Ссылка отличается от указателя тем, что используется не как указатель, а как переменная, адресом которой она была инициализирована:
iref++; //то же самое, что i++
int *ip = &iref; //то же самое, что ip = &i;
Таким образом, iref становится синонимом переменной i.
При передаче больших объектов в функции с помощью ссылки он не копируется в стек и, следовательно, повышается производительность.
#include <iostream.h>
void incr (int&);
void main(void){
int i = 5;
incr(i);
cout<< "i= " << i << "\n";
}
void incr (int& k){
k++;
}
Поскольку ссылка это псевдоним, то при передаче объекта в функцию по ссылке внутри нее объект можно изменять. Ссылки не могут ссылаться на другие ссылки или на поле битов. Не может быть массивов ссылок.
Ссылка может использоваться для возврата результата из функции. Возвратить результат по ссылке - значит возвратить не указатель на объект и не его значение, а сам этот объект.
Параметры КОМАНДНОЙ СТРОКИ
У функции main() могут быть свои формальные аргументы. В них возникает необходимость, если нужно передать какие-либо значения в программу из командной строки.
int main(int argc, char *argv[]) {}
argc – определяет кол-во передаваемых параметров в командной строке, включая имя самой программ.
*argv[] – это массив указателей на строки.
argv[0] – имя самой программы;
argv[1] – первый параметр и т.д.
Функция main() может возвращать значение, если необходимо. Любая программа должна возвращать в DOS код возврата. При нормальном завершении он равен 0. В командных файлах можно анализировать этот код командой IF ERRORLEVEL 0 echo «Ok!». Если нет необходимости возвращать значение, то оператор return не нужен.
#include <iostream.h>
int main(int argc, char* argv[]) {
if(argc<2) {
puts(“Нет аргументов в строке”);
exit(1);
}
else {
cout<<”Имя выполняемой программы”<<argv[0]<<endl;
cout<<”Аргумент командной строки”<<argv[1]<<endl;
}
return 0;
}
Если программа завершилась с ошибкой, то можно передать код ошибки в DOS функцией exit(1).
ПРОИЗВОДНЫЕ ТИПЫ ДАННЫХ
Структуры
Рассмотрим новый тип данных - структуру. Он не только гибок для представления разнообразных данных, но и позволяет создавать новые типы данных.
Пример использования - создание каталога книг. Каждая книга имеет следующие атрибуты: шифр, название, автора, издательство, год издания, число страниц, тираж, цену. Это несколько массивов. Очень сложно организовать одновременную работу с каталогом, если нужно их упорядочить по названиям, авторам, цене и так далее. Лучше иметь один массив, в котором каждый элемент содержит всю информацию о книге.
Структура – это объект, состоящий из последовательностей поименнованных элементов. Каждый элемент имеет свой тип.
Для определения нового типа данных нужно его описать:
struct book {
char title [81];
char author[30];
float value;
};
book – это имя нового типа данных.
Сруктурный шаблон является основной схемой, описывающей, как образуется новый тип. struct - ключевое слово, имя типа структуры book - необязателен, если сразу определить имя переменной, то его можно не вводить.
struct {
char title [81];
char author[30];
float value;
}libry;
Каждый элемент структуры определяется своим собственным описанием. Это переменные и массивы стандартных типов данных.
Шаблон является схемой без содержания. Он сообщает компилятору, как сделать что-то, но ничего не делает в программе, а вот создание структурной переменной, это и есть смысл слова «структура». Согласно шаблону под эту переменную выделяется память, равная сумме всех элементов (81).
struct book играет ту же роль, что и int, float перед именем переменной.
struct book doyle, panshin;
Для доступа к элементам структурной переменной используется операция точка. Имя переменной, точка, имя элемента структуры.
void main(void) {
struct book libry; //описание перем-й типа book
puts("Введите название книги");
gets(libry.title);
puts("Введите фамилию автора");
gets(libry.author);
puts("Введите цену книги");
scanf("%f",&libry.value);
printf("%s, %s, %p.2f",libry.title,libry.author,libry.value);
}
Структурную переменную можно инициализировать:
struct book libry={"Руслан и Людмила", "А.С.Пушкин", 1.50};
Массивы структур
Если переменных типа структура много, то определяется массив структур.
void main(void){
struct book libry[100];
int i;
for(i=0; i<100; i++){
puts("Введите название книги");
gets(libry[i].title);
puts("Введите автора книги");
gets(libry[i], author);
puts("Введите цену книги");
scanf("%f",&libry[i].value);
}
}
Индекс применяется к имени массива структур libry[i].
Если libry[2].title[3] – это 4-й элемент в title в 3-й структуре типа book.
Вложенные структуры
Если одна структура содержится или "вложена" в другую, то говорят, что это вложенные структуры.
struct names{ char name[20];
char fio[20];};
struct worker{ struct names people;
char job[20];
float money;};
void main(void){
struct worker driver = {{"Иван", "Иванов"},
"водитель", 1234.1};
Для обращения к элементу вложенной структуры применяется две операции «точка».
puts(driver .people.name);
Указатели на структуры
Указателями на структуры легче пользоваться, чем самими структурами. Структура не может передаваться в качестве аргумента функции, а указатель на структуру может.
struct worker *pdrv;
pdrv = &driver;
struct worker driver[2]; //массив структур
а) pdrv = driver; // pdrv <=> &driver[0];
pdrv+1 <=> &driver[1].
Доступ к элементу структуры осуществляется через операцию ->.
pdrv->job -> driver[0].job ->(*prdv).job
б) pdrv->people.name
Операции над структурами
1) Операция получения элемента.
driver.money=1234;
2) Операция косвенного получения элемента.
pdrv->money=3456;
Объединения
Объединения - это средство, позволяющее запоминать данные различных типов в одном и том же месте памяти. Объединение позволяет создавать массив, состоящий из элементов одинакового размера, каждый из которых может содержать различные типы данных.
Определяется также как и структура. Кючевое слово union . Есть шаблон определения и переменные этого типа.
union simbl {
int digit;
double bigfl;
char letter;
};
union simbl fit, save[10], *pu.
Компилятор выделяет память по наибольшему из элементов объединения bigfl (double 8 байт), для массива структур save[10] будет выделено (10 x 8) байт.
Как обращаться к элементу объеденения?
fit.digit=23; (использ. 2байта)
fit.bigfl=2.0 (23 стирается и записывается 2.0)
fit.letter='a' (2.0 стирается и записывается'a'в 1байт)
pu=&fit; x=pu->digit;
Все типы объединения начинаются с одного и того же адреса и в данный момент можно обратиться только к одному данному объединения.
В С++ можно создавать «безымянные» объединения. В объявлении безымянного объединения отсутствует как тег объединения, так и список объектов этого типа:
union {
int digit;
double bigfl;
char letter;
};
После появления такого объявления имена членов объединения могут использоваться подобно именам обычных переменных; при этом они все расположены в памяти, начиная с одного адреса.
digit=23;
bigfl=2.0
Безымянные объединения очень удобно использовать в качестве членов структур.
Синоним имени типа
Встречаются ситуации, когда удобно ввести синоним для имени некоторого типа.
Строится синоним имени с помощью ключевого слова typedef.
Примеры:
typedef int INT //INT-синоним типа int
INT x, y;
typedef unsigned size_t;
size_t x, y; //переменная типа unsigned
typedef char string[225];
string array; //char array[225];
1. Функция typedef даёт имена типам данных.
2. Выполняется компилятором.
3. Более гибка, чем #define.
Испоьзование типа real вместо float:
typedef float real;
real x, y[5], *px;
если определение расположено внутри функции, то область действия локальна, вне функции глобальна.
typedef char* STRING //STRING-идинтификатор указателя на тип char.
STRING name, sign; //char*name,*sign;
Перечисления
Спецификатор enum позволяет программисту создавать собственные типы.
enum weekDays {Monday, Tuesday, Wensday, Thursday, Friday};
Идентификаторы перечисления представляют собой целочисленные переменные, которые по умолчанию имеют значения 0,1,..., если не указаны другие значения.
weekDays days;
Переменная days теперь может принимать одно из 5 значений.
days = Wensday;
Пример 2.
enum colors {Red=2, Green=3, Grey};
Если задано значение впереди стоящему члену перечисления, то Grey по умолчанию будет равен 4.
Пример 3.
enum VIDEO_BASE_ADDRES { VGA_EGA=0xA000000, CGA=0xB800000,
MONO=0xB000000};
Битовые поля
В некоторыя задачах для экономии памяти необходимо упаковывать несколько объектов в одно машинное слово. В Си для этого определяются поля и доступ к ним. Поле – это последовательность битов внутри одного целого значения.
struct { unsigned a:8;
unsigned b:6;
unsigned c:2;}d;
Определяем структуру d, содержащую поле а – 8 битов, поле b – 6 битов, с – 2 бита. Поля описываются как unsigned, чтобы подчеркнуть, что это величины без знака. Отдельные поля теперь обозначаются как d.a, d.b, d.c. С полями можно выполнять различные операции.
d.a= d.b=( d.c<<2)+6;
Поля не могут переходить за границу слова в ЭВМ. Если же очередное поле не помещается в частично заполненное слово, то под него выделяется новое слово. Поля могут быть безымянными. Используются как заполнители. Для принудительного перехода на новое слово используется специальный размер 0.
struct {unsigned a:8;
:2;
unsigned b:6;
:0;
unsigned c:12;} d;
Битовые поля и объединения можно применять для неявного преобразования типов.
Пример 1.
struct DOS_DATE { unsigned int day:5;
unsigned int month:4;
unsigned int year:7;};
union DATE_CONV { unsigned int packed_date;
struct DOS_DATE unpacked_date;};
typedef union DATE_CONV DATE
void main(void) {
struct ffblk ff; //структура в которую читается информация о
//файле из каталога, описана в <dir.h>
int done=findfirst(“*.*”, &ff,0); //ищет первый файл в каталоге
if(!done) {
DATE d;
d.packed_date=ff.ff_date;
printf(%2d/%2d/%4d”, d.unpacked_date.day, d.unpacked_date.month, d.unpacked_ date .year+1980);
}
}
Операция new с массивами
Если "имя" это массив, то возвращаемый new указатель указывает на первый элемент массива. При создании с помощью new многомерных массивов следует указывать все размерности массива:
mat_ptr = new int[3][10][12]; // так можно
mat_ptr = new int[3][][12]; // нельзя
...
delete [] mat_ptr; //освободить память, занятую массивом,
//на который указывает mat_ptr
ФАЙЛ
Язык Си "рассматривает" файл как структуру. В stadio.h содержится определение структуры файла. Определен шаблон и директива препроцессора #defile FILE struct iobuf
FILE краткое наименование шаблона файла. Некоторые системы используют директиву typedef для установления этого соответствия.
typedef struct iobuf FILE
Открытие файла fopen()
Функцией управляют три параметра.
FILE *in; //указатель потока
Для связывания указателя с файлом служит функция открытия файла fopen(), которая объявлена в заголовочном файле <stdio.h>.
in = fopen (" test ", " r ");
1 параметр - имя открываемого файла
2 параметр -
"r"-по чтению "r+"-чтение и запись
"w"-по записи "w+"-запись и чтение, если файл уже был, он перезаписываетя
"a"-дозапись "a+"-чтение и дозапись, если файла еще не было, он создается
"b"-двоичный файл
"t"-текстовый файл
in является указателем на файл "test". Теперь будем обращаться к файлу через этот указатель.
Если файл не был открыт (его нет, нет места на диске), то возвращается в указатель 0.
if((in=fopen("test", "r"))==0)
puts("Ошибка открытия файла");
Можно по другому
in=fopen("test", "r");
if (!in)
puts("Ошибка открытия файла");
Закрытие файла fclose()
fclose(FILE *stream); //Если файл закрыт успешно, то возвращается 0 иначе -1.
Вставка узла
 a) в начало списка
a) в начало списка
start
temp
temp->next = start;
start = temp;
 b) в середину списка
b) в середину списка
start current
temp
temp->next = current->next;
current->next = temp;
a)  в конец списка
в конец списка
end temp
end->next = temp;
end = temp;
end->next = NULL;
Удаление узла из списка
a) первого узла
start

TelNum *del = start;
start = start->next;
delete del;
b) В середине писка

current del
TelNum *del = current->next;
current->next = del->next;
delete del;
c) в конце списка
 current end
current end
TelNum *del = end;
current->next=NULL;
delete del;
end = current;
Алгоритмы, приведенные выше, обладают существенным недостатком - если необходимо произвести вставку или удаление ПЕРЕД заданным узлом, то так как неизвестен адрес предыдущего узла, невозможно получить доступ к указателю на удаляемый (вставляемый) узел и для его поиска надо произвести обход списка, что для больших списков неэффективно. Избежать этого позволяет двунаправленный список, который имеет два указателя: один - на последующий узел, другой - на предыдущий.
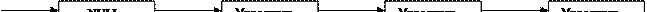
start
NULL
// Пример программы работы с односвязным списком
#include <stdio.h>
#include <conio.h>
struct TelNum;
int printAllData(TelNum * start);
int inputData(TelNum * n);
struct TelNum
{
TelNum * next;
long number;
char name[30];
};
// Описание: печать списка
int printAllData(TelNum * start){
int c=0;
for(TelNum * t=start;t; t= t->next)
printf("#%3.3i %7li %s\n",++c,t->number,t->name);
return 0;
}
// Описание: ввод данных в структуру n конец ввода - ввод нуля
// в первое поле. Возвращает 1 если конец ввода
int inputData(TelNum * n){
printf("Номер?"); scanf("%7li",&n->number);
if(!n->number) return 1;
printf("Имя? "); scanf("%30s",&n->name);
return 0;
}
void main(void){
TelNum * start = NULL; //сторож
TelNum * end = start;
do{ //блок добавления записей
TelNum * temp = new TelNum;
if(inputData(temp)) {
delete temp;
break;
}
else {
if(start==NULL) {
temp->next = start;
start = temp;
end = temp;
}
else {
end->next=temp;
end=temp;
end->next=NULL;
}
}
}while(1);
printf("\nЗаписи после добавления новых:\n");
printAllData(start);
getch();
do{ //блок удаления записей
TelNum * deleted = start;
start = start->next;
delete deleted;
printAllData(start);
getch();
}while(start!=NULL);
}
Бинарные деревья
В бинарном дереве каждый узел содержит 2 указателя. Начальная точка бинарного дерева называется корневым узлом.

Корневой узел Е указывает на В и Н. Узел В является корневым узлом для левого поддерева Е, узел Н – для правого поддерева Е. За исключением самого нижнего яруса каждый узел бинарного дерева имеет одно или два поддерева.
Обычно левое поддерево содержит меньшие данные, правое большие, что ускоряет поиск информации. Дерево такого типа называется деревом бинарного поиска.
Поиск обычно начинается с корня. В зависимости от результата сравнения двигаются либо влево (если данные узла больше образца поиска), либо вправо (если меньше). Новые узлы всегда присоединяются к нижним вершинам, так что дерево всегда растет вниз.
Чтобы распечатать бинарное дерево можно использовать алгоритм, называемый обратным ходом. Простейший алгоритм - рекурсивный. При заданном корне, программа совершает 3 шага:
а) выполняет обход левого поддерева;
б) печать корня;
в) выполняет обход правого поддерева.
Если обнаружен указатель NULL, то продвижение в направлении обхода в данном поддереве прекращается.
При прямом обходе содержимое корня печатается до обхода поддеревьев.
При концевом обходе содержимое корня печатается после совершения обхода двух поддеревьев.
// Пример программы работы с бинарным деревом
#include <stdio.h>
#include <conio.h>
#include <string.h>
struct TelNum;
void printtreepre(TelNum * ); //обход с корня дерева, левое поддерево, правое поддерево
void printtreein(TelNum * ); //обход с вершины правое поддерево,корень, левое поддерево
void printtreepost(TelNum * ); //обход с вершины левое поддерево, правое поддерево,корень
int inputData(TelNum * );
TelNum * addtree(TelNum *, TelNum *);
struct TelNum
{
TelNum * left, *right;
long number;
char name[30];
};
// Описание: печать списка
void printtreepre(TelNum * root)
{
if(!root) return;
if(root->number)
printf("номер %7li фамилия %s\n",root->number,root->name);
printtreepre(root->left);
printtreepre(root->right);
}
void printtreein(TelNum * root)
{
if(!root) return;
if(root->number)
printtreein(root->left);
printf("номер %7li фамилия %s\n",root->number,root->name);
printtreein(root->right);
}
void printtreepost(TelNum * root)
{
if(!root) return;
if(root->number)
printtreepost(root->left);
printtreepost(root->right);
printf("номер %7li фамилия %s\n",root->number,root->name);
}
// Описание: ввод данных
int inputData(TelNum * n)
{
printf("Номер?"); scanf("%7li",&n->number);
if(!n->number) return 1;
printf("Имя? "); scanf("%30s",&n->name);
return 0;
}
// Добавление узла к дереву
TelNum * addtree(TelNum *root, TelNum *temp) {
if(root==NULL) { //добавление узла в вершину дерева
TelNum * root = new TelNum;
root->number=temp->number;
strcpy(root->name,temp->name);
root->left=NULL;
root->right=NULL;
return root;
}
else {
if(root->number>temp->number)
root->left=addtree(root->left,temp);
else root->right=addtree(root->right,temp);
}
return root;
}
// Поиск значения в бинарном дереве
//по номеру телефона
void searchtree(TelNum *root, int num) {
while (root!=NULL) {
if(root->number==num) {
printf("номер %7li фамилия %s\n",root->number,root->name);
return ;
}
else{
if(root->number>num)
root=root->left;
else root=root->right;
}
}
puts("Телефон не найден");
return ;
}
void main(void)
{
TelNum * start = NULL; //сторож
TelNum * temp = new TelNum;
do{ //блок добавления записей
if(inputData(temp))
{delete temp;
break;
}
else
start=addtree(start,temp);
}while(1);
printtreepre(start); //ebcahgi
getch();
printtreein(start); //ighebca
getch();
printtreepost(start); //acbighe
getch();
int num;
puts("Введите номер телефона");
scanf("%d",&num);
searchtree(begin,num);
}
РАЗМЕЩЕНИЕ ДАННЫХ В ПАМЯТИ
Данные могут храниться в регистрах процессора, в области статической памяти, в области организованной как стек и в динамической памяти.
Статическая память - данные размещаются в ней после компиляции и хранятся до конца. В стеке - временно.
Динамическая память "куча" используется в зависимости от выбранной модели памяти. Различают "ближнюю кучу" - неиспользованную часть сегмента стека и "дальнюю кучу" - оставшаяся свободная память машины. В начале блока выделяемой памяти записывается его размер. Он затем используется при удалении.
Вся оперативная память логически разбита на сегменты. Для обращения к сегментам используются 4 специальных регистра микропроцессора для хранения адресов сегментов:
CS – сегмент кода программы,
DS – сегмент статических данных программы,
SS – сегмент стека для временных переменных,
ES - дополнительный сегмент статических данных.
Для оптимизации управления памятью имеется 7 моделей памяти. Размещением данных в памяти управляет программист. Адрес любого участка памяти состоит из смещения и сегмента. Полный (физический) адрес для чтения и записи данных в память получается: адрес сегмента * 16 + смещение.
Организация процессора I8086 накладывает ограничения на размер статистической памяти программы - размер кодов функций и размер статических данных. Размер данных не более 64 Кб в одном сегменте, т.к. размер адресуемой памяти ПЭВМ равен 1 Мб.
Существует 2 варианта построения программы:
А) весь исходный текст компилируется сразу;
Б) программа собирается из нескольких фрагментов (модулей), которые компилируются отдельно. В любом таком модуле свой сегмент данных и сегмент кода. Объединение сегментов может происходить по-разному – в зависимости от используемого метода настройки сегментных регистров CS и DS. Может быть так, что независимо от количества модулей настройка CS, DS выполняется только однажды - тогда размер кода должен быть меньше 64 Кбайт.
Распределение данных по сегментам и управление перехода от сегмента к сегменту берет на себя компилятор. Для каждого модуля можно выделить более одного сегмента статических данных и кода.
Для "малых" моделей все указатели типа near, для больших - far. Указатели на функции для моделей tiny, small,compact - near, в остальных - far. Если все функции в одном файле, то все указатели типа near. Если несколько модулей, но они не обращаются друг к другу, тоже самое. Но если есть обращения функций одного модуля к функциям другого, они должны быть описаны как far функции.
void near fn (int arg);
fn (1);
При вызове функции из другого сегмента адрес возврата состоит из адреса сегмента и смещения
void far ff(int arg);
ff(2);
МОДЕЛИ ПАМЯТИ
C++ поддерживает 7 моделей памяти: tiny, small, medium, compact, large, huge, flat. Для каждой модели различается количество сегментов отведенных под код программы и данных. Рассмотрим эти модели.
1. Крошечная модель T iny - 64 Кбайта код программы и данные
 CS,DS,SS
CS,DS,SS
SP
2. Малая модель S mall – 64Кбайта код программы и 64 Кбайта данные
CS
DS,SS
SP
3. Средняя модель M edium – 1 Мбайт код программы и 64 Кбайта данные
 CS
CS
DS,SS
SP
4. Компактная модель Compact - 64Кбайта код программы и 1 Мбайт данные
 CS
CS
DS
SS
SP
5.Большая модель Large – 1 Мбайт код программы и 1 Мбайт данные

CS
DS
SS
SP
6. Гигантская модель Huge - 1 Мбайт код программы и 1 Мбайт данные
 CS
CS
DS
SS
SP
7.Плоская модель Flat.
Модель Flat соответствует варианту модели Small, но используется 32 разрядные смещения (суммарная длина адреса 6 байт). Эта модель используется только для МП 386 и выше. В этом случае с помощью одного регистра обеспечивается доступ ко всей физической памяти. Хотя регистры DS, SS, ES отличаются, они фактически указывают на один физический адрес начала сегмента (дескрипторы имеют одинаковый адрес и длину сегмента, но разные права доступа к элементам памяти внутри сегмента). Эта модель используется для программ для Windows.
Размер кода или данных ограничен адресной памятью (1 Мбайт).
tiny 64 Кб всего
small 64 Кб кода и 64 Кб данные
medium 1Мб код, 64 Кб данные
compact 64 Кб код, 1Мб данные
large 1Мб код, 1Мб данные
huge тоже что large, но размер статических данных может превышать 64 Кб.
В huge для статистических данных выделяют более 1 сегмента.
int far array [30000]; //массив создается в новом сегменте данных
char far a [70000]; // ошибка более 64кб.
char huge b[70000]; // верно.
Для совместной компляции нескольких модулей создается файл-проект. Проект создается через пункт меню Project - проект, где указываются все компилируемые файлы. Для этого используется подпункт меню:
Open Project -> Insert - добавить модуль
Delete - удалить модуль
СПИСОК ЛИТЕРАТУРЫ
1. М. Уэйт, С. Прайт, Д. Мартин. Язык СИ. - М.: "Мир", 1988 г.
2. Кеpниган Б., Ритчи Д. Язык пpогpаммиpования Си. - М.: Финансы и статистика, 1992г.
3. Кузнецов С.Д. Турбо Си. - М.: Малип, 1992г.
4. П. Киммел Borland C++ 5.0. – C-П.: «BHV-Cанкт Питербург», 1997 год.
5. Цимбал А.А.,Майоров А.Г., Козодаев М.А. Turbo C++: язык и его применение. – М.: «Джен Ай Лтд», 1993 г.
ОСНОВЫ АЛГОРИТМИЗАЦИИ И ПРОГРАММИРОВАНИЯ.
ЯЗЫК С /С++. СТРУКТУРНЫЙ ПОДХОД
Краткий курс лекций
Тирасполь 2000
СОДЕРЖАНИЕ
1. ОБЗОР ЯЗЫКа ПРОГРАММИРОВАНИЯ С. 5
2. ЭТАПЫ СОЗДАНИЯ ПРОГРАММЫ.. 5
3. СТРУКТУРА ПРОГРАММЫ НА ЯЗЫКЕ СИ. 6
3.1. Внутренняя структура программы. 6
3.2. Пример программы на СИ. 6
4. БАЗОВЫЕ ЭЛЕМЕНТЫ ЯЗЫКА СИ. 7
5. ДАННЫЕ В ПРОГРАММЕ НА СИ. 8
5.1. Константы. 8
5.2. Базовые стандартные типы переменных. 9
6. ОПЕРАЦИИ ЯЗЫКА СИ. 11
6.1. Арифметические операции. 11
6.2. Операции отношения. 12
6.3. Логические операции. 12
6.4. Операции с разрядами. 13
6.5. Операции сдвига. 13
6.6. Операция условия ?: 14
6.7. Преобразование типов. 14
6.8. Операции приведения. 14
6.9. Дополнительные операции присваивания. 15
7. ОПЕРАТОРЫ ЯЗЫКА СИ. 15
8. СТАНДАРТНЫЕ ФУНКЦИИ ВВОДА И ВЫВОДА. 22
8.1. Функция вывода данных на экран printf () 22
8.2. Модификаторы спецификаций преобразования. 23
8.3. Функция ввода данных с клавиатуры sсanf() 23
8.4. Функции ввода/вывода одного символа getchar(), putchar() 24
8.5. Функции небуфиризированного ввода с клавиатуры. 24
8.6. Ввод/вывод в поток в С++. 24
8.7. Форматирование вывода. 25
9. МАССИВЫ.. 26
9.1. Одномерные массивы. 26
9.2 Многомерные массивы. 28
10 ФУНКЦИИ. 30
10.1 Cоздание и использование пользовательских функций. 31
10.2 Параметры функции. 32
10.3 Возвращение значения функцией. 33
10.4 Inline-функции. 33
10.5 Значение формальных параметров функции по умолчанию.. 33
10.6 Перегрузка функций. 34
11 КЛАССЫ ПАМЯТИ И ОБЛАСТЬ ДЕЙСТВИЯ. 35
11.1 Глобальные переменные. 35
11.2 Локальные переменные. 36
11.3 Доступ к функциям в многомодульной программе. 37
12 ПРЕПРОЦЕССОР ЯЗЫКА СИ. 39
12.1 Подстановка имен. 39
12.2 Включение файлов. 40
12.3 Условная компиляция. 40
13 УКАЗАТЕЛИ. 41
13.1 Операция косвенной адресации * 41
13.2 Описание указателей. 41
13.3 Использование указателей для связи функций. 42
13.4 Указатели на одномерные массивы. 42
13.5 Указатели на многомерные массивы. 43
13.6 Операции над указателями. 43
13.7 Передача массива в качестве параметра в функцию.. 44
13.8 Указатель на void * 45
14 СИМВОЛЬНЫЕ СТРОКИ И ФУНКЦИИ НАД СТРОКАМИ. 46
14.1 Массивы символьных строк. 46
14.2 Массивы указателей. 47
14.3 Указатель как возвращаемое значение функции. 47
Передача указателя как параметра функции. 47
14.4 Функции, работающие со строками. 48
14.5 Стандартные библиотечные функции. 48
14.6 Преобразование символьных строк. 49
15 ССЫЛКИ. 50
16 Параметры КОМАНДНОЙ СТРОКИ. 51
17 ПРОИЗВОДНЫЕ ТИПЫ ДАННЫХ. 52
17.1 Структуры. 52
17.2 Объединения. 56
17.3 Синоним имени типа. 56
17.4 Определение именнованных констант. 57
17.5 Перечисления. 57
17.6 Битовые поля. 58
18 ДИНАМИЧЕСКОЕ ВЫДЕЛЕНИЕ ПАМЯТИ. 59
18.1 Операция new и delete в С++. 60
18.2 Операция new с массивами. 61
18.3 Инициализаторы с операцией new. 61
18.4 Ошибки при использовании динамичской памяти. 62
19 ФАЙЛ. 64
19.1 Открытие файла fopen() 64
19.2 Закрытие файла fclose() 64
19.3 Функции ввода/вывода одного символа fgetc(), fputc() 64
19.4 Функции форматированного ввода/вывода в файл. 65
19.5 Функции ввода/вывода строки символов в файл. 65
19.6 Функции управления указателем в файле. 66
19.7 Ввод/вывод записей фиксированной длины. 66
20 ДИНАМИЧЕСКИЕ СТРУКТУРЫ ДАННЫХ. 68
20.1 Однонаправленные связные списки. 68
20.2 Бинарные деревья. 71
21 РАЗМЕЩЕНИЕ ДАННЫХ В ПАМЯТИ. 74
22 МОДЕЛИ ПАМЯТИ. 75
Дата: 2018-12-21, просмотров: 656.