Из-за дополнительного расхода дискового пространства файловую систему NTFS не рекомендуется использовать с томами размером менее 400 МБ. Такой расход объясняется необходимостью хранения системных файлов NTFS (в разделе размером 100 МБ для этого требуется около 4 МБ).
В настоящее время NTFS не имеет встроенного шифрования файлов. Следовательно, можно загрузить MS-DOS (или другую операционную систему) и воспользоваться низкоуровневой программой редактирования диска для просмотра хранящихся в томе NTFS данных.
С помощью файловой системы NTFS нельзя форматировать дискеты. Windows NT форматирует дискеты с помощью FAT, так как объем служебной информации, необходимой для функционирования NTFS, не помещается на дискете.
Соглашения именования в NTFS
Имя любого абстрактного объекта – одна из его важнейших характеристик. когда процесс создает файл, он дает ему имя. После завершения процесса файл продолжает существовать и через своё имя может быть доступен другим процессам.
Основная функция файловой системы - связь символьного имени файла и блоков диска, принадлежащих файлу, - реализуется с помощью ссылки из записи каталога о данном файле на запись в таблице, формат которой определяется типом файловой системы на данном диске.
Имена файлов могут состоять не более чем из 255 символов, включая любое расширение. В именах сохраняется регистр введенных символов, но сами имена не зависят от регистра. Файловая система NTFS полностью поддерживает имена, чувствительные к регистру (таким образом, foo отличается от Foo и FOO).
Пользоваться этим не рекомендуется, поскольку многие приложения и поисковые программы эту возможность не учитывают, поэтому данный файл для них может быть недоступен.
В именах могут быть использованы любые символы за исключением указанных ниже.
? " / \ < > * | :В настоящее время из командной строки можно задать имя файла длиной не более 253 символов.
Для имен файлов используется кодировка Unicode, что позволяет пользователям в странах, в которых не используется латинский алфавит (например, в Греции, Японии, индии, России и Израиле), писать имена файлов на своем родном языке.
Файл в системе NTFS
Файл в системе NTFS – это не просто линейная последовательность байтов, как файлы в системах FAT32 и UNIX. Вместо этого файл состоит из множества атрибутов, каждый из которых представляется в виде потока байтов.
Итак, у системы есть файлы - и ничего кроме файлов. Что включает в себя это понятие на NTFS?
- Прежде всего, обязательный элемент - запись в MFT. В этом месте хранится вся информация о файле, за исключением собственно данных: имя файла, размер, положение на диске отдельных фрагментов, и т.д. Если для информации не хватает одной записи MFT, то используются несколько, причем не обязательно подряд.
- Опциональный элемент - потоки данных файла. Может показаться странным определение "опциональный", но, тем не менее, ничего странного тут нет. Во-первых, файл может не иметь данных - в таком случае на него не расходуется свободное место самого диска. Во-вторых, файл может иметь не очень большой размер. Тогда идет в ход довольно удачное решение: данные файла хранятся прямо в MFT, в оставшемся от основных данных месте в пределах одной записи MFT. Файлы, занимающие сотни байт, обычно не имеют своего "физического" воплощения в основной файловой области - все данные такого файла хранятся в одном месте - в MFT.
- Довольно интересно обстоит дело и с данными файла. Каждый файл на NTFS, в общем-то, имеет несколько абстрактное строение - у него нет как таковых данных, а есть потоки (streams). Один из потоков и носит привычный нам смысл - данные файла. Но большинство атрибутов файла - тоже потоки!
Таким образом, получается, что базовая сущность у файла только одна - номер в MFT, а всё остальное опционально.
Данная абстракция может использоваться для создания довольно удобных вещей - например, файлу можно "прилепить" еще один поток, записав в него любые данные - например, информацию об авторе и содержании файла, как это сделано в Windows 2000 (самая правая закладка в свойствах файла, просматриваемых из проводника). Интересно, что эти дополнительные потоки не видны стандартными средствами: наблюдаемый размер файла - это лишь размер основного потока, который содержит традиционные данные. Можно, к примеру, иметь файл нулевой длинны, при стирании которого освободится 1 Гбайт свободного места - просто потому, что какая-нибудь хитрая программа или технология прилепила в нему дополнительный поток (альтернативные данные) гигабайтового размера.
Но на самом деле в текущий момент потоки практически не используются, так что опасаться подобных ситуаций не следует, хотя гипотетически они возможны. Просто имейте в виду, что файл на NTFS - это более глубокое и глобальное понятие, чем можно себе вообразить просто просматривая каталоги диска.
Максимальная длина потока составляет 264 байт. Чтобы получить представление о том, насколько велик поток в 264 байт, представьте, что поток записан в двоичном виде, где каждый символ 0 и 1 занимает 1 мм. В этом случае листинг длиной 264 мм займет 15 световых лет. Для отслеживания местонахождения процесса в каждом потоке используется 64-разрядные файловые указатели. Максимальный размер потока составляет около 18,4 экзабайт (264 байт составит 16 Эбайт ровно или 18 446 744 073 709 551 616 байт).
Обратимся теперь к записи файла MFT:
· Каждая запись состоит из заголовка, за которым следует заголовок атрибута и его значение.
· Каждый заголовок содержит: контрольную сумму, порядковый номер файла, увеличивающийся, когда запись используется для другого файла, счетчик обращений к файлу, количество байт действительно используемых в записи и другие поля.
· За заголовком записи располагается заголовок первого атрибута, а далее значение этого атрибута.
· Затем идет заголовок второго атрибута и т.д.
Если атрибут достаточно велик, то он помещается в отдельном файле (нерезидентный атрибут). Интересно, что если данных в файле не много, то они наоборот хранятся в записи файла MFT. В таблице 2 перечислены атрибуты.
Таблица 2.. Атрибуты, используемые в записях MFT.
| Атрибут | Описание |
| Стандартная информация (информационный атрибут) | Сведения о владельце, информация о защите, счетчик жестких связей, битовые атрибуты (только для чтения, архивный и т.д.). |
| Имя файла | Имя файла в кодировке Unicode. |
| Описатель защиты | Теперь этот атрибут устарел. Теперь используется атрибут $EXTENDEDSECURE. |
| Список атрибутов | Расположение дополнительных записей MFT. Используется, если атрибуты не помещаются в записи. |
| Идентификатор объекта | 64-разрядный идентификатор файла, уникальный для данного тома. |
| Точка повторной обработки | Используется для создания иерархических хранилищ. Наличие этого атрибута предлагает процедуре, анализирующей имя файла выполнить дополнительные действия. |
| Название тома | Используется в $VOLUME. |
| Информация о томе | Версия тома (используется в $VOLUME). |
| Корневой индекс | Используется для каталогов. |
| Размещение индекса | Для очень больших каталогов, которые реализуются не в виде обычных списков, а в виде бинарных деревьев (B-дерев). |
| Битовый массив | Используется для очень больших каталогов. |
| Поток данных утилиты регистрации | Управляет регистрацией в файле $LOGFILE. |
| Данные | Поток данных файла. Следом за заголовком этого атрибута следует список кластеров, где располагаются данные, либо сами данные, если их объем не превышает несколько сот байтов. |
И так, файл в NTFS есть не что иное, как набор атрибутов. Атрибут представляется в виде потока байт. Как видим, один из атрибутов это данные, хранящиеся в файле или, как говорят поток данных. Файловая система допускает добавление файлу новых атрибутов, которые могут содержать какие-то дополнительные данные.
Номера дисковых кластеров файлов можно узнать при помощи утилиты nfi.exe (NTFS File Sectors Information Util), входящей в состав ресурсов Windows.
В файловой системе NTFS применено множеств интересных технологических решений.
- небольшой файл целиком помещается в записи файла MFT.
- операционная система при записи файла старается осуществить операцию таким образом, чтобы было как можно больше цепочек кластеров (участков, где кластеры на диске следуют друг за другом).
- (группы кластеров файла описываются специальными структурами - записями, помещаемыми внутри записи MFT.) Так файл, состоящий всего из одной цепочки кластеров, описывается всего одной такой записью. То же можно сказать о файле, состоящем из небольшого числа цепочек. В записи цепочки кластеров описываются парой из двух значений: смещение кластера от начала и количество кластеров. В заголовке записи указывается смещение первого кластера от начала файла и смещение первого кластера, выходящего за рамки, описываемые данной записью.
|
|
|


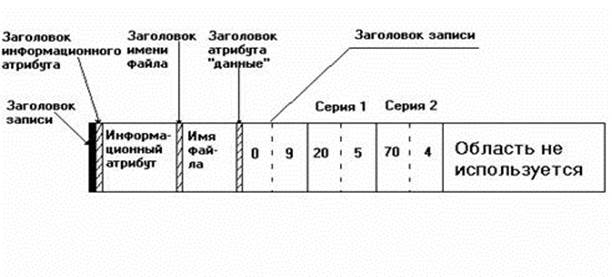
Рис. 6. Пример записи информации о расположении файла, состоящего всего из девяти кластеров.
На Рис. 6 мы схематично изображена запись MFT для файла, состоящего всего из 9 кластеров. После заголовка записи, в которой указываются смещения первого кластера в файле и кластера, не охватываемого данной записью, идут две пары чисел, в которых указываются последовательности непрерывно идущих кластеров. Такие пары называют еще сериями. Как видим, в нашем случае файл состоит из двух непрерывных цепочек и задается двумя сериями. Первая серия блоков располагается в блоках диска с 20 по 24, вторая – с 70 по 73. Каждая серия записывается в записи MFT в виде пары (дисковый адрес, количество блоков). Число таких серий зависит от того, насколько удачно процедура предоставления дискового пространства сумела найти место для хранения файла при его создании. Заметим в этой связи, что числовые значения, определяющие количество кластеров и смещение кластера являются в операционной системе NTFS 64-битными.
Что будет, если файл фрагментирован так, что все его цепочки нельзя описать в одной записи файла MFT? В этом случае используются несколько записей MFT. Причем они не обязаны иметь номера отличающиеся друг от друга на 1. Чтобы связать их друг с другом используется так называемая базовая запись. В первой записи MFT, описывающей данный файл, она (базовая запись) идет перед записью с описанием кластерных цепочек. Она также имеет заголовок, после которого перечислены номера записей MFT, в которых содержится информация о размещении данных файла на диске. Все остальные записи MFT имеют ту же структуру, которая изображена на Рис. 6. Может возникнуть вопрос: а что если базовая запись не сможет поместиться в одой записи MFT? В этом случае ее помещают в отдельный файл, т.е. в терминологии NTFS делают не резидентной.
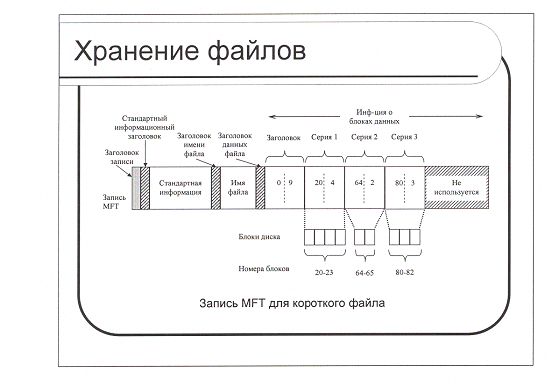
Небольшие файлы и каталоги (обычно до 1500 байт или меньше), типа файла, показанного на слайде, могут полностью содержать. внутри записи главной файловой таблицы. Этот метод называется непосредственным файлом.
Подобный подход обеспечивает очень быстрый доступ к файлам.
Конечно, в большинстве случаев все данные файла не помещаются в запись MFT, поэтому этот атрибут как правило является нерезидентным.
Каталоги в NTFS
Директория или каталог - это файл, имеющий вид таблицы и хранящий ссылки входящих в него файлов или каталогов. Основная задача файлов-директорий - поддержка иерархической древовидной структуры файловой системы. Файл каталога поделен на блоки, каждый из которых содержит имя файла, базовые атрибуты и ссылку на элемент MFT, который уже предоставляет полную информацию об элементе каталога.
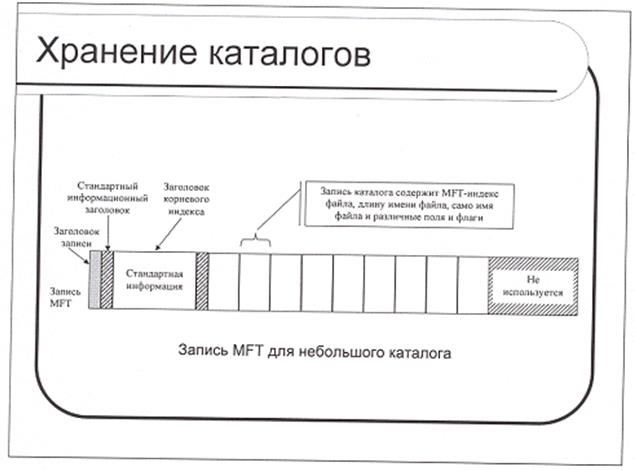
Как и любому файлу, каталогу соответствует запись в таблице MFT. Эта запись включает в себя совокупность записей о файлах, входящих в данный каталог и индексирована таким образом, чтобы обеспечить эффективный поиск имени файла.
Каждая запись о файле включает в себя его имя, метку времени, размер и ссылку на MFT-запись для данного файла. Все это позволяет поисковым программам быстро получать основную информацию о файле из записи в каталоге без обращения к MFT-записи самого файла. Запись MFT для небольшого каталога, где записи о файлах являются резидентным атрибутом, показана на Рис.7.

Рис. 7. MFT запись для небольшого каталога
Как и в случае с обычным файлом, если каталог не слишком велик, то он помещается в записи MFT. На Рис. 8 схематически показана запись MFT содержащая небольшой каталог. Обратим внимание, что в информационном атрибуте содержится информация о корневом каталоге. Сами записи каталога содержат длину имени файла, некоторые другие его параметры, а самое главное содержат номер (индекс) записи MFT для данного файла, в которой содержится уже полная информация о файле.
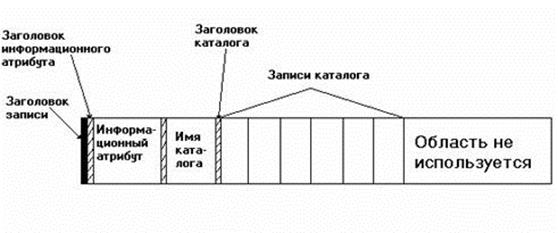
Рис. 8. Небольшой каталог полностью помещается в записи MFT.
Для больших каталогов используется совсем другой формат хранения. Для больших каталогов совокупность записей о файлах не помещается в MFT-запись каталога. Она является нерезидентным атрибутом и организована в виде B+ (бинарного) дерева, обеспечивающего быстрый поиск имени файла в алфавитном порядке. MFT-запись каталога содержит корень этого дерева, а его ветви размещаются в отдельных блоках диска.
Внутренняя структура каталога представляет собой бинарное дерево. Вот что это означает: для поиска файла с данным именем в линейном каталоге, таком, например, как у FAT-а, операционной системе приходится просматривать все элементы каталога, пока она не найдет нужный. Бинарное же дерево располагает имена файлов таким образом, чтобы поиск файла осуществлялся более быстрым способом - с помощью получения двухзначных ответов на вопросы о положении файла. Вопрос, на который бинарное дерево способно дать ответ, таков: в какой группе, относительно данного элемента, находится искомое имя - выше или ниже? Мы начинаем с такого вопроса к среднему элементу, и каждый ответ сужает зону поиска в среднем в два раза. Файлы, скажем, просто отсортированы по алфавиту, и ответ на вопрос осуществляется очевидным способом - сравнением начальных букв. Область поиска, суженная в два раза, начинает исследоваться аналогичным образом, начиная опять же со среднего элемента (Рис. 9).
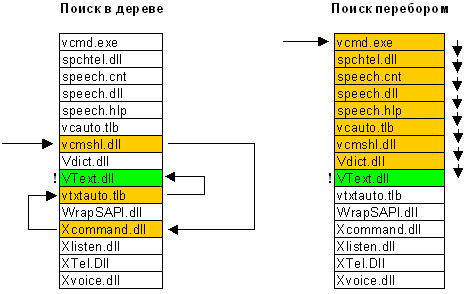
Рис. 9. Поиск файла в каталоге.
Поиск файла по имени
Поиск файла на диске - стандартная задача, которую приходится решать любому работающему с файлами приложению уже на этапе открытия файла. Поисковые программы прибегают для этих целей к специализированным API-функциям поиска файлов.
При поиске файла вначале при помощи механизма символьных ссылок в пространстве имен объектов решается задача трансляции имени диска "в стиле DOS" или буквы диска во внутренние имена устройств Windows. Для этого библиотечный вызов, содержащий имя файла в качестве параметра, передается библиотеке kernel32.dll и перед именем помещается название каталога именованных ресурсов "\??\" в пространстве имен менеджера объектов. В результате "F:\tmp\MyFile.txt" преобразуется в "\??\F:\tmp\MyFile.txt". Далее в каталоге \??\ ищется символьное имя "F:", которое является ссылкой на объект-раздел жесткого диска, например, "\Device\Harddisk\Volume5". Далее находится таблица MFT этого раздела, затем осуществляется навигация по каталогам и отыскивается искомый файл (Рис. 10).
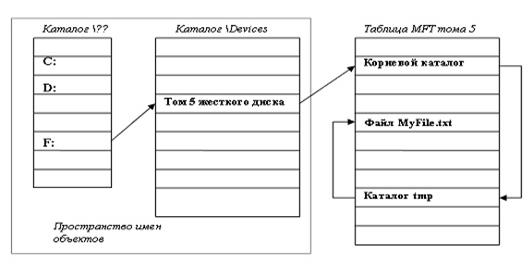
Рис. 10. Процесс поиска файла по имени
Для поиска файлов в каталоге применяются функции FindFirstFile и FindNextFile.
Совместный доступ к файлу
Пользователи часто нуждаются в разделении файлов и совместном доступе к ним.
Операция открытия файла имеет следствием создание объекта "открытый файл". Специфика объекта "открытый файл" состоит в том, что он содержит лишь уникальные данные (например, указатель текущей позиции), тогда как собственно файл - совместно используемые данные. Поэтому, если два раза осуществить операцию открытия одного и того же файла, то система создаст два объекта "файл". Данная ситуация проиллюстрирована Рис.11 для случая одновременного открытия файла потоками разных процессов.
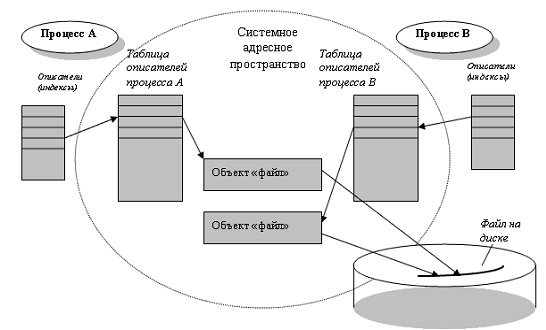
Рис. 11. Организация совместного доступа к файлу
Очевидно, что потоки должны синхронизировать доступ к совместно используемым файлам или каталогам, чтобы получить предсказуемый результат. Между двумя операциями read одного потока другой поток может модифицировать данные, что для многих приложений неприемлемо. ОС Windows предлагает стандартное решение данной проблемы на уровне пользователя - предоставить возможность одному из потоков захватить часть файла между двумя записями для монопольного доступа. Для этого используются Win32-функции LockFile и UnlockFile.
Дата: 2018-11-18, просмотров: 699.