Контрольная по информатике
Студентка 3 курса заочного отделения
специальность 0603 «Финансы»
Шагабутдинова Альбина
Оглавление .
ВАРИАНТ 7
1) Сетевые и иерархические модели данных. Структуры данных в моделях. Особенности и сравнение моделей.
2) Накопители на жестких магнитных дисках. Назначение. История развития.
3) Компьютерные вирусы. Вирусы в сети. Способы проникновения. Механизмы обнаружения вирусов.
4) Средства мультимедиа. Назначение. Дисковод для компакт дисков. Колонки.
Вопрос № 1
Сетевые и иерархические модели данных . Структуры данных в моделях . Особенности и сравнение моделей .
Сетевая модель
В 1971 группа DTBG (Database Task Group) представила в американский национальный институт стандартов отчет, который послужил в дальнейшем основой для разработки сетевых систем управления базами данных. Стандарт сетевой модели впервые был определен в 1975 году организацией CODASYL (Conference of Data System Languages), которая определила базовые понятия модели и формальный язык описания.
Сетевая модель данных опирается на математическую теорию направленных графов. Базовыми элементами сетевой модели являются : Элемент данных – минимальная информационная единица доступная пользователю. Агрегат данных – именованная совокупность элементов данных внутри записи или другого агрегата. Агрегат бывает двух видов – агрегат типа вектор и агрегат типа повторяющаяся группа. Например, агрегат <город, улица, дом, квартира>, которому можно присвоить имя Адрес, является агрегатом типа вектор. Примером, агрегата типа повторяющаяся группа может служить агрегат <месяц, сумма> с названием Зарплата. Агрегат повторяющаяся группа характеризуется числом повторений. В данном примере это число повторений равно 12. Запись - совокупность агрегатов или элементов данных, отражающих некоторую сущность предметной области. Например, записью будет <Фамилия, Зарплата>, где Фамилия – это элемент данных, а Зарплата – агрегат. Данную запись можно назвать Зарплата сотрудника. Тип записей – эта совокупность подобных записей. Например, в предыдущем случае типом записи будет совокупность всех записей Зарплата сотрудника, выражающая множество сотрудников некоторого отдела. Тип записей представляет (моделирует) некоторый класс реального мира. Набор - именованная двухуровневая иерархическая структура, которая содержит запись владельца и запись (или записи) членов. Наборы отражают связи «один ко многим» и «один к одному» между двумя типами записей. На рисунке 1. представлен пример набора. Здесь Отдел – запись–владелец, сотрудник - запись-член. Тип набора определяет связь между двумя типами записей. Каждый экземпляр типа набора содержит один экземпляр записи владельца и произвольное количество записей-членов. Среди всех наборов в сетевой модели допускается существование наборов, не имеющих владельцев. Такие наборы называются сингулярными. Владельцами сингулярных наборов формально считается система. Сингулярные наборы предназначены для доступа к экземплярам отдельных записей.
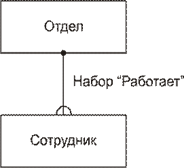 Рис .1. Набор в сетевой модели данных
Рис .1. Набор в сетевой модели данных
Резюмируя выше сказанное, будем говорить, что структура базы данных в сетевой модели задается типами записей и типами наборов.
Отметим некоторые особенности построения сетевой модели .
Ø База данных может состоять из произвольного количества записей и наборов различных типов.
Ø Связь между двумя записями может выражаться произвольным количеством наборов.
Ø В любом наборе может быть только один владелец.
Ø Тип записи может быть владельцем в одних типах наборов и членом в других типах наборов.
Ø Тип записи может не входить ни в какой тип наборов.
Иерархическая модель .
Исторически иерархическая модель появилась раньше сетевой. Она наиболее проста из всех моделей данных. Самой известной иерархической системой позволяющей создавать иерархические базы данных является система IMS (Information Management System) фирмы IBM, используемая в свое время для поддержки лунного проекта «Аполлон». Появление иерархической модели связано с тем, что в реальном мире очень многие связи соответствуют иерархии, когда один объект выступает как родительский, а с ним может быть связано множество подчиненных объектов.
Основными информационными единицами в иерархической модели являются: база данных ( БД ), сегмент и поле. Поле данных определяется как минимальная, неделимая единица данных, доступная пользователю с помощью СУБД. Выделяют также тип поля , представляющий собой совокупность полей одного типа. Сегмент состоит из конкретных экземпляров полей. Тип сегмента - совокупность входящих в него типов полей. Иерархическая модель представляет собой неориентированный граф, в вершинах которого располагаются сегменты (или типы сегмента). Особенностью такой модели является то, что каждый сегмент может иметь не более одного предка, произвольное количество потомков и, по крайней мере, одно поле. Сегмент, который не имеет потомков, называют листовым сегментом. Иерархическое дерево начинается с одного сегмента, называемого корневым сегментом. Очень важно, что каждый сегмент должен иметь свое уникальное имя или идентификатор.
На рисунке 1.1 схематически представлена иерархическая структура. Узлы (сегменты) соединены друг с другом связующими дугами. Сегмент A является корневым сегментом. Сегменты B, E, H, J, I являются листовыми сегментами. Каждый сегмент, при этом, может содержать произвольное количество полей.
Для иерархической модели данных выделяют два языковых средства:
· язык описания данных
· язык модификации данных
Описание базы данных предполагает описание всех ее сегментов и установление связей между ними.
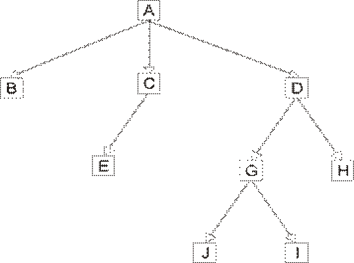
Рис .1.1. Иерархическая структура
Пример иерархической структуры. Иерархическая модель довольно удобна для представления предметных областей, так как иерархические отношения довольно часто встречаются между сущностями реального мира. Но иерархическая модель не поддерживает отношения «многие ко многим», когда множество объектов одного типа связаны с множеством объектов другого типа. Предположим, что требуется построить модель отношения между множеством собственников жилья и множеством квартир. Если основной вопрос будет заключаться в определении того, каким жильем владеет тот или иной собственник, то естественно взять в качестве родительских узлов данные о собственнике. При этом каждый сегмент - собственник будет связан с N узлами – квартирами. Таким образом, по собственнику мы легко найдем все квартиры, которые находятся в его собственности. Однако проблема заключается в том, что у одной и той же квартиры может быть несколько собственников. Т.е. одна и та же квартира может встречаться в разных деревьях. В результате решения таких задач, как получение списка всех квартир, или получения всех собственников конкретной квартиры, будут уже не столь очевидными. Кроме того, сложной выглядит даже операция удаления из базы конкретной квартиры, поскольку для этого придется просматривать все деревья. Можно, конечно, построить параллельно деревья, в которых родительскими сегментами будут данные о квартирах, а порождаемыми сегментами – данные о владельцах, но в результате мы получим еще избыточность данных, что породит дополнительную проблему их согласованности.
Основной единицей обработки в иерархической модели является сегмент. К сегментам могут применяться такие операции как запомнить , модифицировать , удалить , извлечь , найти. Операция поиска сводится к одной из возможных процедур обхода дерева. Иерархические СУБД поддерживают, обычно, правило: никакой сегмент не может существовать без своего родителя (исключая корневой сегмент). Подобные правила, поддерживаемые СУБД, называют ограничениями целостности.
Сетевая модель данных
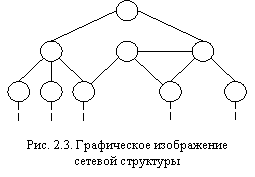
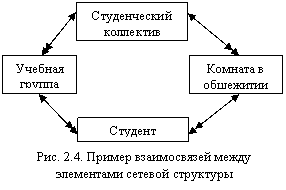
Отличие сетевой структуры от иерархической заключается в том, что каждый элемент в сетевой структуре может быть связан с любым другим элементом (см. рис. 2.3). Пример простой сетевой структуры показан на рис. 2.4.
Достоинством сетевой модели данных является возможность эффективной реализации по показателям затрат памяти и оперативности.
Недостатком сетевой модели данных являются высокая сложность и жесткость схемы БД, построенной на ее основе.
Вопрос № 2
Вопрос №3.
Вопрос № 4.
Функции мультимедиа .
-возможность хранения большого объема самой разной информации на одном носителе (до 20 томов авторского текста, около 2000 и более
высококачественных изображений, 30-45 минут видеозаписи, до 7 часов звука);
-возможность увеличения (детализации) на экране изображения или его наиболее интересных фрагментов, иногда в двадцатикратном увеличении (режим "лупа") при сохранении качества изображения. Это особенно важно
для презентации произведений искусства и уникальных исторических документов;
-возможность сравнения изображения и обработки его разнообразными программными средствами с научно- исследовательскими или познавательными целями;
-возможность выделения в сопровождающем изображение текстовом или другом визуальном материале "горячих слов (областей)", по которым
осуществляется немедленное получение справочной или любой другой
пояснительной (в том числе визуальной) информации (технологии
гипертекста и гипермедиа);
-возможность осуществления непрерывного музыкального или любого другого аудиосопровождения, соответствующего статичному или динамичному визуальному ряду;
-возможность использования видеофрагментов из фильмов, видеозаписей и т.д., функции "стоп-кадра", покадрового "пролистывания" видеозаписи; возможность включения в содержание диска баз данных, методик обработки образов, анимации (к примеру, сопровождение рассказа о композиции картины графической анимационной демонстрацией геометрически построений ее композиции) и т.д.;
-возможность подключения к глобальной сети Internet;
возможность работы с различными приложениями (текстовыми, графическими и звуковыми редакторами, картографической информацией);
-возможность создания собственных "галерей" (выборок) из представляемой в продукте информации (режим "карман" или "мои пометки");
-возможность "запоминания пройденного пути" и создания "закладок" заинтересовавшей экранной "странице";
-возможность автоматического просмотра всего содержания продукта ("слайд-шоу") или создания анимированного и озвученного "путеводителя-гида" по продукту ("говорящей и показывающей инструкции пользователя"); включение в состав продукта игровых компонентов с информационными составляющими;
-возможность "свободной" навигации по информации и выхода в основное меню (укрупненное содержание), на полное оглавление или вовсе из программы в любой точке продукта.
Колонки для компьютера .
Компьютерные колонки не имеют принципиальных отличий от обычных.
Все их особенности сводятся к следующему: меньшая площадь, занимаемая на столе; изоляция магнитного поля; разъемы того же стандарта, что и в звуковой карте (то есть, мини-джеки); совместимость со звуковой картой по уровню сигнала и по сопротивлению; встроенный усилитель (в активных колонках); дизайн более или менее сочетающийся с тоном компьютера (то есть, как правило, серого цвета). Первые две особенности из приведенного списка на качестве звука сказываются негативно.
Существует два типа колонок для компьютера: активные и пассивные. Активные имеют хороший усилитель и отдельное питание. Пассивные качество звука хуже, но намного дешевле.
Список используемой литературы .
1) (Учебник) Могилев А . В ., Пак Н . И ., Хённер Е . К . (2004, 3-е изд., 848с.)
2) Информатика Терехов А.В, Чернышев А.В, Чернышев В.Н_Уч пос_ТГТУ_2007 -128с
3) Основы информатики Савельев А.Я_Учебник_2001 -328с
Контрольная по информатике
Студентка 3 курса заочного отделения
специальность 0603 «Финансы»
Шагабутдинова Альбина
Оглавление .
ВАРИАНТ 7
1) Сетевые и иерархические модели данных. Структуры данных в моделях. Особенности и сравнение моделей.
2) Накопители на жестких магнитных дисках. Назначение. История развития.
3) Компьютерные вирусы. Вирусы в сети. Способы проникновения. Механизмы обнаружения вирусов.
4) Средства мультимедиа. Назначение. Дисковод для компакт дисков. Колонки.
Вопрос № 1
Сетевые и иерархические модели данных . Структуры данных в моделях . Особенности и сравнение моделей .
Сетевая модель
В 1971 группа DTBG (Database Task Group) представила в американский национальный институт стандартов отчет, который послужил в дальнейшем основой для разработки сетевых систем управления базами данных. Стандарт сетевой модели впервые был определен в 1975 году организацией CODASYL (Conference of Data System Languages), которая определила базовые понятия модели и формальный язык описания.
Сетевая модель данных опирается на математическую теорию направленных графов. Базовыми элементами сетевой модели являются : Элемент данных – минимальная информационная единица доступная пользователю. Агрегат данных – именованная совокупность элементов данных внутри записи или другого агрегата. Агрегат бывает двух видов – агрегат типа вектор и агрегат типа повторяющаяся группа. Например, агрегат <город, улица, дом, квартира>, которому можно присвоить имя Адрес, является агрегатом типа вектор. Примером, агрегата типа повторяющаяся группа может служить агрегат <месяц, сумма> с названием Зарплата. Агрегат повторяющаяся группа характеризуется числом повторений. В данном примере это число повторений равно 12. Запись - совокупность агрегатов или элементов данных, отражающих некоторую сущность предметной области. Например, записью будет <Фамилия, Зарплата>, где Фамилия – это элемент данных, а Зарплата – агрегат. Данную запись можно назвать Зарплата сотрудника. Тип записей – эта совокупность подобных записей. Например, в предыдущем случае типом записи будет совокупность всех записей Зарплата сотрудника, выражающая множество сотрудников некоторого отдела. Тип записей представляет (моделирует) некоторый класс реального мира. Набор - именованная двухуровневая иерархическая структура, которая содержит запись владельца и запись (или записи) членов. Наборы отражают связи «один ко многим» и «один к одному» между двумя типами записей. На рисунке 1. представлен пример набора. Здесь Отдел – запись–владелец, сотрудник - запись-член. Тип набора определяет связь между двумя типами записей. Каждый экземпляр типа набора содержит один экземпляр записи владельца и произвольное количество записей-членов. Среди всех наборов в сетевой модели допускается существование наборов, не имеющих владельцев. Такие наборы называются сингулярными. Владельцами сингулярных наборов формально считается система. Сингулярные наборы предназначены для доступа к экземплярам отдельных записей.
Рис .1. Набор в сетевой модели данных
Резюмируя выше сказанное, будем говорить, что структура базы данных в сетевой модели задается типами записей и типами наборов.
Дата: 2019-12-22, просмотров: 554.