В дискуссии по поводу прототипирования, контрольных точек и мини-этапов неявно подразумевалось, что очередные результаты, получаемые проектной командой, появляются через интервалы, измеряемые месяцами или неделями. К этому приучил большинство из нас прежний опыт «нормальных» проектов, и это согласуется с обычным темпом деловой жизни – например, еженедельными совещаниями персонала, ежемесячными отчетами о состоянии работ, ежеквартальными презентациями для высшего руководства и т.д.
Однако, безнадежные проекты, как мы могли убедиться в данной книге, обычно нуждаются в другом подходе. Когда такой проект приходит к прототипированию и пошаговой разработке, обычно имеет смысл организовать всю работу над проектом на основе принципа «ежедневной сборки проекта». Под этим я понимаю следующее: компиляция, сборка, установка и тестирование всей совокупности разработанного командой кода должны выполняться каждый день, как если бы этот день был последним перед завершением проекта, и на следующее утро было бы необходимо сдать законченную систему пользователям.
Разумеется, реалии таковы, что приступить к ежедневной сборке проекта с самого первого дня невозможно. Правда, уже на второй день проекта можно написать подпрограмму типа «Hello, World», и трудно сегодня удивить кого-то совершенно новыми технологиями (в частности, многие из проектов, использующих Java, во время написания этой книги уже находились в процессе разработки). Однако, существуют определенные требования, которым должна удовлетворять версия прототипа системы при первой «официальной» демонстрации: помимо того, что она включает необходимую совокупность компонентов, процедур или модулей и, по крайней мере, несколько сотен, а может быть и тысяч строк кода, она должна выполнять реальный ввод данных, производить реальную обработку или вычисления и формировать реальный выход. Именно с этого момента следует начинать ежедневную сборку проекта и формировать каждый день новую (желательно улучшенную) версию системы.
Почему это так важно? Как любит говорить Jim McCarthy, менеджер продукта Microsoft Visual C++ и автор книги Dynamics of Software Development [4]: «Ежедневная сборка - это биение сердца проекта. Она дает знать, что жизнь продолжается». Такая стратегия может быть приоритетом номер один для менеджера проекта. Если в течение недели каждый крутит свою прялку, и никто не соберется с духом, чтобы сообщить менеджеру проекта, что разрабатываемое ими клиент-серверное приложение никак не хочет правильно взаимодействовать с новой замечательной объектно-ориентированной базой данных, то в результате проект может безнадежно отстать от графика. До тех пор, пока менеджер судит о состоянии проекта по устным отчетам, запискам или диаграммам потоков данных, будет слишком легко перепутать движение с прогрессом и усилия с результатами. Однако, если менеджер проекта настаивает на ежедневной физической демонстрации результатов, будет гораздо труднее скрыть какие-либо трудности, которые в конечном счете могут способствовать провалу проекта.
Некоторые менеджеры проекта будут кивать головами и подтверждать, что они всегда именно так и поступают, однако большинство согласится, что они довольствуются еженедельным, ежемесячным или полугодовым контролем реализации системы. В то время как вряд ли кто-нибудь вправе претендовать на «изобретение» данного подхода, многие знают, что он впервые стал популярным во время разработки операционной системы Windows NT (интересную дискуссию на эту тему можно обнаружить в описании данного проекта, приведенном в [5]). Любопытно также отметить, что при разработке Windows 95 также использовался принцип ежедневной сборки проекта; заключительная бета-версия перед выпуском конечного продукта была реализована в августе 1995 года и называлась «Проект 951».
Важно осознавать, что подобный подход становится неотъемлемой составляющей процесса разработки системы, которому следует проектная команда. Представьте себе, каково быть участником команды, которая должна демонстрировать работающую версию программного обеспечения 951 день подряд! (Правда, если быть честным, я не уверен, что команда Microsoft действительно свято соблюдала такой порядок каждый день. Возможно также, что формирование более чем одной версии укладывалось в 24-часовой промежуток, и возможно, команда могла день или два отдохнуть в этом марафоне.) Кроме того, чтобы быть эффективным, процесс ежедневного завершения проекта должен быть автоматизированным и должен выполняться ночью без чьего-либо участия, когда все программисты отправились домой спать (или влезли на свои рабочие столы и забрались в спальные мешки!). Такой подход подразумевает наличие автоматизированного управления конфигурацией ПО и механизмов контроля исходных кодов, а также разнообразных «скриптов» для выполнения компиляции и сборки приложений. Но что еще более важно, он подразумевает наличие системы автоматизированного тестирования, которая может работать всю ночь, выполняя гору тестов для проверки работоспособности системы. Таким образом, чтобы реализовать на практике принцип ежедневной сборки проекта, необходимо иметь в своем распоряжении адекватный набор средств и технологий; мы еще вернемся к этому вопросу в главе 6.
Действие данного принципа может также дополнительно усилить ряд следующих мер:
· Менеджеру проекта следует переместить свой офис непосредственно к месту разработки и тестирования системы, как только начнется процесс ежедневной сборки проекта. Так поступил Dave Cutler в Microsoft. Рассказывают страшные истории, как он метал громы и молнии, когда появлялся в офисе и обнаруживал, что сборка очередной версии в полночь накрылась. Будет менеджер проявлять свой гнев или нет, важно, чтобы он был почти всегда на виду и непосредственно участвовал в ежедневном процессе, а не уподоблялся генералу, который получает ежедневные сводки с поля боя, находясь за много миль от него в тылу.
· Поскольку вполне вероятно, что ночной процесс ежедневного формирования версии потребует минимального человеческого вмешательства, будет полезным установить следующий порядок: любой программист, допустивший ошибку в коде, которая привела к аварийному завершению ежедневной сборки, удостаивается высокой чести наблюдать за очередной сборкой, пока не появится следующая жертва. Разумеется, такой порядок имеет как плюсы, так и минусы, но по крайней мере благодаря ему команда гораздо «ближе» знакомится с принципом ежедневной сборки проекта.
· Поручите одному из программистов, который обычно приходит в офис рано утром, проверять успешность завершения ежедневной сборки и вывешивать результаты на видное место. Если ни у кого нет желания или возможности появляться в офисе рано утром, наймите студента колледжа. Одна компания велела студенту поднимать над офисом флаг, чтобы таким образом предупреждать сотрудников, какой день ожидается: плохой или хороший. Зеленый флаг означал успешное завершение процесса ежедневной сборки, а красный - аварийное завершение.
Управление рисками
Если управление требованиями - особенно определение приоритетов требований - является в безнадежном проекте наиболее важным процессом, то вторым важнейшим процессом является управление рисками. Если бы понятие «риска» не было столь критическим, тогда мы не употребляли бы по отношению к проекту определение «безнадежный». Интересно отметить, что один из вопросов «теста на алкоголь» связан с идентификацией проектных рисков, и если ответом на такой вопрос со стороны менеджера «нормального» проекта может быть удивленный взгляд (даже если проект оказался в плачевном состоянии), то менеджер безнадежного проекта скорее всего даст на такой вопрос четкий и ясный ответ. Менеджер был бы просто глупцом, если бы он приступил к безнадежному проекту, не имея какого-либо серьезного представления об основных рисках и о том, как с ними бороться.
Увы, но в ходе проекта ситуация может выйти из-под контроля. Это происходит потому, что управление рисками строится в основном на эмоциях и инстинктах, а не на формальных процессах, и менеджер зачастую может просто не заметить вовремя появление новых рисков в ходе проекта. В лучшем случае будут устраняться риски, которые являются очевидными в самом начале проекта; в нормальной ситуации они будут поводом для беспокойства в течение всего проекта (например, риск ухода ключевого разработчика). Однако, могут неожиданно возникнуть совершенно новые риски, которых никто не ожидал, и поскольку команда обычно обладает слишком малым запасом прочности (в терминах плана, бюджета и ресурсов), эти риски могут оказаться для проекта убийственными.
Если вся эта дискуссия относительно рисков разработки ПО кажется вам чересчур раздутой или вообще не относящейся к делу, можете смело переходить к следующей главе. Меня больше всего заботит менеджер проекта, который успешно завершил несколько «нормальных» проектов, справляясь с рисками на интуитивном уровне; такой подход в безнадежном проекте обычно не работает. На самом деле, существуют эффективные формальные процессы управления рисками, позволяющие предпринимать безнадежные проекты, которые в противном случае наверняка стали бы самоубийственными.
На тему об управлении рисками написана масса книг, их обзор не является предметом данной книги. Всю необходимую вам детальную информацию вы можете получить из первоисточников [4, 5, 6, 7], хотя важно остерегаться, чтобы «служба управления рисками» не погребла проект под формами, отчетами и другими бюрократическими штучками. Например, некоторые менеджеры безнадежных проектов следуют очень простой практике идентификации и мониторинга десяти основных рисков проекта; их можно отпечатать на одной странице и еженедельно выполнять оперативный анализ их состояния.
Естественно, можно не менее успешно использовать и другие подходы, но самое главное - обеспечить, чтобы проектная команда их понимала, принимала и следовала им, поскольку рядовые сотрудники на самом нижнем уровне иерархии обычно первыми замечают появление новых рисков. В безнадежном проекте некогда ждать, пока информация доберется до руководства по безнадежно устаревшим каналам; на проблему нужно навалиться всей командой и справиться с ней, пока она не вышла из-под контроля.
Слово «контроль» в данном случае является важным, поскольку проектная команда должна различать оценку риска, контроль риска и ликвидацию риска. В худшем случае проектная команда реагирует на риск только по мере его возникновения - например, выделяя дополнительные ресурсы для проведения дополнительного тестирования, чтобы смягчить последствия ошибки. Такой подход, когда проблеме уделяется внимание только после ее проявления, часто приводит к авральной работе в стиле «тушения пожара», которая, в свою очередь, может оказаться для проектной команды просто катастрофой. Гораздо лучше предупреждать риск заранее, и это означает, что команда согласна соблюдать выполнение формальных процессов оценки и контроля с целью предотвращения потенциальных рисков.
Управление рисками в более профилактической форме направлено на устранение самих причин, приводящих к риску и неудачам; оно нередко является центральным звеном всех начинаний, связанных с управлением качеством в организации. При таком подходе проявляется тенденция к значительному расширению границ оценки рисков и появлению возможности их предотвращения; это может привести к весьма агрессивному стилю управления, основанному на полном контроле над степенью риска в соответствии с его допустимостью для организации. Я всецело разделяю такой подход, однако эта проблема в большей степени стратегическая, она должна обсуждаться и реализовываться за пределами безнадежного проекта. Команда безнадежного проекта преследует в основном тактические цели; она не пытается изменить культуру организации, а всего лишь выжить и нормально закончить проект.
Тем не менее, могут возникнуть некоторые проблемы, связанные с культурой организации, особенно в том случае, если существует мнение, что в других проектах риск отсутствует, и данный проект - это первый, последний и единственный безнадежный проект, когда-либо имевший место в организации. Проблема заключается в том, что проектная команда не находится на необитаемом острове; если бы это было так, то можно было бы решить все вопросы, «ликвидировав вестника», который докладывает о проблемах руководству.
С другой стороны, как отмечает Rob Charette [8], основные причины провалов проектов зачастую кроются в окружающей проект среде (среде самой организации и/или внешней среде), как показано на рис. 5.2. Эта среда почти всегда находится вне пределов досягаемости менеджера проекта, и что не менее важно, менеджер проекта может и не подозревать о наличии этих «внешних» рисков, пока они не обрушатся на проект.
Разумеется, верно и обратное: проект порождает риски, которые могут воздействовать на среду организации и внешнюю среду, и об этом знает каждый. В самом деле, менеджер проекта не должен забывать, что его безнадежный проект может подвергнуть опасности всю организацию - если не цивилизацию и всю вселенную! Те менеджеры, которые плачутся и жалуются, что их команда трудится над завершением проекта всего лишь 127 часов в неделю, зачастую находятся в блаженном неведении относительно происходящего у них под носом, что может привести к крушению проекта.
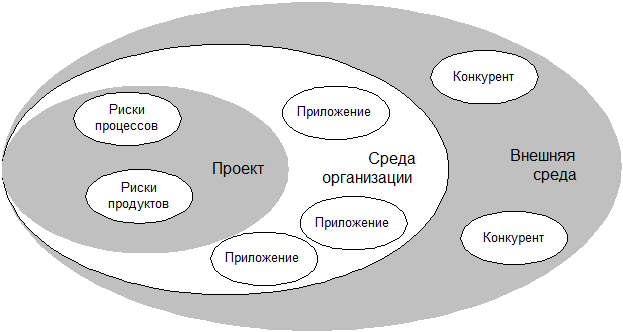
Рис. 5.2 Область действия проектных рисков
Поэтому столь важно использовать формальные процессы управления рисками, с помощью которых можно оценить проектные риски по различным аспектам деятельности организации и попытаться отыскать разумный баланс между ними; в конце концов то, что кажется риском проектировщику и разработчику ПО, может рассматриваться департаментом маркетинга как благоприятная возможность. Такой подход к «глобальному» управлению рисками очень важен, но мне приходилось встречаться с ним в безнадежных проектах совсем не так часто, как хотелось бы. Как было отмечено выше, у проектной команды нет времени, энергии или политического влияния, чтобы пытаться изменить культуру организации с помощью внедрения глобального процесса управления рисками. Следовательно, отсутствие такого процесса в организации само по себе становится риском, который команда должна оценить.
Оценка риска выполняется обычно путем оценки сложности разрабатываемой системы или продукта, а также оценки клиентской среды и среды проектной команды. Сложность продукта можно оценить в терминах объема (например, количества функциональных точек), ограничений производительности, технической сложности и т.д. Риск, связанный с клиентской средой, определяется в основном такими факторами, как количество пользователей, вовлеченных в проект, уровень квалификации пользователей, значение разработки для пользовательского бизнеса, вероятность того, что внедрение новой системы (если оно произойдет) приведет к реорганизации или даунсайзингу и т.д. Наконец, риск, связанный со средой проектной команды, зависит от ее способностей, опыта, морального состояния и физического/эмоционального здоровья.
Как правило, достаточно полная модель риска может включать сто или более факторов риска; как отмечено ранее, некоторые проектные команды сознательно ограничиваются рассмотрением десяти наиболее существенных рисков. Некоторые из рисков можно оценить количественно - например, требования к производительности (скорости реакции системы) или объем системы, выраженный в количестве функциональных точек. Другие факторы - например, степень дружелюбности или враждебности пользователей - могут быть оценены только качественно. Такие факторы принято характеризовать значениями «высокий», «низкий» или «средний».
После того, как риски подверглись идентификации и оценке, менеджер и команда могут попытаться выбрать подходящую стратегию минимизации или исключения по возможности большего количества рисков. Эта деятельность носит, конечно, общий характер, однако не следует забывать, что сама природа безнадежного проекта такова, что количество рисков превышает обычное, они более серьезны, и от них нельзя просто так избавиться. С другой стороны, если риски являются экстраординарными, то и решения должны быть адекватными: в то время как проектная команда «нормального» проекта может никогда не набраться смелости, чтобы обратиться к исполнительному директору или первому вице-президенту с просьбой уменьшить риск путем существенного увеличения бюджета или снятия серьезных бюрократических ограничений, будет вполне разумным обратиться с такой просьбой в безнадежном проекте. Если вы этого не сделаете - а для этого может потребоваться пройти по иерархической лестнице и обойти несколько уровней тупых начальников - то вы так никогда и не узнаете, удалось бы вам решить ваши проблемы или нет.
В любом случае, если существуют серьезные факторы риска, воздействие которых исключить невозможно – а в безнадежных проектах почти всегда так оно и есть – их следует зафиксировать в специальном документе, идентифицировав для каждого риска возможные последствия и разработав план действий в непредвиденных ситуациях. Это не будет чисто политическим «прикрытием задницы», поскольку в том случае, если риск материализуется и повлечет за собой провал проекта, то последствия, как правило, будут печальными для всех, имеющих отношение к проекту; в конце концов, таковы реалии безнадежных проектов. Тем не менее, отрицание реальности - также довольно распространенное явление в безнадежных проектах. Как участники проектной команды, так и пользователи и руководители различных уровней зачастую страдают близорукостью и напрочь игнорируют существование серьезных проектных рисков. Вполне можно ожидать, что менеджер проекта и участники команды будут с усердием уделять свое внимание «внутренним» рискам; однако, как было отмечено выше, участники команды зачастую оставляют без внимания «внешние» риски, поскольку они связаны с проблемами организации и бизнеса, неподвластными команде. Таким образом, документирование рисков является важной практической деятельностью, подталкивающей пользователей и руководство к пониманию того, что они предпочитали не замечать и игнорировать.
Заключение
Довольно легко оставить за бортом многие из тех идей, которые обсуждались в этой главе, и оказаться впоследствии в плену пустопорожней бюрократии. Однако, как отмечает Stephen Nesbit (я получил его сообщение как раз тогда, когда добрался до конца этой главы и не знал толком, как ее закончить):
Отсутствие стандартов и методологии само по себе может превратить проект в безнадежный. Например, в моем последнем проекте сжатый и нереальный план был использован в качестве предлога для того, чтобы отказаться от следующего:
1) Использования системы конфигурационного управления для контроля проектного исходного кода, сосредоточенного в трех различных компьютерных системах, расположенных в двух территориально удаленных местах. В результате значительное время было потеряно впустую в попытках:
а) осуществить сборку программного обеспечения;
б) определить, кому какая версия ПО принадлежит;
в) определить, почему ПО работает на одной системе и не работает на другой.
2) Регистрации узких мест и дефектов с помощью системы конфигурационного управления. В результате стало совершенно невозможно оперативно выяснить, какие ошибки устраняются, а какие проигнорированы; какие компоненты закончены и могут тестироваться.
3) Документальной фиксации основных требований, проектных решений и вариантов, узловых точек в процессе разработки и используемых тестов. В результате участникам проектной команды оказалось чрезвычайно трудно добиться взаимопонимания не только относительно текущего состояния проекта, но также и относительно основных решений, принятых в самом начале проекта.
Итак, пожалуйста, не надо воспринимать эту главу как предлог для отказа от каких-либо процессов, методологий или методов вообще; в самом деле, это может погубить безнадежный проект. Фокус заключается в том, чтобы отыскать те процессы, методологии или методы, которые действительно работают, и которым команда будет следовать естественным образом и бессознательно. Последнее особенно важно: команда испытывает такой стресс и давление, что должна делать многие вещи чисто инстинктивно. Если взвалить на команду бремя новых, незнакомых процессов, которые настолько сложны, что они вынуждены будут каждые пять минут останавливаться и заглядывать в руководство, чтобы определить, что делать дальше, то все пропадет впустую. Поэтому надо поступать проще – и если команда может запомнить только одно слово, этим словом должно быть приоритетность.
Литература к главе:
1. Stephen R. Covey, Roger A. Merill, Rebecca R. Merill. First Things First. New York: Simon & Schuster, 1994.
2. Watts Humphrey. A Discipline of Software Engineering. Reading, MA: Addison-Wesley, 1995.
3. James Bach. The Challenge of ‘Good Enough’ Software. American Programmer, October 1995.
4. Jim McCarthy. Dynamics of Software Development. Redmond, WA: Microsoft Press, 1995.
5. G. Pascal Zachary. Show-Stopper! New York: Free Press, 1994.
6. Rob Thomsett. The Indiana Jones School of Risk Management. American Programmer, September 1992.
7. Capers Jones. Assessment and Control of Software Risks. Englewood Cliffs, NJ: Prentice Hall, 1994.
8. Rob Charette. Building Bridges over Intellectual Rivers. American Programmer, September 1992.
Дополнительная литература:
1. 1. Alan M. Davis. Software Requirements: Objects, Functions, and States. Englewood Cliffs, NJ: Prentice Hall, 1993.
2. Mark C. Paulk, Charles V. Weber, Bill Curtis, Mary Beth Chrises, et al. The Capability Maturity Model: Guidelines for Improving the Software Process. Reading, MA: Addison-Wesley, 1995.
3. Robert N. Charette. Application Strategies for Risk Analysis. New York: McGraw-Hill, 1990.
4. Robert N. Charette. Software Engineering Risk Analysis and Management. New York: McGraw-Hill, 1989.
Дата: 2019-12-10, просмотров: 378.