Информационное обеспечение (ИО) — важнейший элемент ИС и ИТ — предназначено для отражения информации, характеризующей состояние управляемого объекта и являющейся основой для принятия управленческих решений.
Информационное обеспечение (ИО) представляет собой совокупность проектных решений по объемам, размещению, формам организации информации, циркулирующей в ИС. Оно включает в себя специально организованные для автоматического обслуживания совокупность показателей, классификаторов и кодовых обозначений элементов информации, унифицированные системы документации, массивы информации в базах и банках данных на машинных носителях, а также персонал, обеспечивающий надежность хранения, своевременность и качество технологии обработки информации.
Цель разработки ИО ИТ — повышение качества управления организацией на основе повышения достоверности и своевременности данных, необходимых для принятия управленческих решений.
Основное назначение ИО — обеспечивать такую организацию и представление информации, которые отвечали бы любым требованиям пользователей, а также условиям автоматизированных технологий.
Назначение информационного обеспечения обусловливает и требования, предъявляемые к нему.
■ Представлять полную, достоверную и своевременную информацию для реализации всех расчетов и процессов принятия управленческих решений в функциональных подсистемах ИТ с минимумом затрат на ее сбор, хранение, поиск, обработку и передачу.
■ Обеспечивать взаимную увязку задач функциональных подсистем на основе однозначного формализованного описания их входов и выходов на уровне показателей и документов.
■ Предусматривать эффективную организацию хранения и поиска данных, позволяющую формировать данные в рабочие массивы под регламентированные задачи и функционировать в режиме информационно-справочного обслуживания.
■ В процессе решения экономических задач обеспечивать совместную работу управленческих работников и компьютера в режиме диалога.
Одна часть информационного обеспечения учитывает особенности взаимодействия пользователя с ПК при выполнении технологических операций по обработке информации, другая связана с организацией в компьютере различных информационных массивов, используемых для решения экономических задач и передачи данных. Поэтому в составе ИО выделяется внемашинное и внутримашинное информационное обеспечение.
Внемашинное ИО включает систему экономических показателей, потоки информации, систему классификации и кодирования, документацию.
Внутримашинное ИО — система специальным образом организованных данных, подлежащих автоматизированной обработке, накоплению, хранению, поиску, передаче в виде, удобном для восприятия техническими средствами. Это файлы (массивы), базы и банки данных, базы знаний, а также их системы.
2.Внемашинное информационное обеспечение.
Система показателей.
Система показателей служит основой для построения элементов внемашинного и внутримашинного информационного обеспечения и представляет собой совокупность взаимосвязанных социальных, экономических и технико-экономических показателей, используемых для решения задач ИС. Она определяет содержание управленческих документов и массивов. Например, система экономических показателей, представленная в балансе предприятия, в наряде на сдельную оплату труда и пр.
Система показателей менеджмента предназначена для отражения различных функций управления, связанных с прогнозированием, планированием, организацией, оперативным управлением, учетом и анализом, контролем и регулированием, принятием управленческих решений.
Система показателей устанавливается также в зависимости от уровня управления: корпорация, концерн, фирма, предприятие, организация, подразделение.
На уровне корпорации, концерна осуществляется стратегический менеджмент, обеспечивающий стратегию конкурентного предприятия и разработку долгосрочных планов. С этой целью используются, например, системы показателей рынка ценных бумаг, биржевого дела.
Фирмы, входящие в корпорацию, осуществляют свою деловую стратегию. Ее задача — обеспечить долгосрочное конкурентное производство. Для этого нужны показатели о выпускаемых товарах, изучение показателей конкурентных компаний, рынка.
Системы классификации и кодирования.
Автоматизированная обработка на ЭВМ позволяет составлять различные сводки, таблицы, ведомости, где информация сгруппирована по каким-либо реквизитам-признакам, например по работающим подразделениям.
Для выполнения группировок появляется необходимость кодирования этих группировочных реквизитов-признаков условными обозначениями, для чего используются системы классификаций и кодирования. Они позволяют представить информацию в форме, удобной для восприятия машиной. Как правило, кодируются те буквенные выражения реквизитов-признаков, по которым делается группировка. Для этого потребовалось создание средств формализованного описания экономической, информации, на основе которых составляют классификаторы. Классификатор — это систематизированный свод однородных наименований, т. е. классифицируемых объектов и их кодовых обозначений.
Код представляет собой условное обозначение объекта знаком или группой знаков по определенным правилам, установленным системами кодирования.
Коды могут быть цифровыми, буквенными, комбинированными. При обработке экономической информации часто применяют мнемокоды, штрих - коды; в ряде случаев машина сама может кодировать заносимые в нее объекты. Используется самая простая система кодирования — порядковая. В качестве мнемокода применяется условное короткое буквенное обозначение объекта. Например, материально-ответственному лицу присваивается мнемокод «МОЛ».
Процесс присвоения объектам кодовых обозначений называется кодированием.
Основная цель кодирования состоит в однозначном обозначении объектов, а также в обеспечении необходимой достоверности кодируемой информации.
С помощью кодирования обеспечивается выполнение основных функций, связанных с обработкой экономической информации: минимизация объема призначной информации при вводе ее в вычислительную систему и передаче по каналам связи; сортировка и поиск информации по ключевым признакам; разработка сводных экономических отчетов по различным признакам; декодирование при переходе от кодов-признаков к их наименованиям при печати сводных экономических отчетов.
Систематизация экономической информации вызывает необходимость применения различных классификаторов:
■ Общегосударственные классификаторы (ОК), разрабатываемые в централизованном порядке и являющиеся едиными для всей страны.
■ Отраслевые, единые для конкретной отрасли.
■ Региональные, единые для данной территории.
■ Локальные, составляемые на номенклатуры, характерные для данного предприятия, организации, фирмы.
Разработка классификаторов состоит из четырех этапов:
1. Установление перечня и количества объектов, подлежащих кодированию.
2. Систематизация объектов по определенным классификационным признакам (выбор системы классификации).
3. Определение правил обозначения объектов кодирования (выбор системы кодирования).
4. Разработка кодовых обозначений и положений по их ведению и внесению в них изменений.
На первом этапе определяются объекты (номенклатуры), подлежащие кодированию. Ими могут быть работающие, материалы, подразделения, оборудования, предприятия, организации и т. д. Затем по каждой номенклатуре устанавливается полный список всех позиций, подлежащих кодированию.
На втором этапе каждая номенклатура систематизируется по определенным классификационным признакам на основе выбранной системы классификации. Упорядоченное расположение классифицируемых элементов на основе установленных взаимосвязей между признаками составляет систему классификации.
На третьем этапе на основании системы классификации определяют правила обозначения объектов в соответствии с выбранной системой кодирования. Выбор системы кодирования в основном зависит от количества классификационных признаков и разработанной системы классификации и структуры ее построения.
В практике машинной обработки экономической информации широко применяют следующие системы кодирования: порядковую, серийно-порядковую, позиционную, комбинированную, повторения, шахматную, штриховую.
На четвертом этапе осуществляется непосредственное присвоение объектам кодовых обозначений, т. е. выполняется процесс кодирования — присвоение условных обозначений различным позициям номенклатуры. Заканчивается этот этап составлением классификатора, который оформляются в виде справочника.
Унифицированная система документации.
Применение автоматизированных систем обработки обусловило необходимость приспособления документации к требованиям машинной обработки, что ускорило процесс ее унификации и стандартизации. Унифицированная система документации (УСД) включает комплекс взаимосвязанных стандартных форм документов и правил их оформления на основе применения средств вычислительной техники.
Каждой утвержденной Госстандартом России форме документа присваивается в соответствии с Общегосударственным классификатором управленческой деятельности — ОКУД код, который располагается в верхней правой части документа. Основой построения стандартных форм документов являются утвержденные формуляры-образцы.
Так, составление организационно-распорядительных документов регламентируется государственными стандартами; это — основные положения о составлении и оформлении документов и формуляр-образец, представляющий собой модель формы, присущей данной унифицированной системе.
Унифицированная система документации устанавливает общие требования к разработке всех документов и их содержанию, включает формы документов, государственные стандарты и методические материалы, регламентирующие порядок оформления, согласования и утверждения документов.
Так, в соответствии с правилами, утвержденными ГОСТом, первичные документы должны: содержать достоверные данные о состоянии объекта и минимальный, но достаточный объем исходных данных для получения максимальной результатной информации, используемой для управления организацией; обслуживать все звенья и виды хозяйственного руководства и обеспечивать выполнение не только функции учета, но и функции регулирования и оперативного управления; быть максимально приспособленными для машинной обработки и удобными для восприятия человеком; содержать минимум реквизитов документа за счет исключения из него нормативных, расценочных, справочных, а также производных данных; реквизиты, вводимые с клавиатуры в машину, должны быть по возможности сконцентрированы в одной части документа и обведены утолщенной линией.
Первичный документ включает определенный состав реквизитов-признаков, справочных и группировочных, и реквизитов-оснований, исходных и результатных. Унифицированный документ состоит из трех частей: заголовочной, содержательной и оформительской (рисунок 2).
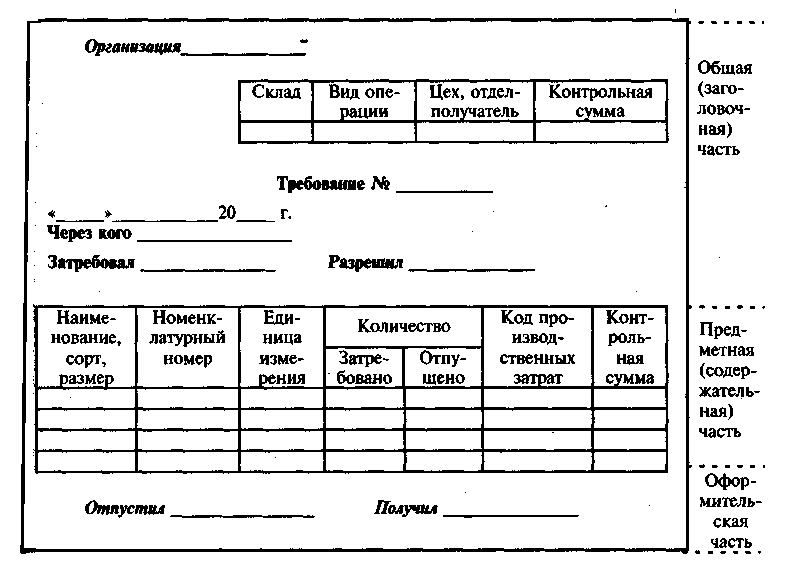
Рисунок 2- Пример построения документа табличной формы
Заголовочная часть содержит: наименование предприятия, организации, работающего, оборудования; характеристику документа (ОКУД); наименование документа; зону для размещения постоянных на документ реквизитов-признаков и их кодов (предприятие, склад, вид операции, цех, требование и т. д.)
Содержательная часть строится в виде таблицы, состоящей из строк и граф, в которых размещаются переменные реквизиты-признаки и количественно-суммовые реквизиты-основания (наименование, номенклатурный номер, количество, код производственных затрат и т. д.)
Оформительская часть документа содержит подписи лиц, несущих юридическую ответственность за составление документа (отпустил, получил).
3.Внутримашинное информационное обеспечение.
Банк данных, его состав, модели баз данных.
Банк данных (БнД) — это система специальным образом организованных данных (баз данных), программных, технических, языковых, организационно-методических средств, предназначенных для обеспечения централизованного накопления и коллективного многоцелевого использования данных.
Центральную роль в функционировании банка данных выполняет система управления базой данных (СУБД). СУБД — это пакет программ, обеспечивающий поиск, хранение, корректировку данных, формирование ответов на запросы. Система обеспечивает сохранность данных, их конфиденциальность, перемещение и связь с другими программными средствами.
Основные функции СУБД:
непосредственное управление данными во внешней памяти (Эта функция включает обеспечение необходимых структур внешней памяти как для хранения данных, непосредственно входящих в БД, так и для служебных целей, например, для убыстрения доступа к данным в некоторых случаях (обычно для этого используются индексы). В некоторых реализациях СУБД активно используются возможности существующих файловых систем, в других работа производится вплоть до уровня устройств внешней памяти. Но подчеркнем, что в развитых СУБД пользователи в любом случае не обязаны знать, использует ли СУБД файловую систему, и если использует, то, как организованы файлы. В частности, СУБД поддерживает собственную систему именования объектов БД.);
управление буферами оперативной памяти (СУБД обычно работают с БД значительного размера; по крайней мере, этот размер обычно существенно больше доступного объема оперативной памяти. Понятно, что если при обращении к любому элементу данных будет производиться обмен с внешней памятью, то вся система будет работать со скоростью устройства внешней памяти. Практически единственным способом реального увеличения этой скорости является буферизация данных в оперативной памяти.);
управление транзакциями (Транзакция - это последовательность операций над БД, рассматриваемых СУБД как единое целое. Либо транзакция успешно выполняется, и СУБД фиксирует изменения БД, произведенные этой транзакцией, во внешней памяти, либо ни одно из этих изменений никак не отражается на состоянии БД. Понятие транзакции необходимо для поддержания логической целостности БД.);
журнализация (Одним из основных требований к СУБД является надежность хранения данных во внешней памяти. Под надежностью хранения понимается то, что СУБД должна быть в состоянии восстановить последнее согласованное состояние БД после любого аппаратного или программного сбоя.);
языки БД (В современных СУБД обычно поддерживается единый интегрированный язык, содержащий все необходимые средства для работы с БД, начиная от ее создания, и обеспечивающий базовый пользовательский интерфейс с базами данных. Стандартным языком наиболее распространенных в настоящее время реляционных СУБД является язык SQL (Structured Query Language).
Организация типичной СУБД и состав ее компонентов соответствует рассмотренному набору функций. Логически в современной реляционной СУБД можно выделить наиболее внутреннюю часть — ядро СУБД, компилятор языка БД (обычно SQL), подсистему поддержки времени выполнения, набор утилит.
Преимущества работы с БнД для пользователей окупают затраты и издержки на его создание. Они заключаются в следующем: повышается производительность работы пользователей, достигается эффективное удовлетворение информационных потребностей; централизованное управление данными освобождает прикладных программистов от организации данных, обеспечивает независимость прикладных программ от данных; организация банка (базы) данных позволяет реализовать другие нерегламентированные запросы, приложения; снижаются затраты не только на создание и хранение данных, но и на поддержание их в актуальном динамичном состоянии; уменьшаются потоки данных, циркулирующих в системе, сокращается избыточность и дублирование.
По организации и технологии обработки данных базы данных подразделяются на централизованные и распределенные.
Централизованную базу данных отличает традиционная архитектура баз данных (рисунок 1).
При подобной архитектуре все необходимые для работы специалистов данные и СУБД размещены на центральном компьютере, или мэйнфрейме (mainframe), вместе с приложением, принимающим входную информацию с пользовательского терминала и отображающим данные на экране пользователя. Предположим, что пользователь вводит запрос, требующий последовательного просмотра базы данных (например, запрос на расчет потребности материалов на деталь в натуральном и стоимостном выражении). СУБД получает этот запрос, просматривает БД, выбирая с диска нужную запись, вычисляет значение и отображает результат на экране. Приложение и СУБД работают на одном компьютере, и, поскольку система обслуживает много различных пользователей, каждый из них ощущает снижение быстродействия по мере увеличения нагрузки на систему.
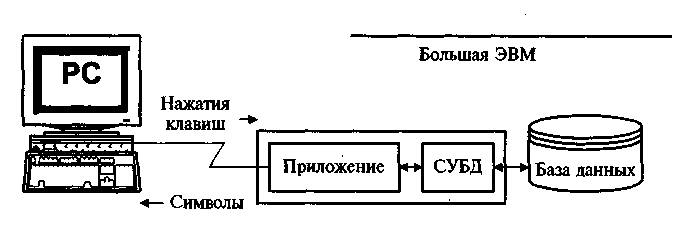
Рисунок 1 - Централизованная БД
Распределенная база данных состоит из нескольких, возможно пересекающихся или даже дублирующих друг друга частей, хранимых в различных компьютерах вычислительной сети. Работа с такой БД осуществляется с помощью системы управления распределенной базой данных (СУРБД).
По способу доступа к данным БД разделяются на БД с локальным доступом и БД с удаленным (сетевым) доступом.
Системы централизованных БД с сетевым доступом предполагают различные архитектуры подобных систем: файл-сервер и клиент-сервер.
Появление персональных компьютеров и локальных вычислительных сетей привело к разработке архитектуры «файл-сервер», показанной на рисунке 2. При такой архитектуре приложение, выполняемое на ПК, может получить прозрачный доступ к файл-серверу, на котором хранятся совместно используемые файлы. Когда приложению, работающему на ПК, требуется получить данные из совместно используемого файла, сетевое программное обеспечение автоматически считывает требуемый блок данных с сервера. Наиболее популярные БД для ПК, включая Microsoft Access, Paradox и dBase, поддерживают архитектуру «файл-сервер», при которой на каждом ПК работает своя копия СУБД.
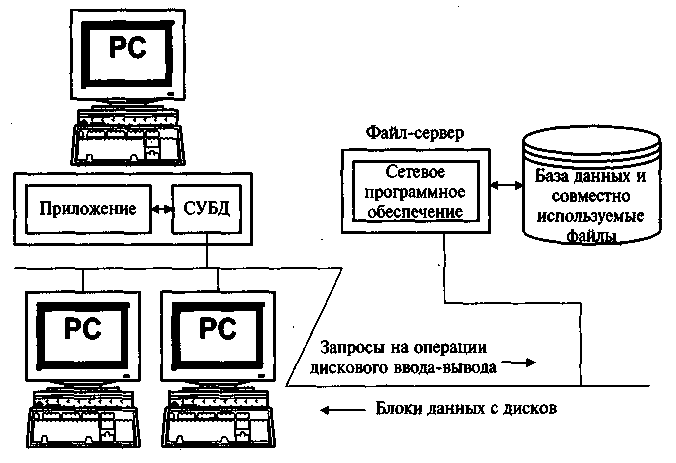
Рисунок 2 - . Архитектура «файл-сервер»
При выполнении обычных запросов эта архитектура обеспечивает великолепную производительность, поскольку в распоряжении каждой копии СУБД находятся все ресурсы ПК. Однако рассмотрим приведенный выше пример. Поскольку запрос требует последовательного просмотра БД," СУБД постоянно запрашивает все новые блоки данных из БД, которая физически расположена на сервере сети. Очевидно, что в результате СУБД запросит и получит по сети все блоки файла. При выполнении запросов такого типа эта архитектура создает слишком большую нагрузку на сеть и уменьшает производительность работы.
Архитектура «клиент-сервер» показана на рисунке 3. При такой архитектуре ПК объединены в локальную сеть, в которой имеется сервер баз данных, содержащий общие БД. Функции СУБД разделены на две части. Пользовательские программы, такие, как приложения, для формирования интерактивных запросов и генераторы отчетов, работают на клиентском компьютере. Хранение данных и управление ими обеспечиваются сервером. В этой архитектуре SQL стал стандартным языком, предназначенным для обработки и чтения данных, содержащихся в БД. SQL обеспечивает взаимодействие между пользовательскими программами и ядром БД.
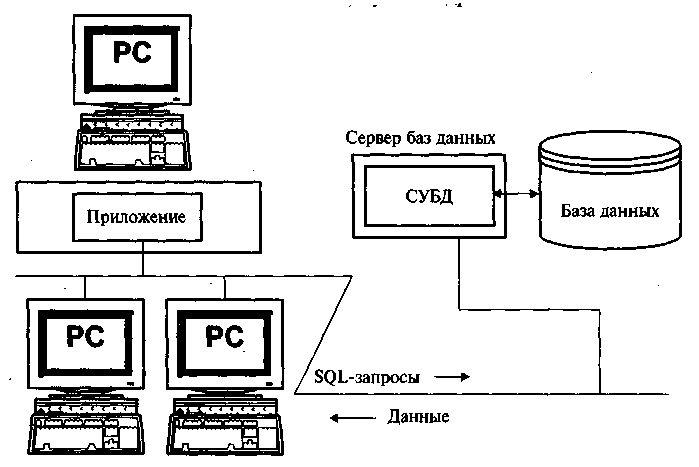
Рисунок 3 - Архитектура «клиент-сервер»
Вернемся к примеру определения потребности материалов на деталь. При архитектуре «клиент-сервер» запрос передается по сети на сервер БД в виде SQL-запроса. Ядро БД на сервере обрабатывает запрос и просматривает БД, которая также расположена на сервере. После вычисления результата ядро БД посылает его обратно по клиентскому приложению, которое отображает его на экране ПК. Архитектура «клиент-сервер» позволяет сократить трафик и распределить процесс загрузки базы данных. Функции работы с пользователем, такие, как обработка ввода и отображение данных, выполняются на ПК пользователя. Функции работы с данными, такие, как дисковый ввод-вывод и выполнение запросов, выполняются сервером БД. Наиболее важно здесь то, что SQL обеспечивает четко определенный интерфейс между клиентской и серверной системами, эффективно передавая запросы на доступ к БД. Эта архитектура используется в современных СУБД Oracle, Informix, Sybase и др.
С ростом популярности СУБД появилось множество различных моделей данных. У каждой из них имелись свои достоинства и недостатки, которые сыграли ключевую роль в развитии реляционной модели данных, появившейся во многом благодаря стремлению упростить проектирование, упорядочить работу с моделями данных и повысить ее эффективность.
Основным средством организации и автоматизации работы с БД являются системы управления базами данных (СУБД).
Выбор СУБД определяется многими факторами, но главным из них является возможность работы с конкретной моделью данных (иерархической, сетевой, реляционной).
Иерархическую модель БД изображают в виде дерева (рисунок 4). Элементы дерева вершины 1—14 представляют совокупность данных, например логические записи. Каждой вершине соответствует множество экземпляров записей, составляющих логический файл. Вершины расположены по уровням и связаны между собой отношениями подчиненности. Одна-единственная вершина верхнего уровня является корневой. Иерархическая модель данных обеспечивает так называемые одно-многозначные отношения между данными. Примером таких отношений могут служить следующие: одному изделию соответствует несколько материалов, используемых на различных операциях обработки, сборки.
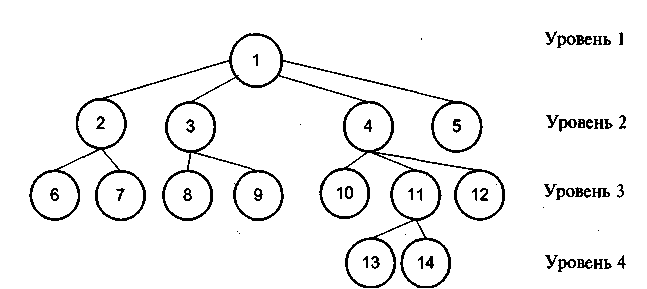
Рисунок 4 - Схема иерархической модели БД
Сетевые модели БД соответствуют более широкому классу объектов управления, хотя требуют для своей организации и дополнительных затрат. Сетевая модель позволяет любому объекту быть связанным с любым другим объектом. Сетевые модели сложны, что создает определенные трудности при необходимости модернизации или развития СУБД. Пример сетевой модели БД представлен на рисунке 5. На рисунке видно, что одно изделие изготавливается в результате выполнения нескольких операций, а одна операция может использоваться для изготовления различных изделий.
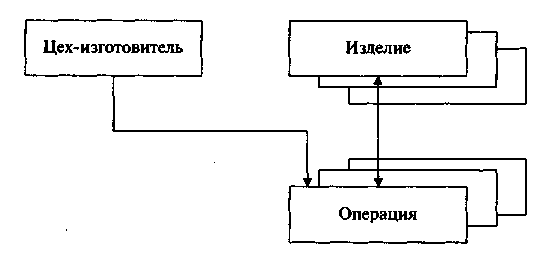
Рисунок 5 - Сетевая модель БД
Реляционная модель БД представляет объекты и взаимосвязи между ними в виде таблиц, а все операции над данными сводятся к операциям над этими таблицами. На этой модели базируются практически все современные СУБД. Эта модель более понятна, «прозрачна» для конечного пользователя организации данных. К преимуществам реляционной модели БД можно отнести также более высокую гибкость при расширении БД, состава запросов к ней.
Таблица 1 – Реляционная модель БД
| Код технологической группы оборудования | Код изделия | Программа выпуска |
| 3 | 20370 | 600 |
| 3 | 20510 | 2000 |
| 5 | 50200 | 1500 |
| 5 | 50230 | 300 |
Реляционная организация БД в виде таблицы содержит программу выпуска изделий (таблица 1). Эта база данных включает в себя три атрибута: код технологической группы оборудования, код изделия, программу выпуска.
Одно из основных различий между тремя типами моделей СУБД состоит в том, что для иерархических и сетевых СУБД их структура не может быть изменена после ввода данных, тогда как для реляционных СУБД структура может изменяться в любое время. Для больших БД, структура которых остается длительное время неизменной, именно иерархические и сетевые СУБД могут оказаться наиболее эффективными, ибо они могут обеспечивать более быстрый доступ к информации БД, чем реляционные СУБД. Однако большинство СУБД для ПК работают с реляционной моделью. К реляционным моделям относят, например, Clipper, dBase, Paradox, FoxPro, Access, Oracle.
В последние годы все большее признание и развитие получают объектно-ориентированные базы данных (ООБД), толчок к появлению которых дали объектно-ориентированное программирование и использование ПК для обработки и представления Практически всех форм информации, воспринимаемых человеком.
В чем принципиальное отличие реляционных и объектно-ориентированных баз данных? В ООБД модель данных более близка сущностям реального мира. Объекты можно сохранить и использовать непосредственно, не раскладывая их по таблицам. Типы данных определяются разработчиком и не ограничены набором предопределенных типов. В объектных СУБД данные объекта, а также его методы помещаются в хранилище как единое целое. Объектная СУБД именно то средство, которое обеспечивает запись объектов в базу данных. Существенной особенностью ООБД можно назвать объединение объектно-ориентированного программирования (ООП) с технологией баз данных для создания интегрированной среды разработки приложений.
ООБД обеспечивает доступ к различным источникам данных, в том числе, конечно, и к данным реляционных СУБД, а также разнообразные средства манипуляции с объектами баз данных. Традиционными областями применения объектных СУБД являются системы автоматизированного проектирования (САПР), моделирование, мультимедиа, поскольку именно из нужд этих отраслей выросло новое направление в базах данных.
Хранилища данных и базы знаний.
Хранилище данных {data warehouse) — это автоматизированная информационно-технологическая система, которая собирает данные из существующих баз и внешних источников, формирует, хранит и эксплуатирует информацию как единую. Оно обеспечивает инструментарий для преобразования больших объемов детализированных данных в форму, которая удобна для стратегического планирования и реорганизации бизнеса и необходима специалисту, ответственному за принятие решений. При этом происходит слияние из разных источников различных сведений в требуемую предметно-ориентированную форму с использованием различных методов анализа.
Хранилище информации предназначено для хранения, оперативного получения и анализа интегрированной информации по всем видам деятельности организации.
Данные в таком хранилище характеризуются следующими свойствами:
■ предметная ориентация — данные организованы согласно предмету, а не приложению (в соответствии со способом их применения);
■ интегрированностъ — данные согласуются с определенной системой наименований, хотя могут принадлежать различным источникам и их формы представления могут не совпадать;
■ упорядоченность во времени — данные согласуются во времени для использования в сравнениях, трендах и прогнозах;
■ неизменяемость и целостность — данные не обновляются и не изменяются, а только перезагружаются и считываются, поддерживая концепцию «одного правдивого источника».
■ большой объем и сложные взаимосвязи данных.
К основным категориям данных, которые располагаются в хранилище, относятся: метаданные, описывающие способы извлечения информации из различных источников, методы их преобразования из различных структур и форматов и доставки в хранилище; фактические данные (архивы), отражающие состояние предметной области и конкретные моменты времени; суммарные данные, полученные на основе проведенных аналитических расчетов.
В информационных хранилищах используются статистические технологии, генерирующие информацию об информации; процедуры суммирования; методы обработки электронных документов, аудио-, видеоинформации, графов и географических карт.
Для уменьшения размера информационного хранилища до минимума при сохранении максимального количества информации применяются эффективные методы сжатия данных.
Для преобразования данных из хранилища в предметно-ориентированную форму требуются языки запросов нового поколения. Руководителям организации данные доступны посредством SQL-запросов, инструментов создания интерактивных отчетов на экране, более развитых систем поддержки принятия решений, многомерного просмотра данных посредством гипертекстовой технологии.
Для хранения данных обычно используются выделенные серверы, или кластеры серверов (группа накопителей, видеоустройств с общим контроллером).
Создание информационного хранилища данных требует решения ряда организационных вопросов, а также удовлетворения следующих требований к аппаратному и программному обеспечению.
Скорость загрузки. В хранилищах необходимо обеспечить периодическую загрузку новых порций данных, укладывающихся в достаточно узкий временной интервал. Требуемая производительность процесса загрузки не должна накладывать ограничения на размер хранилища.
Технология загрузки. Загрузка новых данных в хранилище включает преобразование данных, фильтрацию, переформатирование, проверку целостности, организацию физического хранения, индексирование и обновление метаданных. Это дает возможность объединить разнородную информацию из пакетов, применяемых в структурных подразделениях организации.
Управление качеством данных. В хранилище должна быть обеспечена локальная и глобальная согласованность данных. Мера качества построенного хранилища — объективность исходных данных и степень разнообразия возможных запросов.
Поддержка различных видов данных. В хранилище могут накапливаться данные не только стандартных типов, но и более сложных, таких, как текст, изображения, а также уникальных типов, определяемых разработчиками.
Скорость обработки запросов. Сложные запросы, важные для принятия ответственных решений, должны обрабатываться за секунды или минуты. Скорость обработки запроса должна зависеть от его сложности, а не от объема БД.
Масштабируемость. Хранилище организации может достигнуть нескольких сотен гигабайт. СУБД не должна иметь никаких архитектурных ограничений и должна поддерживать модульную и параллельную обработку, сохранять работоспособность в случае локальных аварий и иметь средства восстановления.
Обслуживание большого числа пользователей. Доступ к хранилищу данных не ограничивается узким кругом специалистов организации. Сервер БД должен поддерживать сотни пользователей без снижения скорости обработки запросов.
Сети хранилищ данных. Сервер должен содержать инструменты, координирующие перемещение данных — между хранилищем организации, информационными системами банков, ГНИ и т. п. Пользователи должны иметь возможность обращаться к нескольким хранилищам с одной клиентской рабочей станции.
Администрирование. СУБД должна обеспечить контроль за приближением к ресурсным ограничениям, сообщать о затратах ресурсов и позволять устанавливать приоритеты для различных категорий пользователей или операций, а кроме того, уметь осуществлять трассировку и настройку системы на максимальную производительность. Качество построенного хранилища определяется удобством доступа к нему для конечного пользователя.
Интегрированные средства многомерного анализа. Для обеспечения высокопроизводительной аналитической обработки необходимы средства многомерных представлений, инструменты, поддерживающие удобные функции создания предварительно вычисленных суммарных показателей и автоматизирующих генерацию таких предварительно вычисленных агрегированных величин.
Средства формирования запросов. Пользователь должен иметь возможность проведения аналитических расчетов, последовательного и сравнительного анализа, а также доступ к детальной и агрегированной информации.
Использование информационных хранилищ дает существенный выигрыш по производительности в системах принятия решений, в системах обработки большого числа транзакций с большим объемом обновления данных.
База знаний
Активно развивающейся областью использования компьютеров является создание баз знаний (БЗ) и их применение в различных областях науки и техники. База знаний представляет собой семантическую модель, предназначенную для представления в ЭВМ знаний, накопленных человеком в определенной предметной области. Основные функции базы знаний: создание, загрузка; актуализация, поддержание в достоверном состоянии; расширение, включение новых знаний; обработка, формирование знаний, соответствующих текущей ситуации.
Для выполнения указанных функций разрабатываются соответствующие программные средства. Совокупность этих программных средств и баз знаний принято называть искусственным интеллектом.
Искусственный интеллект в настоящее время находит применение в таких областях, как планирование и оперативное управление производством, выработка оптимальной стратегии поведения в соответствии со сложившейся ситуацией, экспертные системы и т. д.
Дата: 2019-02-02, просмотров: 421.