В.И. Лойко С.В. Лаптев
СТРУКТУРЫ
И
АЛГОРИТМЫ
ОБРАБОТКИ ДАННЫХ
Учебное пособие
(электронное издание)
Рекомендовано
Методической комиссией
факультета прикладной информатики
Кубанского государственного
аграрного университета
для студентов специальности
«Прикладная информатика»
Краснодар
2013
УДК 681.31 (031)
Лойко В.И. Структуры и алгоритмы обработки данных. Учебное пособие для вузов (электронное издание).- Краснодар: КубГАУ. 2013. - 331 с., ил.
Учебное пособие разработано на основе лекций по курсу "Алгоритмы и структуры данных", преподаваемых автором студентам различных специальностей. В теоретической части пособия изложены основные положения теории алгоритмов и структур данных для персональных ЭВМ. Главное внимание в пособии уделено оперативным структурам.
Рассмотрены простые типы данных и такие структуры, как статические, полустатические и динамические. В динамических структурах данных выделены линейные и нелинейные связные списки.
Изложены и проанализированы основные алгоритмы сортировки и поиска данных в различных структурах.
В практической части учебного пособия приведены методические указания к лабораторным работам и курсовому проектированию.
Учебное пособие предназначено для студентов специальности «Прикладная информатика» и других специальностей, изучающих информатику и информационные технологии.
Ил. 64. Библиогр.: 6 назв.
Рецензент: проф., д-р техн. наук В. И. Ключко
(кафедра ВТ и АСУ, КубГТУ)
© Кубанский государственный
аграрный университет
Оглавление
Введение.. 10
часть 1. введение в теорию структур данных и алгоритмов их обработки.. 12
1.Типы данных.. 13
1.1 Целый тип - INTEGER.. 14
1.2 Вещественный тип - REAL. 15
1.3 Логический тип - BOOLEAN.. 16
1.4 Символьный тип - CHAR.. 16
1.5 Указательный тип - POINTER.. 17
2. Статические и полустатические структуры данных.. 19
2.1 Уровни представления данных. 20
2.2 Классификация структур данных. 21
2.3 Статические структуры данных. 22
2.3.1 Векторы.. 22
2.3.2 Массивы.. 23
2.3.3 Записи. 23
2.3.4 Таблицы.. 26
2.4 Полустатические структуры данных. 27
2.4.1 Стеки. 28
2.4.2 Очередь. 31
2.4.3 Дек. 43
3. Динамические структуры данных.. 46
3.1 Связные списки. 47
3.1.1 Односвязные списки. 47
3.1.2 Кольцевой односвязный список. 48
3.1.3 Двусвязный список. 50
3.1.4 Кольцевой двусвязный список. 51
3.2 Реализация стеков с помощью односвязных списков 51
3.3 Организация операций Getnode, Freenode и утилизация освободившихся элементов. 54
3.3.1 Операция P=GetNode. 55
3.3.2 Операция FreeNode(P). 55
3.3.3 Утилизация освободившихся элементов в многосвязных списках. 56
3.4 Односвязный список, как самостоятельная структура данных. 56
3.4.1 Вставка и извлечение элементов из списка. 58
3.4.2 Примеры типичных операций над списками. 60
3.4.3 Элементы заголовков в списках. 62
3.5 Нелинейные связанные структуры.. 63
4. Рекурсивные структуры данных.. 67
4.1 Деревья. 67
4.1.1 Представление деревьев. 69
4.2 Бинарные деревья. 69
4.2.1 Сведение m-арного дерева к бинарному. 71
4.2.2 Основные операции с деревьями. 73
4.2.3 Создание дерева бинарного поиска. 75
4.2.4 Прохождение (обход) бинарных деревьев. 76
5. Поиск.. 80
5.1 Последовательный поиск. 81
5.2 Индексно-последовательный поиск. 84
5.3 Эффективность последовательного поиска. 85
5.4 Эффективность индексно-последовательного поиска 86
5.5 Методы оптимизации поиска. 87
5.5.1 Переупорядочивание таблицы поиска путем перестановки найденного элемента в начало списка. 88
5.5.2 Метод транспозиции. 89
5.5.3 Дерево оптимального поиска. 91
5.6 Бинарный поиск (метод деления пополам) 93
5.7 Поиск по бинарному дереву. 95
5.8 Поиск со вставкой (с включением) 97
5.9 Поиск с удалением.. 99
6. Сортировка.. 103
6.1 Сортировка методом прямого включения. 104
6.2 Сортировка методом прямого выбора. 107
6.3 Сортировка с помощью прямого обмена (пузырьковая сортировка) 108
6.4 Улучшенные методы сортировки. 111
6.4.1 Быстрая сортировка (Quick Sort) 111
6.4.2 Сортировка Шелла (сортировка с уменьшающимся шагом) 113
7. ПРЕОБРАЗОВАНИЕ КЛЮЧЕЙ (РАССТАНОВКА) 116
7.1. Выбор функции преобразования. 116
7.2. Алгоритм.. 118
часть 2. практикум по сруктурам и алгоритмам обработки данных в эвм... 122
методическое руководство к лабораторным работам... 123
Организационно-методические указания. 123
Полустатические структуры данных.. 125
Лабораторная работа №1 (4 часа). Полустатические структуры данных. 125
Краткая теория. 125
Алгоритмы.. 127
Примеры алгоритмов конкретных задач (стеки и операции над ними) 130
Задания. 146
Динамические структуры данных.. 147
Лабораторная работа №2 (4 часа). Списковые структуры данных. 147
Краткая теория. 148
Алгоритмы.. 149
Линейные однонаправленные списки (односвязные списки) 149
Кольцевые списки. 153
Примеры алгоритмов конкретных задач. 157
Задания. 161
Рекурсивные структуры данных.. 164
Лабораторная работа №3 (4 часа). Бинарные деревья (создание и обход) 164
Краткая теория. 164
Алгоритмы.. 167
Примеры алгоритмов конкретных задач. 172
Задания. 175
Поиск.. 178
Лабораторная работа №4 (4 часа). Исследование методов линейного и бинарного поиска. 178
Краткая теория. 178
Алгоритмы.. 179
Примеры алгоритмов конкретных задач. 187
Задания. 197
Лаборторная работа №5 (4 часа). Исследование методов оптимизации поиска. 199
Краткая теория. 199
Алгоритмы.. 201
Алгоритмы на языке С++. 205
Задания. 208
Лабораторная работа №6 (4 часа). Поиск по дереву с включением и исключением.. 210
Краткая теория. 210
Алгоитмы.. 212
Примеры алгоритмов конкретных задач (поиск по дереву с включением, исключением) 220
Задания. 230
Сортировка.. 232
Лабораторная работа №7 (4 часа). Сортировки методами прямого включения и выбора. 232
Краткая теория. 233
Сортировка методом прямого включения. 234
Алгорим сортировки прямым включением.. 235
Сортировка методом прямого выбора. 236
Алгоритм сортировки прямым выбором.. 239
Примеры алгоритмов и приложений. 242
Задания. 247
Лабораторная работа №8 (4 часа). Сортировки методом прямого обмена и с помощью дерева. 250
Краткая теория. 250
Алгоритмы.. 251
Примеры алгоритмов конкретных задач. 256
Задания. 260
Лабораторная работа №9 (4 часа). Улучшенные методы сортировки. 263
Краткая теория. 263
Алгоритмы.. 266
Примеры алгоритмов конкретных задач. 270
Задания. 274
ТЕСТЫ К ЛАБОРАТОРНЫМ РАБОТАМ.. 276
Методическое руководство к курсовой работе.. 291
1 Требования к курсовой работе. 291
2. Примерный перечень курсовых работ. 292
3. Пример выполнения курсовой работы.. 293
3.1 Постановка задачи. 293
3.2 Краткая теория. 293
3.3 Метод исследования. 297
3.4 Результаты исследования. 298
3.5 Контрольный пример. 299
3.6 Выводы.. 300
3.7 Описание процедур, используемых в программе. 300
Заключение.. 313
Литература.. 315
приложение. Тесты с ответами.. 316
Введение
Компьютер - это машина, которая обрабатывает информацию. Изучение науки об ЭВМ предполагает изучение того, каким образом эта информация организована внутри ЭВМ, как она обрабатывается и как может быть использована. Следовательно, для изучения предмета студенту особенно важно понять концепции организации информации и работы с ней.
Так как вычислительная техника базируется на изучении информации, то первый возникающий вопрос заключается в том, что такое информация. К сожалению, несмотря на то , что концепция информации является краеугольным камнем всей науки о вычислительной технике, на этот вопрос не может быть дано однозначного ответа. В этом контексте понятие "информация" в вычислительной технике сходно с понятием "точка", "прямая" и "плоскость" в геометрии - все это неопределенные термины, о которых могут быть сделаны некоторые утверждения и выводы, но которые не могут быть объяснены в терминах более элементарных понятий.
Базовой единицей информации является бит, который может принимать два взаимоисключающих значения. Если устройство может находиться более чем в двух состояниях, то тот факт, что оно находится в одном из этих состояний, уже требует нескольких битов информации.
Для представления двух возможных состояний некоторого бита используются двоичные цифры - нуль и единица.
Число битов, необходимых для кодирования символа в конкретной вычислительной машине, называется размером байта, а группа битов в этом числе называется байтом. Размер байта в большинстве ЭВМ равен 8.
Память вычислительной машины представляет собой совокупность битов. в любой момент функционирования в ЭВМ каждый из битов памяти имеет значение 0 или 1 (сброшен или установлен). Состояние бита называется его значением или содержимым.
Биты в памяти ЭВМ группируются в элементы большего размера, например в байты. В некоторых ЭВМ несколько байтов объединяются в группы, называемые словами. Каждому такому элементу назначается адрес, который представляет собой имя, идентифицирующее конкретный элемент памяти среди аналогичных элементов. Этот адрес обычно числовой. Он называется ячейкой, а содержимое ячейки есть значение битов, которые ее составляют.
Итак, мы видим, что информация в ЭВМ сама по себе не имеет конкретного смысла. С некоторой конкретной битовой комбинацией может быть связано любое смысловое значение. Именно интерпретация битовой комбинации придает ей заданный смысл.
Метод интерпретации битовой информации часто называется типом данных. Каждая ЭВМ имеет свой набор типов данных.
Важно осознавать роль, выполняемую спецификацией типа в языках высокого уровня. Именно посредством подобных объявлений программист указывает на то, каким образом содержимое памяти ЭВМ интерпретируется программой. Эти объявления детерминируют объем памяти, необходимый для размещения отдельных элементов, способ интерпретации этих элементов и другие важные детали. Объявления также сообщают интерпретатору точное значение используемых символов операций.
часть 1.
введение в теорию структур данных и алгоритмов их обработки
Типы данных
В математике принято классифицировать переменные в соответствие с некоторыми важными характеристиками. Мы различаем вещественные, комплексные и логические переменные, переменные, представляющие собой отдельные значения, множества значений или множества множеств. В обработке данных понятие классификации играет такую же, если не большую роль. Мы будем придерживаться того принципа, что любая константа, переменная, выражение или функция относятся к некоторому типу.
Фактически тип характеризует множество значений, которые может принимать некоторая переменная или выражение и которые может формировать функция.
В большинстве языков программирования различают стандартные типы данных и типы, заданные пользователем. Также в большинстве языков программирования в стандартных типах присутствуют следующие:
a ) целый ( INTEGER );
b) вещественный (REAL) ;
c) логический (BOOLEAN);
d) символьный (CHAR);
E) указательный (POINTER).
Пользовательские типы могут варьироваться в зависимости от языка программирования и предоставляемых программисту возможностей решений конкретных задач.
Любой тип данных должен быть охарактеризован областью значений и допустимыми операциями над этим типом данных.
Целый тип - INTEGER
Этот тип включает некоторое подмножество целых, размер которого варьируется от машины к машине. Если для представления целых чисел в машине используется n разрядов, причем используется дополнительный код, то допустимые числа должны удовлетворять условию -2 n-1<= x< 2 n-1.
Считается, что все операции над данными этого типа выполняются точно и соответствуют обычным правилам арифметики. Если результат выходит за пределы представимого множества, то вычисления будут прерваны. Такое событие называется переполнением.
Числа делятся на знаковые и беззнаковые. Для каждого из них имеется свой диапазон значений:
a)(0..2n-1) для беззнаковых чисел
b) (-2N-1.. 2N-1-1) для знаковых.

При обработке машиной чисел, используется формат со знаком. Если же машинное слово используется для записи и обработки команд и указателей, то в этом случае используется формат без знака.
Операции над целым типом:
a) Сложение.
b) Вычитание.
c) Умножение.
d) Целочисленное деление.
e) Нахождение остатка по модулю.
f) Нахождение экстремума числа (минимума и максимума)
g) Реляционные операции (операции сравнения) (<,>,<=, >=,=,<>)
Примеры:
A div B = C
A mod B = D
C * B + D = A
7 div 3 = 2
7 mod 3 = 1
Во всех операциях, кроме реляционных, в результате получается целое число.
Вещественный тип - REAL
Вещественные типы образуют ряд подмножеств вещественных чисел, которые представлены в машинных форматах с плавающей точкой. Числа в формате с плавающей точкой характеризуются целочисленными значениями мантиссы и порядка, которые определяют диапазон изменения и количество верных знаков в представлении чисел вещественного типа.
X = +/- M * q(+/-P) - полулогарифмическая форма представления числа, показана на рисунке 1.2.
937,56 = 93756 * 10-2 = 0,93756 * 103
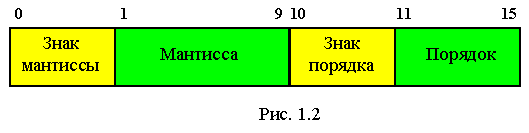
Удвоенная точность необходима для того, чтобы увеличить точность мантиссы.
Логический тип - BOOLEAN
Стандартный логический тип Boolean (размер-1 байт) представляет собой тип данных, любой элемент которого может принимать лишь 2 значения: True и False.
Над логическими элементами данных выполняются логические операции. Основные из них:
a) Отрицание (NOT)
b) Конъюнкция (AND)
c) Дизъюнкция (OR)
Таблица истинности основных логических функций.
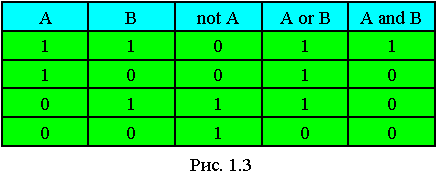
Логические значения получаются также при реляционных операциях с целыми числами.
Символьный тип - CHAR
Тип CHAR содержит 26 прописных латинских букв и 26 строчных, 10 арабских цифр и некоторое число других графических символов, например, знаки пунктуации.
Подмножества букв и цифр упорядочены и "соприкасаются", т.е.
("A"<= x)&(x <= "Z") - x представляет собой прописную букву
("0"<= x)&(x <= "9") - x представляет собой цифру
Тип CHAR содержит некоторый непечатаемый символ, пробел, его можно использовать как разделитель.
Операции:
a) Присваивания
b) Сравнения
c) Определения номера данной литеры в системе кодирования. ORD(Wi)
d) Нахождение литеры по номеру. CHR(i)
e) Вызов следующей литеры. SUCC(Wi)
f) Вызов предыдущей литеры. PRED(Wi)
Указательный тип - POINTER
Переменная типа указатель является физическим носителем адреса величины базового типа. Cтандартный тип-указатель Pointer дает указатель, не связанный ни с каким конкретным базовым типом. Этот тип совместим с любым другим типом-указателем.
Операции:
a) Присваивания
b) Операции с беззнаковыми целыми числами.
При помощи этих операций можно вычислить адрес данных. В машинном виде эти типы занимают максимально возможную длину.
Например:
ABCD:1234 - значение указателя в шестнадцатеричной системе счисления - относительный адрес.
Первое число (ABCD) - адрес сегмента
Второе число (1234) - адрес внутри сегмента.
Для получения абсолютного адреса необходимо произвести сдвиг адреса сегмента влево, и к полученному числу прибавить адрес внутреннего сегмента.
Например:
1) Сдвигаем ABCD на один разряд влево. Получаем АВСD0.
2) Прибавляем 1234. Полученный результат и является абсолютным адресом.
ABCD0
12 3 4
----------
ACF04 - абсолютный адрес данного числа.
Контрольные вопросы:
1. Какие типы данных вы знаете?
2. Как представляются целые числа?
3. Как представляются вещественные числа?
4. Что представляют собой данные логического типа?
5. Какому условию должны удовлетворять допустимые числа типа INTEGER?
6. Какие операции можно производить над целыми числами?
7. Перечислите булевские операции.
8. Какова структура типа CHAR?
9. Какие операции возможны над данными этого типа?
10. Что можно вычислить с помощью данных указательного типа?
Дата: 2019-12-10, просмотров: 228.